In diesem Frühjahr fand ein bedeutender OpenAI Retro Contest statt, der sich dem verstärkten Lernen, Meta-Lernen und natürlich Sonic widmete. Unser Team belegte den 4. Platz von über 900 Teams. Das Trainingsfeld mit Verstärkung unterscheidet sich geringfügig vom normalen maschinellen Lernen, und dieser Wettbewerb unterschied sich von einem typischen RL-Wettbewerb. Ich frage nach Details unter Katze.
TL; DR
Eine richtig abgestimmte Grundlinie benötigt keine zusätzlichen Tricks ... praktisch.
Einführung in das Verstärkungstraining
Verstärktes Lernen ist ein Bereich, der die Theorie der optimalen Kontrolle, die Spieltheorie, die Psychologie und die Neurobiologie kombiniert. In der Praxis wird das verstärkte Lernen verwendet, um Entscheidungsprobleme zu lösen und nach optimalen Verhaltensstrategien oder Richtlinien zu suchen, die für eine „direkte“ Programmierung zu komplex sind. In diesem Fall wird der Agent in der Geschichte der Interaktionen mit der Umgebung geschult. Die Umgebung, die wiederum die Aktionen des Agenten bewertet, bietet ihm eine Belohnung (Skalar) - je besser sich der Agent verhält, desto höher ist die Belohnung. Infolgedessen wird die beste Richtlinie von dem Agenten gelernt, der gelernt hat, die Gesamtbelohnung für die gesamte Zeit der Interaktion mit der Umgebung zu maximieren.
Als einfaches Beispiel können Sie BreakOut spielen. In diesem guten alten Spiel der Atari-Serie muss eine Person / ein Agent die untere horizontale Plattform kontrollieren, den Ball schlagen und damit allmählich alle oberen Blöcke brechen. Je mehr niedergeschlagen - desto größer die Belohnung. Dementsprechend sieht eine Person / ein Agent ein Bildschirmbild und es ist notwendig, eine Entscheidung zu treffen, in welche Richtung die untere Plattform bewegt werden soll.
Wenn Sie sich für das Thema Verstärkungstraining interessieren, empfehle ich Ihnen einen coolen Einführungskurs von HSE sowie dessen detaillierteres Open-Source-Gegenstück . Wenn Sie etwas wollen, das Sie lesen können, aber mit Beispielen - ein Buch, das von diesen beiden Kursen inspiriert ist. Ich habe all diese Kurse überprüft / abgeschlossen / mitgestaltet und weiß daher aus eigener Erfahrung, dass sie eine hervorragende Grundlage bieten.
Über die Aufgabe
Das Hauptziel dieses Wettbewerbs war es, einen Agenten zu finden, der in der SEGA-Reihe gut spielen kann - Sonic The Hedgehog. OpenAI begann gerade damit, Spiele von SEGA in seine Plattform für die Schulung von RL-Agenten zu importieren, und beschloss daher, diesen Moment ein wenig zu fördern. Sogar der Artikel wurde mit dem Gerät von allem und einer detaillierten Beschreibung der grundlegenden Methoden veröffentlicht.
Alle 3 Sonic-Spiele wurden mit jeweils 9 Levels unterstützt, bei denen Sie durch Schnippen einer tränenreichen Träne sogar spielen und sich an Ihre Kindheit erinnern konnten (nachdem Sie sie zuerst bei Steam gekauft hatten).
Als Zustand der Umgebung (was der Agent sah) war das Bild vom Simulator ein RGB-Bild, und als Aktion wurde der Agent aufgefordert, auszuwählen, welche Taste auf dem virtuellen Joystick gedrückt werden soll - springen / links / rechts und so weiter. Der Agent erhielt Belohnungspunkte sowie im ursprünglichen Spiel, d.h. zum Sammeln von Ringen sowie für die Geschwindigkeit des Passierens des Levels. Tatsächlich hatten wir einen Original-Schall vor uns, nur war es notwendig, ihn mit Hilfe unseres Agenten durchzugehen.
Der Wettbewerb fand vom 5. April bis 5. Juni statt, d.h. nur 2 Monate, was ziemlich klein genug scheint. Unser Team konnte erst im Mai zusammenkommen und am Wettbewerb teilnehmen, wodurch wir unterwegs viel lernen konnten.
Baselines
Als Basis wurden vollständige Schulungsleitfäden für das Regenbogentraining (DQN-Ansatz) und PPO (Policy Gradient-Ansatz) auf einer der möglichen Ebenen in Sonic und die Übermittlung des resultierenden Agenten angegeben.
Die Rainbow-Version basierte auf dem wenig bekannten Anyrl- Projekt, aber PPO verwendete die guten alten Baselines von OpenAI und schien uns viel vorzuziehen.
Die veröffentlichten Basislinien unterschieden sich von den im Artikel beschriebenen Ansätzen durch ihre größere Einfachheit und kleinere Mengen von „Hacks“, um das Lernen zu beschleunigen. So haben die Organisatoren Ideen geworfen und die Richtung festgelegt, aber die Entscheidung über die Verwendung und Umsetzung dieser Ideen wurde dem Teilnehmer des Wettbewerbs überlassen.
In Bezug auf Ideen möchte ich OpenAI für die Offenheit und John Schulman für die Ratschläge, Ideen und Vorschläge danken, die er zu Beginn dieses Wettbewerbs geäußert hat. Wir, wie viele Teilnehmer (und vor allem Neulinge in der RL-Welt), konnten uns so besser auf das Hauptziel des Wettbewerbs konzentrieren - Meta-Lernen und Verbesserung der Generalisierung von Agenten, über die wir jetzt sprechen werden.
Merkmale der Entscheidungsbewertung
Das Interessanteste begann zum Zeitpunkt der Bewertung der Agenten. In typischen RL-Wettbewerben / Benchmarks werden Algorithmen in derselben Umgebung getestet, in der sie trainiert wurden. Dies trägt zu Algorithmen bei, die sich gut erinnern können und viele Hyperparameter aufweisen. Im selben Wettbewerb wurde der Test des Algorithmus auf den neuen Sonic-Levels durchgeführt (die niemandem gezeigt wurden), die vom OpenAI-Team speziell für diesen Wettbewerb entwickelt wurden. Die Kirsche auf dem Kuchen war die Tatsache, dass das Mittel während des Testprozesses auch während des Durchgangs des Levels eine Belohnung erhielt, die es ermöglichte, direkt im Testprozess umzuschulen. In diesem Fall sollte jedoch beachtet werden, dass die Tests sowohl zeitlich - 24 Stunden als auch in Spielzecken - auf 1 Million begrenzt waren. Gleichzeitig unterstützte OpenAI nachdrücklich die Erstellung von Agenten, die schnell neue Ebenen erreichen können. Wie bereits erwähnt, war das Erhalten und Studieren solcher Lösungen das Hauptziel von OpenAI während dieses Wettbewerbs.
Im akademischen Umfeld wird die Richtung des Studiums von Richtlinien, die sich schnell an neue Bedingungen anpassen können, als Meta-Lernen bezeichnet und hat sich in den letzten Jahren aktiv weiterentwickelt.
Im Gegensatz zu den üblichen Kaggle-Wettbewerben, bei denen die gesamte Einreichung auf das Senden Ihrer Antwortdatei hinausläuft, musste das Team bei diesem Wettbewerb (und in der Tat bei RL-Wettbewerben) seine Lösung in einen Docker-Container mit der angegebenen API einwickeln, sammeln und senden Docker-Bild. Dies erhöhte die Schwelle für die Teilnahme am Wettbewerb, machte den Entscheidungsprozess jedoch viel ehrlicher - die Ressourcen und die Zeit für das Docker-Image waren begrenzt, zu schwere und / oder langsame Algorithmen haben die Auswahl einfach nicht bestanden. Es scheint mir, dass dieser Ansatz zur Bewertung viel vorzuziehen ist, da er Forschern ohne einen „Heimatcluster aus DGX und AWS“ ermöglicht, mit Liebhabern von Glas-50000-Modellen auf Augenhöhe zu konkurrieren. Ich hoffe, in Zukunft mehr von dieser Art von Wettbewerb zu sehen.
Das Team
Kolesnikov Sergey ( Scitator )
RL-Enthusiast. Zum Zeitpunkt des Wettbewerbs schrieb und verteidigte ein Student am Moskauer Institut für Physik und Technologie (MIPT) ein Diplom des letztjährigen NIPS: Learning to Run-Wettbewerbs (ein Artikel, über den auch geschrieben werden sollte).
Senior Data Scientist @ Dbrain - Wir bringen produktionsbereite Wettbewerbe mit Docker und begrenzten Ressourcen in die reale Welt.
Pawlow Michail ( fgvbrt )
Senior Research Developer DiphakLab . Wiederholte Teilnahme und gewann Preise bei Hackathons und verstärkten Trainingswettbewerben.
Sergeev Ilya ( sergeevii123 )
RL-Enthusiast. Ich habe einen von Deephacks RL-Hackathons geschlagen und alles begann. Data Scientist @ Avito.ru - Computer Vision für verschiedene interne Projekte.
Sorokin Ivan ( 1ytic )
Spracherkennung in languagepro.ru .
Ansätze und Lösung
Nach einem schnellen Test der vorgeschlagenen Baselines fiel unsere Wahl auf den OpenAI-Ansatz - PPO - als eine formellere und interessantere Option für die Entwicklung unserer Lösung. Darüber hinaus hat der PPO-Agent nach seinem Artikel für diesen Wettbewerb die Aufgabe etwas besser gemeistert. Aus demselben Artikel wurden die ersten Verbesserungen geboren, die wir in unserer Lösung verwendet haben, aber das Wichtigste zuerst:
Kollaboratives PPO-Training auf allen verfügbaren Ebenen
Die angelegte Basislinie wurde nur auf einer der verfügbaren 27 Sonic-Ebenen trainiert. Mit Hilfe kleiner Modifikationen war es jedoch möglich, das Training sofort auf alle 27 Stufen zu parallelisieren. Aufgrund der größeren Vielfalt im Training hatte der resultierende Agent eine viel größere Verallgemeinerung und ein besseres Verständnis des Geräts der Sonic-Welt und kam daher um eine Größenordnung besser zurecht.
Zusätzliches Training während des Testens
Um auf die Hauptidee des Wettbewerbs, das Meta-Lernen, zurückzukommen, war es notwendig, einen Ansatz zu finden, der die maximale Verallgemeinerung aufweist und sich leicht an neue Umgebungen anpassen lässt. Und zur Anpassung war es notwendig, den vorhandenen Agenten für die Testumgebung neu zu schulen, was tatsächlich durchgeführt wurde (auf jeder Teststufe unternahm der Agent 1 Million Schritte, was ausreichte, um sich an eine bestimmte Ebene anzupassen). Am Ende jedes Testspiels bewertete der Agent die erhaltene Auszeichnung und optimierte seine Richtlinien anhand der gerade erhaltenen Geschichte. Es ist wichtig anzumerken, dass es bei diesem Ansatz wichtig ist, nicht alle Ihre bisherigen Erfahrungen zu vergessen und sich unter bestimmten Bedingungen nicht zu verschlechtern, was im Wesentlichen das Hauptinteresse des Meta-Lernens ist, da ein solcher Agent sofort seine gesamte vorhandene Fähigkeit zur Verallgemeinerung verliert.
Explorationsboni
Der Agent ging tief in die Vergütungsbedingungen für ein Level ein und erhielt eine Belohnung dafür, dass er sich entlang der x-Koordinate vorwärts bewegte. Er konnte auf einigen Levels stecken bleiben, wenn man zuerst vorwärts und dann zurück musste. Es wurde beschlossen, die Belohnung für den Agenten, die sogenannte zählbasierte Erkundung , zu ergänzen, wenn der Agent eine kleine Belohnung erhielt, wenn er sich in einem Zustand befand, in dem er sich noch nicht befand. Es wurden zwei Arten von Explorationsboni implementiert: basierend auf dem Bild und basierend auf der x-Koordinate des Agenten. Eine Belohnung basierend auf einem Bild wurde wie folgt berechnet: Für jede Pixelposition im Bild wurde gezählt, wie oft jeder Wert für eine Episode auftrat, die Belohnung war umgekehrt proportional zum Produkt über alle Pixelpositionen hinweg, wie oft die Werte an diesen Positionen für eine Episode übereinstimmten. Die auf der x-Koordinate basierende Belohnung wurde auf ähnliche Weise berücksichtigt: Für jede x-Koordinate (mit einer bestimmten Genauigkeit) wurde gezählt, wie oft sich der Agent in dieser Koordinate für die Episode befand. Die Belohnung ist umgekehrt proportional zu diesem Betrag für die aktuelle x-Koordinate.
Verwechslungsexperimente
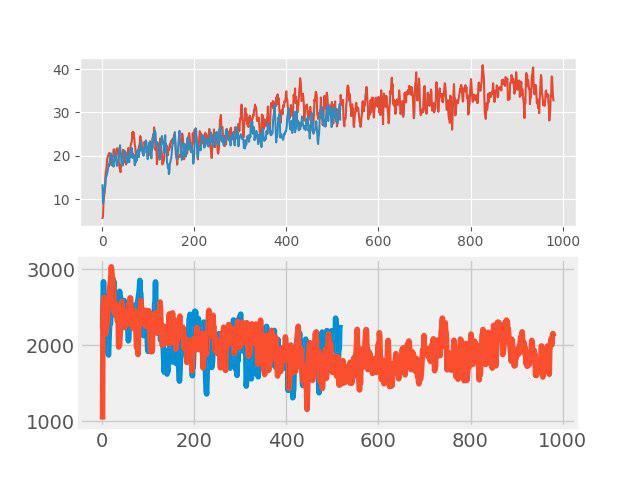
Beim „Unterrichten mit einem Lehrer“ wurde kürzlich eine einfache, aber effektive Methode zur Datenerweiterung, die sogenannte Verwechslung. Die Idee ist sehr einfach: Das Hinzufügen von zwei beliebigen Eingabebildern erfolgt und eine gewichtete Summe der entsprechenden Beschriftungen wird diesem neuen Bild zugewiesen (z. B. 0,7 Hund + 0,3 Katze). Bei Aufgaben wie Bildklassifizierung und Spracherkennung zeigt die Verwechslung gute Ergebnisse. Daher war es interessant, diese Methode für RL zu testen. Die Augmentation wurde in jeder großen Charge durchgeführt, die aus mehreren Episoden bestand. Eingabebilder wurden in Pixel gemischt, aber mit Tags war nicht alles so einfach. Die Werte return, values und neglogpacs wurden durch eine gewichtete Summe gemischt, aber die Aktion (Aktionen) wurde aus dem Beispiel mit dem maximalen Koeffizienten ausgewählt. Eine solche Lösung zeigte keinen spürbaren Anstieg (obwohl es anscheinend einen Anstieg der Verallgemeinerung geben sollte), verschlechterte jedoch nicht die Basislinie. Die folgenden Grafiken vergleichen den PPO-Algorithmus mit Verwechslung (rot) und ohne Verwechslung (blau): Oben ist die Belohnung während des Trainings, unten ist die Länge der Episode.
Auswahl der besten Anfangspolitik
Diese Verbesserung war eine der letzten und trug wesentlich zum Endergebnis bei. Auf der Trainingsebene wurden verschiedene Richtlinien mit unterschiedlichen Hyperparametern trainiert. Auf der Testebene wurde für die ersten Episoden jede von ihnen getestet, und für die weitere Schulung wurde die Richtlinie ausgewählt, die die maximale Testbelohnung für die Episode ergab.
Patzer
Und nun zur Frage, was versucht wurde, aber "nicht geflogen". Immerhin ist dies kein neuer SOTA-Artikel, um etwas zu verbergen.
- Änderung der Netzwerkarchitektur: SELU-Aktivierung , Selbstaufmerksamkeit, SE-Blöcke
- Neuroevolution
- Erstellen Sie Ihre eigenen Sonic-Levels - alles wurde vorbereitet, aber es war nicht genug Zeit
- Meta-Training durch MAML und REPTILE
- Zusammenstellung mehrerer Modelle und Weiterbildung während des Testens jedes Modells unter Verwendung von Wichtigkeitsstichproben
Zusammenfassung
3 Wochen nach Ende des Wettbewerbs veröffentlichte OpenAI die Ergebnisse . Bei 11 zusätzlichen, zusätzlich erstellten Levels erhielt unser Team einen ehrenwerten 4. Platz, nachdem es in einem öffentlichen Test vom 8. aufgesprungen war und die verdeckten Basislinien von OpenAI überholt hatte.
Die Hauptunterscheidungsmerkmale, die im ersten 3ki „geflogen“ sind:
- Verbessertes Aktionssystem (eigene Schaltflächen, zusätzliche entfernt);
- Untersuchung von Zuständen durch Hash aus dem Eingabebild;
- Mehr Ausbildungsniveau;
Darüber hinaus möchte ich darauf hinweisen, dass in diesem Wettbewerb neben dem Gewinn auch die Beschreibung ihrer Entscheidungen sowie Materialien, die anderen Teilnehmern geholfen haben, aktiv gefördert wurden - es gab auch eine separate Nominierung dafür. Was wiederum den Lampenwettbewerb erhöhte.
Nachwort
Ich persönlich mochte diesen Wettbewerb ebenso wie das Meta-Learning-Thema sehr. Während der Teilnahme lernte ich eine große Liste von Artikeln kennen (einige habe ich nicht einmal vergessen ) und lernte eine Vielzahl verschiedener Ansätze, die ich hoffentlich in Zukunft anwenden werde.
In der besten Tradition der Teilnahme am Wettbewerb ist der gesamte Code verfügbar und wird auf github veröffentlicht .