
Im
vorherigen Artikel zum Thema staatliches Risikomanagement haben wir die Grundlagen durchgearbeitet: Warum sollten staatliche Behörden Risiken managen, wo sie zu suchen sind und wie sie bewertet werden. Heute werden wir über den Risikoanalyseprozess sprechen: wie man die Ursachen ihres Auftretens identifiziert und Verstöße identifiziert.
Risikobewertung
Um das Risiko zu bewerten - auch im Rahmen eines statischen, wenn auch dynamischen Ansatzes - müssen Sie die Ursachen und Bedingungen des Auftretens ermitteln und die Hauptmerkmale bestimmen: die Wahrscheinlichkeit und den potenziellen Schaden durch die Implementierung.
Nehmen wir zum Beispiel die Zollabfertigung: Wenn Sie ein Produkt in das Land importieren, mit Ausnahme einer Vielzahl unterschiedlicher Informationen (Kosten, Gewicht, Verpackung, Absender, Empfänger usw.), muss in der Erklärung eine Erklärung gemäß einem speziellen Klassifikator abgegeben werden - der Warennomenklatur der außenwirtschaftlichen Tätigkeit (TN FEA). Dieser Code für die Waren bestimmt dann den Zoll gemäß dem Zolltarif (TN FEA + Sätze).
Der Zolltarif ist ein komplexer Klassifikator: Auf den ersten Blick können einige Waren unterschiedlichen Codes mit unterschiedlichen Zollsätzen zugeordnet werden. Beispielsweise können Sie mit komplexen Bergbaumaschinen nur umgehen, indem Sie sich mit deren Zeichnungen befassen. Daher die Versuchung des Importeurs, den falschen (aber der Wahrheit ähnlichen) Code zu deklarieren, um weniger Geld für das Budget zu zahlen.
Also haben wir
das Risiko identifiziert - die Angabe eines unzuverlässigen Produktcodes in der Erklärung, um Zollzahlungen zu unterschätzen. Der Grund ist das Vorhandensein von „Grenzpositionen“ mit unterschiedlichen Zollsätzen im Klassifikator.
Es ist schwieriger, die Bedingungen für das Eintreten eines solchen Risikos zu ermitteln - wann und mit welchen Gütern es in der Praxis geschieht. Dazu müssen Sie
eine Risikoanalyse durchführen : um die Geschichte der Beobachtungen von Kontrollobjekten zu untersuchen, um herauszufinden, wann und wer den falschen Produktcode behauptet hat, und um einige allgemeine Merkmale dieser Fälle zu identifizieren. Auf diese Weise können
Regeln für das künftige Risikomanagement formuliert werden: Welche Objekte werden dem Risiko zugeordnet und welche Prüfung muss durchgeführt werden?
Der einfachste Weg, diese Regeln zu erhalten, besteht darin, dem Expertenurteil Ihrer Mitarbeiter zu vertrauen.
Expertenregeln
Solche Regeln zur Identifizierung von Risiken sind Fachspezialisten. Sie lassen sich von ihrer Berufserfahrung leiten oder fassen die Meinungen von Kollegen zusammen, die jeden Tag auf Verstöße stoßen. Das Ergebnis sind einfache Urteile der Form "wenn ... dann ...".
Die Wahrscheinlichkeit des Eintretens eines Risikos und der potenzielle Schaden durch die Bedrohung werden in diesem Fall „durch das Auge“ oder durch grobe Schätzungen bestimmt.
Der Vorteil von Expertenregeln ist die einfache Zusammenstellung und Interpretation durch den Menschen. Der Nachteil ist, dass eine große Anzahl von Personen, sowohl Rechtsverletzer als auch angesehene Wirtschaftszweige, gleichzeitig unter die Regel fallen können. Daher ist die Wirksamkeit der Kontrolle gering. Gleichzeitig werden einige Verstöße vorbeigehen, bei denen der Experte Muster nicht erkennen und berücksichtigen konnte.
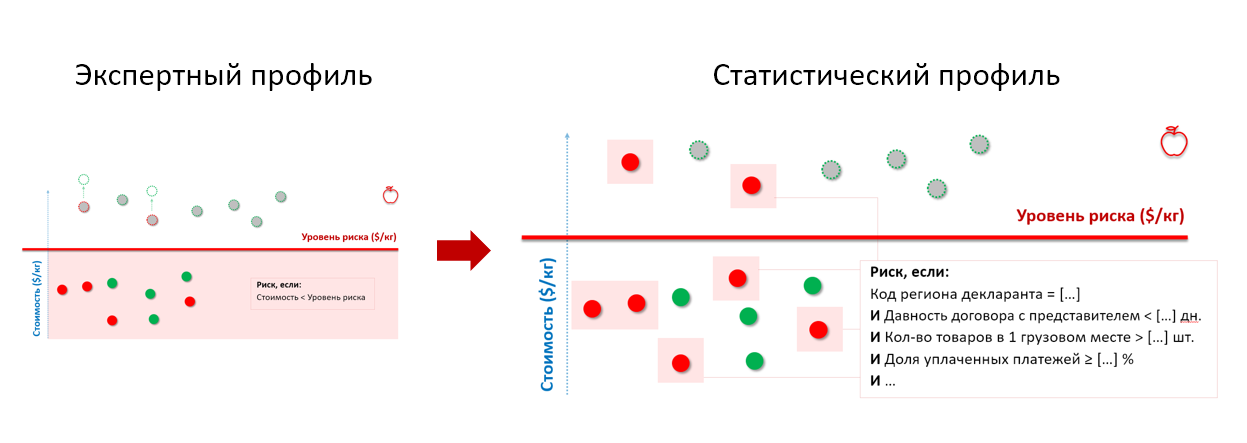
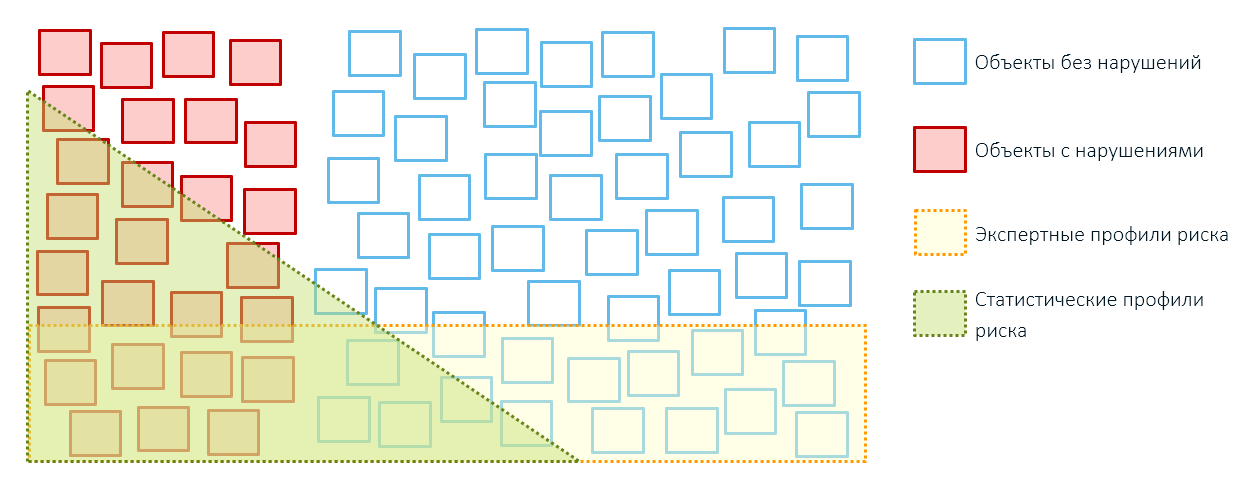
Eine Expertenregel für die Zollkontrolle besagt beispielsweise, dass sich alle Chargen von Äpfeln mit einem Wert unter einem bestimmten Schwellenwert auf Risikolieferungen beziehen:

Wenn wir die Kontrolle durchführen, werden wir sowohl Waren mit Unregelmäßigkeiten (rot) als auch ganz normale Lieferungen (grün) finden, deren niedrige Kosten durch individuelle Rabatte, den Kampf des Absenders mit Überbeständen oder das Wirtschaftsmodell von Unternehmen erklärt werden.
Alles, was über diesem Schwellenwert für bedingte Werte (rote Linie) liegt, ist außer Kontrolle (graue Kreise). Wenn wir sie aber auch überprüfen, werden wir sowohl wirklich legitime Lieferungen als auch Lieferungen finden, deren tatsächlicher Wert noch höher ist als in der Erklärung angegeben (graue Kreise mit rot gestricheltem Umriss) und für die die Zollzahlungen nicht vollständig bezahlt werden.
Daher führt die Anwendung von Expertenregeln normalerweise zu einer übermäßigen Abdeckung von Kontrollobjekten und einer geringen Leistung (denken Sie daran, unsere Boxen aus dem ersten Artikel?):
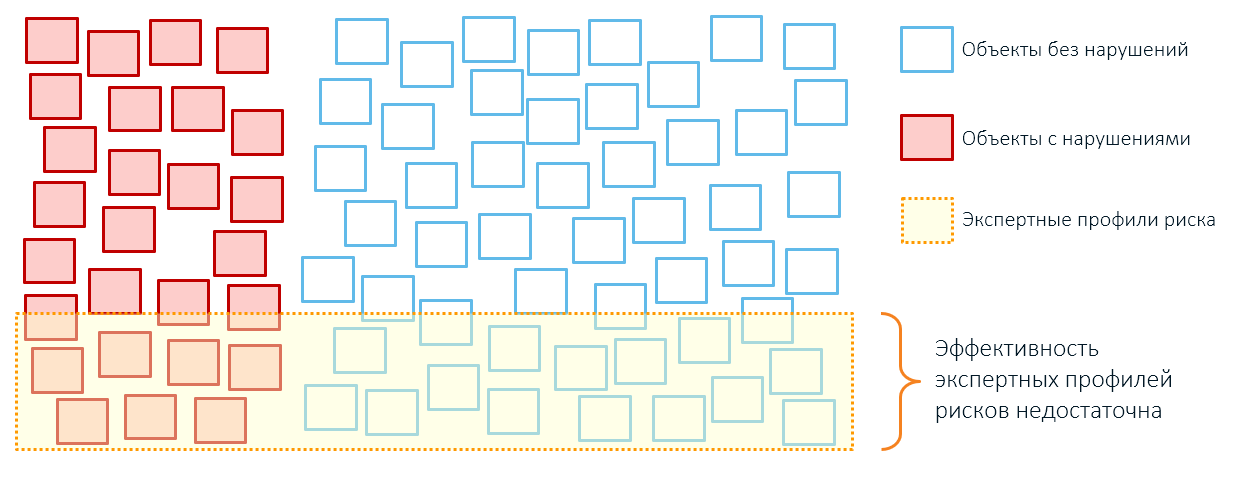
Experten sollten nicht beschuldigt werden: Das menschliche Bewusstsein ist in den Objekten, mit denen es arbeiten kann, begrenzt (ein merkwürdiger Artikel wurde einmal über Habr veröffentlicht, dessen Autor darauf hinwies, dass ihre Anzahl auf sieben begrenzt ist). Daher die großen Striche anstelle der genauen Details: Nehmen wir an, die Brandgefahr wird nur durch das Baujahr des Gebäudes, den Standort und die Kategorie der Bewohner bestimmt. Alle diese Eigenschaften wurden einmal „gespielt“: In einem alten Haus brach ein Feuer aus, in einem funktionsgestörten Bereich brannte ein Raum. Experten erwarten daher zukünftige Bedrohungen genau von Objekten dieser Art.
Aber nicht alle dieser „gefährlichen“ Gebäude werden tatsächlich niederbrennen, auch wenn sie unter die Expertenregel fallen: Viele alte und hölzerne Häuser stehen so, als wäre nichts passiert. Einige funktionsgestörte Häuser stehen seit Jahren ohne Feuer. Es ist nur so, dass der Experte einige subtile individuelle Merkmale gefährlicher Objekte nicht berücksichtigen konnte.
Hier kommt maschinelles Lernen ins Spiel, mit dem
statistische Risikoprofile erstellt werden können . Sie entstehen, wenn wir Datenanalysetechnologien auf die Historie von Verstößen und Informationen über kontrollierte Objekte anwenden.
Statistische Risikoprofile
In diesem Fall lösen wir das Problem der binären Klassifizierung: Ein spezieller analytischer Algorithmus bestimmt selbst, welche Eigenschaften der Objekte es ermöglichen, sie „schlecht“ oder „gut“ zuzuordnen. Wenn alles richtig gemacht wird, erhalten wir am Ende ziemlich genaue Risikobewertungen: detaillierte Bedingungen und automatisch berechnete Wahrscheinlichkeit plus potenzieller Schaden (die mit einem Expertenansatz auch irgendwie „fachmännisch“ ermittelt werden). Diese Merkmale definieren ein „Risikoprofil“ - was, wo, wann und wie beängstigend.
Statistische Risikoprofile werden auf unterschiedliche Weise erstellt. Es kann auf einem Entscheidungsbaum oder einer zufälligen Gesamtstruktur basieren. Sie können ein kniffliges neuronales Netzwerk mit einer großen Anzahl versteckter Ebenen anwenden.
Wir bei SAS sind jedoch der Ansicht, dass es für die Zwecke der staatlichen Kontrolle besser ist, statistische Risikoprofile auf der Grundlage interpretierter Algorithmen zu erstellen, z. B.
Regression oder
Entscheidungsbaum . Die Praxis hat gezeigt, dass es für eine staatliche Stelle schwierig ist, sich zu orientieren, selbst wenn es sich um eine genaue, aber unverständliche Vorhersage einer Maschine handelt, wenn sie nicht erklärt, warum diese angesehene Person als Bösewicht eingestuft wird.
Die staatliche Behörde muss genau verstehen, welche Faktoren auf eine Bedrohung hinweisen und welcher der Verstöße dieselben Merkmale aufweist, da es Verfahren zur Genehmigung von Managemententscheidungen gibt (ein besonderer Fall sind Risikoprofile). Der Beamte sollte verstehen, was genau er "in die Schlacht" startet, da er für das Ergebnis des Risikoprofils verantwortlich ist.
Jede Überprüfung sollte gerechtfertigt sein und diese Rechtfertigung sollte in Worten ausgedrückt werden. Andernfalls müssen Sie vor dem Staatsanwalt rot werden und erklären, wie sich herausstellte, dass die staatliche Behörde das Inlandsgeschäft auf der Grundlage der mysteriösen Anweisungen von deus ex machina „kneift“.
Daher sieht das statistische Risikoprofil auch wie eine Regel aus, die gelesen und verstanden werden kann. Nur die Liste der Merkmale, die mögliche Verstöße beschreiben, ist größer und komplexer als die der Expertenprofile:
 * Profilparameterwerte werden geändert und entsprechen nicht den tatsächlichen Werten
* Profilparameterwerte werden geändert und entsprechen nicht den tatsächlichen WertenEine Reihe von
Risikoindikatoren (Bedingungen) mag etwas bizarr erscheinen. Dies ist jedoch keine „große Zauberei“ - einfach mit Hilfe von Technologien für maschinelles Lernen und den begrenzten Informationen, die wir haben, beschreiben wir ein verstecktes Muster menschlichen Verhaltens, das zu Störungen führt.
Gleiches gilt für die Steuerkontrolle: Verstöße können von der Gesamtmasse der Steuerzahler bestimmte Betragsbereiche bestimmter Transaktionen, Fristen für die Einreichung von Erklärungen, die Anzahl der Mitarbeiter des Unternehmens, die Anzahl der Konten und einen weiteren Satz von 30 verschiedenen Parametern unterscheiden, die zusammen skrupellose Unternehmer beschreiben, die die Mehrwertsteuer unterschätzen.
Eine Person wird nicht in der Lage sein, alle diese Merkmale zu vergleichen, sie wird es mit drei oder fünf schaffen, die leichter zu verstehen sind. Und das Programm kann. So detailliert wie erforderlich. Beim Erstellen eines Modells durchläuft der Algorithmus automatisch eine Vielzahl von Daten und findet heraus, was die Täter gemeinsam haben - auch wenn es sich um eine Liebe zu roten Bindungen in einem gelben Netz handelt.
Dies ähnelt der Beschreibung des Verbrechers in seinen individuellen Merkmalen: der Form der Nase, der Ohren, der Biegung der Augenbrauen, der Farben der Hemden und der Länge des Fußes. Wir kennen sein Gesicht, seine Größe und sein Gewicht nicht, aber wir haben tausend seiner Eigenschaften, einschließlich der Länge der Haare auf der Phalanx des linken kleinen Fingers. Jeder dieser Parameter gibt keine kriminellen Absichten aus - Sie müssen einer Person nicht nur wegen des Krümmungsradius ihrer Ohrmuscheln Handschellen anlegen. Aber die gesamte Menge dieser Eigenschaften bildet zusammen ein ziemlich genaues Porträt des Eindringlings:
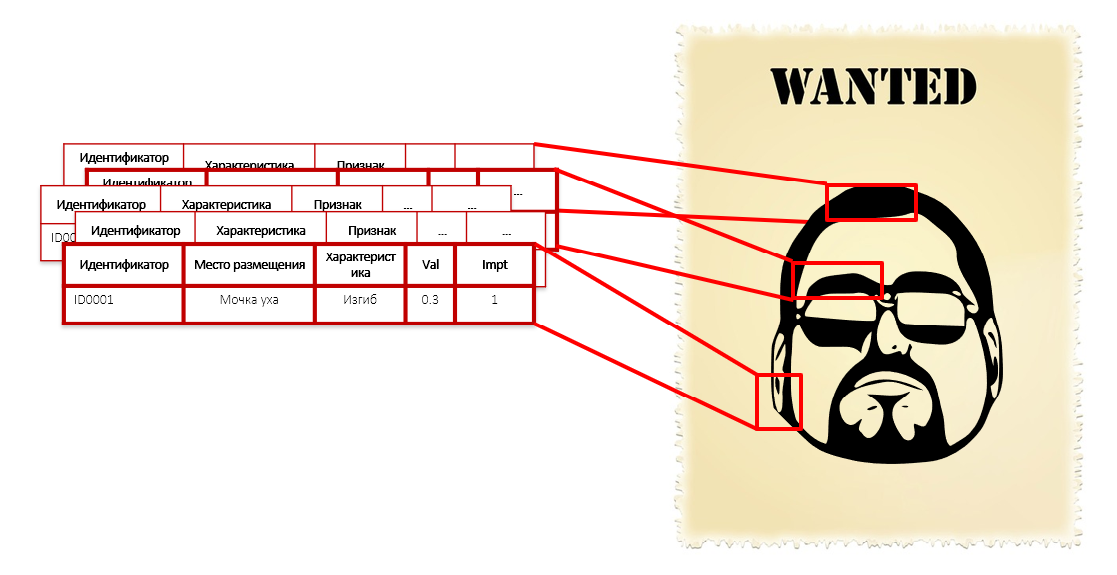
Wenn wir von der Anwendung von Expertenregeln zur statistischen Profilerstellung auf der Grundlage einer Analyse versteckter Muster übergehen, werden absichtlich ineffektive Überprüfungen beseitigt. Das riesige Feld der kontinuierlichen Kontrolle verengt sich auf einen Punkt, der sich auf Objekte auswirkt, die unter das offenbarte
Muster unfairen Verhaltens fallen .
Erinnern Sie sich an Äpfel aus dem obigen Zollbeispiel. Indem wir die Historie der Schecks an den Eingang des statistischen Modells senden, erhalten wir ein Risikoprofil, das die Verhaltensmerkmale von Importeuren und Verstößen berücksichtigt, unabhängig davon, zu welchem Preis sie die Waren deklarieren:
 * Der Satz von Risikoprofilparametern wurde geändert und entspricht nicht dem tatsächlichen
* Der Satz von Risikoprofilparametern wurde geändert und entspricht nicht dem tatsächlichenAuf diese Weise wird das statistische Risikoprofil mithilfe der Algorithmen der Klasse „Entscheidungsbaum“ erstellt. Jede Ebene trennt die Menge der getesteten Entitäten mehr und mehr in „gut“ und „schlecht“ und zeigt, welches Merkmal für die Trennung sich als am signifikantesten herausstellte (im Screenshot von SAS Visual Statistics):
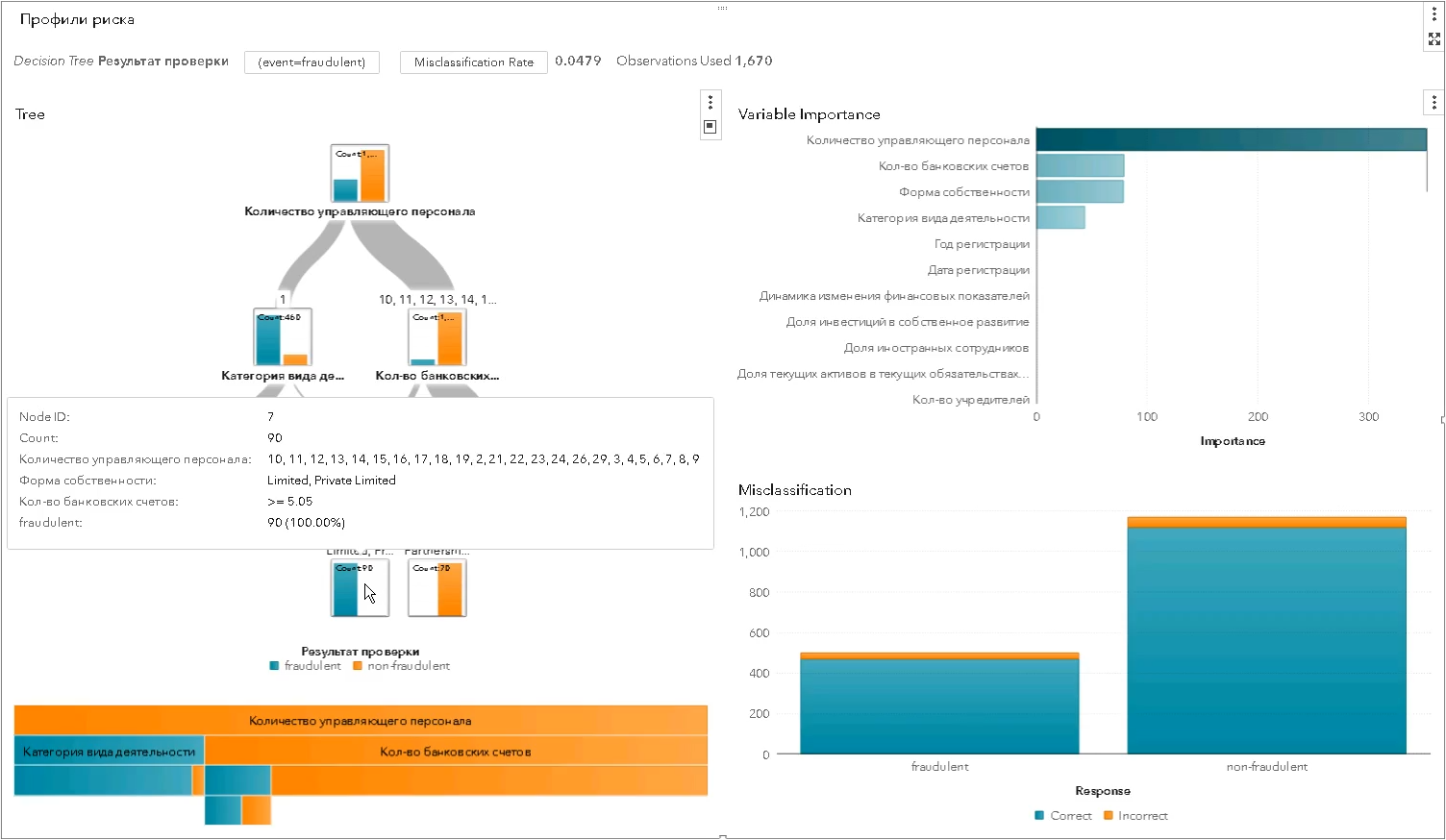
Statistische Profile sind besser als Expertenprofile - genauer, selektiver, unparteiischer. Sie tragen dazu bei, die Effektivität von Inspektionen zu erhöhen, indem sie die Anzahl der „Workouts“ im Leerlauf reduzieren:
Der Nachteil statistischer Profile besteht darin, dass sie sich an früheren Erfahrungen bei der Identifizierung von Verstößen orientieren. Zu bekannten Schemata.
Wenn in der Geschichte der Zollkontrolle beim Import von Waren Fälle von Understatement aufgetreten sind, findet der Algorithmus Anzeichen von Verstößen und erstellt ein statistisches Risikoprofil. Wenn wir nach einem neuen Verstoß suchen, auf den die staatliche Behörde noch nicht aufmerksam geworden ist, und dessen Merkmale wir nicht kennen, müssen wir „durch Berührung“ handeln - durch Versuch und Irrtum.
Unbekannte Suche
Sie können das Unbekannte auf verschiedene Weise fühlen.
Die erste ist die
Zufallsauswahl . Wir nehmen ein beliebiges Objekt (innerhalb unserer Befugnisse) - ein Produkt, ein Unternehmen, ein Gebäude oder einen Bürger - und prüfen es sorgfältig. Der Ansatz ist ziemlich unparteiisch, aber nicht zu effektiv - ein seriöses Thema kann ebenso gut unter „Nachbesprechung“ fallen. Die Stärke der staatlichen Agentur und das Haushaltsgeld werden vergebens ausgegeben.
Die zweite ist die
Identifizierung von Anomalien . In diesem Fall wird ein Objekt zur Überprüfung herangezogen, dessen Parameter sich von den übrigen unterscheiden. Wenn wir abnormale Ereignisse analysieren und nicht nur zufällig eine Reihe von Objekten „stupsen“, ist die Wahrscheinlichkeit, eine Verletzung zu finden, höher.
Bei der Durchführung einer Umweltüberwachung stellt sich beispielsweise heraus, dass die Anlage unerwartet viel Strom verbraucht:
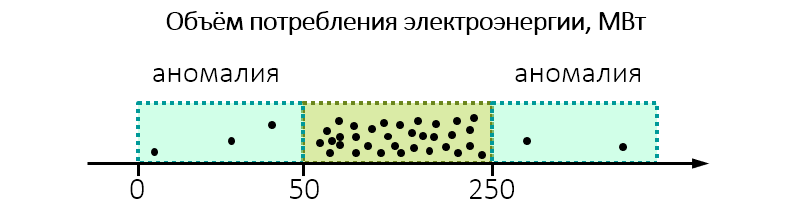
Vielleicht lohnt es sich, einen genaueren Blick darauf zu werfen und zu prüfen, ob die Anlage nicht mehr als zulässig in Wasser oder Luft entweicht.
Oder die Waren beim Zoll haben ein ungewöhnliches Verhältnis des Gewichts der Waren und der Verpackung:
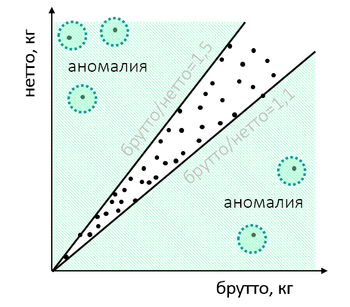
Nach der Überprüfung kann sich herausstellen, dass der Importeur mit dem Gewicht „gespielt“ hat, um einige Verstöße zu vertuschen: Er hat die Kosten unterschätzt und wollte daher einen der Testwerte verschärfen oder einige Waren unter dem Deckmantel anderer ausgeben. Wenn Sie gut graben, unterscheiden sich die „natürlichen“ Gewichtsmerkmale von den fiktiven.
Dies sind jedoch die einfachsten Beispiele, die eine Person sehen kann. In Wirklichkeit findet die Suche nach Anomalien in einem mehrdimensionalen Raum von Attributen statt - es kann Hunderte von ihnen geben. Der Algorithmus macht das, was der Mensch nicht kann - er findet Objekte, die sich gleichzeitig erheblich von den anderen unterscheiden, in einer Vielzahl von Zeichen und ermittelt die sogenannten mehrdimensionalen Ausreißer (im Screenshot von SAS Visual Statistics):
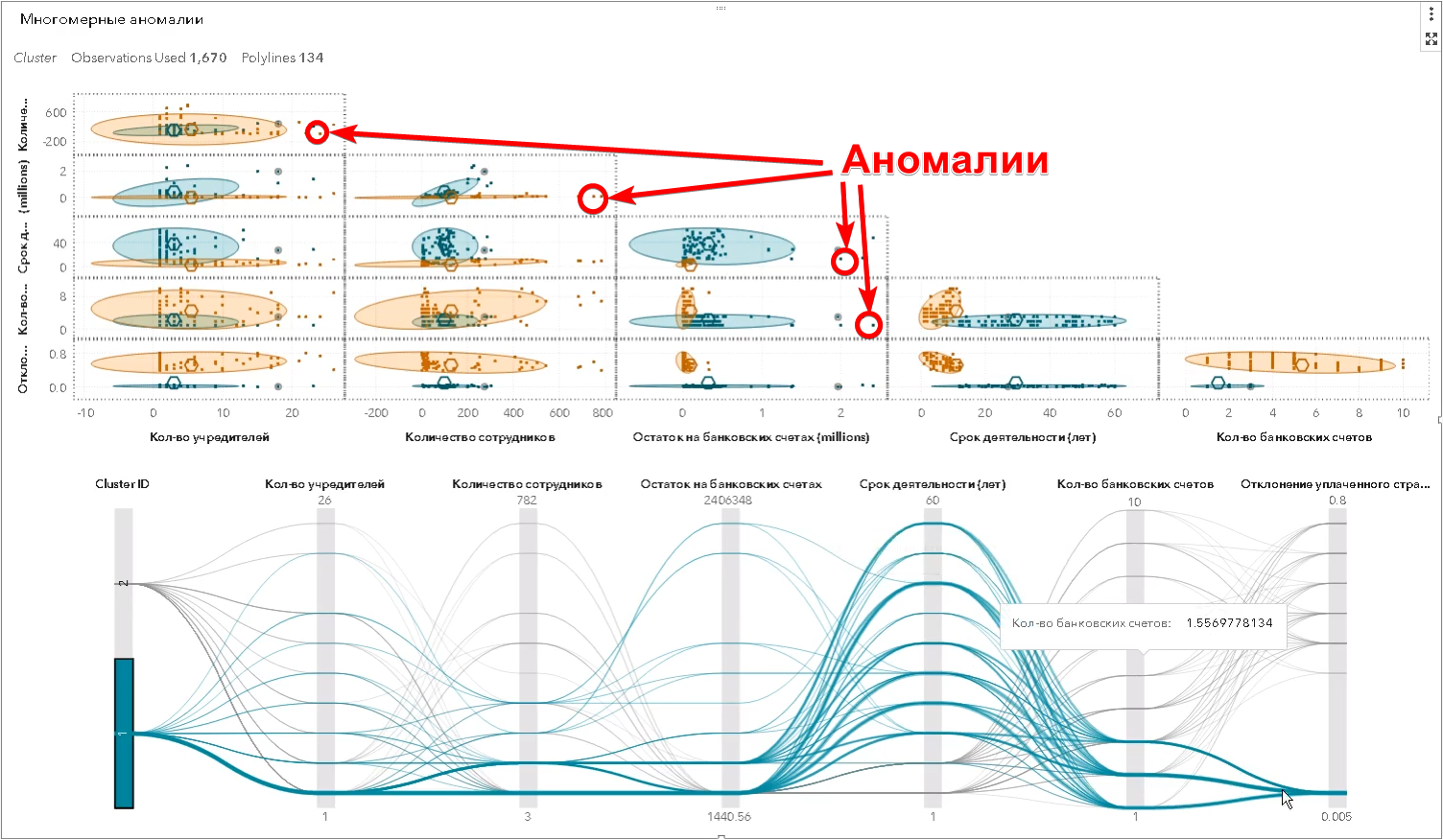
Über die Grenzen der menschlichen Wahrnehmung hinaus gibt es eine Vielzahl von Rechtsbeziehungen zwischen verschiedenen Unternehmen, die mithilfe eines Diagramms dargestellt werden (im Screenshot von SAS Social Network Analysis):
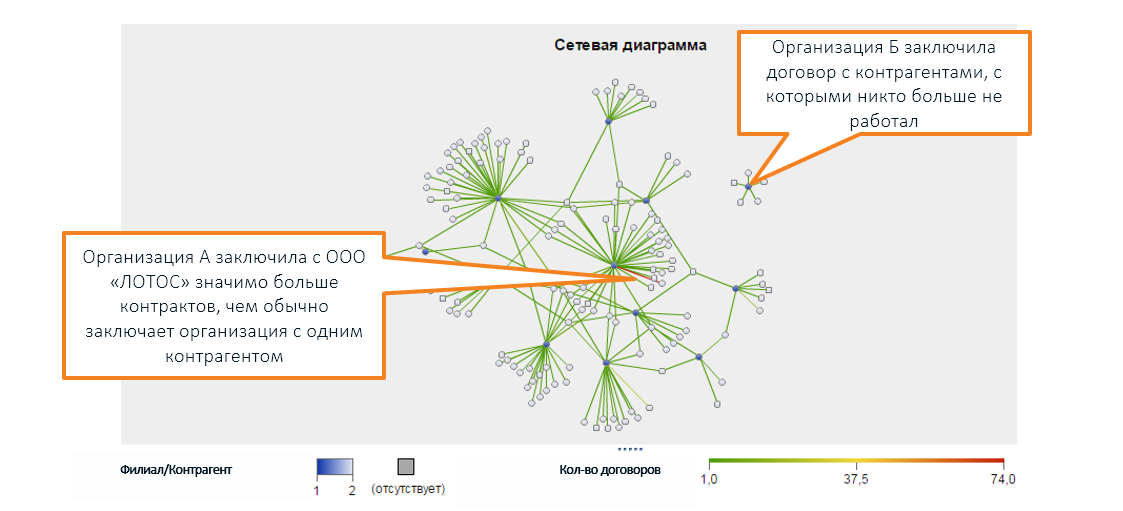 * Namen von Organisationen werden erfunden, Zufälle mit realen Unternehmen sind zufällig
* Namen von Organisationen werden erfunden, Zufälle mit realen Unternehmen sind zufälligUngewöhnliche Eigenschaften weisen nicht unbedingt auf ein Problem hin. Die Prüfung zeigt möglicherweise nichts an: Ja, die Indikatoren sind seltsam, aber es liegt keine Verletzung vor.
Eine Anomalie ist kein Risiko, sondern nur „etwas Ungewöhnliches“. Anomalieprofile werden benötigt, um neue „Rohstoffe“ für die Erstellung von Experten- oder statistischen Profilen bereitzustellen, da das Ergebnis der Anomalieüberprüfung in die Beobachtungshistorie der kontrollierten Objekte einbezogen wird.
Hybrider Ansatz
Die besten Ergebnisse bei den Kontroll- und Überwachungsaktivitäten staatlicher Stellen (und nicht nur darin) können erzielt werden, indem alle drei Methoden zur Identifizierung von Risiken kombiniert werden: Expertenregeln, statistische Risikoprofile auf der Grundlage von Technologien für maschinelles Lernen und Anomalieprofile. Gleichzeitig ist es besser, die Abdeckung von Objekten mit Expertenregeln zu reduzieren und sie nur für gezielte administrative Einflüsse zu belassen (z. B. verhängte Sanktionen - wir blockieren Waren aus diesen Ländern):
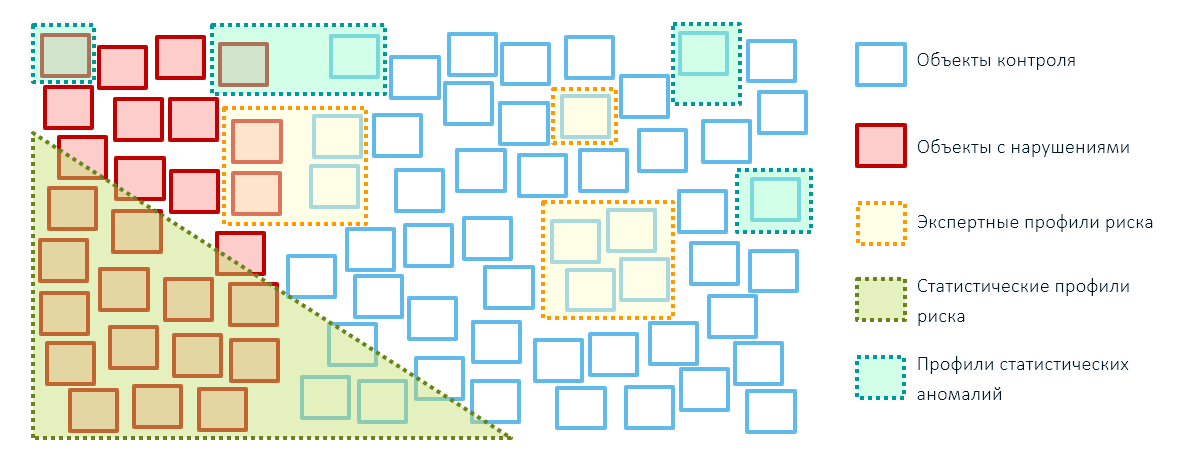
In der Anfangsphase des Aufbaus eines Risikomanagementsystems können Sie nicht auf Expertenregeln verzichten, da für die Erstellung von Analysemodellen eine Präzedenzfallbasis erforderlich ist. Um es zu erstellen, müssen Überprüfungen auf der Grundlage von Expertenrisikoprofilen durchgeführt und erst dann mit mathematischen Modellen fortgefahren werden.
Wir bei SAS glauben, dass die Zukunft der staatlichen Kontroll- und Aufsichtstätigkeit auf einem hybriden Ansatz basiert, der die Erfahrung staatlicher Stellen und das Expertenwissen seiner Mitarbeiter mit modernen Technologien für maschinelles Lernen kombiniert. In diesem Fall reduzieren wir die Ergebnisse aller drei Module in einer integrierten Risikobewertung:
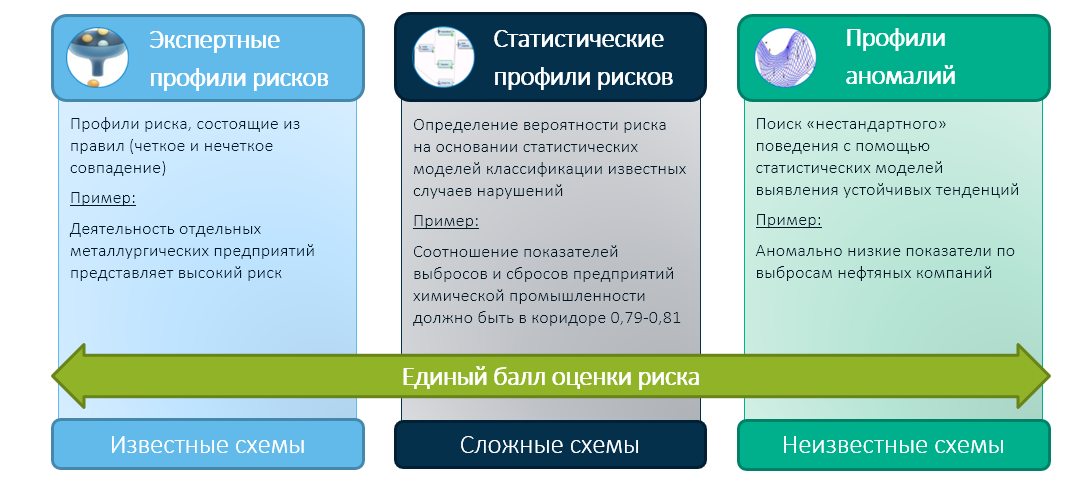
Und bereits eine integrierte Bewertung (zum Beispiel basierend auf einer Expertenentscheidungsmatrix) bestimmt die Wahl der Kontrollstelle - wen sie überprüfen und wem sie vertrauen soll.
Im nächsten Artikel werden wir Methoden analysieren, um die identifizierten Bedrohungen zu minimieren und darüber nachzudenken, warum Feedback und dynamische Risikobewertung so wichtig sind.