Im Rahmen der Produktunterstützung bearbeiten wir ständig Benutzeranfragen. Dies ist ein Standardprozess. Und wie jeder Prozess muss er regelmäßig kritisch bewertet und verbessert werden.
Wir kennen einige systematische Probleme, die gut zu lösen wären und wenn möglich, ohne zusätzliche Ressourcen anzuziehen:
- Fehler beim Versenden von Anträgen: Wir bekommen etwas "Außerirdisches", andere Teams bekommen manchmal etwas "Außerirdisches".
- Es ist schwierig, die "Komplexität" der Anwendung zu beurteilen. Wenn die Anwendung komplex ist, kann sie an einen starken Analysten weitergegeben werden, und mit einer einfachen Anwendung wird der Anfänger damit fertig.
Die Lösung eines dieser Probleme wirkt sich positiv auf die Geschwindigkeit der Verarbeitung von Anwendungen aus.
Die Anwendung des maschinellen Lernens auf die Analyse des Anwendungsinhalts scheint eine echte Chance zu sein, den Versandprozess zu verbessern.
In unserem Fall kann das Problem durch die folgenden Klassifizierungsprobleme formuliert werden:
- Stellen Sie sicher, dass die Anforderung korrekt zugeordnet ist:
- Konfigurationseinheit (eine von 5 innerhalb der Anwendung oder "andere")
- Servicekategorien (Vorfall, Informationsanfrage, Serviceanfrage)
- Schätzen Sie die erwartete Zeit zum Schließen der Anforderung (als übergeordneter Indikator für "Komplexität").
Was und wie werden wir arbeiten?
Um den Algorithmus zu erstellen, verwenden wir den "Standardsatz": Python mit der Scikit-Learn-Bibliothek.
Für eine reale Anwendung werden 2 Szenarien implementiert:
Schulung:
- Abrufen von "Trainings" -Daten vom Application Tracker
- Ausführen eines Algorithmus zum Trainieren eines Modells, Speichern eines Modells
Verwendung:
- Empfangen von Daten vom Application Tracker zur Klassifizierung
- Modellladen, Anwendungsklassifizierung, Speichern von Ergebnissen
- Aktualisieren von Anwendungen im Tracker basierend auf der Klassifizierung
Alles, was mit der Pipeline zu tun hat (Interaktion mit dem Tracker), kann auf alles implementiert werden. In diesem Fall wurden Powershell-Skripte geschrieben, obwohl es möglich war, in Python fortzufahren.
Der Algorithmus für maschinelles Lernen erhält Klassifizierungs- / Trainingsdaten in Form einer CSV-Datei. Verarbeitete Ergebnisse werden auch in eine CSV-Datei ausgegeben.
Daten eingeben
Um den Algorithmus so unabhängig wie möglich von der Meinung der Serviceteams zu machen, werden nur die vom Ersteller der Anwendung erhaltenen Daten als Eingabeparameter des Modells berücksichtigt:
- Kurzbeschreibung / Titel (Text)
- Eine detaillierte Beschreibung des Problems, falls vorhanden (Text). Dies ist die erste Nachricht im Kommunikationsfluss der Anwendung.
- Kundenname (Mitarbeiter, Kategorie)
- Namen anderer Mitarbeiter, die auf Anfrage in die Beobachtungsliste aufgenommen wurden (Liste der Mitarbeiter)
- Anmeldezeit (Datum / Uhrzeit).
Trainingsdatensatz
Für das Training der Algorithmen wurden Daten zu geschlossenen Anrufen der letzten 3 Jahre verwendet - ~ 3.500 Datensätze.
Um dem Klassifizierer die Erkennung „anderer“ Konfigurationseinheiten beizubringen, wurden dem Trainingssatz außerdem geschlossene Anwendungen hinzugefügt, die von anderen Abteilungen für andere Konfigurationseinheiten verarbeitet wurden. Insgesamt zusätzliche Datensätze - ca. 17.000.
Für alle derartigen zusätzlichen Anforderungen wird die Konfigurationseinheit auf "andere" gesetzt.
Vorbehandlung
Text
Die Textvorverarbeitung ist äußerst einfach:
- Wir übersetzen alles in Kleinbuchstaben
- Lassen Sie nur Zahlen und Buchstaben - ersetzen Sie den Rest durch Leerzeichen
Benachrichtigungsliste (Beobachtungsliste)
Die Liste steht zur Analyse in Form einer Zeichenfolge zur Verfügung, in der die Namen in Form von Nachname, Vorname und durch ein Semikolon getrennt dargestellt werden. Zur Analyse konvertieren wir es in eine Liste von Zeichenfolgen.
Durch Kombinieren der Listen erhalten wir eine Reihe eindeutiger Namen, die auf allen Anwendungen des Trainingssatzes basieren. Diese allgemeine Liste bildet einen Vektor von Namen.
Dauer der Antragsbearbeitung
Für unsere Zwecke (Prioritätsverwaltung, Release-Planung) reicht es aus, die Anwendung bis zur Dauer des Dienstes einer bestimmten Klasse zuzuordnen. Außerdem können Sie die Aufgabe mit einer kleinen Anzahl von Klassen von der Regression zur Klassifizierung übertragen.
Text
- Kombinieren Sie den "Titel" und die "Beschreibung des Problems".
- Übergeben Sie an TfidfVectoriser, um einen Wortvektor zu bilden
Name des Antragstellers
Da erwartet wird, dass die Person, die die Anwendung erstellt hat, ein wichtiges Attribut für die weitere Klassifizierung ist, werden wir sie mit DictionaryVectorisor einzeln in eine Codierung übersetzen
Namen von Personen, die in der Benachrichtigungsliste enthalten sind
Die Liste der in den Watchlist-Anwendungen enthaltenen Personen wird auf der Grundlage aller zuvor erstellten Namen in einen Vektor konvertiert: Wenn die Person in der Liste enthalten war, wird die entsprechende Komponente auf 1 gesetzt, andernfalls auf 0. Eine Anwendung kann mehrere Personen in der Watchlist enthalten - bzw. mehrere Komponenten wird einen einzelnen Wert haben.
Erstellungsdatum
Das Erstellungsdatum wird als eine Reihe von numerischen Attributen dargestellt - Jahr, Monat, Tag des Monats, Tag der Woche.
Dies erfolgt unter der Annahme, dass:
- Die Verarbeitungsgeschwindigkeit von Anwendungen variiert im Laufe der Zeit
- Die Verarbeitungsgeschwindigkeit hat einen saisonalen Faktor
- Der Wochentag (insbesondere Wochenendanwendungen) kann dabei helfen, die Konfigurationseinheit und die Dienstkategorie zu identifizieren
Trainingsmodell
Klassifizierungsalgorithmus
Für alle drei Klassifizierungsaufgaben wurde die logistische Regression verwendet. Es unterstützt die Klassifizierung mehrerer Klassen (im One-vs-All-Modell) und lernt ziemlich schnell.
Um Modelle zu trainieren, die die Kategorie des Dienstes und die Dauer der Verarbeitung von Anwendungen definieren, verwenden wir nur Anwendungen, die offensichtlich zu unseren Konfigurationseinheiten gehören.
Lernergebnisse
Konfigurationseinheiten definieren
Das Modell zeigt hohe Indikatoren für Vollständigkeit und Genauigkeit bei der Zuordnung von Anwendungen zu Konfigurationseinheiten. Außerdem definiert das Modell Ereignisse gut, wenn Anwendungen auf fremde Konfigurationseinheiten verweisen.
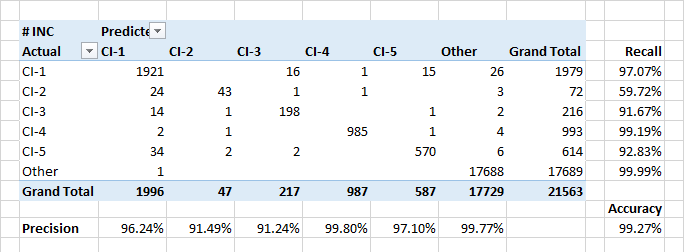
Die relativ geringe Vollständigkeit der CI-2-Klasse ist teilweise auf echte Klassifizierungsfehler in den Daten zurückzuführen. Darüber hinaus präsentieren CI-2 „technische“ Anwendungen, die für andere CIs ausgeführt werden. In Bezug auf die Beschreibung und die beteiligten Benutzer können solche Anwendungen Anwendungen anderer Klassen ähnlich sein.
Die wichtigsten Attribute für die Klassifizierung von Anwendungen als CI-? Erwartungsgemäß wurden die Namen der Kunden von Anwendungen und Personen in das Warnblatt aufgenommen. Es gab jedoch einige Schlüsselwörter, die in den ersten 30 Ke wichtig waren. Das Erstellungsdatum der Anwendung spielt keine Rolle.
Definition der Anwendungskategorie
Die Qualität der Klassifizierung nach Kategorien erwies sich als etwas geringer.
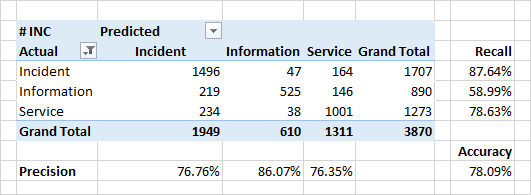
Ein sehr schwerwiegender Grund für die Nichtübereinstimmung der vorhergesagten Kategorien und Kategorien in den Quelldaten sind echte Fehler in den Quelldaten. Aus einer Reihe von organisatorischen Gründen kann die Klassifizierung falsch sein. Anstelle eines "Vorfalls" (ein Defekt im System, unerwartetes Verhalten des Systems) kann die Anwendung beispielsweise als "Information" ("Dies ist kein Fehler - dies ist eine Funktion") oder "Dienst" ("Ja, es ist defekt, aber wir starten es einfach neu - und" markiert werden alles wird ok ").
Das Erkennen solcher Inkonsistenzen ist eine der Aufgaben des Klassifikators.
Wesentliche Attribute für die Klassifizierung bei Kategorien sind Wörter aus dem Inhalt von Anwendungen. Bei Vorfällen sind dies die Wörter "Fehler", "Behebung", "Wann". Es gibt auch Wörter, die einige Module des Systems bezeichnen - dies sind die Module, mit denen Benutzer direkt arbeiten und das Auftreten direkter oder indirekter Fehler beobachten.
Interessanterweise definieren für Anwendungen, die als "Service" definiert sind, Top-Wörter auch einige Module des Systems. Eine Gelegenheit, sie zu überlegen, zu überprüfen und schließlich zu reparieren.
Bestimmen der Bearbeitungszeit der Anwendung
Am schwächsten war es, die Dauer der Bearbeitung von Anträgen vorherzusagen.
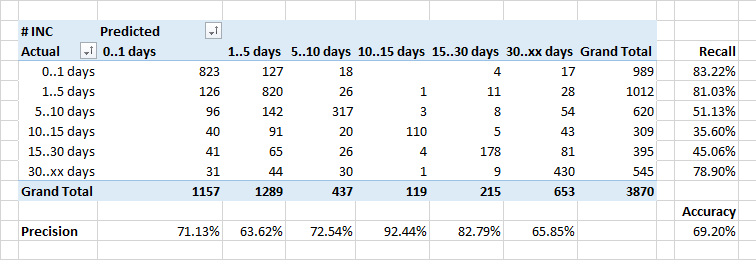
Im Allgemeinen sollte die Abhängigkeit der Anzahl der Anwendungen, die für eine bestimmte Zeit geschlossen sind, idealerweise wie die Umkehrung des Exponenten aussehen. Unter Berücksichtigung der Tatsache, dass einige Vorfälle Korrekturen im System erfordern und dies im Rahmen regulärer Releases erfolgt, erhöht sich die Dauer der Ausführung einiger Anwendungen künstlich.
Daher klassifiziert der Klassifizierer möglicherweise einige "lange" Anwendungen als "schneller" - er kennt den Zeitpunkt der geplanten Versionen nicht und ist der Ansicht, dass die Anwendung schneller geschlossen werden muss.
Dies ist auch ein guter Grund zum Nachdenken ...
Implementierung des Modells als Klasse
Das Modell wird als Klasse implementiert, die alle verwendeten Standard-Scikit-Lernklassen umfasst - Skalierung, Vektorisierung, Klassifizierer und wichtige Einstellungen.
Vorbereitung, Schulung und anschließende Verwendung des Modells werden als Klassenmethoden implementiert, die auf Hilfsobjekten basieren.
Mit der Objektimplementierung können Sie bequem abgeleitete Versionen des Modells generieren, die andere Klassen von Klassifizierern verwenden und / oder die Werte anderer Attribute des Originaldatensatzes vorhersagen. All dies erfolgt durch Überschreiben virtueller Methoden.
Alle Datenaufbereitungsverfahren können jedoch allen Optionen gemeinsam bleiben.
Darüber hinaus ermöglichte die Implementierung des Modells in Form eines Objekts die natürliche Lösung des Problems der Zwischenspeicherung des trainierten Modells zwischen Nutzungssitzungen - durch Serialisierung / Deserialisierung.
Zur Serialisierung des Modells wurde der Standard-Python-Mechanismus pickle / unpickle verwendet.
Da Sie damit mehrere Objekte in derselben Datei serialisieren können, können Sie die Wiederherstellung mehrerer Modelle, die im allgemeinen Verarbeitungsablauf enthalten sind, konsistent speichern.
Fazit
Die resultierenden Modelle sind zwar relativ einfach, liefern aber sehr interessante Ergebnisse:
- identifizierte systematische "Auslassungen" in der Klassifizierung nach Kategorien
- Es wurde klar, welche Teile des Systems mit Problemen verbunden sind (anscheinend - nicht ohne Grund).
- Die Bearbeitungszeiten für Anträge hängen eindeutig von externen Faktoren ab, die separat verbessert werden müssen.
Wir müssen die internen Prozesse basierend auf den erhaltenen „Hinweisen“ noch neu erstellen. Aber auch dieses kleine Experiment ermöglichte es, die Leistungsfähigkeit maschineller Lernmethoden zu bewerten. Darüber hinaus hat das Team zusätzliches Interesse an der Analyse des eigenen Prozesses und seiner Verbesserung geweckt.