
Die Migration von IT-Systemen ist keine leichte Aufgabe. Die besondere Schwierigkeit ist jedoch die Situation, in der Sie nicht nur von altem zu neuem Eisen wechseln müssen, sondern auch auf vorhandenen Geräten auf ein neues Betriebssystem umsteigen müssen, ohne produktive Daten zu migrieren. Ein solcher Schritt dauerte ungefähr ein Jahr, von denen die meisten vorbereitet waren.
Der Client verfügt über zwei Standorte in verschiedenen Städten und jeweils über zwei verbundene Datenspeichersysteme. Informationen von einem Speichersystem mit den integrierten Replikationstools werden an das zweite gesendet. Die Verwaltung erfolgt über ein externes Backup-System. In einer Stadt sind zwei NetApp 3250-Systeme installiert, in der anderen - das NetApp 6220-Hauptsystem und das NetApp 3250-Backup-System. Der Client plant, diesen Komplex in Zukunft zu erweitern, Festplatten hinzuzufügen und Controller zu aktualisieren.
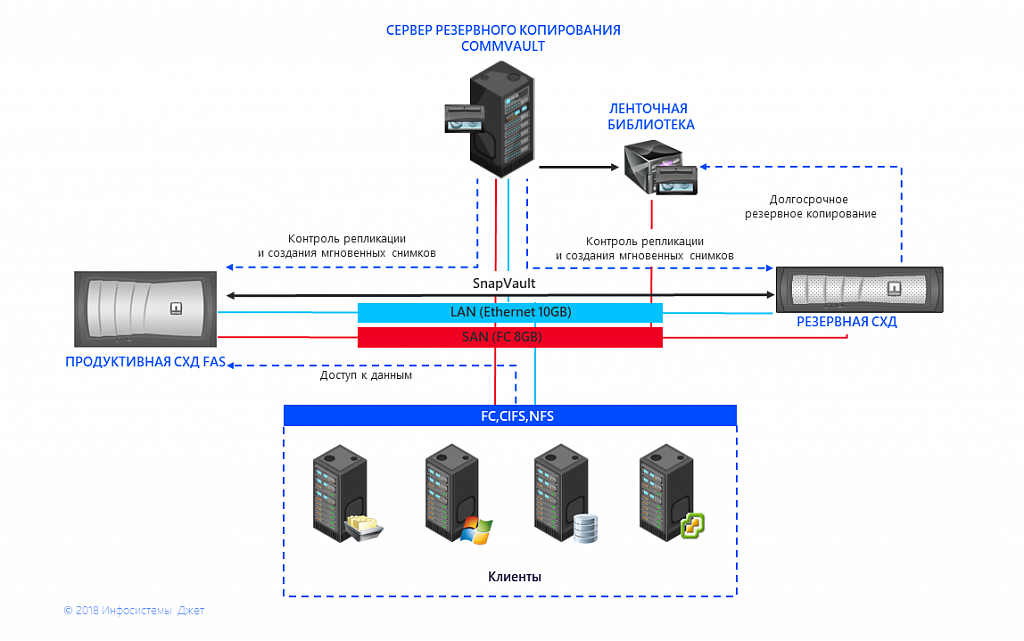 Abb. 1 Schema der Interaktion von Speichersystemen und IBS
Abb. 1 Schema der Interaktion von Speichersystemen und IBSUnd das Hauptproblem hängt damit zusammen - das Ende der Unterstützung. Für das auf dem Speichersystem installierte 7-Mode-Betriebssystem Data ONTAP 8.2 wurden seit einigen Jahren keine größeren Aktualisierungen vorgenommen, und die Veröffentlichung kritischer Fehlerkorrekturen wird 2021 eingestellt. Neuere Laufwerke und Controller sind nicht mit dem älteren Betriebssystem kompatibel.
Die Lösung ist der Übergang zum ONTAP 9.1-Clustersystem als letztem unterstützten für diese Speichercontroller. Die Hauptvorteile sind:
- Horizontale Skalierung durch Kombination zu einem einzigen fehlertoleranten Cluster, wodurch ein einziges System basierend auf produktivem Speicher und SRK erstellt wird.
- Lastausgleich zwischen Controllern, Festplatten sowie Verschieben von Daten innerhalb des Speichersystems, ohne den Dienst zu unterbrechen und den Zugriff auf Anwendungen zu stoppen.
- Wartung von Hard- und Software von Datenspeichersystemen ohne Unterbrechung ihrer Arbeit und Betriebsunterbrechung.
- Die Möglichkeit, heterogene Clusterkonfigurationen zu erstellen, einschließlich Controllern und Festplatten verschiedener Typen, einschließlich Speichersystemen von Drittanbietern, unter Verwendung von Lizenzen zur Virtualisierung ihrer Festplattenkapazität.
- Möglichkeit, SSD als Cache-Schicht für Aggregate zu verwenden.
- Optimierter Betrieb von Datenkomprimierungsmechanismen (Komprimierung und Deduplizierung).
Es gibt 3 Optionen für die Migration vom 7-Modus in den Cluster-Modus:
- Migration mit Datenreplikation mithilfe des Netapp 7-Mode Transition Tool (7MTT) und des kopierbasierten Übergangs (CBT). Hierzu ist ein zweites Speichersystem mit kleinerem Speicherplatz und schrittweiser Replikation auf Basis von SnapMirror erforderlich. Für jeden Dienst wird die Umschaltung zu einem bestimmten Zeitpunkt koordiniert und durchgeführt.
Bei einem unserer Kunden haben wir dieses Verfahren bereits im Metro-Cluster durchgeführt. Aufgrund der großen Anzahl von Volumes, LUNs (> 400) und der langen Koordination von Details, Ausfallzeiten usw. Die Migration dauerte ohne Schulung etwa 3 Monate. - Migrieren Sie ohne Verschieben von Daten mit dem Netapp 7-Mode Transition Tool (7MTT) und dem kopierfreien Übergang (CFT). Dazu benötigen Sie ein zweites Speichersystem mit einer Mindestanzahl von Festplatten, das nach vorläufiger Vorbereitung das produktive Festplattensubsystem wechselt. Für alle Services wird eine große Ausfallzeit vereinbart.
- Migration mit dem Kopieren von Daten mit Host-Tools. Dies ist der traditionelle Migrationspfad zwischen Speichersystemen aller Hersteller.
Da die vorhandenen Speichersysteme noch von Anbietern unterstützt wurden und die Leistung der Controller in naher Zukunft ausreichte, wurde das Budget für den Kauf neuer Controller nicht zugewiesen. In diesem Zusammenhang wurde beschlossen, die Controller mithilfe von 7MTT CFT in den Cluster-Modus zu migrieren. Eine der wichtigsten Anforderungen war das Fehlen merklicher Unterbrechungen beim Betrieb von Speichersystemen: Die meisten Systeme sollten an Wochentagen reibungslos funktionieren. Daher waren die Hauptarbeiten zur Migration auf einem produktiven Speichersystem für das Wochenende geplant.
Die Vorbereitungsphase begann mit der Sammlung von Informationen aus dem Speichersystem und der Durchführung von Vorkontrollen. Die spezialisierte NetApp 7MTT-Software generiert eine Liste von Warnungen, die die Migration beeinträchtigen oder nicht abschließen können. Beispielsweise bestand diese Liste für eines der Systeme aus mehr als 200 Elementen. Es war notwendig, alle Systeme auf die neuesten unterstützten Versionen des Betriebssystems zu aktualisieren, die Firmware der Controller, Festplattenregale und der Festplatten selbst zu aktualisieren. Außerdem verfügt das neue Betriebssystem über eine andere Betriebslogik, die zusätzliche IP-Adressen und Verbindungen zwischen Speichersystemen erfordert.
Der Stoppfaktor wurde recht schnell erkannt - der Client verwendete eine Technologie, die nicht auf der Replikation des gesamten Volumes, sondern auf der Replikation von qtree basierte (ein Unterabschnitt, für den Zugriffs-, Volume- usw. Einschränkungen gelten). Es ist unmöglich, solche SnapVault-Beziehungen auf das neue Betriebssystem zu migrieren . Daher müssten vor Beginn der Arbeiten alle Replikationskopien vollständig entfernt werden. Um sicherzustellen, dass der Client nach dem Verschieben nicht ohne Sicherungen belassen wurde, wurde vor der Migration eine Sicherung basierend auf der gesamten Datenträgerreplikation gestartet. Mit SnapMirror wurden neben den alten Backups neue Backups erstellt und innerhalb von vier Wochen ein Änderungsprotokoll erstellt. Und wenn auf einem der Standorte genügend Platz dafür vorhanden war, war es auf dem zweiten Platz begrenzt, schrittweise Kopien eines der Bände anzufertigen. Nach vier Wochen wurden die alten Beziehungen entfernt und neue erstellt. Ein ziemlich langwieriger, schrittweiser Prozess, der bei einem Standort etwa 1,5 Monate und bei dem zweiten mehr als 3 Monate dauerte. Darüber hinaus möchte ich darauf hinweisen, dass das Verfahren zum Beenden der Snapvault-Beziehung mit dem Entfernen des Ziel-Qtree einhergeht und seine Ausführungsgeschwindigkeit stark von der Anzahl der Dateien und in geringerem Maße von seiner Größe abhängt. Zum Beispiel wurde qtree mit 4 Millionen Dateien und einer Größe von 500 GB innerhalb von 24 Stunden gelöscht.
Dabei traten verschiedene Schwierigkeiten auf. Die Bürokratisierung der Änderungsprozesse an den Client-Systemen erhöhte die Bedingungen für die Koordinierung der Arbeit. Glücklicherweise konnten wir uns darauf einigen, technische Probleme direkt zu lösen und auf einer höheren Ebene nur wichtige „ideologische“ Probleme zu erörtern, z. B. die Vereinbarung eines Arbeitsplans und die Auswahl bestimmter Daten für die Migration.
Schwierigkeiten wurden durch die Verwendung von Zwischenlagern verursacht. Unter der Anleitung von 7MTT haben wir beide Speichersysteme gemäß den Anforderungen und Vorprüfungen konfiguriert. Dann schalteten sie den alten Speicher aus und verbanden die Plattenregale mit dem neuen. Überprüfte alles noch einmal. Aus Sicht der NetApp-Software ist der Migrationsprozess abgeschlossen und alle verteilen sich
hinter Champagner . Der nächste Schritt bestand jedoch darin, alles an die alten Client-Controller zurückzugeben. Tatsache ist, dass ein solcher Übergang - von neuen zu alten Controllern - nicht offiziell unterstützt wird. Nach dem Zurückschalten begann das Betriebssystem, Fehler einzugeben und sich über Probleme mit dem Cluster zu beschweren. Nach der Recherche konnte ich herausfinden, dass das Problem auf die Tatsache zurückzuführen ist, dass der Cluster plötzlich in den Switched-Modus geschaltet hat und nicht mehr in den Switchless-Modus zurückkehren wollte. Es hat lange gedauert, um den Fehler zu beheben. Die Probleme beim Start des Clusters wurden gelöst, indem die Kabel, die zum Start zum Kampfnetzwerk führten, beim Start nicht angeschlossen wurden. Das Intra-Cluster-Netzwerk wurde an einem Kabel angehoben und das zweite hinzugefügt. Übrigens sollte beachtet werden, dass bei älteren Controllern und älteren Versionen des Betriebssystems das Intra-Cluster-Netzwerk nur an bestimmten Ports einer begrenzten Anzahl von Adaptern erhöht werden kann, z. B. beim FAS3250 e1a und e2a (der Kunde musste 10 GB Ethernet-Karten kaufen).
Sie legten zusätzliche Zeit für die Arbeit am zweiten Standort, in der Hoffnung, zumindest einige der Probleme zu vermeiden, aber dies half nicht - das Betriebssystem verhielt sich unvorhersehbar. Das Diagramm wurde zweimal verschoben. Im ersten Fall, als wir mit dem FAS3250 arbeiteten, war es aufgrund eines Fehlers in den kürzlich geänderten Einstellungen der Netzwerkinfrastruktur des Kunden nicht möglich, Kampfsysteme zu migrieren, die rund um die Uhr funktionieren (obwohl beim Testen der Migration eine Woche vor Arbeitsbeginn alles flog). vMotion kopierte virtuelle Maschinen mit einer Geschwindigkeit von weniger als 1 Mbit / s auf ein Remote-Speichersystem.
Während der Migration hat der Client die Architektur teilweise geändert. Volumes, die an ihre VMware vSphere-Infrastruktur verteilt wurden, wurden zuvor über NFS-Ethernet ausgegeben. Der Client hat sie überarbeitet und sie sind zu Fibre Channel gewechselt. Während des Migrationsprozesses stellte sich heraus, dass die LUN ihre ID vollständig geändert hatte. Dementsprechend sah VMware neue LUNs, die mit alten Daten an sie adressiert waren, und weigerte sich, sie dauerhaft zu verbinden. Dank der Hilfe von VMware-Spezialisten war es daher möglich, diese LUNs fortlaufend über die Konsole zu verbinden, was darauf hinweist, dass dies eine Momentaufnahme der alten Datenspeicher ist. Dann musste ich die VMware-Hosts neu starten. Infolgedessen gelang es ihnen, virtuelle Maschinen zu sehen und die virtuelle Infrastruktur zu erhöhen. Und wenn der Client weiterhin NFS verwendet hätte, wäre ein solches Problem nicht aufgetreten - die IP-Adresse und der DNS-Name blieben unverändert.
Der Arbeitsplan direkt an Migrationstagen:
Freitag: Arbeit mit Speichersystemen und IBS
- Sie haben alle Beziehungen zwischen SnapVault und SnapMirror gestoppt, den temporären Speicher gewechselt und überprüft, ob die Systeme für die Migration bereit sind. Wir haben die Verfahren zum Migrieren des Speichers auf 7MTT mithilfe der Copy Free Transition-Methode gestartet. Wiederverbundene Kampfscheibenregimenter mit dem temporären Controller.
- Auf 7MTT migriert, Root-Volume der Ersatzcontroller in die Festplattenregale des Speichersystems des SRK migriert. Wir haben neue Ethernet-Adapter installiert, das SRK-Speichersystem gestartet, die Konfiguration gelöscht und das Betriebssystem-Image über das Netzwerk vom HTTP-Server heruntergeladen. Wir haben neue Versionen der Firmware und des Betriebssystems installiert (zu diesem Zeitpunkt gab es ungeklärte Probleme beim Herunterladen des Images über das Netzwerk. Am Ende wurde es direkt vom Laptop heruntergeladen).
- Wir haben die Controller im Cluster durch alte ersetzt und die Regale der Kampfdisketten mithilfe des Upgrades durch Verschieben des Speicherverfahrens mit dem Speichersystem verbunden. Wir haben den Cluster wiederhergestellt, die Netzwerkschnittstellen neu konfiguriert (ich musste Probleme im Zusammenhang mit dem fehlerhaften Betrieb des Clusters lösen) und Lizenzschlüssel installiert.
Samstag: Arbeit mit dem Hauptspeicher
- Wir haben temporäre Festplattenregale mit temporärem Speicher verbunden und neu eingerichtet.
- Wichtige virtuelle Maschinen wurden mithilfe von VMware vMotion in ein Remote-Rechenzentrum migriert.
- Die wichtigsten Speichersysteme wurden mithilfe der CFT-Methode auf 7MTT migriert. Sie schalteten den Hauptkampfspeicher aus, verbanden seine Festplattenregale mit dem Controller und konvertierten die Betriebssystem-Metadaten in 7MTT. Das Root-Volume der Swap-Controller wurde in die Festplattenregale des SRK-Speichersystems migriert.
- Wir haben neue Ethernet-Adapter installiert und den Kampfspeicher in einer plattenlosen Konfiguration gestartet, die Einstellungen gelöscht und dann über das Netzwerk vom HTTP-Server heruntergeladen. Neue Firmware- und Betriebssystemversionen installiert. Wir haben die Controller im Cluster ausgetauscht und die Regale der Kampfdisketten mithilfe des Upgrades durch Verschieben des Speicherverfahrens mit dem Speichersystem verbunden.
- Wiederherstellung des Clusters, Neukonfiguration der Netzwerkschnittstellen (Basteln mit dem Cluster, der aufgrund verbundener Kampfnetzwerkschnittstellen nicht ordnungsgemäß funktioniert). Installierte Lizenzschlüssel.
- Wir haben die Speicherverbindungen zu VMware-Servern wiederhergestellt, die Zoneneinteilung im SAN-Netzwerk geändert, die Zuordnung von LUNs konfiguriert und die Volumes für die Arbeit mit dem FC-Zugriff auf eine separate SVM verschoben. Verbundene LUN mit ESXi. Aufgrund der Tatsache, dass sich die LUN-ID geändert hat und die Datenspeicher nicht im automatischen Modus angezeigt wurden, musste ich die ESXi-Server konsistent neu starten und die LUNs mit Befehlen über esxcli verbinden.
- Rekonfigurierte Kampfschnittstellen, umbenannte CIFS-Server und wiedererlangter Zugriff auf CIFS-Bälle und NFS-Exporte.
Sonntag: Problemlösung und Einrichtung der IBS-Software
- Virtuelle Maschinen wurden vom Speichersystem zurück in das Kampfspeichersystem migriert.
- Wir haben das Problem mit dem Zugriff auf den Ordner im Aufnahmemodus vom Linux-Host aus gelöst. Wir haben die neueste Version der Überwachungssoftware Netapp onCommand Unified Manager 7.3 bereitgestellt und beide Speichersysteme daran angeschlossen.
- Wir haben die Daten zur aktuellen Auslastung der Einheiten mithilfe der Unified Manager-Software analysiert und mithilfe der SSD die Caching-Schicht mit den vorhandenen Platteneinheiten (Flash / Storage Pool) verbunden.
- Sie haben das alternative Speichersystem deaktiviert und Cluster-Links (Cluster-Peering, SVM-Peering) erstellt, damit die Replikation verwendet werden kann. Wir haben neue SnapMirror-Beziehungen zwischen dem Hauptspeicher und dem SRK-Speicher basierend auf vorhandenen Volumes (die in den SnapMirror 7-Modusbeziehungen verwendet wurden) mit Resynchronisation der geänderten Daten erstellt und dann die SnapMirror-Beziehungen in SnapVault-Beziehungen (SnapMirror XDP) konvertiert.
- Wir haben beide Speichersysteme im NetApp Open Replication-Modus mithilfe des technischen Supports von Commvault mit der Commvault SRC-Software verbunden. Dies funktionierte nicht anders, obwohl wir alles gemäß den Anweisungen durchgeführt haben. Konfiguriertes Senden von Autosupport-Protokollen von Kampfspeichern und Speichersystemen des SRK.
Montag: Schleifen
- Überprüfung des Betriebs der wichtigsten produktiven Speicher- und Speichersysteme des Speichersystems. Mögliche Probleme und Fehlfunktionen lösen.
- Temporäre Geräte aus- und abbauen.
Die Migration selbst dauerte nur zwei Tage. Der Umzug war erfolgreich, alle Kundendaten sind sicher und solide. Das Backup-Management-System und die Integration in die vorhandene SRK-Software wurden ebenfalls beibehalten. Wenn Sie das Commvault-Bundle zuvor mit OnCommand Unified Manager verwendet haben, wurde nach dem Wechsel in den Cluster-Modus entschieden, es zugunsten von Netapp Open Replication aufzugeben, um Commvault direkt mit Speichercontrollern zu verbinden.
Die wichtigsten Empfehlungen, die ich basierend auf den Ergebnissen dieser Migration geben kann: Wechseln Sie vom 7-Modus in den Cluster-Modus und ersetzen Sie die Controller. Wenn Sie weiterhin wie im oben beschriebenen Fall auf die zweiten Steuerungen umsteigen möchten, müssen Sie genügend Zeit einplanen, um verschiedene Probleme zu lösen, die beim Zurücksetzen auf die alten Steuerungen unbedingt auftreten müssen. Die Verwendung der Migration ohne Verschieben von Daten mit 7MTT CFT ist ein völlig sicheres Verfahren, wenn es von Fachleuten als vertrauenswürdig eingestuft wird.
Nützliche Anleitungen, die während dieser Migration verwendet werden:
Dmitry Kostryukov, führender Konstrukteur von Speichersystemen
Design Center für Computerkomplexe "Jet Infosystems"