Zu Beginn meiner Karriere arbeitete ich für ein Unternehmen, das ein Content-Management-System herausbrachte. Dieses CMS half Marketingabteilungen dabei, ihre Websites selbst zu verwalten, anstatt sich bei jeder Änderung auf Entwickler zu verlassen. Das System hat Kunden dabei geholfen, die Betriebskosten zu senken und für mich zu lernen, wie man Webanwendungen erstellt.
Obwohl das Produkt selbst einen sehr allgemeinen Zweck hatte, verwendeten Kunden es normalerweise für bestimmte Aufgaben. Diese Aufgaben drückten das Maximum aus CMS heraus, und die Entwickler mussten nach einer Lösung für die Probleme suchen. Nachdem ich zehn Jahre in einer solchen Umgebung gearbeitet hatte, lernte ich auf vielfältige Weise, wie eine Webanwendung in der Produktion kaputt gehen kann. Einige davon werden in diesem Artikel behandelt.
Eine der Lehren, die wir im Laufe der Jahre gezogen haben, ist, dass einzelne Ingenieure normalerweise sehr tief in den für sie interessanten Bereich eintauchen und den Rest oberflächlich studieren. Das Schema arbeitet normalerweise in einem Team von Ingenieuren mit guter Kommunikation, in denen sich das Wissen überschneidet und einzelne Lücken für jeden von ihnen schließt. In Teams mit wenig Erfahrung oder für einzelne Ingenieure tritt jedoch ein Fehler auf.
Wenn Sie in einer solchen Umgebung angefangen haben, eine Webanwendung von Grund auf neu zu erstellen und bereitzustellen, lernen Sie schnell, was „gefährliches Oberflächenwissen“ ist.
In der Branche gibt es eine Reihe von Lösungen, um dieses Problem zu lösen: verwaltete Webanwendungen (Beanstalk, AppEngine usw.), Containerverwaltung (Kubernetes, ECS usw.) und viele andere. Sie funktionieren sofort und können das Problem perfekt lösen. Dies ist jedoch eine unnötige Komplexität beim Starten einer Webanwendung, und normalerweise funktionieren solche Lösungen "einfach".
Leider funktionieren sie nicht immer „nur“. Wenn es eine Nuance gibt, dann möchte ich etwas mehr über diese finstere Black Box wissen.
In diesem Artikel nehmen wir ein unzuverlässiges System und modifizieren es auf ein angemessenes Maß an Zuverlässigkeit. Bei jedem Schritt wird ein echtes Problem verwendet, dessen Lösung uns zur nächsten Stufe führt. Ich glaube, dass es effizienter ist, nicht alle Teile des endgültigen Entwurfs zu analysieren, sondern einen solchen schrittweisen Ansatz zu verwenden. Er zeigt besser, wann und in welcher Reihenfolge bestimmte Entscheidungen zu treffen sind. Am Ende werden wir die Grundstruktur des Hosting-Dienstes für verwaltete Webanwendungen von Grund auf neu aufbauen, und ich hoffe, wir werden die Gründe für die Existenz der einzelnen Teile im Detail erläutern.
Starten Sie
Stellen Sie sich vor, Ihr Budget für das Hosting beträgt 500 US-Dollar pro Jahr. Sie haben sich daher entschieden, einen t2.medium-Server bei Amazon AWS zu mieten. Zum Zeitpunkt des Schreibens sind dies ungefähr 400 USD pro Jahr.
Sie wissen im Voraus, dass Sie über ein Autorisierungssystem verfügen und Informationen über Benutzer speichern müssen, sodass Sie eine Datenbank benötigen. Aufgrund des begrenzten Budgets werden wir es auf unserem einzigen Server platzieren. Am Ende erhalten wir folgende Infrastruktur:
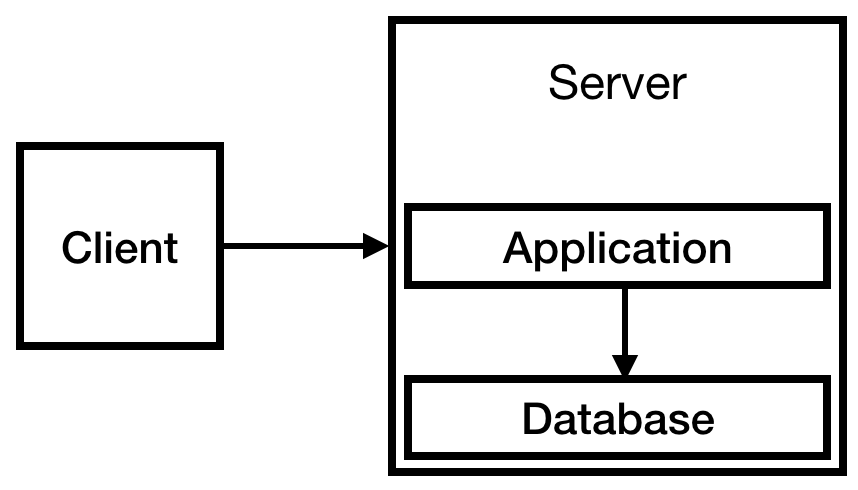 Abb. 1
Abb. 1Das reicht fürs Erste. Tatsächlich kann ein solches System einige Zeit funktionieren. Der Service ist klein, weniger als 10 Besuche pro Tag. Vielleicht hat eine kleine Instanz gereicht, aber wir sind optimistisch, was das Wachstum des Unternehmens angeht, und haben t2.medium mit Bedacht gewählt.
Der Wert des Geschäfts befindet sich in der Datenbank, daher ist es sehr wichtig. Sie müssen sicherstellen, dass bei einem Ausfall des Servers keine Daten verloren gehen. Sie sollten wahrscheinlich sicherstellen, dass der Inhalt der Datenbank nicht auf einer temporären Festplatte gespeichert ist. Wenn die Instanz gelöscht wird, verlieren Sie schließlich Ihre Daten. Dies ist ein sehr beängstigender Gedanke.
Sie sollten auch sicherstellen, dass Sie Backups auf externem Speicher haben. S3 scheint ein guter Ort für sie zu sein und relativ günstig, also lasst es uns auch einrichten. Und Sie müssen auf jeden Fall überprüfen, ob die Sicherung funktioniert, und die Sicherung regelmäßig wiederherstellen.
Jetzt sieht das System ungefähr so aus:
 Abb. 2
Abb. 2Sie haben die Zuverlässigkeit der Datenbank erhöht, und es ist Zeit, sich auf den „Habraeffekt“ vorzubereiten, indem Sie einen Auslastungstest auf dem Server ausführen. Alles läuft einwandfrei, bis 500 Fehler und dann ein 404-Fehlerstrom auftreten. Sie untersuchen also, was passiert ist.
Es stellt sich heraus, dass Sie keine Ahnung haben, was passiert ist, weil Sie Protokolle in die Konsole geschrieben und die Ausgabe nicht in eine Datei geleitet haben. Sie sehen auch, dass der Prozess nicht funktioniert, sodass Sie höchstwahrscheinlich davon ausgehen können, dass aus diesem Grund 404 Fehler auftreten. Eine Welle der Erleichterung besteht darin, dass Sie den lokalen Lasttest korrekt ausgeführt haben und den tatsächlichen Habra-Effekt nicht als Testlast verursacht haben.
Sie beheben das Problem mit dem automatischen Neustart, indem Sie den Dienst
systemd erstellen und den Webserver starten, wodurch gleichzeitig das Problem der Protokollierung gelöst wird. Führen Sie dann einen weiteren Auslastungstest durch, um dies zu überprüfen.
Und wieder sehen wir Fehler 500 (zum Glück ohne 404). Sie überprüfen die Protokolle. Es wird festgestellt, dass der Datenbankverbindungspool voll ist, da ein kleines Limit von 10 Verbindungen festgelegt wurde. Aktualisieren Sie die Einschränkung, starten Sie die Datenbank neu und führen Sie den Auslastungstest erneut aus. Alles läuft gut, also beschließen Sie, über Ihre Website auf Habré zu sprechen.
Tag starten
Mutter Gottes! Ihr Service wird sofort zum Hit. Sie haben die Hauptseite aufgerufen und in den ersten 30 Minuten 5000 Aufrufe erhalten - und Sie sehen die Kommentare. Was schreiben sie dort?
Ich habe einen 404-Fehler, daher musste ich eine zwischengespeicherte Version der Seite öffnen. Hier ist der Link, wenn jemand ihn braucht: ...
...
Nichts öffnet sich. Außerdem habe ich Javascript deaktiviert. Warum denken die Leute, dass ich ihr 2 MB Javascript laden möchte ...
...
Das Herunterladen der Homepage dauert 4 Sekunden. Traceroute aus Australien zeigt, dass sich der Server irgendwo in Texas befindet. Warum lädt die erste Seite 2 Megabyte Javascript?
In einer verrückten Eile konfigurieren Sie Nginx als Reverse-Proxy-Server für Ihre Anwendung und konfigurieren dort eine statische 404-Seite. Sie ändern auch das Bereitstellungsverfahren, um statische Dateien an S3 zu senden: Dies ist erforderlich, damit CloudFront CDN funktioniert, um die Ladezeit in Australien zu verkürzen.
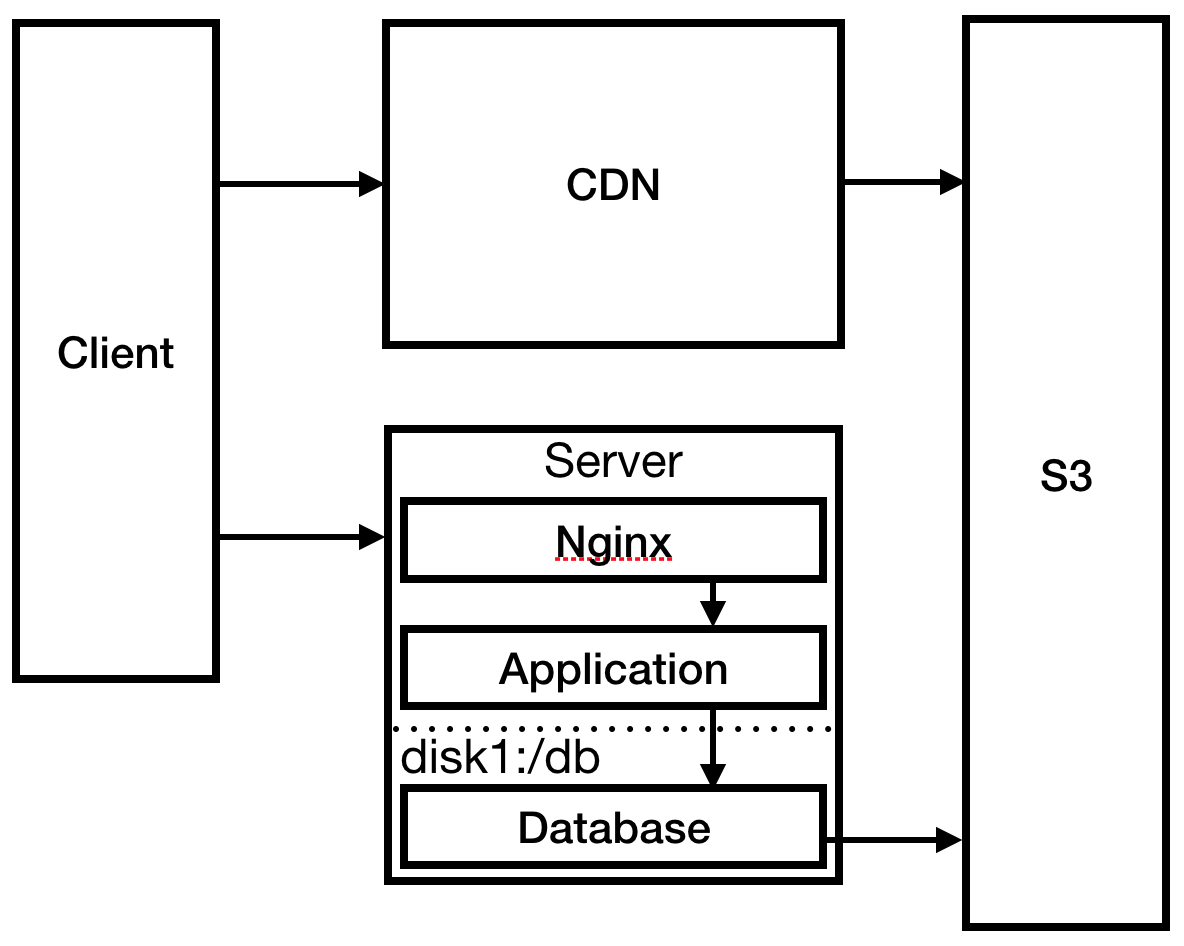 Abb. 3
Abb. 3Sie haben das dringendste Problem gelöst, gehen Sie zum Server und überprüfen Sie die Protokolle. Ihre SSH-Verbindung ist ungewöhnlich verzögert. Nach einigen Studien stellen Sie fest, dass die Protokolldateien den gesamten Speicherplatz belegt haben, was dazu führte, dass der Prozess abstürzte und ein Neustart verhindert wurde. Erstellen Sie eine viel größere Festplatte und hängen Sie die Protokolle dort ein. Konfigurieren Sie
logrotate so, dass die Protokolldateien nicht mehr so groß werden.
Leistungsprobleme
Monate vergehen. Das Publikum wächst. Die Seite beginnt sich zu verlangsamen. Sie haben bei der CloudWatch-Überwachung festgestellt, dass dies nur zwischen 00:00 und 12:00 UTC geschieht. Aufgrund der gleichen Start- und Endverzögerungszeiten stellen Sie fest, dass dies auf eine geplante Aufgabe auf dem Server zurückzuführen ist. Überprüfen Sie crontab und stellen Sie fest, dass ein Job für Mitternacht geplant ist: Backup. Natürlich dauert die Sicherung zwölf Stunden und führt zu einer Überlastung der Datenbank, was zu einer erheblichen Verlangsamung der Site führt.
Sie haben dies bereits gelesen - und entscheiden sich, Sicherungen in einer Slave-Datenbank auszuführen. Dann denken Sie daran: Sie haben keine untergeordnete Datenbank, also müssen Sie sie erstellen. Es macht wenig Sinn, die Slave-Datenbank auf demselben Server auszuführen, daher entscheiden Sie sich für eine Erweiterung. Erstellen Sie zwei neue Server: einen für die Master-Datenbank und einen für die Slave-Datenbank. Ändern Sie die Sicherung so, dass sie mit einer untergeordneten Datenbank funktioniert.
 Abb. 4
Abb. 4Teamwachstum
Für eine Weile läuft alles reibungslos. Monate vergehen. Sie stellen Entwickler ein. Einer der Neuankömmlinge führt einen Fehler ein, der den Produktionsserver herunterfährt. Der Entwickler gibt der Entwicklungsumgebung die Schuld, die sich von der Produktion unterscheidet. In seinen Worten steckt etwas Wahres. Da Sie eine vernünftige Person mit einem guten Charakter sind, nehmen Sie dieses Ereignis als Lektion wahr.
Es ist Zeit, zusätzliche Umgebungen zu erstellen: Staging, Qualitätssicherung und Produktion. Glücklicherweise haben Sie vom ersten Tag an die Erstellung der Infrastruktur automatisiert, sodass alles reibungslos und einfach verläuft. Sie haben vom ersten Tag an gute Methoden für die kontinuierliche Lieferung festgelegt, sodass Sie problemlos ein Förderband aus neuen Niederlassungen zusammenbauen können.
Die Marketingabteilung drängt auf Version 2.0. Sie verstehen nicht ganz, was 2.0 bedeutet, aber Sie stimmen zu. Es ist Zeit, sich auf den nächsten Verkehrsanstieg vorzubereiten. Sie befinden sich bereits in der Nähe des Spitzenwerts auf dem aktuellen Server, sodass die Zeit für den Lastenausgleich gekommen ist. Amazon ELB macht dies einfach. Ungefähr zu dieser Zeit stellen Sie fest, dass die geschichteten Diagramme in diesem Artikel Ebenen von oben nach unten und nicht von links nach rechts anzeigen sollten.
 Abb. 5
Abb. 5Zuversichtlich, dass Sie mit der Last fertig werden, erwähnen Sie erneut Ihre Website auf Habré. Oh Wunder, es kann dem Verkehr standhalten. Großer Erfolg!
Alles schien gut zu laufen, bis Sie die Protokolle überprüft haben. Das Testen von 12 Servern dauerte eine Stunde (vier Server in jeder Umgebung). Ein echter Ärger. Glücklicherweise gibt es genug Geld, um einen ELK-Stack (ElasticSearch, LogStash, Kibana) zu kaufen. Sie stellen es bereit und leiten Server aus allen Umgebungen dorthin.
 Abb. 6
Abb. 6Jetzt können Sie sich wieder den Protokollen zuwenden, sie ansehen - und etwas Merkwürdiges bemerken. Sie sind voll von solchen Einträgen:
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
Sie verwenden weder PHP noch WordPress, daher ist dies ziemlich seltsam. Sie bemerken ähnliche verdächtige Einträge in den Protokollen der Datenbankserver und fragen sich, wie sie überhaupt mit dem Internet verbunden sind. Es ist Zeit, öffentliche und private Subnetze zu implementieren.
 Abb. 7
Abb. 7Überprüfen Sie die Protokolle erneut. Hacking-Versuche blieben bestehen, aber jetzt sind sie auf Port 80 des Load Balancers beschränkt, was ein wenig beruhigend ist, da Anwendungsserver, Datenbankserver und der ELK-Stack nicht mehr gemeinfrei sind.
Trotz der zentralisierten Protokolle haben Sie es satt, nach Ausfallzeiten zu suchen und die Protokolle manuell zu überprüfen. Über Amazon CloudWatch richten Sie E-Mail-Benachrichtigungen ein, wenn Laufwerk, CPU und Netzwerk eine Auslastung von 80% erreichen. Großartig!
Reibungsloser Betrieb
Nur ein Scherz! In der Software gibt es keinen reibungslosen Betrieb. Etwas wird definitiv kaputt gehen. Glücklicherweise haben Sie jetzt viele Werkzeuge, um mit der Situation umzugehen.
Wir haben eine skalierbare Webanwendung mit Backups, Rollbacks (unter Verwendung von blau / grünen Bereitstellungen zwischen der Produktion und der Zwischenstufe), zentralisierten Protokollen, Überwachung und Benachrichtigung erstellt. Die weitere Skalierung hängt in der Regel von den spezifischen Anforderungen der Anwendung ab.
Es gibt viele Hosting-Optionen auf dem Markt, die die meisten der genannten Aufgaben übernehmen. Anstatt selbst zu entwickeln, können Sie sich auf Beanstalk, AppEngine, GKE, ECS usw. verlassen. Die meisten dieser Dienste konfigurieren automatisch angemessene Berechtigungen, Subsysteme, Subnetze für den Lastenausgleich usw. Dadurch entfällt ein erheblicher Teil des Aufwandes für das schnelle und schnelle Ausführen einer Webanwendung zuverlässiges Backend, das lange funktioniert.
Trotzdem finde ich es nützlich zu verstehen, welche Funktionen jede dieser Plattformen bietet und warum sie diese bereitstellen. Dies macht es einfach, eine Plattform auszuwählen, die auf Ihren eigenen Bedürfnissen basiert. Wenn Sie die Anwendung auf einer solchen Plattform hosten, wissen Sie bereits, wie diese Module funktionieren. Wenn etwas schief geht, ist es hilfreich, die Tools zur Lösung des Problems zu kennen.
Fazit
Dieser Artikel lässt viele Details aus. Es wird nicht beschrieben, wie die Erstellung von Infrastrukturen automatisiert, Server vorbereitet und konfiguriert werden. Es umfasst nicht das Erstellen von Entwicklungsumgebungen, das Einrichten von Pipelines für die kontinuierliche Bereitstellung sowie das Bereitstellen und Zurücksetzen. Wir haben uns nicht mit Netzwerksicherheit, Schlüsselfreigabe und dem Prinzip der Mindestberechtigungen befasst. Sie sprachen nicht über die Bedeutung unveränderlicher Infrastrukturen, zustandsloser Server und Migrationen. Für jedes Thema ist ein eigener Artikel erforderlich.
Der Zweck dieses Beitrags ist ein allgemeiner Überblick darüber, wie eine vernünftige Webanwendung in der Produktion aussehen sollte. Zukünftige Artikel können hier verlinken und das Thema erweitern.
Das ist alles für jetzt.
Danke fürs Lesen und gute Codierung!
Hinweis: Nehmen Sie die Reihenfolge nicht wörtlich aus diesem illustrativen Artikel. Unabhängig davon sind mir all diese Ereignisse wirklich passiert, aber zu unterschiedlichen Zeiten, in völlig unterschiedlichen Umgebungen und bei unterschiedlichen Aufgaben.