Nikolai Ryzhikov schlug seine Version der Antwort auf die Frage vor, warum es so schwierig ist, eine Benutzeroberfläche zu entwickeln. Am Beispiel seines Projekts wird er zeigen, dass die Anwendung einiger Ideen aus dem Backend auf dem Frontend sowohl die Reduzierung der Entwicklungskomplexität als auch die Testbarkeit des Frontends beeinflusst.
Das Material wurde auf der Grundlage eines Berichts von Nikolai Ryzhikov auf der Frühjahrskonferenz
HolyJS 2018 Piter vorbereitet .
Derzeit arbeitet Nikolai Ryzhikov im Gesundheits-IT-Bereich an der Schaffung medizinischer Informationssysteme. Mitglied der St. Petersburger Community der funktionalen Programmierer FPROG. Aktives Mitglied der Online Clojure-Community, Mitglied des HL7 FHIR-Standards für den Austausch medizinischer Informationen. Programmiert seit 15 Jahren.
- Die Frage, warum die grafische Benutzeroberfläche immer schwierig war, hat mich immer gequält. Warum hat dies immer viele Fragen aufgeworfen?
Heute werde ich versuchen zu spekulieren, ob es möglich ist, eine Benutzeroberfläche effektiv zu entwickeln. Können wir die Komplexität seiner Entwicklung reduzieren?
Was ist Effizienz?
Definieren wir, was Effizienz ist. Unter dem Gesichtspunkt der Entwicklung einer Benutzeroberfläche bedeutet Effizienz:
- Entwicklungsgeschwindigkeit
- Anzahl der Fehler
- Geldbetrag ausgegeben ...
Es gibt eine sehr gute Definition:
Effizienz macht mehr mit weniger
Nach dieser Bestimmung können Sie alles setzen, was Sie wollen - weniger Zeit, weniger Aufwand. Beispiel: "Wenn Sie weniger Code schreiben, lassen Sie weniger Fehler zu" und erreichen Sie dasselbe Ziel. Im Allgemeinen geben wir uns viel Mühe umsonst. Und Effizienz ist ein ziemlich hohes Ziel - diese Verluste loszuwerden und nur das zu tun, was benötigt wird.
Was ist Komplexität?
Komplexität ist meiner Meinung nach das Hauptproblem in der Entwicklung.
Fred Brooks schrieb 1986 einen Artikel mit dem Titel No Silver Bullet. Darin reflektiert er Software. Bei der Hardware sind die Fortschritte sprunghaft und mit der Software ist alles viel schlimmer. Die Hauptfrage von Fred Brooks: Kann es eine solche Technologie geben, die uns sofort um eine Größenordnung beschleunigt? Und er selbst gibt eine pessimistische Antwort und erklärt, dass es in Software nicht möglich ist, dies zu erreichen, und erklärt seine Position. Ich empfehle dringend, diesen Artikel zu lesen.
Ein Freund von mir sagte, die UI-Programmierung sei so ein "schmutziges Problem". Sie können sich nicht einmal hinsetzen und die richtige Option finden, damit das Problem für immer gelöst wird. Darüber hinaus hat die Komplexität der Entwicklung in den letzten 10 Jahren nur zugenommen.
Vor 12 Jahren ...
Wir haben vor 12 Jahren mit der Entwicklung eines medizinischen Informationssystems begonnen. Zuerst mit Blitz. Dann haben wir uns angesehen, was Google Mail zu tun begann. Es hat uns gefallen und wir wollten mit HTML zu JavaScript wechseln.
In der Tat waren wir dann der Zeit weit voraus. Wir haben ein Dojo genommen, und tatsächlich hatten wir alles so wie jetzt. Es gab Komponenten, die in Dojo-Widgets ziemlich gut waren, es gab ein modulares Build-System, für das der Google Clojure Compiler erstellt und minimiert werden musste (RequireJS und CommonJS rochen damals nicht einmal).
Alles hat geklappt. Wir haben uns Google Mail angesehen, waren begeistert und fanden, dass alles in Ordnung war. Zuerst haben wir nur einen Patientenkartenleser geschrieben. Dann wechselten sie schrittweise zur Automatisierung anderer Arbeitsabläufe im Krankenhaus. Und alles wurde kompliziert. Das Team scheint professionell zu sein - aber jedes Feature begann zu knarren. Diese Sensation trat vor 12 Jahren auf - und verlässt mich immer noch nicht.
Schienen Weg + jQuery
Wir haben die Systemzertifizierung durchgeführt und es war notwendig, ein Patientenportal zu schreiben. Dies ist ein solches System, in dem der Patient seine medizinischen Daten einsehen kann.
Unser Backend wurde dann in Ruby on Rails geschrieben. Obwohl die Ruby on Rails-Community nicht sehr groß ist, hat sie einen enormen Einfluss auf die Branche. Aus Ihrer kleinen leidenschaftlichen Community sind alle Ihre Paketmanager, GitHub, Git, automatischen Make-ups usw. gekommen.
Das Wesentliche an der Herausforderung war, dass wir das Patientenportal in zwei Wochen implementieren mussten. Und wir haben uns entschlossen, Rails auszuprobieren - um alles auf dem Server zu erledigen. So ein klassisches Web 2.0. Und sie haben es getan - sie haben es wirklich in zwei Wochen getan.
Wir waren dem ganzen Planeten voraus: Wir haben SPA gemacht, wir hatten eine REST-API, aber aus irgendeinem Grund war sie unwirksam. Einige Funktionen konnten bereits Einheiten bilden, da nur sie all diese Komplexität von Komponenten, die Beziehung des Backends zum Frontend, berücksichtigen konnten. Und als wir den Rails-Weg eingeschlagen haben - ein bisschen veraltet für unsere Standards -, begannen die Funktionen plötzlich zu nieten. Der durchschnittliche Entwickler begann innerhalb weniger Tage mit der Einführung des Features. Und wir haben sogar angefangen, einfache Tests zu schreiben.
Auf dieser Basis habe ich tatsächlich noch eine Verletzung: Es gab Fragen. Als wir im Backend von Java auf Rails umgestiegen sind, hat sich die Entwicklungseffizienz um das Zehnfache erhöht. Als wir im SPA ein Tor erzielten, stieg auch die Entwicklungseffizienz erheblich an. Wie so?
Warum war Web 2.0 effektiv?
Beginnen wir mit einer anderen Frage: Warum machen wir einen einseitigen Antrag, warum glauben wir daran?
Sie sagen uns nur: Wir müssen das tun - und wir tun es. Und sehr selten in Frage stellen. Ist die REST-API und die SPA-Architektur korrekt? Ist es wirklich für den Fall geeignet, in dem wir es verwenden? Wir denken nicht.
Auf der anderen Seite gibt es herausragende umgekehrte Beispiele. Jeder benutzt GitHub. Wissen Sie, dass GitHub keine Einzelseitenanwendung ist? GitHub ist eine reguläre "Rail" -Anwendung, die auf dem Server gerendert wird und in der es nur wenige Widgets gibt. Hat jemand Mehl daraus erfahren? Ich denke, es gibt drei Leute. Der Rest bemerkte es nicht einmal. Dies hatte keinerlei Auswirkungen auf den Benutzer, aber gleichzeitig müssen wir aus irgendeinem Grund zehnmal mehr für die Entwicklung anderer Anwendungen bezahlen (sowohl Stärke als auch Komplexität usw.). Ein weiteres Beispiel ist Basecamp. Twitter war einst nur eine Rails-Anwendung.
Tatsächlich gibt es so viele Rails-Anwendungen. Dies wurde teilweise vom Genie DHH (David Heinemeier Hansson, Schöpfer von Ruby on Rails) bestimmt. Er war in der Lage, ein auf das Geschäft ausgerichtetes Tool zu erstellen, mit dem Sie sofort das tun können, was Sie benötigen, ohne von technischen Problemen abgelenkt zu werden.
Als wir den Rails-Weg benutzten, gab es natürlich viel schwarze Magie. Während wir uns schrittweise entwickelten, wechselten wir von Ruby zu Clojure, wobei praktisch die gleiche Effizienz beibehalten wurde, aber alles um eine Größenordnung einfacher wurde. Und es war wunderbar.
12 Jahre sind vergangen
Im Laufe der Zeit tauchten im Frontend neue Trends auf.
Wir haben Backbone völlig ignoriert, da die Dojo-Anwendung, die wir zuvor geschrieben haben, noch ausgefeilter war als das, was Backbone anbot.
Dann kam Angular. Es war ein ziemlich interessanter „Lichtstrahl“ - unter dem Gesichtspunkt der Effizienz ist Angular sehr gut. Sie nehmen den durchschnittlichen Entwickler und er nietet die Funktion. Unter dem Gesichtspunkt der Einfachheit bringt Angular jedoch eine Reihe von Problemen mit sich - es ist undurchsichtig, komplex, es gibt Beobachtung, Optimierung usw.
Es erschien eine Reaktion, die ein wenig Einfachheit brachte (zumindest die Unkompliziertheit des Renderings, die es uns aufgrund des virtuellen DOM jedes Mal ermöglicht, einfach neu zu zeichnen, zu verstehen und einfach zu schreiben). Aber in Bezug auf die Effizienz hat uns React, um ehrlich zu sein, erheblich zurückgedrängt.
Das Schlimmste ist, dass sich in 12 Jahren nichts geändert hat. Wir machen immer noch das Gleiche wie damals. Es ist Zeit zum Nachdenken - hier stimmt etwas nicht.
Laut Fred Brooks gibt es zwei Probleme bei der Softwareentwicklung. Natürlich sieht er das Hauptproblem in der Komplexität, aber er teilt es in zwei Gruppen ein:
- erhebliche Komplexität, die sich aus der Aufgabe selbst ergibt. Es kann einfach nicht weggeworfen werden, weil es Teil der Aufgabe ist.
- zufällige Komplexität ist diejenige, die wir einbringen, um dieses Problem zu lösen.
Die Frage ist, wie ist das Gleichgewicht zwischen ihnen. Genau darüber diskutieren wir jetzt.
Warum ist es so schmerzhaft, die Benutzeroberfläche zu erstellen?
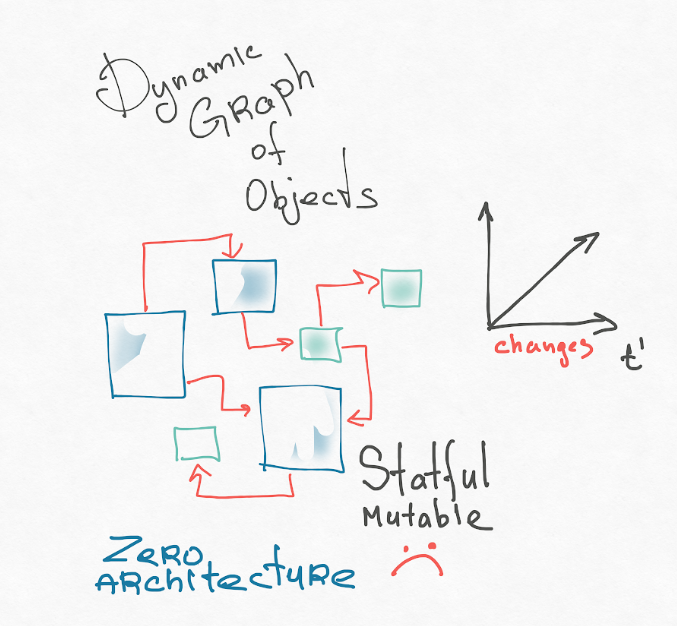
Es scheint mir, dass der erste Grund unser mentales Anwendungsmodell ist. Reaktionskomponenten sind ein reiner OOP-Ansatz. Unser System ist ein dynamischer Graph von veränderlichen Objekten, die miteinander verbunden sind. Turing-Complete-Typen generieren ständig Knoten dieses Diagramms, einige Knoten verschwinden. Haben Sie jemals versucht, sich Ihre Anwendung in Ihrem Kopf vorzustellen? Das ist schrecklich! Normalerweise präsentiere ich eine OOP-Anwendung wie folgt:

Ich empfehle, die Thesen von Roy Fielding (Autor der REST-Architektur) zu lesen. Seine Dissertation trägt den Titel "Architekturstile und das Design netzwerkbasierter Software". Ganz am Anfang gibt es eine sehr gute Einführung, in der er darüber spricht, wie man zur Architektur im Allgemeinen gelangt, und die Konzepte einführt: das System in Komponenten und die Beziehungen zwischen diesen Komponenten aufteilt. Es hat eine "Null" -Architektur, in der alle Komponenten möglicherweise allen zugeordnet werden können. Das ist architektonisches Chaos. Dies ist unsere Objektdarstellung der Benutzeroberfläche.
Roy Fielding empfiehlt, nach einer Reihe von Einschränkungen zu suchen und diese aufzuerlegen, da diese Einschränkungen Ihre Architektur definieren.
Das wahrscheinlich Wichtigste ist, dass Einschränkungen Freunde des Architekten sind. Suchen Sie nach diesen realen Einschränkungen und entwerfen Sie daraus ein System. Weil Freiheit böse ist. Freiheit bedeutet, dass Sie über eine Million Optionen verfügen, aus denen Sie auswählen können, und nicht über ein einziges Kriterium, anhand dessen Sie bestimmen können, ob die Auswahl richtig war. Suchen Sie nach Einschränkungen und bauen Sie darauf auf.
Es gibt einen ausgezeichneten Artikel namens OUT OF THE TAR PIT („Einfacher als eine Teergrube“), in dem die Jungs nach Brooks beschlossen, zu analysieren, was genau zur Komplexität der Anwendung beiträgt. Sie kamen zu dem enttäuschenden Schluss, dass ein veränderliches, staatlich verbreitetes System die Hauptursache für Komplexität ist. Hier ist es möglich, rein kombinatorisch zu erklären - wenn Sie zwei Zellen haben und in jeder von ihnen eine Kugel liegen kann (oder nicht lügen kann), wie viele Zustände sind möglich? - Vier.
Wenn drei Zellen - 2
3 , wenn 100 Zellen - 2
100 . Wenn Sie Ihre Anwendung präsentieren und verstehen, wie viel Status verschwommen ist, stellen Sie fest, dass es unendlich viele mögliche Status Ihres Systems gibt. Wenn Sie gleichzeitig durch nichts eingeschränkt sind, ist es zu schwierig. Und das menschliche Gehirn ist schwach, das haben bereits verschiedene Studien bewiesen. Wir können bis zu drei Elemente gleichzeitig in unseren Köpfen halten. Einige sagen sieben, aber selbst dafür benutzt das Gehirn einen Hack. Komplexität ist daher für uns ein echtes Problem.
Ich empfehle diesen Artikel zu lesen, in dem die Jungs zu dem Schluss kommen, dass mit diesem veränderlichen Zustand etwas getan werden muss. Beispielsweise gibt es relationale Datenbanken, in denen Sie den gesamten veränderlichen Status entfernen können. Und der Rest wird in einem rein funktionalen Stil erledigt. Und sie haben gerade die Idee einer solchen funktional-relationalen Programmierung.
Das Problem ergibt sich also aus der Tatsache, dass:
- Erstens haben wir kein gutes Modell für eine feste Benutzeroberfläche. Komponentenansätze führen uns in die existierende Hölle. Wir legen keine Einschränkungen fest, wir verbreiten den veränderlichen Zustand, was dazu führt, dass die Komplexität des Systems uns irgendwann einfach zerquetscht.
- Zweitens, wenn wir eine klassische Backend-Frontend-Anwendung schreiben, handelt es sich bereits um ein verteiltes System. Die erste Regel für verteilte Systeme lautet, keine verteilten Systeme zu erstellen (Erstes Gesetz für das Design verteilter Objekte: Verteilen Sie Ihre Objekte nicht - von Martin Fowler), da Sie die Komplexität sofort um eine Größenordnung erhöhen. Jeder, der eine Integration geschrieben hat, versteht, dass alle Projektschätzungen mit 10 multipliziert werden können, sobald Sie in die systemübergreifende Interaktion eintreten. Wir vergessen dies jedoch einfach und wechseln zu verteilten Systemen. Dies war wahrscheinlich die Hauptüberlegung, als wir zu Rails wechselten und die gesamte Kontrolle an den Server zurückgaben.
All dies ist zu hart für ein armes menschliches Gehirn. Lassen Sie uns darüber nachdenken, was wir mit diesen beiden Problemen tun können - dem Fehlen von Einschränkungen in der Architektur (dem Diagramm veränderlicher Objekte) und dem Übergang zu verteilten Systemen, die so komplex sind, dass Wissenschaftler immer noch rätseln, wie sie richtig gemacht werden sollen (gleichzeitig wir) verurteilen wir uns zu diesen Qualen in den einfachsten Geschäftsanwendungen)?
Wie hat sich das Backend entwickelt?
Wenn wir das Backend im gleichen Stil schreiben, in dem wir jetzt die Benutzeroberfläche erstellen, wird es das gleiche „blutige Durcheinander“ geben. Wir werden so viel Zeit damit verbringen. Also wirklich einmal versucht zu tun. Dann begannen sie allmählich, Beschränkungen aufzuerlegen.
Die erste große Backend-Erfindung ist die Datenbank.
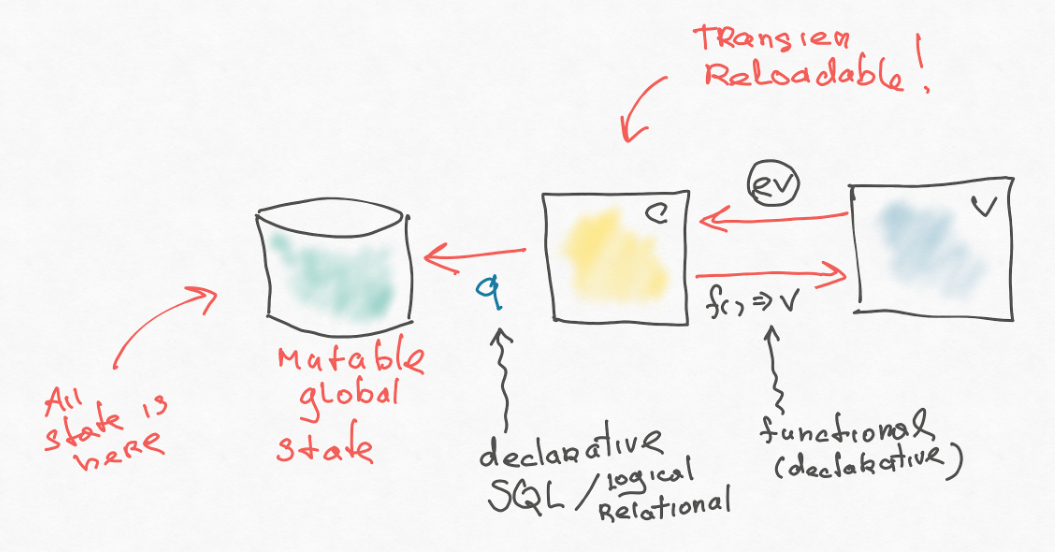
Im Programm hing zunächst unerklärlicherweise der gesamte Staat, und es war schwierig, ihn zu verwalten. Im Laufe der Zeit haben die Entwickler eine Datenbank erstellt und dort den gesamten Status entfernt.
Der erste interessante Unterschied zwischen der Datenbank besteht darin, dass die Daten dort keine Objekte mit eigenem Verhalten sind, sondern reine Informationen. Es gibt Tabellen oder andere Datenstrukturen (z. B. JSON). Sie haben kein Verhalten, und das ist auch sehr wichtig. Weil Verhalten eine Interpretation von Informationen ist und es viele Interpretationen geben kann. Und die grundlegenden Fakten - sie bleiben grundlegend.
Ein weiterer wichtiger Punkt ist, dass wir über diese Datenbank eine Abfragesprache wie SQL haben. Unter dem Gesichtspunkt der Einschränkungen ist SQL in den meisten Fällen keine Turing-vollständige Sprache, sondern einfacher. Auf der anderen Seite ist es deklarativ - ausdrucksvoller, weil Sie in SQL "was" sagen, nicht "wie". Wenn Sie beispielsweise zwei Bezeichnungen in SQL kombinieren, entscheidet SQL, wie dieser Vorgang effizient ausgeführt werden soll. Wenn Sie etwas suchen, nimmt er einen Index für Sie auf. Sie geben dies niemals explizit an. Wenn Sie versuchen, etwas in JavaScript zu kombinieren, müssen Sie dafür eine Menge Code schreiben.
Auch hier ist es wichtig, dass wir Beschränkungen auferlegt haben, und jetzt gehen wir durch eine einfachere und ausdrucksstärkere Sprache zu dieser Basis. Umverteilte Komplexität.
Nachdem das Backend die Basis betreten hatte, wurde die Anwendung zustandslos. Dies führt zu interessanten Effekten - jetzt haben wir beispielsweise möglicherweise keine Angst mehr, die Anwendung zu aktualisieren (der Status hängt nicht in der Anwendungsschicht im Speicher, die beim Neustart der Anwendung verschwindet). Für eine Anwendungsschicht ist zustandslos eine gute Funktion und eine hervorragende Einschränkung. Zieh es an, wenn du kannst. Darüber hinaus kann eine neue Anwendung auf die alte Basis gezogen werden, da Fakten und ihre Interpretation keine verwandten Dinge sind.
Unter diesem Gesichtspunkt sind Objekte und Klassen schrecklich, weil sie Verhalten und Informationen zusammenfügen. Informationen sind reicher und leben länger. Datenbanken und Fakten überleben Code, der in Delphi, Perl oder JavaScript geschrieben wurde.
Als das Backend zu einer solchen Architektur kam, wurde alles viel einfacher. Die goldene Ära des Web 2.0 ist angebrochen. Es war möglich, etwas aus der Datenbank zu holen, die Daten einer Vorlage zu unterziehen (reine Funktion) und das HTML-ku zurückzugeben, das an den Browser gesendet wird.
Wir haben gelernt, wie man ziemlich komplexe Anwendungen im Backend schreibt. Und die meisten Anwendungen sind in diesem Stil geschrieben. Sobald das Backend einen Schritt zur Seite macht - in die Unsicherheit - beginnen die Probleme erneut.
Die Leute begannen darüber nachzudenken und kamen auf die Idee, die PLO und die Rituale wegzuwerfen.
Was machen unsere Systeme eigentlich? Sie nehmen Informationen von irgendwoher - vom Benutzer, von einem anderen System und dergleichen -, legen sie in die Datenbank, transformieren sie, überprüfen sie irgendwie. Von der Basis nehmen sie es mit listigen Abfragen (analytisch oder synthetisch) heraus und geben es zurück. Das ist alles. Und das ist wichtig zu verstehen. Unter diesem Gesichtspunkt sind Simulationen ein sehr falsches und schlechtes Konzept.
Es scheint mir, dass im Allgemeinen die gesamte OOP tatsächlich von der Benutzeroberfläche aus geboren wurde. Die Leute versuchten, eine Benutzeroberfläche zu simulieren und zu simulieren. Sie sahen ein bestimmtes Grafikobjekt auf dem Monitor und dachten: Es wäre schön, es in unserer Laufzeit zusammen mit seinen Eigenschaften usw. zu stimulieren. Diese ganze Geschichte ist sehr eng mit der OOP verflochten. Die Simulation ist jedoch der einfachste und naivste Weg, um die Aufgabe zu lösen. Interessante Dinge werden getan, wenn Sie beiseite treten. Unter diesem Gesichtspunkt ist es wichtiger, Informationen vom Verhalten zu trennen, diese seltsamen Objekte zu entfernen, und alles wird viel einfacher: Ihr Webserver empfängt eine HTTP-Zeichenfolge und gibt eine HTTP-Antwortzeichenfolge zurück. Wenn Sie der Gleichung eine Basis hinzufügen, erhalten Sie eine allgemein reine Funktion: Der Server akzeptiert die Basis und die Anforderung, gibt eine neue Basis und Antwort zurück (eingegebene Daten - Daten übrig).
Auf dem Weg zu dieser Vereinfachung warfen Funktionäre ⅔ mehr Gepäck, das sich im Backend angesammelt hatte. Er wurde nicht gebraucht, es war nur ein Ritual. Wir sind immer noch kein Spielentwickler - wir brauchen den Patienten und den Arzt nicht, um irgendwie zur Laufzeit zu leben, ihre Koordinaten zu bewegen und zu verfolgen. Unser Informationsmodell ist etwas anderes. Wir geben nicht vor, Medizin, Verkauf oder irgendetwas anderes zu sein. Wir schaffen an der Kreuzung etwas Neues. Beispielsweise simuliert Uber nicht das Verhalten von Bedienern und Maschinen, sondern führt ein neues Informationsmodell ein. In unserem Bereich schaffen wir auch etwas Neues, damit Sie die Freiheit spüren können.
Es ist nicht notwendig zu versuchen, vollständig zu simulieren - erstellen.
Clojure = JS--
Es ist Zeit, Ihnen genau zu sagen, wie Sie alles wegwerfen können. Und hier möchte ich Clojure Script erwähnen. Wenn Sie JavaScript kennen, kennen Sie Clojure. In Clojure fügen wir JavaScript keine Funktionen hinzu, sondern entfernen sie.
- Wir werfen die Syntax weg - in Clojure (in Lisp) gibt es keine Syntax. In einer gewöhnlichen Sprache schreiben wir Code, der dann analysiert und ein AST erhalten wird, der kompiliert und ausgeführt wird. In Lisp schreiben wir sofort einen AST, der ausgeführt - interpretiert oder kompiliert werden kann.
- Wir werfen die Veränderlichkeit aus. In Clojure gibt es keine veränderlichen Objekte oder Arrays. Jede Operation wird wie eine neue Kopie generiert. Darüber hinaus ist diese Kopie sehr billig. Das ist so geschickt gemacht, um billig zu sein. Und so können wir wie in der Mathematik mit Werten arbeiten. Wir ändern nichts - wir schaffen etwas Neues. Sicher, einfach.
- Wir werfen Klassen, Spiele mit Prototypen usw. Das ist einfach nicht da.
Infolgedessen verfügen wir weiterhin über Funktionen und Datenstrukturen, über die wir arbeiten, sowie über Grundelemente. Hier ist die ganze Clojure. Und darauf können Sie dasselbe tun wie in anderen Sprachen, wo es viele zusätzliche Tools gibt, die niemand verwenden kann.
Beispiele
Wie kommen wir über AST nach Lisp? Hier ist ein klassischer Ausdruck:
(1 + 2) - 3
Wenn wir versuchen, seinen AST beispielsweise in Form eines Arrays zu schreiben, wobei der Kopf der Knotentyp ist und der nächste Parameter ein Parameter ist, erhalten wir etwas Ähnliches (wir versuchen, dies in Java Script zu schreiben):
['minus', ['plus', 1, 2], 3]
Werfen Sie nun die zusätzlichen Anführungszeichen weg, wir können das Minus durch
- und das Plus durch
+ ersetzen. Wirf die Kommas, die in Lisp Leerzeichen sind, weg. Wir werden den gleichen AST bekommen:
(- (+ 1 2) 3)
Und in Lisp schreiben wir alle so. Wir können überprüfen - dies ist eine rein mathematische Funktion (mein Emacs ist mit dem Browser verbunden; ich lasse das Skript dort fallen, es wertet den Befehl dort aus und sendet ihn zurück an Emacs - Sie sehen den Wert nach dem Symbol
=> ):
(- (+ 1 2) 3) => 0
Wir können auch eine Funktion deklarieren:
(defn xplus [ab] (+ ab)) ((fn [xy] (* xy)) 1 2) => 2
Oder eine anonyme Funktion. Vielleicht sieht das ein bisschen beängstigend aus:
(type xplus)
Ihr Typ ist eine JavaScript-Funktion:
(type xplus) => #object[Function]
Wir können es aufrufen, indem wir ihm den Parameter übergeben:
(xplus 1 2)
Das heißt, wir schreiben nur AST, das dann entweder in JS oder Bytecode kompiliert oder interpretiert wird.
(defn mymin [ab] (if (a > b) ba))
Clojure ist eine gehostete Sprache. Daher werden Grundelemente aus der übergeordneten Laufzeit verwendet, dh im Fall von Clojure Script haben wir JavaScript-Typen:
(type 1) => #object[Number]
(type "string") => #object[String]
Also werden reguläre Ausdrücke geschrieben:
(type #"^Cl.*$") => #object[RegExp]
Die Funktionen, die wir haben, sind Funktionen:
(type (fn [x] x)) => #object[Function]
Als nächstes brauchen wir eine Art zusammengesetzte Typen.
(def user {:name "niquola" :address {:city "SPb"} :profiles [{:type "github" :link "https://….."} {:type "twitter" :link "https://….."}] :age 37} (type user)
Dies kann so gelesen werden, als würden Sie ein Objekt in JavaScript erstellen:
(def user {name: "niquola" …
In Clojure wird dies als Hashmap bezeichnet. Dies ist ein Container, in dem Werte liegen. Wenn eckige Klammern verwendet werden - dies wird als Vektor bezeichnet - ist dies Ihr Array:
(def user {:name "niquola" :address {:city "SPb"} :profiles [{:type "github" :link "https://….."} {:type "twitter" :link "https://….."}] :age 37} => #'intro/user (type user)
Wir zeichnen alle Informationen mit Hashmaps und Vektoren auf.
Seltsame Doppelpunktnamen (
:name ) sind die sogenannten Zeichen: konstante Zeichenfolgen, die erstellt werden, um als Schlüssel in Hashmaps verwendet zu werden. In verschiedenen Sprachen werden sie unterschiedlich genannt - Symbole, etwas anderes. Dies kann jedoch einfach als konstante Zeichenfolge verstanden werden. Sie sind sehr effektiv - Sie können lange Namen schreiben und nicht viel Ressourcen dafür ausgeben, da sie miteinander verbunden sind (d. H. Sie werden nicht wiederholt).
Clojure bietet Hunderte von Funktionen, um diese generischen Datenstrukturen und Grundelemente zu verarbeiten. Wir können neue Schlüssel hinzufügen. Darüber hinaus haben wir immer eine Kopiersemantik, dh jedes Mal, wenn wir eine neue Kopie erhalten. Zuerst müssen Sie sich daran gewöhnen, da Sie nicht mehr wie zuvor irgendwo in der Variablen etwas speichern und dann diesen Wert ändern können. Ihre Berechnung sollte immer einfach sein - alle Argumente müssen explizit an die Funktion übergeben werden.
Dies führt zu einer wichtigen Sache. In funktionalen Sprachen ist eine Funktion eine ideale Komponente, da sie alles explizit am Eingang empfängt. Keine versteckten Links im System. Sie können eine Funktion von einem Ort übernehmen, an einen anderen übertragen und dort verwenden.
In Clojure haben wir auch für komplexe Verbundtypen hervorragende Wertgleichheitsoperationen:
(= {:a 1} {:a 1}) => true
Und diese Operation ist billig, weil listige unveränderliche Strukturen einfach durch Bezugnahme verglichen werden können. Daher können wir sogar eine Hashmap mit Millionen von Schlüsseln in einer Operation vergleichen.
Übrigens haben die Jungs von React einfach die Clojure-Implementierung kopiert und unveränderliche JS gemacht.
Clojure hat auch eine Reihe von Operationen, zum Beispiel, um etwas von einem verschachtelten Pfad in der Hashmap abzurufen:
(get-in user [:address :city])
Fügen Sie in der Hashmap etwas entlang des verschachtelten Pfads ein:
(assoc-in user [:address :city] "LA") => {:name "niquola", :address {:city "LA"}, :profiles [{:type "github", :link "https://….."} {:type "twitter", :link "https://….."}], :age 37}
Aktualisieren Sie einen Wert:
(update-in user [:profiles 0 :link] (fn [old] (str old "+++++")))
Wählen Sie nur einen bestimmten Schlüssel aus:
(select-keys user [:name :address])
Gleiches gilt für den Vektor:
(def clojurists [{:name "Rich"} {:name "Micael"}]) (first clojurists) (second clojurists) => {:name "Michael"}
Es gibt Hunderte von Operationen aus der Basisbibliothek, mit denen Sie diese Datenstrukturen bearbeiten können. Es gibt eine Interop mit dem Host. Man muss sich ein bisschen daran gewöhnen:
(js/alert "Hello!") => nil </csource> "". location window: <source lang="clojure"> (.-location js/window)
Es gibt jeden Zucker entlang der Ketten:
(.. js/window -location -href) => "http://localhost:3000/#/billing/dashboard"
(.. js/window -location -host) => "localhost:3000"
Ich kann das JS-Datum nehmen und das Jahr daraus zurückgeben:
(let [d (js/Date.)] (.getFullYear d)) => 2018
Rich Hickey, der Schöpfer von Clojure, hat uns stark eingeschränkt. Wir haben wirklich nichts anderes, also machen wir alles durch generische Datenstrukturen. Wenn wir beispielsweise SQL schreiben, schreiben wir es normalerweise mit einer Datenstruktur. Wenn Sie genau hinschauen, werden Sie feststellen, dass dies nur eine Hashmap ist, in die etwas eingebettet ist. Dann gibt es eine Funktion, die all dies in eine SQL-Zeichenfolge übersetzt:
{select [:*] :from [:users] :where [:= :id "user-1"]} => {:select [:*], :from [:users], :where [:= :id "user-1"]}
Wir schreiben auch Routings mit einer Datenstruktur und gesetzten Datenstrukturen:
{"users" {:get {:handler :users-list}} :get {:handler :welcome-page}}
[:div.row [:div {:on-click #(.log js/console "Hello")} "User "]]
DB in der Benutzeroberfläche
Also haben wir über Clojure gesprochen. Aber ich habe bereits erwähnt, dass die Datenbank ein großer Erfolg im Backend war. Wenn Sie sich ansehen, was jetzt im Frontend passiert, werden wir sehen, dass die Jungs das gleiche Muster verwenden - sie geben die Datenbank in der Benutzeroberfläche ein (in einer einseitigen Anwendung).
Datenbanken werden in der Ulmenarchitektur, in Clojure-Skripten und sogar in begrenzter Form in Flux und Redux eingeführt (zusätzliche Plugins müssen hier gesetzt werden, um Anforderungen auszulösen). Ulmenarchitektur, Re-Frame und Flux wurden ungefähr zur gleichen Zeit gestartet und voneinander entlehnt. Wir schreiben auf Re-Frame. Als nächstes werde ich ein wenig darüber sprechen, wie es funktioniert.

Ereignis (es ist ein bisschen wie Redux) fliegt aus dem View-Chi, das von einem bestimmten Controller gefangen wird. Den Controller nennen wir Event-Handler. Der Event-Handler gibt einen Effekt aus, der auch von der Datenstruktur interpretiert wird.
Eine Art von Effekt ist das Aktualisieren der Datenbank. Das heißt, es nimmt den aktuellen Datenbankwert und gibt einen neuen zurück. Wir haben auch so etwas wie ein Abonnement - ein Analogon von Anfragen im Backend. Das heißt, dies sind einige reaktive Abfragen, die wir an diese Datenbank senden können. Diese reaktiven Anfragen schließen wir uns anschließend der Ansicht an. Im Falle einer Reaktion scheinen wir vollständig neu zu zeichnen, und wenn sich das Ergebnis dieser Anfrage geändert hat, ist dies praktisch.
Die Reaktion ist bei uns nur irgendwo ganz am Ende vorhanden, und im Allgemeinen ist die Architektur in keiner Weise damit verbunden. Es sieht ungefähr so aus:

Hier wird hinzugefügt, was zum Beispiel in Redux-s fehlt.
Zunächst trennen wir die Effekte. Die Frontend-Anwendung ist nicht eigenständig. Er hat ein bestimmtes Backend - eine Art "Quelle der Wahrheit". Die Anwendung muss dort ständig etwas schreiben und etwas von dort lesen. Schlimmer noch, wenn er mehrere Backends hat, an die es gehen sollte. In der einfachsten Implementierung könnte dies direkt im Action Creater erfolgen - in Ihrem Controller, aber das ist schlecht. Daher führen die Jungs von Re-Frame eine zusätzliche Indirektionsebene ein: Eine bestimmte Datenstruktur fliegt aus dem Controller heraus, was besagt, was zu tun ist. Und dieser Beitrag hat einen eigenen Handler, der die Drecksarbeit erledigt. Dies ist eine sehr wichtige Einführung, auf die wir später noch eingehen werden.
Es ist auch wichtig (manchmal vergessen sie es) - einige grundlegende Fakten sollten in der Basis sein. Alles andere kann aus der Datenbank entfernt werden - und Abfragen tun dies normalerweise, sie transformieren die Daten - sie fügen keine neuen Informationen hinzu, sondern strukturieren die vorhandenen korrekt. Wir brauchen diese Abfrage. In Redux bietet dies meiner Meinung nach jetzt eine erneute Auswahl, und in Re-Frame haben wir es sofort (eingebaut).
Schauen Sie sich unser Architekturdiagramm an. Wir haben ein kleines Backend (im Stil von Web 2.0) mit einer Basis-, Controller- und Ansicht reproduziert. Das einzige, was hinzugefügt wird, ist Reaktivität. Dies ist MVC sehr ähnlich, außer dass sich alles an einem Ort befindet. Sobald die frühen MVCs für jedes Widget ein eigenes Modell erstellt haben, ist hier alles in einer Basis zusammengefasst. Im Prinzip können Sie über den Effekt vom Controller aus mit dem Backend synchronisieren. Sie können ein allgemeineres Erscheinungsbild erstellen, sodass die Datenbank wie ein Proxy für das Backend funktioniert. Es gibt sogar eine Art generischen Algorithmus: Sie schreiben in Ihre lokale Datenbank und diese wird mit der Hauptdatenbank synchronisiert.
In den meisten Fällen ist die Basis nur eine Art Objekt, in das wir etwas in Redux schreiben. Aber im Prinzip kann man sich vorstellen, dass es sich weiter zu einer vollwertigen Datenbank mit einer reichen Abfragesprache entwickeln wird. Vielleicht mit einer Art generischer Synchronisation. Zum Beispiel gibt es datomic - eine logische Datenbank mit drei Speichern, die direkt im Browser ausgeführt wird. Sie nehmen es auf und legen Ihren gesamten Staat dort ab. Datomic hat eine ziemlich umfangreiche Abfragesprache, die in ihrer Leistung mit SQL vergleichbar ist und sogar irgendwo gewinnt. Ein weiteres Beispiel ist Google Lovefield geschrieben. Alles wird sich irgendwo hin bewegen.
Als nächstes werde ich erklären, warum wir ein reaktives Abonnement benötigen.
Jetzt bekommen wir die erste naive Wahrnehmung - wir haben den Benutzer aus dem Backend, haben ihn in die Datenbank gestellt und müssen ihn dann zeichnen. Zum Zeitpunkt des Renderns passiert eine Menge bestimmter Logik, aber wir mischen dies mit dem Rendern und der Ansicht. Wenn wir diesen Benutzer sofort rendern, erhalten wir ein großes, kniffliges Stück, das etwas mit dem virtuellen DOM und etwas anderem macht. Und es ist gemischt mit dem logischen Modell unserer Sichtweise.
Ein sehr wichtiges Konzept, das verstanden werden muss: Aufgrund der Komplexität der Benutzeroberfläche muss es auch modelliert werden. Es ist notwendig zu trennen, wie es gezeichnet wird (wie es erscheint), von seinem logischen Modell. Dann ist das logische Modell stabiler. Sie können es nicht mit der Abhängigkeit von einem bestimmten Framework belasten - Angular, React oder VueJS. Ein Modell ist der übliche erstklassige Bürger in Ihrer Laufzeit. Idealerweise, wenn es sich nur um einige Daten und eine Reihe von Funktionen darüber handelt.

Das heißt, aus dem Backend-Modell (Objekt) können wir ein Ansichtsmodell erhalten, in dem wir das logische Modell ohne Verwendung eines Renderings neu erstellen können. Wenn es eine Art Menü oder ähnliches gibt, kann dies alles im Ansichtsmodell erfolgen.
Warum?
Warum machen wir das alle?
Ich habe gute UI-Tests nur gesehen, wenn 10 Tester beschäftigt sind.
Normalerweise gibt es keine UI-Tests. Daher versuchen wir, diese Logik aus den Komponenten im Ansichtsmodell herauszuschieben. Das Fehlen von Tests ist ein sehr schlechtes Zeichen dafür, dass dort etwas nicht stimmt, irgendwie ist alles schlecht strukturiert.
Warum ist die Benutzeroberfläche schwer zu testen? Warum haben die Jungs im Backend gelernt, wie man ihren Code testet, eine enorme Abdeckung bietet und es wirklich hilft, mit dem Backend-Code zu leben? Warum ist die Benutzeroberfläche falsch? Höchstwahrscheinlich machen wir etwas falsch. Und alles, was ich oben beschrieben habe, hat uns tatsächlich in Richtung Testbarkeit bewegt.
Wie machen wir Tests?
Wenn Sie genau hinschauen, ist der Teil unserer Architektur, der den Controller, das Abonnement und die Datenbank enthält, nicht einmal mit JS verbunden. Das heißt, dies ist eine Art Modell, das einfach mit Datenstrukturen arbeitet: Wir fügen sie irgendwo hinzu, transformieren sie irgendwie und nehmen die Abfrage heraus. Durch Effekte werden wir von der Interaktion mit der Außenwelt getrennt. Und dieses Stück ist voll tragbar. Es kann im sogenannten cljc geschrieben werden - dies ist eine gemeinsame Teilmenge zwischen Clojure Script und Clojure, die sich dort und dort gleich verhält. Wir können dieses Stück einfach aus dem Frontend herausschneiden und in die JVM einfügen - wo das Backend lebt. Dann können wir einen weiteren Effekt in die JVM schreiben, der direkt auf den Endpunkt trifft - er zieht den Router ohne Konvertierung, Analyse usw. von http-Strings usw.
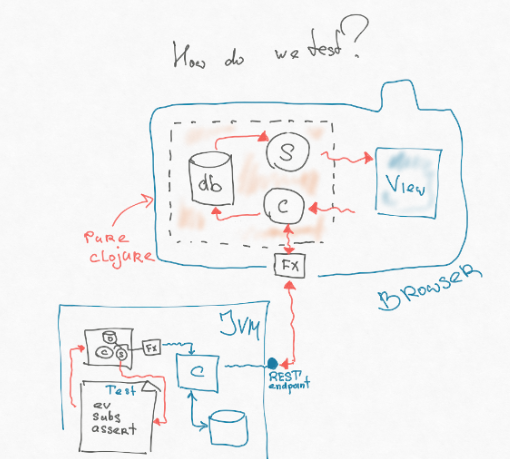
Als Ergebnis können wir einen sehr einfachen Test schreiben - den gleichen Funktionsintegraltest, den die Jungs im Backend schreiben. Wir werfen ein bestimmtes Ereignis aus, es löst einen Effekt aus, der direkt auf den Endpunkt im Backend trifft. Er gibt uns etwas zurück, legt es in der Datenbank ab, berechnet das Abonnement und im Abonnement liegt eine logische Ansicht (wir setzen die Benutzeroberflächenlogik dort auf das Maximum). Wir behaupten diese Ansicht.
Somit können wir 80% des Codes im Backend testen, während uns alle Backend-Entwicklungstools zur Verfügung stehen. Mithilfe von Vorrichtungen oder einigen Fabriken können wir eine bestimmte Situation in der Datenbank neu erstellen.
Zum Beispiel haben wir einen neuen Patienten oder etwas wird nicht bezahlt usw. Wir können eine Reihe möglicher Kombinationen durchgehen.
Somit können wir uns mit dem zweiten Problem befassen - mit einem verteilten System. Weil der Vertrag zwischen den Systemen genau der Hauptschmerzpunkt ist, weil dies zwei verschiedene Laufzeiten sind, zwei verschiedene Systeme: Das Backend hat etwas geändert und etwas ist an unserem Frontend kaputt gegangen (Sie können nicht sicher sein, dass dies nicht passieren wird).
Demonstration
So sieht es in der Praxis aus. Dies ist ein Backend-Helfer, der die Basis geräumt und eine kleine Welt hineingeschrieben hat:
Als nächstes werfen wir das Abonnement:

Normalerweise definiert die URL die Seite vollständig und ein Ereignis wird ausgelöst - Sie befinden sich jetzt auf einer solchen Seite mit einer Reihe von Parametern. Hier gingen wir in einen neuen Workflow und unser Abonnement kehrte zurück:

Hinter den Kulissen ging er zur Basis, holte etwas und legte es in unsere UI-Basis. Das Abonnement hat funktioniert und daraus das logische Ansichtsmodell abgeleitet.
Wir haben es initialisiert. Und hier ist unser logisches Modell:

Auch ohne einen Blick auf die Benutzeroberfläche zu werfen, können wir erraten, was nach diesem Modell gezeichnet wird: Es werden einige Warnungen angezeigt, einige Informationen über den Patienten, Begegnungen und eine Reihe von Links werden angezeigt (dies ist ein Workflow-Widget, das die Rezeption leitet in bestimmten Schritten, wenn der Patient ankommt).
Hier kommen wir auf eine komplexere Welt. Sie haben einige Zahlungen geleistet und auch nach der Initialisierung getestet:
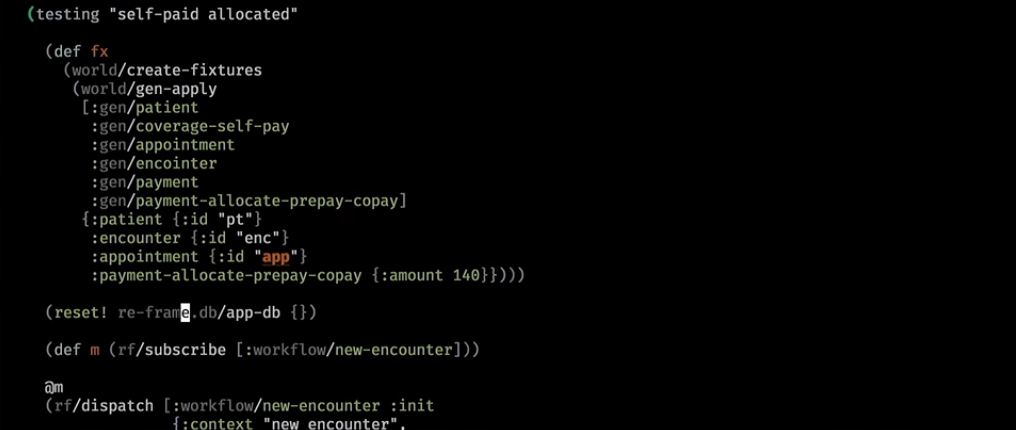
Wenn er den Besuch bereits bezahlt hat, wird dies in der Benutzeroberfläche angezeigt:

Führen Sie Tests aus, die auf CI eingestellt sind. Die Synchronisation zwischen dem Backend und dem Frontend wird durch Tests garantiert und nicht ehrlich.
Zurück zum Backend?
Wir haben die Tests vor sechs Monaten vorgestellt und es hat uns sehr gut gefallen. Das Problem der unscharfen Logik bleibt bestehen. Je intelligenter sich eine Geschäftsanwendung verhält, desto mehr Informationen werden für einige Schritte benötigt. Wenn Sie versuchen, dort einen Workflow aus der realen Welt auszuführen, werden Abhängigkeiten von allem angezeigt: Für jede Benutzeroberfläche müssen Sie etwas aus verschiedenen Teilen der Datenbank im Backend abrufen. Wenn wir Buchhaltungssysteme schreiben, kann dies nicht vermieden werden. Infolgedessen ist, wie gesagt, die gesamte Logik verschmiert.
Mit Hilfe solcher Tests können wir zumindest in der Entwicklungszeit - zum Zeitpunkt der Entwicklung - die Illusion erzeugen, dass wir wie in den alten Tagen von Web 2.0 in einer Laufzeit auf dem Server sitzen und alles komfortabel ist.
Eine andere verrückte Idee kam auf (sie wurde noch nicht umgesetzt). Warum nicht diesen Teil auf das Backend absenken? Warum nicht jetzt ganz von der verteilten Anwendung wegkommen? Lassen Sie dieses Abonnement und unser Ansichtsmodell im Backend generieren? Dort steht die Basis zur Verfügung, alles ist synchron. Alles ist einfach und klar.
Das erste Plus, das ich darin sehe, ist, dass wir die Kontrolle an einem Ort haben werden. Wir vereinfachen einfach alles sofort im Vergleich zu unserer verteilten Anwendung. Tests werden einfach, doppelte Validierungen verschwinden. Die modische Welt interaktiver Mehrbenutzersysteme öffnet sich (wenn zwei Benutzer dasselbe Formular aufrufen, erzählen wir ihnen davon; sie können es gleichzeitig bearbeiten).
Ein interessantes Feature erscheint: Wenn wir zum Backend und zur Aussicht auf die Sitzung gehen, können wir verstehen, wer sich derzeit im System befindet und was er tut. Dies ist ein bisschen wie bei einem Spielentwickler, bei dem die Server so funktionieren. Dort lebt die Welt auf dem Server und das Frontend rendert nur. Infolgedessen können wir einen bestimmten Thin Client bekommen.
Auf der anderen Seite schafft dies eine Herausforderung. Wir benötigen einen Statefull-Server, auf dem diese Sitzungen ausgeführt werden. Wenn wir mehrere App-Server haben, muss die Last irgendwie richtig verteilt oder die Sitzung repliziert werden. Es besteht jedoch der Verdacht, dass dieses Problem geringer ist als die Anzahl der Pluspunkte, die wir erhalten.
Daher kehre ich zum Hauptslogan zurück: Es gibt viele Arten von Anwendungen, die nicht verteilt geschrieben werden können, um die Komplexität zu verringern. Und Sie können die Effizienz um ein Vielfaches steigern, wenn Sie die grundlegenden Postulate, auf die wir uns bei der Entwicklung verlassen haben, noch einmal überarbeiten.
Wenn Ihnen der Bericht gefallen hat, achten Sie darauf: Am 24. und 25. November findet in Moskau ein neues HolyJS statt, und es wird dort auch viele interessante Dinge geben. Bereits bekannte Informationen zum Programm finden Sie auf der Website. Dort können Tickets gekauft werden.