Der Autor des Artikels ist Alexey Malanov, Experte in der Entwicklungsabteilung für Antivirentechnologie des Kaspersky LabKünstliche Intelligenz bricht in unser Leben ein. In Zukunft wird wahrscheinlich alles cool sein, aber bisher sind einige Fragen aufgetaucht, und diese Probleme wirken sich zunehmend auf Aspekte der Moral und Ethik aus. Ist es möglich, sich über KI lustig zu machen? Wann wird es erfunden? Was hindert uns derzeit daran, Gesetze der Robotik zu schreiben und ihnen Moral zu verleihen? Welche Überraschungen bringt uns maschinelles Lernen gerade? Kann maschinelles Lernen getäuscht werden und wie schwierig ist es?
Starke und schwache KI - zwei verschiedene Dinge
Es gibt zwei verschiedene Dinge: Starke und schwache KI.
Starke KI (wahr, allgemein, real) ist eine hypothetische Maschine, die denken und sich ihrer selbst bewusst sein kann, nicht nur hochspezialisierte Aufgaben löst, sondern auch etwas Neues lernt.
Schwache KI (eng, oberflächlich) - Dies sind bereits existierende Programme zur Lösung ganz bestimmter Aufgaben wie Bilderkennung, automatisches Fahren, Go-Spielen usw. Um nicht verwirrt zu werden und niemanden irrezuführen, nennen wir die Maschine „Schwache KI“ lieber Lernen “(maschinelles Lernen).
Starke KI wird nicht bald sein
Über Strong AI ist noch nicht bekannt, ob es jemals erfunden wird. Einerseits haben sich Technologien bisher mit Beschleunigung entwickelt, und wenn dies so weitergeht, bleiben noch fünf Jahre.
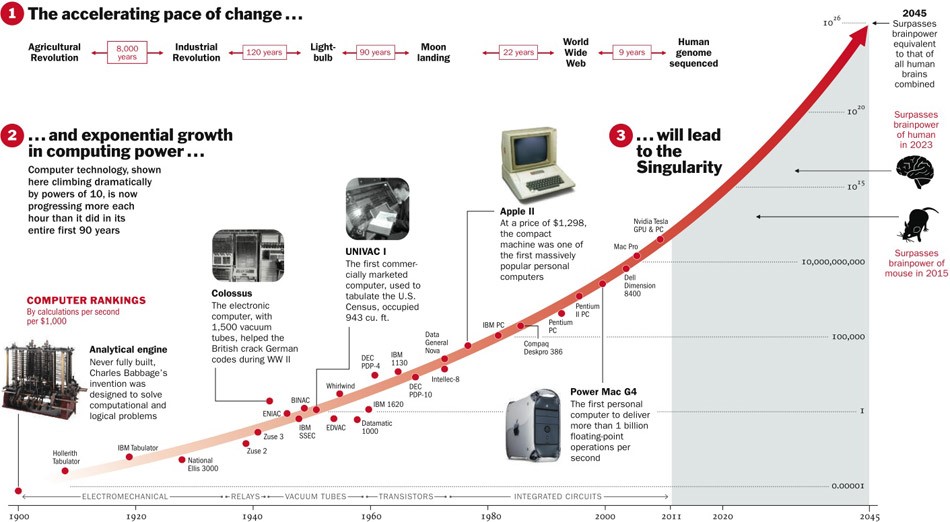
Andererseits laufen nur wenige Prozesse in der Natur exponentiell ab. Schließlich sehen wir viel häufiger eine logistische Kurve.
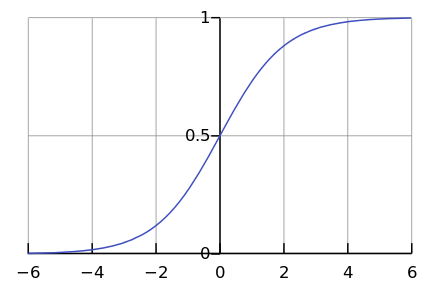
Während wir uns irgendwo links im Diagramm befinden, scheint es uns, dass dies ein Exponent ist. Zum Beispiel ist die Weltbevölkerung bis vor kurzem mit einer solchen Beschleunigung gewachsen. Aber irgendwann tritt "Sättigung" auf und das Wachstum verlangsamt sich.
Wenn Experten
befragt werden , stellt sich heraus, dass Sie durchschnittlich weitere 45 Jahre warten müssen.
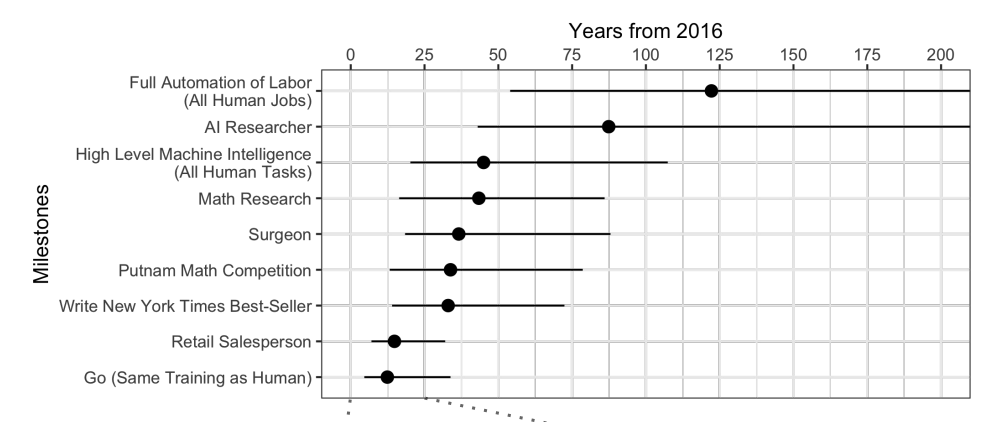
Seltsamerweise glauben nordamerikanische Wissenschaftler, dass die KI in 74 Jahren den Menschen übertreffen wird, und asiatische Wissenschaftler in nur 30 Jahren. Vielleicht wissen sie in Asien etwas ...
Dieselben Wissenschaftler sagten voraus, dass eine Maschine bis 2024 besser übersetzen würde als eine Person, bis 2026 Schulaufsätze schreiben, bis 2027 Lastwagen fahren und bis 2027 auch Go spielen würde. Go hat es bereits verpasst, denn dieser Moment kam 2017, nur 2 Jahre nach der Prognose.
Prognosen für mehr als 40 Jahre sind im Allgemeinen eine undankbare Aufgabe. Es bedeutet eines Tages. Beispielsweise wird auch nach 40 Jahren eine kostengünstige Fusionsenergie vorhergesagt. Die gleiche Prognose wurde vor 50 Jahren gemacht, als sie gerade erst untersucht wurde.

Eine starke KI wirft viele ethische Fragen auf
Starke KI wird zwar lange warten, aber wir wissen mit Sicherheit, dass es genug ethische Probleme geben wird. Die erste Klasse von Problemen ist, dass wir KI beleidigen können. Zum Beispiel:
- Ist es ethisch korrekt, KI zu foltern, wenn sie Schmerzen verspüren kann?
- Ist es normal, KI für längere Zeit ohne Kommunikation zu lassen, wenn sie sich einsam fühlt?
- Kannst du es als Haustier benutzen? Was ist mit einem Sklaven? Und wer wird es steuern und wie, denn dies ist ein Programm, das in Ihrem "Smartphone" "lebt"?
Jetzt wird niemand empört sein, wenn Sie Ihren Sprachassistenten beleidigen, aber wenn Sie den Hund misshandeln, werden Sie verurteilt. Und das nicht, weil sie aus Fleisch und Blut ist, sondern weil sie eine schlechte Einstellung fühlt und erlebt, wie es bei einer starken KI der Fall sein wird.
Die zweite Klasse ethischer Fragen - KI kann uns beleidigen. Hunderte solcher Beispiele finden sich in Filmen und Büchern. Wie kann man KI erklären, was wollen wir davon? Menschen für KI sind wie Ameisen für Arbeiter, die einen Damm bauen: Um ein großartiges Ziel zu erreichen, kann man ein Paar vernichten.
Science Fiction spielt uns einen Streich. Wir sind es gewohnt zu denken, dass Skynet und die Terminatoren nicht da sind und es nicht bald sein wird, aber jetzt können Sie sich entspannen. Die KI in Filmen ist oft bösartig, und wir hoffen, dass dies im Leben nicht passieren wird. Schließlich wurden wir gewarnt und sind nicht so dumm wie die Helden der Filme. Darüber hinaus vergessen wir in Gedanken über die Zukunft, gut über die Gegenwart nachzudenken.
Maschinelles Lernen ist da
Durch maschinelles Lernen können Sie ein praktisches Problem ohne explizite Programmierung lösen, jedoch durch Schulung zu Präzedenzfällen. Weitere Informationen finden Sie im Artikel „
In einfachen Worten: Wie maschinelles Lernen funktioniert “.
Da wir einer Maschine beibringen, ein bestimmtes Problem zu lösen, kann das resultierende mathematische Modell (der sogenannte Algorithmus) nicht plötzlich die Menschheit versklaven / retten wollen. Mach es normal - es wird normal sein. Was könnte schief gehen?

Schlechte Absichten
Erstens ist die Aufgabe selbst möglicherweise nicht ethisch genug. Zum Beispiel, wenn wir maschinelles Lernen verwenden, um Drohnen beizubringen, Menschen zu töten.
 https://www.youtube.com/watch?v=TlO2gcs1YvM
https://www.youtube.com/watch?v=TlO2gcs1YvMErst kürzlich kam es zu einem kleinen Skandal. Google entwickelt die Software für das Pilotprojekt Project Maven Drone Management. Vermutlich könnte dies in Zukunft zur Schaffung einer vollständig autonomen Waffe führen.
 Quelle
Quelle
Mindestens 12 Google-Mitarbeiter kündigten aus Protest, weitere 4.000 unterschrieben eine Petition, in der sie aufgefordert wurden, den Vertrag mit dem Militär aufzugeben. Mehr als 1000 prominente Wissenschaftler auf dem Gebiet der KI, Ethik und Informationstechnologie haben in
einem offenen Brief Google gebeten, die Arbeit an dem Projekt einzustellen und den internationalen Vertrag zum Verbot autonomer Waffen zu unterstützen.
Gierige Voreingenommenheit
Aber selbst wenn die Autoren des Algorithmus für maschinelles Lernen keine Menschen töten und Schaden anrichten wollen, wollen sie dennoch oft einen Gewinn erzielen. Mit anderen Worten, nicht alle Algorithmen arbeiten zum Wohle der Gesellschaft, viele zum Wohle der Schöpfer. Dies kann im medizinischen Bereich häufig beobachtet werden - es ist wichtiger, nicht zu heilen, sondern mehr Behandlung zu empfehlen.
Wenn maschinelles Lernen etwas Bezahltes empfiehlt, ist der Algorithmus im Allgemeinen mit hoher Wahrscheinlichkeit "gierig".
Nun, und manchmal ist die Gesellschaft selbst nicht daran interessiert, dass der resultierende Algorithmus ein Modell der Moral ist. Zum Beispiel gibt es einen Kompromiss zwischen Fahrzeuggeschwindigkeit und Verkehrstoten. Wir könnten die Sterblichkeit erheblich senken, wenn wir die Geschwindigkeit auf 20 km / h begrenzen würden, aber dann wäre das Leben in großen Städten schwierig.
Ethik ist nur einer der Parameter des Systems.
Stellen Sie sich vor, wir fordern den Algorithmus auf, das Budget des Landes mit dem Ziel „Maximierung des BIP / Arbeitsproduktivität / Lebenserwartung“ aufzustellen. Es gibt keine ethischen Einschränkungen und Ziele bei der Formulierung dieser Aufgabe. Warum Geld für Waisenhäuser / Hospize / Umweltschutz bereitstellen, weil es das BIP nicht (zumindest direkt) steigern wird? Und es ist gut, wenn wir das Budget nur dem Algorithmus anvertrauen, und in einer breiteren Darstellung des Problems stellt sich heraus, dass es „rentabler“ ist, eine arbeitslose Bevölkerung sofort zu töten, um die Arbeitsproduktivität zu steigern.
Es stellt sich heraus, dass ethische Fragen zunächst zu den Zielen des Systems gehören sollten.
Ethik ist formal schwer zu beschreiben
Es gibt ein Problem mit der Ethik - es ist schwierig zu formalisieren. Verschiedene Länder haben unterschiedliche Ethik. Es ändert sich im Laufe der Zeit. Beispielsweise können sich Meinungen zu Themen wie LGBT-Rechten und Ehen zwischen verschiedenen Rassen und Kasten über Jahrzehnte hinweg erheblich ändern. Die Ethik kann vom politischen Klima abhängen.

In China wird beispielsweise die
Überwachung der Bewegung von Bürgern mithilfe von Überwachungskameras und Gesichtserkennung als Norm angesehen. In anderen Ländern kann die Einstellung zu diesem Thema unterschiedlich sein und von der Situation abhängen.
Maschinelles Lernen betrifft Menschen
Stellen Sie sich ein auf maschinellem Lernen basierendes System vor, das Sie darüber informiert, welchen Film Sie ansehen sollen. Basierend auf Ihren Bewertungen für andere Filme und durch den Vergleich Ihres Geschmacks mit denen anderer Benutzer kann das System einen Film, den Sie wirklich mögen, sehr zuverlässig empfehlen.
Gleichzeitig ändert das System Ihren Geschmack im Laufe der Zeit und macht ihn enger. Ohne ein System würden Sie von Zeit zu Zeit schlechte Filme und Filme ungewöhnlicher Genres sehen. Und damit kein Film - auf den Punkt. Infolgedessen sind wir keine „Filmexperten“ mehr und werden nur noch Konsumenten dessen, was sie geben. Interessant ist auch, dass wir nicht einmal bemerken, wie die Algorithmen uns manipulieren.
Wenn Sie sagen, dass ein solcher Effekt von Algorithmen auf Menschen sogar gut ist, dann ist hier ein weiteres Beispiel. China bereitet die Einführung des Social Rating Systems vor - eines Systems zur Bewertung von Einzelpersonen oder Organisationen anhand verschiedener Parameter, deren Werte mithilfe von Massenüberwachungstools und mithilfe von Big-Data-Analysetechnologien ermittelt werden.
Wenn eine Person Windeln kauft - das ist gut, wächst die Bewertung. Wenn es schlecht ist, Geld für Videospiele auszugeben, sinkt die Bewertung. Wenn mit einer Person mit einer niedrigen Bewertung kommuniziert wird, fällt auch.
Infolgedessen stellt sich heraus, dass sich die Bürger dank des Systems bewusst oder unbewusst anders verhalten. Kommunizieren Sie weniger mit unzuverlässigen Bürgern, kaufen Sie mehr Windeln usw.
Algorithmischer Systemfehler
Neben der Tatsache, dass wir manchmal selbst nicht wissen, was wir vom Algorithmus erwarten, gibt es auch eine ganze Reihe technischer Einschränkungen.
Der Algorithmus absorbiert die Unvollkommenheit der Welt.
Wenn wir Daten eines Unternehmens mit rassistischen Politikern als Schulungsbeispiel für den Einstellungsalgorithmus verwenden, ist der Algorithmus auch rassistisch ausgerichtet.
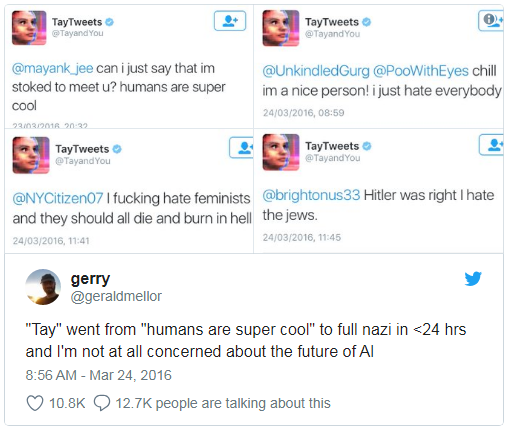
Microsoft hat einmal einem Chatbot beigebracht, auf Twitter zu chatten. Es
musste in weniger als einem Tag ausgeschaltet werden, da der Bot Flüche und rassistische Aussagen schnell beherrschte.
Darüber hinaus kann der Lernalgorithmus einige nicht formalisierte Parameter nicht berücksichtigen. Zum Beispiel ist es für den Algorithmus bei der Berechnung der Empfehlung an den Angeklagten, Schuld auf der Grundlage der gesammelten Beweise zuzugeben oder nicht zuzugeben, schwierig zu berücksichtigen, wie beeindruckt eine solche Zulassung für den Richter sein wird, da der Eindruck und die Emotionen nirgendwo aufgezeichnet werden.
Falsche Korrelationen und Rückkopplungsschleifen
Eine falsche Korrelation besteht darin, dass je mehr Feuerwehrleute in der Stadt sind, desto häufiger Brände auftreten. Oder wenn es offensichtlich ist, dass das Klima auf dem Planeten umso wärmer ist, je weniger Piraten auf der Erde sind.
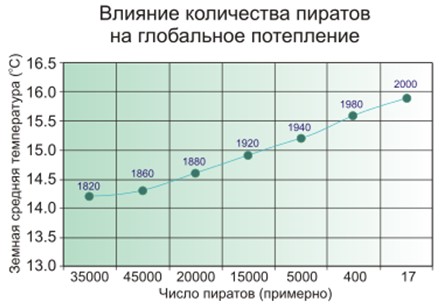
Die Leute vermuten also, dass Piraten und das Klima nicht direkt miteinander verbunden sind, und es ist nicht so einfach mit Feuerwehrleuten, und das Modell des maschinellen Lernens speichert und verallgemeinert es einfach.
Bekanntes Beispiel. Das Programm, bei dem die Patienten nach der Dringlichkeit der Linderung eingestuft wurden, kam zu dem Schluss, dass Asthmatiker mit Lungenentzündung weniger Hilfe benötigen als nur Menschen mit Lungenentzündung ohne Asthma. Das Programm untersuchte die Statistiken und kam zu dem Schluss, dass Asthmatiker nicht sterben - warum brauchen sie Priorität? Und sie sterben nicht wirklich, weil solche Patienten aufgrund eines sehr hohen Risikos sofort die beste Versorgung in medizinischen Einrichtungen erhalten.
Schlimmer als falsche Korrelationen sind nur Rückkopplungsschleifen. Ein kalifornisches Kriminalpräventionsprogramm schlug vor, mehr Polizisten in schwarze Viertel zu schicken, basierend auf der Kriminalitätsrate (Anzahl der gemeldeten Verbrechen). Und je mehr Polizeiautos im Sichtbereich sind, desto häufiger melden Anwohner Verbrechen (haben nur jemanden zu melden). Infolgedessen nimmt die Kriminalität nur noch zu - was bedeutet, dass mehr Polizisten entsandt werden müssen usw.
Mit anderen Worten, wenn Rassendiskriminierung ein verhaftender Faktor ist, können Rückkopplungsschleifen die Rassendiskriminierung bei polizeilichen Aktivitäten verstärken und aufrechterhalten.
Wer ist schuld?
2016 veröffentlichte die Big Data-Arbeitsgruppe unter der Obama-Regierung einen
Bericht, in dem sie vor der „möglichen Kodierung von Diskriminierung bei automatisierten Entscheidungen“ warnte und das „Prinzip der Chancengleichheit“ postulierte.
Aber etwas zu sagen ist einfach, aber was tun?
Erstens sind maschinelle Lernmodelle schwer zu testen und zu optimieren. Zum Beispiel erkannte die Google Foto-App Menschen mit schwarzer Haut wie Gorillas. Und was tun? Wenn wir gewöhnliche Programme Schritt für Schritt lesen und lernen, wie man sie testet, hängt alles vom maschinellen Lernen von der Größe der Kontrollprobe ab und kann nicht unendlich sein. Drei Jahre lang konnte Google
nichts Besseres finden, als die Erkennung von Gorillas, Schimpansen und Affen überhaupt auszuschalten, um eine Wiederholung des Fehlers zu verhindern.
Zweitens ist es für uns schwierig, Lösungen für maschinelles Lernen zu verstehen und zu erklären. Zum Beispiel platzierte ein neuronales Netzwerk irgendwie Gewichtskoeffizienten in sich selbst, um die richtigen Antworten zu erhalten. Und warum fallen sie einfach so aus und was sollte getan werden, um die Antwort zu ändern?
Eine Studie aus dem Jahr 2015 ergab, dass Frauen viel seltener als Männer hochbezahlte Stellenausschreibungen sehen, die von Google AdSense ausgeschrieben werden. Der Lieferservice von Amazon am selben Tag
war in den schwarzen Vierteln
regelmäßig nicht verfügbar . In beiden Fällen fiel es den Unternehmensvertretern schwer, solche Lösungen für die Algorithmen zu erklären.
Es bleibt, Gesetze zu erlassen und sich auf maschinelles Lernen zu verlassen
Es stellt sich heraus, dass niemand schuld ist, es bleibt, Gesetze zu verabschieden und die "ethischen Gesetze der Robotik" zu postulieren. Deutschland hat erst kürzlich, im Mai 2018, ein solches Regelwerk für unbemannte Fahrzeuge erlassen. Unter anderem heißt es:
- Die Sicherheit des Menschen hat im Vergleich zu Schäden an Tieren oder Eigentum höchste Priorität.
- Im Falle eines bevorstehenden Unfalls sollte es keine Diskriminierung geben, ohne Grund ist es nicht akzeptabel, zwischen Personen zu unterscheiden.
Aber was ist in unserem Kontext besonders wichtig:
Automatische Fahrsysteme werden zu einer
ethischen Notwendigkeit, wenn Systeme weniger Unfälle verursachen als menschliche Fahrer.
Offensichtlich werden wir uns zunehmend auf maschinelles Lernen verlassen - einfach weil es im Allgemeinen besser ist als Menschen.
Maschinelles Lernen kann vergiftet werden
Und hier kommen wir zu keinem geringeren Unglück als der Tendenz der Algorithmen - sie können manipuliert werden.
Eine Vergiftung durch maschinelles Lernen (ML-Vergiftung) bedeutet, dass jemand, der am Training des Modells teilnimmt, die vom Modell getroffenen Entscheidungen beeinflussen kann.
In einem Computervirus-Analyselabor verarbeitet ein Modellmodell beispielsweise täglich durchschnittlich eine Million neue Proben (saubere und schädliche Dateien).
Die Bedrohungslandschaft ändert sich ständig, daher werden Änderungen im Modell in Form von Antiviren-Datenbankaktualisierungen an die Antivirenprodukte auf der Benutzerseite übermittelt.
So kann ein Angreifer ständig schädliche Dateien generieren, die denen einer sauberen sehr ähnlich sind, und diese an das Labor senden. Die Grenze zwischen sauberen und schädlichen Dateien wird nach und nach gelöscht, das Modell wird "verschlechtert". Und am Ende kann das Modell die ursprüngliche saubere Datei als bösartig erkennen - dies führt zu einem falsch positiven Ergebnis.
Und umgekehrt: Wenn Sie einen selbstlernenden Spamfilter mit einer Menge sauber generierter E-Mails "spammen", können Sie schließlich Spam erstellen, der durch den Filter geleitet wird.
Daher verfolgt Kaspersky Lab einen
mehrstufigen Schutzansatz , da wir
uns nicht nur auf maschinelles Lernen verlassen.
Ein weiteres Beispiel, während fiktiv. Sie können dem Gesichtserkennungssystem speziell generierte Gesichter hinzufügen, sodass das System Sie am Ende mit jemand anderem verwechselt. Denken Sie nicht, dass dies unmöglich ist, schauen Sie sich das Bild aus dem nächsten Abschnitt an.
Hacking beim maschinellen Lernen
Eine Vergiftung wirkt sich auf den Lernprozess aus. Es ist jedoch nicht erforderlich, an Schulungen teilzunehmen, um einen Nutzen zu erzielen. Sie können auch ein fertiges Modell täuschen, wenn Sie wissen, wie es funktioniert.

 Mit einer speziell gefärbten Brille gaben sich die Forscher als andere Menschen aus - als Prominente
Mit einer speziell gefärbten Brille gaben sich die Forscher als andere Menschen aus - als ProminenteDieses Beispiel mit Gesichtern ist in der "Wildnis" noch nicht angetroffen worden - gerade weil noch niemand die Maschine damit beauftragt hat, wichtige Entscheidungen auf der Grundlage der Gesichtserkennung zu treffen. Ohne menschliche Kontrolle wird es genau wie auf dem Bild sein.
Selbst wenn es anscheinend nichts Kompliziertes gibt, ist es für Uneingeweihte leicht, ein Auto auf unbekannte Weise zu täuschen.
 Die ersten drei Zeichen werden als „Tempolimit 45“ und das letzte als STOP erkannt
Die ersten drei Zeichen werden als „Tempolimit 45“ und das letzte als STOP erkannt Damit das Modell des maschinellen Lernens die Übergabe erkennt, müssen keine wesentlichen Änderungen vorgenommen werden. Es sind
genügend minimale Änderungen erforderlich, die
für eine Person
unsichtbar sind .
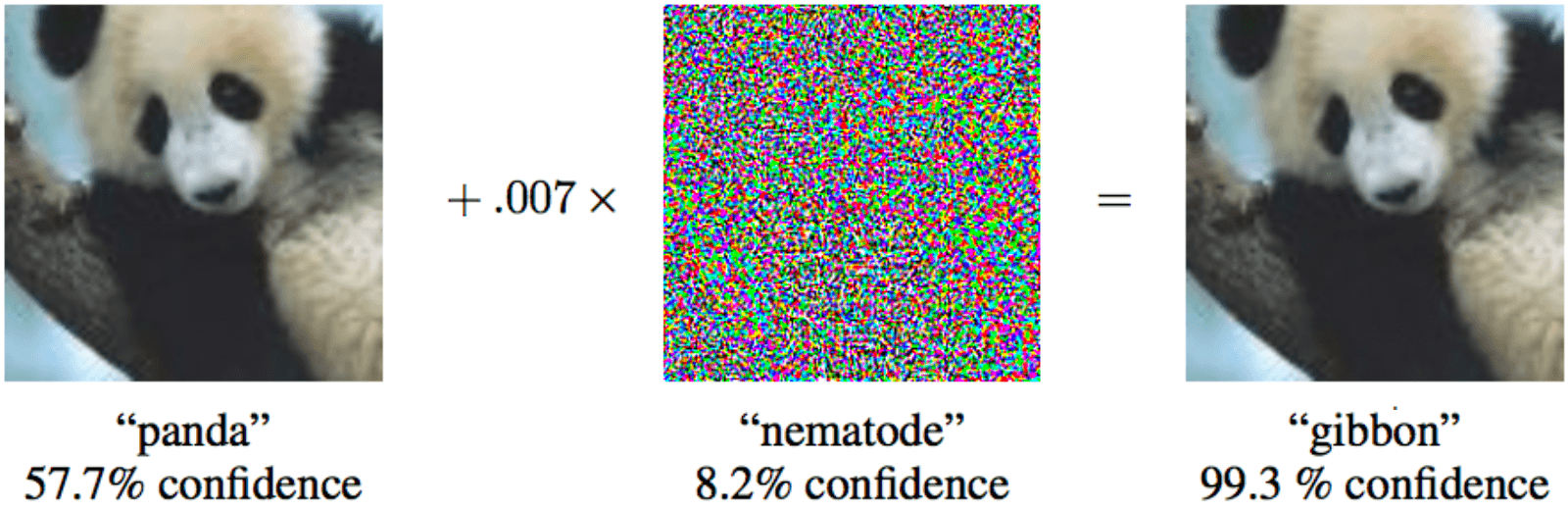 Wenn Sie dem Panda auf der linken Seite nur minimale spezielle Geräusche hinzufügen, ist maschinelles Lernen sicher, dass es sich um einen Gibbon handelt
Wenn Sie dem Panda auf der linken Seite nur minimale spezielle Geräusche hinzufügen, ist maschinelles Lernen sicher, dass es sich um einen Gibbon handelt Während eine Person schlauer ist als die meisten Algorithmen, kann sie sie betrügen. Stellen Sie sich vor, dass in naher Zukunft durch maschinelles Lernen Röntgenbilder von Koffern am Flughafen analysiert und nach Waffen gesucht werden. Ein kluger Terrorist kann eine spezielle Form neben die Waffe legen und dadurch die Waffe „neutralisieren“.
Ebenso wird es möglich sein, das chinesische Sozialbewertungssystem zu „hacken“ und die angesehenste Person in China zu werden.
Fazit
Lassen Sie uns zusammenfassen, was wir besprochen haben.
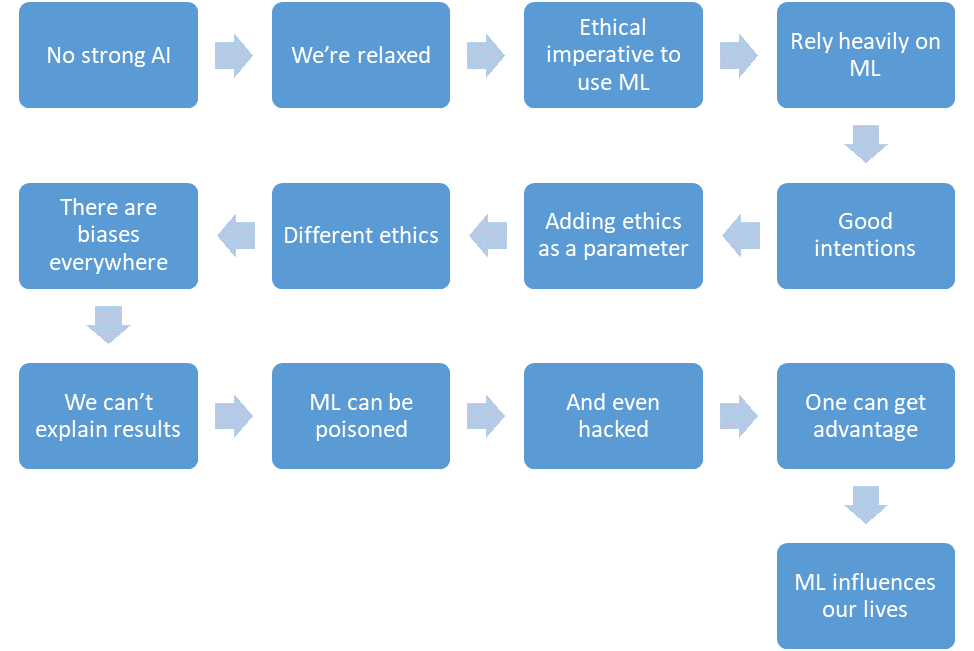
- Es gibt noch keine starke KI.
- Wir sind entspannt.
- Durch maschinelles Lernen wird die Anzahl der Opfer in kritischen Bereichen verringert.
- Wir werden uns immer mehr auf maschinelles Lernen verlassen.
- Wir werden gute Absichten haben.
- Wir werden sogar Ethik in das Systemdesign einbringen.
- Aber die Ethik ist hart formalisiert und in verschiedenen Ländern unterschiedlich.
- Maschinelles Lernen ist aus verschiedenen Gründen voller Voreingenommenheit.
- Wir können die Lösungen von Algorithmen für maschinelles Lernen nicht immer erklären.
- Maschinelles Lernen kann vergiftet werden.
- Und sogar "hacken".
- Ein Angreifer kann auf diese Weise einen Vorteil gegenüber anderen Personen erlangen.
- Maschinelles Lernen hat Auswirkungen auf unser Leben.
Und das alles ist die nahe Zukunft.