
Am 28. August kündigte die CNCF (Cloud Native Computing Foundation) hinter Kubernetes, Prometheus und anderen Open Source-Projekten für moderne Cloud-Anwendungen die Einführung eines neuen Produkts in ihrer Sandbox an -
TiKV .
Diese verteilte Transaktionsdatenbank mit Schlüsselwerten wurde als Ergänzung zu
TiDB entwickelt , einem verteilten Datenbankverwaltungssystem, das OLTP- und OLAP-Funktionen bietet und Kompatibilität mit dem MySQL-Protokoll bietet. Aber lassen Sie uns nacheinander darüber sprechen.
TiDB als Elternteil
Beginnen wir mit dem „übergeordneten“ TiDB-Projekt der chinesischen Firma PingCAP Inc.

Die erste große öffentliche Veröffentlichung dieses DBMS - 1.0 -
fand vor weniger als einem Jahr statt. Die Hauptmerkmale sind „Hybridität“, die die Verarbeitung von Transaktions- und Analysedaten (Hybrid Transactional / Analytical Processing, HTAP) kombiniert, sowie die bereits erwähnte Kompatibilität mit dem MySQL-Protokoll. Ein vollständigeres Bild von TiDB ergibt sich, wenn andere - für neue DBMS bereits übliche - Funktionen erwähnt werden, wie horizontale Skalierbarkeit, hohe Verfügbarkeit und strikte ACID-Konformität.
Die allgemeine Architektur von TiDB ist wie folgt:
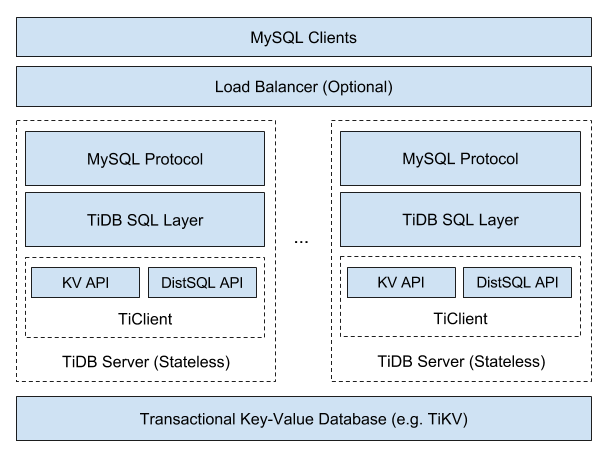
Da TiDB NoSQL-Skalierbarkeit und ACID-Garantien bietet, wird es als
NewSQL eingestuft . Die Autoren verbergen nicht die Tatsache, dass sie das Produkt unter der Inspiration anderer Vertreter von NewSQL erstellt haben:
Google Spanner und
F1 . Chinesische Entwickler bestanden jedoch auf "ihren Best Practices und Lösungen bei der Auswahl der Technologie". Insbesondere wählten sie einen Algorithmus zur Lösung von
Raft- Konsensproblemen (anstelle von
Paxos , das in Spanner verwendet wird),
RocksDB- Speicher (anstelle eines verteilten Dateisystems) und Go (und Rust) als Programmiersprache.
Viele Details zum TiDB-Gerät finden Sie im Bericht „
Wie wir TiDB bauen “ des Mitbegründers und CEO von PingCAP - Max Liu - und wir werden auf einige davon zurückkommen, die eng mit TiKV verwandt sind. TiDB-Quellcode wird unter der kostenlosen Apache-Lizenz v2 vertrieben. Zu den
Hauptnutzern zählen Lenovo, Meizu, die Bank of Beijing, die Industrial and Commercial Bank of China usw.
Was ist TiKV und welche Rolle spielt TiDB (und nicht nur) in der Welt?
TiKV-Architektur und -Funktionen
Kehren wir in einer etwas anderen Darstellung zur allgemeinen Architektur von TiDB zurück:

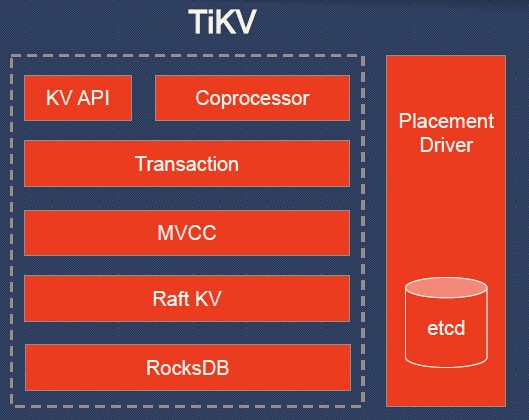
Sie können sehen, dass TiDB selbst SQL-Implementierung und MySQL * -Kompatibilität bietet, während der Rest der Arbeit dem TiKV-Cluster zugewiesen wird. Was ist das für ein "Rest der Arbeit"? Hier ist ein detaillierteres Diagramm:
* In zwei Bildern über die Kompatibilitätsebene mit MySQL in TiDB.Die Konvertierung von Tabellen in Schlüsselwerte erfolgt so, dass aus den Abfragen:
INSERT INTO user VALUES (1, "bob", "huang@pingcap.com"); INSERT INTO user VALUES (2, "tom", "tom@pingcap.com");
... es stellt sich heraus:

Indizes in TiDB sind gewöhnliche Paare, deren Werte eine Datenzeile angeben:

Erläuterungen zum TiKV-Schema:
- KV API - eine Reihe von Programmschnittstellen zum Schreiben / Lesen von Daten;
- Coprozessor - ein Coprozessor-Framework zur Unterstützung von verteiltem Computing (im Vergleich zu HBase);
- Transaktion - ein Transaktionsmodell ähnlich wie Google Percolator (Festschreibungsprotokoll in zwei Phasen; verwendet Zeitstempel-Allokator; siehe auch Vergleich mit Spanner );
- MVCC (MultiVersion Concurrency Control) zum Lesen ohne Sperren und ACID-Transaktionen (Daten sind mit Versionen versehen; Änderungen an der aktuellen Transaktion sind für andere Transaktionen erst zum Zeitpunkt des Commits sichtbar);
- Raft KV - der bereits erwähnte Raft-Algorithmus für horizontale Skalierung und Datenkonsistenz; Die Implementierung in Rust wird von etcd portiert (verifiziert durch umfangreiche Ausbeutung). Übrigens erklärten die Autoren von TiKV "einfache Skalierbarkeit auf über 100 TB Daten";
- RocksDB - lokale Speicherung vom Typ Schlüsselwert, auch in Großprojekten in der Produktion bereits etabliert (Facebook);
- Placement Driver - das „Gehirn“ des Clusters, das nach dem Konzept von Google Spanner erstellt wurde und für das Speichern von Metadaten zu den Regionen verantwortlich ist und die erforderliche Anzahl von Replikaten sowie die Lastverteilung (mithilfe von Raft) unterstützt.

Wenn wir die Verbindungen der Hauptkomponenten verallgemeinern, erhalten wir Folgendes:
- Jeder TiKV-Clusterknoten verfügt über ein oder mehrere Repositorys (RocksDB).
- Jedes Repository hat viele Regionen .
- Eine Region ist eine „Grundeinheit für die Bewegung von Schlüsselwertdaten“ und wird (unter Verwendung von Raft) auf viele Knoten repliziert. Solche Replikatsätze bilden Floßgruppen .
- Wie Sie sehen, ist der Placement-Treiber, der diesen Cluster verwaltet, selbst ein Cluster.
TiKV Installation und Test
Die TiKV-Codebasis ist hauptsächlich in Rust geschrieben, enthält jedoch auch mehrere Komponenten von Drittanbietern in anderen Sprachen (RocksDB in C ++ und gRPC in Go). Unter derselben kostenlosen Apache-Lizenz v2 verteilt.
Wie am Anfang des Artikels erwähnt, erschien TiKV zunächst als wichtiger Bestandteil von TiDB, kann heute jedoch sowohl innerhalb dieses DBMS als auch separat betrieben werden. (In jedem Fall erfordert der Betrieb jedoch einen in Go geschriebenen und als separate Komponente verteilten
Placement-Treiber .)
Die kürzeste
Anweisung zum
Starten von TiKV zusammen mit dem TiDB-DBMS erfordert Git, Docker (17.03+), Docker Compose (1.6.0+) und MySQL Client und umfasst Folgendes:
git clone https://github.com/pingcap/tidb-docker-compose.git cd tidb-docker-compose && docker-compose pull docker-compose up -d
Das Ergebnis dieser Befehle ist die Bereitstellung eines TiDB-Clusters, der standardmäßig aus den folgenden Komponenten besteht:
- 1 Kopie der tatsächlichen TiDB;
- 3 Kopien von TiKV;
- 3 Instanzen von Placement Driver;
- Prometheus und Grafana (zur Überwachung und Grafik) ;
- 2 Kopien (Master + Slave) von TiSpark (Schicht zum Starten von Apache Spark auf TiDB / TiKV, um komplexe OLAP-Anforderungen auszuführen) ;
- 1 Instanz von TiDB-Vision (zur Visualisierung des Platzierungstreibers) .
Weitere Arbeit mit dem erweiterten DBMS:
- Verbindung über MySQL-Client:
mysql -h 127.0.0.1 -P 4000 -u root ; - Grafana-Weboberfläche zum Anzeigen des Clusterstatus -
http://localhost:3000 unter admin / admin; - TiDB-Vision-Weboberfläche für Informationen zum Lastausgleich in einem Cluster und zur Datenmigration über Knoten -
http://localhost:8010 ; - Spark-Webschnittstelle -
http://localhost:8080 (Zugriff auf TiSpark - über spark://127.0.0.1:7077 ).
Wenn Sie einen
nicht ganz standardmäßigen TiDB-Cluster möchten (d. H. Die Größe ändern, die verwendeten Docker-Images, Ports usw.), können Sie nach dem Klonen des
Tidb-Docker-Compose- Repositorys die Konfiguration für Docker Compose bearbeiten:
$ cd tidb-docker-compose $ vi compose/values.yaml $ helm template compose > generated-docker-compose.yaml $ docker-compose -f generated-docker-compose.yaml pull $ docker-compose -f generated-docker-compose.yaml up -d
Weitere Informationen zur Anpassung finden Sie unter „
Anpassen des TiDB-Clusters “. Dort finden Sie Informationen dazu, woher die Konfigurationen für TiDB, TiKV, Platzierungstreiber und andere Besonderheiten stammen.
Für die bequeme
Bereitstellung von TiDB im Kubernetes-Cluster wurde der gleichnamige Operator vorbereitet -
TiDB Operator . Es befindet sich in den Helm-Diagrammen, sodass die Installation auf die folgenden Befehle reduziert werden kann (Folie aus der
Präsentation auf der TiDB DevConf 2018):

Übrigens spricht dieselbe Präsentation über die Ansichten der TiDB-Entwickler zur Überwachung dieses DBMS. Die Textbeschreibung ist leider auf Chinesisch, aber eine allgemeine Idee kann von diesen Folien erhalten werden:

Zurück zum Thema TiKV - dieses Projekt hat seine Startanleitungen zu Testzwecken veröffentlicht:
Und für den
Einsatz von TiKV in der Produktion gibt es vorgefertigte Entwicklungen mit Ansible - wieder
mit und
ohne TiDB .
Als Schnittstellen für die Arbeit mit TiKV werden schließlich angeboten:
Zu
den Plänen der Entwickler gehört auch die Erstellung eines Clients auf Rust.
Zusammenfassung
TiKV ist als Bestandteil eines größeren Open Source-Projekts eines chinesischen Unternehmens entstanden und hat es bereits geschafft, in weiten Kreisen Berühmtheit zu erlangen.
GitHub-Statistiken zeigen nicht nur mehr als 3600 Sterne, sondern auch fast 500 Gabeln und fast 100 Mitwirkende (obwohl nur zwei Dutzend von ihnen mehr als 10 Commits gemacht haben).
Die Verbindung von TiKV mit der Anzahl
der CNCF-Projekte und die Tatsache, dass dies das erste Projekt dieses Typs ist, zeigt auch deutlich die Anerkennung des Produkts durch die Cloud-native Community ... und sollte Impulse für die aktivere Entwicklung seiner Codebasis durch Außenstehende (d. H. Außerhalb der Muttergesellschaft und ihres DBMS) geben ) von Spezialisten.
PS
Lesen Sie auch in unserem Blog: