Tatsächlich widmet sich der Artikel der Entwicklung eines Programms zum Umpacken von DVR-Videos von einem Container in einen anderen, wenn dies als Konvertierung bezeichnet werden kann. Obwohl ich mein ganzes Leben lang dachte, dass der Konverter das Videoformat konvertiert (transkodiert). Dieser Artikel ist der zweite Teil meiner letzten Veröffentlichung, in der ich ausführlich über den Zugriff auf alle Videoaufnahmen des DVR sprach. Ganz am Anfang der Veröffentlichung habe ich mir jedoch eine andere Aufgabe gestellt: den Algorithmus zu untersuchen, mit dem das Standard-264-avi-Repacker-Programm funktioniert, und dasselbe Programm zu erstellen, das dieselben Operationen ausführt, jedoch nicht für eine, sondern für eine ganze Gruppe von Dateien "Ein Klick".
Ich werde das Wesentliche aller Dinge noch einmal in einfacher Sprache erklären.
Der Benutzer hat einen Videorecorder, beispielsweise das beliebte Modell QCM-08DL. Er braucht ein Video für ein bestimmtes Datum und eine bestimmte Uhrzeit. Er kann es entweder auf einem USB-Stick oder über eine webbasierte Schnittstelle eines DVR zu einem Computer entfernen. Die extrahierte Videodatei (Erweiterung .264) wird nur im Player-Programm geöffnet, das mit dem DVR geliefert wird. Der Spieler fühlt sich sehr unwohl. Sie können es weiterhin im VLC-Player öffnen, indem Sie den RAW H264-Modus in den Demultiplexing-Einstellungen (Einstellungen für fortgeschrittene Benutzer) einstellen. Gleichzeitig stören offenbar Blöcke von Audiostreams, die als Video interpretiert werden und keinen Ton enthalten, die normale Wiedergabe. Und um das Video in einem beliebigen Player zu öffnen, muss die .264-Datei zunächst in ein gängiges Format konvertiert werden, z. B. avi. Ein Konvertierungsprogramm ist ebenfalls im DVR enthalten. Sie fühlt sich aber auch sehr unwohl. Wenn es um eine oder mehrere Dateien geht, gibt es keine Probleme. Wenn es jedoch darum geht, Zugriff auf alle Videos auf der Festplatte zu erhalten und diese noch mehr in das beliebte Format zu konvertieren, sind die Standardwerkzeuge praktisch nicht geeignet.

Das Problem des Zugriffs auf alle Dateien wurde behoben. Dies war das Thema der letzten Veröffentlichung. Wir lösen das zweite Problem. Sie gaben mir bereits "gute Ratschläge": Es reicht aus, die Erweiterung im Dateinamen von "264" in "avi" umzubenennen, und alles wird schief gehen, sagen sie, es gibt nichts zu stören. Dies ist jedoch der häufigste Fehler eines normalen Benutzers, der die relevanten Probleme in der Regel nicht versteht.
In einer früheren Veröffentlichung habe ich bereits kurz über die Struktur der .264-Quelldatei geschrieben. Lass mich dich erinnern.
Die Hauptinformationen mit Audio- und Videostreams stammen aus einem Offset von 65.536 Bytes. Videostream-Blöcke beginnen mit einem 8-Byte-Header „01dcH264“ (auch „00dcH264“). Die folgenden 4 Bytes beschreiben die Größe des aktuellen Blocks des Videostreams in Bytes. Nach 4 Bytes von Nullen (00 00 00 00) beginnt der Videostreamblock selbst. Die Audio-Stream-Blöcke haben den Titel "03wb" (obwohl nach meinen Beobachtungen das erste Zeichen des Headers in einigen Fällen nicht unbedingt "0" war). Nach - 12 Bytes an Informationen, die ich noch nicht herausgefunden habe. Und beginnend mit dem 17. Byte - einem Audiostream mit einer festen Länge von 160 Bytes. Am Ende der Datei befinden sich keine Tags.Ich werde das oben Gesagte kommentieren. Alles, was bis zu einem Offset von 65.536 Bytes ist, erwies sich als ungelöst und unnötig. Von einem Offset von 65.536 Bytes bis zum ersten Header des Streams gibt es eine kleine Lücke, deren Inhalt ebenfalls nicht aufgelöst wird, und außerdem erscheint sie, wie ich überprüft habe, nach der Konvertierung durch ein reguläres Programm nicht in der Ausgabe-AVI-Datei.
Jeder Block des Videostreams repräsentiert einen Frame. Das erste Zeichen in der Kopfzeile der Blöcke des Videostreams ist optional "0". Ich habe seinen Zweck nicht herausgefunden, weil es, wie ich herausgefunden habe, nicht der Schlüssel zur Lösung der Aufgabe ist. Das zweite Zeichen im Header des Videostreams kann entweder "1" oder "0" sein. Im zweiten Fall ist der Inhalt des Videostreamblocks der sogenannte Referenzrahmen. Und im ersten Fall ist der Inhalt des Videostreamblocks ein codierter komprimierter Rahmen, der vom Referenzrahmen abhängt. Die Größe des Inhalts des Referenzrahmens ist erheblich größer als die Größe des Inhalts des komprimierten Unterrahmens. Die Wiederholungszeit des Referenzrahmens hängt höchstwahrscheinlich von den Einstellungen des Komprimierungsverhältnisses im DVR ab. In meinem Fall betrug die Wiederholungszeit jedoch 1 Bild / Sek.
Das reguläre Programm zum Umpacken von Videos vom Container „264“ in den Container „avi“ ergab unterschiedliche Ergebnisse hinsichtlich der Bildrate. Bei Videos, die im hochauflösenden Modus (704 * 576) aufgenommen wurden, betrug die Bildrate 20 Bilder / Sek. Und bei niedriger Auflösung (352 * 288) - 25 Bilder / Sek. Diese Informationen werden vom MediaInfo-Dienstprogramm bereitgestellt. Außerdem wird angegeben, dass die Videogröße in jedem Fall gleich ist: 720 * 576, und die Größe des Videostreams (dieses Dienstprogramm meldet) 704 * 576 oder 352 * 288. Die meisten Player werden speziell für die Größe des Videostreams bereitgestellt. Ich habe jedoch einen Player getroffen, der beim Abspielen einer 352 * 288-Datei den Halbbildmodus falsch angezeigt hat. Ich wollte diesen kleinen Fehler des Vollzeit-Repackers beheben, indem ich mir die Bytes des Inhalts des Videostreams ansah und von dort Informationen über die Bildgröße abrief. Aber in Eile konnte ich das nicht tun. Das Obige ist in der folgenden Abbildung dargestellt.

Nun zur Bildrate. Wie ich herausgefunden habe, greift der reguläre Repacker auf kein Headerfeld des Containers „264“ zu. Es beurteilt die Bildrate, indem es das Verhältnis der Anzahl von Videoblöcken und Audiostreams berechnet. Und dieser Wert in der Berechnung wird nicht einmal auf den nächsten ganzen Wert gerundet, wie aus der obigen Abbildung ersichtlich ist (grün eingekreist). Wie ich herausgefunden habe, ist die Anzahl der Audio-Stream-Blöcke pro Zeiteinheit immer und überall (in jeder Datei) festgelegt, nämlich 25 Blöcke pro Sekunde. Wenn Sie die Videodatei mit einer Frequenz von 20 Bildern / Sek. Untersuchen, tritt das Referenzbild (Block) alle 19 komprimierten Bilder und im Fall von 25 Bildern / Sek. Auf. - alle 24 komprimierten Frames.
Wir untersuchen weiterhin die Struktur des Headers des Videostreams. Wir haben die ersten acht Bytes herausgefunden: Dies ist die Bezeichnung der Referenz oder des komprimierten Frames plus das Schlüsselwort „H264“. Die folgenden vier Bytes beschreiben, wie ich herausgefunden habe, nicht die genaue, sondern die ungefähre Größe des Inhalts des Videostreams. Ein normaler Repacker wirft alle Bytes dieses Inhalts vollständig und schreibt dann die resultierende Größe in die entsprechenden Felder des AVI-Containers. Dieser Wert unterscheidet sich von dem Wert, der im entsprechenden Feld der .264-Quelldatei angegeben ist.
Teilweise habe ich zwölf Bytes an Informationen nach dem Header des Audio-Stream-Blocks erraten. In jedem Fall sind die Schlüsselelemente die letzten 4 Bytes, nach denen der Audiostream beginnt. Dies sind zwei 16-Bit-Zahlen, die die Anfangsparameter des iterativen Decodierungsschemas von ADPCM zu PCM beschreiben. Durch die Dekodierung wird der Audiostream um das Vierfache erhöht. Als ich die Dateien im Voraus recherchierte, stellte ich fest, dass der Vollzeit-Repacker das Audio dekodiert, den Videoinhalt jedoch unverändert lässt.
Ohne tiefes Wissen habe ich lange versucht herauszufinden, welcher Decodierungsalgorithmus in meinem Fall verwendet wurde. Intuitiv bereits vermutet, dass die Komprimierungsmethode ADPCM angewendet wurde. Genauer gesagt, nicht intuitiv, sondern mit einem kompetenten Ansatz, der darauf basiert, dass der Audiostream genau viermal komprimiert wird. Und wenn ich ein Fragment in Adobe Audition als RAW in verschiedenen Formaten öffne (und dasselbe Fragment nach dem Umpacken mit einem regulären Programm vergleiche), hat mir ADPCM ein sehr ähnliches (aber nicht genaues) Klangergebnis gegeben. Bei der Analyse des Komprimierungsalgorithmus haben mir die Informationen auf der Website
wiki.multimedia.cx/index.php/IMA_ADPCM geholfen. Hier lernte ich die beiden anfänglichen Decodierungsparameter kennen und stellte dann mithilfe der „Poke-Methode“ fest, dass diese anfänglichen Parameter vor dem Start des Audiostreams in 4 Byte aufgezeichnet wurden. Ich werde die Funktionsweise des Algorithmus beschreiben und eine grobe mathematische Interpretation geben (unter dem Spoiler).
Details zum ADPCM-DecodierungsalgorithmusEs gibt eine Folge von Proben
Darüber hinaus gibt es, wie bereits erwähnt, zwei Anfangsparameter
und
. Benötigen Sie eine neue Beispielsequenz
. Wie Sie bereits erraten können, ist das erste Ausgabebeispiel bereits bekannt: Es stimmt mit einem der Anfangsparameter überein
. Dies ist etwas anderes als eine „anfängliche Verschiebung“. Es ist anzumerken, dass die Eingangs- (Quell-) Abtastwerte in vier Bits codiert sind. Bei vorzeichenbehafteten Typen fallen Ganzzahlen von -8 bis einschließlich 7 unter die Codierung. Das höchstwertige Bit ist tatsächlich für das Vorzeichen der Zahl verantwortlich. Die Ausgabe-PCM-Abtastwerte, die nach dem Decodieren erhalten werden, haben ein vorzeichenbehaftetes 16-Bit-Standardformat.
Wenn Sie den Algorithmuscode in C analysieren, sehen Sie zwei Tabellen. Sie sind unten aufgeführt.
int ima_index_table[] = { -1, -1, -1, -1, 2, 4, 6, 8 };
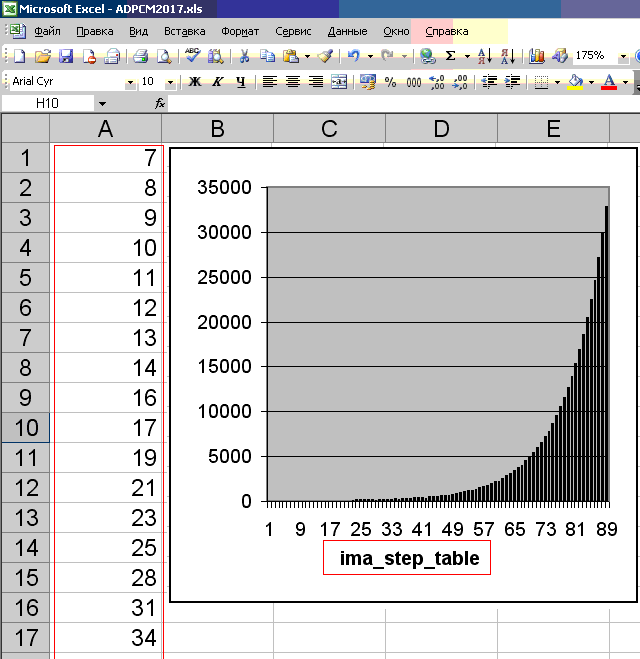
int ima_step_table[] = { 7, 8, 9, 10, 11, 12, 13, 14, 16, 17, 19, 21, 23, 25, 28, 31, 34, 37, 41, 45, 50, 55, 60, 66, 73, 80, 88, 97, 107, 118, 130, 143, 157, 173, 190, 209, 230, 253, 279, 307, 337, 371, 408, 449, 494, 544, 598, 658, 724, 796, 876, 963, 1060, 1166, 1282, 1411, 1552, 1707, 1878, 2066, 2272, 2499, 2749, 3024, 3327, 3660, 4026, 4428, 4871, 5358, 5894, 6484, 7132, 7845, 8630, 9493, 10442, 11487, 12635, 13899, 15289, 16818, 18500, 20350, 22385, 24623, 27086, 29794, 32767 };
Man kann sagen, dass diese beiden "magischen" Arrays tabellarische Funktionen sind, in deren Argumenten dieselben zwei Anfangsparameter eingesetzt werden. Während der Iteration werden bei jedem Schritt die Parameter neu berechnet und erneut in diese Tabellen eingesetzt. Lassen Sie uns zunächst sehen, wie dies im Code implementiert ist.
Wir erklären die notwendigen, einschließlich Hilfsvariablen.
int current1; int step; int stepindex1; int diff; int current; int stepindex; int value;
Bevor Sie mit der Iteration beginnen, müssen Sie der aktuellen Variablen den Anfangsparameter zuweisen
und die Variable stepindex ist
. Dies geschieht außerhalb des fraglichen Algorithmus, daher reflektiere ich dies nicht mit Code. Das Folgende sind die Transformationen, die in einem Kreis (in einer Schleife) ausgeführt werden.
value = read(input_sample);
Im Hilfsvariablenschritt aus dem Array ima_step_table wird der Wert am Index stepindex1 geschrieben. Bei der ersten Iteration ist dies der Anfangsparameter
Für weitere Iterationen ist dies ein neu berechneter Parameter
. Dann wird der Wert aus diesem Array durch eine Bitverschiebungsoperation nach rechts durch 8 (anscheinend vollständig) geteilt, und die Diff-Variable wird als Ergebnis dieser Teilung initialisiert. Dann werden die drei niedrigstwertigen Bits des Wertes der Eingangsabtastung analysiert und abhängig von ihren Zuständen kann die Diff-Variable um drei Terme eingestellt werden. Die Terme sind eine ähnliche ganzzahlige Division des Diff-Wertes durch 4 (>> 2), durch 2 (>> 1) oder Diff ohne Änderungen (sei es eine Division durch 1 zur Verallgemeinerung). Dann wird das höchstwertige (vorzeichenbehaftete) Bit des Wertes der Eingangsabtastung analysiert. Abhängig von ihrem Zustand wird die zuvor erzeugte Diff-Variable zur Variablen current1 addiert oder subtrahiert. Dies ist der Wert des Ausgabebeispiels. Aus Gründen der Richtigkeit sind die Werte auf oben und unten beschränkt. Dann wird stepindex1 angepasst, indem der Wert aus dem Array ima_index_table durch den Index des Werts des Eingangsabtastwerts addiert wird, wobei das Vorzeichenbit auf Null zurückgesetzt wird. Stepindex1-Werte unterliegen ebenfalls einer Begrenzung. Ganz am Ende, bevor dieser Algorithmus wiederholt wird, werden den aktuellen und Schrittindexwerten die gerade wiedergegebenen Werte von current1 und stepindex1 zugewiesen, und der Algorithmus wird erneut wiederholt.
Sie können versuchen, es herauszufinden, um ungefähr zu verstehen, wie die Diff-Variable gebildet wird. Lass
. Dies sind die Werte der Schrittvariablen bei jedem i-ten Schritt der Iteration als Werte der Funktion (Array) des Arguments
wo
. Der Einfachheit halber bezeichnen wir die Diff-Variable als
. Nach der Logik der oben beschriebenen Argumentation haben wir:
wo
- niedrige 3 Bits einer Zahl
. Wir führen zu einem gemeinsamen Nenner und wandeln diesen Ausdruck in eine bequemere Form um:
Die letzte Konvertierung basiert auf der Tatsache, dass in gewissem Sinne die mindestens drei Bits (0 oder 1) einer Zahl vorliegen
Mit den dargestellten Koeffizienten gibt es etwas anderes als das Schreiben des Absolutwerts dieser Zahl und des höchstwertigen Bits der Zahl
entspricht dem Vorzeichen des gesamten Ausdrucks. Weiter nach der Formel
Ein neuer Stichprobenwert wird basierend auf dem alten berechnet. Zusätzlich wird ein neuer Variablenwert berechnet.
::
Das Modul in der Formel gibt an, dass die Variable
kommt in Funktion
ohne das höchstwertige Vorzeichenbit, das sich im Code widerspiegelt. Eine Funktion
Ist der Wert des Arrays ima_index_table, wobei der Index dem Argument entspricht.
Bei der Beschreibung der Formeln habe ich die oben und unten beschriebenen Restriktionsoperationen vernachlässigt. Das gesamte iterative Schema sieht ungefähr so aus:
Sehr tief in der Theorie der Kodierung / Dekodierung von ADPCM habe ich mich nicht vertieft. Die Tabellenwerte des Arrays ima_step_table (von 89 Teilen) beschreiben jedoch anhand ihrer Reflexion im Diagramm (siehe Abbildung unten) die Wahrscheinlichkeitsverteilung der Stichproben relativ zur Nulllinie. In der Praxis ist dies normalerweise der Fall: Je näher die Probe an der Nulllinie liegt, desto häufiger tritt sie auf. Daher basiert ADPCM auf einem Wahrscheinlichkeitsmodell, und keinesfalls kann ein Quellensatz von 16-Bit-PCM-Abtastwerten korrekt in 4-Bit-ADPCM-Abtastwerte konvertiert werden. Im Allgemeinen ist ADPCM PCM mit einem variablen Quantisierungsschritt. Anscheinend spiegelt dieses Diagramm diesen sehr variablen Schritt wider. Er wird richtig ausgewählt, basierend auf dem Gesetz der Verteilung von Audiodaten in der Praxis.
Fahren wir nun mit der Beschreibung der Struktur des AVI-Containers fort. Tatsächlich ist es eine komplexe hierarchische Struktur.
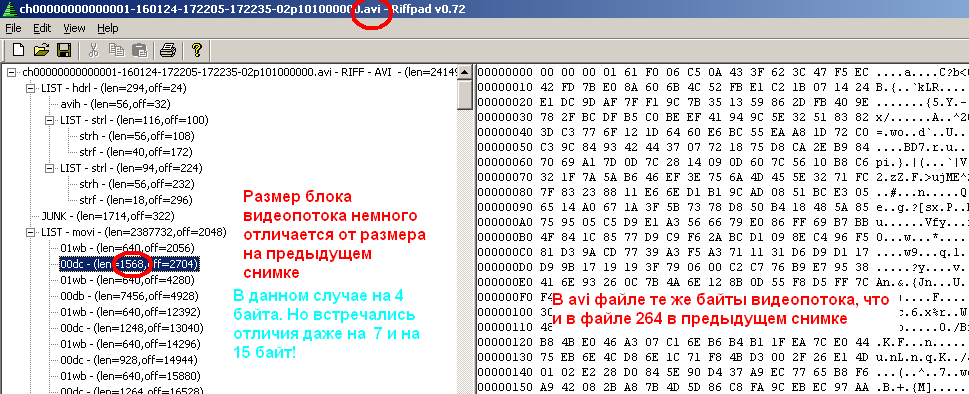
Nachdem ich die Aufgabe für einen speziellen Fall vereinfacht hatte, präsentierte ich die AVI-Struktur in linearer Form. Das Ergebnis ist folgendes: Die AVI-Datei besteht aus einem großen Header, Null-Sprung-Bytes (JUNK), einem Bereich von Audio- und Videostreams (mit ihren Headern und Inhaltsgrößen) und einer Liste von Indizes. Letzteres dient insbesondere dazu, im Player durch das Video zu scrollen. Ohne diese Liste funktioniert das Scrollen nicht (aktiviert). Es ist nur ein Inhaltsverzeichnis, in dem die Schlüsselnamen der Stream-Blöcke (die mit den Namen in den Block-Headern übereinstimmen), die entsprechenden Größen des Inhalts und die Werte der Offsets (Adressen) relativ zum Beginn des Stream-Bereichs aufgelistet sind.
Jetzt können Sie mit der Entwicklung des Programms fortfahren. Eine spezifische Beschreibung des Problems lautet wie folgt.
Im Stammverzeichnis von Abschnitt X befindet sich ein DVR-Verzeichnis. Dieses Verzeichnis enthält viele nicht leere Unterverzeichnisse (und nur Unterverzeichnisse) mit Namen, die bestimmten Daten entsprechen. In jedem dieser Unterverzeichnisse befinden sich viele Dateien mit unterschiedlichen Namen und der Erweiterung "264". Erforderlich in Abschnitt Y: Erstellen Sie das Verzeichnis „DVR“ und darin dieselben Unterverzeichnisse wie in Abschnitt X :. Füllen Sie jedes dieser Unterverzeichnisse mit Dateien mit denselben entsprechenden Namen, jedoch mit den Erweiterungen nicht "264", sondern "avi". Diese AVI-Dateien müssen aus den ursprünglichen 264-Dateien erhalten werden, indem sie verarbeitet werden, wodurch auf die eine oder andere Weise der Algorithmus eines vorhandenen Programms wiederholt wird. Die Verarbeitung besteht darin, Videostreams direkt neu zu verpacken, Audio-Streams neu zu dekodieren und die AVI-Datei zu formatieren. Das Programm sollte über die Befehlszeile wie folgt gestartet werden: "264toavi.exe X: Y:", wobei "264toavi.exe" der Name des Programms ist, "X:" der Quellabschnitt ist, "Y:" der Zielabschnitt ist.Um die Aufgabe zu vereinfachen, war es tatsächlich möglich, ein Programm zu schreiben, das nur die Konvertierung (das Umpacken) einer Datei in zwei Tagen erledigt: den Namen der Eingabedatei und den Namen der Ausgabedatei. Um nur das Umpacken von Gruppen zu implementieren, können Sie eine Befehls-Batch-Datei (bat) mit anderen Tools, z. B. Excel, schreiben. Aber ich habe ein komplettes Programm implementiert, sehr umständlich. Es ist unwahrscheinlich, dass der Quellcode die Aufmerksamkeit der Leser verdient. Ich werde die Struktur des Programmcodes beschreiben.
Das Programm ist in C in der Dev-C ++ - Entwicklungsumgebung mit WinAPI-Elementen geschrieben. Das Programm implementiert drei große Hilfsfunktionen: die Funktion zum Erzeugen des anfänglichen AVI-Headers, die Funktion zum Decodieren eines Audio-Samples und die Funktion zum Scannen der Quelldatei „264“ nach Wörtern. In Worten nenne ich einen Teil von 4 Bytes. Es wurde beobachtet, dass die Größe der Header und der Inhalt aller Streams ein Vielfaches von vier Bytes sind. Die Scanfunktion kann fünf Werte zurückgeben: 0 - wenn es sich um die üblichen 4 Bytes des Videostreams zum erneuten Packen handelt, 1 - wenn es sich um den Header des Blocks des Videostreams des Referenzrahmens handelt, 2 - wenn es sich um den Header des Blocks des Videostreams des komprimierten Frames handelt, 3 - wenn es sich um den Header des Audiostreamblocks handelt, 4 - wenn dies der Fall ist "Beschädigter" Block, der beim Umpacken ignoriert wird. Sehr, sehr selten, aber es ist passiert. Der beschädigte Block (wie ich ihn nannte) ist ein Header wie "\ 0 \ 0 \ 0 \ 0H264", wobei "\ 0" das Nullbyte ist. Der reguläre Repacker ignoriert solche Blöcke. Natürlich kann sich herausstellen, dass der Inhalt eines solchen Blocks ziemlich gut funktioniert, aber ich ignoriere solche Blöcke, um mein Programm näher an den Standard zu bringen.
In der Hauptfunktion wird neben der Organisation von Verzeichnissen die Eingabedatei von der Scanfunktion gelesen. Abhängig davon, was diese Funktion zurückgegeben hat, werden weitere Aktionen ausgeführt. Wenn dies die Header der Videostreams sind, werden die entsprechenden Header in der Ausgabe-AVI-Datei gebildet. Dort werden sie unterschiedlich genannt: "00db" ist der Titel des Blocks des Videostreams des Referenzrahmens und "00dc" ist für den komprimierten Rahmen. Nach dem Umpacken (Umschreiben von Wörtern) vor dem neu aufgetretenen Header wird die Größe des neu gepackten Inhalts berechnet und dieser Wert in das Feld geschrieben, das unmittelbar auf den Header des gerade verarbeiteten Streams folgt. Wenn beim Scannen ein Audiostream-Header auftritt, wird der Headername „03wb“ in der Ausgabe-AVI-Datei generiert und der Audiostream wird in der Schleife von ADPCM zu PCM decodiert, während der decodierte Inhalt in die AVI-Datei geschrieben wird. Zusammen mit all dem wird eine kurze Information (Inhaltsverzeichnis) in einer temporären Indexdatei „Index“ aufgezeichnet. Sie konnten keine Scanfunktion ausführen, sondern alles in die Hauptfunktion schreiben. Aber dann wäre das Programm sehr umständlich und fast schwer zu lesen.
Am Ende des gesamten Vorgangs, wenn die Eingabedatei „264“ beendet ist, bevor zu einer neuen Datei gewechselt wird, schließt das Programm alle Vorgänge kompetent ab. Zuerst werden bestimmte Felder im Header der AVI-Datei angepasst, deren Werte von der Größe und Anzahl der Lesestreams abhängen. Anschließend wird der Inhalt der temporären Indexdatei an die fast fertige AVI-Datei angehängt, die dann gelöscht wird. Nach diesen Vorgängen ist die Ausgabe-AVI-Datei zur Wiedergabe bereit.
Während das Programm ausgeführt wird, findet in der Befehlszeile eine Textvisualisierung statt, in der das aktuelle Verzeichnis, die Datei sowie die Blocknummer des Videostreams pro Referenzrahmen und der entsprechende Zeitpunkt des Videos in Minuten und Sekunden angezeigt werden. Und wenn die Eingabedatei keinen beliebigen Namen hat, sondern den ursprünglichen (der die Kanalnummer, das Datum und die Uhrzeit des Beginns der Aufnahme enthält), erfolgt eine interaktivere Visualisierung auf der Grundlage der Datums- / Zeitarithmetik.
Beim Testen und Debuggen des Programms gab es die Hauptprobleme, die ich bei der Arbeit mit der Sounddecodierung hatte. Einfache Arithmetik funktionierte nicht richtig, wenn ich beim Deklarieren von Variablen in der Dekodierungsfunktion die Typen nicht richtig eingeben würde. Aus diesem Grund wurden einige Blöcke von Audiostreams unterbrochen und es gab Klicks nach Gehör. Einige unverständliche Headerfelder der ursprünglichen 264-Datei, die ich nicht herausfinden konnte, erwiesen sich als unempfindlich gegenüber dem Ergebnis. Im Gegensatz zu einem normalen Programm wirft mein Programm nicht den letzten unvollständigen Flussblock aus dem Umpackvorgang. Obwohl seine Abwesenheit keine praktische Rolle spielen wird. Ein anderes reguläres Programm hinterlässt im Gegensatz zu meinem eine kleine Menge „Müll“ (dies ist der Inhalt des letzten Streams) ganz am Ende der AVI-Datei nach den Indizes. Trotzdem wird das Video fast gleich abgespielt. Und das Programm führt das Umpacken für den gleichen Zeitraum wie das reguläre Programm durch.
Abschließend werde ich Abbildungen geben, die die Struktur der Organisation von Flows in der .264-Datei (im WinHex-Hex-Editor) am Beispiel einer der Dateien und das Erscheinungsbild des RiffPad-Programms mit der darin gepackten neu gepackten AVI-Datei veranschaulichen. Dieses Programm hat das Studium der Struktur einer AVI-Datei erheblich vereinfacht. Es zeigt deutlich die hierarchische Struktur, zeigt den Byte-Inhalt jedes Mitglieds der Struktur und interpretiert den Inhalt der Header sogar geschickt in Form einer Liste von Parametern. Insbesondere das Bild zeigt, dass der Inhalt des Videostreams unverändert überschrieben wird.