Gut zu allen! Nun, es ist Zeit für
unseren nächsten
Devops-Kurs . Wahrscheinlich ist dies einer der stabilsten und Referenzkurse, aber gleichzeitig der vielfältigste in Bezug auf Studenten, da keine Gruppe jemals so ausgesehen hat wie die andere: In einem sind die Entwickler fast vollständig, dann in den nächsten Ingenieuren, dann in den Administratoren und so weiter. Dies bedeutet auch, dass die Zeit für interessante und nützliche Materialien sowie für Online-Meetings gekommen ist.

Dieser Artikel enthält Empfehlungen zum Starten eines Kubernetes-Clusters in Produktionsqualität in einem lokalen Rechenzentrum oder einem peripheren Standort (Edge-Standort).
Was bedeutet Produktionsqualität?
- Sichere Installation
- Das Bereitstellungsmanagement wird mithilfe eines sich wiederholenden und aufgezeichneten Prozesses durchgeführt.
- Die Arbeit ist vorhersehbar und konsequent;
- Es ist sicher, Aktualisierungen und Optimierungen durchzuführen.
- Um Fehler und Ressourcenmangel zu erkennen und zu diagnostizieren, werden Protokolle erstellt und überwacht.
- Der Dienst verfügt über eine ausreichende „Hochverfügbarkeit“ unter Berücksichtigung der verfügbaren Ressourcen, einschließlich Einschränkungen in Bezug auf Geld, physischen Speicherplatz, Stromversorgung usw.
- Der Wiederherstellungsprozess ist verfügbar, dokumentiert und wird für den Fall eines Fehlers getestet.
Kurz gesagt bedeutet Produktionsqualität, Fehler zu antizipieren und die Wiederherstellung mit einem Minimum an Problemen und Verzögerungen vorzubereiten.

In diesem Artikel geht es um die On-Premise-Bereitstellung von Kubernetes auf einem Hypervisor oder einer Bare-Metal-Plattform, da im Vergleich zur Zunahme der großen öffentlichen Clouds nur begrenzte Supportressourcen zur Verfügung stehen. Einige dieser Empfehlungen können jedoch für die öffentliche Cloud nützlich sein, wenn das Budget die ausgewählten Ressourcen begrenzt.
Die Bereitstellung eines Single-Bare-Metal-Bare-Metal-Minikubes kann ein einfacher und kostengünstiger Prozess sein, ist jedoch nicht für die Produktion geeignet. Umgekehrt können Sie mit Borg in einem Offline-Geschäft, einer Filiale oder einem peripheren Standort nicht das Niveau von Google erreichen, obwohl es unwahrscheinlich ist, dass Sie es benötigen.
Dieser Artikel beschreibt Tipps zum Erreichen einer Kubernetes-Bereitstellung auf Produktionsebene, selbst in Situationen mit begrenzten Ressourcen.
Wichtige Komponenten im Kubernetes-ClusterBevor Sie sich mit den Details befassen, ist es wichtig, die Gesamtarchitektur von Kubernetes zu verstehen.
Der Kubernetes-Cluster ist ein stark verteiltes System, das auf der Steuerebene und der Architektur der Cluster-Worker-Knoten basiert (siehe unten):
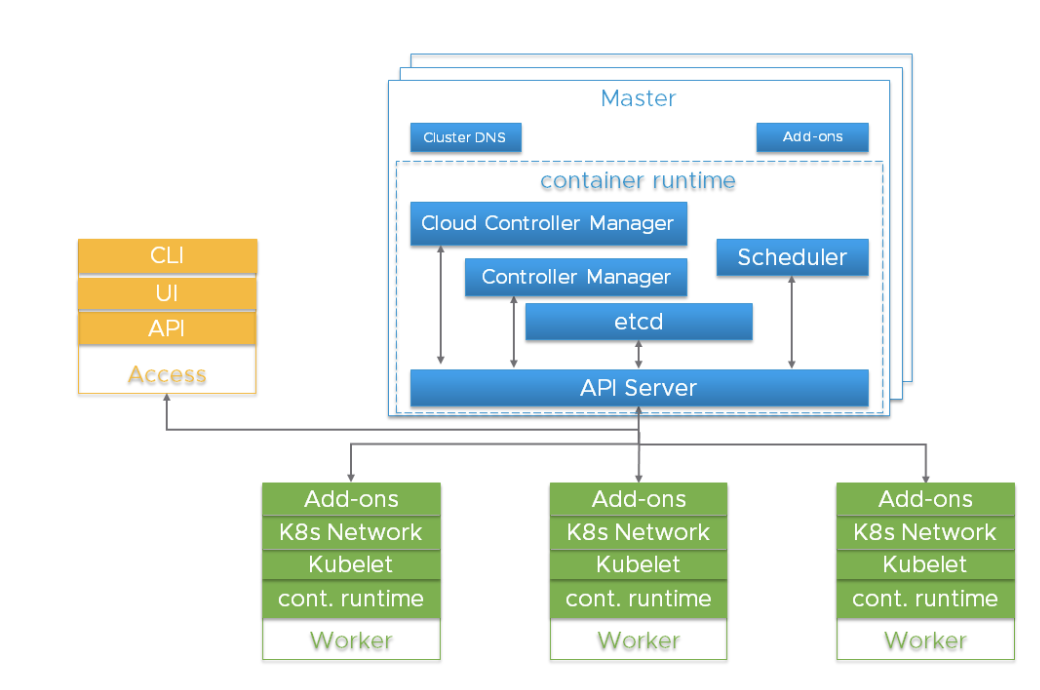
In der Regel befinden sich die Komponenten des API-Servers, des Controller-Managers und des Schedulers in mehreren Instanzen von Knoten auf Steuerungsebene (als Master bezeichnet). Masterknoten enthalten normalerweise auch etcd. Es gibt jedoch große und leicht zugängliche Skripte, bei denen etcd auf unabhängigen Hosts ausgeführt werden muss. Komponenten können als Container ausgeführt werden und optional unter der Aufsicht von Kubernetes als statische Herde eingesetzt werden.
Redundante Instanzen dieser Komponenten werden für eine hohe Verfügbarkeit verwendet. Die Bedeutung und der erforderliche Redundanzgrad können variieren.
| Komponente | Rollen | Folgen des Verlustes | Empfohlene Instanzen |
|---|
| etcd | Behält den Status aller Kubernetes-Objekte bei | Katastrophaler Speicherverlust. Verlust der meisten = Kubernetes verliert die Kontrollebene, API-Server hängt von etcd ab, schreibgeschützte API-Aufrufe, die kein Quorum benötigen, wie bereits erstellte Workloads, können weiterhin funktionieren. | ungerade Zahl, 3+ |
| API-Server | Bietet API für den externen und internen Gebrauch | Neue Pods können nicht gestoppt, gestartet und aktualisiert werden. Scheduler und Controller Manager sind API Server-abhängig. Das Laden wird fortgesetzt, wenn sie nicht von API-Aufrufen abhängig sind (Operatoren, benutzerdefinierte Controller, CRD usw.). | 2+ |
| kube-scheduler | Platziert Pods auf Knoten | Pods können nicht zwischen ihnen platziert, priorisiert oder verschoben werden. | 2+ |
| kube-controller-manager | Steuert viele Controller | Die für den Zustand verantwortlichen Hauptregelkreise funktionieren nicht mehr. Die In-Tree-Integration des Cloud-Anbieters bricht ab. | 2+ |
| Cloud-Controller-Manager (CCM) | Integration von Cloud-Anbietern außerhalb des Baums | Die Integration des Cloud-Anbieters bricht ab | 1 |
| Ergänzungen (z. B. DNS) | Anders | Anders | Hängt vom Add-On ab (z. B. 2+ für DNS) |
Zu den Risiken dieser Komponenten zählen Hardwarefehler, Softwarefehler, fehlerhafte Updates, menschliche Fehler, Netzwerkunterbrechungen und Systemüberlastung, die zu einer Erschöpfung der Ressourcen führen. Redundanz kann die Auswirkungen dieser Gefahren verringern. Dank der Funktionen der Hypervisor-Plattform (Ressourcenplanung, Hochverfügbarkeit) können Sie die Ergebnisse außerdem mit dem Linux-Betriebssystem, Kubernetes und der Container-Laufzeit multiplizieren.
Der API-Server verwendet mehrere Load-Balancer-Instanzen, um Skalierbarkeit und Verfügbarkeit zu erreichen. Ein Load Balancer ist eine wesentliche Komponente für eine hohe Verfügbarkeit. In Abwesenheit eines Balancers können mehrere A-Einträge des DNS-API-Servers als Alternative dienen.
kube-scheduler und kube-controller-manager sind an der Auswahl eines Leiters beteiligt, anstatt einen Load Balancer zu verwenden. Da
Cloud-Controller-Manager für bestimmte Arten von Hosting-Infrastrukturen verwendet wird, deren Implementierung variieren kann, werden wir sie nicht diskutieren - wir geben nur an, dass sie Bestandteil der Managementebene sind.
Auf Kubernetes ausgeführte Pods werden vom Kubelet-Agenten verwaltet. Jede Instanz des Workers führt einen Kubelet-Agenten und eine
CRI- kompatible Container-
Startumgebung aus . Kubernetes selbst wurde entwickelt, um Worker-Node-Fehler zu überwachen und zu beheben. Für kritische Ladefunktionen, Hypervisor-Ressourcenmanagement und Lastisolation kann es jedoch verwendet werden, um die Zugänglichkeit zu verbessern und die Vorhersagbarkeit ihrer Arbeit zu verbessern.
etcdetcd ist ein dauerhafter Speicher für alle Kubernetes-Objekte. Die Verfügbarkeit und Wiederherstellbarkeit des etcd-Clusters sollte bei der Bereitstellung von Kubernetes in Produktionsqualität oberste Priorität haben.
Ein aus fünf Knoten bestehender etcd-Cluster ist die beste Option, wenn Sie dies zulassen können. Warum? Weil Sie einen warten können und gleichzeitig einem Ausfall standhalten. Ein Cluster von drei Knoten ist das Minimum, das wir für einen Service auf Produktionsebene empfehlen können, selbst wenn nur ein Host-Hypervisor verfügbar ist. Mehr als sieben Knoten werden ebenfalls nicht empfohlen, mit Ausnahme
sehr großer Installationen, die mehrere Zugriffszonen abdecken.
Die Mindestempfehlungen für das Hosten eines etcd-Clusterknotens sind 2 GB RAM und eine 8 GB SSD-Festplatte. In der Regel sind 8 GB RAM und 20 GB Festplattenspeicher ausreichend. Die Festplattenleistung wirkt sich auf die Wiederherstellungszeit eines Knotens nach einem Fehler aus.
Überprüfen Sie für Details.
Denken Sie in besonderen Fällen an mehrere etcd-ClusterBei sehr großen Kubernetes-Clustern sollten Sie einen separaten etcd-Cluster für Kubernetes-Ereignisse verwenden, damit zu viele Ereignisse den Kerndienst der Kubernetes-API nicht beeinträchtigen. Bei Verwendung des Flanell-Netzwerks wird die Konfiguration in etcd gespeichert, und die Versionsanforderungen können von denen von Kubernetes abweichen. Dies kann die Sicherung von etcd erschweren. Wir empfehlen daher, einen separaten etcd-Cluster speziell für Flanell zu verwenden.
Bereitstellung eines einzelnen HostsDie Liste der Barrierefreiheitsrisiken umfasst Hardware, Software und den Faktor Mensch. Wenn Sie auf einen einzelnen Host beschränkt sind, kann die Verwendung von redundantem Speicher, fehlerkorrigierendem Speicher und einer doppelten Stromversorgung den Schutz vor Hardwarefehlern verbessern. Durch Ausführen eines Hypervisors auf einem physischen Host können Sie redundante Softwarekomponenten verwenden und betriebliche Vorteile hinzufügen, die mit der Bereitstellung, Aktualisierung und Überwachung der Ressourcennutzung verbunden sind. Selbst in Stresssituationen bleibt das Verhalten wiederholbar und vorhersehbar. Selbst wenn Sie beispielsweise nur das Starten von Singletones von Masterdiensten zulassen können, sollten diese vor Überlastung und Ressourcenverarmung geschützt sein und mit der Arbeitslast Ihrer Anwendung konkurrieren. Ein Hypervisor kann effizienter und einfacher zu verwenden sein als die Priorisierung im Linux-Scheduler, in cgroups, Kubernetes-Flags usw.
Sie können drei virtuelle etcd-Maschinen bereitstellen, wenn die Hostressourcen dies zulassen. Jede VM muss von einem separaten physischen Speichergerät unterstützt werden oder separate Teile des Speichers mithilfe von Redundanz (Spiegelung, RAID usw.) verwenden.
Doppelt redundante Instanzen der Server-API, des Schedulers und des Controller-Managers sind das nächste Upgrade, wenn Ihr einziger Host über genügend Ressourcen dafür verfügt.
Bereitstellungsoptionen für einen einzelnen Host, von am wenigsten für die Produktion geeignet bis zu den meisten| Typ | Eigenschaften | Ergebnis |
|---|
| Mindestausstattung | Singleton etcd und Master-Komponenten. | Heimlabor, überhaupt nicht in Produktionsqualität. Multiple Single Point of Failure (SPOF). Die Wiederherstellung ist langsam, und wenn Speicherplatz verloren geht, fehlt er vollständig. |
| Verbesserung der Speicherredundanz | etcd Singleton- und Master-Komponenten, etcd-Speicher ist redundant. | Sie können mindestens einen Speichergerätefehler beheben. |
| Redundanz auf verwalteter Ebene | Es gibt keinen Hypervisor, mehrere Instanzen von Komponenten auf verwalteter Ebene in statischen Pods. | Der Schutz vor Softwarefehlern ist erschienen, aber das Betriebssystem und die Container-Startumgebung sind immer noch die gleichen Fehlerquellen mit verheerenden Updates. |
| Hinzufügen eines Hypervisors | Ausführen von drei redundanten Instanzen auf verwalteter Ebene in der VM. | Es gibt Schutz vor Softwarefehlern und menschlichen Fehlern sowie einen betrieblichen Vorteil bei Installation, Ressourcenverwaltung, Überwachung und Sicherheit. Betriebssystem-Updates und Container-Startumgebungen sind weniger störend. Der Hypervisor ist der einzige einzelne Fehlerpunkt. |
Dual-Host-BereitstellungBei zwei Hosts ähneln die Speicherprobleme bei etcd der Option für einen einzelnen Host - Sie benötigen Redundanz. Es ist vorzuziehen, drei encd-Instanzen auszuführen. Es mag nicht intuitiv erscheinen, aber es ist besser, alle etcd-Knoten auf einen Host zu konzentrieren. Sie erhöhen die Zuverlässigkeit nicht, indem Sie sie durch 2 + 1 zwischen zwei Hosts teilen. Ein Verlust eines Knotens mit den meisten encd-Instanzen führt zu einem Fehler, unabhängig davon, ob es sich um eine Mehrheit von 2 oder 3 handelt. Wenn die Hosts nicht identisch sind, platzieren Sie den gesamten etcd-Cluster auf dem zuverlässigeren.
Es wird empfohlen, redundante API-Server, Kube-Scheduler und Kube-Controller-Manager auszuführen. Sie sollten von Hosts gemeinsam genutzt werden, um das Risiko von Fehlern in der Container-Startumgebung, im Betriebssystem und in der Hardware zu minimieren.
Durch Starten einer Hypervisor-Schicht auf physischen Hosts können Sie mit redundanten Programmkomponenten arbeiten und Ressourcen verwalten. Es hat auch den betrieblichen Vorteil einer geplanten Wartung.
Bereitstellungsoptionen für zwei Hosts, von den am wenigsten für die Produktion geeigneten bis zu den meisten| Typ | Eigenschaften | Ergebnis |
|---|
| Mindestausstattung | Zwei Hosts ohne redundanten Speicher. Singleton etcd und Master-Komponenten auf demselben Host. | etcd - ein einzelner Fehlerpunkt, es macht keinen Sinn, zwei auf anderen Masterdiensten auszuführen. Die gemeinsame Nutzung zwischen zwei Hosts erhöht das Risiko von Ausfällen auf verwalteten Ebenen. Der potenzielle Vorteil der Isolierung von Ressourcen durch Ausführen einer verwalteten Schicht auf einem Host und von Anwendungs-Workloads auf einem anderen. Wenn der Speicher verloren geht, erfolgt keine Wiederherstellung. |
| Verbesserung der Speicherredundanz | Singleton etcd- und Master-Komponenten auf demselben Host, etcd-Speicher redundant. | Sie können mindestens einen Speichergerätefehler beheben. |
| Redundanz auf verwalteter Ebene | Es gibt keinen Hypervisor, mehrere Instanzen von Komponenten auf verwalteter Ebene in statischen Pods. etcd Cluster auf einem Host, andere Komponenten auf verwalteter Ebene werden getrennt. | Ein Hardwarefehler, das Aktualisieren der Firmware, des Betriebssystems und der Container-Startumgebung auf einem Host ohne etcd ist weniger schädlich. |
| Hinzufügen eines Hypervisors zu beiden Hosts | Drei redundante Komponenten auf verwalteter Ebene werden in virtuellen Maschinen usw. auf einem Host ausgeführt, und Komponenten auf verwalteter Ebene werden getrennt. Anwendungs-Workloads können sich auf beiden VM-Knoten befinden. | Verbesserte Isolation der Anwendungslast. Aktualisierungen des Betriebssystems und der Container-Startumgebung sind weniger störend. Die geplante Wartung von Hardware / Firmware wird zerstörungsfrei, wenn der Hypervisor die VM-Migration unterstützt. |
Bereitstellung auf drei (oder mehr) HostsÜbergang zu kompromisslosem Service in Produktionsqualität. Wir empfehlen, etcd zwischen den drei Hosts aufzuteilen. Ein Hardwarefehler verringert die Anzahl möglicher Anwendungs-Workloads, führt jedoch nicht zu einem vollständigen Serviceausfall.
Sehr große Cluster erfordern mehr Instanzen.
Das Starten einer Hypervisor-Schicht bietet betriebliche Vorteile und eine verbesserte Isolierung der Anwendungs-Workloads. Dies würde den Rahmen des Artikels sprengen, aber auf der Ebene von drei oder mehr Hosts sind möglicherweise verbesserte Funktionen verfügbar (Clustered Redundant Shared Storage, Ressourcenverwaltung mit einem dynamischen Load Balancer, automatisierte Statusüberwachung mit Live-Migration und Failover).
Bereitstellungsoptionen für drei (oder mehr) Hosts, von den am wenigsten für die Produktion geeigneten bis zu den am meisten geeigneten| Typ | Eigenschaften | Ergebnis |
|---|
| Minimum | Drei Gastgeber. Instanz etcd auf jedem Knoten. Hauptkomponenten auf jedem Knoten. | Der Verlust eines Knotens verringert die Leistung, führt jedoch nicht zu einem Rückgang von Kubernetes. Die Möglichkeit der Wiederherstellung bleibt bestehen. |
| Hinzufügen eines Hypervisors zu Hosts | In virtuellen Maschinen auf drei Hosts usw. werden ein API-Server, Scheduler und ein Controller-Manager ausgeführt. Auf jedem Host werden Workloads in der VM ausgeführt. | Schutz vor Betriebssystemfehlern / Container / Software-Startumgebung und menschlichen Fehlern hinzugefügt. Betriebliche Vorteile von Installation, Upgrade, Ressourcenverwaltung, Überwachung und Sicherheit. |
Konfigurieren Sie KubernetesMaster- und Worker-Knoten müssen vor Überlastung und Ressourcenverarmung geschützt werden. Hypervisor-Funktionen können verwendet werden, um kritische Komponenten zu isolieren und Ressourcen zu reservieren. Es gibt auch Kubernetes-Konfigurationseinstellungen, die beispielsweise die Geschwindigkeit von API-Aufrufen verlangsamen können. Einige Installationskits und kommerzielle Distributionen kümmern sich darum. Wenn Sie Kubernetes jedoch selbst bereitstellen, sind die Standardeinstellungen möglicherweise nicht geeignet, insbesondere für kleine Ressourcen oder für einen zu großen Cluster.
Der Ressourcenverbrauch auf überschaubarem Niveau korreliert mit der Anzahl der Herde und der Abflussrate der Herde. Sehr große und sehr kleine Cluster profitieren von den geänderten Einstellungen für die Kube-Apiserver-Anforderung und die Speicherverlangsamung.
Node Allocatable sollte auf den
Worker-Knoten basierend auf der angemessenen unterstützten Lastdichte für jeden Knoten konfiguriert werden. Namespaces können erstellt werden, um einen Cluster von Arbeitsknoten in mehrere virtuelle Cluster mit
Kontingenten für CPU und Speicher aufzuteilen.
SicherheitJeder Kubernetes-Cluster verfügt über eine Stammzertifizierungsstelle (CA). Die Zertifikate Controller Manager, API Server, Scheduler, Kubelet Client, Kube-Proxy und Administrator müssen generiert und installiert werden. Wenn Sie ein Installationstool oder eine Distribution verwenden, müssen Sie sich möglicherweise nicht selbst darum kümmern. Der manuelle Vorgang wird
hier beschrieben. Sie sollten bereit sein, Zertifikate neu zu installieren, wenn Sie die Knoten erweitern oder ersetzen.
Da Kubernetes vollständig von der API verwaltet wird, muss die Liste der Personen, die Zugriff auf den Cluster haben, unbedingt gesteuert und eingeschränkt werden. Verschlüsselungs- und Authentifizierungsoptionen werden in dieser Dokumentation erläutert.
Kubernetes-Anwendungs-Workloads basieren auf Container-Images. Sie benötigen die Quelle und den Inhalt dieser Bilder, um zuverlässig zu sein. Dies bedeutet fast immer, dass Sie das Container-Image im lokalen Repository hosten. Die Verwendung von Bildern aus dem öffentlichen Internet kann zu Zuverlässigkeits- und Sicherheitsproblemen führen. Sie müssen ein Repository auswählen, das das Signieren des Bildes, das Scannen der Sicherheit, das Steuern des Zugriffs zum Senden und Herunterladen von Bildern und das Protokollieren von Aktivitäten unterstützt.
Prozesse müssen so konfiguriert sein, dass sie die Verwendung von Host-, Hypervisor-, OS6-, Kubernetes- und anderen Abhängigkeits-Firmware-Updates unterstützen. Die Versionsüberwachung ist erforderlich, um die Überwachung zu unterstützen.
Empfehlungen:
- Verbessern Sie die Standardsicherheitseinstellungen für Komponenten auf verwalteter Ebene (z. B. Blockieren von Worker-Knoten ).
- Verwenden Sie die Herd-Sicherheitsrichtlinie .
- Denken Sie an die für Ihre Netzwerklösung verfügbare NetworkPolicy- Integration, einschließlich Nachverfolgung, Überwachung und Fehlerbehebung.
- Verwenden Sie RBAC, um Autorisierungsentscheidungen zu treffen.
- Denken Sie an die physische Sicherheit, insbesondere bei der Bereitstellung an peripheren oder Remote-Standorten, die möglicherweise übersehen werden. Fügen Sie Speicherverschlüsselung hinzu, um die Folgen von Gerätediebstahl zu begrenzen, und schützen Sie sich vor dem Anschließen bösartiger Geräte wie USB-Sticks.
- Schützen Sie die Textanmeldeinformationen des Cloud-Anbieters (Zugriffsschlüssel, Token, Kennwörter usw.).
Geheime Objekte von Kubernetes eignen sich zum Speichern kleiner Mengen sensibler Daten. Sie werden in etcd gespeichert. Sie können sicher zum Speichern von Anmeldeinformationen der Kubernetes-API verwendet werden. Manchmal erfordert jedoch eine Workload oder die Erweiterung des Clusters selbst eine umfassendere Lösung. Das HashiCorp Vault-Projekt ist eine beliebte Lösung, wenn Sie mehr benötigen, als die integrierten geheimen Objekte bieten können.
Notfallwiederherstellung und -sicherung
Durch die Implementierung von Redundanz durch die Verwendung mehrerer Hosts und VMs wird die Anzahl bestimmter Arten von Fehlern verringert. Szenarien wie eine Naturkatastrophe, ein schlechtes Update, ein Hackerangriff, Softwarefehler oder ein menschlicher Fehler können jedoch immer noch zu Abstürzen führen.
Ein kritischer Teil einer Produktionsbereitstellung ist die Erwartung einer zukünftigen Wiederherstellung.
Es ist auch erwähnenswert, dass ein Teil Ihrer Investition in Design, Dokumentation und Automatisierung des Wiederherstellungsprozesses wiederverwendet werden kann, wenn Sie umfangreiche replizierte Bereitstellungen an mehreren Standorten benötigen.
Unter den Elementen der Notfallwiederherstellung sind Backups (und möglicherweise Replikate), Ersetzungen, der geplante Prozess, die Personen, die diesen Prozess durchführen, und regelmäßige Schulungen erwähnenswert.
Die häufigen Testübungen und -prinzipien von
Chaos Engineering können verwendet werden, um Ihre Bereitschaft zu testen.
Aufgrund der Verfügbarkeitsanforderungen müssen Sie möglicherweise lokale Kopien des Betriebssystems, der Kubernetes-Komponenten und der Container-Images speichern, um die Wiederherstellung auch bei einem Absturz des Internets zu ermöglichen. Die Möglichkeit, Ersatzhosts und -knoten in einer Situation der „physischen Isolation“ bereitzustellen, verbessert die Sicherheit und erhöht die Bereitstellungsgeschwindigkeit.
Alle Kubernetes-Objekte werden in etcd gespeichert. Das regelmäßige Sichern von etcd-Clusterdaten ist ein wichtiges Element beim Wiederherstellen von Kubernetes-Clustern in Notfallszenarien, z. B. wenn alle Masterknoten verloren gehen.
etcd
etcd . Kubernetes . , Kubernetes.
, Kubernetes etcd , - . , .
etcd. , , , , /. , . :
- : CA, API Server, Apiserver-kubelet-client, ServiceAccount, “Front proxy”, Front proxy;
- DNS;
- IP/;
- ;
- kubeconfig;
- LDAP ;
- .
Anti-affinity . , . , Kubernetes , . , , - .
, .
stateful-, — Kubernetes (, SQL ). , , Kubernetes,
roadmap feature request , , , Container Storage Interface (CSI). , - , , . , Kubernetes , , , Kubernetes .
stateful- (, Cassandra) , , . - Kubernetes ( -) .
( ) , , . , , .
, (,
Ansible ,
BOSH ,
Chef ,
Juju ,
kubeadm ,
Puppet .). , .
, , , , , , . , Git, .
, , — . 2 , — . — , .

— . - , Airbus A320 — . , . , .
, . , , , . Kubernetes , - , , (, FedEx, Amazon).
production-grade Kubernetes . . , , , , . , (, Kubernetes
self-hostingkeine statischen Herde). Vielleicht sollten sie in den folgenden Artikeln besprochen werden, wenn genügend Interesse besteht. Aufgrund der hohen Geschwindigkeit der Verbesserung von Kubernetes sind einige Materialien möglicherweise bereits sehr veraltet, wenn Ihre Suchmaschine diesen Artikel nach 2019 gefunden hat.DAS ENDE
Wie immer warten wir hier auf Ihre Fragen und Kommentare, und Sie können zum Tag der offenen Tür von Alexander Titov gehen .