 Tensorprozessor der 3. GenerationGoogle Tensor Processor
Tensorprozessor der 3. GenerationGoogle Tensor Processor ist ein
ASIC (Special Purpose Integrated Circuit), der von Google von Grund auf für maschinelle Lernaufgaben entwickelt wurde. Er arbeitet an mehreren wichtigen Google-Produkten, darunter Übersetzen, Fotos, Suchassistent und Google Mail. Cloud TPU bietet allen Entwicklern und Datenwissenschaftlern, die modernste Modelle für maschinelles Lernen in der Google Cloud einführen, die Vorteile der Skalierbarkeit und Benutzerfreundlichkeit. Auf der Google Next '18 haben wir angekündigt, dass Cloud TPU v2 jetzt für alle Benutzer verfügbar ist, einschließlich
kostenloser Testkonten , und Cloud TPU v3 für Alpha-Tests verfügbar ist.

Aber viele Leute fragen - was ist der Unterschied zwischen CPU, GPU und TPU? Wir haben eine
Demo-Site erstellt, auf der sich die Präsentation und die Animation befinden, die diese Frage beantworten. In diesem Beitrag möchte ich auf bestimmte Merkmale des Inhalts dieser Website eingehen.
Wie funktionieren neuronale Netze?
Bevor Sie mit dem Vergleich von CPU, GPU und TPU beginnen, schauen wir uns an, welche Berechnungen für maschinelles Lernen erforderlich sind - und insbesondere für neuronale Netze.
Stellen Sie sich zum Beispiel vor, wir verwenden ein einschichtiges neuronales Netzwerk, um handgeschriebene Zahlen zu erkennen, wie in der folgenden Abbildung dargestellt:
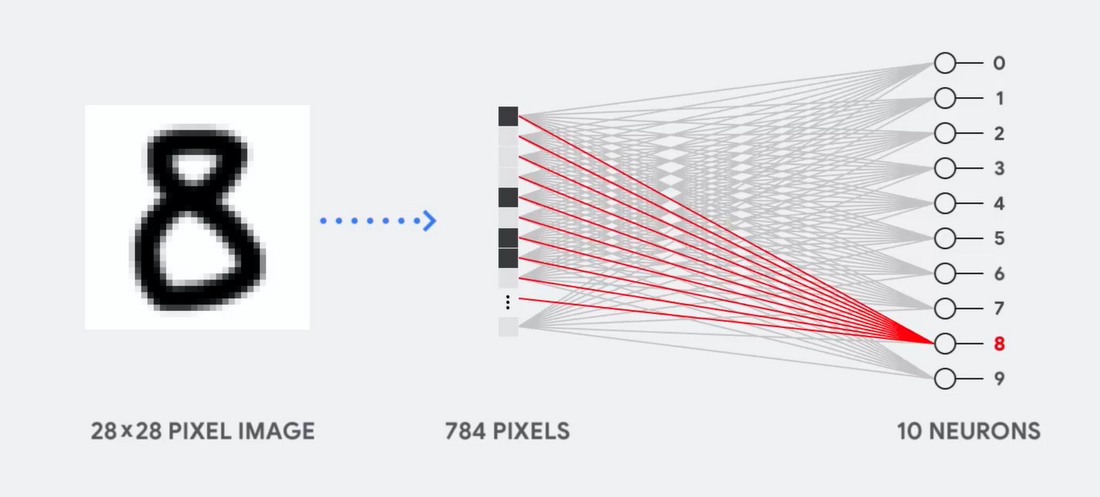
Wenn das Bild ein Raster von 28 x 28 Pixel in Graustufen ist, kann es in einen Vektor mit 784 Werten (Messungen) konvertiert werden. Ein Neuron, das die Zahl 8 erkennt, nimmt diese Werte und multipliziert sie mit den Parameterwerten (rote Linien im Diagramm).
Der Parameter fungiert als Filter und extrahiert Merkmale der Daten, die die Ähnlichkeit von Bild und Form 8 anzeigen:

Dies ist die einfachste Erklärung für die Klassifizierung von Daten durch neuronale Netze. Multiplikation von Daten mit den entsprechenden Parametern (Färbung von Punkten) und deren Addition (Summe der Punkte rechts). Das höchste Ergebnis zeigt die beste Übereinstimmung zwischen den eingegebenen Daten und dem entsprechenden Parameter an, was höchstwahrscheinlich die richtige Antwort ist.
Einfach ausgedrückt, müssen neuronale Netze eine große Anzahl von Multiplikationen und Additionen von Daten und Parametern durchführen. Oft organisieren wir sie in Form einer
Matrixmultiplikation , die in der Schule in der Algebra auftreten kann. Daher besteht das Problem darin, eine große Anzahl von Matrixmultiplikationen so schnell wie möglich durchzuführen und so wenig Energie wie möglich zu verbrauchen.
Wie funktioniert eine CPU?
Wie geht die CPU mit dieser Aufgabe um? Die CPU ist ein Allzweckprozessor, der auf der
von Neumann-Architektur basiert. Dies bedeutet, dass die CPU wie folgt mit Software und Speicher arbeitet:
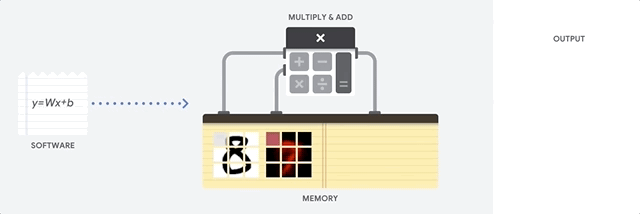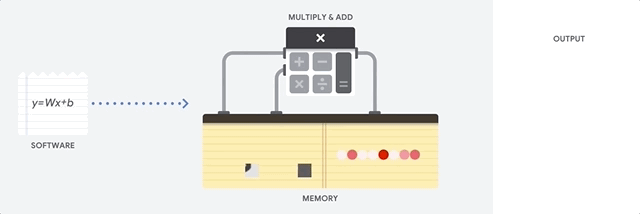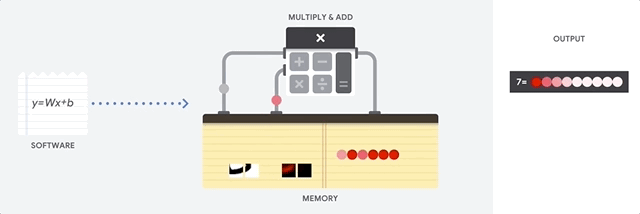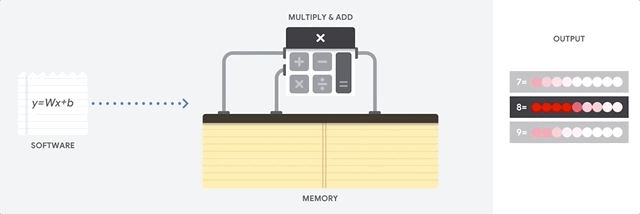
Der Hauptvorteil der CPU ist die Flexibilität. Dank der von Neumann-Architektur können Sie völlig unterschiedliche Software für Millionen verschiedener Zwecke herunterladen. Die CPU kann für Textverarbeitung, Raketentriebwerkssteuerung, Bankgeschäfte und Bildklassifizierung unter Verwendung eines neuronalen Netzwerks verwendet werden.
Da die CPU jedoch so flexibel ist, weiß das Gerät nicht immer im Voraus, wie der nächste Vorgang aussehen wird, bis es die nächste Anweisung aus der Software liest. Die CPU muss die Ergebnisse jeder Berechnung im Speicher innerhalb der CPU speichern (die sogenannten Register oder den
L1-Cache ). Der Zugriff auf diesen Speicher wird zu einem Minus der CPU-Architektur, die als von Neumann-Architekturengpass bekannt ist. Und obwohl eine große Anzahl von Berechnungen für neuronale Netze zukünftige Schritte vorhersehbar macht, führt jede
arithmetische Logikvorrichtung der CPU (ALU, eine Komponente, die Multiplikatoren und Addierer speichert und steuert) Operationen nacheinander aus und greift jedes Mal auf Speicher zu, was den Gesamtdurchsatz begrenzt und eine erhebliche Menge an Energie verbraucht .
Wie die GPU funktioniert
Um den Durchsatz im Vergleich zur CPU zu erhöhen, verwendet die GPU eine einfache Strategie: Warum nicht Tausende von ALUs in den Prozessor integrieren? Die moderne GPU enthält etwa 2500 - 5000 ALU auf dem Prozessor, wodurch Tausende von Multiplikationen und Additionen gleichzeitig durchgeführt werden können.

Eine solche Architektur funktioniert gut mit Anwendungen, die eine massive Parallelisierung erfordern, wie beispielsweise der Matrixmultiplikation in einem neuronalen Netzwerk. Bei einer typischen Trainingslast von Deep Learning (GO) erhöht sich der Durchsatz in diesem Fall im Vergleich zur CPU um eine Größenordnung. Daher ist die GPU heute die beliebteste Prozessorarchitektur für GO.
Die GPU bleibt jedoch ein Allzweckprozessor, der eine Million verschiedener Anwendungen und Software unterstützen muss. Und das bringt uns zurück zum Grundproblem des von Neumann-Architekturengpasses. Für jede Berechnung in Tausenden von ALUs, GPUs, muss auf Register oder gemeinsam genutzten Speicher verwiesen werden, um Zwischenberechnungsergebnisse zu lesen und zu speichern. Da die GPU auf Tausenden ihrer ALUs mehr paralleles Rechnen ausführt, verbraucht sie auch proportional mehr Energie für den Speicherzugriff und nimmt einen großen Bereich ein.
Wie funktioniert TPU?
Bei der Entwicklung von TPU bei Google haben wir eine Architektur erstellt, die für eine bestimmte Aufgabe entwickelt wurde. Anstatt einen Allzweckprozessor zu entwickeln, haben wir einen Matrixprozessor entwickelt, der auf die Arbeit mit neuronalen Netzen spezialisiert ist. TPU wird nicht in der Lage sein, mit einem Textverarbeitungsprogramm zu arbeiten, Raketentriebwerke zu steuern oder Bankgeschäfte zu tätigen, aber es kann eine große Anzahl von Multiplikationen und Additionen für neuronale Netze mit einer unglaublichen Geschwindigkeit verarbeiten, während es viel weniger Energie verbraucht und in ein kleineres physisches Volumen passt.
Die Hauptsache, die ihm dies ermöglicht, ist die radikale Beseitigung des von Neumann-Architekturengpasses. Da die Hauptaufgabe von TPU die Matrixverarbeitung ist, waren die Schaltungsentwickler mit allen erforderlichen Berechnungsschritten vertraut. Daher konnten sie Tausende von Multiplikatoren und Addierern platzieren und physikalisch verbinden, um eine große physikalische Matrix zu bilden. Dies wird als
Pipeline-Array-Architektur bezeichnet . Im Fall von Cloud TPU v2 werden zwei Pipeline-Arrays von 128 x 128 verwendet, was insgesamt 32.768 ALUs für 16-Bit-Gleitkommawerte auf einem Prozessor ergibt.
Mal sehen, wie ein Pipeline-Array Berechnungen für ein neuronales Netzwerk durchführt. Zunächst lädt die TPU die Parameter aus dem Speicher in eine Matrix aus Multiplikatoren und Addierern.

Die TPU lädt dann die Daten aus dem Speicher. Nach Abschluss jeder Multiplikation wird das Ergebnis an die folgenden Faktoren übertragen, während Additionen durchgeführt werden. Daher ist die Ausgabe die Summe aller Multiplikationen der Daten und Parameter. Während des gesamten Prozesses der volumetrischen Berechnung und Datenübertragung ist der Zugriff auf den Speicher völlig unnötig.
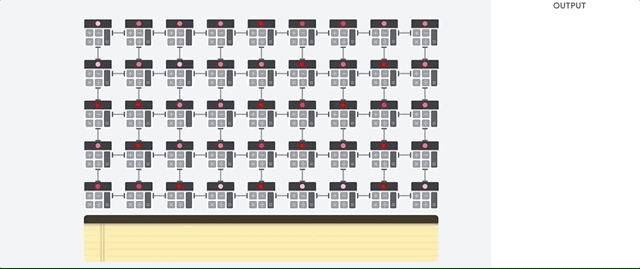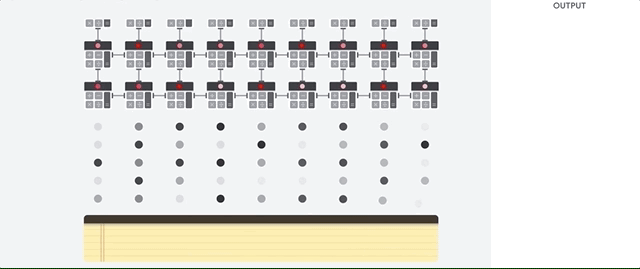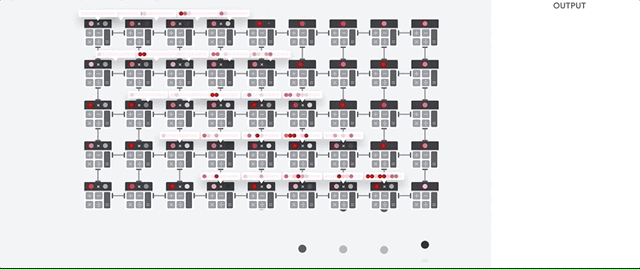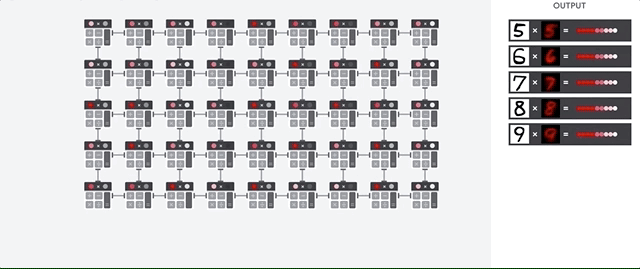
Daher zeigt TPU einen höheren Durchsatz bei der Berechnung für neuronale Netze, verbraucht viel weniger Energie und nimmt weniger Platz ein.
Vorteil: 5 mal weniger Kosten
Was sind die Vorteile der TPU-Architektur? Kosten. Hier sind die Kosten für Cloud TPU v2 für August 2018 zum Zeitpunkt des Schreibens:
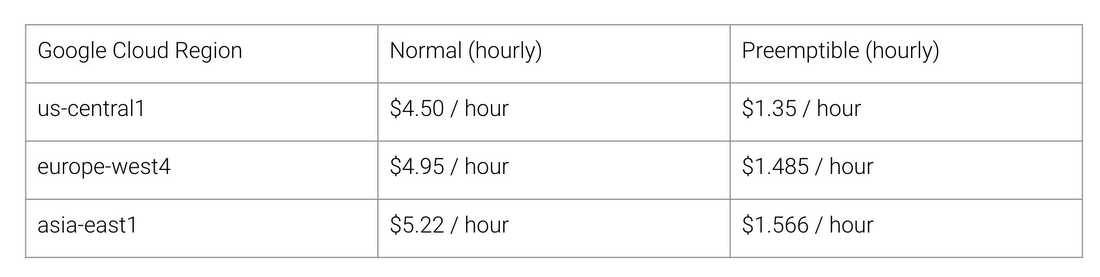
Normale und TPU-Arbeitskosten für verschiedene Regionen von Google Cloud
Die Stanford University verteilt eine Reihe von
DAWNBench- Tests, mit denen die Leistung von Deep-Learning-Systemen gemessen wird. Dort können Sie verschiedene Kombinationen von Aufgaben, Modellen und Computerplattformen sowie die entsprechenden Testergebnisse anzeigen.
Zum Ende des Wettbewerbs im April 2018 betrugen die Mindestschulungskosten für Prozessoren mit einer anderen Architektur als TPU 72,40 USD (für die Schulung von ResNet-50 mit einer Genauigkeit von 93% für ImageNet vor
Ort ). Mit Cloud TPU v2 kann dieses Training für 12,87 USD durchgeführt werden. Dies ist weniger als 1/5 der Kosten. Dies ist die Kraft der Architektur, die speziell für neuronale Netze entwickelt wurde.