
Leider gibt es im Internet nicht genügend Informationen über die Migration realer Anwendungen und den Produktionsbetrieb des Percona XtraDB-Clusters (im Folgenden: PXC). Ich werde versuchen, diese Situation zu korrigieren und über unsere Erfahrungen mit meiner Geschichte zu berichten. Es gibt keine schrittweisen Installationsanweisungen und der Artikel sollte nicht als Ersatz für Off-Dokumentation betrachtet werden, sondern als Sammlung von Empfehlungen.
Das Problem
Ich arbeite als Systemadministrator bei
ultimative-guitar.com . Da wir einen Webdienst bereitstellen, verfügen wir natürlich über Backends und eine Datenbank, die den Kern des Dienstes bildet. Die Verfügbarkeit des Dienstes hängt direkt von der Datenbankleistung ab.
Als Datenbank wurde Percona MySQL 5.7 verwendet. Die Reservierung wurde mit dem Master-Replikationsschema-Master implementiert. Slaves wurden verwendet, um einige Daten zu lesen.
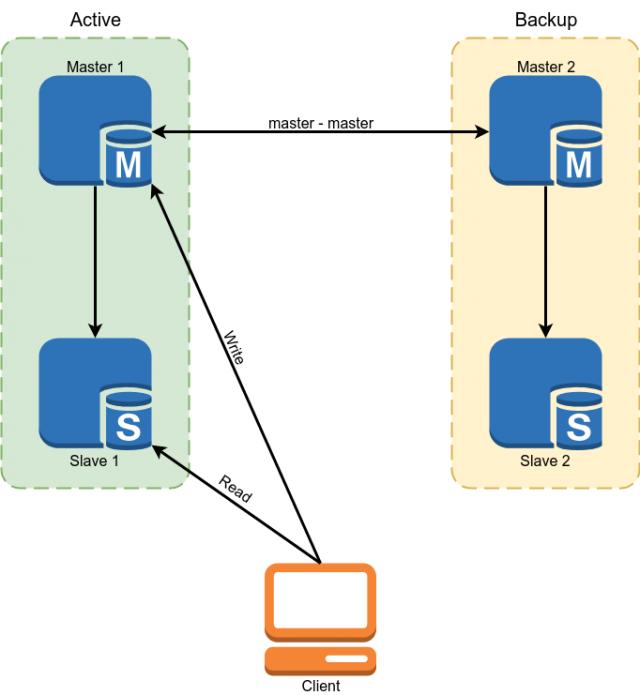
Dieses Schema hatte jedoch nicht die folgenden Nachteile:
- Aufgrund der Tatsache, dass bei der MySQL-Replikation asynchrone Slaves auf unbestimmte Zeit verzögert werden können. Alle kritischen Daten mussten vom Master gelesen werden.
- Aus dem vorherigen Absatz folgt die Komplexität der Entwicklung. Der Entwickler konnte nicht nur eine Anfrage an die Datenbank stellen, sondern musste darüber nachdenken, ob er jeweils für den Rückstand des Slaves bereit war, und wenn nicht, die Daten aus dem Assistenten lesen.
- Manuelles Schalten im Falle eines Unfalls. Die Implementierung der automatischen Umschaltung war problematisch, da die MySQL-Architektur keinen integrierten Schutz gegen Split Brain bietet. Wir müssten uns einen Schiedsrichter mit einer komplexen Logik der Wahl eines Meisters schreiben. Beim Schreiben an beide Master können gleichzeitig Konflikte auftreten, die die Master-Replikation unterbrechen und zum klassischen Split-Brain führen.
Ein paar trockene Zahlen, damit Sie verstehen, womit wir gearbeitet haben:
Datenbankgröße: 300 GB
QPS: ~ 10k
RW-Verhältnis: 96/4%
Master Server Konfiguration:
CPU: 2x E5-2620 v3
RAM: 128 GB
SSD: Intel Optane 905p 960 GB
Netzwerk: 1 Gbit / s
Wir haben eine klassische OLTP-Last mit viel Lesen, die sehr schnell und mit wenig Schreiben erledigt werden muss. Die Belastung der Datenbank ist recht gering, da das Caching in Redis und Memcached aktiv verwendet wird.
Entscheidungsauswahl
Wie Sie vielleicht aus dem Titel erraten haben, haben wir PXC gewählt, aber hier werde ich erklären, warum wir es gewählt haben.
Wir hatten 4 Möglichkeiten:
- DBMS ändern
- MySQL-Gruppenreplikation
- Schrauben Sie die erforderlichen Funktionen selbst mithilfe von Skripten über den Master-Replikationsmaster.
- MySQL Galera Cluster (oder seine Gabeln, zum Beispiel PXC)
Die Option zum Ändern der Datenbank wurde praktisch nicht in Betracht gezogen, weil Die Anwendung ist groß, an vielen Stellen an die MySQL-Funktionalität oder -Syntax gebunden, und die Migration zu PostgreSQL erfordert beispielsweise viel Zeit und Ressourcen.
Die zweite Option war MySQL Group Replication. Ein zweifelsfreier Vorteil ist, dass es sich im Vanille-Zweig von MySQL entwickelt, was bedeutet, dass es in Zukunft weit verbreitet sein und einen großen Pool aktiver Benutzer haben wird.
Aber er hat ein paar Nachteile. Erstens werden das Anwendungs- und Datenbankschema stärker eingeschränkt, was bedeutet, dass die Migration schwieriger wird. Zweitens löst die Gruppenreplikation das Problem der Fehlertoleranz und des geteilten Gehirns, aber die Replikation im Cluster ist immer noch asynchron.
Die dritte Option für zu viele Fahrräder hat uns auch nicht gefallen, die wir zwangsläufig implementieren müssen, um das Problem auf diese Weise zu lösen.
Galera erlaubte es, das MySQL-Failover-Problem vollständig zu lösen und das Problem teilweise mit der Relevanz der Daten auf den Slaves zu lösen. Zum Teil, weil die Replikationsasynchronität erhalten bleibt. Nachdem eine Transaktion auf einem lokalen Knoten festgeschrieben wurde, werden die Änderungen asynchron auf die verbleibenden Knoten übertragen. Der Cluster stellt jedoch sicher, dass die Knoten nicht zu stark verzögert werden, und verlangsamt die Arbeit künstlich, wenn sie zu verzögern beginnen. Der Cluster stellt sicher, dass nach dem Festschreiben der Transaktion niemand widersprüchliche Änderungen festschreiben kann, selbst auf dem Knoten, der die Änderungen noch nicht repliziert hat.
Nach der Migration sollte das Datenbankoperationsschema folgendermaßen aussehen:
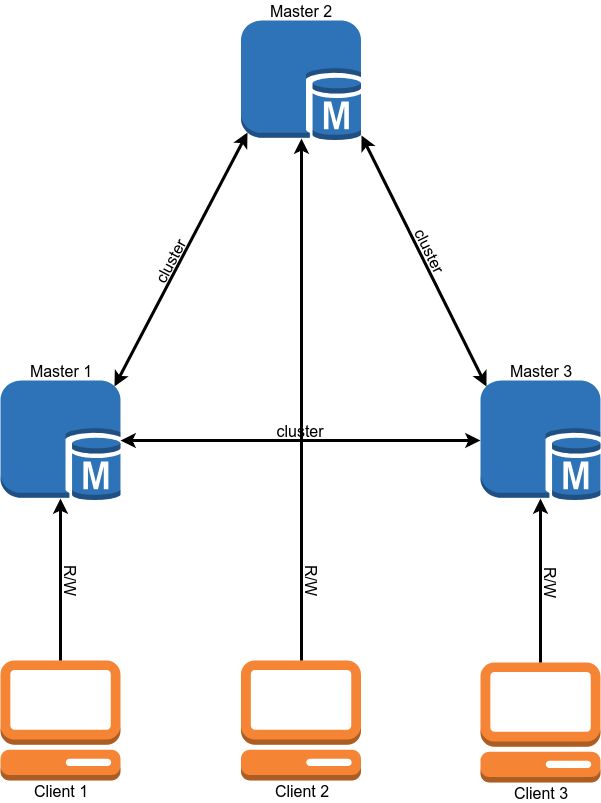
Die Migration
Warum ist Migration das zweite Element nach Auswahl einer Lösung? Es ist ganz einfach: Der Cluster enthält eine Reihe von Anforderungen, denen die Anwendung und die Datenbank entsprechen müssen, und diese müssen vor der Migration erfüllt werden.
- InnoDB-Engine für alle Tabellen. MyISAM, Memory und andere Backends werden nicht unterstützt. Es ist ganz einfach behoben - wir konvertieren alle Tabellen in InnoDB.
- Binlog im ROW-Format. Der Cluster benötigt kein Binlog, um zu funktionieren. Wenn Sie keine klassischen Slaves benötigen, können Sie ihn deaktivieren. Das Binlog-Format sollte jedoch ROW sein.
- Alle Tabellen müssen einen PRIMARY / FOREIGN KEY haben. Dies ist erforderlich, damit von verschiedenen Knoten aus gleichzeitig in dieselbe Tabelle geschrieben werden kann. Für Tabellen, die keinen eindeutigen Schlüssel enthalten, können Sie den zusammengesetzten Primärschlüssel oder das automatische Inkrementieren verwenden.
- Verwenden Sie für Transaktionen nicht 'LOCK TABLES', 'GET_LOCK () / RELEASE_LOCK ()', 'FLUSH TABLES {{table}} WITH READ LOCK' oder die Isolationsstufe 'SERIALIZABLE'.
- Verwenden Sie nicht die Abfragen 'CREATE TABLE ... AS SELECT' , as Sie kombinieren Schema und Datenänderung. Es ist leicht in zwei Abfragen zu unterteilen, von denen die erste eine Tabelle erstellt und die zweite mit Daten füllt.
- Verwenden Sie nicht 'DISCARD TABLESPACE' und 'IMPORT TABLESPACE' als Sie werden nicht repliziert
- Setzen Sie die Optionen 'innodb_autoinc_lock_mode' auf '2'. Diese Option kann Daten beschädigen, wenn mit der STATEMENT-Replikation gearbeitet wird. Da jedoch nur die ROW-Replikation im Cluster zulässig ist, treten keine Probleme auf.
- Als 'log_output' wird nur 'FILE' unterstützt. Wenn Sie einen Protokolleintrag in der Tabelle haben, müssen Sie ihn entfernen.
- XA-Transaktionen werden nicht unterstützt. Wenn sie verwendet wurden, müssen Sie den Code ohne sie neu schreiben.
Ich sollte beachten, dass fast alle diese Einschränkungen aufgehoben werden können, wenn Sie die Variable "pxc_strict_mode = PERMISSIVE" setzen. Wenn Ihre Daten für Sie jedoch wichtig sind, ist es besser, dies nicht zu tun. Wenn Sie 'pxc_strict_mode = ENFORCING' festgelegt haben, können Sie mit MySQL die oben genannten Vorgänge nicht ausführen oder den Start des Knotens verhindern.
Nachdem wir alle Anforderungen an die Datenbank erfüllt und den Betrieb unserer Anwendung in der Entwicklungsumgebung gründlich getestet haben, können wir mit der nächsten Stufe fortfahren.
Clusterbereitstellung und -konfiguration
Auf unseren Datenbankservern werden mehrere Datenbanken ausgeführt, und andere Datenbanken müssen nicht in den Cluster migriert werden. Ein Paket mit MySQL-Cluster ersetzt jedoch das klassische MySQL. Wir hatten verschiedene Lösungen für dieses Problem:
- Verwenden Sie die Virtualisierung und starten Sie den Cluster in VM. Diese Option hat uns aufgrund der hohen (im Vergleich zu den übrigen) Gemeinkosten und des Auftretens eines anderen Unternehmens, das gewartet werden muss, nicht gefallen
- Erstellen Sie Ihre Version des Pakets, wodurch MySQL an einem nicht standardmäßigen Ort platziert wird. Somit ist es möglich, mehrere Versionen von MySQL auf einem Server zu haben. Eine gute Option, wenn Sie viele Server haben, aber die ständige Unterstützung Ihres Pakets, die regelmäßig aktualisiert werden muss, kann viel Zeit in Anspruch nehmen.
- Verwenden Sie Docker.
Wir haben Docker ausgewählt, verwenden es jedoch in der Mindestoption. Für die Datenspeicherung werden lokale Volumes verwendet. Der Betriebsmodus '--net host' wird verwendet, um die Netzwerklatenz und die CPU-Auslastung zu reduzieren.
Wir mussten auch unsere eigene Version des Docker-Images erstellen. Der Grund dafür ist, dass das Standard-Image von Percona die Wiederherstellungsposition beim Start nicht unterstützt. Dies bedeutet, dass bei jedem Neustart der Instanz keine schnelle IST-Synchronisierung durchgeführt wird, bei der nur die erforderlichen Änderungen hochgeladen werden, sondern ein langsamer SST, der die Datenbank vollständig neu lädt.
Ein weiteres Problem ist die Clustergröße. In einem Cluster speichert jeder Knoten den gesamten Datensatz. Daher lässt sich das Lesen mit zunehmender Clustergröße perfekt skalieren. Mit dem Datensatz ist die Situation umgekehrt: Beim Festschreiben wird jede Transaktion auf das Fehlen von Konflikten auf allen Knoten überprüft. Je mehr Knoten vorhanden sind, desto länger dauert das Festschreiben natürlich.
Hier haben wir auch mehrere Möglichkeiten:
- 2 Knoten + Arbiter. 2 Knoten + Arbiter. Eine gute Option für Tests. Während der Bereitstellung des zweiten Knotens sollte der Master nicht aufzeichnen.
- 3 Knoten. Die klassische Version. Gleichgewicht zwischen Geschwindigkeit und Zuverlässigkeit. Bitte beachten Sie, dass in dieser Konfiguration ein Knoten die gesamte Last dehnen muss, weil Zum Zeitpunkt des Hinzufügens des 3. Knotens ist der zweite der Spender.
- 4+ Knoten. Bei einer geraden Anzahl von Knoten muss ein Arbiter hinzugefügt werden, um ein Split-Brain zu vermeiden. Eine Option, die für sehr viel Lesen gut funktioniert. Die Zuverlässigkeit des Clusters wächst ebenfalls.
Wir haben uns bisher für die Option mit 3 Knoten entschieden.
Die Cluster-Konfiguration kopiert die eigenständige MySQL-Konfiguration fast vollständig und unterscheidet sich nur in wenigen Optionen:
"Wsrep_sst_method = xtrabackup-v2" Diese Option legt die Methode zum Kopieren von Knoten fest. Andere Optionen sind mysqldump und rsync, aber sie blockieren den Knoten für die Dauer der Kopie. Ich sehe keinen Grund, die Nicht-xtrabackup-v2-Kopiermethode zu verwenden.
"Gcache" ist ein Analogon zum Cluster-Binlog. Es ist ein kreisförmiger Puffer (in einer Datei) fester Größe, in den alle Änderungen geschrieben werden. Wenn Sie einen der Clusterknoten ausschalten und dann wieder einschalten, wird versucht, die fehlenden Änderungen aus Gcache zu lesen (IST-Synchronisation). Wenn die vom Knoten erforderlichen Änderungen nicht vorhanden sind, ist ein vollständiges Neuladen des Knotens (SST-Synchronisation) erforderlich. Die Größe von gcache wird wie folgt festgelegt: wsrep_provider_options = 'gcache.size = 20G;'.
wsrep_slave_threads Im Gegensatz zur klassischen Replikation in einem Cluster können mehrere Schreibsätze parallel auf dieselbe Datenbank
angewendet werden . Diese Option gibt die Anzahl der Mitarbeiter an, die die Änderungen anwenden. Es ist besser, den Standardwert 1 nicht zu belassen, weil Während der Arbeit eines großen Schreibsatzes durch den Worker wartet der Rest in der Warteschlange und die Knotenreplikation beginnt zu verzögern. Einige empfehlen, diesen Parameter auf 2 * CPU THREADS zu setzen, aber ich denke, Sie müssen sich die Anzahl der gleichzeitigen Schreibvorgänge ansehen, die Sie haben.
Wir haben uns für den Wert 64 entschieden. Bei einem niedrigeren Wert gelang es dem Cluster manchmal nicht, alle Schreibsätze aus der Warteschlange während Lastbursts anzuwenden (z. B. beim Starten schwerer Kronen).
wsrep_max_ws_size Die Größe einer einzelnen Transaktion in einem Cluster ist auf 2 GB begrenzt. Große Transaktionen passen jedoch nicht gut zum PXC-Konzept. Es ist besser, 100 Transaktionen mit jeweils 20 MB abzuschließen als eine pro 2 GB. Daher haben wir zuerst die Transaktionsgröße im Cluster auf 100 MB begrenzt und dann das Limit auf 50 MB reduziert.
Wenn Sie den strengen Modus aktiviert haben, können Sie die Variable "
binlog_row_image " auf "minimal" setzen. Dadurch wird die Größe der Einträge im Binlog um ein Vielfaches reduziert (10-mal im Test von Percona). Dies spart Speicherplatz und ermöglicht Transaktionen, die nicht in das Limit mit "binlog_row_image = full" passen.
Grenzwerte für SST. Für Xtrabackup, mit dem Knoten gefüllt werden, können Sie die Netzwerknutzung, die Anzahl der Threads und die Komprimierungsmethode begrenzen. Dies ist erforderlich, damit der Donor-Server beim Befüllen des Knotens nicht langsamer wird. Dazu wird der Datei my.cnf der Abschnitt "sst" hinzugefügt:
[sst] rlimit = 80m compressor = "pigz -3" decompressor = "pigz -dc" backup_threads = 4
Wir begrenzen die Kopiergeschwindigkeit auf 80 Mb / s. Wir verwenden pigz für die Komprimierung. Dies ist eine Multithread-Version von gzip.
GTID Wenn Sie klassische Slaves verwenden, empfehle ich, GTID im Cluster zu aktivieren. Auf diese Weise können Sie den Slave mit einem beliebigen Knoten des Clusters verbinden, ohne den Slave neu laden zu müssen.
Zusätzlich möchte ich über 2 Clustermechanismen sprechen, deren Bedeutung und Konfiguration.
Flusskontrolle
Die Flusskontrolle ist eine Möglichkeit, die Schreiblast in einem Cluster zu verwalten. Knoten dürfen bei der Replikation nicht zu weit zurückbleiben. Auf diese Weise wird eine "fast synchrone" Replikation erreicht. Der Funktionsmechanismus ist recht einfach: Sobald die Länge der Empfangswarteschlange den eingestellten Wert erreicht, wird die Nachricht "Flusssteuerungspause" an die anderen Knoten gesendet, die sie auffordert, mit dem Festschreiben neuer Transaktionen zu pausieren, bis der nacheilende Knoten das Harken der Warteschlange beendet hat .
Daraus ergeben sich mehrere Dinge:
- Die Aufzeichnung im Cluster erfolgt mit der Geschwindigkeit des langsamsten Knotens. (Aber es kann verschärft werden.)
- Wenn beim Festschreiben von Transaktionen viele Konflikte auftreten, können Sie Flow Control aggressiver konfigurieren, wodurch sich die Anzahl verringern sollte.
- Die maximale Verzögerung eines Knotens in einem Cluster ist eine Konstante, jedoch nicht nach Zeit, sondern nach Anzahl der Transaktionen in der Warteschlange. Die Verzögerungszeit hängt von der durchschnittlichen Transaktionsgröße und der Anzahl der wsrep_slave_threads ab.
Sie können die Einstellungen für die Flusskontrolle folgendermaßen anzeigen:
mysql> SHOW GLOBAL STATUS LIKE 'wsrep_flow_control_interval_%';
wsrep_flow_control_interval_low | 36
wsrep_flow_control_interval_high | 71
Zunächst interessiert uns der Parameter wsrep_flow_control_interval_high. Es steuert die Länge der Warteschlange, nach der die FC-Pause aktiviert wird. Dieser Parameter wird nach folgender Formel berechnet: gcs.fc_limit * √N (wobei N = Anzahl der Knoten im Cluster).
Der zweite Parameter ist wsrep_flow_control_interval_low. Es ist für den Wert der Warteschlangenlänge verantwortlich, bei deren Erreichen der FC ausgeschaltet wird. Berechnet nach der Formel: wsrep_flow_control_interval_high * gcs.fc_factor. Standardmäßig ist gcs.fc_factor = 1.
Durch Ändern der Länge der Warteschlange können wir also die Replikationsverzögerung steuern. Durch Verringern der Länge der Warteschlange wird die Zeit erhöht, die der Cluster in der FC-Pause verbringt, die Verzögerung der Knoten wird jedoch verringert.
Sie können die Sitzungsvariable "
wsrep_sync_wait = 7"
festlegen . Dadurch wird der PXC gezwungen, Lese- oder Schreibanforderungen erst auszuführen, nachdem alle Schreibsätze in der aktuellen Warteschlange angewendet wurden. Dies erhöht natürlich die Latenz von Anforderungen. Die Erhöhung der Latenz ist direkt proportional zur Länge der Warteschlange.
Es ist auch wünschenswert, die maximale Transaktionsgröße auf das minimal mögliche zu reduzieren, damit lange Transaktionen nicht versehentlich durchrutschen.
EVS oder Auto Evict
Mit diesem Mechanismus können Sie Knoten auswerfen, die instabil sind (z. B. Paketverlust oder lange Verzögerungen) oder langsam reagieren. Dank dessen können Kommunikationsprobleme mit einem Knoten nicht den gesamten Cluster beeinträchtigen, sondern den Knoten deaktivieren und im normalen Modus weiterarbeiten. Dieser Mechanismus ist besonders nützlich, wenn der Cluster über das WAN oder Teile des Netzwerks betrieben wird, die nicht unter Ihrer Kontrolle stehen. Standardmäßig ist der EFD deaktiviert.
Fügen Sie zum Aktivieren die Option "evs.version = 1;" zum Parameter
wsrep_provider_options hinzu und "evs.auto_evict = 5;" (Die Anzahl der Operationen, nach denen der Knoten ausgeschaltet wird. Der Wert 0 deaktiviert den EFD.) Es gibt auch verschiedene Parameter, mit denen Sie den EFD optimieren können:
- evs.delayed_margin Die Zeit, die ein Knoten benötigt, um zu antworten. Standardmäßig 1 Sek., Wenn Sie jedoch in einem lokalen Netzwerk arbeiten, kann dies auf 0,05-0,1 Sek. Oder weniger reduziert werden.
- evs.inactive_check_period Überprüfungszeitraum. Standard 0,5 Sek
Tatsächlich beträgt die Zeit, die ein Knoten bei Problemen arbeiten kann, bevor der EFD ausgelöst wird, evs.inactive_check_period * evs.auto_evict. Sie können auch "evs.inactive_timeout" festlegen. Ein Knoten, der nicht antwortet, wird sofort gelöscht, standardmäßig 15 Sekunden.
Eine wichtige Nuance ist, dass dieser Mechanismus selbst den Knoten beim Wiederherstellen der Kommunikation nicht zurückgibt. Es muss von Hand neu gestartet werden.
Wir haben den EFD zu Hause eingerichtet, aber wir hatten noch keine Gelegenheit, ihn im Kampf zu testen.
Lastausgleich
Damit Clients die Ressourcen jedes Knotens gleichmäßig nutzen und Anforderungen nur auf Live-Clusterknoten ausführen können, benötigen wir einen Load Balancer. Percona bietet 2 Lösungen:
- ProxySQL. Dies ist der L7-Proxy für MySQL.
- Haproxy. Haproxy weiß jedoch nicht, wie der Status eines Clusterknotens überprüft und festgestellt werden soll, ob er zur Ausführung von Anforderungen bereit ist. Um dieses Problem zu lösen, wird vorgeschlagen, ein zusätzliches percona-clustercheck-Skript zu verwenden
Zuerst wollten wir ProxySQL verwenden, aber nach dem Benchmarking stellte sich heraus, dass die Latenz gegenüber Haproxy um etwa 15 bis 20% abnimmt, selbst wenn der Fast_forward-Modus verwendet wird (das Umschreiben von Abfragen, das Routing und viele andere ProxySQL-Funktionen funktionieren in diesem Modus nicht, Anforderungen werden unverändert weitergeleitet). .
Haproxy ist schneller, aber das Percona-Skript hat einige Nachteile.
Erstens ist es in Bash geschrieben, was nicht zu seiner Anpassung beiträgt. Ein schwerwiegenderes Problem ist, dass das Ergebnis der MySQL-Prüfung nicht zwischengespeichert wird. Wenn wir also 100 Clients haben, von denen jeder alle 1 Sekunde den Status des Knotens überprüft, sendet das Skript alle 10 ms eine Anfrage an MySQL. Wenn MySQL aus irgendeinem Grund langsam zu arbeiten beginnt, erstellt das Validierungsskript eine große Anzahl von Prozessen, was die Situation definitiv nicht verbessern wird.
Es wurde beschlossen,
eine Lösung zu schreiben
, bei der die MySQL-Statusprüfung und die Haproxy-Antwort nicht miteinander zusammenhängen. Das Skript überprüft in regelmäßigen Abständen den Status des Knotens im Hintergrund und speichert das Ergebnis zwischen. Der Webserver gibt Haproxy das zwischengespeicherte Ergebnis.
Beispiel für eine Haproxy-Konfigurationlisten db
bind 127.0.0.1:3302
mode tcp
balance first
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 id 1
server node2 192.168.0.2:3302 check port 9200 backup id 2
server node3 192.168.0.3:3302 check port 9200 backup id 3
listen db_slave
bind 127.0.0.1:4302
mode tcp
balance leastconn
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 backup
server node2 192.168.0.2:3302 check port 9200
server node3 192.168.0.3:3302 check port 9200
Dieses Beispiel zeigt eine einzelne Assistentenkonfiguration. Die verbleibenden Cluster-Server fungieren als Slaves.
Überwachung
Um den Clusterstatus zu überwachen, haben wir Prometheus + mysqld_exporter und Grafana verwendet, um die Daten zu visualisieren. Weil mysqld_exporter sammelt eine Reihe von Metriken, um Dashboards selbst zu erstellen. Dies ist ziemlich mühsam. Sie können vorgefertigte
Dashboards von Percona übernehmen und selbst anpassen.
Wir verwenden Zabbix auch, um grundlegende Cluster-Metriken und Warnungen zu erfassen.
Die wichtigsten Cluster-Metriken, die Sie überwachen möchten:
- wsrep_cluster_status Muss auf allen Knoten auf Primär gesetzt werden. Wenn der Wert "nicht primär" ist, hat dieser Knoten den Kontakt zum Cluster-Quorum verloren.
- wsrep_cluster_size Die Anzahl der Knoten im Cluster. Dies schließt auch "verlorene" Knoten ein, die sich im Cluster befinden müssen, aber aus irgendeinem Grund nicht verfügbar sind. Wenn der Knoten vorsichtig ausgeschaltet wird, nimmt der Wert dieser Variablen ab.
- wsrep_local_state Gibt an, ob der Knoten ein aktives Mitglied des Clusters ist und betriebsbereit ist.
- wsrep_evs_state Ein wichtiger Parameter, wenn Sie die automatische Räumung aktiviert haben (standardmäßig deaktiviert ). Diese Variable gibt an, dass EVS diesen Knoten als fehlerfrei betrachtet.
- wsrep_evs_evict_list Die Liste der Knoten, die von EVS aus dem Cluster geworfen wurden. In einer normalen Situation sollte die Liste leer sein.
- wsrep_evs_delayed Liste der Kandidaten für die Entfernung des EFD. Muss auch leer sein.
Wichtige Leistungskennzahlen:
- wsrep_evs_repl_latency Zeigt die Kommunikationsverzögerung innerhalb des Clusters an (minimale / durchschnittliche / maximale / ältere Abweichung / Paketgröße). Das heißt, es misst die Netzwerklatenz. Steigende Werte können auf eine Überlastung der Netzwerk- oder Clusterknoten hinweisen. Diese Metrik wird auch bei ausgeschaltetem EFD aufgezeichnet.
- wsrep_flow_control_paused_ns Die Zeit (in ns) seit dem Start des Knotens, die er in der Ablaufsteuerungspause verbracht hat. Idealerweise sollte es 0 sein. Das Wachstum dieses Parameters weist auf Probleme mit der Clusterleistung oder das Fehlen von "wsrep_slave_threads" hin. Mit dem Parameter " wsrep_flow_control_sent " können Sie bestimmen, welcher Knoten langsamer wird.
- wsrep_flow_control_paused Der Prozentsatz der Zeit seit der letzten Ausführung von "FLUSH STATUS", die der Knoten in der Flow-Steuerungspause verbracht hat. Neben der vorherigen Variablen sollte sie gegen Null tendieren.
- wsrep_flow_control_status Gibt an, ob Flow Control derzeit ausgeführt wird. Auf dem FC-Pauseninitiierungsknoten ist der Wert dieser Variablen EIN.
- wsrep_local_recv_queue_avg Durchschnittliche Länge der Empfangswarteschlange. Das Wachstum dieses Parameters weist auf Probleme mit der Leistung des Knotens hin.
- wsrep_local_send_queue_avg Die durchschnittliche Länge der Sendewarteschlange . Das Wachstum dieses Parameters weist auf Netzwerkleistungsprobleme hin.
Es gibt keine universellen Empfehlungen zu den Werten dieser Parameter. Es ist klar, dass sie gegen Null tendieren sollten, aber bei realer Last wird dies höchstwahrscheinlich nicht der Fall sein und Sie müssen selbst bestimmen, wo die Grenze des Normalzustands des Clusters verläuft.
Backup
Cluster-Backup unterscheidet sich praktisch nicht von Standalone-MySQL. Für den Produktionseinsatz haben wir mehrere Möglichkeiten.
- Entfernen Sie das Backup von einem der "Gain" -Knoten mit xtrabackup. Die einfachste Option, aber während des Backup-Clusters wird die Leistung verschwendet.
- Verwenden Sie klassische Slaves und Backups von Replikaten.
Backups mit Standalone und mit der mit xtrabackup erstellten Clusterversion sind untereinander portierbar. Das heißt, die vom Cluster erstellte Sicherung kann für eigenständiges MySQL bereitgestellt werden und umgekehrt. Natürlich sollte die Hauptversion von MySQL übereinstimmen, vorzugsweise die Nebenversion. Mit mysqldump erstellte Backups sind natürlich auch portabel.
Die einzige Einschränkung besteht darin, dass Sie nach der Bereitstellung der Sicherung das Skript mysql_upgrade ausführen müssen, mit dem die Struktur einiger Systemtabellen überprüft und korrigiert wird.
Datenmigration
Nachdem wir die Konfiguration, Überwachung und andere Dinge herausgefunden haben, können wir mit der Migration auf das Produkt beginnen.
Die Datenmigration in unserem Schema war recht einfach, aber wir haben ein bisschen durcheinander gebracht;).
Legende - Master 1 und Master 2 sind durch Master-Replikationsmaster verbunden. Die Aufnahme geht nur an Master 1. Master 3 ist ein sauberer Server.
Unser Migrationsplan (im Plan werde ich der Einfachheit halber Operationen mit Slaves weglassen und nur über Master-Server sprechen).
Versuch 1
- Entfernen Sie die Datenbanksicherung mit xtrabackup von Master 1.
- Kopieren Sie die Sicherung auf Master 3 und führen Sie den Cluster im Einzelknotenmodus aus.
- Richten Sie die Master-Replikation zwischen Master 3 und 1 ein.
- Schalten Sie das Lesen und Schreiben auf den Master 3. Überprüfen Sie die Anwendung.
- Deaktivieren Sie auf Master 2 die Replikation und starten Sie Clustered MySQL. Wir warten darauf, dass er die Datenbank vom Master 3 kopiert. Während des Kopierens hatten wir einen Cluster aus einem Knoten im Status „Spender“ und einem Knoten, der noch nicht funktioniert. Während des Kopierens haben wir eine Reihe von Sperren erhalten und am Ende sind beide Knoten mit einem Fehler gefallen (das Erstellen eines neuen Knotens kann aufgrund toter Sperren nicht abgeschlossen werden). Dieses kleine Experiment hat uns vier Minuten Ausfallzeit gekostet.
- Schalten Sie das Lesen und Schreiben zurück auf Master 1.
Die Migration funktionierte nicht, da beim Testen der Schaltung in der Entwicklungsumgebung in der Datenbank praktisch kein Schreibverkehr auftrat und beim Wiederholen derselben Schaltung unter Last Probleme auftraten.
Wir haben das Migrationsschema leicht geändert, um diese Probleme zu vermeiden, und es zum zweiten Mal erfolgreich wiederholt;).
Versuch 2
- Wir starten Master 3 neu, damit es im Einzelknotenmodus wieder funktioniert.
- Wir erhöhen Cluster MySQL erneut auf dem Master 2. Im Moment ging der Datenverkehr von der Replikation nur an den Cluster, sodass keine wiederholten Probleme mit Sperren auftraten und der zweite Knoten erfolgreich zum Cluster hinzugefügt wurde.
- Schalten Sie das Lesen und Schreiben erneut auf Master 3 um. Wir überprüfen den Betrieb der Anwendung.
- Deaktivieren Sie die Master-Replikation mit Master 1. Aktivieren Sie Cluster-MySQL auf Master 1 und warten Sie, bis es startet. Um nicht auf denselben Rechen zu treten, ist es wichtig, dass die Anwendung nicht auf den Donor-Knoten schreibt (Einzelheiten finden Sie im Abschnitt zum Lastausgleich). Nach dem Starten des dritten Knotens haben wir einen voll funktionsfähigen Cluster von drei Knoten.
- Sie können eine Sicherung von einem der Knoten des Clusters entfernen und die Anzahl der benötigten klassischen Slaves erstellen.
Der Unterschied zwischen dem zweiten und dem ersten Schema besteht darin, dass wir den Datenverkehr erst nach dem Anheben des zweiten Knotens im Cluster auf den Cluster umgeschaltet haben.
Dieser Vorgang dauerte für uns ca. 6 Stunden.
Multi-Master
Nach der Migration arbeitete unser Cluster im Single-Master-Modus, dh der gesamte Datensatz ging an einen der Server, und nur die Daten wurden vom Rest gelesen.
Nach dem Wechsel der Produktion in den Multi-Master-Modus ist ein Problem aufgetreten - Transaktionskonflikte traten häufiger auf als erwartet. Es war besonders schlimm bei Abfragen, die viele Datensätze ändern, z. B. den Wert aller Datensätze in einer Tabelle aktualisieren. Die Transaktionen, die erfolgreich auf demselben Knoten nacheinander im Cluster ausgeführt wurden, werden parallel ausgeführt, und eine längere Transaktion erhält einen Deadlock-Fehler. Ich werde nicht zögern, nachdem wir mehrere Versuche unternommen haben, dies auf Anwendungsebene zu beheben, haben wir die Idee des Multi-Masters aufgegeben.
Andere Nuancen
- Ein Cluster kann ein Slave sein. Wenn Sie diese Funktion verwenden, empfehle ich, alle Knoten außer der Slave-Option "skip_slave_start = 1" zur Konfiguration hinzuzufügen. Andernfalls startet jeder neue Knoten die Replikation vom Master, was entweder zu Replikationsfehlern oder zu Datenbeschädigungen auf dem Replikat führt.
- Wie ich bereits sagte, kann ein Knoten Clients nicht ordnungsgemäß bedienen. Es muss beachtet werden, dass in einem Cluster von drei Knoten Situationen möglich sind, in denen ein Knoten ausgeflogen ist, der zweite ein Spender ist und nur ein Knoten für den Kundendienst übrig bleibt.
Schlussfolgerungen
Nach der Migration und einiger Betriebszeit kamen wir zu den folgenden Schlussfolgerungen.
- Der Galera-Cluster funktioniert und ist ziemlich stabil (zumindest solange keine abnormalen Knotenabfälle oder deren abnormales Verhalten aufgetreten sind). In Bezug auf Fehlertoleranz haben wir genau das bekommen, was wir wollten.
- Perconas Multi-Master-Statements sind in erster Linie Marketing. Ja, es ist möglich, den Cluster in diesem Modus zu verwenden, dies erfordert jedoch eine tiefgreifende Änderung der Anwendung für dieses Verwendungsmodell.
- Es gibt keine synchrone Replikation, aber jetzt steuern wir die maximale Verzögerung von Knoten (bei Transaktionen). Zusammen mit der Begrenzung der maximalen Transaktionsgröße von 50 MB können wir die maximale Verzögerungszeit von Knoten ziemlich genau vorhersagen. Für Entwickler ist es einfacher geworden, Code zu schreiben.
- Bei der Überwachung beobachten wir kurzfristige Spitzen im Wachstum der Replikationswarteschlange. Der Grund liegt in unserem 1-Gbit / s-Netzwerk. Es ist möglich, einen Cluster in einem solchen Netzwerk zu betreiben, aber während Lastbursts treten Probleme auf. Jetzt planen wir ein Upgrade des Netzwerks auf 10 Gbit / s.
Insgesamt drei "Wunschliste" haben wir ungefähr anderthalb erhalten. Die wichtigste Anforderung ist die Fehlertoleranz.
Unsere PXC-Konfigurationsdatei für Interessierte:
my.cnf[mysqld]
#Main
server-id = 1
datadir = /var/lib/mysql
socket = mysql.sock
port = 3302
pid-file = mysql.pid
tmpdir = /tmp
large_pages = 1
skip_slave_start = 1
read_only = 0
secure-file-priv = /tmp/
#Engine
innodb_numa_interleave = 1
innodb_flush_method = O_DIRECT
innodb_flush_log_at_trx_commit = 2
innodb_file_format = Barracuda
join_buffer_size = 1048576
tmp-table-size = 512M
max-heap-table-size = 1G
innodb_file_per_table = 1
sql_mode = "NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ERROR_FOR_DIVISION_BY_ZERO"
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
#Wsrep
wsrep_provider = "/usr/lib64/galera3/libgalera_smm.so"
wsrep_cluster_address = "gcomm://192.168.0.1:4577,192.168.0.2:4577,192.168.0.3:4577"
wsrep_cluster_name = "prod"
wsrep_node_name = node1
wsrep_node_address = "192.168.0.1"
wsrep_sst_method = xtrabackup-v2
wsrep_sst_auth = "USER:PASS"
pxc_strict_mode = ENFORCING
wsrep_slave_threads = 64
wsrep_sst_receive_address = "192.168.0.1:4444"
wsrep_max_ws_size = 50M
wsrep_retry_autocommit = 2
wsrep_provider_options = "gmcast.listen_addr=tcp://192.168.0.1:4577; ist.recv_addr=192.168.0.1:4578; gcache.size=30G; pc.checksum=true; evs.version=1; evs.auto_evict=5; gcs.fc_limit=80; gcs.fc_factor=0.75; gcs.max_packet_size=64500;"
#Binlog
expire-logs-days = 4
relay-log = mysql-relay-bin
log_slave_updates = 1
binlog_format = ROW
binlog_row_image = minimal
log_bin = mysql-bin
log_bin_trust_function_creators = 1
#Replication
slave-skip-errors = OFF
relay_log_info_repository = TABLE
relay_log_recovery = ON
master_info_repository = TABLE
gtid-mode = ON
enforce-gtid-consistency = ON
#Cache
query_cache_size = 0
query_cache_type = 0
thread_cache_size = 512
table-open-cache = 4096
innodb_buffer_pool_size = 72G
innodb_buffer_pool_instances = 36
key_buffer_size = 16M
#Logging
log-error = /var/log/stdout.log
log_error_verbosity = 1
slow_query_log = 0
long_query_time = 10
log_output = FILE
innodb_monitor_enable = "all"
#Timeout
max_allowed_packet = 512M
net_read_timeout = 1200
net_write_timeout = 1200
interactive_timeout = 28800
wait_timeout = 28800
max_connections = 22000
max_connect_errors = 18446744073709551615
slave-net-timeout = 60
#Static Values
ignore_db_dir = "lost+found"
[sst]
rlimit = 80m
compressor = "pigz -3"
decompressor = "pigz -dc"
backup_threads = 8
Quellen und nützliche Links
→
Unser Docker-Image→
Percona XtraDB Cluster 5.7 Dokumentation→
Überwachen des Clusterstatus - Galera Cluster-Dokumentation→
Galera-Statusvariablen - Galera-Cluster-Dokumentation