In Python können Sie mit Daten arbeiten und diese visualisieren. Davon profitieren nicht nur Programmierer, sondern auch Wissenschaftler: Biologen, Physiker und Soziologen. Heute werden wir zusammen mit
Shwars , dem Kurator unseres
Python-Starthilfekurses für KI , kurz Meteorologen werden und das Klima russischer Städte untersuchen. Aus Bibliotheken zur Visualisierung und zum Arbeiten mit Daten verwenden wir Pandas, Matplotlib und Bokeh.

Wir recherchieren zu
Azure Notebooks , der Cloud-basierten Version von Jupyther Notebook. Um mit Python zu beginnen, müssen wir also nichts auf unserem Computer installieren und können direkt vom Browser aus arbeiten. Sie müssen sich nur mit Ihrem Microsoft-Konto anmelden, eine Bibliothek und den neuen Python 3-Laptop darin erstellen. Dann können Sie die Codefragmente aus diesem Artikel entnehmen und experimentieren!
Wir bekommen die Daten
Zunächst importieren wir die Hauptbibliotheken, die wir benötigen.
Pandas ist eine Bibliothek für die Arbeit mit tabellarischen Daten oder sogenannten Datenrahmen. Mit
Pyplot können wir Diagramme erstellen.
import pandas as pd import matplotlib.pyplot as plt
Die Quelldaten sind im Internet leicht zu finden, aber wir haben die Daten bereits in einem praktischen CSV-Format für Sie vorbereitet. CSV ist ein Textformat, bei dem alle Spalten durch Kommas getrennt sind. Daher der Name - Kommagetrennte Werte.
Pandas können CSV-Dateien sowohl von einer lokalen Festplatte als auch direkt aus dem Internet öffnen. Die Daten selbst befinden sich in unserem
Repository auf GitHub , daher müssen wir nur die richtige URL angeben.
data = pd.read_csv("https://raw.githubusercontent.com/shwars/PythonJump/master/Data/climat_russia_cities.csv") data

Benennen Sie die Tabellenspalten um, damit Sie bequemer nach Namen zugreifen können. Wir müssen auch Zeichenfolgen in numerische Werte konvertieren, um sie bearbeiten zu können. Wenn wir versuchen, dies mit der Funktion
pd.to_numeric zu tun, stellen wir fest, dass ein seltsamer Fehler auftritt. Dies liegt daran, dass im Text anstelle eines Minus ein langer Strich verwendet wird.
data.columns=["City","Lat","Long","TempMin","TempColdest","AvgAnnual","TempWarmest","AbsMax","Precipitation"] data["TempMin"] = pd.to_numeric(data["TempMin"])
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) pandas/_libs/src/inference.pyx in pandas._libs.lib.maybe_convert_numeric() ValueError: Unable to parse string "−38.0" ... ... ... ValueError: Unable to parse string "−38.0" at position 0
Aus diesem Problem ergibt sich eine wichtige Moral: Daten liegen normalerweise in einer "schmutzigen" Form vor, deren Verwendung unpraktisch ist, und die Aufgabe eines Datenwissenschaftlers besteht darin, diese Daten einer guten Übersicht zu unterziehen.
Sie können sehen, dass einige der Spalten in unserer Tabelle vom Typ
object und nicht vom numerischen Typ
float64 . In solchen Spalten ersetzen wir den Bindestrich durch ein Minus und konvertieren dann die gesamte Tabelle in ein Zahlenformat. Spalten, die nicht konvertiert werden können (Städtenamen), bleiben unverändert (hierfür haben wir die Schlüsselfehler
errors='ignore' ).
print(data.dtypes) for x in ["TempMin","TempColdest","AvgAnnual"]: data[x] = data[x].str.replace('−','-') data = data.apply(pd.to_numeric,errors='ignore') print(data.dtypes)
City object Lat float64 Long float64 TempMin object TempColdest object AvgAnnual object TempWarmest float64 AbsMax float64 Precipitation int64 dtype: object City object Lat float64 Long float64 TempMin float64 TempColdest float64 AvgAnnual float64 TempWarmest float64 AbsMax float64 Precipitation int64 dtype: object
Wir recherchieren Daten
Nachdem wir saubere Daten haben, können wir versuchen, interessante Diagramme zu erstellen.
Durchschnittliche Jahrestemperatur
Lassen Sie uns zum Beispiel sehen, wie die Durchschnittstemperatur vom Breitengrad abhängt.
ax = data.plot(x="Lat",y="AvgAnnual",kind="Scatter") ax.set_xlabel("") ax.set_ylabel(" ")

Die Grafik zeigt, dass je näher am Äquator, desto wärmer.
Städte aufzeichnen
Schauen wir uns nun die Städte an, die Temperaturchampions sind, und prüfen Sie, ob ein Zusammenhang zwischen den minimalen und maximalen Temperaturen in der Stadt besteht.
ax=data.plot(x="TempMin",y="AbsMax",kind="scatter") ax.set_xlabel(" ") ax.set_ylabel(" ") ax.invert_xaxis()
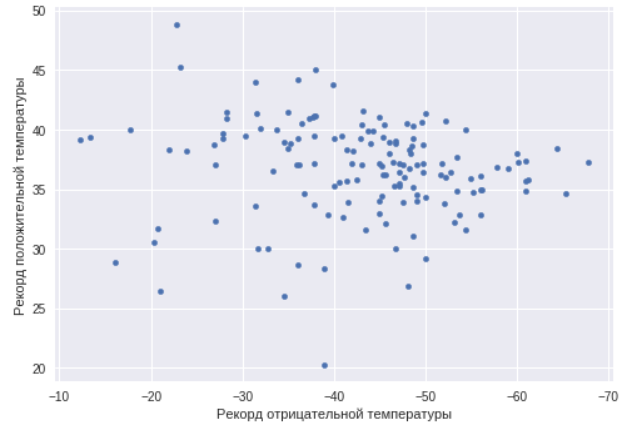
Wie Sie sehen können, gibt es in diesem Fall keine solche Korrelation. Es gibt Städte mit einem stark kontinentalen Klima und nur warme und kalte Städte. Wir finden Städte mit einer maximalen Temperaturverteilung, dh Städte mit einem stark kontinentalen Klima.
data['spread'] = data['TempWarmest'] - data['TempColdest'] data.nlargest(3,'spread')

Diesmal haben wir keine Rekordhöhen erreicht, sondern die Durchschnittswerte des wärmsten und kältesten Monats. Wie erwartet die größte Streuung unter Städten aus der Republik Sacha (Jakutien).
Winter und Sommer
Betrachten Sie für weitere Untersuchungen Städte in einem Umkreis von 300 km von Moskau. Um den Abstand zwischen den Längen- und Breitengraden zu berechnen, verwenden wir die
Geopie- Bibliothek, die zuerst mit
pip install .
!pip install geopy import geopy.distance
Fügen Sie der Tabelle eine weitere Spalte hinzu - die Entfernung zu Moskau.
msk_coords = tuple(data.loc[data["City"]==""][["Lat","Long"]].iloc[0]) data["DistMsk"] = data.apply(lambda row : geopy.distance.distance(msk_coords,(row["Lat"],row["Long"])).km,axis=1) data.head()

Wir verwenden den Ausdruck, um nur die für uns interessanten Zeilen auszuwählen.
msk = data.loc[data['DistMsk']<300] msk
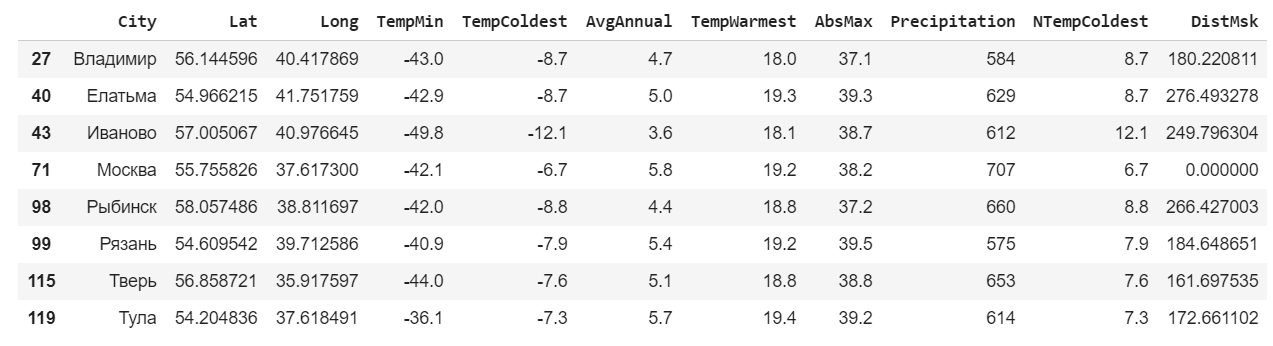
Für diese Städte erstellen wir einen Zeitplan mit minimalen, durchschnittlichen jährlichen und maximalen Temperaturen.
ax=msk.plot(x="City",y=["TempColdest","AvgAnnual","TempWarmest"],kind="bar",stacked="true") ax.legend(["","",""],loc='lower right')
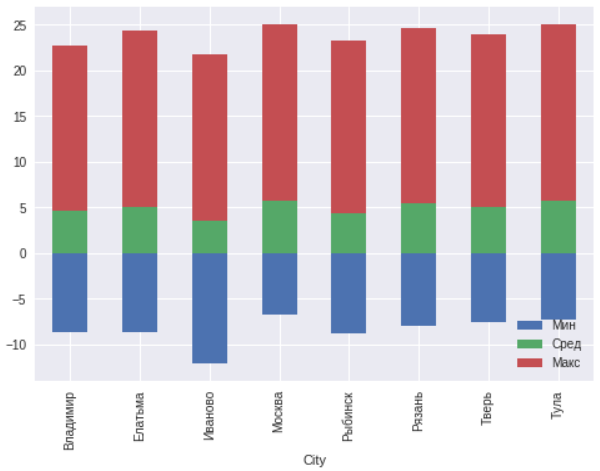
Im Allgemeinen werden innerhalb von 300 Kilometern um Moskau keine Anomalien beobachtet. Ivanovo liegt nördlich der übrigen Städte und daher sind die Temperaturen dort um einige Grad niedriger.
Arbeiten Sie mit Geodaten
Versuchen wir nun, den durchschnittlichen Jahresniederschlag in Bezug auf die Städte auf der Karte anzuzeigen und zu sehen, wie der Niederschlag vom geografischen Standort abhängt. Dafür verwenden wir eine andere Visualisierungsbibliothek -
Bokeh . Es muss auch installiert werden.
Dann berechnen wir eine weitere Spalte - die Größe des Kreises, die die Niederschlagsmenge anzeigt. Der Koeffizient wird empirisch ausgewählt.
!pip install bokeh from bokeh.io import output_file, output_notebook, show from bokeh.models import ( GMapPlot, GMapOptions, ColumnDataSource, Circle, LogColorMapper, BasicTicker, ColorBar, DataRange1d, PanTool, WheelZoomTool, BoxSelectTool, HoverTool ) from bokeh.models.mappers import ColorMapper, LinearColorMapper from bokeh.palettes import Viridis5 from bokeh.plotting import gmap
Um mit der Karte arbeiten zu können, benötigen Sie den Google Maps-API-Schlüssel. Es muss unabhängig
auf der Website bezogen werden .
Ausführlichere Anweisungen zur Verwendung von Bokeh zum Zeichnen von Diagrammen auf Karten finden Sie
hier und
hier .
google_key = "<INSERT YOUR KEY HERE>" data["PrecipSize"] = data["Precipitation"] / 50.0 map_options = GMapOptions(lat=msk_coords[0], lng=msk_coords[1], map_type="roadmap", zoom=4) plot = gmap(google_key,map_options=map_options) plot.title.text = " " source = ColumnDataSource(data=data) my_hover = HoverTool() my_hover.tooltips = [('', '@City'),('','@Precipitation')] plot.circle(x="Long", y="Lat", size="PrecipSize", fill_color="blue", fill_alpha=0.8, source=source) plot.add_tools(PanTool(), WheelZoomTool(), BoxSelectTool(), my_hover) output_notebook() show(plot)
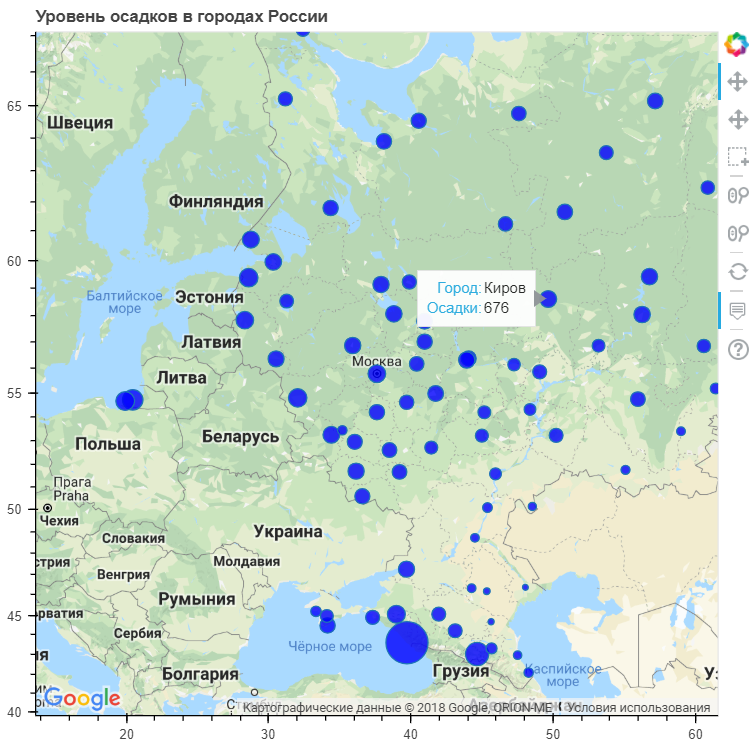
Wie Sie sehen können, fällt die größte Niederschlagsmenge in Küstenstädten. Obwohl es eine ziemlich große Anzahl von Städten gibt, in denen der Niederschlag durchschnittlich oder sogar niedriger als das nationale Niveau ist.
Den gesamten Code mit Kommentaren von Dmitry Soshnikov können Sie hier unabhängig sehen und ausführen.
Zusammenfassung
Wir haben die Fähigkeiten der Sprache gezeigt, ohne komplexe Algorithmen, bestimmte Bibliotheken oder Hunderte von Codezeilen zu verwenden. Selbst mit Standardtools können Sie Ihre Daten analysieren und einige Schlussfolgerungen ziehen.
Datensätze sind weit davon entfernt, immer perfekt zusammengesetzt zu sein. Bevor Sie also mit der Visualisierung beginnen, müssen Sie sie in Ordnung bringen. Die Qualität der Visualisierung hängt weitgehend von der Qualität der verwendeten Daten ab.
Es gibt eine Vielzahl verschiedener Arten von Diagrammen und Grafiken, und es ist nicht erforderlich, sich nur auf Standardbibliotheken zu beschränken.
Es gibt
Geoplotlib ,
Plotly , minimalistisches
Leder und andere.
Wenn Sie mehr über die Arbeit mit Daten in Python erfahren und sich mit künstlicher Intelligenz vertraut machen möchten, laden wir Sie zu einem eintägigen Intensivkurs aus dem
Binärbezirk ein -
Python-Starthilfe für KI .