Der Raum der umgebenden Welt ist mit individuellen Ereignissen und ihren Ketten gefüllt - diese Ereignisse spiegeln sich in den Medien, in den Berichten von Bloggern und gewöhnlichen Menschen in sozialen Netzwerken wider. Ein Bild der umgebenden Realität, das ein gewisses Maß an Objektivität beansprucht, kann nur erhalten werden, wenn wir unterschiedliche Sichtweisen auf dasselbe Problem sammeln. Der Kategorisierer von Ereignissen ist das Tool, mit dem gesammelte Informationen „gesammelt“ werden: Versionen der Beschreibung von Ereignissen. Als Nächstes können Benutzer über Suchwerkzeuge, Empfehlungen und visuelle Darstellungen von Zeitsequenzen von Ereignissen auf Informationen zu Ereignissen zugreifen.
Heute werden wir unter dem Codenamen "Varya" über unser System, genauer über seinen Softwarekern, sprechen - zu Ehren des Hauptentwicklers.
Wir können den Namen unseres Startups auf Anfrage der Habrahabr-Administration noch nicht erwähnen. Jetzt haben wir einen Antrag eingereicht, um uns den Startup-Status zuzuweisen. Wir können Ihnen jedoch jetzt etwas über die Funktionalität und unsere Ideen erzählen. Unser System stellt die Relevanz von Ereignisinformationen für den Benutzer und ein kompetentes Datenmanagement sicher. Im System bestimmt jeder Benutzer selbst, was zu sehen und zu lesen ist, steuert die Suche und die Empfehlungen.
Unser Projekt ist ein Startup mit einem Team von 8 Mitarbeitern, die über Kompetenzen im Entwurf technisch und algorithmisch komplexer Systeme, in der Programmierung, im Marketing und im Management verfügen.
Gemeinsam arbeitet das Team jeden Tag an dem Projekt - Algorithmen zum Kategorisieren, Suchen und Präsentieren von Informationen wurden bereits implementiert. Die Implementierung von Algorithmen in Bezug auf Empfehlungen für den Benutzer steht noch bevor: basierend auf der Beziehung von Ereignissen, Personen und der Analyse der Benutzeraktivität und -interessen.
Welche Aufgaben lösen wir und warum sprechen wir darüber? Wir helfen Menschen dabei, detaillierte Informationen über Ereignisse jeglicher Größenordnung zu erhalten, unabhängig davon, wo und wann sie aufgetreten sind.
Das Projekt bietet Benutzern eine Plattform für die Diskussion von Ereignissen in einem Kreis von Gleichgesinnten, mit der Sie einen Kommentar oder Ihre eigene Version des Geschehens teilen können. Die Social-Media-Plattform wurde für diejenigen geschaffen, die „überdurchschnittlich“ wissen und eine persönliche Meinung zu den wichtigsten Ereignissen der Vergangenheit, Gegenwart und Zukunft haben möchten.
Benutzer selbst finden und erstellen nützliche Inhalte im Medienbereich und überwachen deren Zuverlässigkeit. Wir erinnern uns an die Ereignisse ihres Lebens.
Jetzt, da sich das Projekt in der MVP-Phase befindet, testen wir Hypothesen über die Funktionalität und Arbeit des Kategorisierers, um die richtige Richtung für die weitere Entwicklung zu bestimmen. In diesem Artikel werden wir über die Technologien sprechen, mit denen wir unsere Aufgaben lösen und unsere Best Practices austauschen.
Die Aufgabe der maschinellen Textverarbeitung wird von Suchmaschinen gelöst: Yandex, Google, Bing usw. Ein ideales System zum Arbeiten mit Informationsflüssen und zum Isolieren von Ereignissen in diesen könnte wie folgt aussehen.
Für das System wird eine ähnliche Infrastruktur wie Yandex und Google erstellt, das gesamte Internet wird in Echtzeit auf Aktualisierungen überprüft, und im Informationsstrom werden Ereigniskerne zugewiesen, um die sich Agglomerationen ihrer Versionen und zugehöriger Inhalte bilden. Die Software-Implementierung des Dienstes basiert auf einem Deep-Learning-Neuronalen Netzwerk und / oder einer Lösung, die auf der Yandex-Bibliothek - CatBoost - basiert.
Cool Wir haben jedoch noch kein solches Datenvolumen und es gibt keine entsprechenden Rechenressourcen für die Assimilation.
Die Klassifizierung nach Themen ist eine beliebte Aufgabe. Es gibt viele Algorithmen für ihre Lösung: naive Bayes-Klassifizierer, latente Dirichlet-Platzierung, Boosting über Entscheidungsbäume und neuronale Netze. Wie wahrscheinlich bei allen Problemen des maschinellen Lernens treten bei Verwendung der beschriebenen Algorithmen zwei Probleme auf:
Erstens, wo bekommt man viele Daten?
Zweitens, wie man sie billig und wütend platziert?
Welchen Ansatz haben wir für ein ereignisbasiertes System gewählt?
Unser Produkt arbeitet mit Veranstaltungen. Veranstaltungen unterscheiden sich etwas von regulären Artikeln.
Um den „Kaltstart“ zu überwinden, haben wir uns für zwei WikiMedia-Projekte entschieden: Wikipedia und Wikinews. Ein Wikipedia-Artikel kann mehrere Ereignisse beschreiben (zum Beispiel die Geschichte der Entwicklung von Sun Microsystems, eine Biographie von Mayakovsky oder den Verlauf des Großen Vaterländischen Krieges).
Andere Quellen für Ereignisinformationen sind RSS-Feeds. Die Nachrichten geschehen auf unterschiedliche Weise: Große analytische Artikel enthalten mehrere Ereignisse wie Wikipedia-Texte, und kurze Informationsnachrichten aus verschiedenen Quellen repräsentieren dasselbe Ereignis.
Somit bilden der Artikel und die Ereignisse viele-zu-viele-Beziehungen. In der MVP-Phase gehen wir jedoch davon aus, dass ein Artikel ein Ereignis ist.
Wenn Sie sich die Benutzeroberfläche von Google oder Yandex ansehen, denken Sie möglicherweise, dass Suchmaschinen nur nach Schlüsselwörtern suchen. Dies gilt nur für sehr einfache Online-Händler. Die meisten Suchmaschinen haben mehrere Kriterien, und die Suchmaschine unseres Projekts ist keine Ausnahme. Darüber hinaus werden in der Benutzeroberfläche bei weitem nicht alle bei der Suche berücksichtigten Parameter angezeigt. Unser Projekt enthält eine Liste von Parametern, die der Benutzer auswählt, z.
Themen und Schlüsselwörter -
"was?" ;; Ort -
"wo?" ;; Datum -
"wann?" ;;
Diejenigen, die Suchmaschinen schreiben, wissen, dass Schlüsselwörter allein viele Probleme verursachen. Nun, der Rest der Optionen ist auch nicht so einfach.
Das Thema der Veranstaltung ist eine sehr schwierige Sache. Das menschliche Gehirn ist so konzipiert, dass er es liebt, alles zu kategorisieren, und die reale Welt ist damit überhaupt nicht einverstanden. Eingehende Artikel möchten ihre eigenen Themengruppen bilden, und sie sind keineswegs diejenigen, in die wir und unsere begeisterten Benutzer sie verteilen.
Wir haben jetzt 15 Hauptthemen von Ereignissen, und diese Liste wurde mehrmals überarbeitet und wird mindestens wachsen.
Orte und Daten sind etwas formeller angeordnet, aber hier gibt es Fallstricke.
Wir haben also eine Reihe formalisierter Kriterien und Rohdaten, die wir diesen Kriterien zuordnen müssen. Und so machen wir es.
Spinne
Die Aufgabe der Spinne ist es, eingehende Artikel so zu falten, dass sie schnell durchsucht werden können. Dazu muss die Spinne in der Lage sein, den Artikeln das Thema, den Ort und das Datum sowie einige andere für das Ranking erforderliche Parameter zuzuweisen. Unsere Eingabespinne erhält ein Textmodell des vom Crawler erstellten Artikels. Ein Textmodell ist eine Liste von Teilen eines Artikels und den entsprechenden Texten. Zum Beispiel hat fast jeder Artikel mindestens eine Überschrift und einen Text. Tatsächlich hat sie immer noch den ersten Absatz, eine Reihe von Kategorien, auf die sich dieser Text bezieht, und eine Liste von Infoboxfeldern (für Wikipedia und Quellen mit solchen Metadaten-Tags). Es gibt noch ein Veröffentlichungsdatum. Für das Ranking in einer Suchmaschine ist es wichtig zu wissen, ob beispielsweise ein Datum in der Kopfzeile oder irgendwo am Ende des Textes gefunden wird. Ein Textmodell wird verwendet, um ein Themenmodell, ein Standortmodell und ein Datumsmodell zu erstellen. Anschließend wird das Ergebnis dem Index hinzugefügt. Zu jedem dieser Modelle kann ein separater Artikel geschrieben werden. Daher werden wir hier nur kurz die Ansätze skizzieren.
Thema
Das Thema der Dokumente zu bestimmen, ist eine häufige Aufgabe. Themen können vom Autor des Dokuments manuell zugeordnet oder automatisch ermittelt werden. Natürlich haben wir Themen, die Nachrichtenquellen und Wikipedia unseren Dokumenten zugeordnet haben, aber bei diesen Themen geht es nicht um Ereignisse. Finden Sie das Thema „Feiertage“ häufig in Newsfeeds? Sie werden vielmehr das Thema "Gesellschaft" kennenlernen. Wir hatten dies auch in einer der frühesten Ausgaben. Wir konnten nicht bestimmen, was sich darauf beziehen sollte, und waren gezwungen, es zu entfernen. Darüber hinaus haben alle Quellen ihre eigenen Themen.
Wir möchten die Liste der Themen verwalten, die unseren Benutzern in der Benutzeroberfläche angezeigt werden. Daher ist für uns die Aufgabe, das Thema des Dokuments zu bestimmen, die Aufgabe der Fuzzy-Klassifizierung. Die Klassifizierungsaufgabe erfordert gekennzeichnete Beispiele, dh eine Liste von Dokumenten, denen unsere gewünschten Themen bereits zugeordnet wurden. Unsere Liste ähnelt allen ähnlichen Themenlisten, stimmt jedoch nicht mit diesen überein, sodass wir keine beschriftete Stichprobe hatten. Sie können es auch manuell oder automatisch erhalten, aber wenn sich unsere Themenliste ändert (und es wird!), Ist manuell keine Option.
Wenn Sie keine beschriftete Probe haben, können Sie die latente Dirichlet-Platzierung und andere thematische Modellierungsalgorithmen verwenden. Die Menge der Algorithmen, die Sie erhalten, ist jedoch diejenige, die sich herausgestellt hat, und nicht die, die Sie wollten.
Hier müssen wir noch einen Punkt erwähnen: Unsere Artikel stammen aus verschiedenen Quellen. Alle thematischen Modelle bauen auf die eine oder andere Weise auf dem verwendeten Vokabular auf. Für Nachrichten und Wikipedia ist es anders, anders, sogar gesiebte Hochfrequenzen.
Wir standen also vor zwei Aufgaben:
1. Überlegen Sie sich eine Möglichkeit, unsere Dokumente schnell in einem halbautomatischen Modus auszulegen.
2. Erstellen Sie basierend auf diesen Dokumenten ein erweiterbares Modell unserer Themen.
Um sie zu lösen, haben wir einen Hybridalgorithmus erstellt, der die in der Abbildung gezeigten automatisierten und manuellen Stufen enthält.
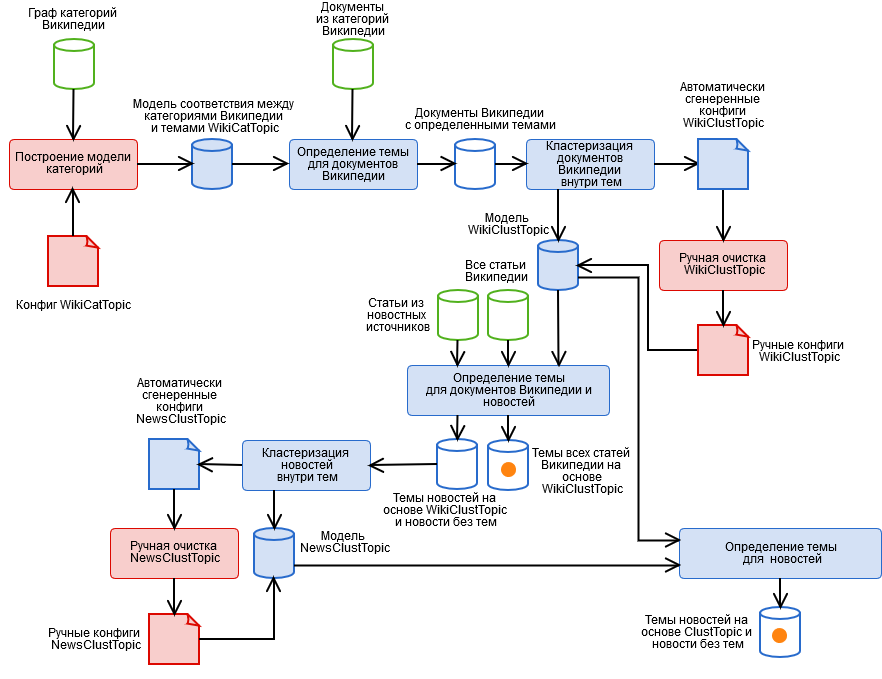
- Manuelles Markieren von Wikipedia-Kategorien und Abrufen eines kategorialen WikiCatTopic-Themenmodells. Zu diesem Zeitpunkt wird eine Konfiguration erstellt, die jedem unserer T-Themen einen Untergraphen der WT-Kategorien von Wikipedia zuweist. Wikipedia ist eine Pseudo-Ontologie. Das heißt, wenn etwas in die Kategorie „Wissenschaft“ fällt, handelt es sich möglicherweise überhaupt nicht um Wissenschaft. Beispielsweise können Sie aus der harmlosen Unterkategorie „Informationstechnologien“ tatsächlich zu jedem Wikipedia-Artikel gelangen. Es wird ein separater Artikel darüber benötigt, wie man damit lebt.
- Erkennen von Themen für Wikipedia-Dokumente basierend auf WikiCatTopic automatisch. Dem Dokument wird das Thema T zugewiesen, wenn es in eine der Kategorien des Diagramm-CT fällt. Beachten Sie, dass diese Methode nur für Wikipedia-Artikel gilt. Um die Definition von Themen auf beliebigen Text zu verallgemeinern, war es möglich, eine Worttüte für jedes Thema zu erstellen und den Kosinusabstand zum Thema zu berücksichtigen (und wir haben versucht, nichts Gutes), aber hier müssen drei Dinge berücksichtigt werden.
- Solche Themen enthalten sehr unterschiedliche Artikel, so dass das Bild des Themas im Wortraum nicht kohärent ist, was bedeutet, dass das „Vertrauen“ eines solchen Modells in die Bestimmung des Themas sehr gering ist (schließlich ähnelt der Artikel einem kleinen Satz von Artikeln, aber nicht dem Rest).
- Ein beliebiger Text, hauptsächlich Nachrichten, unterscheidet sich in seiner lexikalischen Zusammensetzung von Wikipedia, dies fügt jedoch kein Modell der „Gewissheit“ hinzu. Darüber hinaus können einige Themen nicht auf Wikipedia erstellt werden.
- Stufe 1 ist eine sehr mühsame Arbeit, und jeder ist zu faul, um sie zu tun.
- Clustering von Dokumenten innerhalb von Themen basierend auf den Ergebnissen von Absatz 2 unter Verwendung der k-means-Methode und Erhalten eines Clustermodells des WikiClustTopic-Themas. Ein ziemlich einfacher Schritt, mit dem wir zwei der drei Probleme aus Absatz 2 weitgehend lösen konnten. Für Cluster erstellen wir eine Menge Wörter, und die Zugehörigkeit zu einem Thema wird als Maximum der Kosinusabstände zu seinen Clustern definiert. Das Modell wird in unseren Konfigurationsdateien für die Korrespondenz zwischen Clustern und Wikipedia-Dokumenten beschrieben.
- Manuelle Reinigung des WikiClustTopic-Modells, Aktivieren-Deaktivieren-Übertragen von Clustern. Hier kehrten wir auch zu Stufe 1 zurück, als völlig falsche Cluster entdeckt wurden.
- Automatische Erkennung von WikiClustTopic-Themen für Wikipedia-Dokumente und -Nachrichten.
- Clustering von Nachrichten innerhalb von Themen basierend auf den Ergebnissen von Absatz 5 unter Verwendung der k-means-Methode sowie Nachrichten, die keine Themen erhalten haben, und Abrufen eines Clustermodells des NewsClustTopic-Themas. Jetzt haben wir ein Themenmodell, das die Besonderheiten der Nachrichten berücksichtigt (sowie wertvolle Informationen über die Qualität der Arbeit des Crawlers).
- Manuelle Reinigung des NewsClustTopic-Modells.
- Neuzuordnung von Nachrichtenthemen basierend auf dem integrierten Modell ClustTopic = WikiClustTopic + NewsClustTopic. Basierend auf diesem Modell werden Themen neuer Dokumente bestimmt.
Standorte
Die automatische Standortbestimmung ist ein Sonderfall bei der Suche nach benannten Entitäten. Die Merkmale der Standorte sind wie folgt:
- Alle Standortlisten sind unterschiedlich und passen nicht gut zusammen. Wir haben unseren eigenen Hybrid gebaut, der nicht nur die Hierarchie (Russland umfasst die Region Nowosibirsk) berücksichtigt, sondern auch historische Namensänderungen (zum Beispiel, aus dem RSFSR wurde Russland), basierend auf: Geonamen, Wikidata und anderen offenen Quellen. Wir mussten jedoch noch einen Geotag-Konverter mit Google Maps schreiben :)
- Einige Orte bestehen aus mehreren Wörtern, zum Beispiel Nischni Nowgorod, und Sie müssen in der Lage sein, sie zu sammeln.
- Orte ähneln anderen Wörtern, insbesondere den Namen derer, zu deren Ehren sie genannt werden: Kirov, Zhukov, Vladimir. Das ist Homonymie. Um dies zu beheben, haben wir Statistiken zu Wikipedia-Artikeln gesammelt, in denen Siedlungen beschrieben werden, in denen die Namen von Orten gefunden werden, und versucht, mithilfe von Open Corpora-Wörterbüchern eine Liste solcher Homonyme zu erstellen.
- Die Menschheit hat die Vorstellungskraft nicht stark belastet, und viele Orte werden gleich benannt. Unser Lieblingsbeispiel: Karasuk in Kasachstan und in Russland bei Nowosibirsk. Dies ist eine Homonymie innerhalb der Standortklasse. Wir lösen das Problem, indem wir berücksichtigen, welche anderen Orte mit diesem gefunden werden und ob sie für eines der Homonyme Eltern oder Kind sind. Diese Heuristik ist nicht universell, funktioniert aber gut.
Termine
Daten - die Verkörperung der Formalität im Vergleich zu Themen und Orten. Wir haben für sie einen erweiterbaren Parser für reguläre Ausdrücke erstellt, und wir können nicht nur Tag-Monat-Jahr analysieren, sondern auch alle möglichen interessanteren Dinge wie „Ende des Winters 1941“, „in den 90er Jahren des 19. Jahrhunderts“ und „letzten Monat“ Unter Berücksichtigung des Zeitalters und des Basisdatums des Dokuments sowie des Versuchs, das fehlende Jahr wiederherzustellen. Über Daten müssen Sie wissen, dass nicht alle von ihnen gut sind. Am Ende eines Artikels über eine Schlacht im Zweiten Weltkrieg wird das Denkmal möglicherweise vierzig Jahre später eröffnet. Um solche Fälle zu behandeln, müssen Sie den Artikel in Ereignisse zerlegen, aber wir tun dies noch nicht. Wir betrachten also nur die wichtigsten Daten: aus der Überschrift und den ersten Absätzen.
Suchmaschine
Die Suchmaschine ist ein Gizmo, das zum einen bei Bedarf nach Dokumenten sucht und zum anderen diese in absteigender Reihenfolge der Relevanz für die Abfrage anordnet, dh in abnehmender Relevanz. Um die Relevanz zu berechnen, verwenden wir viele Parameter, viel mehr als nur Trivance:
Der Grad, in dem das Dokument zum Thema gehört.
Der Grad des Eigentums an dem Standortdokument (wie oft und in welchen Teilen des Dokuments befindet sich der ausgewählte Standort).
Der Grad, in dem das Dokument mit dem Datum übereinstimmt (berücksichtigt die Anzahl der Tage am Schnittpunkt des Intervalls von der Anforderung und die Daten des Dokuments sowie die Anzahl der Tage am Schnittpunkt abzüglich der Vereinigung).
Die Länge des Dokuments. Lange Artikel sollten höher sein.
Das Vorhandensein des Bildes. Jeder liebt Bilder, es sollte mehr geben!
Art des Wikipedia-Artikels. Wir können Artikel mit Beschreibungen von Ereignissen trennen, und sie sollten im Beispiel "auftauchen".
Quelle des Artikels. Nachrichten und benutzerdefinierte Artikel sollten höher sein als Wikipedia.
Als Suchmaschine verwenden wir Apache Lucene.
Crawler
Die Aufgabe des Crawlers ist es, Artikel für die Spinne zu sammeln. In unserem Fall umfassen wir hier auch die primäre Reinigung des Textes und die Erstellung eines Textmodells des Dokuments. Crawler verdient einen separaten Artikel.
PS Wir freuen uns über jedes Feedback. Wir laden Sie ein, unser Projekt zu testen. Um einen Link zu erhalten, schreiben Sie persönliche Nachrichten (wir können hier nicht veröffentlichen). Hinterlassen Sie Ihre Kommentare unter dem Artikel oder wenn Sie zu unserem Service gelangen - genau dort, über das Feedback-Formular.