Wenn Menschen im Internet nach einem Bild oder Video suchen, fügen sie häufig den Ausdruck "in guter Qualität" hinzu. Qualität bezieht sich normalerweise auf die Auflösung - Benutzer möchten, dass das Bild groß ist und gleichzeitig auf dem Bildschirm eines modernen Computers, Smartphones oder Fernsehgeräts gut aussieht. Aber was ist, wenn die Quelle in guter Qualität einfach nicht existiert?
Heute werden wir den Lesern von Habr erzählen, wie wir die Auflösung von Videos mithilfe neuronaler Netze in Echtzeit erhöhen können. Sie erfahren auch, wie sich der theoretische Ansatz zur Lösung dieses Problems vom praktischen unterscheidet. Wenn Sie sich nicht für technische Details interessieren, können Sie sicher durch den Beitrag scrollen - am Ende finden Sie Beispiele unserer Arbeit.

Es gibt viele Videoinhalte im Internet in geringer Qualität und Auflösung. Es können Filme sein, die vor Jahrzehnten gedreht wurden, oder Fernsehkanäle, die aus verschiedenen Gründen nicht in bester Qualität sind. Wenn Benutzer ein solches Video auf den Vollbildmodus ausdehnen, wird das Bild trüb und unscharf. Eine ideale Lösung für alte Filme wäre, den Originalfilm zu finden, ihn mit modernen Geräten zu scannen und manuell wiederherzustellen. Dies ist jedoch nicht immer möglich. Sendungen sind noch komplizierter - sie müssen live verarbeitet werden. In dieser Hinsicht besteht die akzeptabelste Option für uns darin, die Auflösung zu erhöhen und Artefakte mithilfe der Computer-Vision-Technologie zu bereinigen.
In der Industrie wird die Aufgabe, Bilder und Videos zu vergrößern, ohne an Qualität zu verlieren, als Superauflösung bezeichnet. Es wurden bereits viele Artikel zu diesem Thema verfasst, aber die Realität der „Kampf“ -Anwendung erwies sich als viel komplizierter und interessanter. Kurz zu den Hauptproblemen, die wir in unserer eigenen DeepHD-Technologie lösen mussten:
- Sie müssen in der Lage sein, Details wiederherzustellen, die aufgrund ihrer geringen Auflösung und Qualität nicht im Originalvideo enthalten waren, um sie zu „beenden“.
- Lösungen aus dem Bereich der Superauflösung stellen Details wieder her, machen jedoch nicht nur die Objekte im Video klar und detailliert, sondern auch Komprimierungsartefakte, die das Publikum nicht mögen.
- Es gibt ein Problem beim Sammeln des Trainingsmusters - es ist eine große Anzahl von Paaren erforderlich, bei denen dasselbe Video sowohl in niedriger Auflösung als auch in hoher Qualität und in hoher Qualität vorhanden ist. In der Realität gibt es normalerweise kein Qualitätspaar für schlechte Inhalte.
- Die Lösung sollte in Echtzeit funktionieren.
Technologieauswahl
In den letzten Jahren hat die Verwendung neuronaler Netze zu erheblichen Erfolgen bei der Lösung fast aller Aufgaben der Bildverarbeitung geführt, und die Aufgabe der Superauflösung ist keine Ausnahme. Wir haben die vielversprechendsten Lösungen basierend auf GAN gefunden (Generative Adversarial Networks, generative konkurrierende Netzwerke). Mit ihnen können Sie hochauflösende fotorealistische Bilder erhalten, die durch fehlende Details ergänzt werden, z. B. durch Zeichnen von Haaren und Wimpern auf den Bildern von Personen.

Im einfachsten Fall besteht ein neuronales Netzwerk aus zwei Teilen. Der erste Teil - der Generator - nimmt ein Eingabebild auf und gibt eine doppelte Vergrößerung zurück. Der zweite Teil - der Diskriminator - empfängt das erzeugte und "echte" Bild als Eingabe und versucht, es voneinander zu unterscheiden.
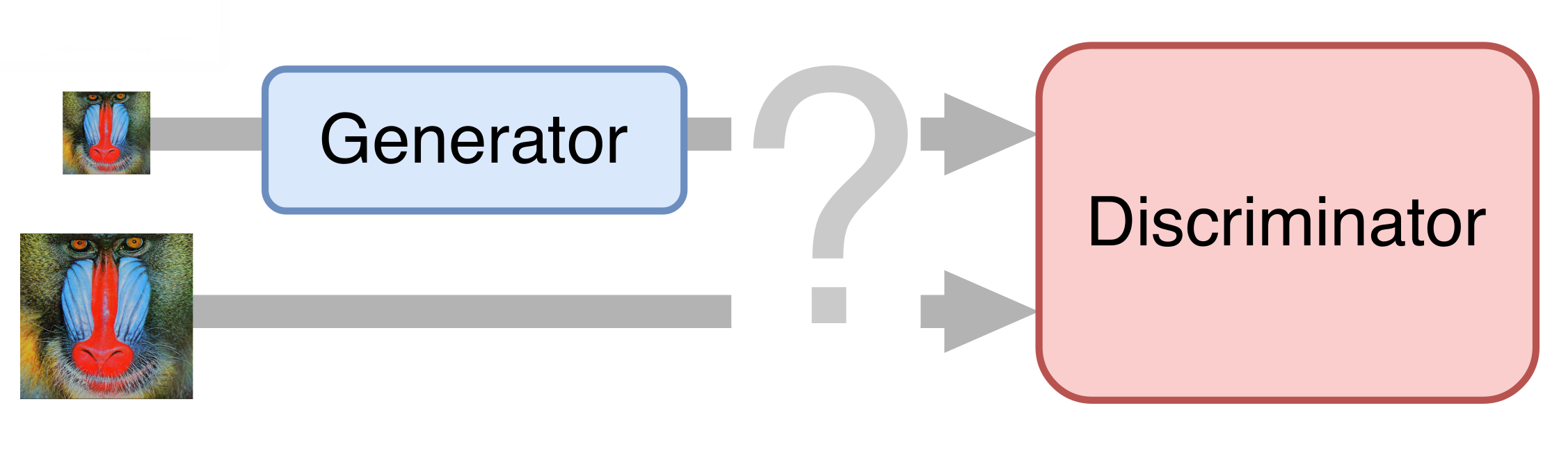
Vorbereitung des Trainingssets
Für das Training haben wir Dutzende von Clips in UltraHD-Qualität gesammelt. Zuerst haben wir sie auf eine Auflösung von 1080p reduziert, um Referenzbeispiele zu erhalten. Dann haben wir diese Videos halbiert und sie auf dem Weg mit einer anderen Bitrate komprimiert, um etwas Ähnliches wie ein echtes Video in geringer Qualität zu erhalten. Wir haben die resultierenden Videos in Frames aufgeteilt und sie so verwendet, um das neuronale Netzwerk zu trainieren.
Deblocking
Natürlich wollten wir eine End-to-End-Lösung: Das neuronale Netzwerk so trainieren, dass hochauflösendes Video und Qualität direkt aus dem Original generiert werden. Die GANs erwiesen sich jedoch als sehr launisch und versuchten ständig, die Komprimierungsartefakte zu verfeinern, anstatt sie zu beseitigen. Daher musste ich den Prozess in mehrere Phasen unterteilen. Das erste ist die Unterdrückung von Videokomprimierungsartefakten, die auch als Deblocking bezeichnet werden.
Ein Beispiel für eine der Freigabemethoden:

Zu diesem Zeitpunkt haben wir die Standardabweichung zwischen dem generierten und dem ursprünglichen Frame minimiert. Obwohl wir die Auflösung des Bildes erhöht haben, haben wir aufgrund der Regression auf den Durchschnitt keine echte Erhöhung der Auflösung erzielt: Das neuronale Netzwerk, das nicht wusste, in welchen bestimmten Pixeln ein bestimmter Rand im Bild verläuft, musste mehrere Optionen mitteln, um ein verschwommenes Ergebnis zu erhalten. Die Hauptsache, die wir in dieser Phase erreicht haben, ist die Beseitigung von Videokomprimierungsartefakten, sodass das generative Netzwerk in der nächsten Phase nur benötigt wird, um die Klarheit zu erhöhen und die fehlenden kleinen Details und Texturen hinzuzufügen. Nach Hunderten von Experimenten haben wir die optimale Architektur in Bezug auf Leistung und Qualität ausgewählt, die vage an die
DRCN- Architektur erinnert:
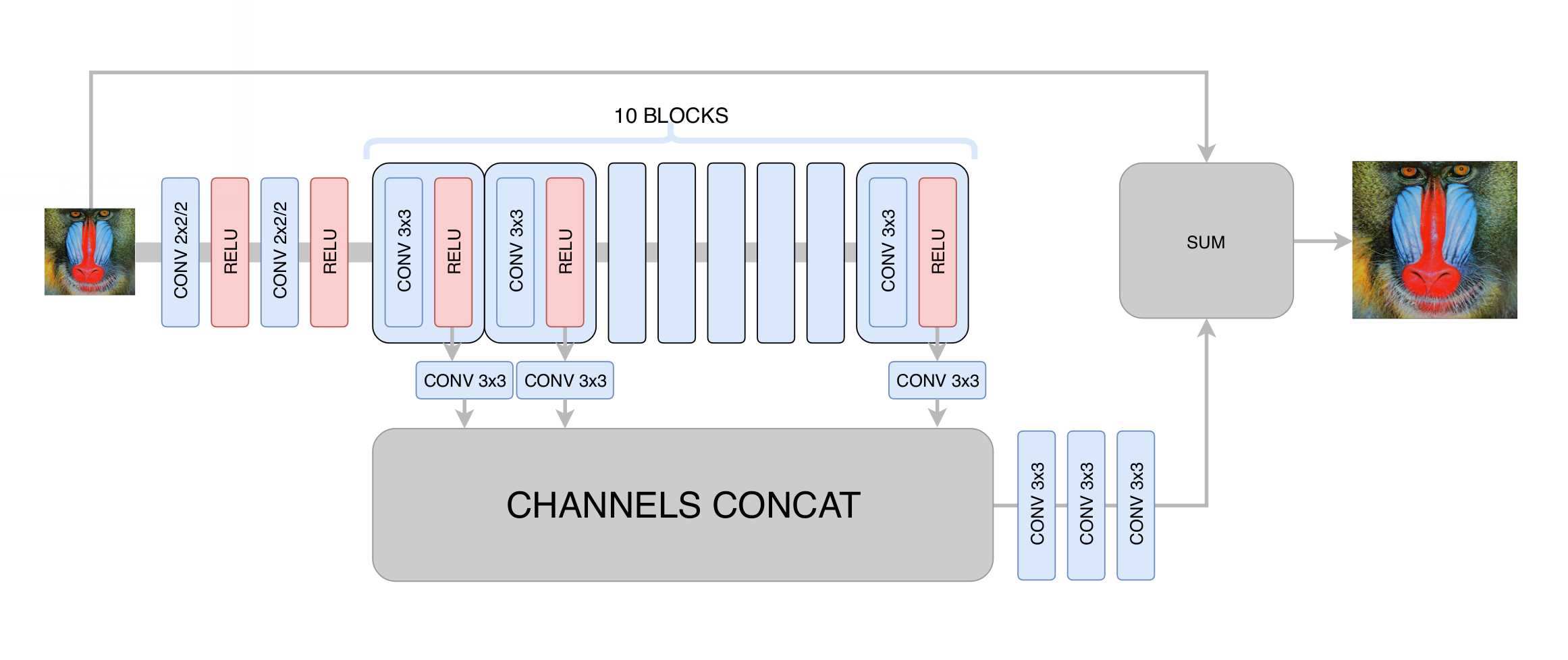
Die Hauptidee einer solchen Architektur ist der Wunsch, die tiefste Architektur zu erhalten, ohne Probleme mit der Konvergenz in ihrer Ausbildung zu haben. Einerseits extrahiert jede nachfolgende Faltungsschicht immer komplexere Merkmale des Eingabebildes, wodurch Sie bestimmen können, welche Art von Objekt sich an einem bestimmten Punkt im Bild befindet, und komplexe und stark beschädigte Teile wiederherstellen können. Andererseits bleibt der Abstand in der Grafik eines neuronalen Netzwerks von einer seiner Schichten zum Ausgang klein, was die Konvergenz des neuronalen Netzwerks verbessert und die Verwendung einer großen Anzahl von Schichten ermöglicht.
Generatives Netzwerktraining
Wir haben die
SRGAN- Architektur
als Grundlage für ein neuronales Netzwerk zur Erhöhung der Auflösung verwendet. Bevor Sie ein wettbewerbsfähiges Netzwerk trainieren, müssen Sie den Generator vorab trainieren - trainieren Sie ihn auf die gleiche Weise wie in der Deblockierungsphase. Andernfalls gibt der Generator zu Beginn des Trainings nur Rauschen zurück, der Diskriminator beginnt sofort zu „gewinnen“ - er lernt leicht, Rauschen von realen Frames zu unterscheiden, und es funktioniert kein Training.

Dann trainieren wir GAN, aber es gibt einige Nuancen. Für uns ist es wichtig, dass der Generator nicht nur fotorealistische Bilder erstellt, sondern auch die darauf verfügbaren Informationen speichert. Zu diesem Zweck fügen wir der klassischen GAN-Architektur die Funktion zum Verlust von Inhalten hinzu. Es repräsentiert mehrere Schichten des neuronalen VGG19-Netzwerks, die auf dem Standard-ImageNet-Datensatz trainiert wurden. Diese Ebenen verwandeln das Bild in eine Feature-Map, die Informationen zum Inhalt des Bildes enthält. Die Verlustfunktion minimiert den Abstand zwischen solchen Karten, die aus den erzeugten und ursprünglichen Rahmen erhalten werden. Das Vorhandensein einer solchen Verlustfunktion ermöglicht es auch, den Generator in den ersten Trainingsschritten nicht zu verderben, wenn der Diskriminator noch nicht trainiert ist und nutzlose Informationen liefert.
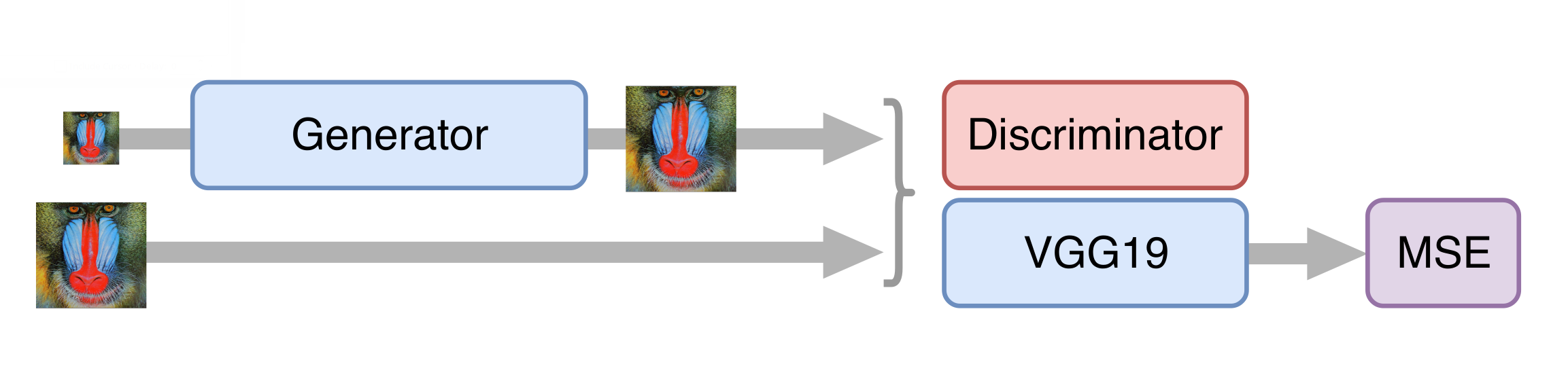
Beschleunigung des neuronalen Netzes
Alles lief gut und nach einer Reihe von Experimenten erhielten wir ein gutes Modell, das bereits auf alte Filme angewendet werden konnte. Es war jedoch immer noch zu langsam, um Streaming-Videos zu verarbeiten. Es stellte sich heraus, dass es unmöglich ist, den Generator einfach ohne einen signifikanten Qualitätsverlust des endgültigen Modells zu reduzieren. Dann kam uns der Wissensdestillationsansatz zu Hilfe. Bei dieser Methode wird ein leichteres Modell so trainiert, dass die Ergebnisse eines schwereren Modells wiederholt werden. Wir haben viele echte Videos in geringer Qualität aufgenommen, sie mit dem im vorherigen Schritt erhaltenen generativen neuronalen Netzwerk verarbeitet und das leichtere Netzwerk trainiert, um das gleiche Ergebnis aus denselben Frames zu erzielen. Aufgrund dieser Technik haben wir ein Netzwerk erhalten, dessen Qualität dem Original nicht sehr unterlegen ist, das jedoch zehnmal schneller ist: Um einen Fernsehkanal mit einer Auflösung von 576p zu verarbeiten, ist eine NVIDIA Tesla V100-Karte erforderlich.
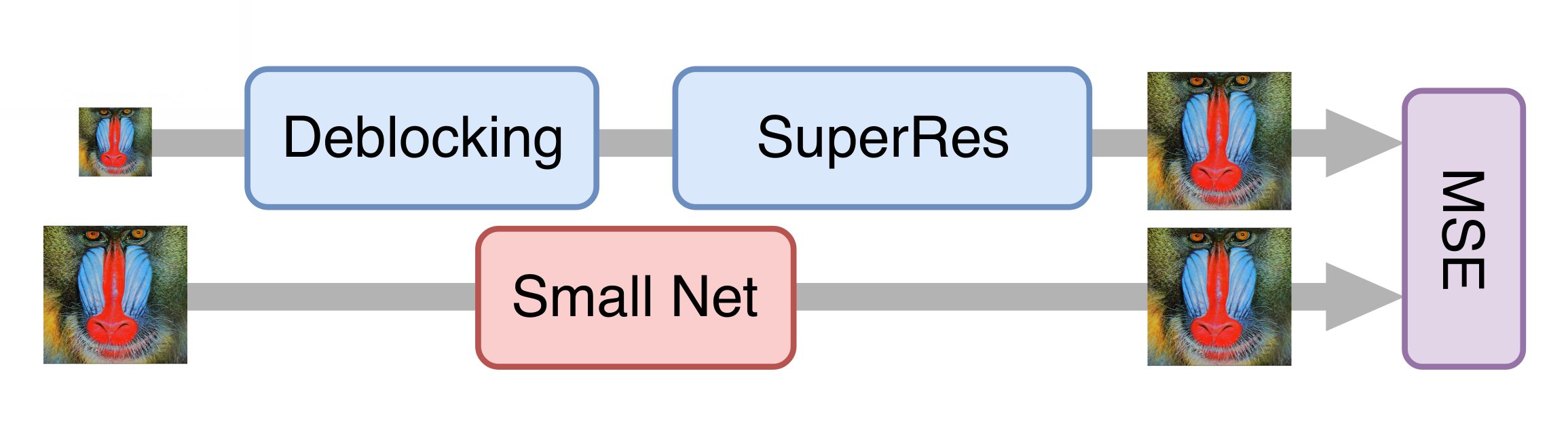
Bewertung der Qualität von Lösungen
Der vielleicht schwierigste Moment bei der Arbeit mit generativen Netzwerken ist die Bewertung der Qualität der resultierenden Modelle. Es gibt keine eindeutige Fehlerfunktion, wie zum Beispiel bei der Lösung des Klassifizierungsproblems. Stattdessen kennen wir nur die Genauigkeit des Diskriminators, die nicht die Qualität des Generators widerspiegelt, der uns interessiert (ein Leser, der mit diesem Bereich gut vertraut war, könnte vorschlagen,
die Wasserstein-Metrik zu verwenden , aber leider ergab sich ein merklich schlechteres Ergebnis).
Die Leute haben uns geholfen, dieses Problem zu lösen. Wir haben Benutzern des
Yandex.Tolok- Dienstes Bildpaare gezeigt, von denen eines die Quelle war und das andere von einem neuronalen Netzwerk verarbeitet wurde oder beide von verschiedenen Versionen unserer Lösungen verarbeitet wurden. Gegen eine Gebühr wählten die Benutzer ein besseres Video aus einem Paar aus, sodass wir einen statistisch signifikanten Vergleich der Versionen erhielten, selbst bei Änderungen, die mit dem Auge schwer zu erkennen sind. Unsere endgültigen Modelle gewinnen in mehr als 70% der Fälle, was ziemlich viel ist, da die Benutzer nur wenige Sekunden damit verbringen, ein paar Videos zu bewerten.
Ein interessantes Ergebnis war auch die Tatsache, dass Videos mit einer Auflösung von 576p, die durch die DeepHD-Technologie auf 720p erhöht wurden, in 60% der Fälle dasselbe Originalvideo mit einer Auflösung von 720p übertreffen - d. H. Die Verarbeitung erhöht nicht nur die Auflösung des Videos, sondern verbessert auch dessen visuelle Wahrnehmung.
Beispiele
Im Frühjahr haben wir die DeepHD-Technologie an mehreren alten Filmen getestet, die im KinoPoisk zu sehen sind: „
Rainbow “ von Mark Donskoy (1943), „
Cranes are Flying “ von Mikhail Kalatozov (1957), „
My Dear Man “ von Joseph Kheifits (1958), „
The Fate of a Man “. Sergei Bondarchuk (1959), "
Ivan Childhood " von Andrei Tarkovsky (1962), "
Vater eines Soldaten " Rezo Chkheidze (1964) und "
Tango of Our Childhood " von Albert Mkrtchyan (1985).

Der Unterschied zwischen den Versionen vor und nach der Verarbeitung macht sich besonders bemerkbar, wenn Sie sich die Details ansehen: Studieren Sie die Mimik der Helden in Nahaufnahmen, berücksichtigen Sie die Textur der Kleidung oder ein Stoffmuster. Es war möglich, einige der Mängel der Digitalisierung zu kompensieren: zum Beispiel die Überbelichtung der Gesichter zu beseitigen oder sichtbarere Objekte im Schatten zu platzieren.
Später wurde die DeepHD-Technologie eingesetzt, um die Qualität der Sendungen
einiger Kanäle im Yandex.Air-Dienst zu verbessern. Das Erkennen solcher Inhalte ist durch das
dHD- Tag einfach.
Jetzt können Sie
auf Yandex in verbesserter Qualität „Die Schneekönigin“, „Bremer Stadtmusiker“, „Goldene Antilope“ und andere beliebte Cartoons des Filmstudios Sojusmultfilm sehen. Einige Beispiele für Dynamik sind im Video zu sehen:
Für anspruchsvolle Betrachter wird der Unterschied besonders deutlich: Das Bild ist schärfer geworden, Baumblätter, Schneeflocken, Sterne am Nachthimmel über dem Dschungel und andere kleine Details sind besser sichtbar.
Mehr ist mehr.
Nützliche Links
Jiwon Kim, Jung Kwon Lee und Kyoung Mu Lee Tief rekursives Faltungsnetzwerk für Bild-Superauflösung [
arXiv: 1511.04491 ].
Christian Ledig et al. Fotorealistische Einzelbild-Superauflösung unter Verwendung eines generativen gegnerischen Netzwerks [
arXiv: 1609.04802 ].
Mehdi SM Sajjadi, Bernhard Schölkopf, Michael Hirsch EnhanceNet: Einzelbild-Superauflösung durch automatisierte Textur-Synthese [
arXiv: 1612.07919 ].