Haben Sie jemals offene Stellen analysiert?
Sie stellten die Frage, in welchen Technologien die Nachfrage auf dem Arbeitsmarkt am aktuellsten ist. Vor einem Monat? Vor einem Jahr?
Wie oft werden neue Java-Stellenangebote in einem bestimmten Bereich Ihrer Stadt geöffnet und wie aktiv werden sie geschlossen?
In diesem Artikel werde ich Ihnen erklären, wie Sie das gewünschte Ergebnis erzielen und ein Berichtssystem zu einem für uns interessanten Thema aufbauen können. Lass uns gehen!
(Bildquelle)Wahrscheinlich sind viele von Ihnen vertraut und haben sogar eine Ressource wie
Headhunter.ru verwendet . Täglich werden auf dieser Website Tausende neuer Stellen in verschiedenen Bereichen ausgeschrieben. HeadHunter verfügt außerdem über eine API, mit der der Entwickler mit den Daten dieser Ressource interagieren kann.
Toolkit
Anhand eines einfachen Beispiels betrachten wir den Aufbau des Prozesses zum Abrufen von Daten für das Berichtssystem, der auf der Arbeit mit der API-Site Headhunter.ru basiert. Als Zwischenspeicherung von Informationen verwenden wir das eingebettete SQLite-DBMS. Die verarbeiteten Daten werden in der NoSQL-Datenbank von MongoDB, Python 3.4, als Hauptsprache gespeichert.
HH APIDie Funktionen der HeadHunter-API sind sehr umfangreich und in der offiziellen Dokumentation zu
GitHib ausführlich beschrieben. Dies ist zunächst die Möglichkeit, anonyme Anforderungen zu senden, für die keine Berechtigung zum Empfangen von Auftragsinformationen im JSON-Format erforderlich ist. In letzter Zeit wurden eine Reihe von Methoden bezahlt (Arbeitgebermethoden), die jedoch bei dieser Aufgabe nicht berücksichtigt werden.
Jede freie Stelle bleibt 30 Tage lang auf der Website. Wenn sie nicht erneuert wird, wird sie archiviert. Wurde die Stelle vor Ablauf von 30 Tagen archiviert, wurde sie vom Arbeitgeber geschlossen .
Mit der HeadHunter-API (im Folgenden als HH-API bezeichnet) können Sie eine Reihe veröffentlichter Stellenangebote für jedes Datum in den letzten 30 Tagen erhalten, die wir verwenden werden. Wir erfassen täglich veröffentlichte Stellenangebote für jeden Tag.
Implementierung
- Verbinden Sie SQLite DB
import sqlite3 conn_db = sqlite3.connect('hr.db', timeout=10) c = conn_db.cursor()
- Tabelle zum Speichern von Änderungen im Auftragsstatus
Der Einfachheit halber speichern wir den Verlauf der Änderung des Stellenstatus (Verfügbarkeit nach Datum) in einer speziellen Tabelle der SQLite-Datenbank. Dank der Tabelle vacancy_history wissen wir zu jedem Zeitpunkt des Entladens, d. H. Welche Daten war sie aktiv.
c.execute(''' create table if not exists vacancy_history ( id_vacancy integer, date_load text, date_from text, date_to text )''')
- Stellenfilterung
Es gibt eine Einschränkung, dass eine Anfrage nicht mehr als 2000 Sammlungen zurückgeben kann. Da an einem Tag viel mehr Stellen auf der Website veröffentlicht werden können, werden wir einen Filter in den Anfragetext einfügen, zum Beispiel: Stellen nur in St. Petersburg (Bereich = 2) nach IT-Spezialisierung (Spezialisierung = 1)
path = ("/vacancies?area=2&specialization=1&page={}&per_page={}&date_from={}&date_to={}".format(page, per_page, date_from, date_to))
- Zusätzliche Auswahlbedingungen
Der Arbeitsmarkt wächst schnell und selbst unter Berücksichtigung des Filters kann die Anzahl der offenen Stellen 2000 überschreiten. Daher werden wir für jeden Tag ein zusätzliches Limit in Form eines separaten Starts festlegen: freie Stellen für die erste Tageshälfte und freie Stellen für die zweite Tageshälfte
def get_vacancy_history(): ... count_days = 30 hours = 0 while count_days >= 0: while hours < 24: date_from = (cur_date.replace(hour=hours, minute=0, second=0) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') date_to = (cur_date.replace(hour=hours + 11, minute=59, second=59) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') while count == per_page: path = ("/vacancies?area=2&specialization=1&page={} &per_page={}&date_from={}&date_to={}" .format(page, per_page, date_from, date_to)) conn.request("GET", path, headers=headers) response = conn.getresponse() vacancies = response.read() conn.close() count = len(json.loads(vacancies)['items']) ...
Erster AnwendungsfallNehmen wir an, wir stehen vor der Aufgabe, offene Stellen zu identifizieren, die für ein bestimmtes Zeitintervall geschlossen wurden, beispielsweise für Juli 2018. Dies wird wie folgt gelöst: Das Ergebnis einer einfachen SQL-Abfrage an die Tabelle vacancy_history gibt die benötigten Daten zurück, die zur weiteren Analyse an den DataFrame übergeben werden können:
c.execute(""" select a.id_vacancy, date(a.date_load) as date_last_load, date(a.date_from) as date_publish, ifnull(a.date_next, date(a.date_load, '+1 day')) as date_close from ( select vh1.id_vacancy, vh1.date_load, vh1.date_from, min(vh2.date_load) as date_next from vacancy_history vh1 left join vacancy_history vh2 on vh1.id_vacancy = vh2.id_vacancy and vh1.date_load < vh2.date_load where date(vh1.date_load) between :date_in and :date_out group by vh1.id_vacancy, vh1.date_load, vh1.date_from ) as a where a.date_next is null """, {"date_in" : date_in, "date_out" : date_out}) date_in = dt.datetime(2018, 7, 1) date_out = dt.datetime(2018, 7, 31) closed_vacancies = get_closed_by_period(date_in, date_out) df = pd.DataFrame(closed_vacancies, columns = ['id_vacancy', 'date_last_load', 'date_publish', 'date_close']) df.head()
Wir erhalten das Ergebnis dieses Typs:
Wenn wir mit Excel-Tools oder BI-Tools von Drittanbietern analysieren möchten, können wir die Tabelle vacancy_history zur weiteren Analyse in eine CSV-Datei hochladen:
Schwere Artillerie
Was aber, wenn wir komplexere Datenanalysen durchführen müssen? Hier
hilft die dokumentenorientierte NoSQL-Datenbank
MongoDB , mit der Sie Daten im JSON-Format speichern können.
Die oben genannten Maßnahmen zum Sammeln von Stellenangeboten werden täglich gestartet, sodass nicht jedes Mal alle Stellenangebote angezeigt und detaillierte Informationen zu den einzelnen Stellen erhalten werden müssen. Wir nehmen nur diejenigen, die in den letzten fünf Tagen eingegangen sind.
- Abrufen einer Reihe von Stellenangeboten für die letzten 5 Tage aus einer SQLite-Datenbank:
def get_list_of_vacancies_sql(): conn_db = sqlite3.connect('hr.db', timeout=10) conn_db.row_factory = lambda cursor, row: row[0] c = conn_db.cursor() items = c.execute(""" select distinct id_vacancy from vacancy_history where date(date_load) >= date('now', '-5 day') """).fetchall() conn_db.close() return items
- Eine Reihe von Jobs für die letzten fünf Tage von MongoDB erhalten:
def get_list_of_vacancies_nosql(): date_load = (dt.datetime.now() - td(days=5)).strftime('%Y-%m-%d') vacancies_from_mongo = [] for item in VacancyMongo.find({"date_load" : {"$gte" : date_load}}, {"id" : 1, "_id" : 0}): vacancies_from_mongo.append(int(item['id'])) return vacancies_from_mongo
- Es bleibt der Unterschied zwischen den beiden Arrays zu ermitteln. Für Stellenangebote, die nicht in MongoDB enthalten sind, müssen detaillierte Informationen abgerufen und in die Datenbank geschrieben werden:
sql_list = get_list_of_vacancies_sql() mongo_list = get_list_of_vacancies_nosql() vac_for_pro = [] s = set(mongo_list) vac_for_pro = [x for x in sql_list if x not in s] vac_id_chunks = [vac_for_pro[x: x + 500] for x in range(0, len(vac_for_pro), 500)]
- Wir haben also ein Array mit neuen Stellenangeboten, die in MongoDB noch nicht verfügbar sind. Wir erhalten detaillierte Informationen zu jedem dieser Stellen mithilfe einer Anfrage in der HH-API. Bevor wir sie direkt in MongoDB verarbeiten, verarbeiten wir jedes Dokument:
- Wir bringen die Höhe der Löhne auf das Rubeläquivalent;
- Fügen Sie jeder offenen Stelle (Junior / Middle / Senior usw.) einen Abschluss eines Fachniveaus hinzu.
All dies ist in der Funktion vacancies_processing implementiert:
from nltk.stem.snowball import SnowballStemmer stemmer = SnowballStemmer("russian") def vacancies_processing(vacancies_list): cur_date = dt.datetime.now().strftime('%Y-%m-%d') for vacancy_id in vacancies_list: conn = http.client.HTTPSConnection("api.hh.ru") conn.request("GET", "/vacancies/{}".format(vacancy_id), headers=headers) response = conn.getresponse() if response.status != 404: vacancy_txt = response.read() conn.close() vacancy = json.loads(vacancy_txt)
- Abrufen detaillierter Informationen durch Zugriff auf die HH-API, empfangene Vorverarbeitung
MongoDB wird die Daten ausführen und in mehrere Streams mit jeweils 500 offenen Stellen einfügen:
t_num = 1 threads = [] for vac_id_chunk in vac_id_chunks: print('starting', t_num) t_num = t_num + 1 t = threading.Thread(target=vacancies_processing, kwargs={'vacancies_list': vac_id_chunk}) threads.append(t) t.start() for t in threads: t.join()
Die bevölkerte Sammlung in MongoDB sieht ungefähr so aus:
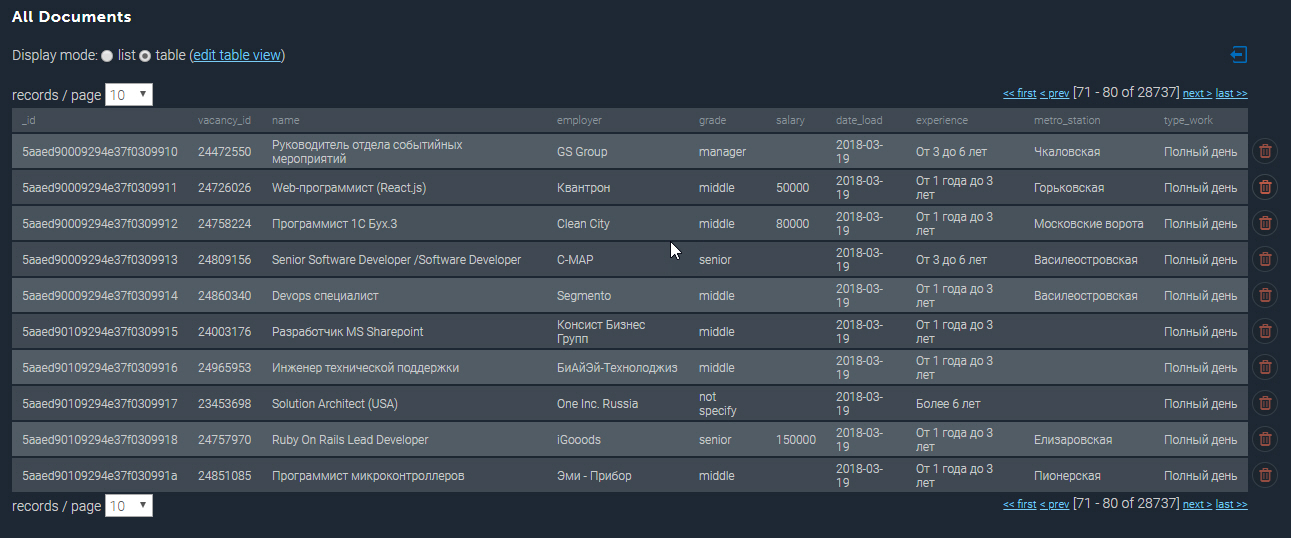
Einige weitere Beispiele
Mit der gesammelten Datenbank können wir verschiedene analytische Proben durchführen. Also werde ich die Top 10 der bestbezahlten Stellenangebote von Python-Entwicklern in St. Petersburg herausbringen:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[pP]ython*"}}) df_mongo = pd.DataFrame(list(cursor_mongo)) del df_mongo['_id'] pd.concat([df_mongo.drop(['employer'], axis=1), df_mongo['employer'].apply(pd.Series)['name']], axis=1)[['grade', 'name', 'salary_processed' ]].sort_values('salary_processed', ascending=False)[:10]
Top 10 der bestbezahlten Jobs von Python| Klasse | Name | Name | Gehalt_verarbeitet |
|---|
| Senior | Web Teamleiter / Architekt (Python / Django / React) | Investex Ltd. | 293901.0 |
| Senior | Leitender Python-Entwickler in Montenegro | Betmaster | 277141.0 |
| Senior | Leitender Python-Entwickler in Montenegro | Betmaster | 275289.0 |
| Mitte | Back-End-Webentwickler (Python) | Soshace | 250000.0 |
| Mitte | Back-End-Webentwickler (Python) | Soshace | 250000.0 |
| Senior | Leitender Python-Ingenieur für ein Schweizer Startup | Assaia International AG | 250000.0 |
| Mitte | Back-End-Webentwickler (Python) | Soshace | 250000.0 |
| Mitte | Back-End-Webentwickler (Python) | Soshace | 250000.0 |
| Senior | Python-Teamleiter | Digitalhr | 230000.0 |
| Senior | Leitender Entwickler (Python, PHP, Javascript) | IK GROUP | 220231.0 |
Lassen Sie uns nun herausfinden, welche U-Bahn-Station die höchste Konzentration an freien Stellen für Java-Entwickler aufweist. Mit einem regulären Ausdruck filtere ich nach dem Jobtitel "Java" und wähle auch nur die Jobs aus, bei denen die Adresse angegeben ist:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[jJ]ava[^sS]"}, "address" : {"$ne" : None}}) df_mongo = pd.DataFrame(list(cursor_mongo)) df_mongo['metro'] = df_mongo.apply(lambda x: x['address']['metro']['station_name'] if x['address']['metro'] is not None else None, axis = 1) df_mongo.groupby('metro')['_id'] \ .count() \ .reset_index(name='count') \ .sort_values(['count'], ascending=False) \ [:10]
Jobs für Java-Entwickler in U-Bahn-Stationen| U-Bahn | zählen |
|---|
| Vasileostrovskaya | 87 |
| Petrogradskaya | 68 |
| Wyborg | 46 |
| Lenin-Platz | 45 |
| Gorkovskaya | 45 |
| Chkalovskaya | 43 |
| Narva | 32 |
| Aufstandsplatz | 29 |
| Altes Dorf | 29 |
| Elizarovskaya | 27 |
Zusammenfassung
Die Analysefunktionen des entwickelten Systems sind also wirklich breit und können verwendet werden, um einen Start zu planen oder eine neue Richtung der Aktivität zu eröffnen.
Ich stelle fest, dass bisher nur die Grundfunktionalität des Systems vorgestellt wird. In Zukunft ist geplant, sich in Richtung Analyse durch geografische Koordinaten zu entwickeln und das Auftreten von Leerständen in einem bestimmten Bereich der Stadt vorherzusagen.
Den vollständigen Quellcode für diesen Artikel finden Sie unter dem Link zu meinem
GitHub .
PS Kommentare zu dem Artikel sind willkommen. Gerne beantworte ich alle Ihre Fragen und finde Ihre Meinung heraus. Vielen Dank!