Ein wichtiges Merkmal maschineller Lernaufgaben ist, dass mit verschiedenen Methoden gleich gute Ergebnisse erzielt werden können. Dies macht ML-Wettbewerbe aufregend: Selbst wenn Sie andere Kompetenzen als einen offensichtlich starken Gegner haben, können Sie trotzdem gewinnen. Die Teams von Tensorborne und Neurobotics hatten fast die gleichen Chancen, den DeepHack-Hackathon zu gewinnen, und belegten schließlich die ersten beiden Plätze. Während des
Yandex-Trainings machten Vertreter beider Teams einen umfangreichen Bericht. Bei der Dekodierung finden Sie eine detaillierte Analyse der Lösungen und Tipps für beginnende Wettbewerber.
Und natürlich einen Hackathonurlaub machen. Wenn Sie an einem wöchentlichen Hackathon teilnehmen und gleichzeitig arbeiten, ist das schlecht. Sie kommen um 19 Uhr an, nachdem Sie ein wenig gearbeitet haben, setzen sich und kompilieren Docker mit TensorFlow, Keras, so dass alles auf einigen Remote-Servern beginnt, auf die Sie nicht einmal Zugriff haben. Irgendwann in zwei Nächten erkranken Sie an Katharsis, und das funktioniert bei Ihnen - ohne Docker, ohne alles, weil Sie verstanden haben, dass es möglich ist und so.
Vitaly Davydov:
- Hallo allerseits! Wir hätten zwei Berichte haben sollen, aber wir haben beschlossen, sie zu einem großen zusammenzufassen, weil wir über den ersten und zweiten Platz im DeepHack-Wettbewerb sprechen. Wir vertreten zwei Teams. Unser Tensorborne-Team belegte den 2. Platz und das Team von Gregory Neurobotics den ersten Platz.

Der Bericht wird aus drei Hauptteilen bestehen. Im Intro werde ich über die Geschichte von DeepHack sprechen, was es ist, was die Metriken waren usw. Als nächstes werden die Jungs über Lösungen sprechen, über welche Probleme, Beispiele usw.
Bevor wir über DeepHack sprechen, sollte angemerkt werden, dass es sich um eine kleine Teilmenge eines anderen sehr großen globalen Wettbewerbs handelt, ConvAI2, der Facebook im vergangenen Jahr gestartet hat. Dieses Jahr ist die zweite Iteration. Irgendwann sponserte Facebook das Moskauer Institut für Physik und Technologie, und der DeepHack-Wettbewerb wurde auf der Grundlage des PhysTech-Labors ins Leben gerufen.

Lesen Sie mehr über ConvAI. Welches Problem versucht er zu lösen? Er ist spezialisiert auf interaktive Systeme. Das Problem bei Dialogsystemen besteht darin, dass es kein einziges Bewertungsinstrument gibt, ein Bewertungsinstrument, um die Qualität von Dialogen zu verstehen. Diese Sache ist von Person zu Person sehr subjektiv: Jemand mag das Gespräch, jemand nicht. Die allgemeine globale Aufgabe von ConvAI besteht darin, eine gemeinsame einheitliche Metrik für die Bewertung von Dialogen zu erstellen, die noch nicht verfügbar ist. Preis - 20.000 USD für AWS Mechanical Turk. Dies sind keine Kredite an Amazon, sondern nur Kredite an Mechanical Turk, was in der Tat ein Analogon zu Yandex.Tolki ist. Dies ist ein Crowdsourcing-Service, mit dem Sie Markups für Daten erstellen können.
Die Aufgabe, die auf ConvAI basiert, besteht darin, einen Chit-Chat-Bot zu erstellen, mit dem Sie eine Art Dialog führen können. Sie wählten drei Metriken: Ratlosigkeit, Treffer @ 1 und F1. Als nächstes werde ich die Tabelle zeigen, die zum Zeitpunkt unserer Einreichung war.
Die Bewertung, mit der sie dies versuchten, durchlief drei Phasen. Die erste Phase sind automatische Metriken, dann die Bewertung von AWS Mechanical Turk und der Live-Chat mit Freiwilligen.
Da ConvAI von Facebook gesponsert wird, bewirbt er seine Bibliothek aktiv für die Erstellung von ParlAI-Konversationssystemen. Es ist ziemlich kompliziert, aber ich denke, alle Teilnehmer haben diese Bibliothek benutzt. Wir haben uns schon seit einiger Zeit damit beschäftigt, es ist zum Beispiel nicht mit Python 3.6 kompatibel und es gibt eine Reihe von Problemen damit.
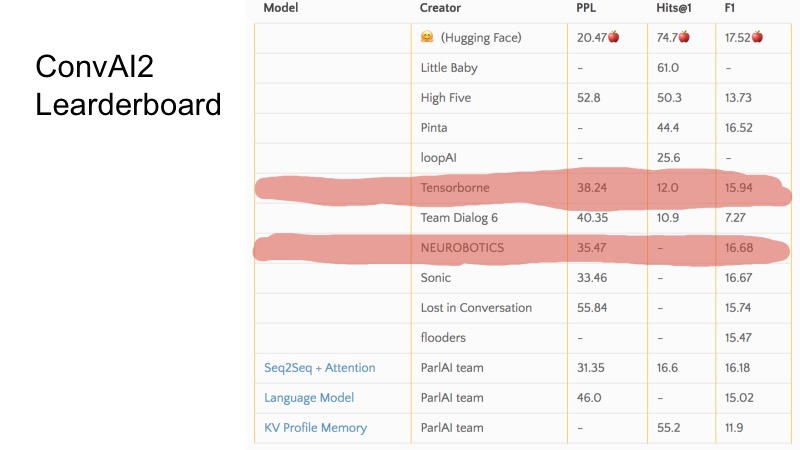
In diesen wenigen Zeilen können Sie sehen, welche Positionen wir zum Zeitpunkt der Einreichung besetzt haben. Im Allgemeinen ist ConvAI in dem Sinne seltsam organisiert, dass es drei Metriken gibt und es nicht sehr klar ist, wie das Ranking in dieser Tabelle verläuft. Es ist ersichtlich, dass für einige Metriken einige Teams höher und für andere niedriger sind. Die Organisation der gesamten ConvAI war etwas seltsam.
Es gibt jedoch drei grundlegende Basislinien. Um sich für DeepHack zu qualifizieren, musste diese Basislinie gebrochen werden, und die 10 besten Teams schafften es bis ins Finale. Im Geheimen möchte ich sagen, dass nur 8 Teams Entscheidungen gesendet haben und alle das Finale erreicht haben. Es war nicht sehr schwierig.

Die Aufgabe von DeepHack war etwas verständlicher und unkomplizierter. Wir mussten erneut einen Sprechroboter bauen, der jedoch eine bestimmte Persönlichkeit emuliert. Das heißt, der Roboter erhielt eine Beschreibung einer Person am Eingang, und während eines Gesprächs mit ihm musste er sie offenbaren. Der Preis war sehr interessant - eine Reise zum NIPS in diesem Herbst, die voll gesponsert wird.
Die Metrik war im Gegensatz zu ConvAI bereits anders. Es gab zwei Metriken, und die Gesamtmetrik wird zwischen den beiden gewichtet. Die erste Metrik ist die Gesamtqualität, eine Einschätzung, wie angemessen der Bot reagiert hat, wie interessant es war, mit ihm zu kommunizieren, ob er Müll geschrieben hat usw. Die zweite Metrik ist Rollenspiel, entweder 0 oder 1. Es bedeutet Ist der Bot auf die Beschreibung gekommen, die er erhalten hat? Die Person, die mit dem Bot kommuniziert, sieht die Beschreibung nicht. Die Auswertung fand in Telegram statt, dh es gab einen einzelnen Telegramm-Bot, und als der Benutzer anfing, mit ihm zu kommunizieren, kam er ehrlich gesagt zu einem zufälligen Bot aus allen Einsendungen. Yandex und MIPT haben dort anscheinend ein wenig Verkehr geschüttet, und soweit ich mich erinnere, gab es ungefähr zehntausend Dialoge.
Ich habe bereits über die Qualifikationsrunde gesprochen. Das Finale war Vollzeit. Es fand während sieben Arbeitstagen am Moskauer Institut für Physik und Technologie statt, ein Cluster wurde bereitgestellt, ein Ort, an dem wir saßen und arbeiteten. Die Bewertung erfolgte tatsächlich jeden Tag, und das Endergebnis, die Bewertung des Bots am Ende, wurde auf diese Weise berechnet. Der Wettbewerb begann am Montag, die erste Einreichung erfolgte am Dienstag und die Bewertung fand am nächsten Tag statt. Die Lösung, die Sie am Dienstag veröffentlicht haben, wurde am Mittwoch mit einem Gewicht von 1,5 bewertet. Was Sie am Mittwoch gesendet haben - mit einem Gewicht von 1,4 usw.

Über den Datensatz, den Facebook für das Training zur Verfügung gestellt hat. Es heißt Persona-Chat und beschreibt zwei Persönlichkeiten und eine Reihe von Dialogen. Es gibt eine Beschreibung der ersten und der zweiten Person. Bei der Beschreibung des Dialogs versuchen sie, sich gegenseitig zu offenbaren. Das ist alles was gegeben wurde. Wie immer war es jedoch im Wettbewerb nicht verboten, andere Datensätze von Drittanbietern zu verwenden.
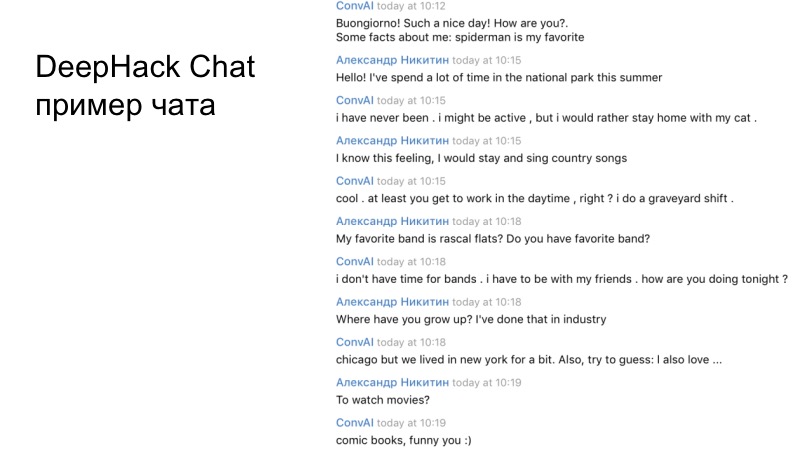
Ein Beispiel für den Dialog unseres Teams. Wenn Sie sorgfältig lesen, ist es klar, dass der resultierende Bot ziemlich angemessen funktioniert und ganz richtig antwortet.
Gregory wird über den ersten Platz sprechen.
Grigory Rashkov:
- Ich möchte über unsere Erfahrungen bei der Teilnahme am Wettbewerb, unsere Strategie und unsere Entscheidung sprechen.

Erstens ist die Besonderheit des Wettbewerbs, dass es eine lange Dauer ist, wir hatten nicht zwei Tage wie bei einem gewöhnlichen Hackathon, sondern fünf Tage, für die wir viele Entscheidungen treffen konnten.

Sehr subjektive Einschätzungen, da insbesondere völlig unterschiedliche Personen mit ihren Kriterien bewertet wurden, sagte der Hackathon-Organisator Mikhail Bubtsev, dass er die Frage nicht so beantwortete, wenn er überhaupt erraten würde, über welches Profil er sprach, aber der Bot irgendwann seinem Profil widersprach Wie geschrieben steht, hat er ein anderes Profil gewählt, auch wenn er wusste, worum es ging.
Und der dritte ist der Mangel an Validierung. Die Teilnehmer konnten keine kleine Änderung vornehmen und erhielten sofort Feedback.
Wie in allen Horrorfilmen hat sich unser Team gleich zu Beginn entschieden, sich zu trennen. Die erste Gruppe befasste sich mit unserer Hauptlösung basierend auf dem Wasserstein-GAN, die zweite Gruppe mit dem Bot, dem Admin-Panel des Bots basierend auf der Basislinie. Weil wir am ersten und zweiten Tag etwas schicken mussten.

Kurz zur Basislinie: Seq2Seq plus Aufmerksamkeit, die leicht an diese spezielle Aufgabe angepasst ist. Wie genau? Eine Phrase wird an die Eingabe gesendet, die Einbettung wird von GloVe übernommen, aber dann wird die Darstellung jeder Phrase als gewichtete Einbettung weiter betrachtet. Gewichte werden basierend auf der inversen Frequenz des Wortes ausgewählt. Je seltener ein Wort vorkommt, desto mehr Gewicht bringt es.

Dies ist notwendig, um die Einzigartigkeit dieser Eigenschaften widerzuspiegeln. Es ging alles um eine Menge, eine Matrix, eine Maske wurde auf der Basis dieser Menge und eines verborgenen Zustands erstellt, dann wurde diese Maske der Menge überlagert, ein Kontext wurde erhalten und dann wurde sie durch Nichtlinearität verbunden und dem Decodereingang zugeführt.

Für den ersten Tag haben wir unsere Entscheidung noch nicht geschrieben, wir mussten etwas senden, also haben wir einen Agenten geschrieben, der auf der Basislinie basiert, aber uns die Aufgabe gestellt, uns irgendwie von der grauen Masse der Agenten abzuheben. Dazu haben wir einfache Heuristiken verwendet, unser Bot war der erste, der einen Dialog begann, und er hat in diesem Satz ein Lächeln verwendet. Und es hat funktioniert.
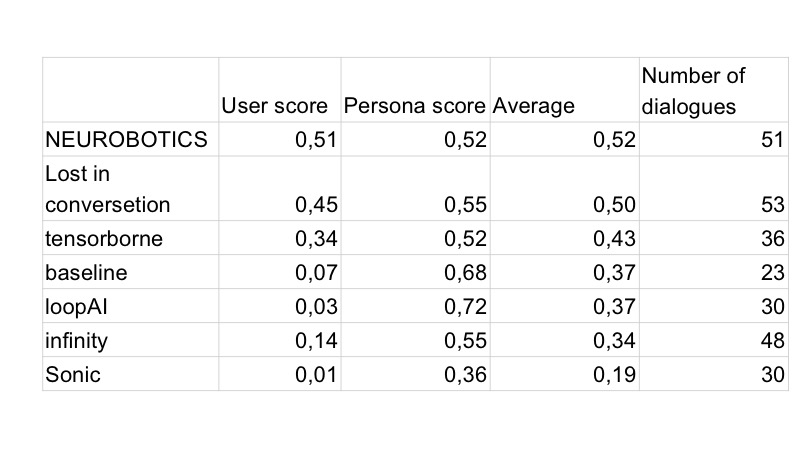
Natürlich wurden am nächsten Tag alle Bots zuerst erstellt und alle hatten Emoticons. Am zweiten Tag arbeiteten die Bewohner von Vilabaggio weiter mit der GAN zusammen, die Bewohner von Vilaribo versuchten andere Heuristiken.
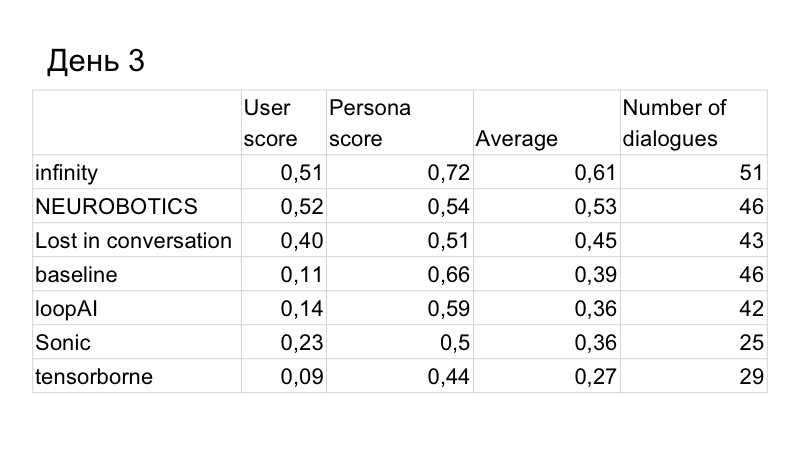
Infolgedessen verbesserte sich die Punktzahl für die Qualität des Dialogs leicht, aber wir wurden von der Person übertroffen. Dies sind die Ergebnisse des dritten Tages, es waren nur noch zwei Tage übrig. Wir haben verstanden, dass es nicht genug Zeit für uns wäre, ein GAN zu schreiben und es normal zu testen, da es schon lange studiert hat und wir viele Hyperparameter auswählen müssen. Deshalb haben wir uns entschlossen, zur Basislinie zu wechseln, weil es so gut funktioniert.

Unsere Aufgabe war es, die Erkennung des Benutzerprofils zu verbessern. Wir haben eine solche Heuristik vorgeschlagen. Was war das Problem? Der Benutzer sprach glücklich mit dem Bot und fragte, welche Art von Arbeit er habe, welche Hobbys er habe, welche Art von Auto er fahre. Der Bot antwortete all dies gut, weil der Bot im Allgemeinen gut reagierte. Infolgedessen sah der Benutzer am Ende des Dialogs zwei Profile, die nichts mit dem zu tun hatten, was sich im Dialog befand, einfach weil dort andere Dinge angezeigt wurden als die, die der Benutzer fragte. Aus diesem Grund haben wir beschlossen, dass es notwendig ist, Informationen aus dem Profil herauszugeben.
Wie geht das am logischsten? Wenn eine Person irgendwelche Interessen hat, wird sie wahrscheinlich darüber sprechen und nach gemeinsamen Interessen suchen. Aus diesem Grund haben wir beschlossen, dass der Bot an einigen Stellen anhand seines Profils Fragen stellt. Es gab einen interessanten Effekt, dass der Generator, der einfach nach den Sprachregeln von G geschrieben wurde, eine Tatsache A aus dem Profil verwendet. Als Ergebnis wird G (A) in den Dialog eingegeben, all dies wird an den Speicher des Bots gesendet und das nächste Mal, wenn das Modell Informationen generiert, Wenn Sie sowohl vom Profil als auch von diesem Dialog ausgehen, dh mit größerer Wahrscheinlichkeit etwas sagen, das mit dem Profil zusammenhängt.
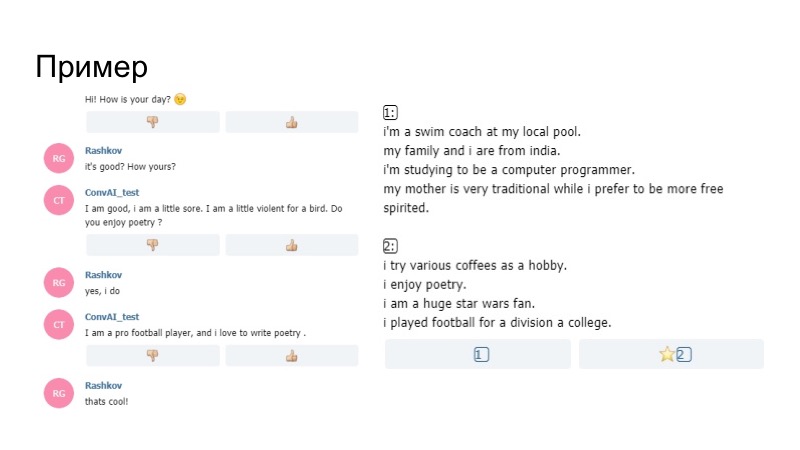
Wie sah es in der Realität aus? Der Bot im Profil sagt, dass er von Poesie begeistert ist, und fragt dann während des Gesprächs, ob ich Poesie mag. Ich sage ja, und weiter nach seinem Modell sagt nicht der Generator, den wir nach den Regeln gebaut haben, dass er gerne Gedichte schreibt. So konzentrierte sich der Bot auf sein Profil und es funktionierte.

Wir kehrten wieder auf den ersten Platz zurück. Der letzte Tag blieb. Wir haben festgestellt, dass wir dennoch als Dialog verlieren.

Wir haben mehrere weitere Lösungen genutzt. Erstens verwendeten sie Paraphrase, analysierten, was andere Leute sagten, weil die Organisatoren diese Datenbank angelegt hatten, und stellten fest, dass viele Leute, die mit dem Bot kommunizieren, nicht ganz korrekt sind.
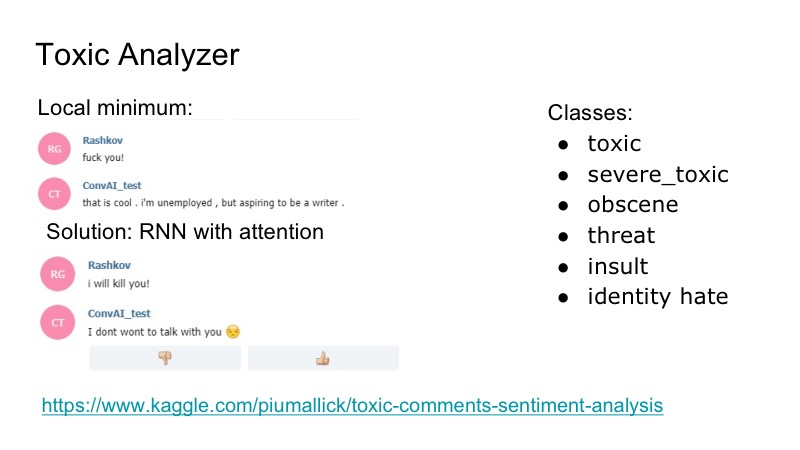
Es gibt ein interessantes lokales Minimum am Bot: Es reagiert sehr gut auf Beleidigungen, er stimmt ihnen zu, und um dies zu beheben, haben wir uns entschlossen, den Kaggle-Wettbewerb für den Analysator für toxische Kommentare zu verwenden. Wir haben einen sehr einfachen Klassifikator geschrieben, ebenfalls mit RNN-Aufmerksamkeit. In diesem Datensatz überlappten sich die folgenden Klassen: Beleidigungen, Bedrohungen ... Aus diesem Grund haben wir beschlossen, das Modell, das sprechen wird, nicht separat zu unterrichten, da ein solches Problem aufgetreten ist, das jedoch nicht sehr häufig auftrat. Deshalb haben wir gerade eine Art Gag geschrieben, auf den der Bot geantwortet hat, und alle waren glücklich.

Zusätzlich haben wir Paraphrase verwendet, um die Sprache unseres Bots zu bereichern. Dies war auch nicht sehr schwierig. Wir haben die Wörter aus der Phrase durch Synonyme ersetzt, die resultierenden n-Gramme in der Phrase betrachtet, so dass sie sich nicht wesentlich von den ursprünglichen unterscheiden, und dann die Kombination ausgewählt, die für die Phrase mit der größten Wahrscheinlichkeit am besten geeignet ist.
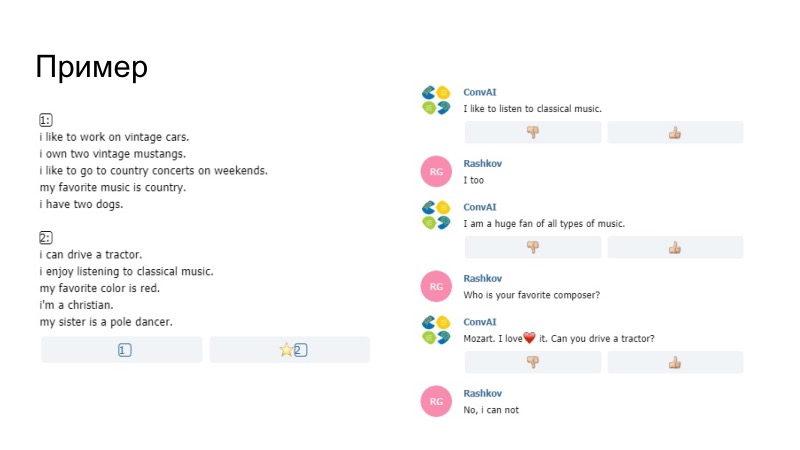
Als Beispiel für das, was passiert ist, sagt der Bot hier, dass er gerne Musik hört, dass es Spaß im Profil macht, dass es durch "Gefällt mir" bei uns ersetzt wurde. Wir sind uns nicht sicher, ob das Modell selbst oder unser Paraphraser es generiert hat, aber dieses Ding hat bestanden. Eine weitere Bemerkung, dass es unmöglich war, nur Daten aus dem Profil zu senden. Dort wurden Pentagramme verglichen. Wenn die Pentagramme mit Ihrer Bemerkung und Ihrem Profil übereinstimmten, dann passierte dieser Satz einfach nicht, die Organisatoren arrangierten ihn. Außerdem haben wir unter anderem ein Smiley-Wörterbuch hinzugefügt.

Im zweiten Beispiel haben wir viele Lächeln. Dann gab es Heuristiken, als der Bot auf Ihr Verhalten reagierte, dass Sie lange nicht darauf geschrieben haben. Paraphraser arbeitete auch hier und es gab ein gutes Ergebnis.

Die Qualität des Dialogs war die beste, auch die Qualität, die Rolle zu spielen.
Wir haben versucht, das Modell dazu zu bringen, eine Reihe von Optionen zu generieren, und wir haben sie mit dem Profil verglichen. Aber es schien mir, dass in diesem Fall der Bot schlechter funktioniert, wir konnten keine Validierung durchführen, nur subjektive Bewertungen in zwei oder drei Gesprächen. Deshalb haben sie beschlossen, so etwas nicht zu setzen, weil das Profil bereits gut erkannt wurde.
Dann haben wir eine Lösung für das inverse Problem geschrieben, das zweite Modell, das das gewünschte Profil aus dem Dialog ausgewählt hat. Wir wollten es zunächst für das Training verwenden, um die Verlustfunktion daraus abzulesen und weiter im Netz zu verteilen. Aber das könnte den Sprecher selbst verschlechtern, also beschlossen sie, es nicht so auszudrücken. Wir haben auch darüber nachgedacht, dieses Ding für das Verhalten des Bots zu verwenden, aber wir hatten keine Zeit, alles zu testen, und beschlossen, dieses Ding abzulehnen. Darüber hinaus haben wir beschlossen, Emoticons basierend auf der emotionalen Färbung der Phrase zu platzieren, ein Modell zu schreiben, aber keinen geeigneten Datensatz zu finden, und diejenigen, die verwendet wurden, sind nicht wenig darüber.

Unser Team.
Auch wenn Ihr Hauptmodell, auf das Sie hoffen, es nicht schreiben kann oder ein schlechtes Ergebnis liefert, geben Sie nicht sofort auf, Sie müssen einige einfachere Dinge ausprobieren, was ganz natürlich ist. Und zweitens lohnt es sich manchmal, zu beobachten, was Ihrem Modell fehlt, und über bestimmte Aufgaben nachzudenken, diese zu zerlegen und bestimmte Problembereiche zu lösen, was wir getan haben. Vielen Dank für Ihre Aufmerksamkeit.
Sergey Kolesnikov:
- Mein Name ist Sergey Kolesnikov, ich werde die Entscheidung von Tensorborne vertreten.

Wir haben uns einen schönen Namen ausgedacht, sind zum Wettbewerb gegangen, haben uns viele verschiedene Stücke ausgedacht, um danach zwei Artikel zu veröffentlichen, haben aber den Hackathon nicht gewonnen. Daher heißt es: "Wie man den Hackathon nicht gewinnt, aber trotzdem die verdammten zwei Artikel veröffentlicht." Akademiker, Sir.
Die Merkmale des Wettbewerbs, an dem wir teilgenommen haben, haben unsere Motivation übertroffen. Aufgrund der Tatsache, dass die Bewertung täglich durchgeführt wurde, mussten die Pakete auch täglich erstellt werden, und die endgültige Belohnung wurde, wie wir es in RL mögen, durch diskontierte Summierung bestimmt. All dies führte dazu, dass wir jeden Tag mindestens etwas senden mussten, damit es funktionierte, und wir bekamen zumindest eine Art Punktzahl. Infolgedessen ist es wirklich zu dem gewachsen, was Sie wollen - Sie wollen nicht, aber Sie mussten rudern.
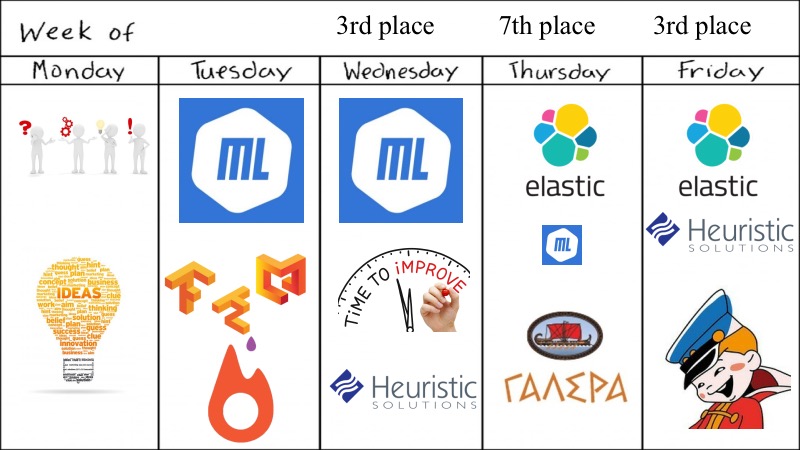
Was hatten wir? Vorschau für die ganze Woche.
Trotz der Tatsache, dass der Hackathon sagte, dass er wöchentlich war, wurde alles in vier Tagen entschieden, was für diese Aufgabe ConvAI nicht genug zu sein scheint.
Anfangs waren wir zu fünft, alle gute akademische Absolventen oder so Fiztekh, also kamen wir am Montag und warfen viele Vorschläge, Ideen, die Sie ausprobieren können, und welche Deep-Learning-Modelle Sie ausprobieren sollten. Wir haben zwar nicht mit GAN experimentiert, weil wir bereits mit ihnen für Texte experimentiert haben und dies nicht funktioniert. Deshalb haben wir etwas Einfacheres genommen, außerdem gab es sehr ähnliche Wettbewerbe und wir hatten Pretrain-Modelle. Am Dienstag konnten wir sogar etwas über Deep Learning starten, ML war wo immer möglich, wir haben wundervolle Docker mit GPU-Unterstützung und andere Dinge für Tensorflow und Keras gestartet, wir müssen dafür eine separate Medaille vergeben, da dies nicht so trivial ist wie ich möchte.
Nach den Ergebnissen vom Dienstag waren sie vielversprechend, und wir beschlossen, unsere ML mit kleinen Heuristiken und dergleichen leicht zu verbessern, und scheiterten auf dem siebten Platz. Aber dank unserer Teamkollegen hat jemand ElasticSearch gefunden und ausprobiert. Es gab einen sehr unangenehmen Moment, in dem ElasticSearch einwandfrei funktionierte und DL-Modelle und ML usw. etwas weniger robust waren. Das Ende des Wettbewerbs war nahe. Und wie der Vorredner feststellte, haben wir uns entschlossen, in die Richtung zu paddeln, die funktioniert. Wir haben ElasticSearch, kleine Heuristiken, genommen und fanden das gut genug und wirklich gut genug, weil wir den zweiten Platz belegt haben.
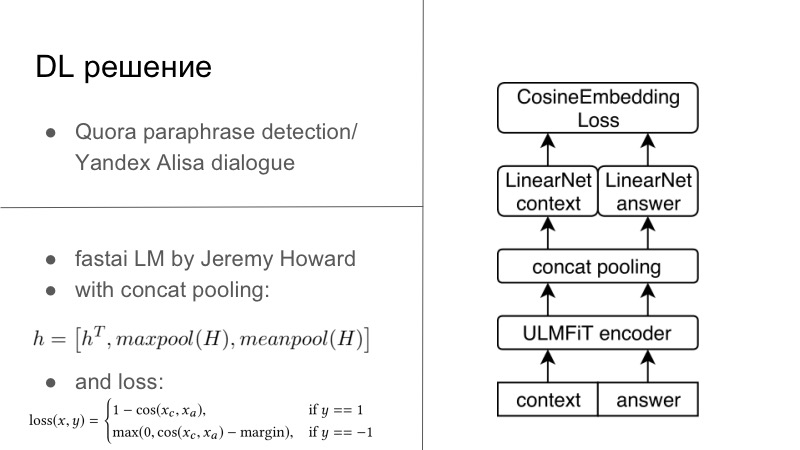
Weitere Details. Tatsächlich gab es mehrere DL-Lösungen. Die erste DL-Lösung war recht einfach. Wer erinnert sich, im Jahr vor dem letzten oder letzten Jahr gab es einen Quora-Paraphrase-Erkennungswettbewerb, und dieses Jahr gab es einen Wettbewerb von Yandex für Alice, um Dialoge und mehr zu erstellen. Möglicherweise stellen Sie fest, dass die Aufgaben dort sehr eng sind. Im ersten musste gesagt werden, ob diese beiden Sätze Paraphrasen waren, und im zweiten musste der Dialog fortgesetzt werden. Wir dachten, da wir Dialogsysteme entwickeln, lassen Sie uns den Dialog auch gut fortsetzen. Und es hat perfekt funktioniert, der Dialog mit Quora war sehr persönlich.
Im Grunde sah alles so aus, als hätten wir einen Encoder, normalerweise trainieren wir alle auf unseren üblichen RNNs und vorzugsweise LSTM mit Aufmerksamkeit und anderen Dingen. Und dann haben wir standardmäßig entweder den auf der Folie unten dargestellten Cosaine-Einbettungsverlust oder einen anderen Einbettungsverlust vom Typ Tripler-Verlust verwendet oder etwas anderes, das Paraphrase oder Antworten auf einen bestimmten Dialog einbettet, und keine Paraphrase-Verzögerungen usw. Dies war die erste Lösung, es war auf Tensorflow, Keras, es war fertig, wir haben es versucht und es war ziemlich gut.
Eine andere Lösung wurde an einem Tag zwei Hackathons am Abend geboren. Es gibt einen wunderbaren Jeremy Howard, er fördert DL und ML für alle, er hat zwei wundervolle Kurse, die Sie in diesen Kurs und mehr einführen, und für diesen Kurs hat er sein FastAI geschrieben. All dies funktioniert auf PyTorch und schreibt PyTorch in vielerlei Hinsicht sogar neu. Dies ist einer der Minuspunkte dieser Bibliothek. Aber von den Pluspunkten her hat Jeremy wenig mit NLP zu tun. In diesem Jahr veröffentlichten sie im März einen Artikel mit einem anderen Studenten, in dem sie LSTM in allen Best Practices des wunderbaren FastAI schulten, mit vielen Tricks, die er in seinem Kurs fördert, und SOTA praktisch erhielten für alles.
Da ich ein kleiner Evangelist von PyTorch bin, konnte ich dieses Modell immer noch von FastAI entwurzeln, es, wie Sie bereits sagen können, in mein PyTorch-Framework packen und sogar das Ganze für diese Aufgabe trainieren. Grundsätzlich hatten wir einen bestimmten Dialogkontext. Selbst wenn wir mehrere Sätze hatten, verketten Sie ihn einfach zu einem kräftigen Satz. Und dann hatten wir eine Antwort, einen Vorschlag. FastAI, Universal Language Model — — Encoder.
, , , 1 , seq2seq. . , , FastAI — Concat poolling. ? seq2seq, attention. maxpool minpool , , .
, , , , maxpool minpool, . , — H, Hc Ha. , feedforward , . , , , , metric learning. — CosineEmbedding Loss, PyTorch.
, loss . , contrastive loss, , . , .
DL-. ElasticSearch, .
? , - ElasticSearch . - - Persona Dataset , , Facebook, , , - . - . , , , , , Persona Dataset , Amazon Mechanical Turk , .
ElasticSearch, , . , Persona Dataset , , 10 . , . , , , , .
- . , Persona , , , , , evaluation. heuristic solutions.
, , , , . . , , , , , . .
— . , — -, -, , .
dirty hack. , , . . — , .

? , -DL- , DL, . , , , . . , -, , , . , , . . , , . DL , ElasticSearch .
, personality score. , -, 0,25–0,3 , . , , - .

. — , , , Docker ElasticSearch, . , . . . Also, try to guess… , — , funny you. , general, . , , .
, , . . , — , , . , Docker, .

? ConvAI , NIPS, - .
-, ElasticSearch . , , . , , ElasticSearch . , DL.
-, DL-. : , , , . , , , , .
, . , . , . — pre-trained- ( — . .), . .
, proposals , RL bandits . , . — . , . , , , , toxic- . .
— . , DeepHacks . NLP, DeepHack , , « ». , . . , , , , , .
— . distributed- , . , DeepHack. - . . , , , , .
! . pre-trained-. , , .
Und natürlich einen Hackathonurlaub machen. Wenn Sie an einem wöchentlichen Hackathon teilnehmen und gleichzeitig arbeiten, ist das schlecht. Sie kommen um 19 Uhr an, nachdem Sie ein wenig gearbeitet haben, setzen sich und kompilieren Docker mit TensorFlow, Keras, so dass alles auf einigen Remote-Servern beginnt, auf die Sie nicht einmal Zugriff haben. Irgendwann in zwei Nächten erkranken Sie an Katharsis, und das funktioniert bei Ihnen - ohne Docker, ohne alles, weil Sie verstanden haben, dass dies möglich ist und so.Es scheint, dass Sie, wenn Sie an einem großen Wettbewerb teilnehmen, etwas mehr Zeit dafür einplanen, als wie viel Sie in einer Woche nicht schlafen können, und teilnehmen. Geh und gewinne. Vielen Dank!