Auf der NVIDIA SIGGRAPH 2018 stellte Firmenchef Jensen Juan offiziell die lang erwartete (und gemunkelte und spekulierte) Turing-GPU-Architektur vor. Die nächste Generation von NVIDIA-GPUs, Turing, wird eine Reihe neuer Funktionen enthalten und später in diesem Jahr die Welt sehen. Obwohl die professionelle Visualisierung (ProViz) im Mittelpunkt der heutigen Ankündigungen stand, erwarten wir, dass die neue Architektur in anderen kommenden NVIDIA-Produkten verwendet wird. Der heutige Test ist nicht nur eine Auflistung aller Funktionen von Turing.

Hybrid-Rendering und neuronale Netze: RT- und Tensorkerne
Was ist das Besondere und Neue an der Turing-Architektur? Marquee wurde zumindest für die NVIDIA ProViz-Community für das Hybrid-Rendering entwickelt, bei dem Raytracing mit herkömmlicher Rasterung kombiniert wird.

Wesentliche Änderung: NVIDIA hat noch mehr Raytracing-Geräte in Turing aufgenommen, um die schnellste hardwarebeschleunigte Raytracing-Funktion anzubieten. Neu für die Turing-Architektur ist die spezialisierte RT Core-Recheneinheit, wie NVIDIA sie nennt. Derzeit gibt es nicht genügend Informationen darüber. Es ist nur bekannt, dass ihre Funktion die Unterstützung der Raytracing-Funktion ist. Diese Prozessoreinheiten beschleunigen sowohl die Überprüfung des Schnittpunkts von Strahlen und Dreiecken als auch die Manipulation von BVH (Hierarchien von Begrenzungsvolumina).
NVIDIA behauptet, dass die schnellsten Turing-Komponenten 10 Milliarden (Giga) Strahlen pro Sekunde zählen können, was im Vergleich zum nicht beschleunigten Pascal eine 25-fache Verbesserung der Raytracing-Leistung darstellt.
Die Turing-Architektur umfasst verstärkte Volta-Tensorkerne. Tensorkerne sind ein wichtiger Aspekt mehrerer NVIDIA-Initiativen. Neben der Beschleunigung der Strahlverfolgung besteht ein wichtiges Werkzeug in der „Zaubertrick-Tasche“ von NVIDIA darin, die Anzahl der in der Szene erforderlichen Strahlen mithilfe der KI-Rauschunterdrückung zu reduzieren, um das Bild zu löschen. Hier sind die Tensorkerne am besten geeignet. Natürlich ist dies nicht der einzige Bereich, in dem sie gut sind - alle neuronalen Netze und KI-Imperien von NVIDIA bauen darauf auf.
Turing zeichnet sich durch die Unterstützung eines größeren Genauigkeitsbereichs aus, was die Möglichkeit einer signifikanten Beschleunigung bei Arbeitslasten ohne hohe Genauigkeitsanforderungen bedeutet. Zusätzlich zum Präzisionsmodus Volta FP16 unterstützen Turing-Tensorkerne INT8 und sogar INT4. Dies ist zwei- bzw. viermal schneller als FP16. Obwohl NVIDIA bei der Präsentation nicht auf Details eingehen wollte, würde ich vorschlagen, dass sie etwas Ähnliches wie Datenverpackungen implementieren, die für Operationen mit geringer Genauigkeit auf CUDA-Kernen verwendet werden. Trotz der verringerten Genauigkeit des neuronalen Netzwerks (die Rückgabe ist verringert - laut INT4 erhalten wir nur 16 (!) Werte) - gibt es bestimmte Modelle, die diese geringe Genauigkeit wirklich benötigen. Infolgedessen zeigen Modi mit reduzierter Genauigkeit einen guten Durchsatz, insbesondere bei Ausgabeaufgaben, was zweifellos einigen Benutzern gefallen wird.
Zurück zum Hybrid-Rendering im Allgemeinen ist es interessant, dass NVIDIA trotz dieser großen individuellen Beschleunigungen das allgemeine Versprechen von Leistungssteigerungen etwas bescheidener erscheint. Obwohl das Unternehmen verspricht, die Produktivität im Vergleich zu Pascal um das Sechsfache zu steigern, ist es an der Zeit zu fragen, welche Teile im Vergleich zu welchen beschleunigt werden. Die Zeit wird zeigen.
Um Tensorkerne außerhalb von Raytracing und eng fokussierten Deep-Learning-Aufgaben besser nutzen zu können, wird NVIDIA ein SDK, NVIDIA NGX, bereitstellen, das die Integration neuronaler Netze in die Bildverarbeitung ermöglicht. NVIDIA erwartet die Verwendung neuronaler Netze und Tensorkerne für zusätzliche Bild- und Videoverarbeitung, einschließlich Methoden wie dem bevorstehenden Deep-Anti-Aliasing (DLAA).
Turing SM: dedizierte INT-Kerne, einzelner Cache, Shading mit variabler Rate
Neben RT- und Tensorkernen führt die Turing Streaming Multiprocessor (SM) -Architektur selbst neue Tricks ein. Insbesondere wurde eine der letzten Volta-Änderungen vererbt, wodurch Integer-Kerne in ihren eigenen Blöcken zugewiesen werden und nicht Teil der CUDA-Gleitkommakerne sind. Der Vorteil ist eine schnellere Adressgenerierung und FMA-Leistung (Fused Multiply Add).
Was ALU betrifft (ich warte immer noch auf die Bestätigung für Turing) - Unterstützung für schnellere Operationen mit geringer Genauigkeit (zum Beispiel schnelles FP16). In Volta wird dies als Betrieb von FP16 mit doppelter Frequenz relativ zu FP32 und INT8-Betrieb mit 4-facher Geschwindigkeit implementiert. Tensorkerne unterstützen dieses Konzept bereits, daher wäre es logisch, es auf CUDA-Kernel zu übertragen.
Schnelles FP16, Rapid Packed Math-Technologie und andere Möglichkeiten, mehrere kleine Operationen in eine große Operation zu packen, sind Schlüsselkomponenten für die Verbesserung der GPU-Leistung in einer Zeit, in der sich Moores Gesetz verlangsamt.
Wenn große (exakte) Datentypen nur bei Bedarf verwendet werden, können sie zusammen gepackt werden, um mehr Arbeit im gleichen Zeitraum zu erledigen. Dies ist vor allem für die Ausgabe neuronaler Netze sowie für die Spieleentwicklung wichtig. Tatsache ist, dass nicht alle Shader-Programme FP32-Präzision benötigen und eine Verringerung der Genauigkeit die Leistung verbessern und die nützliche Speicherbandbreite sowie die Verwendung der Registrierungsdatei verringern kann.
Turing SM enthält etwas, das NVIDIA als "einheitliche Cache-Architektur" bezeichnet. Da ich immer noch offizielle SMID-Diagramme von NVIDIA erwarte, ist nicht klar, ob dies dieselbe Vereinheitlichung ist, die wir bei Volta gesehen haben - wo der L1-Cache mit gemeinsam genutztem Speicher kombiniert wurde - oder ob NVIDIA noch einen Schritt weiter gegangen ist. Auf jeden Fall behauptet NVIDIA, dass es jetzt doppelt so viel Bandbreite bietet wie die "vorherige Generation", aber es ist nicht klar, ob es "Pascal" oder "Volta" bedeutet (letzteres ist wahrscheinlicher).
Schließlich wurde, tief in der Pressemitteilung von Turing verborgen, die Unterstützung von Schattierungen mit variabler Rate erwähnt. Dies ist eine relativ junge und sich weiterentwickelnde Grafik-Rendering-Technologie, über die nur wenige Informationen vorliegen (insbesondere darüber, wie genau sie von NVIDIA implementiert wird). Bei einem sehr hohen Abstraktionsgrad klingt dies jedoch wie „NVIDIAs Technologie der nächsten Generation, mit der Sie Schattierungen mit unterschiedlichen Auflösungen anwenden können, mit der Entwickler verschiedene Bereiche des Bildschirms mit unterschiedlichen effektiven Auflösungen anzeigen können, um die Qualität (und die Renderzeit) in Bereichen zu konzentrieren, in denen sie am dringendsten benötigt wird.“ .
Füttere das Biest: GDDR6-Unterstützung
Da der von GPUs verwendete Speicher von Drittanbietern entwickelt wird, gibt es keine Geheimnisse. JEDEC und sein großes dreiköpfiges Unternehmen Samsung, SK Hynix und Micron entwickeln GDDR6-Speicher als Nachfolger von GDDR5 und GDDR5X. NVIDIA hat bestätigt, dass Turing dies unterstützen wird. Je nach Hersteller wird für GDDR6 der ersten Generation eine Speicherbandbreite von bis zu 16 Gbit / s pro Bus angegeben, was doppelt so viel ist wie bei NVIDIA GDDR5-Karten der neuesten Generation und 40% schneller als bei den neuesten NVIDIA GDDR5X-Karten.
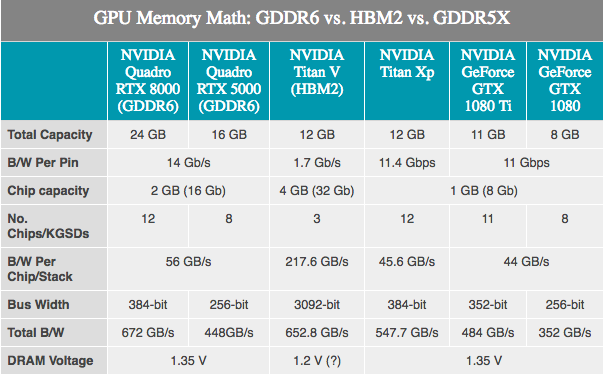
Im Vergleich zu GDDR5X scheint GDDR6 kein großer Durchbruch zu sein, da viele der GDDR6-Innovationen bereits auf GDDR5X angewendet wurden. Zu den grundlegenden Änderungen gehören niedrigere Betriebsspannungen (1,35 V), und der interne Speicher ist jetzt aufgeteilt: zwei Speicherkanäle pro Mikroschaltung. Für einen Standard-32-Bit-Chip - zwei 16-Bit-Speicherkanäle - haben wir insgesamt 16 solcher Kanäle auf einer 256-Bit-Karte. Obwohl dies wiederum besagt, dass es eine sehr große Anzahl von Kanälen gibt, werden GPUs den maximalen Nutzen aus der Innovation ziehen, da sie historisch gesehen die „parallelsten“ Geräte sind.

NVIDIA hat seinerseits bestätigt, dass die ersten Turing Quadro-Karten GDDR6 mit 14 Gbit / s verwenden werden. Gleichzeitig bestätigte NVIDIA auch die Verwendung von Samsung-Speicher, insbesondere für seine fortschrittlichen 16-Gigabyte-Geräte. Dies ist wichtig, da dies bedeutet, dass eine typische 256-Bit-NVIDIA-GPU mit 8 Standardmodulen ausgestattet werden kann und 16 GB Gesamtspeicherkapazität erhält, oder sogar 32 GB, wenn sie den Clamshell-Modus verwenden (ermöglicht die Adressierung von 32 GB Speicher auf Standard-256-Bit) Bus).
Alle möglichen Details: NVLink, VirtualLink und 8K HEVC
NVIDIA endete bereits mit einer Überprüfung der Turing-Architektur und bestätigte beiläufig die Unterstützung einiger der neuen externen E / A-Funktionen. NVLink-Unterstützung wird in mindestens mehreren Turing-Produkten vorhanden sein. Denken Sie daran, dass NVIDIA es in allen drei neuen Quadro-Karten verwendet. NVIDIA bietet eine bidirektionale GPU-Konfiguration.
Ein wichtiger Punkt (bevor ein Teil unseres spielorientierten Publikums tief in das Lesen eintaucht): Das Vorhandensein von NVLink in Turing-Geräten bedeutet nicht, dass es in Consumer-Grafikkarten verwendet wird. Vielleicht beschränkt sich alles nur auf Quadro- und Tesla-Karten.
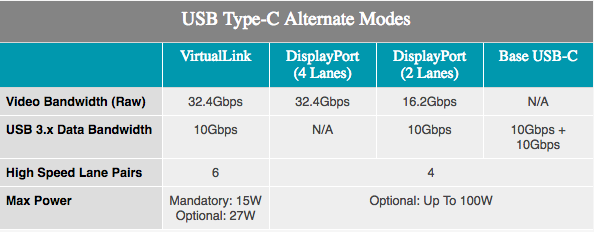
Mit der zusätzlichen VirtualLink-Unterstützung können ProViz-Spieler und -Benutzer von VR erwarten. Ein alternativer USB-Typ-C-Modus wurde im letzten Monat angekündigt und unterstützt 15 W + Leistung, 10 Gbit / s Datenübertragung dank USB 3.1 Gen 2, 4 DisplayPort HBR3-Bändern an einem Kabel. Mit anderen Worten, dies ist eine DisplayPort 1.4-Verbindung mit zusätzlichen Daten und Strom. Dadurch kann die Grafikkarte das VR-Headset direkt steuern. Der Standard wird von NVIDIA, AMD, Oculus, Valve und Microsoft unterstützt, sodass Turing-Produkte das erste einer Reihe von Produkten sein werden, die den neuen Standard unterstützen.
Obwohl NVIDIA das Thema kaum angesprochen hat, wissen wir, dass die NVENC-Video-Encoder-Einheit in Turing aktualisiert wurde. Die neueste NVENC-Iteration bietet spezielle Unterstützung für die HEKC 8K-Codierung. In der Zwischenzeit konnte NVIDIA die Qualität seines Encoders verbessern und so die gleiche Qualität wie zuvor mit einer um 25% niedrigeren Videobitrate erzielen.
Leistungsindikatoren
Neben den angekündigten Hardwarespezifikationen zeigt NVIDIA mehrere Zahlen zur Leistung der Turing-Geräte. Es sei darauf hingewiesen, dass wir hier sehr, sehr wenig wissen. Die Komponenten basieren offenbar auf den vollständig und teilweise enthaltenen Turing-SKUs mit 4608 CUDA-Kernen und 576 Tensorkernen. Die Frequenzen wurden jedoch nicht bekannt gegeben, da diese Zahlen für Quadro-Hardware profiliert sind, werden wir wahrscheinlich niedrigere Taktraten als bei allen Verbrauchergeräten feststellen.

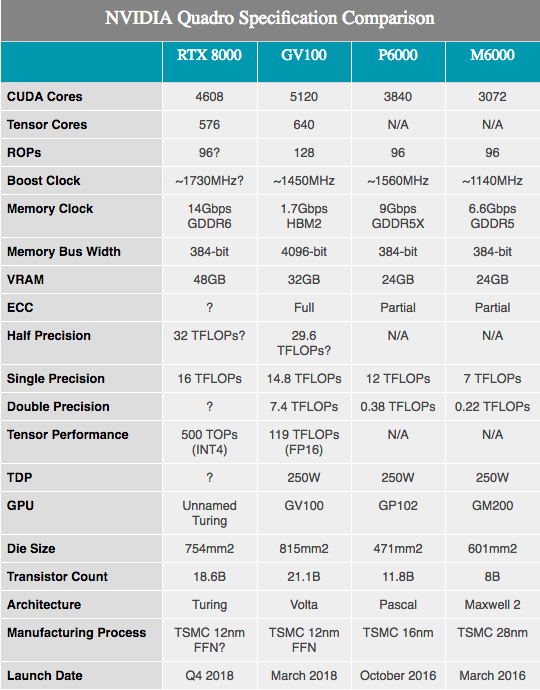
Zusammen mit den oben genannten 10GigaRays / s für RT-Kerne beträgt die Leistung von NVIDIA-Tensorkernen 500 Billionen Tensoroperationen pro Sekunde (500T TOPs). Als Referenz erwähnt NVIDIA häufig, dass die GV100-GPU maximal 120 T TOP liefern kann, aber dies ist nicht dasselbe. Während der GV100 bei der Verarbeitung von FP16-Vorgängen erwähnt wird, wird die Turing-Leistung mit INT4 mit extrem geringer Genauigkeit angegeben, was nur ein Viertel der Größe von FP16 entspricht und daher den Durchsatz um das Vierfache erhöht. Wenn wir die Genauigkeit normalisieren, scheinen Turing-Tensorkerne nicht den besten Durchsatz pro Kern zu haben, sondern bieten mehr Genauigkeitsoptionen als Volta. In jedem Fall haben 576 Tensorkerne in diesem Chip fast das Niveau des GV100 erreicht, der 640 solcher Kerne hat.
In Bezug auf die CUDA-Kerne behauptet NVIDIA, dass die Turing-GPU 16 TFLOPS-Leistung bieten kann. Dies liegt etwas über der Leistung von 15 TFLOPS mit der einfachen Präzision des Tesla V100 oder sogar noch mehr vor der Leistung von 13,8 TFLOPS von Titan V. Wenn Sie nach verbraucherfreundlicheren Informationen suchen, sind dies etwa 32% mehr als beim Titan Xp. Nachdem wir einige grobe Berechnungen auf Papier skizziert haben, können wir von einer GPU-Taktrate von etwa 1730 MHz ausgehen, da auf SM-Ebene keine zusätzlichen Änderungen vorgenommen wurden, die die traditionellen ALU-Leistungsformeln ändern würden.
In der Zwischenzeit gab NVIDIA bekannt, dass die Quadro-Karten mit einem GDDR6-Speicher mit 14 Gbit / s ausgestattet sein werden. Wenn wir uns die beiden besten Quadro-SKUs mit 48 GB bzw. 24 GB GDDR6 ansehen, sehen wir fast den 384-Bit-Speicherbus auf dieser Turing-GPU. In Zahlen ausgedrückt entspricht dies einer Speicherbandbreite von 672 GB / s für die beiden Top-End-Quadro-Karten.
Andernfalls ist es bei einer Änderung der Architektur schwierig, viele nützliche Leistungsvergleiche durchzuführen, insbesondere beim Vergleich mit Pascal. Nach dem, was wir mit Volta gesehen haben, hat sich die Gesamtleistung von NVIDIA verbessert, insbesondere bei gut gestalteten Computer-Workloads. Daher kann eine Verbesserung der Papierleistung um ungefähr 33% im Vergleich zum Quadro P6000 etwas viel Größeres sein.
Ich werde die Kristallgröße der neuen GPU erwähnen. Es befindet sich auf 754 mm2 und ist nicht nur groß, sondern auch riesig. Im Vergleich zu anderen GPUs ist nur NVIDIA GV100 an zweiter Stelle, was derzeit das Flaggschiff von NVIDIA bleibt. Bei 18,6 Milliarden Transistoren ist jedoch leicht zu erkennen, warum der resultierende Chip so groß sein sollte. Anscheinend hat NVIDIA große Pläne für diese GPU, die letztendlich das Vorhandensein von zwei riesigen Grafikprozessoren in ihrem Produktstapel rechtfertigen können.
NVIDIA hat seinerseits keine spezifische Modellnummer für diese GPU angegeben - unabhängig davon, ob es sich um eine herkömmliche GPU der Klasse 102 oder sogar der Klasse 100 handelt. Ich frage mich, ob wir eine Modifikation dieser Art von GPU für ein Verbraucherprodukt in der einen oder anderen Form sehen werden. Es ist so groß, dass NVIDIA es möglicherweise für seine profitableren Quadro- und Tesla-GPUs behalten möchte.
Veröffentlicht im vierten Quartal 2018, wenn nicht früher
Abschließend möchte ich sagen, dass NVIDIA zusammen mit der Ankündigung der Turing-Architektur angekündigt hat, dass die ersten 4 Quadro-Karten auf Basis der Turing-GPUs - Quadro RTX 8000, RTX 6000 und RTX 5000 - im vierten Quartal dieses Jahres ausgeliefert werden. Da die Art dieser Ankündigung etwas umgekehrt ist - normalerweise kündigt NVIDIA zuerst Verbraucherkomponenten an -, würde ich nicht dieselbe Zeitleiste auf Verbraucherkarten anwenden, für die keine so strengen Validierungsanforderungen gelten. Wir werden Turing-Geräte im vierten Quartal dieses Jahres sehen, wenn nicht früher. Wer Quadro kaufen möchte, kann jetzt Geld sparen: Das Beste der neuen Quadro RTX 8000-Karten kostet etwa 10.000 US-Dollar.
Für Verbraucher mit NVIDIAs Tesla lässt die Einführung des Turing Volta in der Schwebe. NVIDIA teilte uns nicht mit, ob Turing irgendwann in den High-End-Bereich von Tesla expandieren und den GV100 ersetzen würde oder ob der beste Volta-Prozessor jahrhundertelang der Meister seiner Domäne bleiben würde. Da die anderen Tesla-Karten bisher auf Pascal basieren, sind sie die ersten Kandidaten für die Verdrängung von Turing im Jahr 2019.
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden empfehlen, einen
Rabatt von 30% für Habr-Benutzer auf ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s von $ 20 oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s bis Dezember kostenlos, wenn Sie für einen Zeitraum von sechs Monaten bezahlen, können Sie
hier bestellen.
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel Dodeca-Core Xeon E5-2650v4 128 GB DDR4 6 x 480 GB SSD 1 Gbit / s 100 TV von 249 US-Dollar in den Niederlanden und den USA! Lesen Sie,
wie Sie eine Infrastruktur aufbauen Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?