Durch die Einführung von AI auf Chipebene können Sie mehr Daten lokal verarbeiten, da eine Erhöhung der Anzahl der Geräte nicht mehr den gleichen Effekt erzielt
Chiphersteller arbeiten an neuen Architekturen, die die pro Watt und Zyklus verarbeitete Datenmenge erheblich erhöhen. Der Grundstein für eine der größten Revolutionen in der Chiparchitektur der letzten Jahrzehnte ist gelegt.
Alle großen Hersteller von Chips und Systemen ändern die Entwicklungsrichtung. Sie traten in das Rennen der Architekturen ein, das einen Paradigmenwechsel in allem ermöglicht: von Lese- und Schreibmethoden über das Gedächtnis bis hin zu ihrer Verarbeitung und letztendlich dem Layout verschiedener Elemente auf einem Chip. Obwohl die Miniaturisierung fortgesetzt wird, setzt niemand auf Skalierung, um mit dem explosiven Wachstum von Daten von Sensoren und der Erhöhung des Verkehrsaufkommens zwischen Maschinen fertig zu werden.
Unter den Änderungen in den neuen Architekturen:
- Neue Methoden zur Verarbeitung einer größeren Datenmenge in einem Taktzyklus, manchmal mit geringerer Genauigkeit oder nach Priorität bestimmter Vorgänge, je nach Anwendung.
- Neue Speicherarchitekturen, die die Art und Weise ändern, wie wir Daten speichern, lesen, schreiben und darauf zugreifen.
- Spezialisierte Verarbeitungsmodule im gesamten System in der Nähe des Speichers. Anstelle eines Zentralprozessors werden je nach Datentyp und Anwendung Beschleuniger ausgewählt.
- Auf dem Gebiet der KI wird daran gearbeitet, verschiedene Datentypen in Form von Vorlagen zu kombinieren, wodurch die Datendichte effektiv erhöht und Diskrepanzen zwischen verschiedenen Typen minimiert werden.
- Jetzt ist das Layout im Gehäuse der Hauptbestandteil der Architektur, wobei immer mehr auf die einfache Änderung dieser Designs geachtet wird.
"Es gibt verschiedene Trends, die den technologischen Fortschritt beeinflussen", sagte Stephen Wu, ein angesehener Rambus-Ingenieur. - In Rechenzentren können Sie Hardware und Software optimal nutzen. Aus diesem Blickwinkel betrachten die Eigentümer von Rechenzentren die Wirtschaft. Etwas Neues einzuführen ist teuer. Da sich jedoch die Engpässe ändern, werden spezielle Chips für eine effizientere Datenverarbeitung eingeführt. Und wenn Sie den Datenfluss zu E / A und Speicher reduzieren, kann dies große Auswirkungen haben. “
Die Änderungen sind am Rande der Computerinfrastruktur, dh bei den Endsensoren, offensichtlicher. Die Hersteller erkannten plötzlich, dass Dutzende Milliarden Geräte zu viele Daten generieren würden: Ein solches Volumen konnte nicht zur Verarbeitung in die Cloud gesendet werden. Die Verarbeitung all dieser Daten am Rande führt jedoch zu anderen Problemen: Sie erfordern erhebliche Leistungsverbesserungen, ohne den Stromverbrauch signifikant zu erhöhen.
"Es gibt einen neuen Trend zu geringerer Genauigkeit", sagte Robert Ober, Teslas führender Plattformarchitekt bei Nvidia. - Dies sind nicht nur Rechenzyklen. Dies ist ein intensiveres Packen von Daten in den Speicher, wo das Format von 16-Bit-Befehlen verwendet wird. “
Aubert glaubt, dass Sie dank einer Reihe von Architekturoptimierungen in absehbarer Zukunft die Verarbeitungsgeschwindigkeit alle paar Jahre verdoppeln können. "Wir werden eine dramatische Steigerung der Produktivität sehen", sagte er. - Dafür müssen Sie drei Dinge tun. Der erste ist das Rechnen. Der zweite ist die Erinnerung. Der dritte Bereich ist die Hostbandbreite und die E / A-Bandbreite. Es muss noch viel Arbeit geleistet werden, um den Speicher und den Netzwerkstapel zu optimieren. “
Es wird bereits etwas implementiert. In einer Präsentation auf der Hot Chips-Konferenz 2018 wies Jeff Rupley, leitender Architekt im Austin Research Center von Samsung, auf einige wichtige architektonische Änderungen am M3-Prozessor hin. Eine enthält mehr Anweisungen pro Schlag - sechs statt vier im letzten M2-Chip. Zusätzlich wurde eine Verzweigungsvorhersage in neuronalen Netzen implementiert und die Befehlswarteschlange wurde verdoppelt.
Solche Änderungen verlagern den Innovationspunkt von der direkten Herstellung von Mikroschaltungen auf Architektur und Design einerseits und auf die Anordnung von Elementen auf der anderen Seite der Produktionskette. Obwohl die Innovationen in technologischen Prozessen fortgesetzt werden, ist es nur auf Kosten dieser unglaublich schwierig, in jedem neuen Chipmodell eine Steigerung der Produktivität und Leistung um 15 bis 20% zu erreichen - und dies reicht nicht aus, um das schnelle Wachstum des Datenvolumens zu bewältigen.
"Änderungen finden exponentiell statt", sagte Victor Pan, Präsident und CEO von Xilinx, in einer Rede auf der Hot Chips-Konferenz. "Jedes Jahr werden 10 Zettabyte [10
21 Byte] Daten generiert, die meisten davon in unstrukturierter Form."
Neue Ansätze zur Erinnerung
Das Arbeiten mit so vielen Daten erfordert ein Umdenken jeder Komponente im System, von den Datenverarbeitungsmethoden bis zu ihrer Speicherung.
"Es gab viele Versuche, neue Speicherarchitekturen zu erstellen", sagte Carlos Machin, Senior Innovation Director bei eSilicon EMEA. - Das Problem ist, dass Sie alle Zeilen lesen und jeweils ein Bit auswählen müssen. Eine Möglichkeit besteht darin, einen Speicher zu erstellen, der von links nach rechts sowie von oben nach unten gelesen werden kann. Sie können noch weiter gehen und dem Speicher Berechnungen hinzufügen. “
Diese Änderungen umfassen das Ändern der Methoden zum Lesen des Speichers, der Position und des Typs der Verarbeitungselemente sowie die Einführung von AI, um die Speicherung, Verarbeitung und Bewegung von Daten im gesamten System zu priorisieren.
„Was ist, wenn wir bei spärlichen Daten jeweils nur ein Byte aus diesem Array lesen können - oder vielleicht acht aufeinanderfolgende Bytes aus demselben Bytepfad, ohne Energie für andere Bytes oder Bytepfade zu verschwenden, an denen wir nicht interessiert sind ? "Fragt Mark Greenberg, Cadence Product Marketing Director." - In Zukunft ist dies möglich. Wenn Sie sich beispielsweise die Architektur von HBM2 ansehen, ist der Stapel in 16 virtuellen Kanälen mit jeweils 64 Bit organisiert, und Sie benötigen nur 4 aufeinanderfolgende 64-Bit-Wörter, um auf einen virtuellen Kanal zuzugreifen. Somit ist es möglich, Datenfelder mit einer Breite von 1024 Bit zu erstellen, horizontal zu schreiben, aber vier 64-Bit-Wörter gleichzeitig vertikal zu lesen. "
Das Gedächtnis ist eine der Hauptkomponenten der von Neumann-Architektur, aber jetzt ist es auch eine der Hauptarenen für Experimente geworden. "Der Hauptfeind sind virtuelle Speichersysteme, bei denen Daten auf unnatürlichere Weise verschoben werden", sagte Dan Bouvier, Chefarchitekt für Kundenprodukte bei AMD. - Dies ist eine Sendung. Daran sind wir im Bereich Grafik gewöhnt. Wenn wir jedoch die Konflikte in der DRAM-Speicherbank lösen, erhalten wir ein viel effizienteres Streaming. Dann kann eine separate GPU DRAM im Bereich von 90% Wirkungsgrad verwenden, was sehr gut ist. Wenn Sie das Streaming jedoch ohne Unterbrechungen einrichten, fallen CPU und APU ebenfalls in den Wirkungsgradbereich von 80% bis 85%. “
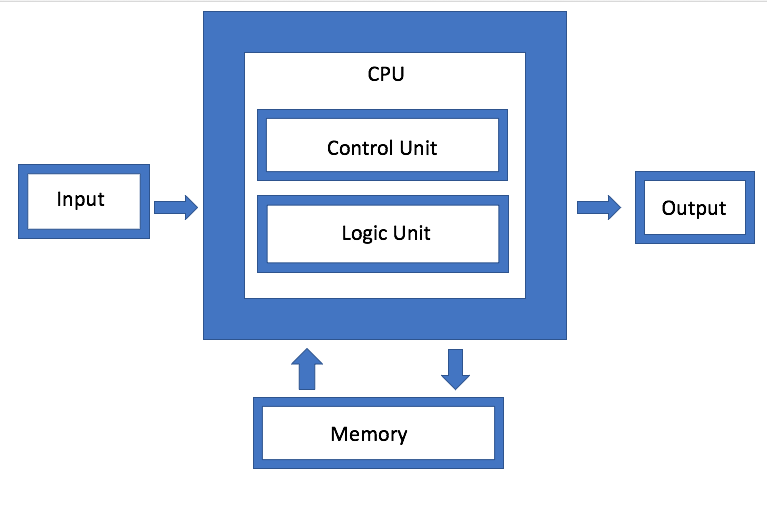 Abb. 1. Architektur von Neumann. Quelle: Halbleitertechnik
Abb. 1. Architektur von Neumann. Quelle: HalbleitertechnikIBM entwickelt eine andere Art von Speicherarchitektur, bei der es sich im Wesentlichen um eine aktualisierte Version der Festplattenaggregation handelt. Das Ziel ist, dass das System anstelle eines einzelnen Laufwerks beliebig jeden verfügbaren Speicher über einen Connector verwenden kann, den Jeff Stucheli, ein IBM-Hardwarearchitekt, als "Swiss Army Knife" zum Verbinden von Elementen bezeichnet. Der Vorteil des Ansatzes besteht darin, dass Sie verschiedene Datentypen mischen und abgleichen können.
„Der Prozessor wird zum Zentrum einer Hochleistungssignalschnittstelle“, sagt Stucelli. "Wenn Sie die Mikroarchitektur ändern, führt der Kern mehr Operationen pro Zyklus mit derselben Frequenz aus."
Konnektivität und Durchsatz sollten die Verarbeitung eines radikal erhöhten Volumens generierter Daten sicherstellen. "Die Hauptengpässe liegen jetzt in den Datenbewegungsorten", sagte Wu von Rambus. "Die Branche hat großartige Arbeit geleistet und die Geschwindigkeit der Datenverarbeitung erhöht." Wenn Sie jedoch Daten oder spezielle Datenvorlagen erwarten, müssen Sie den Speicher schneller ausführen. Wenn Sie sich also DRAM und NVM ansehen, hängt die Leistung vom Verkehrsmuster ab. Wenn die Daten gestreamt werden, bietet der Speicher eine sehr gute Leistung. Wenn die Daten jedoch in zufälligen Tropfen vorliegen, sind sie weniger effizient. Und egal was Sie tun, mit zunehmender Lautstärke müssen Sie es immer noch schneller machen. “
Mehr Computer, weniger Verkehr.
Das Problem wird durch die Tatsache verschärft, dass es verschiedene Arten von Daten gibt, die von Geräten am Rand mit unterschiedlichen Frequenzen und Geschwindigkeiten erzeugt werden. Damit sich diese Daten frei zwischen verschiedenen Verarbeitungsmodulen bewegen können, muss die Verwaltung wesentlich effizienter werden als in der Vergangenheit.
„Es gibt vier Hauptkonfigurationen: Viele-zu-Viele-Speichersubsysteme, E / A mit geringem Stromverbrauch sowie Netz- und Ringtopologien“, sagt Charlie Janak, Vorsitzender und CEO von Arteris IP. - Sie können alle vier auf einem Chip platzieren, was bei den wichtigsten IoT-Chips der Fall ist. Oder Sie können HBM-Subsysteme mit hohem Durchsatz hinzufügen. Die Komplexität ist jedoch enorm, da einige dieser Workloads sehr spezifisch sind und der Chip verschiedene Arbeitsaufgaben hat. Wenn Sie sich einige dieser Mikrochips ansehen, erhalten sie riesige Datenmengen. Dies ist in Systemen wie Autoradar und Lidar der Fall. Sie können ohne einige erweiterte Verbindungen nicht existieren. “
Die Aufgabe besteht darin, die Datenbewegung zu minimieren und gleichzeitig den Datenfluss bei Bedarf zu maximieren - und irgendwie ein Gleichgewicht zwischen lokaler und zentraler Verarbeitung zu finden, ohne den Energieverbrauch unnötig zu erhöhen.
"Einerseits ist dies ein Bandbreitenproblem", sagte Rajesh Ramanujam, Produktmarketingmanager bei NetSpeed Systems. - Sie möchten den Datenverkehr so weit wie möglich reduzieren, um Daten näher an den Prozessor zu übertragen. Wenn Sie die Daten dennoch verschieben müssen, ist es ratsam, sie so weit wie möglich zu komprimieren. Aber nichts existiert für sich. Alles muss auf Systemebene geplant werden. Bei jedem Schritt müssen mehrere voneinander abhängige Achsen berücksichtigt werden. Sie bestimmen, ob Sie Speicher auf herkömmliche Weise zum Lesen und Schreiben verwenden oder ob Sie neue Technologien verwenden. In einigen Fällen müssen Sie möglicherweise die Art und Weise ändern, in der Sie die Daten selbst speichern. Wenn Sie eine höhere Leistung benötigen, bedeutet dies normalerweise eine Vergrößerung der Chipfläche, was sich auf die Wärmeableitung auswirkt. Unter Berücksichtigung der funktionalen Sicherheit kann eine Datenüberlastung nicht mehr zugelassen werden. “
Aus diesem Grund wird der Datenverarbeitung am Rand und der Kanalbandbreite von verschiedenen Datenverarbeitungsmodulen so viel Aufmerksamkeit geschenkt. Wenn Sie jedoch unterschiedliche Architekturen entwickeln, ist es sehr unterschiedlich, wie und wo diese Datenverarbeitung implementiert wird.
Zum Beispiel führte Marvell einen SSD-Controller mit integrierter KI ein, um die hohe Rechenlast am Rande zu bewältigen. Die AI-Engine kann für Analysen direkt im SSD-Laufwerk verwendet werden.
"Sie können Modelle direkt in die Hardware laden und die Hardware-Verarbeitung auf dem SSD-Controller durchführen", sagte Ned Varnitsa, Chefingenieur von Marvell. - Heute macht es den Server in der Cloud (Host). Wenn jedoch jede Festplatte Daten an die Cloud sendet, wird eine große Menge an Netzwerkverkehr erzeugt. Es ist besser, die Verarbeitung am Rand durchzuführen, und der Host gibt nur einen Befehl aus, bei dem es sich nur um Metadaten handelt. Je mehr Laufwerke Sie haben, desto mehr Rechenleistung. Dies ist ein großer Vorteil des reduzierten Verkehrsaufkommens. “
Dieser Ansatz ist besonders interessant, da er sich je nach Anwendung an unterschiedliche Daten anpasst. Der Host kann also eine Aufgabe generieren und zur Verarbeitung an das Speichergerät senden. Danach werden nur noch Metadaten oder Berechnungsergebnisse zurückgesendet. In einem anderen Szenario kann ein Speichergerät Daten speichern, vorverarbeiten und Metadaten, Tags und Indizes generieren, die dann vom Host nach Bedarf für die weitere Analyse abgerufen werden.
Dies ist eine der möglichen Optionen. Es gibt andere. Rupli von Samsung betonte, wie wichtig es ist, Redewendungen zu verarbeiten und zusammenzuführen, mit denen zwei Anweisungen dekodiert und zu einer Operation kombiniert werden können.
AI befasst sich mit Kontrolle und Optimierung
Auf allen Optimierungsebenen wird künstliche Intelligenz eingesetzt - dies ist eines der wirklich neuen Elemente in der Chiparchitektur. Anstatt dem Betriebssystem und der Middleware die Verwaltung von Funktionen zu ermöglichen, wird diese Überwachungsfunktion auf den Chip, zwischen den Chips und auf Systemebene verteilt. In einigen Fällen werden neuronale Hardware-Netzwerke eingeführt.
„Es geht nicht so sehr darum, mehr zusammen zu packen, sondern die traditionelle Architektur zu ändern“, sagt Mike Gianfanya, Vice President Marketing bei eSilicon. - Mithilfe von KI und maschinellem Lernen können Sie Elemente im gesamten System verteilen und so eine effizientere Verarbeitung mit Prognosen erzielen. Oder Sie können separate Chips verwenden, die unabhängig voneinander im System oder im Modul funktionieren. “
ARM hat seinen ersten Chip für maschinelles Lernen entwickelt, den es später in diesem Jahr für mehrere Märkte veröffentlichen will. "Dies ist ein neuer Prozessortyp", sagte Ian Bratt, Honoured Engineer von ARM. - Es enthält einen grundlegenden Block - es ist eine Computer-Engine sowie eine MAC-Engine, eine DMA-Engine mit einem Steuermodul und einem Broadcast-Netzwerk. Insgesamt gibt es 16 Rechenkerne, die mit der 7-nm-Prozesstechnologie hergestellt wurden und 4 TeraOps mit einer Frequenz von 1 GHz erzeugen. “
Da ARM mit einem Partner-Ökosystem zusammenarbeitet, ist sein Chip vielseitiger und anpassbarer als andere AI / ML-Chips, die entwickelt werden. Anstelle einer monolithischen Struktur wird die Verarbeitung nach Funktionen getrennt, sodass jedes Computermodul auf einer separaten Feature-Map arbeitet. Bratt identifizierte vier Hauptbestandteile: statische Planung, effizientes Falten, Verengungsmechanismen und programmierte Anpassung an zukünftige Designänderungen.
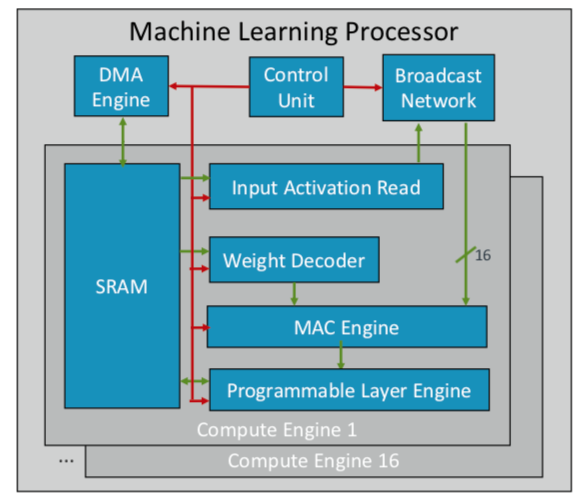 Abb. 2. ARM-Prozessor-ML-Architektur. Quelle: ARM / Hot Chips
Abb. 2. ARM-Prozessor-ML-Architektur. Quelle: ARM / Hot ChipsIn der Zwischenzeit entschied sich Nvidia für eine andere Taktik: die Schaffung einer speziellen Deep-Learning-Engine neben der GPU, um die Bild- und Videoverarbeitung zu optimieren.
Fazit
Mit einigen oder allen dieser Ansätze erwarten die Chiphersteller, dass sich die Leistung alle paar Jahre verdoppelt, um mit dem explosiven Datenwachstum Schritt zu halten und gleichzeitig im engen Rahmen der Energieverbrauchsbudgets zu bleiben. Dies ist jedoch nicht nur mehr Computer. Dies ist eine Änderung in der Chip- und Systemdesignplattform, wenn das wachsende Datenvolumen anstelle von Hardware- und Softwareeinschränkungen zum Hauptfaktor wird.
"Als Computer in Unternehmen auftauchten, schien es vielen, dass sich die Welt um uns herum beschleunigt hatte", sagte Aart de Gues, Vorsitzender und CEO von Synopsys. - Sie haben Papierstücke mit Stapel Bücher abgerechnet. Das Hauptbuch hat sich in einen Stapel Lochkarten zum Drucken und Rechnen verwandelt. Eine enorme Veränderung ist eingetreten, und wir sehen es wieder. Mit dem mentalen Aufkommen einfacher Computer hat sich der Algorithmus der Aktionen nicht geändert: Sie können jeden Schritt verfolgen. Aber jetzt passiert etwas anderes, das zu einer neuen Beschleunigung führen könnte. Es ist wie auf einem landwirtschaftlichen Feld, nur an einem bestimmten Tag, an dem die Temperatur das gewünschte Niveau erreicht, zu gießen und eine bestimmte Art von Dünger aufzutragen. Diese Verwendung von maschinellem Lernen ist eine Optimierung, die in der Vergangenheit nicht offensichtlich war. “
Mit dieser Einschätzung ist er nicht allein. "Die neuen Architekturen werden übernommen", sagte Wally Raines, Präsident und CEO von Mentor, Siemens Business. - Sie werden entworfen. Maschinelles Lernen wird in vielen oder den meisten Fällen eingesetzt, da Ihr Gehirn aus eigenen Erfahrungen lernt. Ich habe 20 oder mehr Unternehmen besucht, die spezialisierte KI-Prozessoren der einen oder anderen Art entwickeln, und jeder von ihnen hat seine eigene kleine Nische. Sie werden ihre Anwendung jedoch zunehmend in bestimmten Anwendungen sehen und sie werden die traditionelle von Neumann-Architektur ergänzen. Neuromorphes Computing wird zum Mainstream. Dies ist ein großer Schritt in Bezug auf Recheneffizienz und Kostenreduzierung. Mobile Geräte und Sensoren werden die Arbeit erledigen, die Server heute leisten. “