Hinweis perev. : Der Artikel wurde von Javier Salmeron, einem Ingenieur aus der bekannten Kubernetes-Community von Bitnami, verfasst und Anfang August im CNCF-Blog veröffentlicht. Der Autor spricht über die Grundlagen des RBAC-Mechanismus (rollenbasierte Zugriffskontrolle), der vor anderthalb Jahren in Kubernetes eingeführt wurde. Das Material ist besonders nützlich für diejenigen, die mit dem Gerät der Schlüsselkomponenten von K8 vertraut sind (siehe Links zu anderen ähnlichen Artikeln am Ende).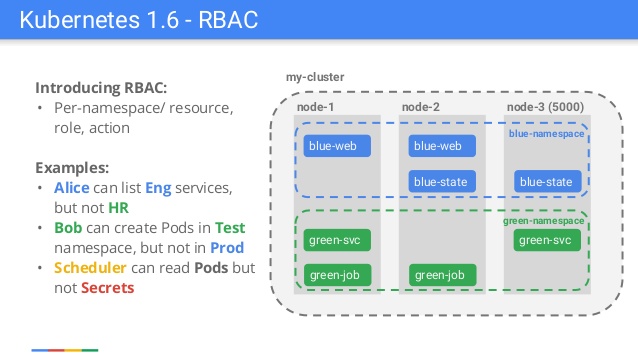 Folie aus einer Präsentation eines Google-Mitarbeiters anlässlich der Veröffentlichung von Kubernetes 1.6
Folie aus einer Präsentation eines Google-Mitarbeiters anlässlich der Veröffentlichung von Kubernetes 1.6Viele erfahrene Kubernetes-Benutzer erinnern sich möglicherweise an die Version Kubernetes 1.6, als die auf der rollenbasierten Zugriffskontrolle (RBAC) basierende Autorisierung Beta wurde. So erschien ein alternativer Authentifizierungsmechanismus, der die bereits vorhandene, aber schwer zu verwaltende und zu verstehende Attributbasierte Zugriffskontrolle (ABAC) ergänzte. Alle begrüßten die neue Funktion begeistert, aber gleichzeitig waren unzählige Benutzer enttäuscht. StackOverflow und GitHub waren reich an Berichten über RBAC-Einschränkungen, da die meisten Dokumentationen und Beispiele RBAC nicht berücksichtigten (aber jetzt ist alles in Ordnung). Das Referenzbeispiel war Helm: Nur das Ausführen von
helm init +
helm install funktionierte nicht mehr. Plötzlich mussten wir „seltsame“ Elemente wie
ServiceAccounts oder
RoleBindings bevor
RoleBindings das Diagramm überhaupt mit WordPress oder Redis
RoleBindings (weitere
RoleBindings hierzu finden Sie in den
Anweisungen ).
Wenn man diese erfolglosen ersten Versuche beiseite lässt, kann man den enormen Beitrag, den RBAC geleistet hat, um Kubernetes zu einer produktionsbereiten Plattform zu machen, nicht leugnen. Viele von uns haben es geschafft, mit Kubernetes mit vollen Administratorrechten zu spielen, und wir verstehen vollkommen, dass es in einer realen Umgebung notwendig ist:
- Viele Benutzer mit unterschiedlichen Eigenschaften, die den gewünschten Authentifizierungsmechanismus bereitstellen.
- Sie haben die volle Kontrolle darüber, welche Vorgänge jeder Benutzer oder jede Benutzergruppe ausführen kann.
- Haben Sie die volle Kontrolle darüber, welche Operationen jeder Prozess im Herzen ausführen kann.
- Begrenzen Sie die Sichtbarkeit bestimmter Ressourcen in Namespaces.
In dieser Hinsicht ist RBAC ein Schlüsselelement, das dringend benötigte Funktionen bietet. In diesem Artikel werden wir schnell auf die Grundlagen eingehen
(Einzelheiten finden Sie in diesem Video ; folgen Sie dem einstündigen Link zum Bitnami-Webinar in englischer Sprache - ca. Übersetzung ). Und gehen Sie etwas tiefer in die verwirrendsten Momente ein.
Der Schlüssel zum Verständnis von RBAC in Kubernetes
Um die Idee von RBAC vollständig zu verwirklichen, müssen Sie verstehen, dass drei Elemente daran beteiligt sind:
- Themen - eine Gruppe von Benutzern und Prozessen, die Zugriff auf die Kubernetes-API haben möchten;
- Ressourcen - Eine Sammlung von Kubernetes-API-Objekten, die in einem Cluster verfügbar sind. Ihre Beispiele (unter anderem) sind Pods , Bereitstellungen , Dienste , Knoten , persistente Volumes ;
- Verben (Verben) - eine Reihe von Operationen, die für Ressourcen ausgeführt werden können. Es gibt verschiedene Verben (abrufen, beobachten, erstellen, löschen usw.), aber alle sind letztendlich Operationen aus der CRUD-Kategorie (Erstellen, Lesen, Aktualisieren, Löschen).

Unter Berücksichtigung dieser drei Elemente lautet die Schlüsselidee von RBAC:
"Wir möchten die Themen, API-Ressourcen und Operationen verbinden." Mit anderen Worten, wir möchten für einen bestimmten
Benutzer angeben, welche
Vorgänge mit einer Vielzahl von
Ressourcen ausgeführt werden können .
Grundlegendes zu RBAC-Objekten in der API
Durch die Kombination dieser drei Entitätstypen werden die in der Kubernetes-API verfügbaren RBAC-Objekte deutlich:
Roles verbinden Ressourcen und Verben. Sie können für verschiedene Themen wiederverwendet werden. An einen Namespace gebunden (wir können keine Vorlagen verwenden, die mehr als einen [Namespace] darstellen, aber wir können dasselbe Rollenobjekt für verschiedene Namespaces bereitstellen). Wenn Sie die Rolle auf den gesamten Cluster anwenden möchten, gibt es ein ähnliches ClusterRoles Objekt.RoleBindings verbinden die verbleibenden Entitätsentitäten. Durch Angabe einer Rolle, die API-Objekte bereits mit Verben verknüpft, wählen wir nun die Themen aus, die sie verwenden können. Das Äquivalent für die Cluster-Ebene (d. H. Ohne Bindung an Namespaces) ist ClusterRoleBindings .
Im folgenden Beispiel geben wir dem Benutzer
jsalmeron das Recht, im
Test- Namespace zu lesen, eine Liste
abzurufen und Herde zu erstellen. Dies bedeutet, dass
jsalmeron die folgenden Befehle ausführen kann:
kubectl get pods --namespace test kubectl describe pod --namespace test pod-name kubectl create --namespace test -f pod.yaml
... aber nicht so:
kubectl get pods --namespace kube-system
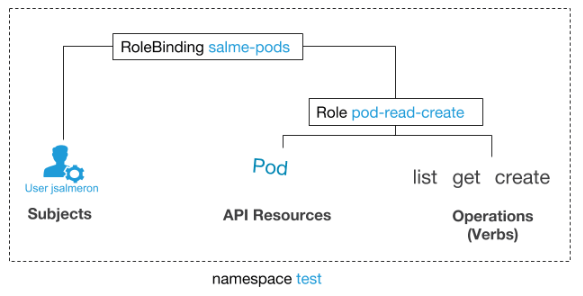
Beispiele für YAML-Dateien:
kind: Role apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: pod-read-create namespace: test rules: - apiGroups: [""] resources: ["pods"] verbs: ["get", "list", "create"]
kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: salme-pods namespace: test subjects: - kind: User name: jsalmeron apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: pod-read-create apiGroup: rbac.authorization.k8s.io
Ein weiterer interessanter Punkt ist folgender: Können wir jetzt, da der Benutzer Pods erstellen kann, begrenzen, wie viel? Dies erfordert andere Objekte, die nicht direkt mit der RBAC-Spezifikation zusammenhängen, und ermöglicht Ihnen das Konfigurieren von Ressourcenlimits:
ResourceQuota und
LimitRanges . Es lohnt sich auf jeden Fall, sie zu untersuchen, wenn Sie eine so wichtige Cluster-Komponente konfigurieren [wie das Erstellen von Herden].
Themen: Benutzer und ... ServiceAccounts?
Eine der Schwierigkeiten, mit denen viele Kubernetes-Benutzer im Zusammenhang mit Themen konfrontiert sind, ist die Unterscheidung zwischen regulären Benutzern und
ServiceAccounts . Theoretisch ist alles einfach:
Users - globale Benutzer, die für Personen oder Prozesse außerhalb des Clusters entwickelt wurden;ServiceAccounts - begrenzt durch den Namespace und für Prozesse innerhalb des Clusters vorgesehen, die auf Pods ausgeführt werden.
Die Ähnlichkeit beider Typen liegt in der Notwendigkeit, sich bei der API zu authentifizieren, um bestimmte Vorgänge für viele Ressourcen auszuführen, und ihre Themenbereiche sehen sehr spezifisch aus. Sie können auch zu Gruppen gehören, sodass
RoleBinding mit
RoleBinding mehr als einen Betreff binden können (obwohl für
ServiceAccounts -
system:serviceaccounts RoleBinding nur eine Gruppe zulässig ist). Der Hauptunterschied ist jedoch die Ursache der Kopfschmerzen: Benutzer haben keine entsprechenden Objekte in der Kubernetes-API. Es stellt sich heraus, dass eine solche Operation existiert:
kubectl create serviceaccount test-service-account
... aber dieser ist weg:
kubectl create user jsalmeron
Diese Situation hat schwerwiegende Folgen: Wenn der Cluster keine Informationen über Benutzer speichert, muss der Administrator Konten außerhalb des Clusters verwalten. Es gibt verschiedene Möglichkeiten, das Problem zu lösen: TLS-Zertifikate, Token, OAuth2 usw.
Darüber hinaus müssen Sie
kubectl Kontexte erstellen,
kubectl wir über diese neuen Konten auf den Cluster zugreifen können. Um Dateien mit ihnen zu erstellen, können Sie die Befehle
kubectl config (für die kein Zugriff auf die Kubernetes-API erforderlich ist, sodass sie von jedem Benutzer ausgeführt werden können). Das obige Video zeigt ein Beispiel für das Erstellen eines Benutzers mit TLS-Zertifikaten.
RBAC in Bereitstellungen: Beispiel
Wir haben ein Beispiel gesehen, in dem dem angegebenen Benutzer Rechte für Operationen im Cluster gewährt werden. Aber was ist mit
Bereitstellungen, die Zugriff auf die Kubernetes-API erfordern? Stellen Sie sich ein bestimmtes Szenario vor, um ein besseres Verständnis zu erhalten.
Nehmen Sie zum Beispiel die beliebte Infrastrukturanwendung RabbitMQ. Wir werden das
Helm-Diagramm für RabbitMQ von Bitnami (aus dem offiziellen
Helm- / Diagramm- Repository) verwenden, das den
Bitnami / Rabbitmq-Container verwendet . In den Container ist ein Plugin für Kubernetes integriert, das für die Erkennung anderer Mitglieder des RabbitMQ-Clusters verantwortlich ist. Aus diesem Grund erfordert der Prozess im Container Zugriff auf die Kubernetes-API, und wir müssen das
ServiceAccount mit den richtigen RBAC-Berechtigungen konfigurieren.
Befolgen Sie bei
ServiceAccounts folgenden bewährten Methoden:
- Konfigurieren Sie
ServiceAccounts für jede Bereitstellung mit einem
Mindestsatz an Berechtigungen .
Bei Anwendungen, die Zugriff auf die Kubernetes-API benötigen, könnten Sie versucht sein, eine Art "privilegiertes
ServiceAccount " zu erstellen, das fast alles im Cluster
ServiceAccount kann. Dies scheint zwar eine einfachere Lösung zu sein, kann jedoch letztendlich zu einer Sicherheitslücke führen, die unerwünschte Vorgänge ermöglichen kann. (Das Video zeigt ein Beispiel für eine Pinne [Helm-Komponente] und die Konsequenzen von
ServiceAccounts mit großen Berechtigungen.)
Darüber hinaus haben unterschiedliche
Bereitstellungen unterschiedliche Anforderungen hinsichtlich des Zugriffs auf die API. Daher ist es für jede
Bereitstellung sinnvoll, unterschiedliche
ServiceAccounts zu haben.
Lassen Sie uns vor diesem Hintergrund sehen, welche RBAC-Konfiguration für
den Fall der
Bereitstellung mit RabbitMQ korrekt ist.
In der
Plugin-Dokumentation und
ihrem Quellcode können Sie sehen, dass eine Liste von
Endpunkten von der Kubernetes-API angefordert wird. Auf diese Weise werden die verbleibenden Mitglieder des RabbitMQ-Clusters erkannt. Daher erstellt das Bitnami RabbitMQ-Diagramm:
- ServiceAccount für Herde mit RabbitMQ:
{{- if .Values.rbacEnabled }} apiVersion: v1 kind: ServiceAccount metadata: name: {{ template "rabbitmq.fullname" . }} labels: app: {{ template "rabbitmq.name" . }} chart: {{ template "rabbitmq.chart" . }} release: "{{ .Release.Name }}" heritage: "{{ .Release.Service }}" {{- end }}
- Rolle (wir gehen davon aus, dass der gesamte RabbitMQ-Cluster in einem einzigen Namespace bereitgestellt wird), sodass das Verb get für die Endpoint- Ressource abgerufen werden kann:
{{- if .Values.rbacEnabled }} kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: {{ template "rabbitmq.fullname" . }}-endpoint-reader labels: app: {{ template "rabbitmq.name" . }} chart: {{ template "rabbitmq.chart" . }} release: "{{ .Release.Name }}" heritage: "{{ .Release.Service }}" rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get"] {{- end }}
- RoleBinding , das ein
ServiceAccount mit einer Rolle verbindet:
{{- if .Values.rbacEnabled }} kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: {{ template "rabbitmq.fullname" . }}-endpoint-reader labels: app: {{ template "rabbitmq.name" . }} chart: {{ template "rabbitmq.chart" . }} release: "{{ .Release.Name }}" heritage: "{{ .Release.Service }}" subjects: - kind: ServiceAccount name: {{ template "rabbitmq.fullname" . }} roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: {{ template "rabbitmq.fullname" . }}-endpoint-reader {{- end }}

Das Diagramm zeigt, dass Prozesse, die in RabbitMQ-Pods ausgeführt werden,
Get- Operationen für
Endpoint- Objekte ausführen dürfen. Dies ist die Mindestmenge an Vorgängen, die erforderlich ist, damit alles funktioniert. Gleichzeitig wissen wir, dass das bereitgestellte Diagramm sicher ist und keine unerwünschten Aktionen innerhalb des Kubernetes-Clusters ausführt.
Letzte Gedanken
Für die Arbeit mit Kubernetes in der Produktion sind RBAC-Richtlinien nicht optional. Sie können nicht als eine Reihe von API-Objekten betrachtet werden, die nur Administratoren kennen sollten. Entwickler benötigen sie tatsächlich, um sichere Anwendungen bereitzustellen und das Potenzial der Kubernetes-API für Cloud-native Anwendungen voll auszuschöpfen. Weitere Informationen zu RBAC finden Sie unter folgenden Links:
PS vom Übersetzer
Lesen Sie auch in unserem Blog: