Vor einigen Jahren haben Empfehlungssysteme gerade erst begonnen, ihre Verbraucher zu überzeugen. Online-Shops verwenden aktiv Empfehlungsalgorithmen und bieten ihren Kunden basierend auf ihrer Einkaufshistorie immer mehr neue Produkte an.
Im Kundenservice sind Empfehlungssysteme vor nicht allzu langer Zeit relevant geworden. Aufgrund der Zunahme der angebotenen Inhalte verloren sich die Kunden in den Informationsflüssen darüber, was, wo und wann sie sehen müssen. Pay-TV-Betreiber und Online-Kinos hatten die Kopfschmerzen von Liebhabern von Videoinhalten.

Als effektiver Weg, um das ewige Problem zu lösen: "Was gibt es zu sehen?" Es sind Empfehlungssysteme erschienen, die auf der Grundlage eines bestimmten mathematischen Modells arbeiten.
Vor zwei Jahren haben wir ein Empfehlungssystem eingeführt, es später durch eine redaktionelle Auswahl ergänzt und spürbare Auswirkungen sowohl auf den Verkauf als auch auf die Dauer der Nutzung unseres Dienstes festgestellt.
Was sind Empfehlungssysteme?
Ein Empfehlungssystem ist, wenn Sie etwas sehen möchten, aber nicht genau wissen, was, und der Fernseher Ihre Vorlieben sehr erfolgreich errät. Hierbei handelt es sich um eine Inhaltsfilterung, bei der Filme und Fernsehsendungen anhand von Einstellungen und Analysen des Benutzerverhaltens ausgewählt werden. Das vom Bediener verwendete System sollte die Reaktion des Betrachters auf ein bestimmtes Element vorhersagen und Inhalte anbieten, die ihm gefallen könnten.
Bei der Programmierung von Empfehlungssystemen werden drei Hauptmethoden verwendet: kollaborative Filterung, inhaltsbasierte Filterung und Expertensysteme (wissensbasierte Systeme).
Die kollaborative Filterung basiert auf drei Schritten: Sammeln von Benutzerinformationen, Erstellen einer Matrix zur Berechnung von Assoziationen und Abgeben zuverlässiger Empfehlungen.
Ein gutes Beispiel für kollaboratives Filtern ist Cinematch, das Netflix verwendet. Benutzer geben explizit oder implizit Bewertungen für gesehene Filme ab, und Empfehlungen werden unter Berücksichtigung sowohl ihrer Benutzerbewertungen als auch der anderer Zuschauer gebildet. Zu diesem Zweck wählt das System Benutzer mit ähnlichen Einstellungen aus, deren Bewertungen nahe an ihren eigenen liegen. Basierend auf der Meinung dieses Personenkreises erhält der Zuschauer automatisch die Empfehlung, einen bestimmten Film anzusehen.
Für den maximal korrekten Betrieb des Empfehlungssystems spielen natürlich die gesammelten und gesammelten Daten eine grundlegende Rolle. Je mehr Daten über das Verbrauchsprofil eines bestimmten Teilnehmers gesammelt werden, desto genauer werden ihm Empfehlungen gegeben.
Das Inhaltsempfehlungssystem wird basierend auf den Attributen formuliert, die jedem Element zugewiesen sind. Wenn Sie Filme eines bestimmten Genres ansehen, bietet Ihnen das System automatisch Inhalte an, die an bestimmten Positionen Ihrem Genre nahe kommen. Auf der Grundlage eines solchen Empfehlungssystems funktioniert die Pandora-Website.
Expertenempfehlungssysteme bieten Empfehlungen nicht auf der Grundlage von Bewertungen, sondern auf der Grundlage von Ähnlichkeiten zwischen Benutzeranforderungen und Produktbeschreibungen oder abhängig von Einschränkungen, die der Benutzer bei der Angabe des gewünschten Produkts festgelegt hat. Daher ist dieser Systemtyp einzigartig, da der Client explizit angeben kann, was er möchte.
Expertensysteme sind in Kontexten am effektivsten, in denen die verfügbare Datenmenge begrenzt ist, und die kollaborative Filterung funktioniert am besten in Umgebungen mit großen Datenmengen. Wenn die Daten jedoch diversifiziert sind, ist es möglich, dasselbe Problem mit verschiedenen Methoden zu lösen. Dies bedeutet, dass die eingegangenen Empfehlungen auf verschiedene Weise optimal kombiniert werden, wodurch die Qualität des Gesamtsystems verbessert wird.
Es ist ein solches Hybridsystem von E-Contenta, das in unserem
WiFire-TV- Dienst
funktioniert . Es wurde im Dezember 2016 in Betrieb genommen und debuggt und funktioniert nach folgendem Prinzip: Wenn das System viel über den Benutzer oder den Inhalt weiß, herrschen kollaborative Filteralgorithmen vor. Wenn der Inhalt neu ist oder nicht genügend Informationen über die Interaktion der Benutzer mit ihm gesammelt werden, werden Inhaltsalgorithmen verwendet, um die Ähnlichkeit des Inhalts basierend auf vorhandenen Metadaten zu bewerten.
Wie Empfehlungsalgorithmen erstellt wurden
Um eine personalisierte Auswahl in E-Contenta zu erstellen, mussten alle verfügbaren Inhalte nach der Wahrscheinlichkeit eingestuft werden, mit der ein bestimmter Benutzer an diesen Inhalten interessiert sein würde.
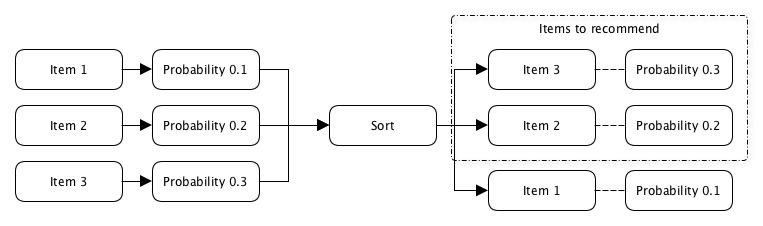
Das Interesse des Benutzers wird hauptsächlich zu dem Zeitpunkt bestimmt, zu dem er auf den ihm empfohlenen Inhalt klickt, und die Wahrscheinlichkeit ist definiert als das Verhältnis der Anzahl der Klicks zu der Häufigkeit, mit der dieser Inhalt diesem Benutzer empfohlen wurde.
p (Klick) = N Klicks / N AnzeigenDie Schwierigkeit liegt in der Tatsache, dass Sie dem Benutzer etwas empfehlen müssen, das er noch nie gesehen hat, was bedeutet, dass es einfach keine Daten zur Anzahl der Klicks oder Impressionen gibt, um diese Wahrscheinlichkeit zu berechnen.
Daher wurde anstelle der tatsächlichen Wahrscheinlichkeit beschlossen, eine Schätzung dieser Wahrscheinlichkeit, dh des vorhergesagten Werts, zu verwenden.
Die Idee eines kollaborativen Filters ist einfach:
- Nehmen Sie historische Daten über Benutzer, die Inhalte anzeigen
- Gruppieren Sie Benutzer anhand dieser Daten nach dem Inhalt, den sie angezeigt haben
- Damit ein bestimmter Benutzer die Wahrscheinlichkeit seines Interesses an einer bestimmten Inhaltseinheit basierend auf historischen Daten anderer Benutzer in derselben Gruppe vorhersagen kann.
Somit beteiligen sich Benutzer gemeinsam an der Auswahl von Inhalten.
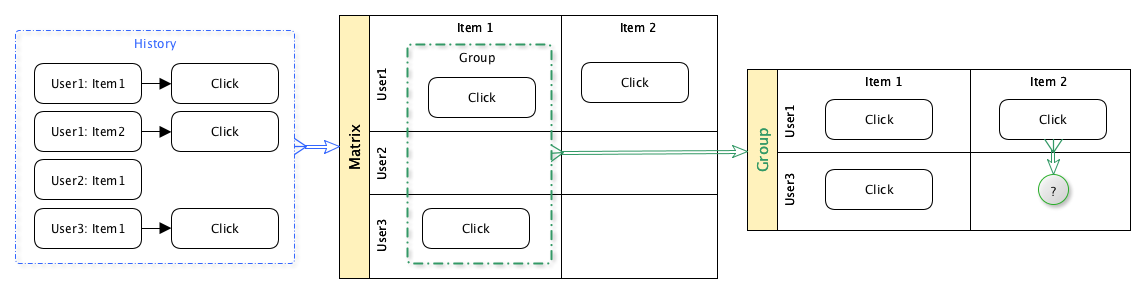
Es gibt viele verschiedene Möglichkeiten, diesen Ansatz umzusetzen:
1. Erstellen Sie ein Modell, indem Sie direkt die Bezeichner der Inhaltseinheiten verwenden:
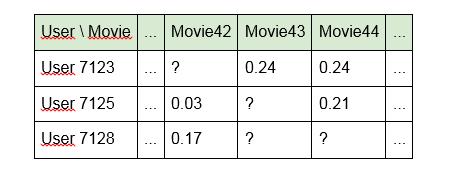
Der Nachteil dieses Ansatzes besteht darin, dass das Modell keine Verknüpfungen zwischen Inhaltseinheiten "sieht". Zum Beispiel sind "Terminator" und "Terminator 2" für sie so weit voneinander entfernt wie "Alien" und "Gute Nacht, Kinder!". Außerdem ist die Matrix selbst sehr spärlich (viele leere Zellen und etwas gefüllt).
2. Verwenden Sie anstelle von Bezeichnern die im Titel von Artikeln, Programmen oder Filmen enthaltenen Wörter:
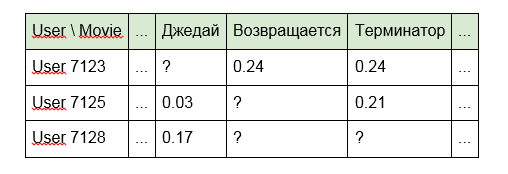
3. Für Filme, Namen von Schauspielern, Regisseuren oder Daten aus der IMDb:
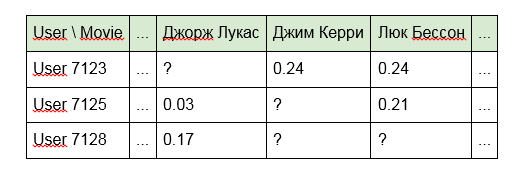
Die zweite und dritte Option beseitigen teilweise die Nachteile des ersten Ansatzes angesichts der Verbindung von Inhalten, die gemeinsame Merkmale aufweisen (desselben Regisseurs oder derselben Wörter im Titel). Die Sparsamkeit der Matrix wird jedoch ebenfalls verringert, aber wie sie sagen, gibt es keine Grenze für die Perfektion.
Es ist ziemlich teuer, eine ganze Reihe von Benutzerbewertungen im Speicher zu behalten. Wenn wir die Anzahl der Runet-Benutzer bei 80 Millionen Menschen und die Größe der IMDb-Datenbank bei 370.000 Filmen grob schätzen, erhalten wir die erforderliche Größe von 27 Terabyte. Die singuläre Zerlegung ist eine Methode zur Reduzierung der Dimension der Matrix.
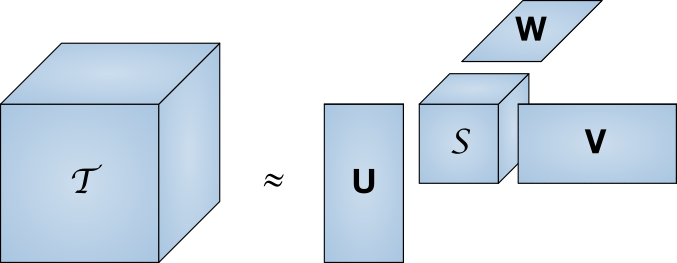 Eine große Matrix T wird als Produkt eines Satzes kleinerer Matrizen dargestellt
Eine große Matrix T wird als Produkt eines Satzes kleinerer Matrizen dargestelltMit anderen Worten, die Suche nach der "Kern" -Matrix, die die gleichen Eigenschaften wie die vollständige Matrix hat, jedoch viel kleiner ist. Mit abnehmender Abmessung nimmt auch die Entladung ab. In diesem Artikel werden wir nicht auf die Feinheiten der Implementierung eingehen, zumal bereits fertige Bibliotheken für eine Reihe von Programmiersprachen existieren.
Technische Schwierigkeiten
KaltstartDie Situation, in der der Mangel an Daten für neue Inhalte oder der Benutzer keine qualitativ hochwertigen Empfehlungen zulässt, die auch als „Kaltstart“ bezeichnet werden, ist ein typisches Problem für die kollaborative Filterung.
Eine Lösung besteht darin, mehrere Inhaltseinheiten in die Empfehlungen zu mischen, die nicht genügend Daten erfassen. Gleichzeitig wird dem neuen Benutzer der beliebteste Inhalt empfohlen.
Am beliebtestenBei Verwendung des obigen Ansatzes ist es wichtig, nicht zu vergessen, dass seine Folge eine systematische Erhöhung der Häufigkeit des Auftretens der „beliebtesten“ in der empfohlenen Liste sein wird. Aus dem Verhalten von Benutzern zu lernen, denen häufig die „beliebtesten“ angeboten werden, riskiert das Empfehlungssystem, zu lernen, ausschließlich die beliebtesten Inhalte zu empfehlen.
Der Hauptunterschied zwischen persönlichen Empfehlungen und den banalen Empfehlungen der beliebtesten Inhalte besteht darin, dass sie den individuellen Geschmack berücksichtigen, der sich erheblich von den „durchschnittlichen“ unterscheiden kann.
Daher sollte die Stichprobe der Benutzerreaktionen auf den Inhalt, der zum Trainieren des Empfehlungsmodells verwendet wird, normalisiert werden.
Verfügbarkeit, Failover und SkalierbarkeitDie Anzahl der Benutzer der Ressource kann eine Last von Hunderten und Tausenden von Anforderungen an das Empfehlungssystem pro Sekunde erzeugen. Darüber hinaus sollte der Ausfall eines oder mehrerer Server nicht zu einem Denial-of-Service führen.
In diesem Fall besteht die klassische Lösung darin, einen Load Balancer zu verwenden, der eine Anforderung an einen der Cluster-Server sendet. Darüber hinaus kann jeder Server eine eingehende Anforderung verarbeiten. Bei einem Ausfall eines der Server im Cluster schaltet der Balancer die Last automatisch auf die im System verbleibenden Server um. Durch Auswahl von HTTP als Transportprotokoll können wir Nginx als Load Balancer verwenden.
Wenn die Zielgruppe der Ressource wächst, kann die Anzahl der Server im Cluster zunehmen. In diesem Fall ist es wichtig, die Kosten für die Vorbereitung eines neuen Servers zu minimieren.
Das Empfehlungssystem erfordert die Installation einer Reihe von Komponenten, auf die es sich funktional stützt. Docker wird verwendet, um die Bereitstellung eines Empfehlungssystems mit all seinen Abhängigkeiten zu automatisieren.
Mit Docker können Sie alle erforderlichen Komponenten sammeln, in ein Image „packen“ und ein solches Image in ein Repository (Registrierung) stellen. Anschließend können Sie es in wenigen Minuten herunterladen und auf einem neuen Server bereitstellen. Ein wichtiger Vorteil von Docker ist, dass der „Overhead“ bei seiner Verwendung minimal ist: Die Aufrufzeit der Anwendung im Docker-Container wird im Vergleich zu der Anwendung, die unter einem normalen Betriebssystem ausgeführt wird, um einige Nanosekunden erhöht.
Ein weiterer wichtiger Vorteil ist die Möglichkeit, im Falle eines neuen Fehlers schnell zur vorherigen stabilen Version der Anwendung zurückzukehren (nehmen Sie einfach die alte Version aus der Registrierung).
Die zweite Art von Systemanforderungen, um die Sie sich kümmern müssen, sind Anforderungen, die die Benutzeraktivität verfolgen. Damit der Benutzer nicht warten muss, bis das System die von ihm ausgeführte Aktion vollständig verarbeitet hat, wird der Verarbeitungsprozess unabhängig vom Prozess der Aufzeichnung von Aktionen ausgeführt.
Apache Kafka wurde bei E-Contenta als Plattform ausgewählt, die die Datenübertragung von Benutzeraktionen an Prozessoren ermöglicht. Kafka implementiert das Architekturmuster Message-Oriented Middleware, das eine garantierte Zustellung von Zehntausenden von Nachrichten pro Sekunde ermöglicht und als Puffer fungiert, der Handler in Spitzenzeiten vor übermäßigem Datenvolumen schützt.
Vollständiges SelbstlernenRegelmäßig erscheinen neue Inhalte und neue Benutzer - ohne regelmäßige Schulung verschlechtert sich die Qualität des Modells. Das Training sollte auf separaten Servern durchgeführt werden, damit der Trainingsprozess, der erhebliche Rechenressourcen erfordert, die Leistung von Kampfservern nicht beeinträchtigt.
Die klassische Lösung für die Orchestrierung regelmäßig verteilter Aufgaben ist Jenkins. Der geplante Dienst beginnt mit dem Empfang und der Normalisierung neuer Schulungsbeispiele, dem Training eines Empfehlungsmodells, der Bereitstellung neuer Modelle und der Aktualisierung aller Clusterserver, sodass die Qualität der Empfehlungen ohne zusätzlichen Aufwand beibehalten werden kann. Im Falle eines Fehlers bei einem der Schritte bringt Jenkins das System unabhängig in den vorherigen stabilen Zustand zurück und benachrichtigt den Administrator über den Fehler.
Wie wir es auf WifireTV implementiert haben
Damit das System ordnungsgemäß funktioniert, haben wir außerdem einen unabhängigen Fernsehzähler eingeladen und ihn eingeladen, die Fernsehansicht der Teilnehmer zu messen. Die resultierenden eindeutigen Daten werden mithilfe datenwissenschaftlicher Algorithmen animiert. Kontinuierlich arbeitendes Feedback von Abonnenten, die mit Empfehlungen interagieren, füllt die Basis der Präzedenzfälle für Algorithmen für maschinelles Lernen und ermöglicht es, Empfehlungen zu ändern, abhängig von impliziten Anzeichen für sich ändernde Präferenzen von Abonnenten, wie z. B. der Jahreszeit, bevorstehenden Feiertagen oder einer sich ändernden Familienzusammensetzung.
Während des Testprozesses mussten wir das Problem lösen, das mit der Empfehlung von Fernsehinhalten verbunden ist - wie wir unseren Abonnenten helfen können, die Sendungsströme zu verstehen. Die Aufgabe wird auch durch verzögerte Anzeigedienste erschwert. Wir haben ein System eingebaut, das anstelle eines endlosen zyklischen Kanalwechsels hilft, ein interessantes Programm in nur 2-3 Tastendrücken zu finden. Zu diesem Zweck überwacht das Empfehlungssystem die Veröffentlichung neuer Programmreihen und prognostiziert das Interesse der Zuschauer an unregelmäßigen Sendungen und Sendungen von Filmen. Tatsächlich ersetzen Maschinenalgorithmen die Arbeit des verantwortlichen Editors.
Die Arbeit mit Streaming-Fernsehen hat ihre eigenen Besonderheiten. Beispielsweise werden häufig dieselben beliebten Fernsehsendungen auf verschiedenen Kanälen ausgestrahlt. In diesem Fall muss das Empfehlungssystem die Duplizierung von Informationen verstehen und eine Empfehlung auswählen, die auf den Präferenzen des Teilnehmers in Bezug auf Kanäle, Übertragungsstartzeit usw. basiert. Eine solche Verdoppelung von Informationen tritt auch auf, wenn ein Teilnehmer ein Abonnement für SD- und HD-Versionen von Kanälen hat.
In all diesen zwei Jahren haben wir mit verschiedenen Versionen von Empfehlungssystemen experimentiert und einen Mittelweg gefunden, der es uns ermöglicht, das Engagement des Publikums zu verbessern und vorhandene Inhalte effektiver zu monetarisieren. Wir verwenden die oben beschriebene automatische Auswahl der Empfehlungen zusammen mit der manuellen Abstimmung - redaktionelle Auswahl.
Dieser Ansatz ermöglichte es, die Monetarisierung von VoD- und SVOD-Diensten signifikant (zehnmal) zu steigern.
Redaktionelle Empfehlungen sind Sammlungen thematischer Filme und Serien, die mit hochkarätigen Premieren, Feiertagen und unvergesslichen Daten verbunden sind. Es ist sehr praktisch, Abonnenten zu benachrichtigen und ihnen die Möglichkeit zu geben, neue Filme, alte Hits oder unbeliebte Filme anzusehen, aber unserer Meinung nach sehr interessante Filme in Bezug auf Inhalt und Handlung. Wir kommunizieren eng mit unseren Lieferanten (Online-Kinos und zusätzliche Videodienste wie ivi, megogo, amediateka) und wählen persönlich jeden Film aus, der für unseren Abonnenten interessant sein wird.
An Feiertagen treffen wir eine spezielle Auswahl zu einem bestimmten Thema. Am Tag des Sieges sind dies beispielsweise Filme zum Thema Militär. Am 1. September - eine Auswahl von Inhalten für Kinder, die aus Bildungsprogrammen, Cartoons und Dokumentationen besteht.
Die manuelle Auswahl erhöht perfekt die Loyalität unserer Abonnenten. Nach unseren konservativsten Schätzungen sehen sich etwa 10% unserer monatlichen Abonnentenfilme an, die wir empfehlen, und dieser Indikator wächst ständig.
Was ist das Ergebnis?
Wifire TV betreibt derzeit ein intelligentes Empfehlungssystem von E-Contenta. Es basiert auf Datenwissenschaft und Metadaten von 90% der Abonnenten des Betreibers. Der Algorithmus berücksichtigt Hunderte von Daten: Was der Abonnent sieht, welche Filme und Programme beliebt sind, wann er den Dienst nutzt und wer sich jetzt vor dem Bildschirm befindet. Wir möchten unseren Abonnenten den Wert des Abonnierens von Premium-Channel-Paketen vermitteln und diese in Empfehlungen mischen, die für den Benutzer relevant sind. Wir möchten auch zeigen, dass das Erfassen und Ansehen legaler Videoinhalte normal, bequem und einfach ist.
Das Empfehlungssystem informiert den Abonnenten über interessante Filme, auch wenn diese schon lange nicht mehr in der Kategorie der neuen Produkte enthalten sind. Somit ist das umfangreiche Videoverzeichnis keine staubige Bibliothek mehr und wird zu einem interaktiven Schaufenster, das sich flexibel an den Geschmack und die Stimmung der Abonnenten anpasst.