In diesem Artikel möchte ich über einige Techniken zum Arbeiten mit Daten beim Trainieren eines Modells sprechen. Insbesondere, wie Sie die Segmentierung von Objekten auf den Feldern ziehen, wie Sie das Modell trainieren und das Markup des Datensatzes erhalten, indem Sie nur einige Beispiele markieren.
Herausforderung
Es gibt einen bestimmten Prozess der Herstellung von Pizza und Fotos aus den verschiedenen Phasen (einschließlich nicht nur Pizza). Es ist bekannt, dass sich weiße Pickel auf der Kruste befinden, wenn das Teigrezept verdorben wird. Es gibt auch eine binäre Kennzeichnung der Qualität des Tests für jede Instanz von Pizza, die von Experten erstellt wurde. Es ist notwendig, einen Algorithmus zu entwickeln, der die Qualität des Tests anhand des Fotos bestimmt.
Der Datensatz besteht aus Fotos, die von verschiedenen Telefonen unter verschiedenen Bedingungen und in verschiedenen Winkeln aufgenommen wurden. Pizza Instanzen - 17k. Fotos insgesamt - 60k.
Meiner Meinung nach ist die Aufgabe recht typisch und gut geeignet, um verschiedene Ansätze für die Datenverarbeitung aufzuzeigen. Um es zu lösen, müssen Sie:
1. Wählen Sie Fotos aus, auf denen sich eine Pizzakruste befindet.
2. Markieren Sie auf den ausgewählten Fotos den Kuchen.
3. Trainieren Sie das neuronale Netzwerk in den ausgewählten Bereichen.
Fotos filtern
Auf den ersten Blick scheint es am einfachsten zu sein, diese Aufgabe den Schreibern zu übertragen und dann den Datensatz auf saubere Daten zu trainieren. Ich entschied jedoch, dass es für mich einfacher war, einen kleinen Teil selbst zu markieren, als mit einem Schreiber zu erklären, welcher Winkel richtig war. Außerdem hatte ich kein hartes Kriterium für den richtigen Winkel.
Also hier ist was ich getan habe:
1. Markierte 100 Randfotos;

2. Ich habe die Features nach dem globalen Ziehen aus dem resnet-152-Raster mit Gewichten von imagenet11k_places365 berechnet.
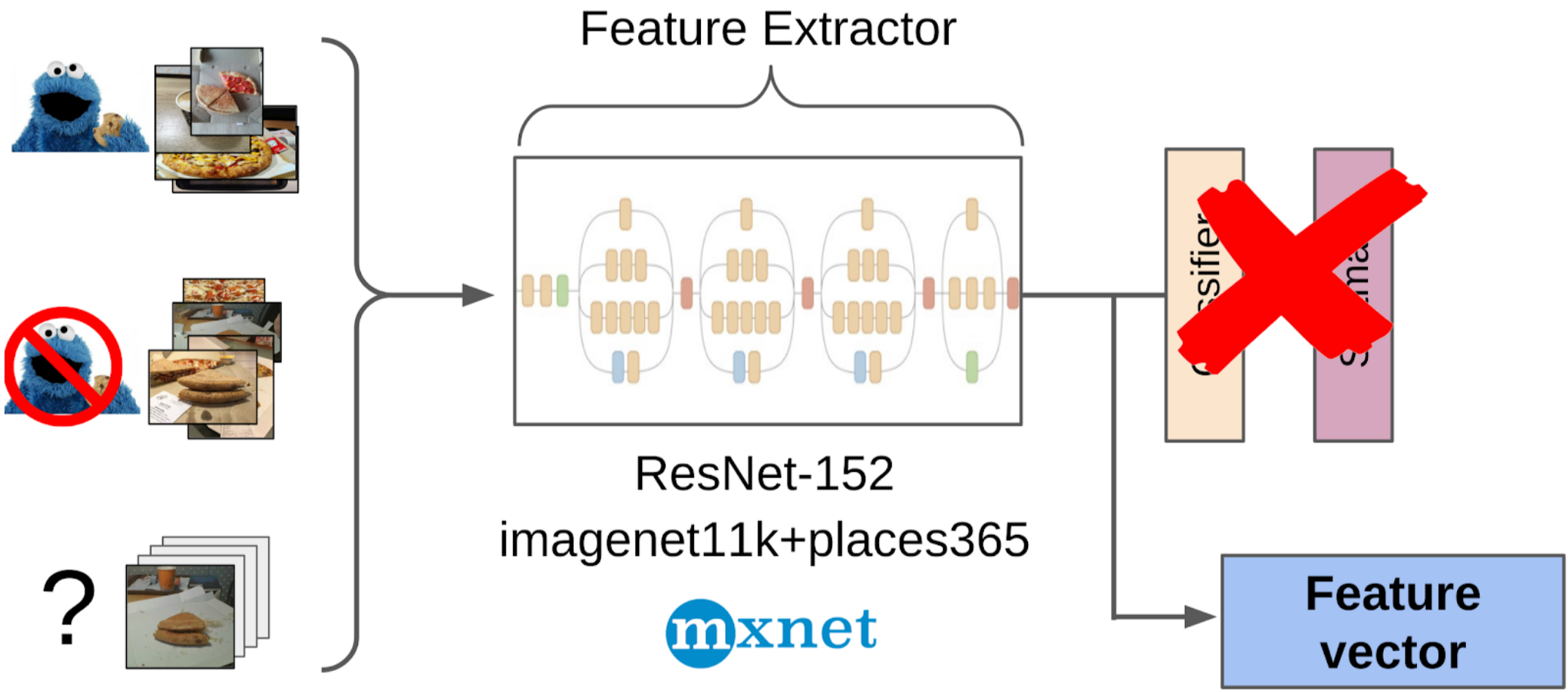
3. Ermittelte den Durchschnitt der Merkmale jeder Klasse und erhielt zwei Anker.
4. Ich habe die Entfernung von jedem Anker zu allen Merkmalen der verbleibenden 50.000 Fotos berechnet.
5. Die oberen 300 in der Nähe eines Ankers sind für die positive Klasse relevant, die oberen 500, die dem anderen Anker am nächsten liegen, sind negativ.
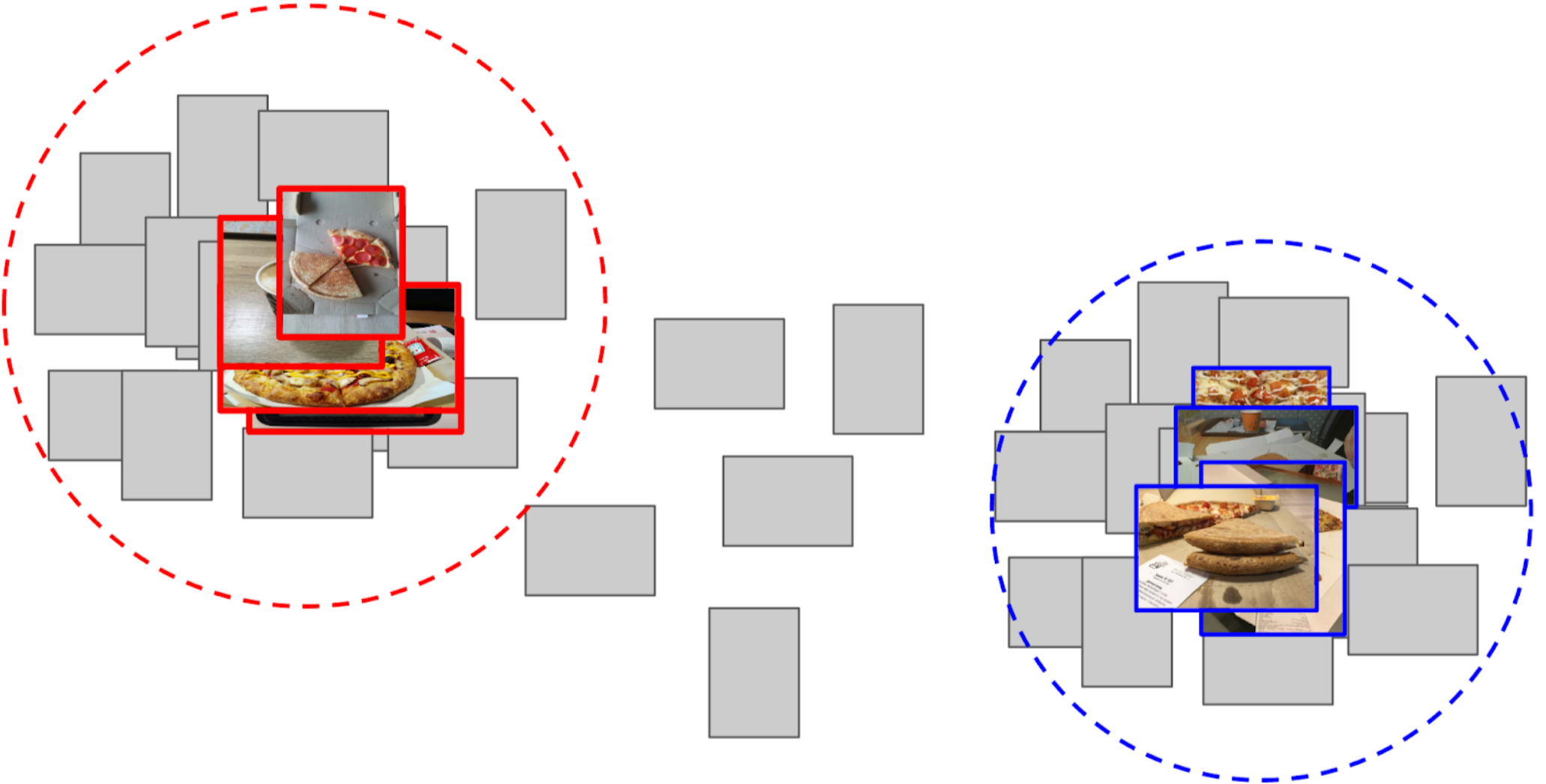
6. Ich habe LightGBM für diese Beispiele mit denselben Funktionen trainiert (XGboost ist auf dem Bild angegeben, da es ein Logo hat und besser erkennbar ist, LightGBM jedoch kein Logo).
7. Mit diesem Modell habe ich das Markup des gesamten Datensatzes erhalten.

Ich habe bei Kaggle-Wettbewerben ungefähr den gleichen Ansatz wie bei der
Basislinie verwendet .
Eine Erklärung an den Fingern, warum dieser Ansatz überhaupt funktioniertEin neuronales Netzwerk kann als stark nichtlineare Transformation eines Bildes wahrgenommen werden. Bei der Klassifizierung wird das Bild in die Wahrscheinlichkeiten der Klassen umgewandelt, die im Trainingssatz enthalten waren. Und diese Wahrscheinlichkeiten können im Wesentlichen als Funktionen für Light GBM verwendet werden. Dies ist jedoch eine ziemlich schlechte Beschreibung, und im Fall von Pizza werden wir daher sagen, dass die Klasse der Kuchen bedingt 0,3 Katzen und 0,7 Hunde beträgt und Müll der Rest ist. Stattdessen können Sie nach dem globalen durchschnittlichen Pooling weniger spärliche Funktionen verwenden. Sie haben eine solche Eigenschaft, dass Merkmale aus den Stichproben des Trainingssatzes generiert werden, die durch eine lineare Transformation (eine vollständig mit Softmax verbundene Schicht) getrennt werden sollten. Aufgrund der Tatsache, dass es im Imagenet-Zug keine explizite Pizza gab, ist es jedoch besser, eine nichtlineare Transformation in Form von Bäumen vorzunehmen, um die Klassen des neuen Trainingssatzes zu trennen. Im Prinzip können Sie noch weiter gehen und Features aus einigen Zwischenschichten des neuronalen Netzwerks übernehmen. Sie werden insofern besser sein, als sie die Lokalität von Objekten noch nicht verloren haben. Aufgrund der Größe des Merkmalsvektors sind sie jedoch viel schlechter. Außerdem sind sie weniger linear als vor einer vollständig verbundenen Schicht.
Ein leichter Exkurs
ODS hat sich kürzlich beschwert, dass niemand über ihre Fehler schreibt. Die Situation korrigieren. Vor ungefähr einem Jahr nahm ich mit
Eugene Nizhibitsky am
Kaggle Sea Lions- Wettbewerb
teil . Die Aufgabe bestand darin, die Pelzrobben in den Bildern der Drohne zu zählen. Das Markup wurde einfach in Form von Schlachtkörperkoordinaten vergeben, aber
irgendwann markierte
Vladimir Iglovikov sie mit Kästchen und teilte dies großzügig mit der Gemeinde. Zu dieser Zeit betrachtete ich mich als Vater der semantischen Segmentierung (nach
Kaggle Dstl ) und entschied, dass Unet das Zählen erheblich erleichtern würde, wenn ich lernen würde, Katzen klassisch zu unterscheiden.
Erklärung der semantischen SegmentierungDie semantische Segmentierung ist im Wesentlichen eine pixelweise Klassifizierung eines Bildes. Das heißt, jedes Quellpixel des Bildes muss einer Klasse zugeordnet werden. Bei der binären Segmentierung (im Fall des Artikels) handelt es sich entweder um eine positive oder eine negative Klasse. Bei der Segmentierung mehrerer Klassen wird jedem Pixel eine Klasse aus dem Trainingssatz zugewiesen (Hintergrund, Gras, Katze, Mann usw.). Bei der binären Segmentierung funktionierte die neuronale
U-Net- Netzwerkarchitektur zu diesem Zeitpunkt gut. Dieses neuronale Netzwerk ist in seiner Struktur einem herkömmlichen Codierer-Decodierer ähnlich, jedoch mit Merkmalen, die vom Codiererteil in den geeigneten Größenstufen an den Decodierer weitergeleitet werden.

In Vanilleform wird es jedoch von niemandem mehr verwendet, aber zumindest wird die Chargennorm hinzugefügt. Nun, in der Regel nehmen sie einen
fetten Encoder und blasen den Decoder auf. U-Netz-ähnliche Architekturen wurden durch neuartige
FPN- Segmentierungsgitter ersetzt, die bei einigen Aufgaben eine gute Leistung zeigen. Unet-ähnliche Architekturen haben jedoch bis heute nicht an Relevanz verloren. Sie eignen sich gut als Basislinie, sind leicht zu trainieren und es ist sehr einfach, die Tiefe / Größe der Neurowissenschaften durch Ändern verschiedener Eccoder zu variieren.
Dementsprechend begann ich Segmentierung zu unterrichten, wobei ich in der ersten Phase nur Boxkatzen als Ziel hatte. Nach der ersten Trainingsphase habe ich den Zug vorhergesagt und mir angesehen, wie die Vorhersagen aussehen. Mit Hilfe der Heuristik könnte man abstraktes Vertrauen aus der Maske auswählen und die Vorhersagen bedingt in zwei Gruppen aufteilen: wo alles gut ist und wo alles schlecht ist.

Vorhersagen, bei denen alles in Ordnung ist, könnten verwendet werden, um die nächste Iteration des Modells zu trainieren. Vorhersagen, bei denen alles schlecht ist, könnten mit großen Flächen ohne Siegel, maskierten Händen und auch in den Zug geworfen werden. Und so trainierten Eugene und ich iterativ ein Modell, das sogar lernte, Pelzrobbenflossen für große Personen zu segmentieren.
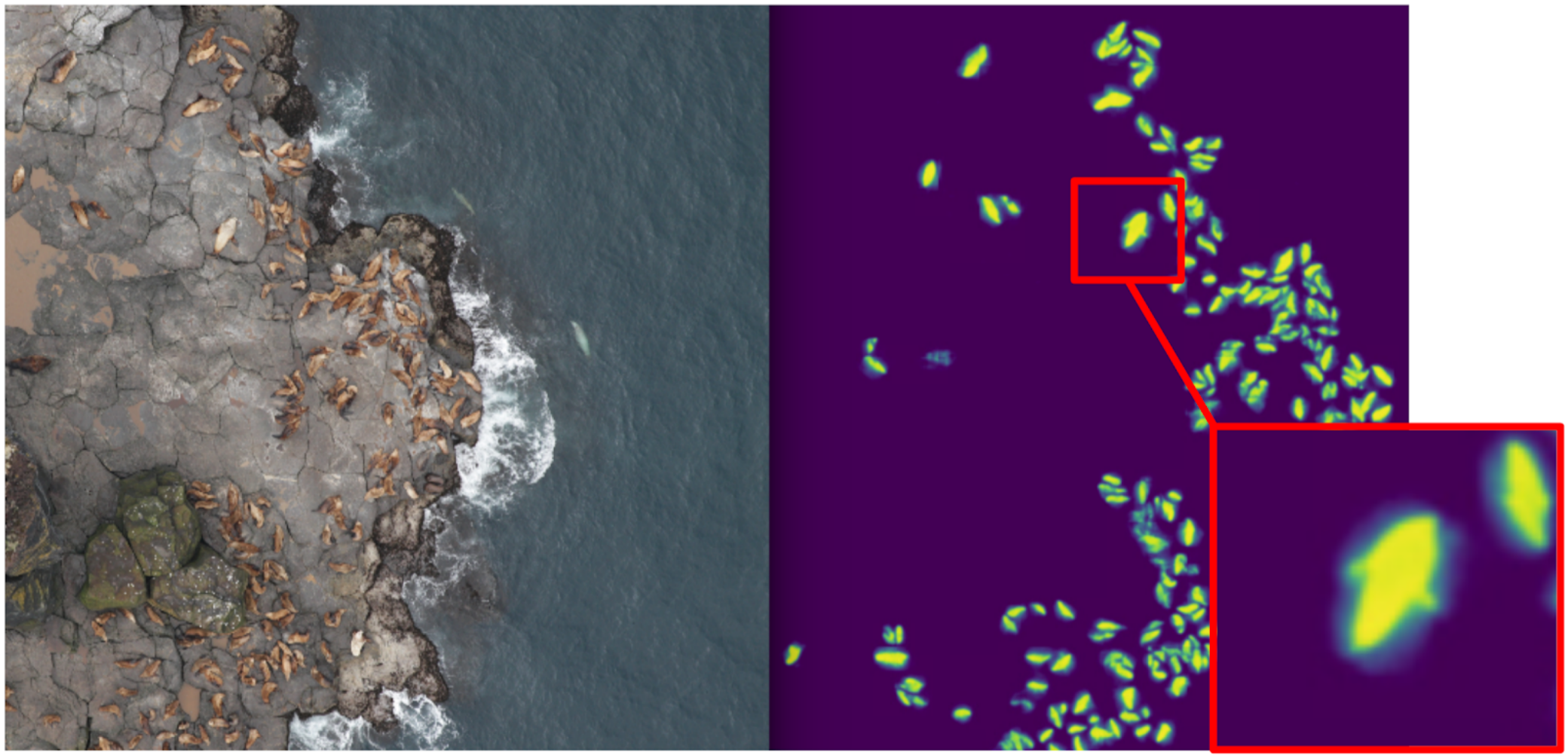
Aber es war ein heftiger Fehlschlag: Wir haben viel Zeit damit verbracht, zu lernen, wie man coole Katzen segmentiert und ... Es hat bei ihrer Berechnung fast nicht geholfen. Die Annahme, dass die Dichte der Siegel (die Anzahl der Individuen pro Flächeneinheit der Maske) konstant ist, hat nicht funktioniert, da die Drohne in unterschiedlichen Höhen flog und die Bilder unterschiedliche Maßstäbe hatten. Gleichzeitig wurden bei der Segmentierung einzelne Personen immer noch nicht herausgegriffen, wenn sie eng beieinander lagen - was ziemlich häufig vorkam. Und vor dem
innovativen Ansatz zur Trennung der Objekte des Tocoder-Teams bei DSB2018 gab es noch ein weiteres Jahr. Infolgedessen blieben wir bei nichts anderem als belegten wir den 40. Platz von 600 Teams.
Ich habe jedoch zwei Schlussfolgerungen gezogen: Die semantische Segmentierung ist ein praktischer Ansatz zur Visualisierung und Analyse der Funktionsweise des Algorithmus, und Masken können mit etwas Aufwand aus den Boxen geschweißt werden.
Aber zurück zur Pizza. Um den Kuchen auf ausgewählten und gefilterten Fotos hervorzuheben, wäre es am richtigsten, die Aufgabe den Schreibern zu geben. Zu diesem Zeitpunkt hatten wir bereits die Boxen und den Konsensalgorithmus für sie implementiert. Also habe ich nur ein paar Beispiele geworfen und sie dem Markup gegeben. Als Ergebnis erhielt ich 500 Proben mit einem genau ausgewählten Krustenbereich.
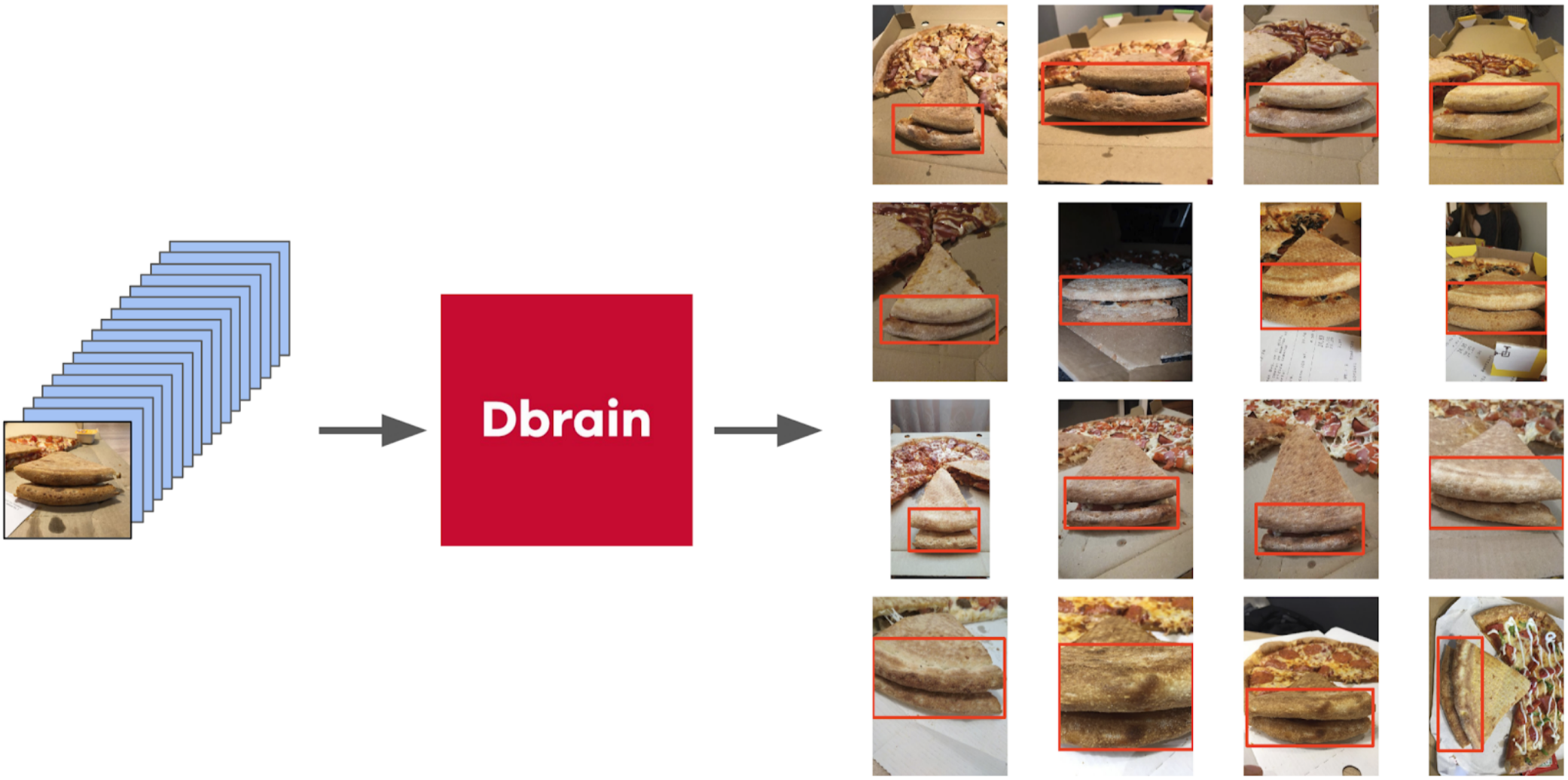
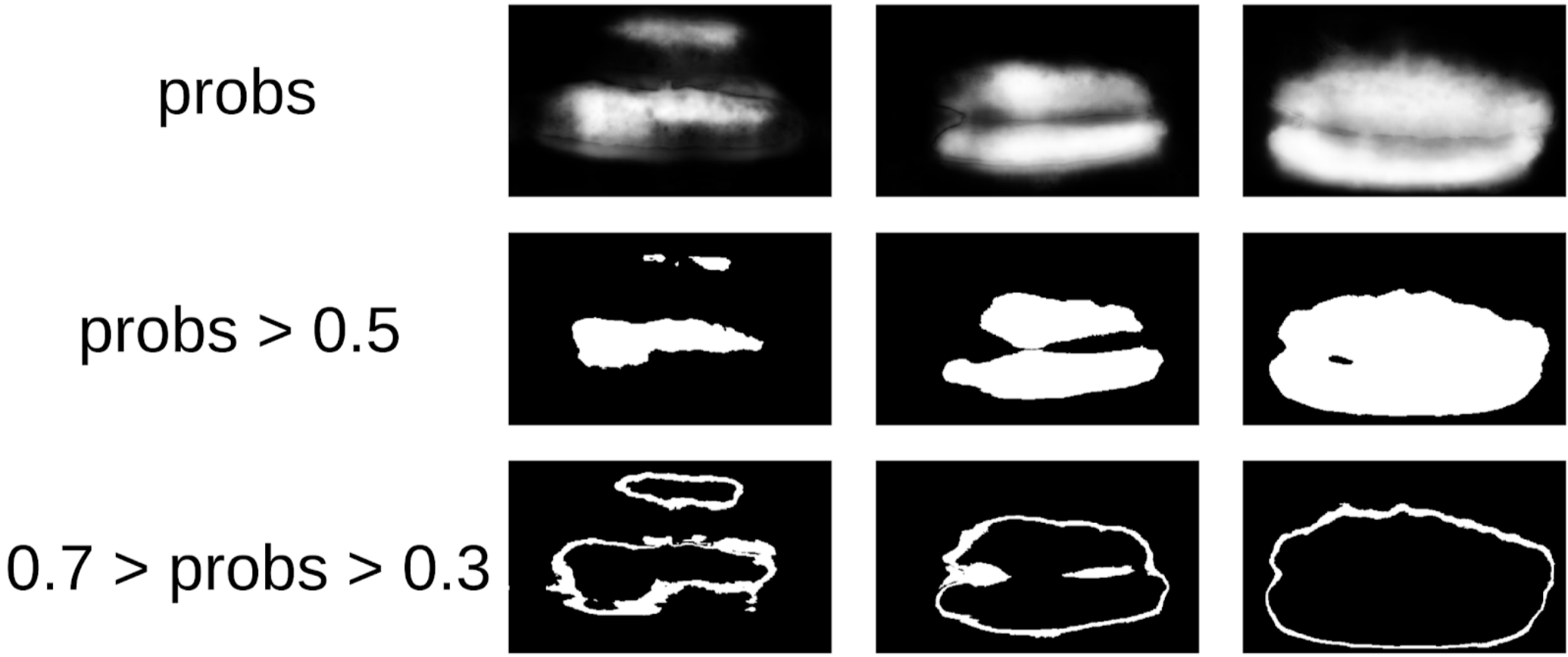
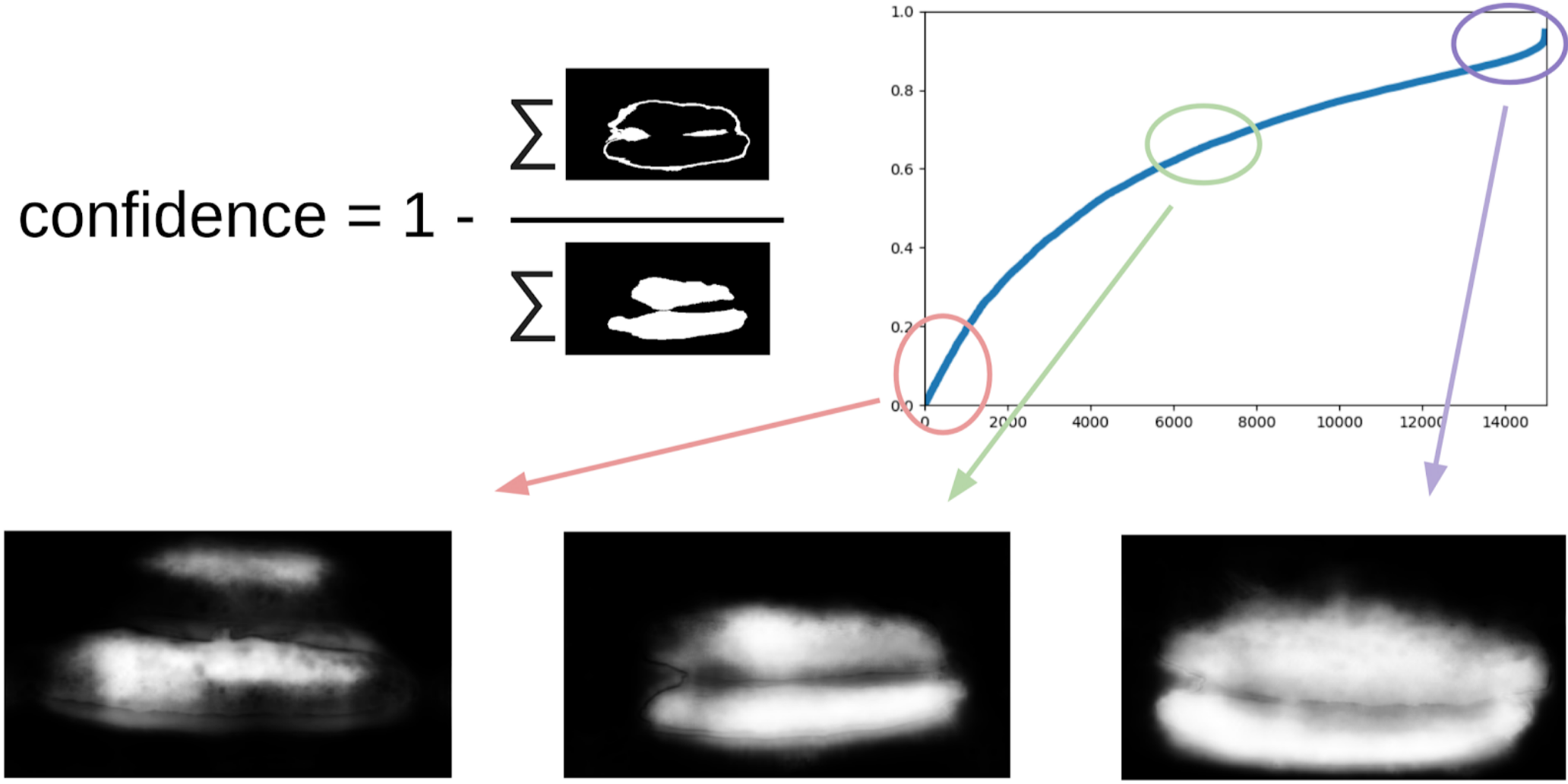
Dann grub ich meinen Code aus den Siegeln und näherte mich formeller dem aktuellen Verfahren. Nach der ersten Iteration des Trainings war auch deutlich sichtbar, wo das Modell falsch war. Das Vertrauen von Vorhersagen kann wie folgt definiert werden:
1 - (grauer Bereich) / (Maskenbereich) # Ich verspreche, es wird eine Formel geben
Um das nächste Mal die Kisten an den Masken zu ziehen, wird ein kleines Ensemble den TTA-Zug vorhersagen. Dies kann bis zu einem gewissen Grad als WAAAAGH-Wissensdestillation angesehen werden, aber es ist richtiger, Pseudo-Labeling zu nennen.
Als nächstes müssen Sie mit Ihren Augen eine bestimmte Vertrauensschwelle wählen, ab der wir einen neuen Zug bilden. Optional können Sie die komplexesten Samples markieren, die das Ensemble nicht verarbeiten konnte. Ich entschied, dass es nützlich sein würde, und malte irgendwo ungefähr 20 Bilder, während ich das Mittagessen verdaute.
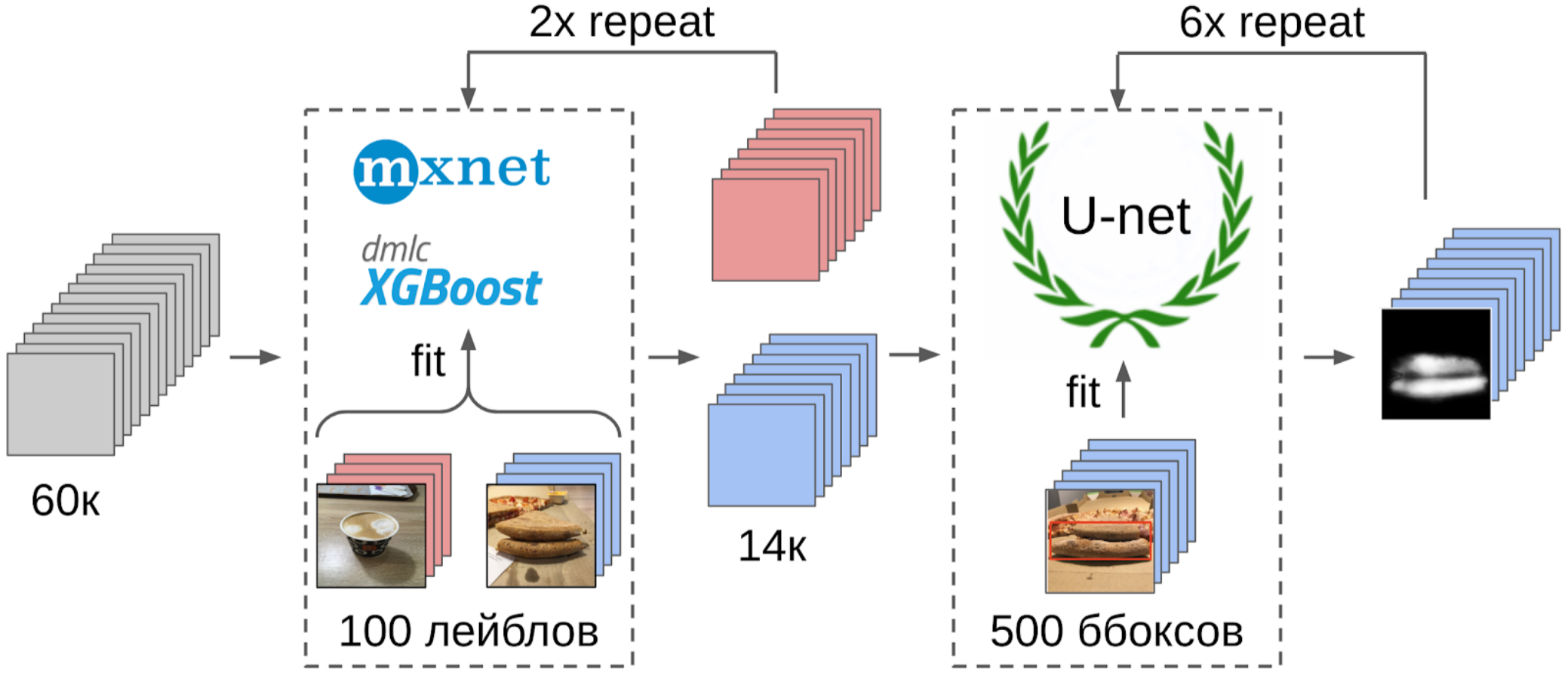
Und jetzt der letzte Teil der Pipeline: das Modelltraining. Um die Proben vorzubereiten, extrahierte ich den Maskenbereich des Kuchens. Ich habe die Maske auch ein wenig mit Dilatation aufgeblasen und auf das Bild aufgetragen, um den Hintergrund zu entfernen, da es keine Informationen über die Qualität des Tests geben sollte. Und dann habe ich gerade einige Modelle aus dem Imagenet Zoo eingereicht. Insgesamt konnte ich ungefähr 12.000 selbstbewusste Proben sammeln. Daher habe ich nicht das gesamte neuronale Netzwerk unterrichtet, sondern nur die letzte Gruppe von Windungen, damit das Modell nicht umgeschult wird.
Warum müssen Sie Schichten einfrierenDaraus ergeben sich zwei Vorteile: 1. Das Netzwerk lernt schneller, da Sie keine Farbverläufe für eingefrorene Ebenen lesen müssen. 2. Das Netzwerk wird nicht umgeschult, da es jetzt weniger freie Parameter hat. Es wird argumentiert, dass die ersten Gruppen von Windungen während des Trainings auf Imagenet recht häufige Zeichen wie scharfe Farbübergänge und Texturen erzeugen, die für eine sehr breite Klasse von Objekten in der Fotografie geeignet sind. Dies bedeutet, dass Sie sie während des Transer-Lernens nicht trainieren können.
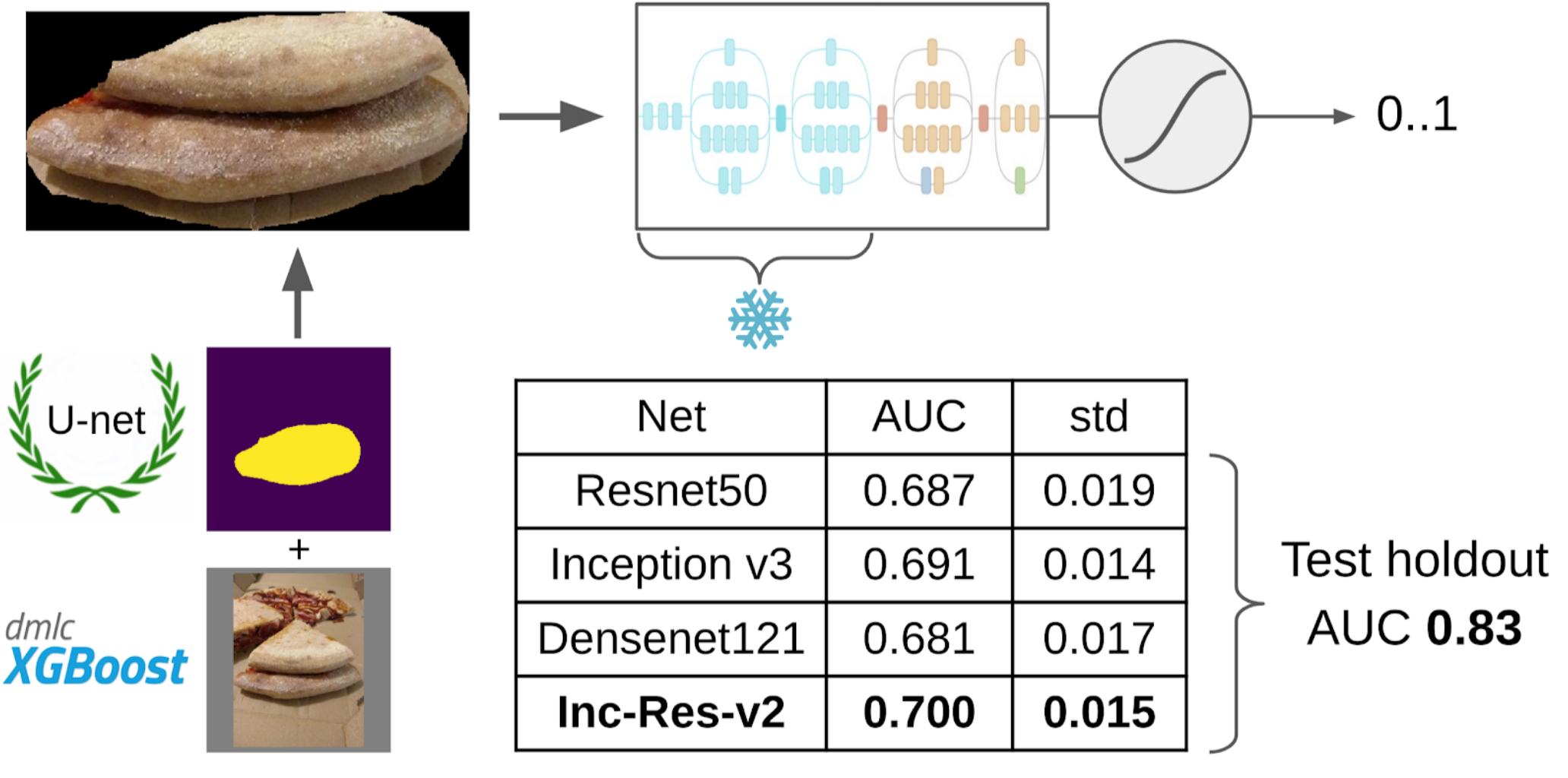
Das beste Einzelmodell war Inception-Resnet-v2, und für sie betrug die ROC-AUC auf einer Falte 0,700. Wenn Sie nichts auswählen und Rohbilder so wie sie sind senden, beträgt die ROC-AUC 0,58. Während ich die Lösung entwickelte, wurde der nächste Datenstapel bei DODO Pizza gekocht, und es war möglich, die gesamte Pipeline auf einen ehrlichen Holdout zu testen. Wir haben die gesamte Pipeline überprüft und ROC-AUC 0.83 erhalten.
Schauen wir uns jetzt die Fehler an:
Top False Negative

Hier ist zu sehen, dass sie mit einem Fehler beim Markieren des Kuchens verbunden sind, da es eindeutig Anzeichen für einen verdorbenen Test gibt.
Top False Positive

Hier hängen die Fehler damit zusammen, dass das erste Modell keinen sehr guten Winkel gewählt hat, wonach es schwierig ist, Schlüsselzeichen für die Testqualität zu finden.
Fazit
Kollegen ärgern mich manchmal, dass ich viele Probleme durch Segmentierung mit Unet löse. Meiner Meinung nach ist dies jedoch ein ziemlich leistungsfähiger und praktischer Ansatz. Es ermöglicht Ihnen, Modellfehler und das Vertrauen seiner Vorhersagen zu visualisieren. Darüber hinaus sieht die gesamte Gewinnlinie sehr einfach aus und jetzt gibt es eine Reihe von Repositorys für jedes Framework.