In diesem Artikel werden wir darüber sprechen, wie und warum wir
das Interaktionssystem entwickelt haben - einen Mechanismus, der Informationen zwischen Clientanwendungen und 1C: Enterprise-Servern überträgt - von der Einstellung der Aufgabe bis zum Durchdenken der Architektur- und Implementierungsdetails.
Das Interaktionssystem (im Folgenden als CB bezeichnet) ist ein verteiltes fehlertolerantes Nachrichtensystem mit garantierter Zustellung. SV ist als hoch ausgelasteter Dienst mit hoher Skalierbarkeit konzipiert und sowohl als Onlinedienst (von 1C bereitgestellt) als auch als Verbreitungsprodukt verfügbar, das auf seinen Serverkapazitäten bereitgestellt werden kann.
CB verwendet verteilten
Hazelcast- Speicher und die
Elasticsearch- Suchmaschine. Wir werden auch über Java sprechen und wie wir PostgreSQL horizontal skalieren.

Erklärung des Problems
Um zu verdeutlichen, warum wir das Interaktionssystem entwickelt haben, möchte ich Ihnen ein wenig darüber erzählen, wie die Entwicklung von Geschäftsanwendungen in 1C funktioniert.
Zunächst ein wenig über uns für diejenigen, die noch nicht wissen, was wir tun :) Wir erstellen die 1C: Enterprise-Technologieplattform. Die Plattform enthält ein Tool zum Entwickeln von Geschäftsanwendungen sowie zur Laufzeit, mit dem Geschäftsanwendungen in einer plattformübergreifenden Umgebung arbeiten können.
Client-Server-Entwicklungsparadigma
Auf „1C: Enterprise“ erstellte Geschäftsanwendungen arbeiten in der dreistufigen
Client-Server- Architektur „DBMS - Anwendungsserver - Client“. In der
eingebetteten Sprache 1C geschriebener Anwendungscode kann auf dem Anwendungsserver oder auf dem Client ausgeführt werden. Alle Arbeiten mit Anwendungsobjekten (Verzeichnisse, Dokumente usw.) sowie das Lesen und Schreiben in die Datenbank werden nur auf dem Server ausgeführt. Die Funktionalität der Formular- und Befehlsschnittstelle ist auch auf dem Server implementiert. Der Kunde empfängt, öffnet und zeigt Formulare an, „kommuniziert“ mit dem Benutzer (Warnungen, Fragen ...), kleine Berechnungen in Formularen, die eine schnelle Reaktion erfordern (z. B. Multiplizieren des Preises mit dem Betrag), Arbeiten mit lokalen Dateien, Arbeiten mit Geräten.
Im Anwendungscode müssen die Header der Prozeduren und Funktionen explizit angeben, wo der Code ausgeführt wird - unter Verwendung der Anweisungen & Auf dem Client / & Auf dem Server (& AtClient / & AtServer in der englischen Sprachversion). Entwickler auf 1C werden mich jetzt korrigieren und sagen, dass es tatsächlich
mehr Richtlinien gibt, aber für uns ist dies jetzt nicht wesentlich.
Servercode kann vom Clientcode aufgerufen werden, Clientcode kann jedoch nicht vom Servercode aufgerufen werden. Dies ist eine grundlegende Einschränkung, die wir aus mehreren Gründen vorgenommen haben. Insbesondere, weil der Servercode so geschrieben werden muss, dass er gleichermaßen ausgeführt wird, unabhängig davon, wo er aufgerufen wird - vom Client oder vom Server. Und wenn der Servercode von einem anderen Servercode aufgerufen wird, fehlt der Client als solcher. Und weil während der Ausführung des Servercodes der Client, der ihn verursacht hat, geschlossen werden konnte, die Anwendung beenden konnte und der Server niemanden zum Aufrufen hatte.
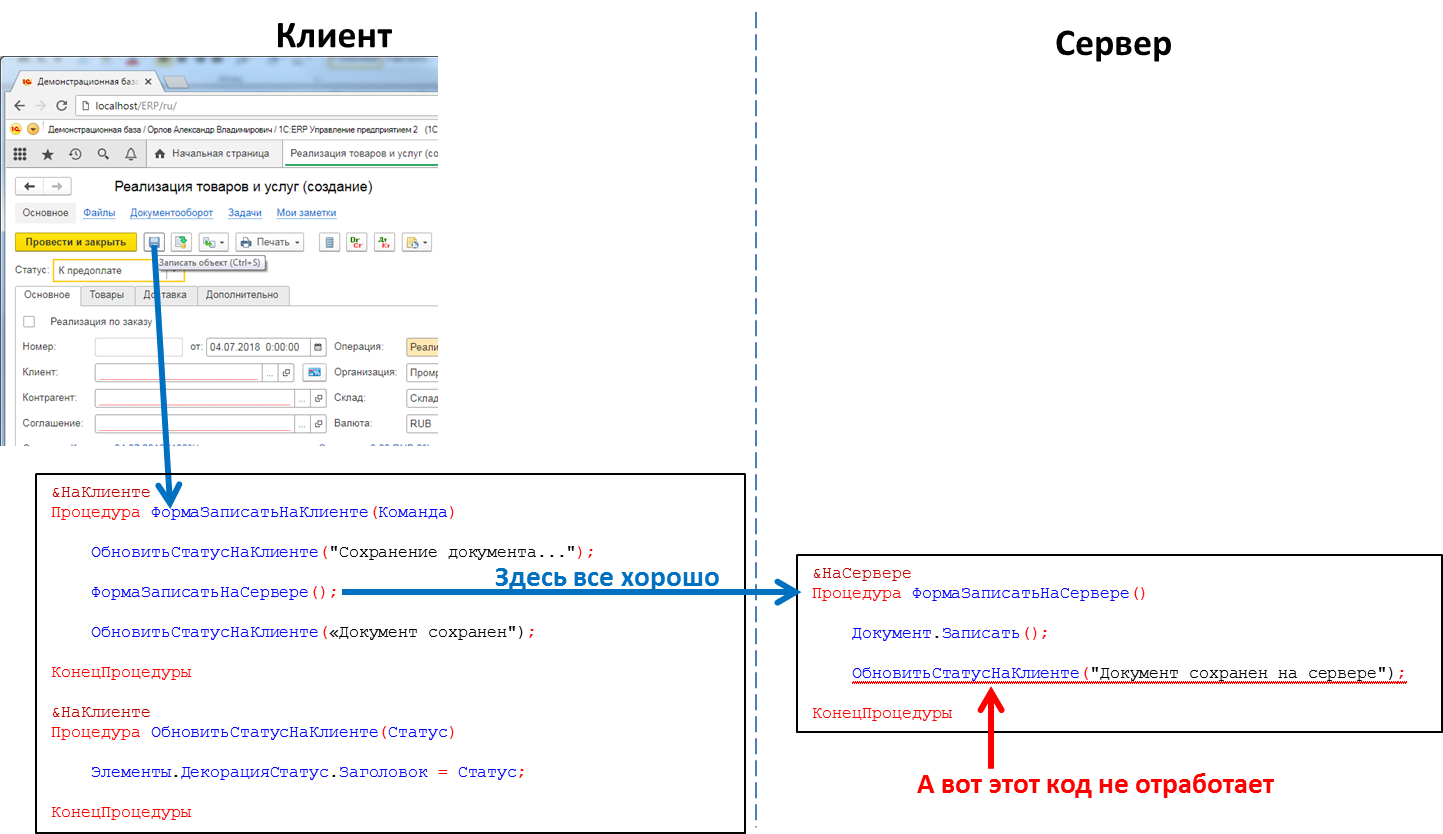 Der Code, der den Klick auf die Schaltfläche verarbeitet: Der Serverprozeduraufruf vom Client funktioniert, der Clientprozeduraufruf vom Server nicht
Der Code, der den Klick auf die Schaltfläche verarbeitet: Der Serverprozeduraufruf vom Client funktioniert, der Clientprozeduraufruf vom Server nichtDies bedeutet, dass wir keine solche Methode haben, wenn wir beispielsweise vom Server eine Nachricht an die Clientanwendung übertragen möchten, dass die Erstellung eines Berichts mit langer Wiedergabe beendet wurde und der Bericht angezeigt werden kann. Wir müssen zum Beispiel Tricks aus dem Client-Code anwenden, um den Server regelmäßig abzufragen. Dieser Ansatz belastet das System jedoch mit unnötigen Anrufen und sieht in der Tat nicht sehr elegant aus.
Wenn beispielsweise ein
SIP- Telefonanruf eingeht, müssen Sie die Clientanwendung darüber informieren, damit sie ihn anhand der Nummer des Anrufers in der Kontrahentendatenbank findet und die Benutzerinformationen über den anrufenden Kontrahenten anzeigt. Oder benachrichtigen Sie beispielsweise nach Eingang der Bestellung im Lager die Kundenanwendung des Kunden darüber. Im Allgemeinen gibt es viele Fälle, in denen ein solcher Mechanismus nützlich wäre.
Eigentlich inszenieren
Erstellen Sie eine Messaging-Engine. Schnell, zuverlässig, mit garantierter Zustellung und flexibler Suche nach Nachrichten. Implementieren Sie basierend auf dem Mechanismus einen Messenger (Nachrichten, Videoanrufe), der in 1C-Anwendungen funktioniert.
Entwerfen Sie ein horizontal skalierbares System. Eine zunehmende Last sollte durch Erhöhen der Anzahl der Knoten geschlossen werden.
Implementierung
Wir haben uns entschieden, den Serverteil von SV nicht direkt in die 1C: Enterprise-Plattform einzubetten, sondern ihn als separates Produkt zu implementieren, dessen API aus dem 1C-Anwendungscode aufgerufen werden kann. Dies geschah aus einer Reihe von Gründen, von denen der Hauptgrund darin bestand, dass ich den Austausch von Nachrichten zwischen verschiedenen 1C-Anwendungen (z. B. zwischen dem Amt für Handel und Rechnungswesen) ermöglichen wollte. Verschiedene 1C-Anwendungen können auf verschiedenen Versionen der 1C: Enterprise-Plattform ausgeführt werden, auf verschiedenen Servern usw. Unter solchen Bedingungen ist die Implementierung von CB als separates Produkt „auf der Seite“ von 1C-Installationen die optimale Lösung.
Deshalb haben wir uns entschlossen, CB als separates Produkt herzustellen. Für kleine Unternehmen empfehlen wir die Verwendung des CB-Servers, den wir in unserer Cloud installiert haben (wss: //1cdialog.com), um den mit der lokalen Installation und Konfiguration des Servers verbundenen Overhead zu vermeiden. Großkunden können es jedoch für angebracht halten, ihren eigenen CB-Server in ihren Einrichtungen zu installieren. Einen ähnlichen Ansatz haben wir in unserem Cloud-basierten SaaS-Produkt
1cFresh verwendet - es wird als Umlaufprodukt für die Installation durch Kunden freigegeben und auch in unserer Cloud
https://1cfresh.com/ bereitgestellt.
App
Für den Lastenausgleich und die Fehlertoleranz stellen wir nicht eine Java-Anwendung bereit, sondern mehrere. Wir stellen ihnen einen Lastenausgleich vor. Wenn Sie eine Nachricht von Knoten zu Knoten übertragen müssen, verwenden Sie Publish / Subscribe in Hazelcast.
Kommunikation des Clients mit dem Server - per Websocket. Es ist gut für Echtzeitsysteme geeignet.
Verteilter Cache
Wählen Sie zwischen Redis, Hazelcast und Ehcache. Auf dem Hof 2015. Redis hat gerade einen neuen Cluster gestartet (zu neu, beängstigend), es gibt einen Sentinel mit einer Reihe von Einschränkungen. Ehcache weiß nicht, wie man sich zu einem Cluster zusammensetzt (diese Funktionalität wurde später angezeigt). Wir haben uns für Hazelcast 3.4 entschieden.
Hazelcast geht sofort zum Cluster. Im Einzelknotenmodus ist es nicht sehr nützlich und kann nur als Cache passen - es weiß nicht, wie Daten auf die Festplatte ausgegeben werden sollen, es hat einen einzelnen Knoten verloren - es hat Daten verloren. Wir stellen mehrere Hazelcasts bereit, zwischen denen wir wichtige Daten sichern. Der Cache ist kein Backup - es ist nicht schade.
Für uns ist Hazelcast:
- Repository von Benutzersitzungen. Das Aufrufen einer Sitzung in der Datenbank ist jedes Mal sehr lang. Daher werden alle Sitzungen in Hazelcast gespeichert.
- Cache. Suchen Sie nach einem Benutzerprofil - checken Sie den Cache ein. Schrieb eine neue Nachricht - legte sie in den Cache.
- Themen zur Kommunikation von Anwendungsinstanzen. Noda generiert ein Ereignis und fügt es in das Hazelcast-Thema ein. Andere Anwendungsknoten, die dieses Thema abonniert haben, empfangen und verarbeiten das Ereignis.
- Clustersperren. Zum Beispiel erstellen wir eine Diskussion über einen eindeutigen Schlüssel (Diskussions-Singleton im Rahmen der 1C-Datenbank):
conversationKeyChecker.check(""); doInClusterLock("", () -> { conversationKeyChecker.check(""); createChannel(""); });
Überprüft, ob kein Kanal vorhanden ist. Sie nahmen das Schloss, überprüften es erneut und erstellten es. Wenn Sie die Sperre nach dem Aufnehmen nicht überprüfen, besteht die Möglichkeit, dass in diesem Moment auch ein anderer Thread diese Sperre aktiviert hat und nun versucht, dieselbe Diskussion zu erstellen - diese ist jedoch bereits vorhanden. Es ist unmöglich, eine Sperre durch synchronisierte oder übliche Java-Sperre durchzuführen. Durch die Basis - langsam und die Basis ist schade, durch Hazelcast - was Sie brauchen.
DBMS auswählen
Wir haben umfangreiche und erfolgreiche Erfahrungen in der Arbeit mit PostgreSQL und in der Zusammenarbeit mit den Entwicklern dieses DBMS.
PostgreSQL ist mit einem Cluster nicht einfach - es verfügt über
XL ,
XC ,
Citus , aber im Allgemeinen handelt es sich nicht um noSQL, die sofort skalierbar sind. NoSQL wurde nicht als Haupt-Repository angesehen, es war genug, dass wir Hazelcast genommen haben, mit dem wir vorher nicht gearbeitet hatten.
Da Sie eine relationale Datenbank skalieren müssen, bedeutet dies
Sharding . Wie Sie wissen, teilen wir beim Sharding die Datenbank in separate Teile auf, sodass jeder von ihnen auf einen separaten Server verschoben werden kann.
Die erste Version unseres Shardings implizierte die Möglichkeit, jede der Tabellen unserer Anwendung in unterschiedlichen Anteilen auf verschiedene Server zu verteilen. Es gibt viele Nachrichten auf Server A - bitte übertragen wir einen Teil dieser Tabelle auf Server B. Bei einer solchen Lösung ging es nur um vorzeitige Optimierung. Deshalb haben wir uns entschlossen, uns auf einen mandantenfähigen Ansatz zu beschränken.
Informationen zu Mandantenfähigkeit finden Sie beispielsweise auf der
Citus Data- Website.
In SV gibt es Konzepte für Anwendung und Teilnehmer. Eine Anwendung ist eine spezifische Installation einer Geschäftsanwendung wie ERP oder Buchhaltung mit ihren Benutzern und Geschäftsdaten. Ein Abonnent ist eine Organisation oder eine Person, in deren Namen die Anwendung auf dem CB-Server registriert ist. Ein Teilnehmer kann mehrere Anwendungen registrieren und diese Anwendungen können Nachrichten miteinander austauschen. Der Abonnent wurde auch der Mieter in unserem System. Nachrichten von mehreren Teilnehmern können sich in einer physischen Basis befinden. Wenn wir feststellen, dass ein Abonnent viel Datenverkehr generiert, leiten wir ihn zu einer separaten physischen Basis (oder sogar zu einem separaten Datenbankserver).
Wir haben eine Hauptdatenbank, in der eine Routing-Tabelle mit Informationen zum Speicherort aller Teilnehmerdatenbanken gespeichert ist.
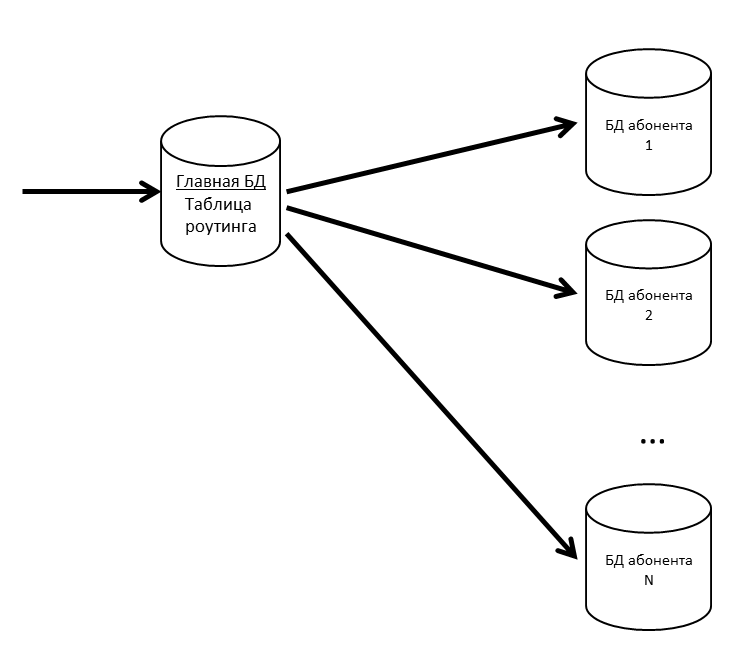
Damit die Hauptdatenbank keinen Engpass darstellt, behalten wir die Routing-Tabelle (und andere häufig angeforderte Daten) im Cache.
Wenn die Abonnentendatenbank langsamer wird, werden wir sie in Partitionen aufteilen. In anderen Projekten verwenden wir pg_pathman, um große Tabellen zu partitionieren.
Da der Verlust von Benutzernachrichten schlecht ist, unterstützen wir unsere Datenbanken mit Replikaten. Durch die Kombination von synchronen und asynchronen Replikaten können Sie bei Verlust der Hauptdatenbank sicher sein. Ein Nachrichtenverlust tritt nur bei gleichzeitigem Ausfall der Hauptdatenbank und ihrer synchronen Replik auf.
Wenn das synchrone Replikat verloren geht, wird das asynchrone Replikat synchron.
Wenn die Hauptdatenbank verloren geht, wird das synchrone Replikat zur Hauptdatenbank, das asynchrone Replikat zum synchronen Replikat.
Elasticsearch für die Suche
Da CB unter anderem auch ein Messenger ist, benötigen Sie hier eine schnelle, bequeme und flexible Suche unter Berücksichtigung der Morphologie nach ungenauen Übereinstimmungen. Wir haben beschlossen, das Rad nicht neu zu erfinden und die kostenlose Elasticsearch-Suchmaschine zu verwenden, die auf der
Lucene- Bibliothek basiert. Wir stellen Elasticsearch auch in einem Cluster (Stammdaten - Daten) bereit, um Probleme bei Ausfall von Anwendungsknoten zu beseitigen.
Auf Github haben wir ein
Plugin der russischen Morphologie für Elasticsearch gefunden und verwenden es. Im Elasticsearch-Index speichern wir die Wurzeln von Wörtern (die das Plugin definiert) und N-Gramm. Während der Benutzer den zu suchenden Text eingibt, suchen wir den eingegebenen Text unter den N-Gramm. Bei der Speicherung im Index wird das Wort "Texte" in folgende N-Gramm unterteilt:
[diese, tech, tex, text, texte, ek, eks, ekst, eksts, ks, kst, kst, kst, st, st, du],
Und auch die Wurzel des Wortes "Text" wird gespeichert. Mit diesem Ansatz können Sie sowohl am Anfang, in der Mitte als auch am Ende des Wortes suchen.
Gesamtbild
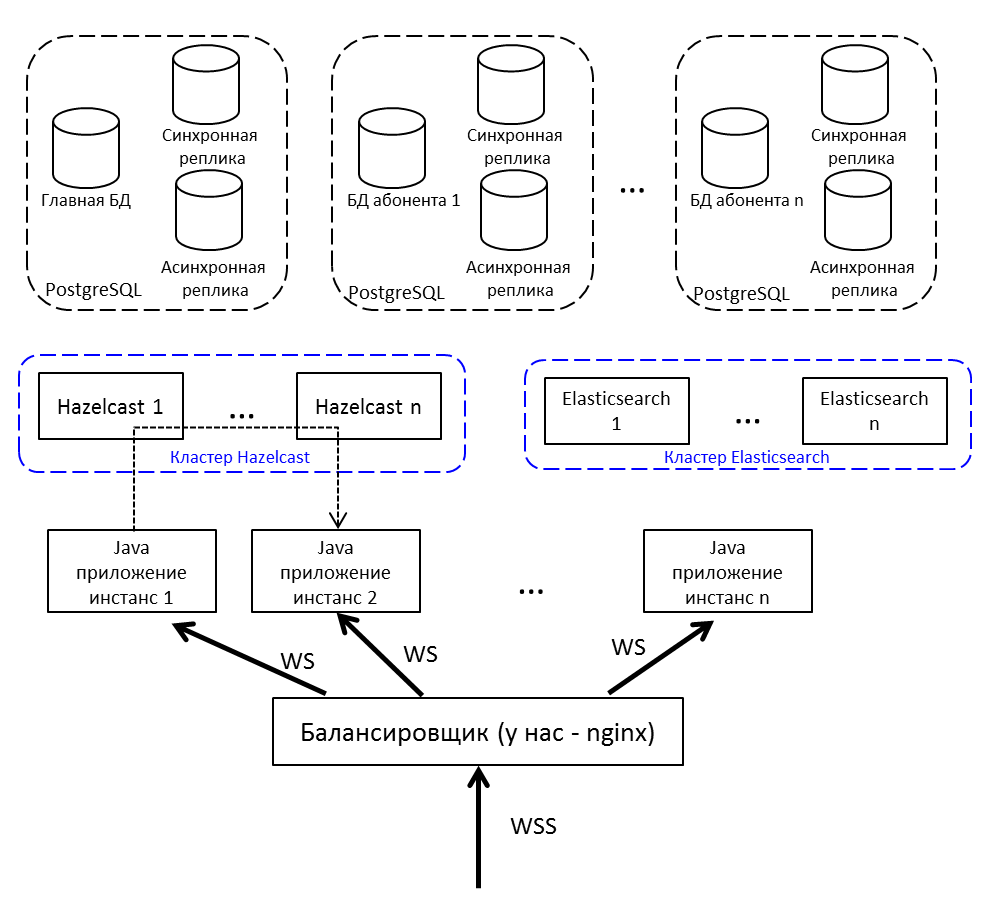
Wiederholen Sie das Bild vom Anfang des Artikels, aber mit Erklärungen:
- Internet Balancer; Wir haben Nginx, es kann jeder sein.
- Instanzen von Java-Anwendungen kommunizieren über Hazelcast miteinander.
- Für die Arbeit mit einem Web-Socket verwenden wir Netty .
- In Java 8 geschriebene Java-Anwendung besteht aus OSGi- Bundles. Die Pläne - Migration auf Java 10 und Übergang zu Modulen.
Entwicklung und Erprobung
Bei der Entwicklung und Erprobung von CB sind wir auf eine Reihe interessanter Merkmale der von uns verwendeten Produkte gestoßen.
Lasttests und Speicherlecks
Die Freisetzung jeder CB-Freisetzung ist ein Stresstest. Es war erfolgreich, als:
- Der Test dauerte mehrere Tage und es gab keinen Denial-of-Service
- Die Reaktionszeit für Schlüsseloperationen hat einen angenehmen Schwellenwert nicht überschritten
- Der Leistungsabfall gegenüber der Vorgängerversion beträgt nicht mehr als 10%
Wir füllen die Testbasis mit Daten - dafür erhalten wir Informationen über den aktivsten Abonnenten vom Produktionsserver, multiplizieren seine Zahlen mit 5 (Anzahl der Nachrichten, Diskussionen, Benutzer) und testen.
Wir führen Lasttests des Interaktionssystems in drei Konfigurationen durch:
- Stresstest
- Nur Verbindungen
- Abonnentenregistrierung
Während des Stresstests starten wir mehrere hundert Threads, die das System ohne Unterbrechung laden: Nachrichten schreiben, Diskussionen erstellen, eine Liste mit Nachrichten abrufen. Wir simulieren die Aktionen normaler Benutzer (eine Liste meiner ungelesenen Nachrichten abrufen, an jemanden schreiben) und Softwarelösungen (ein Paket mit einer anderen Konfiguration übertragen, die Benachrichtigung verarbeiten).
Dies ist beispielsweise Teil des Stresstests:
- Der Benutzer meldet sich an.
- Fordert ungelesene Diskussionen an
- 50% Chance, Nachrichten zu lesen
- Mit 50% Wahrscheinlichkeit schreibt Nachrichten
- Nächster Benutzer:
- Mit 20% Wahrscheinlichkeit entsteht eine neue Diskussion.
- Wählt zufällig eine seiner Diskussionen aus
- Geht hinein
- Fordert Nachrichten und Benutzerprofile an
- Erstellt aus dieser Diskussion fünf Nachrichten, die an zufällige Benutzer gerichtet sind.
- Aus der Diskussion
- Wiederholt 20 mal
- Meldet sich ab und kehrt zum Anfang des Skripts zurück
- Der Chat-Bot betritt das System (emuliert den Austausch von Nachrichten aus dem Code der angewendeten Lösungen).
- Mit 50% Wahrscheinlichkeit entsteht ein neuer Kanal für den Datenaustausch (Sonderdiskussion)
- Mit einer Wahrscheinlichkeit von 50% wird eine Nachricht in einen der vorhandenen Kanäle geschrieben
Das Szenario "Nur Verbindungen" wurde aus einem bestimmten Grund angezeigt. Es gibt eine Situation: Benutzer haben das System angeschlossen, sind aber noch nicht involviert. Jeder Benutzer schaltet morgens um 09:00 Uhr den Computer ein, stellt eine Verbindung zum Server her und ist stumm. Diese Typen sind gefährlich, es gibt viele von ihnen - von den Paketen haben sie nur PING / PONG, aber sie behalten die Verbindung zum Server (sie können sie nicht behalten - und plötzlich eine neue Nachricht). Der Test gibt die Situation wieder, in der innerhalb einer halben Stunde eine große Anzahl solcher Benutzer versucht, sich beim System anzumelden. Es sieht aus wie ein Stresstest, konzentriert sich aber genau auf diesen ersten Eingang - damit es keine Fehler gibt (eine Person benutzt das System nicht, aber es fällt bereits ab - es ist schwierig, sich etwas Schlimmeres auszudenken).
Das Abonnentenregistrierungsszenario stammt aus dem ersten Start. Wir haben einen Stresstest durchgeführt und waren uns sicher, dass das System in der Korrespondenz nicht langsamer wird. Aber die Benutzer gingen und die Registrierung begann in einer Zeitüberschreitung abzufallen. Bei der Registrierung haben wir
/ dev / random verwendet , was an die Entropie des Systems gebunden ist. Der Server konnte nicht genügend Entropie ansammeln und erstarrte zehn Sekunden lang, als er ein neues SecureRandom anforderte. Es gibt viele Möglichkeiten, aus dieser Situation herauszukommen, zum Beispiel: Wechseln Sie zu weniger sicher / dev / urandom, setzen Sie eine spezielle Karte, die Entropie erzeugt, generieren Sie Zufallszahlen im Voraus und speichern Sie sie im Pool. Wir haben das Problem vorübergehend mit einem Pool geschlossen, aber seitdem führen wir einen separaten Test zur Registrierung neuer Abonnenten durch.
Als
Lastgenerator verwenden wir
JMeter . Er weiß nicht, wie man mit einem Web-Socket arbeitet, ein Plug-In wird benötigt. Die ersten Suchergebnisse für "jmeter websocket" sind
Artikel mit BlazeMeter , die ein
Plugin von Maciej Zaleski empfehlen.
Mit ihm beschlossen wir zu beginnen.
Fast unmittelbar nach Beginn der ernsthaften Tests stellten wir fest, dass in JMeter Speicherlecks auftraten.
Das Plugin ist eine separate große Geschichte, mit 176 Sternen hat es 132 Gabeln auf Github. Der Autor selbst hat sich seit 2015 nicht mehr dazu verpflichtet (wir haben es 2015 aufgenommen, dann gab dies keinen Verdacht), mehrere Github-Probleme mit Speicherlecks, 7 nicht geschlossene Pull-Anfragen.
Wenn Sie sich entscheiden, Lasttests mit diesem Plugin durchzuführen, beachten Sie die folgenden Diskussionen:
- In einer Multithread-Umgebung wurde die übliche LinkedList verwendet, sodass sie zur Laufzeit NPE erhielten. Es wird entweder durch Umschalten auf ConcurrentLinkedDeque oder durch synchronisierte Blöcke gelöst. Sie haben die erste Option für sich selbst ausgewählt ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/43 ).
- Speicherverlust, Verbindung trennen löscht keine Verbindungsinformationen ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/44 ).
- Im Streaming-Modus (wenn der Web-Socket am Ende des Beispiels nicht geschlossen wird, aber im Plan weiter verwendet wird) funktionieren die Antwortmuster ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/19 ) nicht.
Dies ist einer von denen auf Github. Was haben wir getan:
- Sie nahmen die Gabel Elyran Kogan (@elyrank) - die Probleme 1 und 3 wurden darin behoben
- Problem 2 gelöst
- Der Steg wurde vom 9.2.14 auf den 9.3.12 aktualisiert
- Wrapped SimpleDateFormat in ThreadLocal; SimpleDateFormat ist nicht threadsicher, was zu Laufzeit-NPE führte
- Ein weiterer Speicherverlust wurde behoben (die Verbindung wurde beim Trennen falsch geschlossen).
Und doch fließt es!
Die Erinnerung endete nicht an einem Tag, sondern an zwei. Es blieb absolut keine Zeit mehr, sie beschlossen, weniger Threads auszuführen, aber auf vier Agenten. Das hätte für mindestens eine Woche reichen sollen.
Zwei Tage sind vergangen ...
Jetzt ging Hazelcast die Erinnerung aus. In den Protokollen wurde deutlich, dass sich Hazelcast nach einigen Testtagen über einen Speichermangel beschwert. Nach einer Weile fällt der Cluster auseinander und die Knoten sterben weiterhin einzeln ab. Wir haben JVisualVM mit Hazelcast verbunden und eine „aufsteigende Säge“ gesehen - er rief regelmäßig GC an, konnte aber sein Gedächtnis nicht löschen.
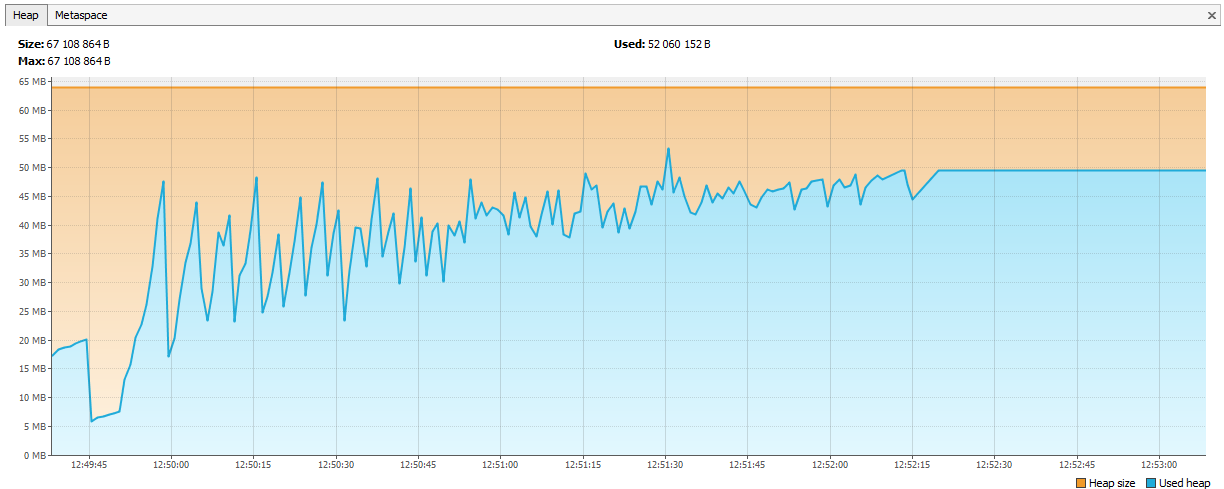
Es stellte sich heraus, dass in Hazelcast 3.4 beim Entfernen von map / multiMap (map.destroy ()) der Speicher nicht vollständig freigegeben wird:
github.com/hazelcast/hazelcast/issues/6317github.com/hazelcast/hazelcast/issues/4888Jetzt ist der Fehler in 3.5 behoben, aber dann war es ein Problem. Wir haben eine neue MultiMap mit dynamischen Namen erstellt und gemäß unserer Logik gelöscht. Der Code sah ungefähr so aus:
public void join(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.put(auth.getUserId(), auth); } public void leave(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.remove(auth.getUserId(), auth); if (sessions.size() == 0) { sessions.destroy(); } }
Rufen Sie an:
service.join(auth1, "____UUID1"); service.join(auth2, "____UUID1");
multiMap wurde für jedes Abonnement erstellt und gelöscht, wenn es nicht benötigt wurde. Wir haben beschlossen, Map <String, Set> zu starten. Der Schlüssel ist der Name des Abonnements und die Werte sind die Kennungen der Sitzungen (von denen Sie bei Bedarf die Benutzer-IDs erhalten können).
public void join(Authentication auth, String sub) { addValueToMap(sub, auth.getSessionId()); } public void leave(Authentication auth, String sub) { removeValueFromMap(sub, auth.getSessionId()); }
Die Diagramme wurden gerade ausgerichtet.
Was haben wir noch über Stresstests gelernt?
- JSR223 muss in einen groovigen und aktivierten Kompilierungscache geschrieben werden - dies ist viel schneller. Link
- Jmeter-Plugins-Diagramme sind leichter zu verstehen als Standard. Link
Über unsere Erfahrungen mit Hazelcast
Hazelcast war ein neues Produkt für uns. Wir haben ab Version 3.4.1 damit begonnen. Jetzt hat unser Produktionsserver Version 3.9.2 (zum Zeitpunkt des Schreibens ist die neueste Version von Hazelcast 3.10).
ID-Generierung
Wir haben mit ganzzahligen Bezeichnern begonnen. Stellen wir uns vor, wir brauchen ein weiteres Long für eine neue Entität. Die Sequenz passt nicht in die Datenbank, Tabellen sind am Sharding beteiligt. Es stellt sich heraus, dass in DB1 eine Nachrichten-ID = 1 und in DB2 eine Nachrichten-ID = 1 vorhanden ist. Sie können eine solche ID auch in Haastcast nicht in Elasticsearch einfügen. Das Schlimmste ist jedoch, wenn Sie die Daten reduzieren möchten von zwei Datenbanken in eine (z. B. die Entscheidung, dass eine Datenbank für diese Abonnenten ausreicht). Sie können mehrere AtomicLongs in Hazelcast erstellen und den Zähler dort belassen. Die Leistung beim Abrufen einer neuen ID beträgt incrementAndGet plus die Zeit für eine Anforderung in Hazelcast. Aber Hazelcast hat etwas Optimaleres - FlakeIdGenerator. Jeder Kunde erhält bei Kontakt einen ID-Bereich, z. B. den ersten von 1 bis 10.000, den zweiten von 10.001 bis 20.000 usw. Jetzt kann der Client neue Kennungen unabhängig voneinander ausgeben, bis der an ihn ausgegebene Bereich endet. Es funktioniert schnell, aber wenn Sie die Anwendung (und den Hazelcast-Client) neu starten, beginnt eine neue Sequenz - daher die Lücken usw. Darüber hinaus ist den Entwicklern nicht klar, warum IDs ganzzahlig sind, aber sie gehen so unterschiedlich vor. Wir haben alle gewogen und auf UUIDs umgestellt.
Übrigens, für diejenigen, die wie Twitter sein wollen, gibt es eine solche Snowcast-Bibliothek - dies ist eine Snowflake-Implementierung zusätzlich zu Hazelcast. Sie können es hier sehen:
github.com/noctarius/snowcastgithub.com/twitter/snowflakeAber wir haben ihre Hände nicht erreicht.
TransactionalMap.replace
Eine weitere Überraschung: TransactionalMap.replace funktioniert nicht. Hier ist ein Test:
@Test public void replaceInMap_putsAndGetsInsideTransaction() { hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { context.getMap("map").put("key", "oldValue"); context.getMap("map").replace("key", "oldValue", "newValue"); String value = (String) context.getMap("map").get("key"); assertEquals("newValue", value); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); } Expected : newValue Actual : oldValue
Ich musste meinen Ersatz mit getForUpdate schreiben:
protected <K,V> boolean replaceInMap(String mapName, K key, V oldValue, V newValue) { TransactionalTaskContext context = HazelcastTransactionContextHolder.getContext(); if (context != null) { log.trace("[CACHE] Replacing value in a transactional map"); TransactionalMap<K, V> map = context.getMap(mapName); V value = map.getForUpdate(key); if (oldValue.equals(value)) { map.put(key, newValue); return true; } return false; } log.trace("[CACHE] Replacing value in a not transactional map"); IMap<K, V> map = hazelcastInstance.getMap(mapName); return map.replace(key, oldValue, newValue); }
Testen Sie nicht nur reguläre Datenstrukturen, sondern auch deren Transaktionsversionen. Es kommt vor, dass IMap funktioniert, aber TransactionalMap ist weg.
Bringen Sie eine neue JAR ohne Ausfallzeiten an
Zuerst haben wir beschlossen, Objekte unserer Klassen in Hazelcast aufzunehmen. Zum Beispiel haben wir eine Klassenanwendung, die wir speichern und lesen möchten. Speichern:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); map.set(id, application);
Wir lesen:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); return map.get(id);
Alles arbeitet. Dann haben wir beschlossen, einen Index in Hazelcast zu erstellen, um danach zu suchen:
map.addIndex("subscriberId", false);
Beim Schreiben einer neuen Entität erhielten sie eine ClassNotFoundException. Hazelcast versuchte den Index zu ergänzen, wusste aber nichts über unsere Klasse und wollte, dass sie eine JAR mit dieser Klasse hat. Wir haben das getan, alles hat funktioniert, aber ein neues Problem ist aufgetreten: Wie kann man die JAR aktualisieren, ohne den Cluster vollständig zu stoppen? Hazelcast holt die neue JAR während eines podweisen Upgrades nicht ab. In diesem Moment haben wir beschlossen, dass wir sehr gut leben können, ohne nach Index zu suchen. Wenn Sie Hazelcast als Schlüsselwertspeicher verwenden, funktioniert dann alles? Nicht wirklich. Auch hier das unterschiedliche Verhalten von IMap und TransactionalMap. Wo IMap keine Rolle spielt, gibt TransactionalMap einen Fehler aus.
IMap Wir schreiben 5000 Objekte, lesen es. Alles wird erwartet.
@Test void get5000() { IMap<UUID, Application> map = hazelcastInstance.getMap("application"); UUID subscriberId = UUID.randomUUID(); for (int i = 0; i < 5000; i++) { UUID id = UUID.randomUUID(); String title = RandomStringUtils.random(5); Application application = new Application(id, title, subscriberId); map.set(id, application); Application retrieved = map.get(id); assertEquals(id, retrieved.getId()); } }
Und es funktioniert nicht in der Transaktion, wir erhalten eine ClassNotFoundException:
@Test void get_transaction() { IMap<UUID, Application> map = hazelcastInstance.getMap("application_t"); UUID subscriberId = UUID.randomUUID(); UUID id = UUID.randomUUID(); Application application = new Application(id, "qwer", subscriberId); map.set(id, application); Application retrievedOutside = map.get(id); assertEquals(id, retrievedOutside.getId()); hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { TransactionalMap<UUID, Application> transactionalMap = context.getMap("application_t"); Application retrievedInside = transactionalMap.get(id); assertEquals(id, retrievedInside.getId()); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); }
In 3.8 wurde der Mechanismus zur Bereitstellung von Benutzerklassen angezeigt. Sie können einen Hauptknoten zuweisen und die JAR-Datei darauf aktualisieren.
Jetzt haben wir den Ansatz komplett geändert: Wir serialisieren ihn in JSON und speichern ihn in Hazelcast. Hazelcast muss die Struktur unserer Klassen nicht kennen, aber wir können ohne Ausfallzeiten aktualisieren. Die Versionierung von Domänenobjekten wird von der Anwendung gesteuert. Verschiedene Versionen der Anwendung können gleichzeitig gestartet werden, und es ist möglich, dass eine neue Anwendung Objekte mit neuen Feldern schreibt, die alte jedoch nichts über diese Felder weiß. Gleichzeitig liest die neue Anwendung Objekte aus, die von der alten Anwendung aufgezeichnet wurden und in denen keine neuen Felder vorhanden sind. Wir behandeln solche Situationen innerhalb der Anwendung, aber der Einfachheit halber ändern oder löschen wir keine Felder, sondern erweitern Klassen nur durch Hinzufügen neuer Felder.
Wie wir hohe Leistung bieten
Vier Reisen nach Hazelcast - gut, zwei in die Datenbank - schlecht
Das Aufrufen von Daten im Cache ist immer besser als in der Datenbank, Sie möchten jedoch keine nicht beanspruchten Datensätze speichern. Die Entscheidung darüber, was zwischengespeichert werden soll, verschieben wir auf die letzte Entwicklungsstufe. Wenn die neue Funktionalität codiert ist, aktivieren wir PostgreSQL, um alle Abfragen zu protokollieren (log_min_duration_statement auf 0) und 20 Minuten lang Lasttests durchzuführen. Mithilfe gesammelter Protokolle können Dienstprogramme wie pgFouine und pgBadger Analyseberichte erstellen. In Berichten suchen wir hauptsächlich nach langsamen und häufigen Abfragen. Für langsame Abfragen erstellen wir einen Ausführungsplan (EXPLAIN) und bewerten, ob eine solche Abfrage beschleunigt werden kann. Häufige Anforderungen für dieselben Eingabedaten werden gut zwischengespeichert. Wir versuchen, Anfragen "flach" zu halten, eine Tabelle pro Anfrage.
Bedienung
SV als Onlinedienst wurde im Frühjahr 2017 gestartet, als im November 2017 ein separates SV-Produkt veröffentlicht wurde (zu diesem Zeitpunkt im Beta-Status).
Über einen Zeitraum von mehr als einem Jahr traten keine ernsthaften Probleme beim Betrieb des Onlinedienstes von CB auf. Wir überwachen den Onlinedienst über
Zabbix , sammeln und stellen ihn bei
Bamboo bereit .
Das CB-Server-Distributionskit wird in Form von nativen Paketen geliefert: RPM, DEB, MSI. Außerdem bieten wir für Windows ein einziges Installationsprogramm in Form einer EXE-Datei an, mit der der Server, Hazelcast und Elasticsearch auf einem Computer installiert werden. Zuerst haben wir diese Version der Installation "Demo" genannt, aber jetzt wurde klar, dass dies die beliebteste Bereitstellungsoption ist.