
Ich liebe Ceph. Ich arbeite seit 4 Jahren mit ihm (0.80.x - 12.2.6 12.2.5). Manchmal bin ich so leidenschaftlich über ihn, dass ich Abende und Nächte in seiner Gesellschaft verbringe und nicht mit meiner Freundin. Ich habe verschiedene Probleme mit diesem Produkt festgestellt und lebe bis heute mit einigen. Manchmal freute ich mich über einfache Entscheidungen und manchmal träumte ich davon, mich mit Entwicklern zu treffen, um meine Empörung auszudrücken. Aber Ceph wird immer noch in unserem Projekt verwendet und es ist möglich, dass es zumindest von mir für neue Aufgaben verwendet wird. In dieser Geschichte werde ich unsere Erfahrungen mit dem Betrieb von Ceph teilen, mich auf irgendeine Weise zum Thema äußern, was mir an dieser Lösung nicht gefällt, und vielleicht denen helfen, die sie nur betrachten. Die Ereignisse, die vor etwa einem Jahr begannen, als ich Dell EMC ScaleIO, jetzt als Dell EMC VxFlex OS bekannt, mitbrachte, veranlassten mich, diesen Artikel zu schreiben.
Dies ist keinesfalls eine Werbung für Dell EMC oder deren Produkt! Persönlich bin ich nicht sehr gut mit großen Unternehmen und Black Boxes wie VxFlex OS. Aber wie Sie wissen, ist alles auf der Welt relativ und am Beispiel von VxFlex OS ist es sehr praktisch zu zeigen, was Ceph in Bezug auf den Betrieb ist, und ich werde versuchen, es zu tun.
Parameter Es geht um 4-stellige Zahlen!
Ceph-Dienste wie MON, OSD usw. haben verschiedene Parameter zum Einrichten aller Arten von Subsystemen. Die Parameter werden in der Konfigurationsdatei festgelegt und von Daemons zum Zeitpunkt des Starts gelesen. Einige Werte können bequem im laufenden Betrieb mithilfe des "Injektions" -Mechanismus geändert werden, der unten beschrieben wird. Alles ist fast super, wenn Sie den Moment weglassen, in dem es Hunderte von Parametern gibt:
Hammer:
> ceph daemon mon.a config show | wc -l 863
Leuchtend:
> ceph daemon mon.a config show | wc -l 1401
Es stellt sich in zwei Jahren ~ 500 neue Parameter heraus. Im Allgemeinen ist die Parametrisierung cool. Es ist nicht cool, dass es Schwierigkeiten gibt, 80% dieser Liste zu verstehen. Die Dokumentation beschreibt nach meinen Schätzungen ~ 20% und ist an einigen Stellen nicht eindeutig. Ein Verständnis der Bedeutung der meisten Parameter muss im Github des Projekts oder in den Mailinglisten gefunden werden, aber dies hilft nicht immer.
Hier ist ein Beispiel für einige Parameter, die mich erst kürzlich interessiert haben. Ich habe sie im Blog einer Ceph-Gadfly gefunden:
throttler_perf_counter = false // enable/disable throttler perf counter osd_enable_op_tracker = false // enable/disable OSD op tracking
Codekommentare im Sinne von Best Practices. Als ob ich die Wörter verstehe und sogar grob, worum es geht, aber was es mir geben wird, ist es nicht.
Oder hier: osd_op_threads in Luminous war verschwunden und nur die Quellen halfen, einen neuen Namen zu finden: osd_peering_wq threads
Mir gefällt auch, dass es besonders ganzheitliche Möglichkeiten gibt. Hier zeigt der Typ, dass es gut ist, rgw_num _rados_handles zu erhöhen :
und der andere Typ denkt, dass> 1 unmöglich und sogar gefährlich ist .
Und meine Lieblingssache ist, wenn Anfänger in ihren Blog-Posts Beispiele für eine Konfiguration angeben, bei der alle Parameter gedankenlos (wie mir scheint) aus einem anderen Blog der gleichen Art kopiert werden und so eine Reihe von Parametern, von denen niemand außer dem Autor des Codes weiß, abwandern config zu config.
Ich brenne auch nur wild mit dem, was sie in Luminous gemacht haben. Es gibt eine super coole Funktion - Parameter im laufenden Betrieb ändern, ohne Prozesse neu zu starten. Sie können beispielsweise den Parameter eines bestimmten OSD ändern:
> ceph tell osd.12 injectargs '--filestore_fd_cache_size=512'
oder setzen Sie '*' anstelle von 12 und der Wert wird auf allen OSDs geändert. Es ist wirklich sehr cool. Aber wie viel in Ceph geschieht dies mit dem linken Fuß. Bai Design können nicht alle Parameterwerte im laufenden Betrieb geändert werden. Genauer gesagt können sie eingestellt werden und erscheinen in der Ausgabe geändert, aber tatsächlich werden nur wenige erneut gelesen und erneut angewendet. Beispielsweise können Sie die Größe des Thread-Pools nicht ändern, ohne den Prozess neu zu starten. Damit der Team-Executor versteht, dass es sinnlos ist, den Parameter auf diese Weise zu ändern, haben sie beschlossen, eine Nachricht zu drucken. Hallo.
Zum Beispiel:
> ceph tell mon.* injectargs '--mon_allow_pool_delete=true' mon.c: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.a: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.b: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
Mehrdeutig. Tatsächlich wird das Entfernen von Pools nach der Injektion möglich. Das heißt, diese Warnung ist für diesen Parameter nicht relevant. Ok, aber es gibt immer noch Hunderte von Parametern, einschließlich sehr nützlicher, die ebenfalls eine Warnung enthalten, und es gibt keine Möglichkeit, ihre tatsächliche Anwendbarkeit zu überprüfen. Im Moment kann ich anhand des Codes nicht einmal verstehen, welche Parameter nach der Injektion angewendet werden und welche nicht. Um die Zuverlässigkeit zu gewährleisten, müssen Sie die Dienste neu starten. Dies macht Sie wütend. Wütend, weil ich weiß, dass es einen Injektionsmechanismus gibt.
Was ist mit VxFlex OS? Ähnliche Prozesse wie MON (in VxFlex ist es MDM), OSD (SDS in VxFlex) haben auch Konfigurationsdateien, in denen es Dutzende von Parametern für alle gibt. Zwar sagen ihre Namen auch nichts aus, aber die gute Nachricht ist, dass wir nie auf sie zurückgegriffen haben, um so viel zu brennen wie bei Ceph.
Technische Schulden
Wenn Sie Ihre Bekanntschaft mit Ceph mit der aktuellsten Version für heute beginnen, scheint alles in Ordnung zu sein, und Sie möchten einen positiven Artikel schreiben. Aber wenn Sie mit ihm in der Prod von Version 0.80 leben, dann sieht nicht alles so rosig aus.
Vor Jewel wurden Ceph-Prozesse als Root ausgeführt. Jewel entschied, dass sie vom Benutzer 'ceph' aus arbeiten sollten, und dies erforderte einen Eigentümerwechsel für alle Verzeichnisse, die von Ceph-Diensten verwendet werden. Es scheint, dass dies? Stellen Sie sich ein OSD vor, das eine 2-TB-SATA-Magnetplatte mit voller Kapazität bedient. Das Parallelschalten einer solchen Festplatte (zu verschiedenen Unterverzeichnissen) bei voller Festplattenauslastung dauert also 3-4 Stunden. Stellen Sie sich zum Beispiel vor, Sie haben dreihundert solcher Festplatten. Selbst wenn Sie die Knoten aktualisieren (sofort 8-12 Festplatten), erhalten Sie ein ziemlich langes Update, bei dem der Cluster über OSD verschiedener Versionen verfügt und ein Replikat von Daten zum Zeitpunkt der Serveraktualisierung weniger ist. Im Allgemeinen hielten wir es für absurd, bauten Ceph-Pakete neu auf und ließen OSD als Root laufen. Wir haben beschlossen, das OSD beim Eingeben oder Ersetzen an einen neuen Benutzer zu übertragen. Jetzt ändern wir 2-3 Laufwerke pro Monat und fügen 1-2 hinzu. Ich denke, wir können das bis 2022 schaffen.
CRUSH Tunables
CRUSH ist das Herz von Ceph, alles dreht sich darum. Dies ist der Algorithmus, mit dem pseudozufällig der Datenort ausgewählt wird und dank dessen die mit dem RADOS-Cluster arbeitenden Clients herausfinden, auf welchem OSD die benötigten Daten (Objekte) gespeichert sind. Das Hauptmerkmal von CRUSH ist, dass keine Metadatenserver wie Lustre oder IBM GPFS (jetzt Spectrum Scale) erforderlich sind. Mit CRUSH können Clients und OSD direkt miteinander interagieren. Natürlich ist es schwierig, die primitiven RADOS-Objektspeicher- und Dateisysteme zu vergleichen, die ich als Beispiel gegeben habe, aber ich denke, die Idee ist klar.
CRUSH-Tunables wiederum sind eine Reihe von Parametern / Flags, die sich auf den Betrieb von CRUSH auswirken und es zumindest theoretisch effizienter machen.
Beim Upgrade von Hammer auf Jewel (Test natürlich) wurde eine Warnung angezeigt, die besagt, dass das Tunables-Profil Parameter enthält, die für die aktuelle Version (Jewel) nicht optimal sind, und es wird empfohlen, das Profil auf das optimale Profil umzuschalten. Im Allgemeinen ist alles klar. Das Dock sagt, dass dies sehr wichtig und der richtige Weg ist, aber es wird auch gesagt, dass nach dem Datenwechsel eine Rebellion von 10% der Daten auftritt. 10% - es klingt nicht beängstigend, aber wir haben beschlossen, es zu testen. Bei einem Cluster ist es ungefähr zehnmal weniger als bei einem Produkt. Bei der gleichen Anzahl von PGs pro OSD, die mit Testdaten gefüllt sind, haben wir eine Rebellion von 60%! Stellen Sie sich zum Beispiel vor, mit 100 TB Daten beginnen sich 60 TB zwischen OSDs zu bewegen, und dies bei ständig steigender Clientlast, die Latenz erfordert! Wenn ich es noch nicht gesagt habe, bieten wir s3 an und wir haben auch nachts nicht viel weniger Last auf rgw, von denen es unter statischen Websites 8 und 4 mehr gibt. Im Allgemeinen haben wir entschieden, dass dies nicht unser Weg ist, zumal ein solcher Umbau der neuen Version, mit der wir nicht an dem Produkt gearbeitet hatten, zumindest zu optimistisch war. Darüber hinaus hatten wir große Bucket-Indizes, die nur sehr schlecht neu erstellt werden, und dies war auch der Grund für die Verzögerung beim Umschalten des Profils. Über die Indizes wird separat etwas niedriger sein. Am Ende haben wir einfach die Warnung entfernt und beschlossen, später darauf zurückzukommen.
Beim Wechseln des Profils beim Testen fielen Cephfs-Clients in den CentOS 7.2-Kerneln aus, weil sie mit dem neueren Hashing-Algorithmus des neuen Profils nicht arbeiten konnten. Wir verwenden keine Cephfs im Produkt, aber wenn wir es früher getan hätten, wäre dies ein weiterer Grund, das Profil nicht zu wechseln.
Das Dock sagt übrigens, dass Sie das Profil zurücksetzen können, wenn das, was während des Aufstands passiert, nicht zu Ihnen passt. Nach einer Neuinstallation der Hammer-Version und einem Upgrade auf Jewel sieht das Profil folgendermaßen aus:
> ceph osd crush show-tunables { ... "straw_calc_version": 1, "allowed_bucket_algs": 22, "profile": "unknown", "optimal_tunables": 0, ... }
Es ist wichtig, dass es "unbekannt" ist. Wenn Sie versuchen, den Wiederaufbau zu stoppen, indem Sie ihn auf "Legacy" (wie im Dock angegeben) oder sogar auf "Hammer" umstellen, hört der Rebellance nicht auf, sondern setzt sich nur in Übereinstimmung mit anderen Tunables fort und nicht " optimal. " Im Allgemeinen muss alles gründlich überprüft und doppelt überprüft werden, Ceph ist nicht vertrauenswürdig.
CRUSH Trade-of
Wie Sie wissen, ist alles auf dieser Welt ausgeglichen und Nachteile werden auf alle Vorteile angewendet. Der Nachteil von CRUSH besteht darin, dass PGs auch bei gleichem Gewicht ungleichmäßig auf verschiedene OSDs verteilt sind. Außerdem hindert nichts verschiedene PGs daran, mit unterschiedlichen Geschwindigkeiten zu wachsen, während die Hash-Funktion abfällt. Insbesondere haben wir eine OSD-Auslastung von 48-84%, obwohl sie die gleiche Größe und das gleiche Gewicht haben. Wir versuchen sogar, Server gleich schwer zu machen, aber das ist so, nur unser Perfektionismus, nicht mehr. Angesichts der Tatsache, dass E / A ungleichmäßig auf die Festplatten verteilt ist, ist das Schlimmste, dass bei Erreichen des vollständigen Status (95%) von mindestens einem OSD im Cluster die gesamte Aufzeichnung gestoppt wird und der Cluster schreibgeschützt wird. Der ganze Cluster! Und es spielt keine Rolle, dass der Cluster immer noch voller Speicherplatz ist. Alles, das Finale, kommt raus! Dies ist ein architektonisches Merkmal von CRUSH. Stellen Sie sich vor, Sie sind im Urlaub, einige OSDs haben die Marke von 85% überschritten (standardmäßig die erste Warnung) und Sie haben 10% auf Lager, um zu verhindern, dass die Aufzeichnung gestoppt wird. Und 10% bei aktiver Aufnahme sind nicht so lang. Idealerweise benötigt Ceph bei einem solchen Design eine diensthabende Person, die in solchen Fällen die vorbereiteten Anweisungen befolgen kann.
Deshalb haben wir beschlossen, die Daten im Cluster aus dem Gleichgewicht zu bringen, weil Mehrere OSDs lagen nahe an der Vollwertmarke (85%).
Es gibt verschiedene Möglichkeiten:
Der einfachste Weg ist etwas verschwenderisch und nicht sehr effektiv, weil Die Daten selbst bewegen sich möglicherweise nicht aus dem überfüllten OSD, oder die Bewegung ist vernachlässigbar.
- Ändern Sie das permanente Gewicht des OSD (GEWICHT)
Dies führt zu einer Änderung des Gewichts aller höheren Bucket-Hierarchien (CRUSH-Terminologie), des OSD-Servers, des Rechenzentrums usw. und infolgedessen auf die Bewegung von Daten, auch nicht von jenen OSD, von denen es notwendig ist.
Wir haben versucht, das Gewicht eines OSD zu reduzieren, nachdem die Daten neu erstellt wurden, haben wir es reduziert, dann das dritte und wir haben festgestellt, dass wir dies für eine lange Zeit spielen würden.
- Nicht permanentes OSD-Gewicht ändern (REWEIGHT)
Dies geschieht durch Aufrufen von "ceph osd reweight-by-usage". Dies führt zu einer Änderung des sogenannten OSD-Einstellgewichts, und das Gewicht des höheren Eimers ändert sich nicht. Infolgedessen werden die Daten sozusagen zwischen verschiedenen OSDs eines Servers ausgeglichen, ohne die Grenzen des CRUSH-Buckets zu überschreiten. Dieser Ansatz hat uns sehr gut gefallen. Wir haben uns im Trockenlauf angesehen, welche Änderungen am Produkt vorgenommen werden sollen. Alles war in Ordnung, bis der Aufstandsprozess in der Mitte einen Einsatz bekam. Wieder googeln, Newsletter lesen, mit verschiedenen Optionen experimentieren und am Ende stellt sich heraus, dass der Stopp durch das Fehlen einiger Tunables im oben genannten Profil verursacht wurde. Wieder waren wir in technische Schulden verwickelt. Infolgedessen gingen wir den Weg des Hinzufügens von Festplatten und des ineffektivsten Wiederaufbaus. Zum Glück mussten wir das noch tun, weil Es war geplant, das CRUSH-Profil mit einem ausreichenden Kapazitätsspielraum zu wechseln.
Ja, wir kennen den Balancer (Luminous and Higher), der Teil von mgr ist und das Problem der ungleichmäßigen Datenverteilung lösen soll, indem PG beispielsweise nachts zwischen OSDs verschoben wird. Aber ich habe noch keine positiven Kritiken über seine Arbeit gehört, auch nicht im aktuellen Mimic.
Sie werden wahrscheinlich sagen, dass technische Schulden nur unser Problem sind, und ich würde dem wahrscheinlich zustimmen. Aber für vier Jahre mit Ceph im Produkt hatten wir nur eine Ausfallzeit s3 aufgezeichnet, die eine ganze Stunde dauerte. Und dann lag das Problem nicht bei RADOS, sondern bei RGW, das nach Eingabe seiner Standard-100-Threads festgefahren war und die meisten Benutzer die Anforderungen nicht erfüllten. Es war immer noch auf Hammer. Meiner Meinung nach ist dies ein guter Indikator und wird dadurch erreicht, dass wir keine plötzlichen Bewegungen ausführen und bei Ceph eher skeptisch gegenüber allem sind.
Wild gc
Wie Sie wissen, ist das Löschen von Daten direkt von der Festplatte eine ziemlich anspruchsvolle Aufgabe. In fortgeschrittenen Systemen wird das Löschen verzögert oder gar nicht ausgeführt. Ceph ist auch ein fortschrittliches System, und im Fall von RGW werden beim Löschen eines s3-Objekts die entsprechenden RADOS-Objekte nicht sofort von der Festplatte gelöscht. RGW markiert s3-Objekte als gelöscht, und ein separater gc-Stream löscht Objekte direkt aus RADOS-Pools und wird dementsprechend von Datenträgern verschoben. Nach der Aktualisierung auf Luminous änderte sich das Verhalten von gc merklich, es begann aggressiver zu arbeiten, obwohl die gc-Parameter gleich blieben. Mit dem Wort merklich meine ich, dass wir anfingen zu sehen, wie gc an der externen Überwachung des Dienstes auf Sprunglatenz arbeitet. Dies wurde von einem hohen IO im rgw.gc.-Pool begleitet Das Problem, mit dem wir konfrontiert sind, ist jedoch viel epischer als nur IO. Wenn gc funktioniert, werden viele Protokolle des Formulars generiert:
0 <cls> /builddir/build/BUILD/ceph-12.2.5/src/cls/rgw/cls_rgw.cc:3284: gc_iterate_entries end_key=1_01530264199.726582828
Wobei 0 am Anfang die Protokollierungsstufe ist, auf der diese Nachricht gedruckt wird. Es gibt sozusagen keinen Weg, die Protokollierung unter Null zu senken. Infolgedessen wurde in ein paar Stunden ~ 1 GB Protokolle von einem OSD in uns generiert, und alles wäre in Ordnung gewesen, wenn die Ceph-Knoten nicht plattenlos gewesen wären ... Wir laden das Betriebssystem über PXE direkt in den Speicher und verwenden keine lokale Festplatte oder NFS, NBD für die Systempartition (/). Es stellt sich heraus, zustandslose Server. Nach einem Neustart wird der gesamte Status durch Automatisierung gerollt. Wie es funktioniert, werde ich irgendwie in einem separaten Artikel beschreiben. Jetzt ist es wichtig, dass 6 GB Speicher für "/" zugewiesen werden, von denen ~ 4 normalerweise frei sind. Wir senden alle Protokolle an Graylog und verwenden eine ziemlich aggressive Protokollrotationsrichtlinie. In der Regel treten keine Probleme mit dem Festplatten- / RAM-Überlauf auf. Aber wir waren nicht bereit dafür, mit 12 OSDs füllte sich der "/" - Server sehr schnell, die Teilnehmer reagierten nicht rechtzeitig auf den Auslöser in Zabbix und das OSD wurde gerade gestoppt, da kein Protokoll geschrieben werden konnte. Infolgedessen haben wir die Intensität von gc reduziert, das Ticket wurde nicht gestartet, weil Es war bereits vorhanden, und wir haben cron ein Skript hinzugefügt, in dem die OSD-Protokolle abgeschnitten werden, wenn ein bestimmter Betrag überschritten wird, ohne auf die Protokollierung zu warten. Übrigens wurde der Protokollierungsgrad erhöht .
Platzierungsgruppen und gelobte Skalierbarkeit
Meiner Meinung nach ist PG die am schwierigsten zu verstehende Abstraktion. PG wird benötigt, um CRUSH effektiver zu machen. Der Hauptzweck von PG besteht darin, Objekte zu gruppieren, um den Ressourcenverbrauch zu reduzieren, die Produktivität und Skalierbarkeit zu erhöhen. Objekte direkt und einzeln zu adressieren, ohne sie zu PG zu kombinieren, wäre sehr teuer.
Das Hauptproblem von PG besteht darin, die Anzahl für einen neuen Pool zu bestimmen. Aus dem Ceph-Blog:
"Die Auswahl der richtigen Anzahl von PGs für Ihren Cluster ist ein bisschen schwarze Kunst - und ein Albtraum für die Benutzerfreundlichkeit."
Dies ist immer sehr spezifisch für eine bestimmte Installation und erfordert viel Nachdenken und Berechnung.
Wichtige Empfehlungen:
- Zu viele PGs auf dem OSD sind schlecht, und es wird zu viel Ressourcen für ihre Wartung und Bremsen während des Neuausgleichs / der Wiederherstellung geben.
- Nur wenige PGs auf OSD sind schlecht, die Leistung leidet und OSDs werden ungleichmäßig gefüllt.
- Die Zahl PG muss ein Vielfaches von Grad 2 sein. Dies wird dazu beitragen, "Power of CRUSH" zu erhalten.
Und hier brennt es bei mir. PGs sind weder im Volumen noch in der Anzahl der Objekte begrenzt. Wie viele Ressourcen (in reellen Zahlen) werden benötigt, um ein PG zu warten? Kommt es auf seine Größe an? Kommt es auf die Anzahl der Replikate dieses PG an? Sollte ich ein Dampfbad nehmen, wenn ich genug Speicher, schnelle CPUs und ein gutes Netzwerk habe?
Außerdem müssen Sie über das zukünftige Wachstum des Clusters nachdenken. Die PG-Nummer kann nicht reduziert, sondern nur erhöht werden. Gleichzeitig wird dies nicht empfohlen, da dies im Wesentlichen die Aufteilung eines Teils von PG in neue und wilde Umbauten zur Folge hat.
"Das Erhöhen der PG-Anzahl eines Pools ist eines der wirkungsvollsten Ereignisse in einem Ceph-Cluster und sollte nach Möglichkeit für Produktionscluster vermieden werden."
Daher müssen Sie nach Möglichkeit sofort über die Zukunft nachdenken.
Ein echtes Beispiel.
Ein Cluster von 3 Servern mit jeweils 14 x 2 TB OSD, insgesamt 42 OSDs. Replik 3, nützlicher Ort ~ 28 TB. Um unter S3 verwendet zu werden, müssen Sie die Anzahl der PGs für den Datenpool und den Indexpool berechnen. RGW verwendet mehr Pools, aber die beiden sind primär.
Wir gehen in den PG-Rechner (es gibt einen solchen Rechner), wir betrachten mit den empfohlenen 100 PG auf dem OSD nur 1312 PG. Aber nicht alles ist so einfach: Wir haben eine Einführung - der Cluster wird definitiv innerhalb eines Jahres dreimal wachsen, aber das Eisen wird etwas später gekauft. Wir erhöhen die "Ziel-PGs pro OSD" dreimal auf 300 und erhalten 4480 PG.
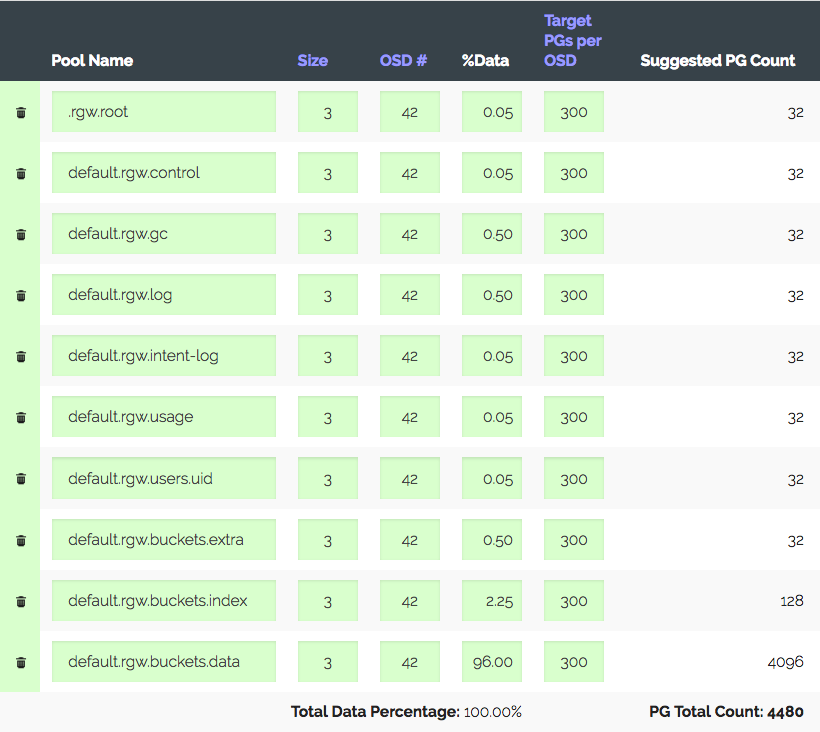
Stellen Sie die Anzahl der PGs für die entsprechenden Pools ein - wir erhalten eine Warnung: Es sind zu viele PGs pro OSD ... eingetroffen. Empfangen ~ 300 PG auf OSD mit einem Limit von 200 (Luminous). Früher waren es übrigens 300. Und das Interessanteste ist, dass nicht alle unnötigen PGs spähen dürfen, das heißt, dies ist nicht nur eine Warnung. Aus diesem Grund glauben wir, dass wir alles richtig machen, Grenzen erhöhen, die Warnung ausschalten und weitermachen.
Ein weiteres reales Beispiel ist interessanter.
S3, 152 TB nutzbares Volumen, 252 OSD bei 1,81 TB, ~ 105 PG bei OSD. Der Cluster wuchs allmählich, alles war in Ordnung, bis mit den neuen Gesetzen in unserem Land ein Wachstum auf 1 PB, d. H. + ~ 850 TB, erforderlich war und gleichzeitig die Leistung aufrechterhalten werden muss, was jetzt für S3 ziemlich gut ist. Angenommen, wir nehmen Festplatten mit 6 (5,7 Real) TB und berücksichtigen unter Berücksichtigung von Replik 3 + 447 OSD. Unter Berücksichtigung der aktuellen erhalten wir 699 OSDs mit jeweils 37 PGs, und wenn wir unterschiedliche Gewichte berücksichtigen, stellt sich heraus, dass die alten OSDs nur ein Dutzend PGs haben. Also sagst du mir, wie erträglich das funktionieren wird? Die Leistung eines Clusters mit einer anderen Anzahl von PGs ist ziemlich schwer synthetisch zu messen, aber die von mir durchgeführten Tests zeigen, dass für eine optimale Leistung 50 PG bis 2 TB OSD erforderlich sind. Und was ist mit weiterem Wachstum? Ohne die Anzahl der PG zu erhöhen, können Sie mit der Zuordnung von PG zu OSD 1: 1 fortfahren. Vielleicht verstehe ich etwas nicht?
Ja, Sie können einen neuen Pool für RGW mit der gewünschten Anzahl von PGs erstellen und ihm eine separate S3-Region zuordnen. Oder bauen Sie sogar einen neuen Cluster in der Nähe. Aber Sie müssen zugeben, dass dies alles Krücken sind. Und es stellt sich heraus, dass es aufgrund seines Konzepts wie ein gut skalierbarer Ceph erscheint, PG skaliert mit Vorbehalten. Sie müssen entweder mit behinderten Vorings leben, um sich auf das Wachstum vorzubereiten, oder irgendwann alle Daten im Cluster neu erstellen oder nach Leistung punkten und mit dem leben, was passiert. Oder alles durchgehen.
Ich bin froh, dass die Entwickler von Ceph verstehen, dass PG eine komplexe und überflüssige Abstraktion für den Benutzer ist und er es besser ist, nichts davon zu wissen.
"In Luminous haben wir wichtige Schritte unternommen, um eine der gebräuchlichsten Methoden, um Ihren Cluster in einen Graben zu treiben, endgültig zu eliminieren. Wir freuen uns darauf, PGs schließlich vollständig auszublenden, damit sie nicht etwas sind, was die meisten Benutzer jemals wissen müssen oder müssen." denke an ".
In vxFlex gibt es kein Konzept für PG oder Analoga. Sie fügen dem Pool einfach Festplatten hinzu und fertig. Und so weiter bis zu 16 PB. Stellen Sie sich vor, es muss nichts berechnet werden, es gibt keine Haufen von Status dieser PGs, die Festplatten werden während des gesamten Wachstums gleichmäßig entsorgt. Weil Festplatten werden an vxFlex als Ganzes übergeben (es gibt kein Dateisystem darüber). Es gibt keine Möglichkeit, die Fülle zu beurteilen, und es gibt überhaupt kein solches Problem. Ich weiß nicht einmal, wie ich Ihnen vermitteln soll, wie angenehm es ist.
"Ich muss auf SP1 warten"
Eine andere Geschichte von "Erfolg". Wie Sie wissen, ist RADOS der primitivste Schlüsselwertspeicher. S3, das auf RADOS implementiert ist, ist ebenfalls primitiv, aber immer noch etwas funktionaler. , S3 . , , RGW . — RADOS-, OSD. . , . OSD down. , , . , scrub' . , - 503, .
Bucket Index resharding — , (RADOS-) , , OSD, .
, , Jewel ! Hammer, .. -. ?
Hammer 20+ , , OSD Graylog , . , .. IO . Luminous, .. . Luminous, , . , . IO index-, , . , IO , . , … ; , :
, . , .. , .
, Hammer->Jewel - . OSD - . , OSD .
— , , . Hammer s3, . , . , , etag, body, . . , . Suspend . "" . , .
, 2 — , Cloudmouse. , Ceph, , .
vxFlex OS 2 . , . , . , . , , , Dell EMC.
Leistung
. , ? Gute Frage. , . , Ceph, vxFlex . - . , .
9 ceph-devel : , CPU ( Xeon' !) IOPS All-NVMe Ceph 12.2.7 bluestore.
, , "" Ceph . ( Hammer) Ceph , s3 . , ScaleIO Ceph RBD . Ceph, — CPU. RDMA InfiniBand, jemalloc . , 10-20 , iops, io, Ceph . vxFlex . — Ceph system time, scaleio — io wait. , bluestore, , , -, , Ceph. ScaleIO . , , Ceph Dell EMC.
, , PG. (), IO. - PG IO, , . , nearfull. , .
vxFlex - , . ( ceph-volume), , .
Scrub
, . , , Ceph.
, . " " — - , . , 2 TB >50%, Ceph, . . , .
vxFlex OS , , . — bandwidth . . , .
, , vxFlex scrub-error. Ceph 2 .
Überwachung
Luminous — . . MGR- Zabbix (3 ). . , , - IO , gc, . — RGW .

. .
S3, "" :
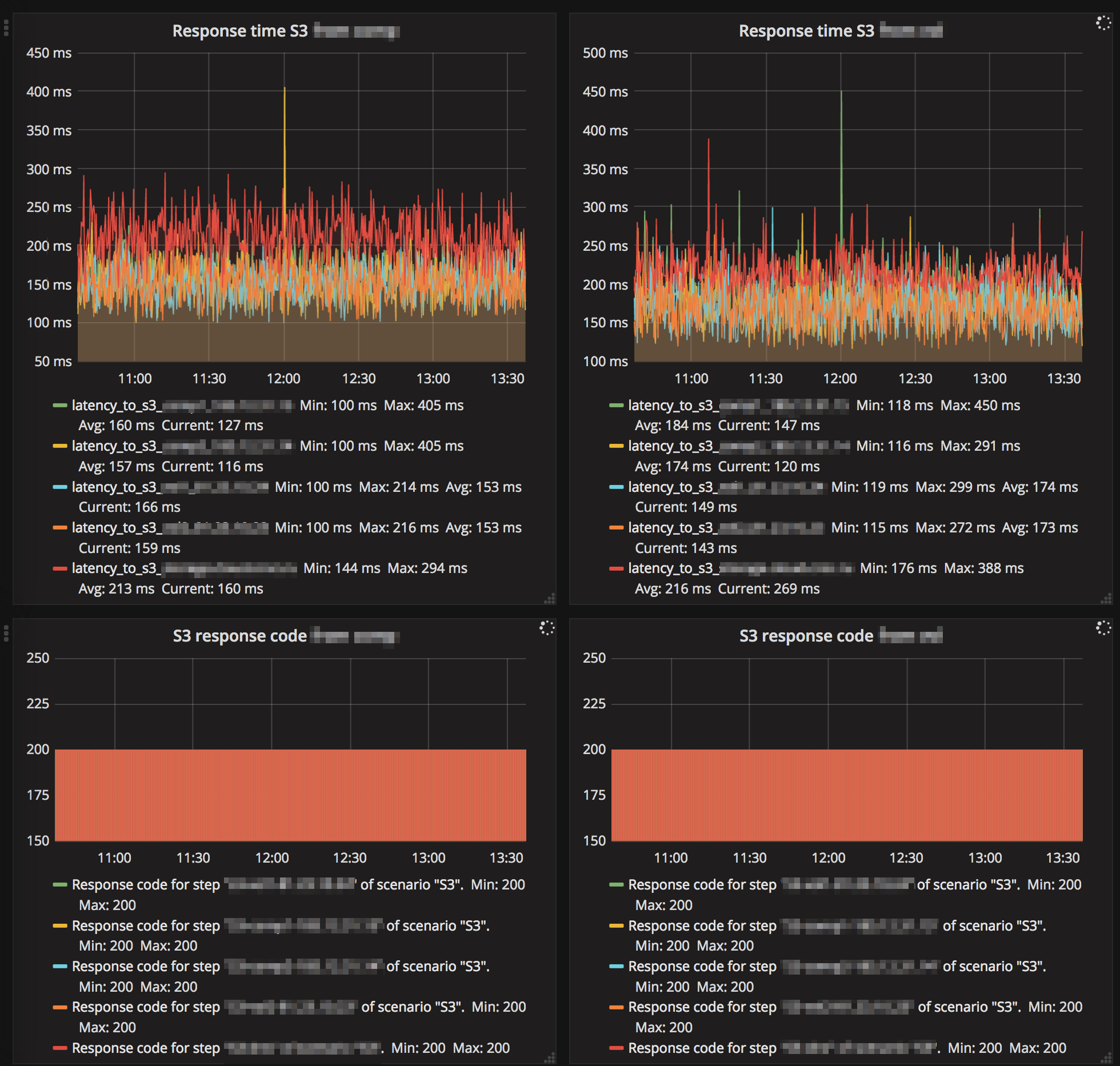
Ceph , , , , .
, eph Graylog GELF . , , OSD down, out, failed . , , OSD down , .
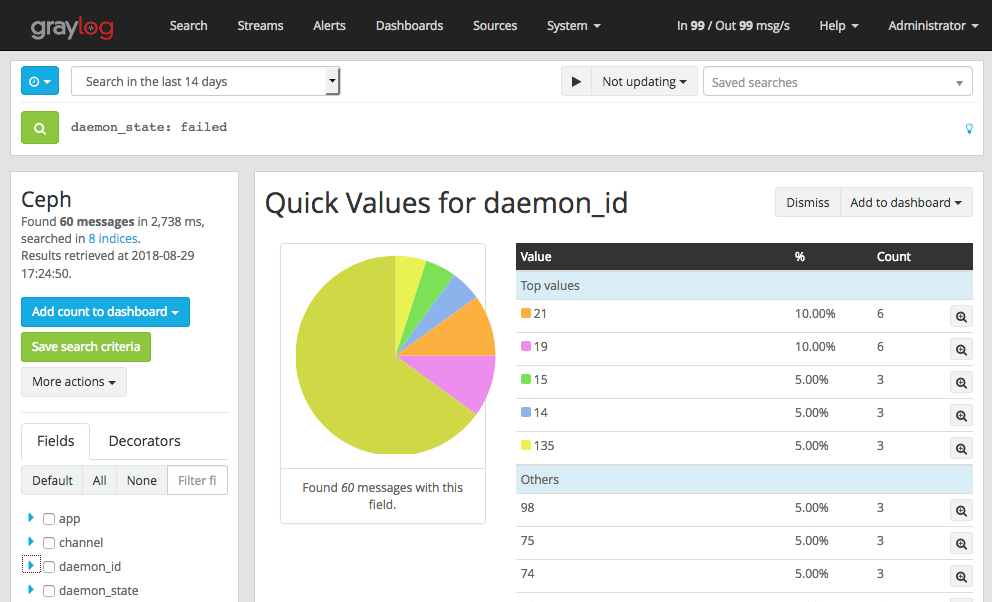
- , OSD heartbeat failed (. ). vm.zone_reclaim_mode=1 NUMA.
Ceph. c vxFlex . :
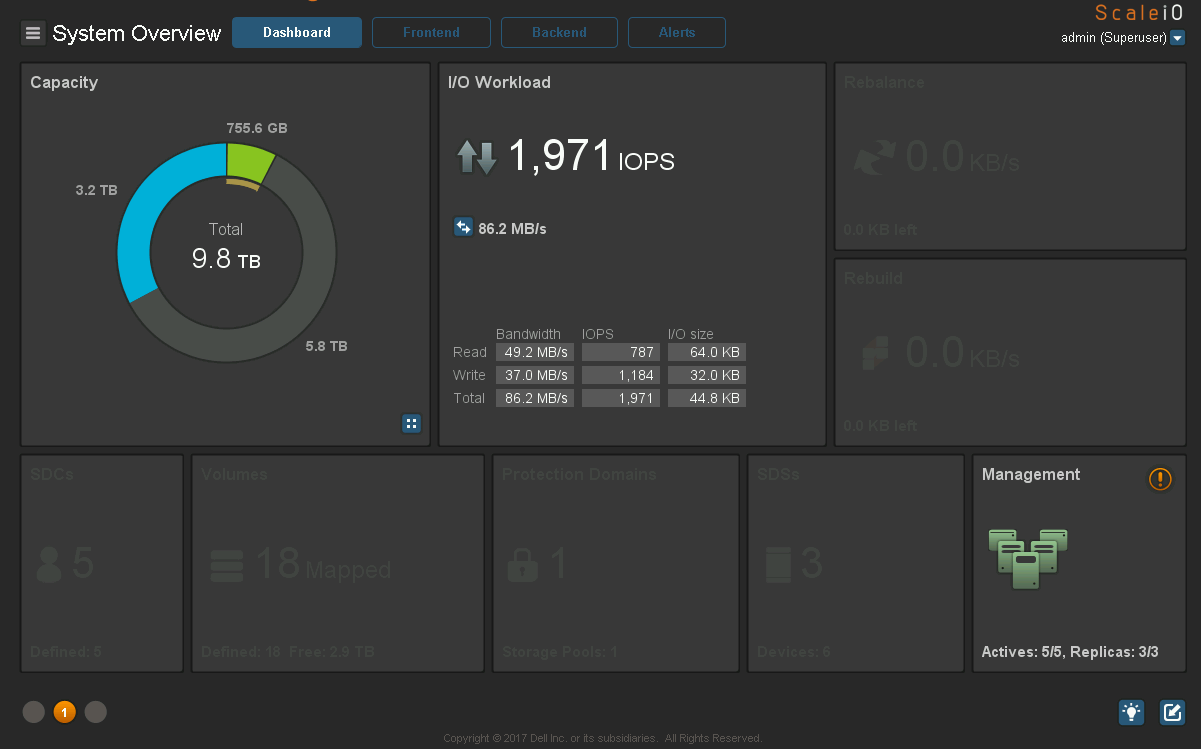
:

IO :
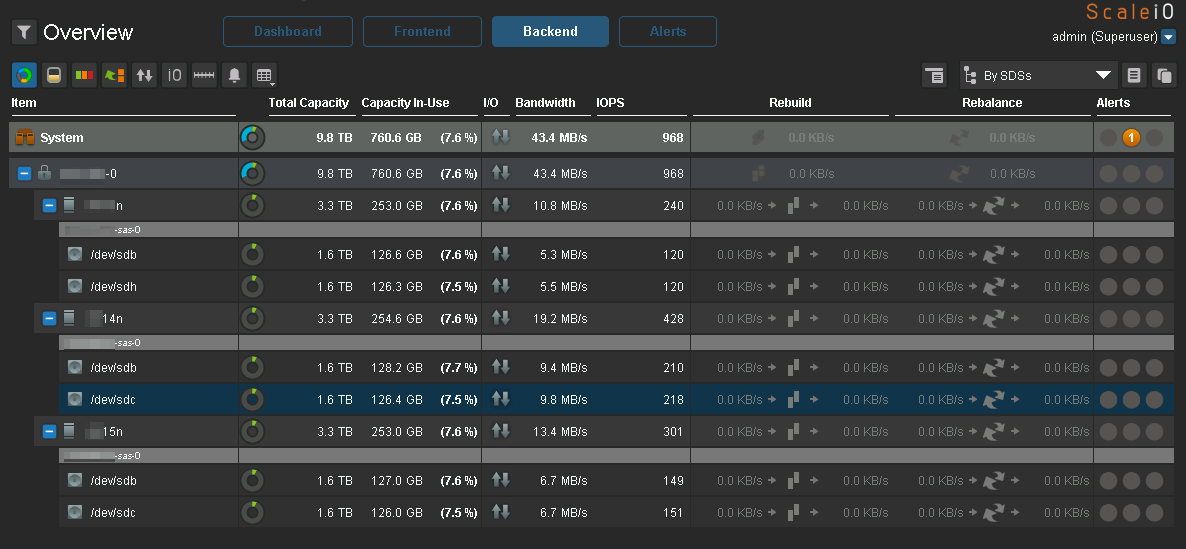
IO, Ceph.
:
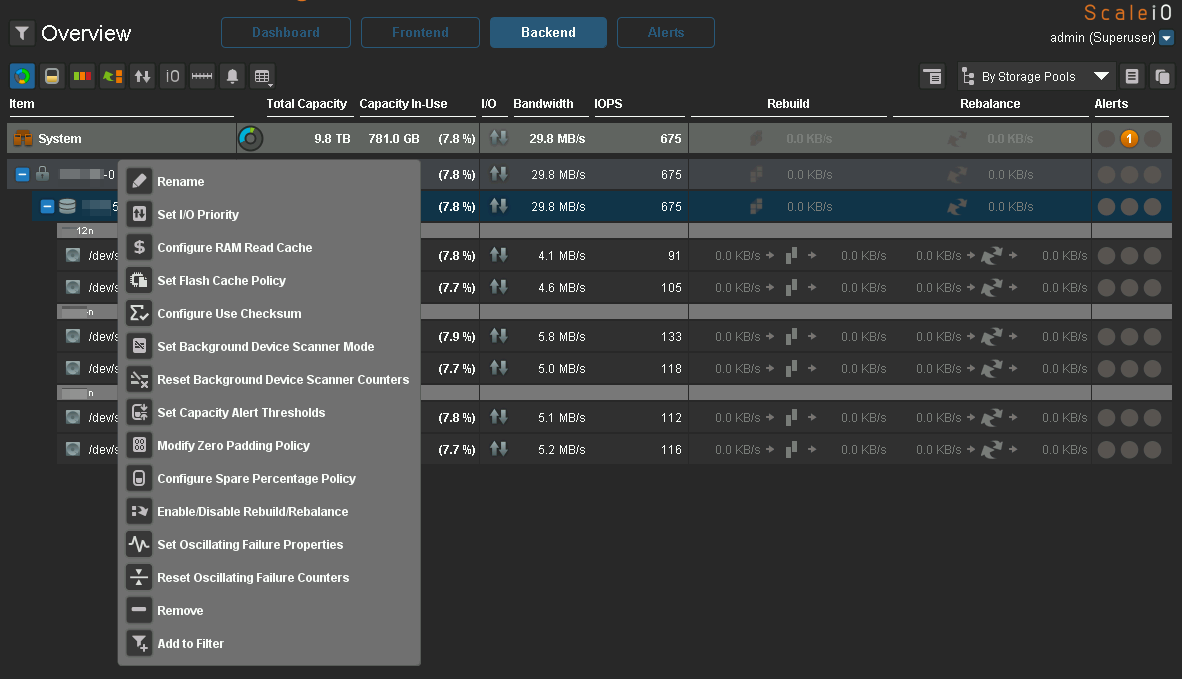
Ceph, Luminous . 2.0, Mimic , .
vxFlex
Degraded state , .
vxFlex — RH . 7.5 , . Ceph RBD cephfs — .
vxFlex Ceph. vxFlex — , , , .
16 PB, . eph 2 PB …
Fazit
, Ceph , , , Ceph — . .
, Ceph " ". , " , , R&D, - ". . " ", Ceph , , .
Ceph 2k18 , . 24/7 ( S3, , EBS), , Ceph . , . — . / maintenance backfilling , c Ceph , , .
Ceph ? , " ". Ceph. . , , , , …
!
HEALTH_OK!