Das Konzept des Lazy Computing ist es kaum wert, ausführlich besprochen zu werden. Die Idee, dasselbe seltener zu tun, besonders wenn es lang und schwer ist, ist so alt wie die Welt. Denn sofort auf den Punkt.
Laut dem Autor dieses Textes sollte ein normaler Kreditgeber:
- Speichern Sie Berechnungen zwischen Programmaufrufen.
- Verfolgen Sie Änderungen im Berechnungsbaum.
- Mäßig transparente Syntax haben.

Konzept
In der Reihenfolge:
- Speichern Sie Berechnungen zwischen Programmaufrufen:
Wenn wir dasselbe Skript mehrere zehnhundert Mal am Tag aufrufen, warum sollten wir es dann bei jedem Aufruf des Skripts neu berechnen, wenn es möglich ist, das Ergebnisobjekt in einer Datei zu speichern? Es ist besser, ein Objekt von der Festplatte zu ziehen, aber ... wir müssen uns seiner Relevanz sicher sein. Plötzlich wird das Skript neu geschrieben und das gespeicherte Objekt ist veraltet. Auf dieser Grundlage können wir das Objekt nicht einfach laden, wenn eine Datei vorhanden ist. Daraus folgt der zweite Punkt. - Verfolgen Sie Änderungen im Berechnungsbaum:
Die Notwendigkeit, das Objekt zu aktualisieren, muss auf der Grundlage der Daten zu den Argumenten der Funktion berechnet werden, die es generiert. So werden wir sicher sein, dass das geladene Objekt gültig ist. In der Tat hängt der Rückgabewert für eine reine Funktion nur von den Argumenten ab. Dies bedeutet, dass wir, während wir die Ergebnisse reiner Funktionen zwischenspeichern und Änderungen in den Argumenten überwachen, über die Relevanz des Caches ruhig sein können. Wenn das berechnete Objekt von einem anderen zwischengespeicherten (faulen) Objekt abhängt, das wiederum von einem anderen abhängt, müssen Sie gleichzeitig die Änderungen in diesen Objekten korrekt ausarbeiten und die nicht mehr relevanten Kettenknoten rechtzeitig aktualisieren. Andererseits wäre es schön zu berücksichtigen, dass wir nicht immer die Daten der gesamten Berechnungskette laden müssen. Oft reicht es aus, nur das Endergebnisobjekt zu laden. - Mäßig transparente Syntax haben:
Dieser Punkt ist klar. Wenn es erforderlich ist, den gesamten Code zu ändern, um das Skript in verzögerte Berechnungen umzuschreiben, ist dies eine mittelmäßige Lösung. Änderungen sollten auf ein Minimum vorgenommen werden.
Diese Argumentation führte zu einer technischen Lösung in der Python-Evalcache-Bibliothek (Links am Ende des Artikels).
Syntaxlösung und Arbeitsmechanismus
Einfaches Beispielimport evalcache import hashlib import shelve lazy = evalcache.Lazy(cache = shelve.open(".cache"), algo = hashlib.sha256) @lazy def summ(a,b,c): return a + b + c @lazy def sqr(a): return a * a a = 1 b = sqr(2) c = lazy(3) lazyresult = summ(a, b, c) result = lazyresult.unlazy() print(lazyresult)
Wie funktioniert es
Das erste, was hier auffällt, ist die Kreation des faulen Dekorateurs. Eine solche syntaktische Lösung ist für Python-Pythons ziemlich Standard. Dem Lazy Decorator wird ein Cache-Objekt übergeben, in dem der Lenificator die Ergebnisse der Berechnungen speichert. Die Anforderungen der diktartigen Schnittstelle werden dem Cache-Typ überlagert. Mit anderen Worten, wir können alles zwischenspeichern, was dieselbe Schnittstelle wie der Diktattyp implementiert. Um das obige Beispiel zu demonstrieren, haben wir das Wörterbuch aus der Regalbibliothek verwendet.
Der Dekorateur erhält außerdem ein Hash-Protokoll, mit dem er Hash-Schlüssel für Objekte erstellt, sowie einige zusätzliche Optionen (Schreibberechtigung, Leseberechtigung, Debug-Ausgabe), die in der Dokumentation oder im Code enthalten sind.
Der Dekorator kann sowohl auf Funktionen als auch auf Objekte anderer Typen angewendet werden. In diesem Moment wird ein faules Objekt auf seiner Basis mit einem Hash-Schlüssel erstellt, der auf der Basis der Darstellung berechnet wird (oder eine speziell für diesen Funktionstyp definierte Hash-Funktion verwendet).
Ein Schlüsselmerkmal der Bibliothek ist, dass ein Lazy-Objekt andere Lazy-Objekte erzeugen kann und der Hash des Elternteils (oder der Eltern) in den Hash-Schlüssel des Nachkommen gemischt wird. Bei faulen Objekten sind die Verwendung der Operation zum Aufnehmen eines Attributs, die Verwendung von Aufrufen ( __call__ ) von Objekten und die Verwendung von Operatoren zulässig.
Beim Durchlaufen eines Skripts werden tatsächlich keine Berechnungen durchgeführt. Für b wird das Quadrat nicht berechnet, und für Lazyresult wird die Summe der Argumente nicht berücksichtigt. Stattdessen wird ein Baum von Operationen erstellt und Hash-Schlüssel von faulen Objekten werden berechnet.
Echte Berechnungen (wenn das Ergebnis zuvor nicht in den Cache gestellt wurde) werden nur in der folgenden Zeile ausgeführt: result = lazyresult.unlazy()
Wenn das Objekt zuvor berechnet wurde, wird es aus der Datei geladen.
Sie können den Build-Baum visualisieren:
Erstellen Sie eine Baumvisualisierung evalcache.print_tree(lazyresult) ... generic: <function summ at 0x7f1cfc0d5048> args: 1 generic: <function sqr at 0x7f1cf9af29d8> args: 2 ------- 3 -------
Da die Hashes von Objekten auf der Grundlage der Daten zu den Argumenten erstellt werden, die diese Objekte generieren, ändert sich bei einer Änderung des Arguments der Hash des Objekts und damit die Hashes der gesamten Kette. Auf diese Weise können Sie die Cache-Daten auf dem neuesten Stand halten, indem Sie Aktualisierungen rechtzeitig vornehmen.
Faule Objekte reihen sich in einem Baum aneinander. Wenn wir eine nicht verzögerte Operation für eines der Objekte ausführen, werden genau so viele Objekte geladen und gezählt, wie erforderlich, um ein gültiges Ergebnis zu erhalten. Im Idealfall wird das erforderliche Objekt einfach geladen. In diesem Fall zieht der Algorithmus keine sich bildenden Objekte in den Speicher.
In Aktion
Oben war ein einfaches Beispiel, das die Syntax zeigt, aber nicht die Rechenleistung des Ansatzes demonstriert.
Hier ist ein Beispiel, das dem wirklichen Leben etwas näher kommt (von Sympy verwendet).
Beispiel mit Sympy und Numpy Operationen zur Vereinfachung symbolischer Ausdrücke sind äußerst kostspielig und erfordern buchstäblich eine Lenifizierung. Der weitere Aufbau eines großen Arrays dauert noch länger, aber dank der Lenifizierung werden die Ergebnisse aus dem Cache abgerufen. Beachten Sie, dass, wenn Koeffizienten am oberen Rand des Skripts geändert werden, in dem der Sympy-Ausdruck generiert wird, die Ergebnisse neu berechnet werden, da sich der Hash-Schlüssel des Lazy-Objekts ändert (dank der coolen __repr__ Anweisungen).
Sehr oft tritt eine Situation auf, wenn ein Forscher Computerexperimente an einem lang erzeugten Objekt durchführt. Es kann mehrere Skripte verwenden, um die Generierung und Verwendung des Objekts zu trennen, was zu Problemen bei der vorzeitigen Aktualisierung von Daten führen kann. Der vorgeschlagene Ansatz kann diesen Fall erleichtern.
Worum geht es?
evalcache ist Teil des zencad-Projekts. Dies ist ein kleines Skript, das inspiriert ist und die gleichen Ideen wie openscad nutzt. Im Gegensatz zu netzorientiertem OpenScad verwendet ZenCad, das auf dem OpenCascade-Kern ausgeführt wird, eine Brep-Darstellung von Objekten, und Skripte werden in Python geschrieben.
Geometrische Operationen werden oft über einen langen Zeitraum durchgeführt. Der Nachteil von CAD-Skriptsystemen besteht darin, dass jedes Mal, wenn Sie das Skript ausführen, das Produkt erneut vollständig nachgezählt wird. Darüber hinaus steigen mit dem Wachstum und der Komplikation des Modells die Gemeinkosten nicht linear. Dies führt dazu, dass Sie nur mit extrem kleinen Modellen bequem arbeiten können.
Die Aufgabe von evalcache war es, dieses Problem zu beheben. In Zencad werden alle Operationen als faul deklariert.
Beispiele:
Beispiel für einen Modellbau
Dieses Skript generiert das folgende Modell:
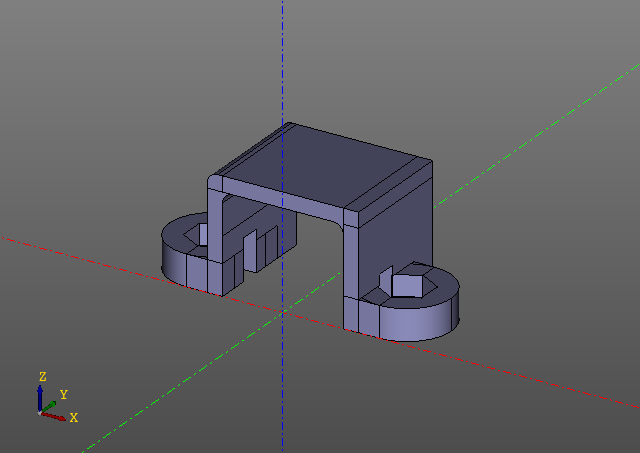
Beachten Sie, dass das Skript keine Evalcache-Aufrufe enthält. Der Trick besteht darin, dass die Lenifizierung in die Zencad-Bibliothek selbst eingebettet ist und auf den ersten Blick nicht einmal sichtbar ist, obwohl die gesamte Arbeit hier mit faulen Objekten arbeitet und die direkte Berechnung nur in der Anzeigefunktion durchgeführt wird. Wenn ein Modellparameter geändert wird, wird das Modell natürlich an der Stelle nachgezählt, an der sich der erste Hash-Schlüssel geändert hat.
Sperrige ComputermodelleHier ist ein weiteres Beispiel. Dieses Mal beschränken wir uns auf Bilder:
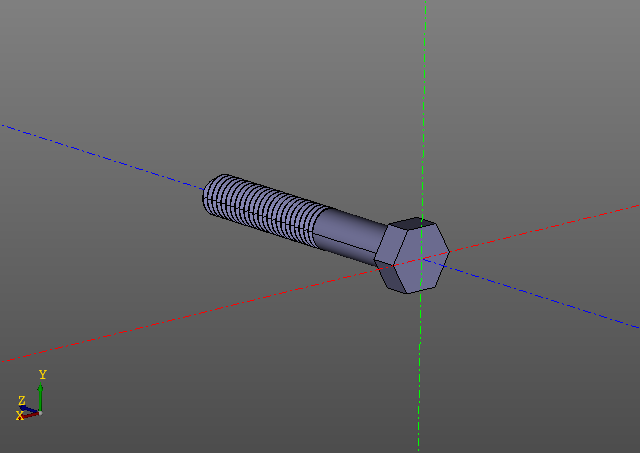
Die Berechnung einer Gewindefläche ist keine leichte Aufgabe. Auf meinem Computer wird eine solche Schraube in der Größenordnung von zehn Sekunden erstellt ... Das Bearbeiten eines Modells mit Gewinden ist mithilfe des Caching viel angenehmer.
Und jetzt ist das ein Wunder:

Das Überqueren von Gewindeflächen ist eine komplexe Rechenaufgabe. Praktischer Wert ist jedoch nichts anderes als die Überprüfung der Mathematik. Die Berechnung dauert anderthalb Minuten. Ein würdiges Ziel für die Lenifizierung.
Die Probleme
Der Cache funktioniert möglicherweise nicht wie beabsichtigt.
Cache-Fehler können in falsch positive und falsch negative unterteilt werden .
Falsch negative Fehler
Falsch negative Fehler sind Situationen, in denen sich das Ergebnis der Berechnung im Cache befindet, das System es jedoch nicht gefunden hat.
Dies geschieht, wenn der von evalcache aus irgendeinem Grund verwendete Hash-Schlüssel-Algorithmus einen anderen Schlüssel für die Neuberechnung erzeugt hat. Wenn die Hash-Funktion für das Objekt des zwischengespeicherten Typs nicht überschrieben wird, verwendet evalcache das __repr__ Objekts, um den Schlüssel zu __repr__ .
Ein Fehler tritt beispielsweise auf, wenn die geleaste Klasse das Standardobjekt object.__repr__ , das sich von Anfang zu Start ändert, nicht überschreibt. Oder wenn das überschriebene __repr__ irgendwie für die Berechnung der sich ändernden Daten unbedeutend ist (wie die Adresse des Objekts oder der Zeitstempel).
Schlecht:
class A: def __init__(self): self.i = 3 A_lazy = lazy(A) A_lazy().unlazy()
Gut:
class A: def __init__(self): self.i = 3 def __repr__(self): return "A({})".format(self.i) A_lazy = lazy(A) A_lazy().unlazy()
Falsch negative Fehler führen dazu, dass die Lenifizierung nicht funktioniert. Das Objekt wird bei jeder neuen Skriptausführung neu gezählt.
Falsch positive Fehler
Dies ist eine abscheulichere Art von Fehler, da dies zu Fehlern im endgültigen Berechnungsobjekt führt:
Dies kann aus zwei Gründen geschehen.
- Unglaublich:
Im Cache ist eine Hash-Schlüsselkollision aufgetreten. Für den sha256-Algorithmus mit einem Leerzeichen von 115792089237316195423570985008687907853269984665640564039457584007913129639936 ist die Wahrscheinlichkeit einer Kollision vernachlässigbar. - Wahrscheinlich:
Eine Darstellung eines Objekts (oder einer überschriebenen Hash-Funktion) beschreibt es nicht vollständig oder stimmt mit einer Darstellung eines Objekts eines anderen Typs überein.
class A: def __init__(self): self.i = 3 def __repr__(self): return "({})".format(self.i) class B: def __init__(self): self.i = 3 def __repr__(self): return "({})".format(self.i) A_lazy = lazy(A) B_lazy = lazy(B) a = A_lazy().unlazy() b = B_lazy().unlazy()
Beide Probleme hängen mit einem inkompatiblen __repr__ -Objekt zusammen. Wenn es aus irgendeinem Grund nicht möglich ist, den __repr__ zu überschreiben, können Sie in der Bibliothek eine spezielle Hash-Funktion für den Benutzertyp festlegen.
Über Analoga
Es gibt viele Lenifizierungsbibliotheken, die es grundsätzlich für ausreichend halten, eine Berechnung nicht mehr als einmal pro Skriptaufruf auszuführen.
Es gibt viele Disk-Caching-Bibliotheken, die auf Ihre Anfrage ein Objekt mit dem für Sie erforderlichen Schlüssel speichern.
Aber ich konnte immer noch keine Bibliotheken finden, die das Zwischenspeichern von Ergebnissen im Ausführungsbaum ermöglichen würden. Wenn es welche gibt, bitte unsicher.
Referenzen:
Github-Projekt
Pypi-Projekt