Dieser Artikel konzentriert sich auf den Lastenausgleich in Webprojekten. Viele glauben, dass die Lösung für dieses Problem in der Lastverteilung zwischen den Servern - je genauer, desto besser. Aber wir wissen, dass dies nicht ganz stimmt.
Die Stabilität des Systems ist aus geschäftlicher Sicht viel wichtiger .
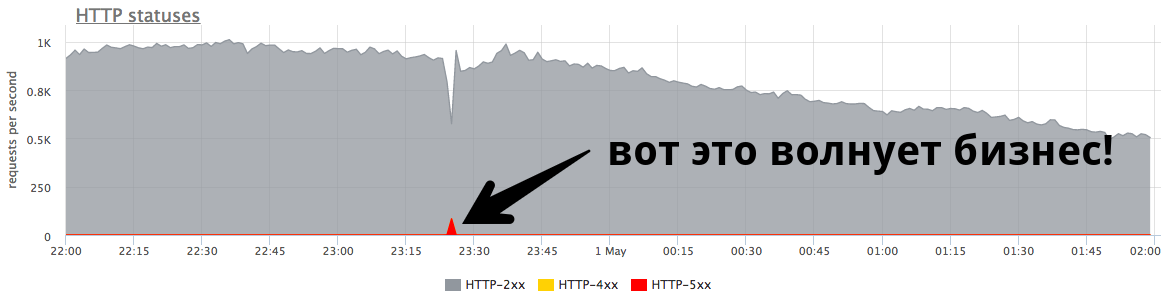
Der kleine Minutenpeak bei 84 U / min von „fünfhundert“ sind fünftausend Fehler, die echte Benutzer erhalten haben. Das ist viel und sehr wichtig. Es ist notwendig, nach Gründen zu suchen, Fehler zu bearbeiten und weiterhin solche Situationen zu verhindern.
Nikolay Sivko (
NikolaySivko ) sprach in seinem Bericht über RootConf 2018 über die subtilen und noch nicht sehr beliebten Aspekte des Lastausgleichs:
- wann die Anfrage zu wiederholen ist (Wiederholungsversuche);
- wie man Werte für Zeitüberschreitungen auswählt;
- wie man die zugrunde liegenden Server zum Zeitpunkt des Unfalls / der Überlastung nicht tötet;
- ob Gesundheitschecks erforderlich sind;
- wie man mit flackernden Problemen umgeht.
Unter Katzendecodierung dieses Berichts.
Über den Sprecher: Nikolay Sivko Mitbegründer von okmeter.io. Er arbeitete als Systemadministrator und Leiter einer Gruppe von Administratoren. Überwachter Betrieb bei hh.ru. Er gründete den Überwachungsdienst okmeter.io. Im Rahmen dieses Berichts ist die Überwachung der Entwicklungserfahrung die Hauptursache für Fälle.
Worüber werden wir reden?
Dieser Artikel befasst sich mit Webprojekten. Unten sehen Sie ein Beispiel für eine Live-Produktion: Die Grafik zeigt Anforderungen pro Sekunde für einen bestimmten Webdienst.
Wenn ich über das Balancieren spreche, nehmen viele es als "wir müssen die Last auf die Server verteilen - je genauer, desto besser".
In der Tat ist dies nicht ganz richtig. Dieses Problem ist für eine sehr kleine Anzahl von Unternehmen relevant. In den meisten Fällen sorgen sich Unternehmen um Fehler und Systemstabilität.
Der kleine Peak in der Grafik ist "fünfhundert", den der Server innerhalb einer Minute zurückgegeben und dann gestoppt hat. Aus Sicht eines Unternehmens wie eines Online-Shops beträgt dieser kleine Spitzenwert von 84 RPS von „fünfhundert“ für echte Benutzer 5040 Fehler. Einige haben etwas in Ihrem Katalog nicht gefunden, andere konnten die Waren nicht in den Warenkorb legen. Und das ist sehr wichtig. Obwohl dieser Peak auf dem Diagramm nicht sehr groß erscheint,
ist er bei echten Benutzern sehr häufig .
In der Regel hat jeder solche Spitzen, und Administratoren reagieren nicht immer darauf. Sehr oft, wenn ein Unternehmen fragt, was es ist, antworten sie ihm:
- "Dies ist ein kurzer Ausbruch!"
- "Es ist nur eine Veröffentlichung, die rollt."
- "Der Server ist tot, aber alles ist schon in Ordnung."
- "Vasya hat das Netzwerk eines der Backends gewechselt."
Oft
versuchen die Leute
nicht einmal, die Gründe dafür
zu verstehen , und machen keine Nacharbeiten, damit es nicht wieder passiert.
Feinabstimmung
Ich habe den Bericht „Feinabstimmung“ (Eng. Feinabstimmung) genannt, weil ich dachte, dass nicht jeder diese Aufgabe übernimmt, aber es lohnt sich. Warum kommen sie nicht dorthin?
- Nicht jeder kommt zu dieser Aufgabe, denn wenn alles funktioniert, ist es nicht sichtbar. Dies ist sehr wichtig für Probleme. Fakapa kommt nicht jeden Tag vor, und ein so kleines Problem erfordert sehr ernsthafte Anstrengungen, um es zu lösen.
- Sie müssen viel nachdenken. Sehr oft kann der Administrator - die Person, die das Gleichgewicht anpasst - dieses Problem nicht unabhängig lösen. Als nächstes werden wir sehen warum.
- Es fängt die zugrunde liegenden Ebenen. Diese Aufgabe ist sehr eng mit der Entwicklung verbunden, mit der Annahme von Entscheidungen, die Ihr Produkt und Ihre Benutzer betreffen.
Ich bestätige, dass es aus mehreren Gründen an der Zeit ist, diese Aufgabe zu erledigen:- Die Welt verändert sich, wird dynamischer, es gibt viele Veröffentlichungen. Sie sagen, dass es jetzt richtig ist, 100 Mal am Tag zu veröffentlichen, und die Veröffentlichung ist das zukünftige Fakap mit einer Wahrscheinlichkeit von 50 bis 50 (genau wie die Wahrscheinlichkeit, einen Dinosaurier zu treffen).
- Auch aus technologischer Sicht ist alles sehr dynamisch. Kubernetes und andere Orchestratoren erschienen. Es gibt keine gute alte Bereitstellung, wenn ein Backend auf einer IP-Adresse deaktiviert ist, ein Update durchgeführt wird und der Dienst hochgefahren wird. Während des Rollouts in k8s ändert sich die Liste der IP-Upstreams vollständig.
- Microservices: Jetzt kommuniziert jeder über das Netzwerk, was bedeutet, dass Sie dies zuverlässig tun müssen. Das Balancieren spielt eine wichtige Rolle.
Prüfstand
Beginnen wir mit einfachen, offensichtlichen Fällen. Aus Gründen der Klarheit werde ich einen Prüfstand verwenden. Dies ist eine Golang-Anwendung, die http-200 gibt, oder Sie können sie in den Modus "http-503 geben" schalten.
Wir starten 3 Instanzen:
- 127.0.0.1:20001
- 127.0.0.1:20002
- 127.0.0.1:20003
Wir bedienen 100rps über yandex.tank über nginx.
Nginx aus der Box:
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; location / { proxy_pass http://backends; } }
Primitives Szenario
Schalten Sie irgendwann eines der Backends im Give 503-Modus ein, und wir erhalten genau ein Drittel der Fehler.
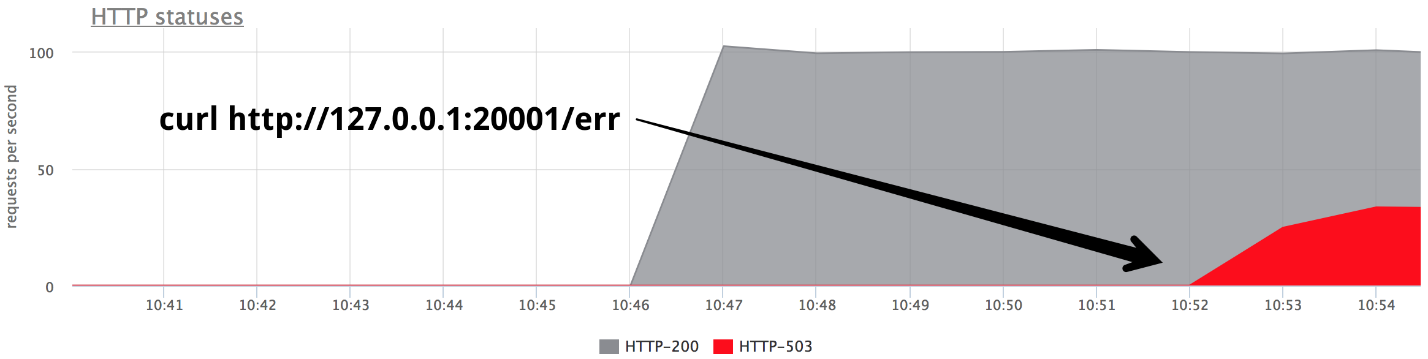
Es ist klar, dass nichts sofort funktioniert: nginx versucht es nicht sofort, wenn es
eine Antwort vom Server erhalten hat.
Nginx default: proxy_next_upstream error timeout;
Tatsächlich ist dies von Seiten der Nginx-Entwickler ziemlich logisch: nginx hat nicht das Recht, für Sie zu entscheiden, was Sie zurückziehen möchten und was nicht.
Dementsprechend brauchen wir Wiederholungsversuche - Wiederholungsversuche, und wir beginnen, darüber zu sprechen.
Wiederholungen
Es ist notwendig, einen Kompromiss zu finden zwischen:
- Die Benutzeranfrage ist heilig, verletzt werden, aber antworten. Wir wollen dem Benutzer um jeden Preis antworten, der Benutzer ist der wichtigste.
- Besser mit einem Fehler antworten als die Server überlasten.
- Datenintegrität (für nicht idempotente Anforderungen), d. H. Es ist unmöglich, bestimmte Arten von Anforderungen zu wiederholen.
Die Wahrheit liegt wie immer irgendwo dazwischen - wir sind gezwungen, zwischen diesen drei Punkten zu balancieren. Versuchen wir zu verstehen, was und wie.
Ich habe die fehlgeschlagenen Versuche in drei Kategorien unterteilt:
1.
TransportfehlerFür den HTTP-Transport handelt es sich um TCP. In der Regel werden hier Fehler beim Verbindungsaufbau und Zeitüberschreitungen beim Verbindungsaufbau behandelt. In meinem Bericht werde ich drei gängige Balancer erwähnen (wir werden etwas weiter über Envoy sprechen):
- nginx : Fehler + Timeout (proxy_connect_timeout);
- HAProxy : Timeout-Verbindung;
- Gesandter : Verbindungsfehler + abgelehnter Stream.
Nginx hat die Möglichkeit zu sagen, dass ein fehlgeschlagener Versuch ein Verbindungsfehler und ein Verbindungszeitlimit ist. HAProxy hat ein Verbindungszeitlimit, Envoy hat auch alles Standard und Normal.
2.
Timeout anfordern:Angenommen, wir haben eine Anfrage an den Server gesendet, der erfolgreich mit ihm verbunden ist, aber die Antwort kommt nicht zu uns. Wir haben darauf gewartet und verstehen, dass es keinen Sinn mehr macht, länger zu warten. Dies wird als Anforderungszeitlimit bezeichnet:
- Nginx hat: timeout (prox_send_timeout * + proxy_read_timeout *);
- HAProxy hat OOPS :( - es existiert im Prinzip nicht. Viele Leute wissen nicht, dass HAProxy, wenn es erfolgreich eine Verbindung hergestellt hat, niemals versuchen wird, die Anfrage erneut zu senden.
- Gesandter kann alles: Timeout || per_try_timeout.
3.
HTTP-StatusAlle Balancer mit Ausnahme von HAProxy können verarbeiten, wenn das Backend Ihnen dennoch geantwortet hat, jedoch mit einem fehlerhaften Code.
- nginx : http_ *
- HAProxy : OOPS :(
- Gesandter : 5xx, Gateway-Fehler (502, 503, 504), retriable-4xx (409)
Zeitüberschreitungen
Lassen Sie uns nun ausführlich über Timeouts sprechen. Es scheint mir, dass es sich lohnt, darauf zu achten. Es wird keine weitere Raketenwissenschaft geben - dies sind einfach strukturierte Informationen darüber, was im Allgemeinen passiert und wie es damit zusammenhängt.
Zeitüberschreitung verbinden
Das Verbindungszeitlimit ist die Zeit zum Herstellen einer Verbindung. Dies ist ein Merkmal Ihres Netzwerks und Ihres spezifischen Servers und hängt nicht von der Anforderung ab. Normalerweise ist der Standardwert für das Verbindungszeitlimit auf klein festgelegt. In allen Proxys ist der Standardwert groß genug, und dies ist falsch - es sollten
Einheiten sein, manchmal mehrere zehn Millisekunden (wenn es sich um ein Netzwerk innerhalb eines DC handelt).
Wenn Sie problematische Server etwas schneller als diese Einheiten identifizieren möchten - zig Millisekunden -, können Sie die Last im Backend anpassen, indem Sie einen kleinen Rückstand für den Empfang von TCP-Verbindungen festlegen. In diesem Fall können Sie Linux anweisen, es zurückzusetzen, wenn das Backlog der Anwendung voll ist, um das Backlog zu überlaufen. Dann können Sie das "schlechte" überlastete Backend etwas früher als das Verbindungszeitlimit aufnehmen:
fail fast: listen backlog + net.ipv4.tcp_abort_on_overflow
Timeout anfordern
Das Anforderungszeitlimit ist kein Netzwerkmerkmal, sondern ein
Merkmal einer Gruppe von Anforderungen (Handler). Es gibt unterschiedliche Anforderungen - sie haben einen unterschiedlichen Schweregrad, eine völlig andere Logik und müssen auf völlig unterschiedliche Repositorys zugreifen.
Nginx selbst
hat keine Zeitüberschreitung für die gesamte Anfrage. Er hat:
- proxy_send_timeout: Zeit zwischen zwei erfolgreichen Schreibvorgängen write ();
- proxy_read_timeout: Zeit zwischen zwei erfolgreichen Lesevorgängen ().
Das heißt, wenn Sie ein Backend langsam haben, ein Byte mal, gibt etwas in einer Zeitüberschreitung, dann ist alles in Ordnung. Daher verfügt nginx nicht über request_timeout. Aber wir sprechen über Upstream. In unserem Rechenzentrum werden sie daher von uns gesteuert. Unter der Annahme, dass das Netzwerk keine langsame Loris hat, kann read_timeout im Prinzip als request_timeout verwendet werden.
Der Gesandte hat alles: Timeout || per_try_timeout.
Wählen Sie das Anforderungszeitlimit
Jetzt ist meiner Meinung nach das Wichtigste, welches request_timeout zu setzen ist. Wir gehen davon aus, wie viel der Benutzer warten darf - dies ist ein bestimmtes Maximum. Es ist klar, dass der Benutzer nicht länger als 10 Sekunden warten wird, daher müssen Sie ihm schneller antworten.
- Wenn wir den Ausfall eines einzelnen Servers behandeln möchten, sollte das Zeitlimit geringer sein als das maximal zulässige Zeitlimit: request_timeout <max.
- Wenn Sie zwei garantierte Versuche haben möchten, eine Anforderung an zwei verschiedene Backends zu senden, entspricht das Zeitlimit für einen Versuch der Hälfte dieses zulässigen Intervalls: per_try_timeout = 0,5 * max.
- Es gibt auch eine Zwischenoption - 2 optimistische Versuche, falls das erste Backend "abgestumpft" ist, das zweite jedoch schnell reagiert: per_try_timeout = k * max (wobei k> 0,5).
Es gibt verschiedene Ansätze, aber im Allgemeinen ist die
Auswahl eines Timeouts schwierig . Es wird immer Grenzfälle geben, zum Beispiel wird der gleiche Handler in 99% der Fälle in 10 ms verarbeitet, aber es gibt 1% der Fälle, in denen wir auf 500 ms warten, und dies ist normal. Dies muss gelöst werden.
Mit diesen 1% muss etwas getan werden, da beispielsweise die gesamte Gruppe von Anforderungen dem SLA entsprechen und in 100 ms passen sollte. Sehr oft wird in diesen Momenten der Antrag bearbeitet:
- Paging wird an Stellen angezeigt, an denen es nicht möglich ist, alle Daten in einem Timeout zurückzugeben.
- Die Administratoren / Berichte werden in eine separate Gruppe von URLs unterteilt, um das Zeitlimit für sie zu erhöhen und um Benutzeranforderungen zu verringern.
- Wir reparieren / optimieren diejenigen Anforderungen, die nicht in unser Timeout passen.
Sofort müssen wir eine Entscheidung treffen, die aus psychologischer Sicht nicht sehr einfach ist. Wenn wir in der vorgegebenen Zeit keine Zeit haben, dem Benutzer zu antworten, geben wir einen Fehler (dies ist wie in einem alten chinesischen Sprichwort: „Wenn die Stute tot ist, steigen Sie aus!“)
.Danach wird die Überwachung Ihres Dienstes aus Sicht des Benutzers vereinfacht:
- Wenn es Fehler gibt, ist alles schlecht, es muss behoben werden.
- Wenn es keine Fehler gibt, passen wir in die richtige Reaktionszeit, dann ist alles in Ordnung.
Spekulative Wiederholungen # nifig
Wir haben dafür gesorgt, dass die Auswahl eines Timeout-Werts ziemlich schwierig ist. Wie Sie wissen, müssen Sie etwas komplizieren, um etwas zu vereinfachen :)
Spekulatives Retray - eine wiederholte Anforderung an einen anderen Server, die unter bestimmten Bedingungen gestartet wird, die erste Anforderung jedoch nicht unterbrochen wird. Wir nehmen die Antwort von dem Server, der schneller geantwortet hat.
Ich habe diese Funktion bei mir bekannten Balancern nicht gesehen, aber es gibt ein hervorragendes Beispiel für Cassandra (schneller Leseschutz):
speculative_retry = N ms |
M- ten PerzentilAuf diese Weise müssen Sie
keine Auszeit nehmen . Sie können es auf einem akzeptablen Niveau belassen und in jedem Fall einen zweiten Versuch unternehmen, eine Antwort auf die Anfrage zu erhalten.
Cassandra hat eine interessante Gelegenheit, eine statische spekulative Wiederholung oder Dynamik festzulegen. Dann wird der zweite Versuch über das Perzentil der Antwortzeit unternommen. Cassandra sammelt Statistiken über die Antwortzeiten früherer Anfragen und passt einen bestimmten Zeitlimitwert an. Das funktioniert ziemlich gut.
Bei diesem Ansatz beruht alles auf dem Gleichgewicht zwischen Zuverlässigkeit und Störlast. Nicht auf Servern. Sie bieten Zuverlässigkeit, aber manchmal erhalten Sie zusätzliche Anforderungen an den Server. Wenn Sie es irgendwo eilig hatten und eine zweite Anfrage gesendet haben, die erste jedoch noch beantwortet wurde, hat der Server etwas mehr Last erhalten. In einem Einzelfall ist dies ein kleines Problem.

Timeout-Konsistenz ist ein weiterer wichtiger Aspekt. Wir werden mehr über das Abbrechen von Anforderungen sprechen. Wenn das Zeitlimit für die gesamte Benutzeranforderung jedoch 100 ms beträgt, ist es im Allgemeinen nicht sinnvoll, das Zeitlimit für die Anforderung in der Datenbank auf 1 s festzulegen. Es gibt Systeme, mit denen Sie dies dynamisch tun können: Service zu Service überträgt den Rest der Zeit, die Sie auf eine Antwort auf diese Anfrage warten. Es ist kompliziert, aber wenn Sie es plötzlich brauchen, können Sie leicht herausfinden, wie es im selben Gesandten gemacht wird.
Was müssen Sie noch über Wiederholungsversuche wissen?
Punkt ohne Rückkehr (V1)
Hier ist V1 nicht Version 1. In der Luftfahrt gibt es ein solches Konzept - Geschwindigkeit V1. Dies ist die Geschwindigkeit, nach der es unmöglich ist, die Beschleunigung auf der Landebahn zu verlangsamen. Es ist notwendig, abzuheben und dann eine Entscheidung darüber zu treffen, was als nächstes zu tun ist.
Der gleiche Punkt ohne Rückgabe befindet sich in den Load Balancern:
Wenn Sie 1 Byte der Antwort an Ihren Client übergeben haben, können keine Fehler behoben werden . Wenn das Backend zu diesem Zeitpunkt stirbt, helfen keine erneuten Versuche. Sie können nur die Wahrscheinlichkeit verringern, dass ein solches Szenario ausgelöst wird, ein ordnungsgemäßes Herunterfahren durchführen, dh Ihrer Anwendung mitteilen: „Sie akzeptieren jetzt keine neuen Anforderungen, sondern ändern die alten!“ Und löschen sie erst dann.
Wenn Sie den Client steuern, handelt es sich um eine knifflige Ajax- oder mobile Anwendung. Möglicherweise wird versucht, die Anforderung zu wiederholen, und Sie können aus dieser Situation herauskommen.
Punkt ohne Wiederkehr [Gesandter]
Der Gesandte hatte so einen seltsamen Trick. Es gibt per_try_timeout - es begrenzt, wie viel jeder Versuch, eine Antwort auf eine Anfrage zu erhalten, dauern kann. Wenn dieses Timeout funktioniert hat, das Backend jedoch bereits auf den Client reagiert, wurde alles unterbrochen und der Client hat einen Fehler erhalten.
Mein Kollege Pavel Trukhanov (
tru_pablo ) hat einen
Patch erstellt , der sich bereits in Master Envoy befindet und in 1.7 enthalten sein wird. Jetzt funktioniert es wie es sollte: Wenn die Antwort übertragen wurde, funktioniert nur das globale Timeout.
Wiederholungen: müssen begrenzt werden
Wiederholungen sind gut, aber es gibt sogenannte Killer-Anfragen: Schwere Abfragen, die sehr komplexe Logik ausführen, greifen häufig auf die Datenbank zu und passen oft nicht zu per_try_timeout. Wenn wir immer wieder einen Wiederholungsversuch senden, töten wir unsere Basis. Da
in den meisten Datenbankdiensten (99,9%) keine Stornierung von Anforderungen erfolgt .
Die Stornierung von Anfragen bedeutet, dass der Client den Haken gelöst hat. Sie müssen sofort alle Arbeiten einstellen. Golang fördert diesen Ansatz aktiv, endet jedoch leider mit einem Backend, und viele Datenbank-Repositorys unterstützen dies nicht.
Dementsprechend müssen die Wiederholungsversuche begrenzt werden, was fast alle Balancer zulässt (wir denken ab sofort nicht mehr über HAProxy nach).
Nginx:- proxy_next_upstream_timeout (global)
- proxt_read_timeout ** als per_try_timeout
- proxy_next_upstream_tries
Gesandter:- Zeitüberschreitung (global)
- per_try_timeout
- num_retries
In Nginx können wir sagen, dass wir versuchen, Wiederholungen in Fenster X durchzuführen, dh in einem bestimmten Zeitintervall, beispielsweise 500 ms, werden so viele Wiederholungen durchgeführt, wie passen. Oder es gibt eine Einstellung, die die Anzahl der wiederholten Proben begrenzt. In
Envoy ist dies die gleiche Menge oder Zeitüberschreitung (global).
Wiederholungen: anwenden [nginx]
Betrachten Sie ein Beispiel: Wir setzen Wiederholungsversuche in Nginx 2 - dementsprechend versuchen wir nach Erhalt von HTTP 503 erneut, eine Anfrage an den Server zu senden. Schalten Sie dann die
beiden Backends aus.
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; proxy_next_upstream error timeout http_503; proxy_next_upstream_tries 2; location / { proxy_pass http://backends; } }
Unten sehen Sie die Grafiken unseres Prüfstands. Das obere Diagramm enthält keine Fehler, da nur sehr wenige vorhanden sind. Wenn Sie nur Fehler hinterlassen, ist klar, dass dies der Fall ist.
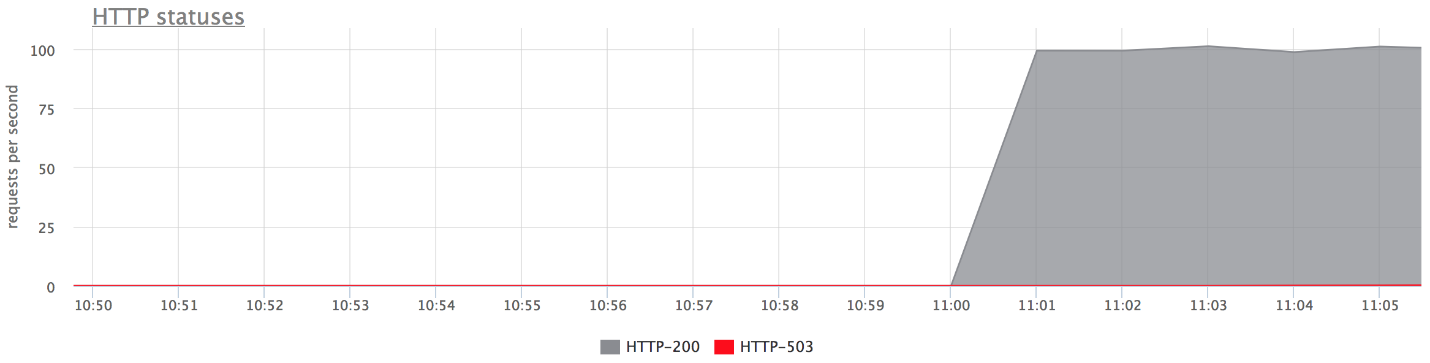
 Was ist passiert?
Was ist passiert?- proxy_next_upstream_tries = 2.
- Wenn Sie den ersten Versuch zum "toten" Server und den zweiten zum anderen "toten" machen, erhalten Sie HTTP-503, wenn beide Versuche zu den "schlechten" Servern unternommen werden.
- Es gibt nur wenige Fehler, da Nginx einen fehlerhaften Server "verbietet". Das heißt, wenn in nginx einige Fehler vom Backend zurückgekehrt sind, werden die folgenden Versuche zum Senden einer Anforderung an das Backend abgebrochen. Dies wird durch die Variable fail_timeout geregelt .
Aber es gibt Fehler, und das passt nicht zu uns.
Was tun?Wir können entweder die Anzahl der Wiederholungsversuche erhöhen (aber dann zum Problem der "Killer-Anfragen" zurückkehren) oder die Wahrscheinlichkeit verringern, dass eine Anfrage zu "toten" Backends gelangt. Dies kann mit
Gesundheitsprüfungen erfolgen.Gesundheitschecks
Ich schlage vor, Integritätsprüfungen als Optimierung des Auswahlprozesses für einen "Live" -Server zu betrachten.
Dies gibt in keiner Weise Garantien. Dementsprechend ist es wahrscheinlicher, dass wir während der Ausführung einer Benutzeranforderung nur "Live" -Server erreichen. Der Balancer greift regelmäßig auf eine bestimmte URL zu, der Server antwortet ihm: "Ich bin am Leben und bereit."
Gesundheitschecks: in Bezug auf das Backend
Aus der Sicht des Backends können Sie interessante Dinge tun:
- Überprüfen Sie die Betriebsbereitschaft aller zugrunde liegenden Subsysteme, von denen der Backend-Betrieb abhängt: Die erforderliche Anzahl von Verbindungen zur Datenbank wird hergestellt, der Pool verfügt über freie Verbindungen usw. usw.
- Sie können Ihre eigene Logik an die URL für Integritätsprüfungen hängen, wenn der verwendete Balancer nicht sehr intelligent ist (z. B. nehmen Sie den Load Balancer vom Host). Der Server kann sich daran erinnern, dass "ich in letzter Minute so viele Fehler gemacht habe - ich bin wahrscheinlich eine Art" falscher "Server, und in den nächsten 2 Minuten werde ich mit" fünfhundert "auf Gesundheitsprüfungen antworten. Also werde ich mich verbannen! " Dies hilft manchmal sehr, wenn Sie einen unkontrollierten Load Balancer haben.
- In der Regel beträgt das Überprüfungsintervall etwa eine Sekunde, und Sie benötigen den Health Check-Handler, um Ihren Server nicht zu beenden. Es sollte leicht sein.
Gesundheitschecks: Implementierungen
In der Regel ist hier für alle alles gleich:
- Anfrage;
- Timeout drauf;
- Intervall, in dem wir Überprüfungen durchführen. Ausgetrickste Proxys haben Jitter , dh eine gewisse Randomisierung, sodass alle Integritätsprüfungen nicht sofort in das Backend gelangen und es nicht beenden.
- Ungesunder Schwellenwert - Der Schwellenwert für die Anzahl der fehlgeschlagenen Integritätsprüfungen, die der Dienst als ungesund markieren muss.
- Gesunder Schwellenwert - im Gegenteil, wie viele erfolgreiche Versuche müssen bestanden werden, damit der Server wieder in Betrieb genommen werden kann.
- Zusätzliche Logik. Sie können Status + Körper überprüfen usw. analysieren.
Nginx implementiert Health Check-Funktionen nur in der kostenpflichtigen Version von nginx +.
Ich stelle eine Funktion von
Envoy fest , es hat einen
Panikmodus für die Gesundheitsprüfung
. Als wir mehr als N% der Hosts (sagen wir 70%) als "ungesund" verboten haben, glaubt er, dass alle unsere Gesundheitschecks lügen und alle Hosts tatsächlich am Leben sind. In einem sehr schlimmen Fall hilft dies Ihnen, nicht in eine Situation zu geraten, in der Sie selbst auf Ihr Bein geschossen und alle Server gesperrt haben. Dies ist ein Weg, um wieder sicher zu sein.
Alles zusammenfügen
Normalerweise für Gesundheitschecks festgelegt:
- Oder Nginx +;
- Oder Nginx + noch etwas :)
In unserem Land besteht die Tendenz, nginx + HAProxy festzulegen, da die kostenlose Version von nginx keine Integritätsprüfungen enthält und die Anzahl der Verbindungen zum Backend bis 1.11.5 unbegrenzt war. Diese Option ist jedoch schlecht, da HAProxy nach dem Herstellen einer Verbindung nicht weiß, wie es in den Ruhestand gehen soll. Viele Leute denken, wenn HAProxy bei Nginx- und Nginx-Wiederholungsversuchen einen Fehler zurückgibt, ist alles in Ordnung. Nicht wirklich. Sie können zu einem anderen HAProxy und demselben Backend gelangen, da die Backend-Pools identisch sind. Sie führen also eine weitere Abstraktionsebene für sich ein, die die Genauigkeit Ihres Ausgleichs und dementsprechend die Verfügbarkeit des Dienstes verringert.
Wir haben Nginx + Envoy, aber wenn Sie verwirrt sind, können Sie sich nur auf Envoy beschränken.
Was für ein Gesandter?
Envoy ist ein trendiger Jugend-Load-Balancer, der ursprünglich in Lyft entwickelt und in C ++ geschrieben wurde.
Nach dem Auspacken kann er heute ein paar Brötchen zu unserem Thema machen. Sie haben es wahrscheinlich als Service Mesh für Kubernetes gesehen. In der Regel fungiert Envoy als Datenebene, dh es gleicht den Verkehr direkt aus, und es gibt auch eine Steuerebene, die Informationen darüber bereitstellt, worauf Sie die Last verteilen müssen (Serviceerkennung usw.).
Ich werde dir ein paar Worte über seine Brötchen erzählen.
Um die Wahrscheinlichkeit einer erfolgreichen Wiederholungsreaktion beim nächsten Versuch zu erhöhen, können Sie etwas schlafen und warten, bis die Backends zur Besinnung kommen. Auf diese Weise werden wir kurze Datenbankprobleme behandeln. Envoy hat ein
Backoff für Wiederholungsversuche - Pausen zwischen Wiederholungsversuchen. Darüber hinaus nimmt das Verzögerungsintervall zwischen den Versuchen exponentiell zu. Der erste Wiederholungsversuch erfolgt nach 0 bis 24 ms, der zweite nach 0 bis 74 ms, und dann erhöht sich für jeden nachfolgenden Versuch das Intervall, und die spezifische Verzögerung wird zufällig aus diesem Intervall ausgewählt.
Der zweite Ansatz ist nicht Envoy-spezifisch, sondern ein Muster, das als Leistungsunterbrechung (leuchtender Leistungsschalter oder Sicherung) bezeichnet wird. Wenn unser Backend langweilig wird, versuchen wir es jedes Mal zu beenden. Dies liegt daran, dass Benutzer in einer unverständlichen Situation auf die Aktualisierungsseite klicken und Ihnen immer mehr neue Anfragen senden. Ihre Balancer werden nervös, senden Wiederholungsversuche, die Anzahl der Anfragen steigt - die Last wächst, und in dieser Situation wäre es schön, keine Anfragen zu senden.
Mit dem Leistungsschalter können Sie nur feststellen, dass wir uns in diesem Zustand befinden, den Fehler schnell beheben und den Backends "den Atem anhalten".
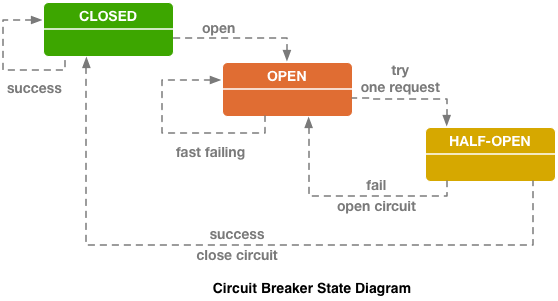 Leistungsschalter (hystrix like libs), Original auf ebays Blog.
Leistungsschalter (hystrix like libs), Original auf ebays Blog.Oben ist der Hystrix-Leistungsschalterkreis. Hystrix ist die Java-Bibliothek von Netflix, mit der Fehlertoleranzmuster implementiert werden können.
- Die "Sicherung" kann sich im "geschlossenen" Zustand befinden, wenn alle Anforderungen an das Backend gesendet werden und keine Fehler vorliegen.
- Wenn eine bestimmte Fehlerschwelle ausgelöst wird, dh einige Fehler aufgetreten sind, geht der Leistungsschalter in den Zustand „Offen“. Es gibt schnell einen Fehler an den Client zurück und Anforderungen gelangen nicht an das Backend.
- Einmal in einem bestimmten Zeitraum wird immer noch ein kleiner Teil der Anforderungen an das Backend gesendet. Wenn ein Fehler ausgelöst wird, bleibt der Status "Offen". Wenn alles gut funktioniert und reagiert, schließt sich die „Sicherung“ und die Arbeit wird fortgesetzt.
In Envoy als solchem ist dies nicht alles. Es gibt Obergrenzen für die Tatsache, dass es nicht mehr als N Anforderungen für eine bestimmte vorgelagerte Gruppe geben kann. Wenn mehr, stimmt hier etwas nicht - wir geben einen Fehler zurück. Es können keine N aktiven Wiederholungsversuche mehr vorhanden sein (d. H. Wiederholungsversuche, die gerade stattfinden).
Sie hatten keine Wiederholungsversuche, etwas ist explodiert - senden Sie Wiederholungsversuche. Envoy versteht, dass mehr als N abnormal ist und alle Anfragen mit einem Fehler gesendet werden müssen.
Leistungsschalter [Gesandter]- Maximale Cluster-Verbindungen (Upstream-Gruppe)
- Cluster max ausstehende Anforderungen
- Cluster max Anforderungen
- Cluster max aktive Wiederholungsversuche
Diese einfache Sache funktioniert gut, ist konfigurierbar, Sie müssen keine speziellen Parameter festlegen und die Standardeinstellungen sind ziemlich gut.
Leistungsschalter: unsere Erfahrung
Früher hatten wir einen HTTP-Metrikkollektor, dh Agenten, die auf den Servern unserer Clients installiert waren, sendeten Metriken über HTTP an unsere Cloud. Wenn wir Probleme mit der Infrastruktur haben, schreibt der Agent die Metriken auf seine Festplatte und versucht dann, sie an uns zu senden.
Und Agenten versuchen ständig, Daten an uns zu senden. Sie sind nicht verärgert darüber, dass wir irgendwie falsch reagieren, und gehen nicht.
( , ) , , .
nginx limit req. , , , 200 RPS. , , , limit req.
TCP HTTP ( nginx limit req). . limit req .
, , .
Circuit breaker, , N , , - , , . , , spool .
Circuit breaker + request cancellation ( ). , N Cassandra, N Elastic, , — , . — , .
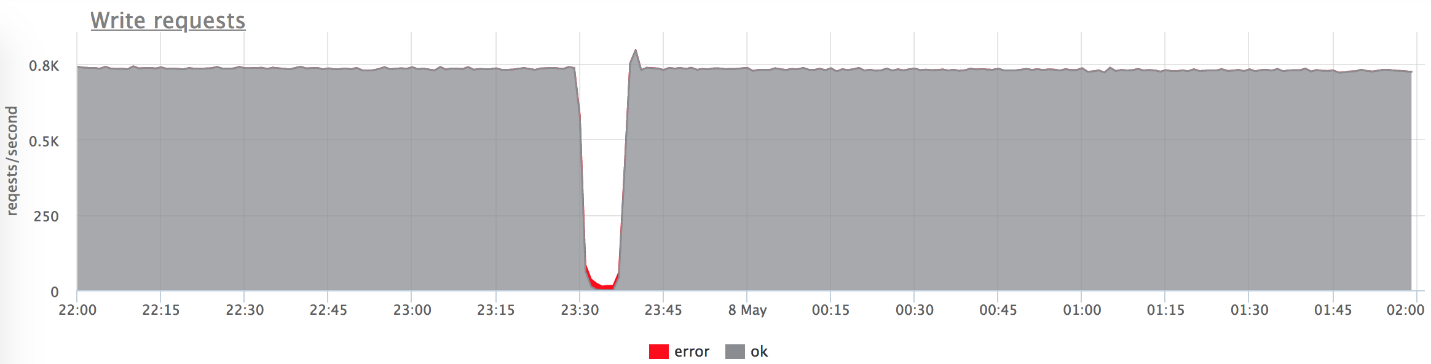
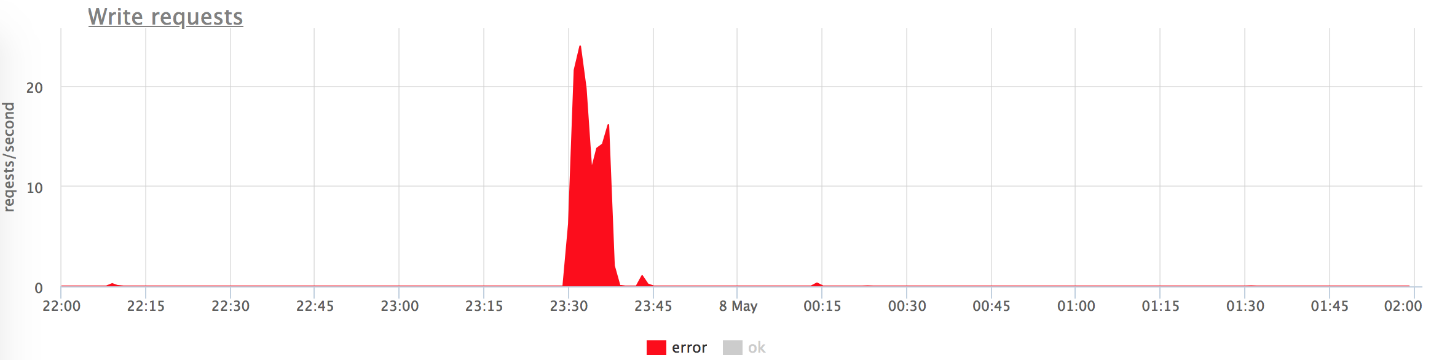
, (: — «», — «»). , 800 RPS 20-30. «», , .
— , .
, , — . .
, , , , Health checks — HTTP 200.
.
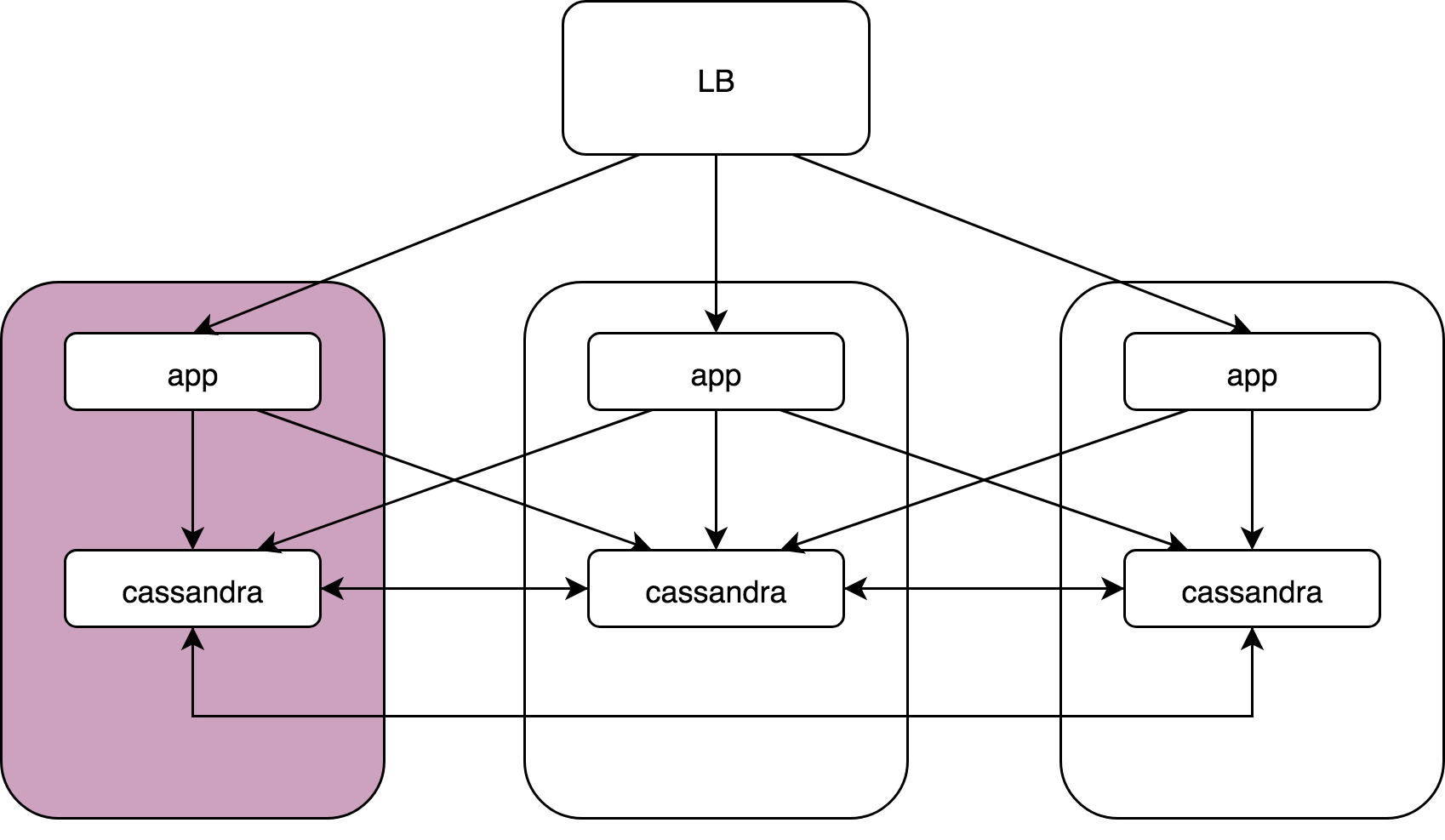
Load Balancer, 3 , Cassandra. Cassandra, Cassandra , Cassandra data noda.
— :
kernel: NETDEV WATCHDOG: eth0 (ixgbe): transmit queue 3 timed out.: ( ), 64 . , 1/64 . reboot, .
, , , . , , , . , , . , .
Cassandra: coordinator -> nodesCassandra, (speculative retries), . latency 99 , .
App -> cassandra coordinator. Cassandra «» , , , latency ..
gocql — cassandra client. . HostSelectionPolicy,
bitly/go-hostpool . Epsilon greedy , .
,
Epsilon-greedy .
(multi-armed bandit): , , N .
:
- « explore» — : 10 , , .
- « exploit» — .
, (10 — 30%)
round -
robin , , , . 70 — 90% .
Host-pool . . ( — , , ). . , , , .
«» () —Cassandra Cassandra coordinator-data. (nginx, Envoy — ) «» Application, Cassandra , , .
Envoy
Outlier detection :
- Consecutive http-5xx.
- Consecutive gateway errors (502,503,504).
- Success rate.
«» , - , . , . — , , . , , .
, «», max_ejection_percent. , outlier, . , 70% — , — , !
, — !
, , . , latency , :
,
, . , , , — , .
. 99% nginx/
HAProxy /Envoy. proxy , «».
proxy ( HAProxy:)),
, .DevOpsConf Russia Kubernetes . .
, — DevOps.
, , YouTube- — .