System.IO.Pipelines ist eine neue Bibliothek, die die Organisation von Code in .NET vereinfacht. Es ist schwierig, eine hohe Leistung und Genauigkeit sicherzustellen, wenn Sie mit komplexem Code arbeiten müssen. Die Aufgabe von System.IO.Pipelines besteht darin, den Code zu vereinfachen. Weitere Details unter dem Schnitt!

Die Bibliothek entstand aus den Bemühungen des .NET Core-Entwicklungsteams, Kestrel zu einem
der schnellsten Webserver der Branche zu machen . Es wurde ursprünglich als Teil der Kestrel-Implementierung konzipiert, hat sich jedoch zu einer wiederverwendbaren API entwickelt, die in Version 2.1 als erstklassige BCL-API (System.IO.Pipelines) verfügbar ist.
Welche Probleme löst sie?
Um Daten aus einem Stream oder Socket richtig zu analysieren, müssen Sie eine große Menge Standardcode schreiben. Gleichzeitig gibt es viele Fallstricke, die den Code selbst und seine Unterstützung erschweren.
Welche Schwierigkeiten treten heute auf?
Beginnen wir mit einer einfachen Aufgabe. Wir müssen einen TCP-Server schreiben, der zeilengetrennte Nachrichten (\ n) vom Client empfängt.
TCP-Server mit NetworkStream
ABWEICHUNG: Wie bei jeder Aufgabe, die eine hohe Leistung erfordert, sollte jeder spezifische Fall anhand der Funktionen Ihrer Anwendung berücksichtigt werden. Es ist möglicherweise nicht sinnvoll, Ressourcen für die Verwendung verschiedener Ansätze aufzuwenden, die später erläutert werden, wenn der Umfang der Netzwerkanwendung nicht sehr groß ist.
Normaler .NET-Code vor der Verwendung von Pipelines sieht ungefähr so aus:
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; await stream.ReadAsync(buffer, 0, buffer.Length);
siehe
sample1.cs auf
githubDieser Code funktioniert wahrscheinlich mit lokalen Tests, weist jedoch eine Reihe von Fehlern auf:
- Möglicherweise wird nach einem einzelnen Aufruf von ReadAsync nicht die gesamte Nachricht empfangen (bis zum Ende der Zeile).
- Das Ergebnis der Methode stream.ReadAsync () wird ignoriert - die tatsächlich in den Puffer übertragene Datenmenge.
- Der Code behandelt nicht den Empfang mehrerer Zeilen in einem einzelnen ReadAsync-Aufruf.
Dies sind die häufigsten Fehler beim Lesen von Streaming-Daten. Um sie zu vermeiden, müssen Sie eine Reihe von Änderungen vornehmen:
- Sie müssen die eingehenden Daten puffern, bis eine neue Zeile gefunden wird.
- Es ist notwendig, alle an den Puffer zurückgegebenen Zeilen zu analysieren.
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; var bytesBuffered = 0; var bytesConsumed = 0; while (true) { var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, buffer.Length - bytesBuffered); if (bytesRead == 0) {
siehe
sample2.cs auf
githubIch wiederhole: Dies könnte mit lokalen Tests funktionieren, aber manchmal gibt es Zeichenfolgen, die länger als 1 KB (1024 Byte) sind. Der Eingabepuffer muss vergrößert werden, bis eine neue Zeile gefunden wird.
Außerdem sammeln wir Puffer in einem Array, wenn wir lange Zeichenfolgen verarbeiten. Wir können diesen Prozess mit ArrayPool verbessern, wodurch eine Neuzuweisung von Puffern während der Analyse langer Zeilen vom Client vermieden wird.
async Task ProcessLinesAsync(NetworkStream stream) { byte[] buffer = ArrayPool<byte>.Shared.Rent(1024); var bytesBuffered = 0; var bytesConsumed = 0; while (true) {
siehe sample3.cs auf githubDer Code funktioniert, aber jetzt hat sich die Puffergröße geändert. Infolgedessen werden viele Kopien davon angezeigt. Es wird auch mehr Speicher verwendet, da die Logik den Puffer nach der Verarbeitung der Zeilen nicht reduziert. Um dies zu vermeiden, können Sie die Liste der Puffer speichern, anstatt die Größe des Puffers jedes Mal zu ändern, wenn eine Zeichenfolge länger als 1 KB ankommt.
Außerdem erhöhen wir die Puffergröße von 1 KB erst, wenn sie vollständig leer ist. Dies bedeutet, dass wir immer kleinere Puffer an ReadAsync übertragen. Dadurch steigt die Anzahl der Aufrufe an das Betriebssystem.
Wir werden versuchen, dies zu beseitigen und einen neuen Puffer zuweisen, sobald die Größe des vorhandenen Puffers weniger als 512 Byte beträgt:
public class BufferSegment { public byte[] Buffer { get; set; } public int Count { get; set; } public int Remaining => Buffer.Length - Count; } async Task ProcessLinesAsync(NetworkStream stream) { const int minimumBufferSize = 512; var segments = new List<BufferSegment>(); var bytesConsumed = 0; var bytesConsumedBufferIndex = 0; var segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) }; segments.Add(segment); while (true) {
siehe sample4.cs auf githubInfolgedessen ist der Code erheblich kompliziert. Während der Suche nach dem Trennzeichen verfolgen wir die gefüllten Puffer. Verwenden Sie dazu eine Liste, in der gepufferte Daten angezeigt werden, wenn Sie nach einem neuen Zeilentrennzeichen suchen. Infolgedessen akzeptieren ProcessLine und IndexOf List anstelle von Byte [], Offset und Count. Die Parsing-Logik beginnt mit der Verarbeitung eines oder mehrerer Segmente des Puffers.
Und jetzt verarbeitet der Server Teilnachrichten und verwendet gemeinsam genutzten Speicher, um den Gesamtspeicherverbrauch zu reduzieren. Es müssen jedoch einige Änderungen vorgenommen werden:
- Von ArrayPoolbyte verwenden wir nur Byte [] - standardmäßig verwaltete Arrays. Mit anderen Worten, wenn die ReadAsync- oder WriteAsync-Funktionen ausgeführt werden, ist die Gültigkeitsdauer der Puffer an den Zeitpunkt der asynchronen Operation gebunden (um mit den E / A-APIs des Betriebssystems zu interagieren). Da der angeheftete Speicher nicht verschoben werden kann, wirkt sich dies auf die Leistung des Garbage Collector aus und kann zu einer Fragmentierung des Arrays führen. Möglicherweise müssen Sie die Implementierung des Pools ändern, je nachdem, wie lange asynchrone Vorgänge auf die Ausführung warten.
- Der Durchsatz kann verbessert werden, indem die Verbindung zwischen Lese- und Prozesslogik unterbrochen wird. Wir erhalten den Effekt der Stapelverarbeitung, und jetzt kann die Analyselogik große Datenmengen lesen, große Pufferblöcke verarbeiten, anstatt einzelne Zeilen zu analysieren. Dadurch wird der Code noch komplizierter:
- Sie müssen zwei Zyklen erstellen, die unabhängig voneinander arbeiten. Der erste liest Daten aus dem Socket und der zweite analysiert die Puffer.
- Was benötigt wird, ist eine Möglichkeit, der Parsing-Logik mitzuteilen, dass die Daten verfügbar werden.
- Es muss auch ermittelt werden, was passiert, wenn die Schleife Daten zu schnell aus dem Socket liest. Wir brauchen eine Möglichkeit, den Lesezyklus anzupassen, wenn die Parsing-Logik nicht mithält. Dies wird üblicherweise als "Durchflussregelung" oder "Durchflusswiderstand" bezeichnet.
- Wir müssen sicherstellen, dass die Daten sicher übertragen werden. Jetzt wird der Puffersatz sowohl vom Lesezyklus als auch vom Analysezyklus verwendet, da sie in verschiedenen Threads unabhängig voneinander arbeiten.
- Die Speicherverwaltungslogik ist auch an zwei verschiedenen Codeteilen beteiligt: Ausleihen von Daten aus dem Pufferpool, der Daten aus dem Socket liest, und Zurückkehren aus dem Pufferpool, der die Parsing-Logik darstellt.
- Man muss äußerst vorsichtig sein, wenn man nach dem Ausführen der Parsing-Logik Puffer zurückgibt. Andernfalls besteht die Möglichkeit, dass wir den Puffer zurückgeben, in den die Socket-Leselogik noch geschrieben wird.
Die Komplexität beginnt durch das Dach zu gehen (und das ist bei weitem nicht alles!). Um ein Hochleistungsnetzwerk zu erstellen, müssen Sie sehr komplexen Code schreiben.
Der Zweck von System.IO.Pipelines besteht darin, dieses Verfahren zu vereinfachen.
TCP-Server und System.IO.Pipelines
Mal sehen, wie System.IO.Pipelines funktioniert:
async Task ProcessLinesAsync(Socket socket) { var pipe = new Pipe(); Task writing = FillPipeAsync(socket, pipe.Writer); Task reading = ReadPipeAsync(pipe.Reader); return Task.WhenAll(reading, writing); } async Task FillPipeAsync(Socket socket, PipeWriter writer) { const int minimumBufferSize = 512; while (true) {
siehe sample5.cs auf githubDie Pipeline-Version unseres Zeilenlesers verfügt über zwei Schleifen:
- FillPipeAsync liest aus dem Socket und schreibt in PipeWriter.
- ReadPipeAsync liest aus PipeReader und analysiert eingehende Zeilen.
Im Gegensatz zu den ersten Beispielen gibt es keine speziell zugewiesenen Puffer. Dies ist eine der Hauptfunktionen von System.IO.Pipelines. Alle Pufferverwaltungsaufgaben werden an die PipeReader / PipeWriter-Implementierungen übertragen.
Das Verfahren ist vereinfacht: Wir verwenden den Code nur für die Geschäftslogik, anstatt eine komplexe Pufferverwaltung zu implementieren.
In der ersten Schleife wird PipeWriter.GetMemory (int) zuerst aufgerufen, um eine bestimmte Speichermenge vom Hauptschreiber abzurufen. Dann wird PipeWriter.Advance (int) aufgerufen, das PipeWriter mitteilt, wie viele Daten tatsächlich in den Puffer geschrieben werden. Darauf folgt ein Aufruf von PipeWriter.FlushAsync (), damit PipeReader auf die Daten zugreifen kann.
Die zweite Schleife verbraucht die Puffer, die von PipeWriter geschrieben, aber ursprünglich vom Socket empfangen wurden. Wenn die Anforderung an PipeReader.ReadAsync () zurückgegeben wird, erhalten wir ein ReadResult, das zwei wichtige Nachrichten enthält: Daten, die in der Form ReadOnlySequence gelesen werden, sowie den logischen Datentyp IsCompleted, der dem Leser mitteilt, ob der Writer die Arbeit beendet hat (EOF). Wenn der Zeilenabschluss (EOL) gefunden und die Zeichenfolge analysiert wurde, teilen wir den Puffer in Teile auf, um das bereits verarbeitete Fragment zu überspringen. Danach wird PipeReader.AdvanceTo aufgerufen und teilt PipeReader mit, wie viele Daten verbraucht wurden.
Am Ende jedes Zyklus sind sowohl der Leser als auch der Schreiber fertig. Infolgedessen gibt der Hauptkanal den gesamten zugewiesenen Speicher frei.
System.io.pipelines
Teillesung
Neben der Speicherverwaltung erfüllt System.IO.Pipelines eine weitere wichtige Funktion: Es scannt die Daten im Kanal, verbraucht sie jedoch nicht.
PipeReader verfügt über zwei Haupt-APIs: ReadAsync und AdvanceTo. ReadAsync empfängt Daten vom Kanal. AdvanceTo teilt PipeReader mit, dass diese Puffer vom Reader nicht mehr benötigt werden, sodass Sie sie entfernen können (z. B. sie an den Hauptpufferpool zurückgeben).
Das Folgende ist ein Beispiel eines HTTP-Analysators, der Daten aus Teilkanaldatenpuffern liest, bis er eine geeignete Startzeile empfängt.

ReadOnlySequenceT
Die Kanalimplementierung speichert eine Liste verwandter Puffer, die zwischen PipeWriter und PipeReader übergeben werden. PipeReader.ReadAsync macht ReadOnlySequence verfügbar, einen neuen BCL-Typ, der aus einem oder mehreren ReadOnlyMemory <T> -Segmenten besteht. Es ähnelt Span oder Memory, wodurch wir die Möglichkeit haben, Arrays und Strings zu betrachten.
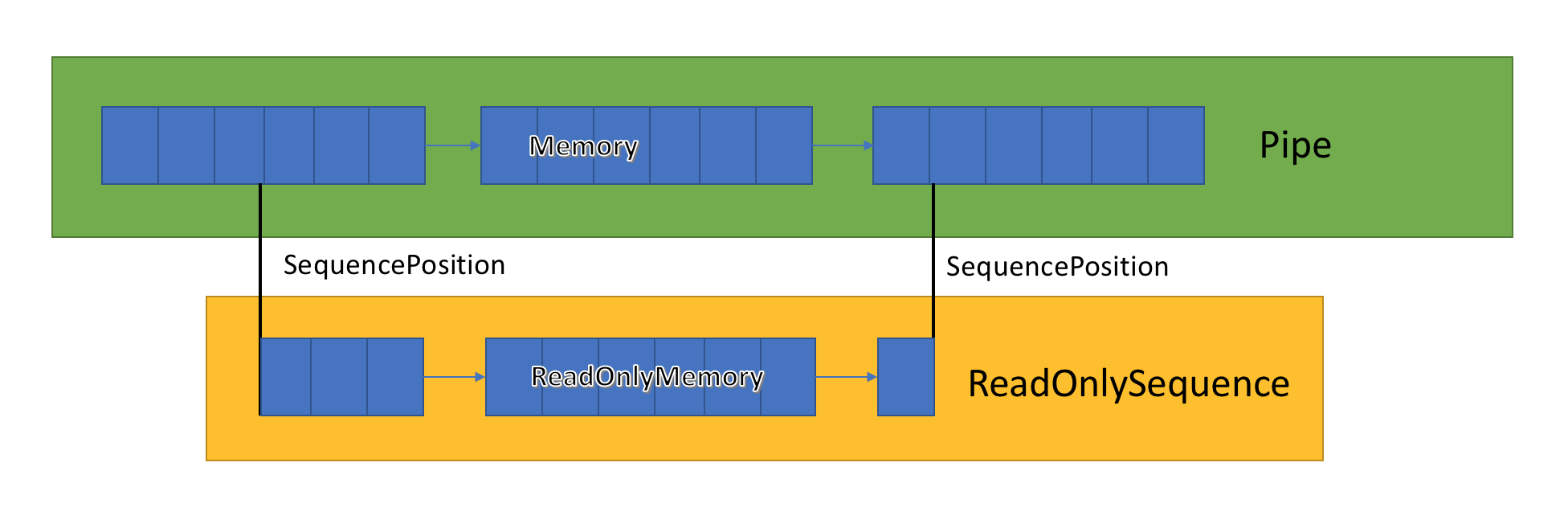
Innerhalb des Kanals gibt es Zeiger, die anzeigen, wo sich der Leser und der Schreiber im allgemeinen Satz hervorgehobener Daten befinden, und die sie auch beim Schreiben und Lesen von Daten aktualisieren. SequencePosition ist ein einzelner Punkt in einer verknüpften Liste von Puffern und wird verwendet, um ReadOnlySequence <T> effizient zu trennen.
Da ReadOnlySequence <T> ein oder mehrere Segmente unterstützt, besteht die Standardoperation der Hochleistungslogik darin, schnelle und langsame Pfade basierend auf der Anzahl der Segmente zu trennen.
Als Beispiel sehen Sie hier eine Funktion, die ASCII ReadOnlySequence in eine Zeichenfolge konvertiert:
string GetAsciiString(ReadOnlySequence<byte> buffer) { if (buffer.IsSingleSegment) { return Encoding.ASCII.GetString(buffer.First.Span); } return string.Create((int)buffer.Length, buffer, (span, sequence) => { foreach (var segment in sequence) { Encoding.ASCII.GetChars(segment.Span, span); span = span.Slice(segment.Length); } }); }
siehe
sample6.cs auf
githubDurchflusswiderstand und Durchflussregelung
Im Idealfall arbeiten Lesen und Analyse zusammen: Der Lesestream verbraucht Daten aus dem Netzwerk und legt sie in Puffer, während der Analysestream geeignete Datenstrukturen erstellt. Die Analyse dauert normalerweise länger als nur das Kopieren von Datenblöcken aus dem Netzwerk. Infolgedessen kann der Lesestream den Analysestream leicht überlasten. Daher wird der Lesestream gezwungen sein, entweder zu verlangsamen oder mehr Speicher zu verbrauchen, um Daten für den Analysestream zu speichern. Um eine optimale Leistung zu gewährleisten, ist ein Gleichgewicht zwischen der Pausenfrequenz und der Zuweisung einer großen Speichermenge erforderlich.
Um dieses Problem zu lösen, verfügt die Pipeline über zwei Funktionen zur Datenflusssteuerung: PauseWriterThreshold und ResumeWriterThreshold. PauseWriterThreshold bestimmt, wie viele Daten gepuffert werden müssen, bevor PipeWriter.FlushAsync angehalten wird. ResumeWriterThreshold bestimmt, wie viel Speicher der Leser verbrauchen kann, bevor der Rekorder den Betrieb wieder aufnimmt.
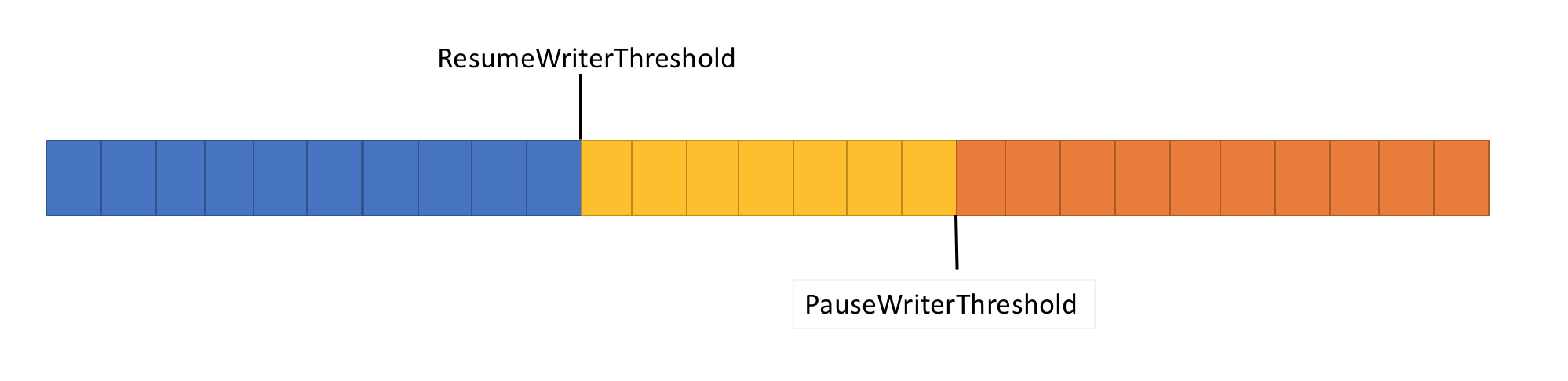
PipeWriter.FlushAsync „sperrt“, wenn die Datenmenge im Pipeline-Stream den in PauseWriterThreshold festgelegten Grenzwert überschreitet, und „entsperrt“, wenn der in ResumeWriterThreshold festgelegte Grenzwert unterschritten wird. Um ein Überschreiten der Verbrauchsgrenze zu verhindern, werden nur zwei Werte verwendet.
E / A-Planung
Bei Verwendung von async / await werden nachfolgende Vorgänge normalerweise entweder in den Pool-Threads oder im aktuellen SynchronizationContext aufgerufen.
Bei der Ausführung von E / A ist es sehr wichtig, sorgfältig zu überwachen, wo sie ausgeführt werden, um den Prozessor-Cache besser nutzen zu können. Dies ist wichtig für Hochleistungsanwendungen wie Webserver. System.IO.Pipelines verwendet den PipeScheduler, um zu bestimmen, wo asynchrone Rückrufe ausgeführt werden sollen. Auf diese Weise können Sie sehr genau steuern, welche Streams für E / A verwendet werden sollen.
Ein Beispiel für eine praktische Anwendung ist der Kestrel Libuv-Transport, bei dem E / A-Rückrufe auf dedizierten Kanälen der Ereignisschleife ausgeführt werden.
Die PipeReader-Vorlage bietet weitere Vorteile.
- Einige Basissysteme unterstützen "Warten ohne Pufferung": Sie müssen keinen Puffer zuweisen, bis verfügbare Daten im Basissystem angezeigt werden. Unter Linux mit epoll können Sie also keinen Lesepuffer bereitstellen, bis die Daten bereit sind. Dies vermeidet die Situation, in der viele Threads auf Daten warten und Sie sofort eine große Menge an Speicher reservieren müssen.
- Die Standard-Pipeline erleichtert das Schreiben von Komponententests für Netzwerkcode: Die Analyselogik ist vom Netzwerkcode getrennt, und Komponententests führen diese Logik nur in Puffern im Speicher aus, anstatt sie direkt aus dem Netzwerk zu verbrauchen. Es macht es auch einfach, komplexe Muster durch Senden von Teildaten zu testen. ASP.NET Core verwendet es, um verschiedene Aspekte der http-Parsing-Tools von Kestrel zu testen.
- Systeme, mit denen Benutzercode die Hauptpuffer des Betriebssystems verwenden kann (z. B. registrierte Windows-E / A-APIs), eignen sich zunächst für die Verwendung von Pipelines, da die PipeReader-Implementierung immer Puffer bereitstellt.
Andere verwandte Typen
Wir haben System.IO.Pipelines auch eine Reihe neuer einfacher BCL-Typen hinzugefügt:
- MemoryPoolT , IMemoryOwnerT , MemoryManagerT . ArrayPoolT wurde in .NET Core 1.0 hinzugefügt, und in .NET Core 2.1 gibt es jetzt eine allgemeinere abstrakte Darstellung für einen Pool, der mit jedem MemoryT funktioniert. Wir erhalten einen Erweiterungspunkt, mit dem wir erweiterte Verteilungsstrategien sowie die Verwaltung von Steuerpuffern implementieren können (verwenden Sie beispielsweise vordefinierte Puffer anstelle von ausschließlich verwalteten Arrays).
- IBufferWriterT ist ein Empfänger zum Aufzeichnen synchronisierter gepufferter Daten (implementiert von PipeWriter).
- IValueTaskSource - ValueTaskT gibt es seit der Veröffentlichung von .NET Core 1.1, aber in .NET Core 2.1 wurden äußerst effektive Tools erworben, die unterbrechungsfreie asynchrone Vorgänge ohne Verteilung ermöglichen. Weitere Informationen finden Sie hier.
Wie benutzt man Förderer?
Die APIs befinden sich im Nuget-Paket
System.IO.Pipelines .
Ein Beispiel für eine .NET Server 2.1-Serveranwendung, die Pipelines zum Verarbeiten von Kleinbuchstaben verwendet (aus dem obigen Beispiel), finden Sie
hier . Es kann mit dotnet run (oder Visual Studio) gestartet werden. In diesem Beispiel wird erwartet, dass Daten vom Socket an Port 8087 übertragen werden. Anschließend werden empfangene Nachrichten in die Konsole geschrieben. Sie können einen Client wie Netcat oder Putty verwenden, um eine Verbindung zu Port 8087 herzustellen. Senden Sie eine Nachricht in Kleinbuchstaben und sehen Sie, wie es funktioniert.
Derzeit läuft die Pipeline auf Kestrel und SignalR, und wir hoffen, dass sie in Zukunft in vielen Netzwerkbibliotheken und Komponenten der .NET-Community eine breitere Anwendung finden wird.