
Von Anfang an haben wir Engineering- und Produktlösungen geplant, damit Discord für Voice-Chat beim Spielen mit Freunden gut geeignet ist. Diese Lösungen ermöglichten eine starke Skalierung des Systems mit einem kleinen Team und begrenzten Ressourcen.
Dieser Artikel beschreibt die verschiedenen Technologien, die Discord für Audio- / Video-Chats verwendet.
Aus Gründen der Klarheit werden wir die gesamte Gruppe von Benutzern und Kanälen als "Gruppe" (Gilde) bezeichnen - im Client werden sie "Server" genannt. Stattdessen bezieht sich der Begriff „Server“ auf unsere Serverinfrastruktur.Hauptprinzipien
Jeder Audio- / Video-Chat in Discord unterstützt viele Teilnehmer. Wir haben tausend Menschen gesehen, die sich abwechselnd in Chats in großen Gruppen unterhielten. Eine solche Unterstützung erfordert eine Client-Server-Architektur, da ein Peer-to-Peer-Peer-to-Peer-Netzwerk mit zunehmender Teilnehmerzahl unerschwinglich teuer wird.
Durch das Weiterleiten des Netzwerkverkehrs über Discord-Server wird außerdem sichergestellt, dass Ihre IP-Adresse niemals sichtbar ist und niemand einen DDoS-Angriff startet. Das Routing über Server hat weitere Vorteile: Zum Beispiel Moderation. Administratoren können Ton und Video für Eindringlinge schnell ausschalten.
Client-Architektur
Discord läuft auf vielen Plattformen.
- Web (Chrome / Firefox / Edge usw.)
- Standalone-Anwendung (Windows, MacOS, Linux)
- Telefon (iOS / Android)
Wir können alle diese Plattformen nur auf eine Weise unterstützen: durch die Wiederverwendung von
WebRTC- Code. Diese Spezifikation für die Echtzeitkommunikation umfasst Netzwerk-, Audio- und Videokomponenten. Der Standard wird
vom World Wide Web Consortium und der
Internet Engineering Group übernommen . WebRTC ist in allen modernen Browsern und als native Bibliothek zur Implementierung in Anwendungen verfügbar.
Das Audio und Video in Discord läuft auf WebRTC. Daher ist die Browseranwendung auf die Implementierung von WebRTC im Browser angewiesen. Anwendungen für Desktops, iOS und Android verwenden jedoch eine einzige C ++ - Multimedia-Engine, die auf ihrer eigenen WebRTC-Bibliothek basiert und speziell auf die Bedürfnisse unserer Benutzer zugeschnitten ist. Dies bedeutet, dass einige Funktionen in der Anwendung besser funktionieren als im Browser. In unseren nativen Anwendungen können wir beispielsweise:
- Windows Volume Mute wird standardmäßig umgangen, wenn alle Anwendungen bei Verwendung eines Headsets automatisch stummgeschaltet werden . Dies ist unerwünscht, wenn Sie und Ihre Freunde einen Raid durchführen und die Discord-Chat-Aktivitäten koordinieren.
- Verwenden Sie Ihren eigenen Lautstärkeregler anstelle des globalen Betriebssystem-Mixers.
- Verarbeiten Sie die ursprünglichen Audiodaten, um Sprachaktivitäten zu erkennen und Audio und Video in Spielen zu übertragen.
- Reduzieren Sie die Bandbreite und den CPU-Verbrauch in Ruhephasen - selbst bei den meisten Voice-Chats zu einem bestimmten Zeitpunkt sprechen nur wenige Personen gleichzeitig.
- Bereitstellung systemweiter Funktionen für den Push-to-Talk-Modus.
- Senden Sie zusammen mit Audio-Video-Paketen zusätzliche Informationen (z. B. eine Prioritätsanzeige im Chat).
Eine eigene Version von WebRTC bedeutet häufige Updates für alle Benutzer: Dies ist ein zeitaufwändiger Prozess, den wir zu automatisieren versuchen. Dieser Aufwand zahlt sich jedoch dank der spezifischen Funktionen für unsere Spieler aus.
In Discord wird die Sprach- und Videokommunikation durch Eingabe eines Sprachkanals oder Anrufs initiiert. Das heißt, die Verbindung wird immer vom Client initiiert. Dies verringert die Komplexität der Client- und Serverteile und erhöht auch die Fehlertoleranz. Bei einem Infrastrukturausfall können sich die Teilnehmer einfach wieder mit dem neuen internen Server verbinden.
Unter unserer Kontrolle
Mit der Steuerung der nativen Bibliothek können Sie einige Funktionen anders implementieren als in der Browser-Implementierung von WebRTC.
Erstens stützt sich WebRTC auf das Session Description Protocol (
SDP ), um Audio / Video zwischen Teilnehmern auszuhandeln (bis zu 10 KB pro Paketaustausch). In einer eigenen Bibliothek wird die untergeordnete API von WebRTC (
webrtc::Call ) verwendet, um beide Flows zu erstellen - eingehende und ausgehende. Bei Verbindung mit einem Sprachkanal findet nur ein minimaler Informationsaustausch statt. Dies ist die Adresse und der Port des Backend-Servers, die Verschlüsselungsmethode, die Schlüssel, der Codec und die Stream-Identifikation (ca. 1000 Byte).
webrtc::AudioSendStream* createAudioSendStream( uint32_t ssrc, uint8_t payloadType, webrtc::Transport* transport, rtc::scoped_refptr<webrtc::AudioEncoderFactory> audioEncoderFactory, webrtc::Call* call) { webrtc::AudioSendStream::Config config{transport}; config.rtp.ssrc = ssrc; config.rtp.extensions = {{"urn:ietf:params:rtp-hdrext:ssrc-audio-level", 1}}; config.encoder_factory = audioEncoderFactory; const webrtc::SdpAudioFormat kOpusFormat = {"opus", 48000, 2}; config.send_codec_spec = webrtc::AudioSendStream::Config::SendCodecSpec(payloadType, kOpusFormat); webrtc::AudioSendStream* audioStream = call->CreateAudioSendStream(config); audioStream->Start(); return audioStream; }
Darüber hinaus verwendet WebRTC Interactive Connectivity Establishment (
ICE ), um die beste Route zwischen den Teilnehmern zu ermitteln. Da jeder Client eine Verbindung zum Server herstellt, benötigen wir keinen ICE. Auf diese Weise können Sie eine viel zuverlässigere Verbindung herstellen, wenn Sie sich hinter NAT befinden, und Ihre IP-Adresse vor anderen Teilnehmern geheim halten. Clients pingen regelmäßig, damit die Firewall eine offene Verbindung aufrechterhält.
Schließlich verwendet WebRTC das Secure Real-Time Transport Protocol (
SRTP ) zum Verschlüsseln von Medien. Verschlüsselungsschlüssel werden mithilfe des
DTLS- Protokolls (Datagram Transport Layer Security) basierend auf Standard-TLS festgelegt. Mit der integrierten WebRTC-Bibliothek können Sie mithilfe der
webrtc::Transport API Ihre eigene Transportschicht implementieren.
Anstelle von DTLS / SRTP haben wir uns für eine schnellere
Salsa20-Verschlüsselung entschieden . Darüber hinaus senden wir in Ruhephasen keine Audiodaten - ein häufiges Ereignis, insbesondere in großen Chatrooms. Dies führt zu erheblichen Einsparungen bei der Bandbreite und den CPU-Ressourcen. Sowohl der Client als auch der Server müssen jedoch jederzeit bereit sein, um den Datenempfang zu beenden und die Seriennummern von Audio- / Videopaketen neu zu schreiben.
Da die Webanwendung die browserbasierte Implementierung der
WebRTC-API verwendet , können SDP, ICE, DTLS und SRTP nicht abgebrochen werden. Der Client und der Server tauschen alle erforderlichen Informationen aus (weniger als 1200 Byte beim Austausch von Paketen) - und die SDP-Sitzung wird auf der Grundlage dieser Informationen für Clients eingerichtet. Das Backend ist dafür verantwortlich, die Unterschiede zwischen Desktop- und Browseranwendungen zu beheben.
Backend-Architektur
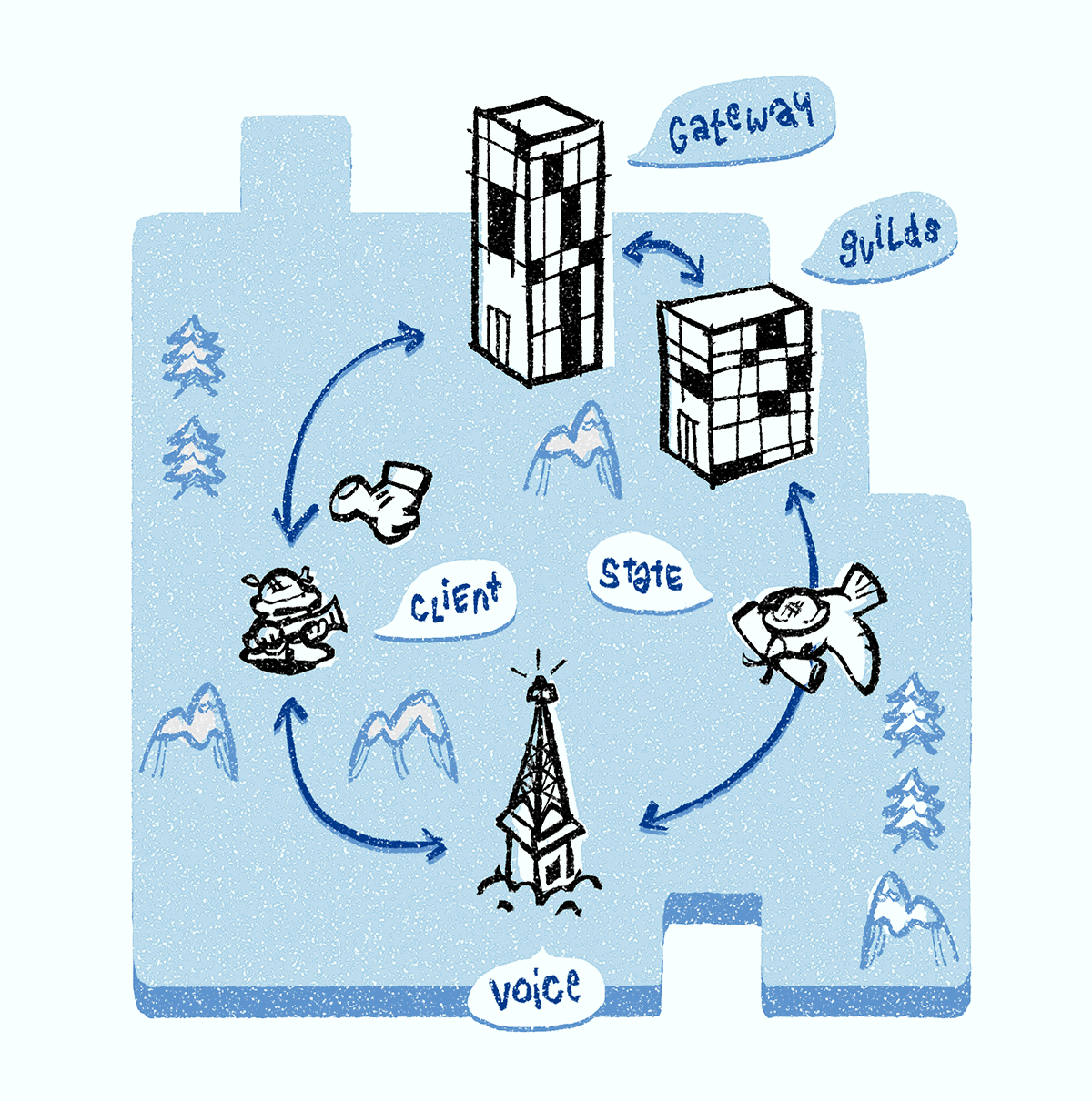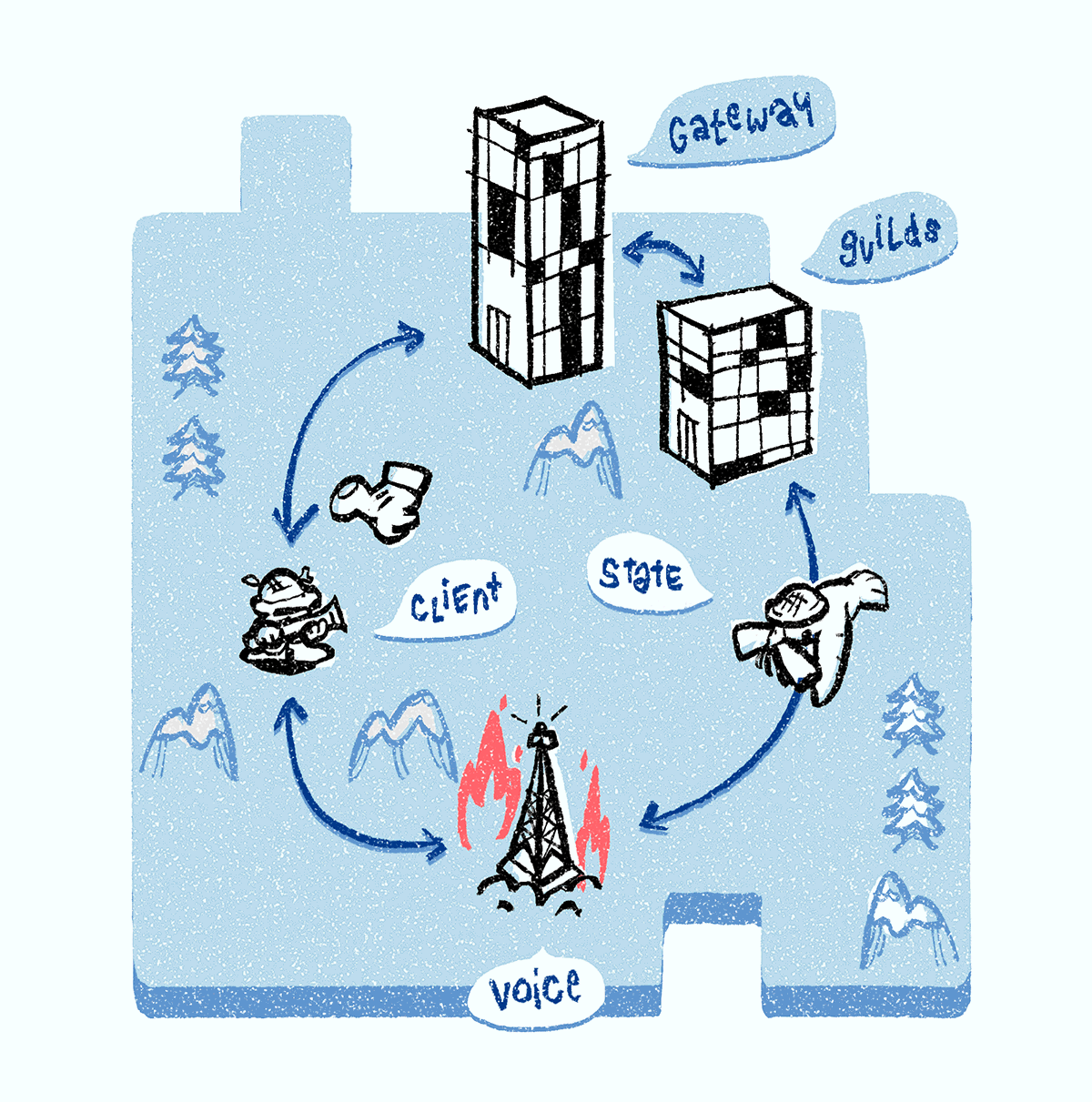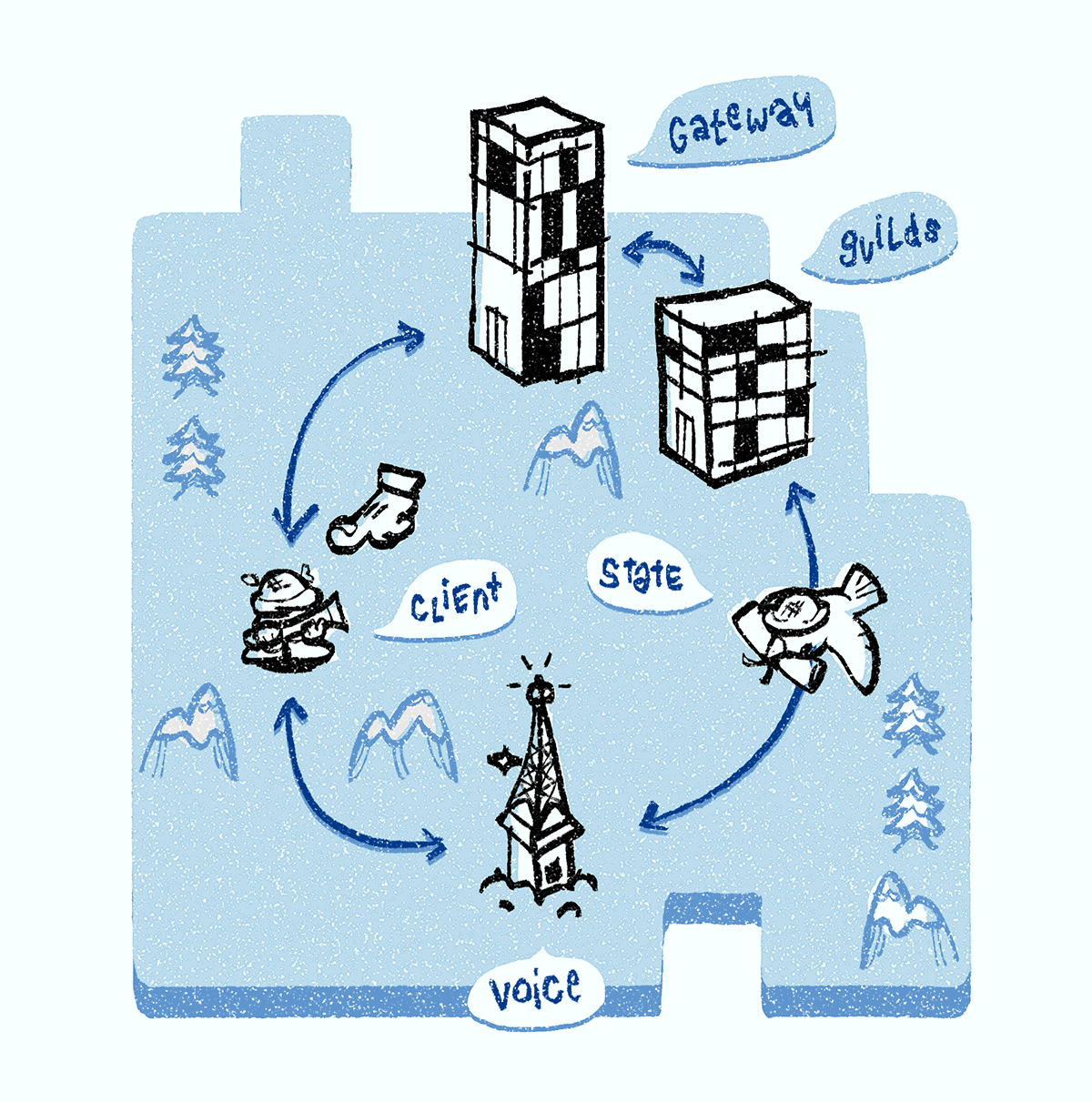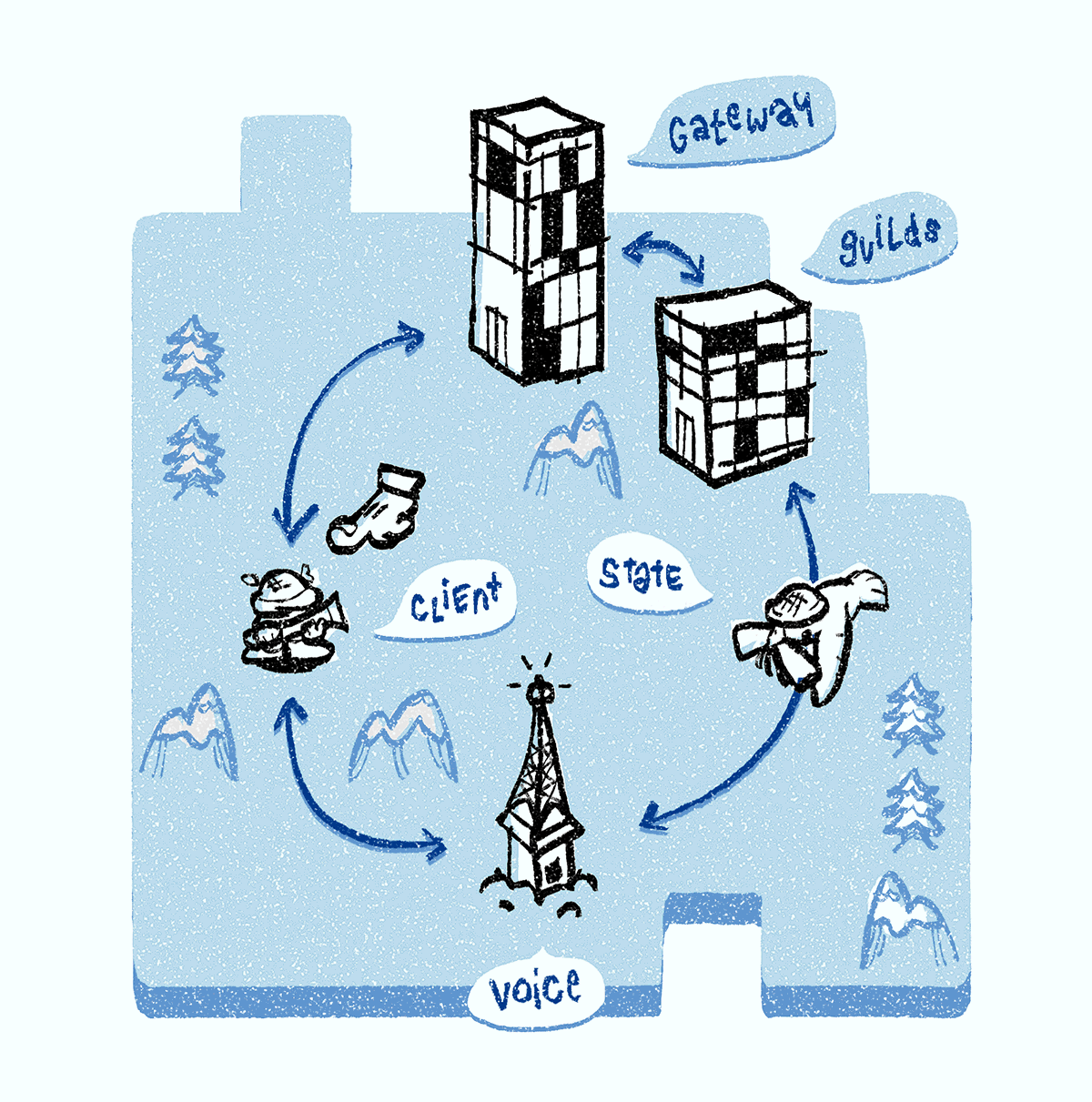
Es gibt mehrere Voice-Chat-Dienste im Backend, aber wir werden uns auf drei konzentrieren: Discord Gateway, Discord Guilds und Discord Voice. Alle unsere Signalserver sind in
Elixir geschrieben , sodass wir Code wiederholt wiederverwenden können.
Wenn Sie online sind, unterstützt Ihr Client eine WebSocket-Verbindung zu einem Discord Gateway (wir nennen es eine WebSocket-
Gateway- Verbindung). Über diese Verbindung erhält Ihr Client Ereignisse in Bezug auf Gruppen und Kanäle, Textnachrichten, Anwesenheitspakete usw.
Bei Verbindung mit einem Sprachkanal wird der Verbindungsstatus vom Sprachstatusobjekt angezeigt. Der Client aktualisiert dieses Objekt über die Gateway-Verbindung.
defmodule VoiceStates.VoiceState do @type t :: %{ session_id: String.t(), user_id: Number.t(), channel_id: Number.t() | nil, token: String.t() | nil, mute: boolean, deaf: boolean, self_mute: boolean, self_deaf: boolean, self_video: boolean, suppress: boolean } defstruct session_id: nil, user_id: nil, token: nil, channel_id: nil, mute: false, deaf: false, self_mute: false, self_deaf: false, self_video: false, suppress: false end
Wenn Sie mit einem Sprachkanal verbunden sind, wird Ihnen einer der Discord Voice-Server zugewiesen. Er ist dafür verantwortlich, jedem Teilnehmer des Kanals Ton zu übertragen. Alle Sprachkanäle in einer Gruppe sind einem Server zugeordnet. Wenn Sie als erster chatten, ist der Discord Guilds-Server dafür verantwortlich, den Discord Voice-Server der gesamten Gruppe gemäß dem unten beschriebenen Verfahren zuzuweisen.
Discord Voice Server-Ziel
Jeder Discord Voice-Server meldet regelmäßig seinen Status und seine Auslastung. Diese Informationen werden in einem Service Discovery-System
abgelegt (wir verwenden
etcd ), wie in einem
vorherigen Artikel erläutert.
Der Discord Guilds-Server überwacht das Service Discovery-System und weist der Gruppe den am wenigsten verwendeten Discord Voice-Server in der Region zu. Bei Auswahl dieser Option werden alle Sprachstatusobjekte (auch vom Discord Guilds-Server unterstützt) auf den Discord Voice-Server übertragen, damit er die Audio- / Video-Weiterleitung konfigurieren kann. Clients werden über den ausgewählten Discord Voice-Server benachrichtigt. Anschließend öffnet der Client die
zweite WebSocket-Verbindung mit dem Sprachserver (wir nennen sie die WebSocket-
Sprachverbindung ), mit der die Multimedia-Weiterleitung und die Sprachanzeige konfiguriert werden.
Wenn der Client den Status "
Warten auf Endpunkt" anzeigt, bedeutet dies, dass der Discord Guilds-Server nach dem optimalen Discord Voice-Server sucht. Eine
Voice Connected- Nachricht zeigt an, dass der Client erfolgreich UDP-Pakete mit dem ausgewählten Discord Voice-Server ausgetauscht hat.
Der Discord Voice-Server enthält zwei Komponenten: ein Signalmodul und eine Multimedia-Relaiseinheit, die als selektive Weiterleitungseinheit (
SFU ) bezeichnet wird. Das Signalmodul steuert die SFU vollständig und ist für die Generierung von Flusskennungen und Verschlüsselungsschlüsseln, die Umleitung von Sprachindikatoren usw. verantwortlich.
Unsere SFU (in C ++) ist für die Leitung des Audio- und Videoverkehrs zwischen Kanälen verantwortlich. Es ist eigenständig entwickelt: Für unseren speziellen Fall bietet die SFU maximale Leistung und damit die größten Einsparungen. Wenn Moderatoren gegen den Server verstoßen (ihn stumm schalten), werden ihre Audiopakete nicht verarbeitet. SFU fungiert auch als Brücke zwischen nativen und browserbasierten Anwendungen: Es implementiert Transport und Verschlüsselung sowohl für Browser- als auch für native Anwendungen und konvertiert Pakete während der Übertragung. Schließlich ist die SFU für die Verarbeitung des
RTCP- Protokolls verantwortlich, mit dem die Videoqualität optimiert wird. Die SFU sammelt und verarbeitet RTCP-Berichte von Empfängern - und benachrichtigt die Absender, welches Band für die Videoübertragung verfügbar ist.
Fehlertoleranz
Da nur Discord Voice-Server direkt aus dem Internet verfügbar sind, werden wir darüber sprechen.
Das Signalmodul überwacht kontinuierlich die SFU. Wenn es abstürzt, wird es sofort mit einer minimalen Unterbrechung des Dienstes neu gestartet (mehrere verlorene Pakete). Der SFU-Status wird vom Signalmodul ohne Interaktion mit dem Client wiederhergestellt. Obwohl SFU-Abstürze selten sind, verwenden wir denselben Mechanismus, um SFUs ohne Betriebsunterbrechungen zu aktualisieren.
Wenn der Discord Voice-Server abstürzt, reagiert er nicht auf Ping - und wird aus dem Service Discovery-System entfernt. Der Client bemerkt auch einen Serverabsturz aufgrund einer unterbrochenen WebSocket-Sprachverbindung und fordert dann den
Ping des Sprachservers über die WebSocket-Gateway-Verbindung an. Der Discord Guilds-Server bestätigt den Fehler, konsultiert das Service Discovery-System und weist der Gruppe einen neuen Discord Voice-Server zu. Die Discord Guilds senden dann alle Sprachstatusobjekte an den neuen Sprachserver. Alle Clients erhalten eine Benachrichtigung über den neuen Server und stellen eine Verbindung zu diesem her, um das Multimedia-Setup zu starten.
Sehr oft fallen Discord Voice-Server unter DDoS (wir sehen dies an der raschen Zunahme eingehender IP-Pakete). In diesem Fall führen wir das gleiche Verfahren aus wie beim Absturz des Servers: Wir entfernen ihn aus dem Service Discovery-System, wählen einen neuen Server aus, übertragen alle Sprachkommunikationsstatusobjekte an ihn und benachrichtigen Clients über den neuen Server. Wenn der DDoS-Angriff abgeklungen ist, kehrt der Server zum Service Discovery-System zurück.
Wenn der Gruppeninhaber beschließt, eine neue Region für die Abstimmung auszuwählen, folgen wir einem sehr ähnlichen Verfahren. Discord Guilds Server wählt in Absprache mit einem Service Discovery-System den besten verfügbaren Sprachserver in einer neuen Region aus. Anschließend übersetzt er alle Objekte des Status der Sprachkommunikation und benachrichtigt die Clients über den neuen Server. Clients unterbrechen die aktuelle WebSocket-Verbindung mit dem alten Discord Voice-Server und stellen eine neue Verbindung mit dem neuen Discord Voice-Server her.
Skalieren
Die gesamte Infrastruktur von Discord Gateway, Discord Guilds und Discord Voice unterstützt die horizontale Skalierung. Discord Gateway und Discord Guilds arbeiten in der Google Cloud.
Wir haben weltweit mehr als 850 Sprachserver in 13 Regionen (in mehr als 30 Rechenzentren). Diese Infrastruktur bietet eine größere Redundanz bei Ausfällen in Rechenzentren und DDoS. Wir arbeiten mit mehreren Partnern zusammen und verwenden unsere physischen Server in deren Rechenzentren. In jüngerer Zeit wurde die südafrikanische Region hinzugefügt. Dank technischer Anstrengungen sowohl in der Client- als auch in der Serverarchitektur kann Discord jetzt mehr als 2,6 Millionen Voice-Chat-Benutzer mit ausgehendem Datenverkehr von mehr als 220 Gbit / s und 120 Millionen Paketen pro Sekunde gleichzeitig bedienen.
Was weiter?
Wir überwachen ständig die Qualität der Sprachkommunikation (Metriken werden vom Client an die Backend-Server gesendet). Diese Informationen werden in Zukunft dazu beitragen, die Verschlechterung automatisch zu erkennen und zu beseitigen.
Wir haben zwar vor einem Jahr Video-Chat und Screencasts gestartet, aber jetzt können sie nur noch in privaten Nachrichten verwendet werden. Video benötigt im Vergleich zu Audio deutlich mehr CPU-Leistung und Bandbreite. Die Herausforderung besteht darin, die Menge an Bandbreite und CPU / GPU-Ressourcen auszugleichen, die verwendet werden, um die beste Videoqualität sicherzustellen, insbesondere wenn sich eine Gruppe von Spielern in einem Kanal auf verschiedenen Geräten befindet.
Die SVC-Technologie (
Scalable Video Coding ), eine Erweiterung des H.264 / MPEG-4 AVC-Standards, kann eine Lösung für das Problem darstellen.
Screencasts benötigen aufgrund der höheren FPS und Auflösung als herkömmliche Webcams noch mehr Bandbreite als Video. Wir arbeiten derzeit an der Unterstützung der hardwarebasierten Videokodierung in einer Desktop-Anwendung.