
Dieser Leitfaden enthält strukturierte Entwurfsrichtlinien für skalierbare, ausfallsichere und leicht zugängliche Cloud-Anwendungen. Es soll Ihnen helfen, Entscheidungen über Ihre Architektur zu treffen, unabhängig davon, welche Cloud-Plattform Sie verwenden.
Das Handbuch ist in eine Abfolge von Schritten unterteilt: Auswählen einer Architektur → Auswählen von Technologien zum Berechnen und Speichern von Daten → Entwerfen einer Azure-Anwendung → Auswählen von Vorlagen → Überprüfen der Architektur. Für jeden von ihnen gibt es Empfehlungen, die Ihnen bei der Entwicklung der Anwendungsarchitektur helfen.
Heute veröffentlichen wir einen Teil des ersten Kapitels dieses Buches. Hier können Sie die Vollversion kostenlos herunterladen.
Inhaltsverzeichnis
- Die Wahl der Architektur - 1;
- Die Wahl der Technologien zum Berechnen und Speichern von Daten - 35;
- Entwerfen einer Azure-Anwendung: Entwurfsprinzipien - 60;
- Entwerfen einer Azure-Anwendung: Qualitätsindikatoren - 95;
- Entwerfen einer Azure-Anwendung: Entwurfsmuster - 103;
- Vorlagenverzeichnis - 110;
- Checklisten für die Architekturvalidierung - 263;
- Schlussfolgerung - 291;
- Azure-Referenzarchitekturen - 292;
Wahl der Architektur
Die erste Entscheidung, die Sie beim Entwerfen einer Cloud-Anwendung treffen müssen, ist die Auswahl einer Architektur. Die Wahl der Architektur hängt von der Komplexität der Anwendung, dem Umfang, ihrem Typ (IaaS oder PaaS) und den Aufgaben ab, für die sie vorgesehen ist. Es ist auch wichtig, die Fähigkeiten des Entwicklungsteams und der Projektmanager sowie die Verfügbarkeit einer vorgefertigten Architektur für die Anwendung zu berücksichtigen.
Die Wahl der Architektur unterwirft der Struktur der Anwendung bestimmte Einschränkungen, wodurch die Auswahl der Technologien und anderer Elemente der Anwendung eingeschränkt wird. Diese Einschränkungen sind sowohl mit Vor- als auch mit Nachteilen der ausgewählten Architektur verbunden.
Mithilfe der Informationen in diesem Abschnitt können Sie bei der Implementierung einer bestimmten Architektur ein Gleichgewicht zwischen ihnen finden. In diesem Abschnitt werden zehn zu beachtende Entwurfsprinzipien aufgeführt. Das Befolgen dieser Prinzipien hilft Ihnen dabei, eine skalierbarere, stabilere und verwaltbarere Anwendung zu erstellen.
Wir haben eine Reihe von Architekturoptionen identifiziert, die häufig in Cloud-Anwendungen verwendet werden. Der Abschnitt, der jedem von ihnen gewidmet ist, enthält:
- Beschreibung und Logik der Architektur;
- Empfehlungen zum Umfang dieser Architektur;
- Vor- und Nachteile sowie Anwendungsempfehlungen;
- Empfohlene Bereitstellungsoption mit geeigneten Azure-Diensten.
Architekturübersicht
Dieser Abschnitt bietet einen kurzen Überblick über die von uns identifizierten Architekturoptionen sowie allgemeine Empfehlungen für deren Verwendung. Weitere Informationen finden Sie in den entsprechenden Abschnitten, die über die Links verfügbar sind.
N-Level
Die N-Tier-Architektur wird am häufigsten in Unternehmensanwendungen verwendet. Um Abhängigkeiten zu verwalten, ist die Anwendung in Ebenen unterteilt, von denen jede für eine bestimmte logische Funktion verantwortlich ist, z. B. für die Darstellung von Daten, Geschäftslogik oder den Zugriff auf Daten. Eine Ebene kann andere Ebenen darunter aufrufen. Eine solche Unterteilung in horizontale Schichten kann jedoch zusätzliche Schwierigkeiten verursachen. Beispielsweise kann es schwierig sein, Änderungen an einem Teil der Anwendung vorzunehmen, ohne die anderen Elemente zu beeinflussen. Daher ist das Aktualisieren einer solchen Anwendung häufig nicht einfach, und Entwickler müssen seltener neue Funktionen hinzufügen.
Die N-Tier-Architektur ist eine natürliche Wahl, wenn bereits verwendete Anwendungen übertragen werden, die auf der Basis einer Tiered-Architektur erstellt wurden. Daher wird diese Architektur am häufigsten in IaaS-Lösungen (Infrastructure as a Service) oder in Anwendungen verwendet, die IaaS mit verwalteten Diensten kombinieren.

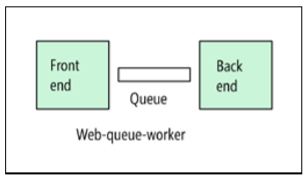
Webinterface - Warteschlange - Worker-Rolle
Für PaaS-Lösungen ist die Webschnittstellen-Warteschlangen-Arbeitsrollenarchitektur geeignet. Mit dieser Architektur verfügt die Anwendung über eine Weboberfläche, die HTTP-Anforderungen verarbeitet, und eine Server-Arbeitsrolle, die für Vorgänge verantwortlich ist, die lange dauern oder Rechenressourcen erfordern. Eine asynchrone Nachrichtenwarteschlange wird verwendet, um zwischen der Schnittstelle und der Serverarbeitsrolle zu kommunizieren.
Die Architektur „Webinterface - Warteschlange - Arbeitsrolle“ eignet sich für relativ einfache Aufgaben, die Rechenressourcen erfordern. Wie die N-Tier-Architektur ist dieses Modell leicht zu verstehen. Die Verwendung von verwalteten Diensten vereinfacht die Bereitstellung und den Betrieb. Beim Erstellen von Anwendungen für komplexe Themenbereiche kann es jedoch schwierig sein, Abhängigkeiten zu steuern. Die Weboberfläche und die Arbeitsrolle können leicht auf große monolithische Komponenten erweitert werden, die schwer zu warten und zu aktualisieren sind. Wie bei der N-Tier-Architektur zeichnet sich dieses Modell durch eine niedrigere Aktualisierungsrate und begrenzte Verbesserungsmöglichkeiten aus.
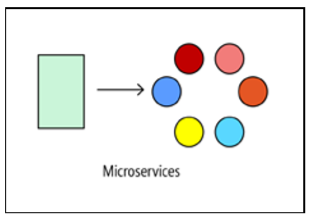
Microservices
Wenn die Anwendung komplexere Probleme lösen soll, versuchen Sie, sie auf der Grundlage der Microservices-Architektur zu implementieren. Eine solche Anwendung besteht aus vielen kleinen unabhängigen Diensten. Jeder Dienst ist für eine separate Geschäftsfunktion verantwortlich. Services sind lose gekoppelt und verwenden API-Verträge zur Interaktion.
Ein kleines Entwicklerteam kann daran arbeiten, einen separaten Service zu erstellen. Services können ohne komplexe Koordination zwischen Entwicklern bereitgestellt werden, sodass sie regelmäßig aktualisiert werden können. Die Microservice-Architektur ist schwieriger zu implementieren und zu verwalten als die beiden vorherigen Ansätze. Es erfordert eine ausgereifte Entwicklungsmanagementkultur. Wenn jedoch alles richtig organisiert ist, hilft dieser Ansatz, die Häufigkeit der Veröffentlichung neuer Versionen zu erhöhen, die Implementierung von Innovationen zu beschleunigen und die Architektur fehlertoleranter zu machen.
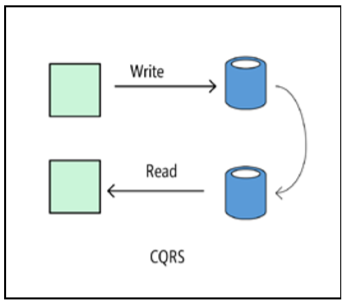
Cqrs
Die Architektur von CQRS (Command and Query Responsibility Segregation, Verteilung der Verantwortung zwischen Teams und Abfragen) ermöglicht es Ihnen, Lese- und Schreibvorgänge zwischen einzelnen Modellen zu trennen. Infolgedessen werden Teile des Systems, die für das Ändern von Daten verantwortlich sind, von Teilen des Systems isoliert, die für das Lesen von Daten verantwortlich sind. Darüber hinaus können Lesevorgänge in einer materialisierten Ansicht ausgeführt werden, die physisch von der Datenbank, in die geschrieben wird, getrennt ist. Auf diese Weise können Sie die Lese- und Schreibprozesse unabhängig skalieren und die materialisierte Präsentation für die Ausführung von Abfragen optimieren.
Das CQRS-Modell wird am besten für ein Subsystem einer größeren Architektur verwendet. Im Allgemeinen sollte es nicht auf die gesamte Anwendung angewendet werden, da dies die Architektur unnötig kompliziert. Es funktioniert gut in Kollaborationssystemen, in denen eine große Anzahl von Benutzern gleichzeitig mit denselben Daten arbeitet.
Ereignisbasierte Architektur
Eine ereignisbasierte Architektur verwendet ein Publishing-Subscribe-Modell, bei dem Lieferanten Ereignisse veröffentlichen und Verbraucher sie abonnieren. Lieferanten sind unabhängig von Verbrauchern, und Verbraucher sind unabhängig voneinander.
Eine ereignisbasierte Architektur eignet sich gut für Anwendungen, die große Datenmengen mit geringer Latenz schnell empfangen und verarbeiten müssen, z. B. das Internet der Dinge. Darüber hinaus funktioniert eine solche Architektur gut in Fällen, in denen verschiedene Subsysteme dieselben Ereignisdaten unterschiedlich verarbeiten müssen.

Big Data, Big Computing
Big Data und Big Computing sind spezielle Architekturoptionen, mit denen spezielle Probleme gelöst werden können. Bei Verwendung der Big-Data-Architektur werden große Datenmengen in Fragmente unterteilt, die dann zu Analyse- und Berichtszwecken parallel verarbeitet werden. Big Computing wird auch als High Performance Computing (HPC) bezeichnet. Mit dieser Technologie können Sie das Computing auf mehrere (Tausende) Prozessorkerne verteilen. Diese Architekturen können für Simulationen, 3D-Rendering und andere ähnliche Aufgaben verwendet werden.
Architekturoptionen als Einschränkungen
Architektur wirkt als Einschränkung beim Entwerfen einer Lösung, insbesondere bestimmt sie, welche Elemente verwendet werden können und welche Verbindungen zwischen ihnen möglich sind. Einschränkungen definieren die "Form" der Architektur und ermöglichen Ihnen die Auswahl aus einem engeren Satz von Optionen. Wenn die Einschränkungen der ausgewählten Architektur erfüllt sind, weist die Lösung Eigenschaften auf, die für diese Architektur charakteristisch sind.
Beispielsweise sind Microservices durch die folgenden Einschränkungen gekennzeichnet:
- Jeder Dienst ist für eine separate Funktion verantwortlich.
- Dienstleistungen sind unabhängig voneinander;
- Daten sind nur für den Dienst verfügbar, der dafür verantwortlich ist. Dienste tauschen keine Daten aus.
Das Befolgen dieser Einschränkungen führt zur Schaffung eines Systems, in dem Dienste unabhängig voneinander bereitgestellt werden können, Fehler isoliert werden, häufige Aktualisierungen möglich sind und neue Technologien leicht zur Anwendung hinzugefügt werden können.
Stellen Sie vor der Auswahl einer Architektur sicher, dass Sie die zugrunde liegenden Prinzipien und die damit verbundenen Einschränkungen gut verstehen. Andernfalls können Sie eine Lösung erhalten, die äußerlich mit dem ausgewählten Architekturmodell übereinstimmt, jedoch das Potenzial dieses Modells nicht vollständig aufzeigt. Der gesunde Menschenverstand ist ebenfalls wichtig. Manchmal ist es klüger, die eine oder andere Einschränkung aufzugeben, als nach einer sauberen Architektur zu streben.
Die folgende Tabelle zeigt, wie das Abhängigkeitsmanagement in jeder ihrer Architekturen implementiert ist und für welche Aufgaben diese oder jene Architektur am besten geeignet ist.

Analyse der Vor- und Nachteile
Einschränkungen verursachen zusätzliche Schwierigkeiten. Daher ist es wichtig zu verstehen, was Sie bei der Auswahl der einen oder anderen Architekturoption opfern müssen, und die Frage beantworten zu können, ob die Vorteile der ausgewählten Option die Nachteile für eine bestimmte Aufgabe in einem bestimmten Kontext überwiegen.
Nachfolgend sind einige der Nachteile aufgeführt, die bei der Auswahl einer Architektur zu berücksichtigen sind:
- Komplexität Ist die Verwendung komplexer Architektur für Ihre Aufgabe gerechtfertigt? Und umgekehrt, ist eine zu einfache Architektur für eine komplexe Aufgabe ausgewählt? In diesem Fall besteht die Gefahr, dass Sie ein System ohne klare Struktur erhalten, da die verwendete Architektur es Ihnen nicht ermöglicht, Abhängigkeiten korrekt zu verwalten.
- Asynchrones Messaging und letztendlich Konsistenz. Asynchrones Messaging hilft bei der Trennung von Diensten und verbessert die Zuverlässigkeit (dank der Möglichkeit, Nachrichten erneut zu senden) und die Skalierbarkeit. Es schafft jedoch gewisse Schwierigkeiten, wie die Semantik nur einer einzigen Übertragung und das Problem der Kohärenz auf lange Sicht.
- Interaktion zwischen Diensten. Wenn Sie die Anwendung in separate Dienste aufteilen, besteht das Risiko, dass der Datenaustausch zwischen den Diensten zu lange dauert oder zu einer Überlastung des Netzwerks führt (z. B. bei Verwendung von Microservices).
- Verwaltbarkeit. Wie schwierig wird es sein, die Anwendung zu verwalten, ihre Arbeit zu überwachen, Updates bereitzustellen und andere Aufgaben auszuführen?
N-Tier-Architektur
In der N-Tier-Architektur ist eine Anwendung in logische und physische Schichten unterteilt.
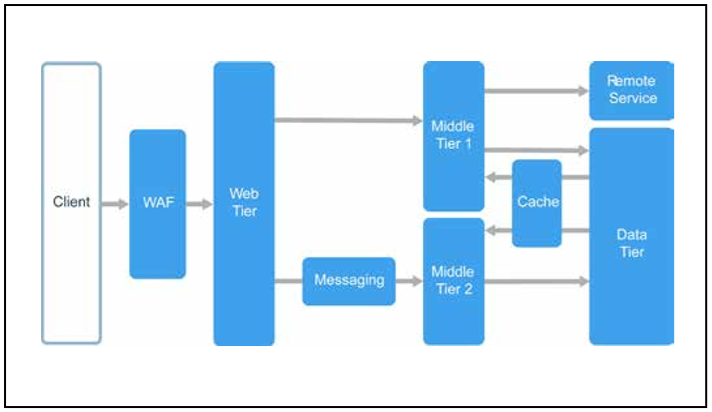
Ebenen sind ein Mechanismus zum Teilen von Verantwortung und zum Verwalten von Abhängigkeiten. Jede Schicht hat ihren eigenen Verantwortungsbereich. Ebenen auf höherer Ebene nutzen die Dienste von Ebenen auf niedrigerer Ebene, jedoch nicht umgekehrt.
Die Ebenen sind physisch getrennt und arbeiten auf verschiedenen Computern. Eine Ebene kann direkt oder über asynchrone Nachrichten (Nachrichtenwarteschlangen) auf die andere zugreifen. Obwohl jede Schicht auf einer eigenen Ebene platziert werden sollte, ist dies nicht erforderlich. Sie können mehrere Ebenen auf einer Ebene platzieren. Die physische Trennung der Ebenen macht die Lösung nicht nur skalierbarer und fehlertoleranter, sondern auch langsamer, da das Netzwerk häufig für die Interaktion verwendet wird. Eine herkömmliche dreistufige Anwendung besteht aus einer Präsentationsebene, einer Zwischenschicht und einer Datenbankebene. Eine Mittelstufe ist optional. Komplexere Anwendungen können aus mehr als drei Ebenen bestehen. Das obige Diagramm zeigt eine Anwendung mit zwei Zwischenstufen, die für verschiedene Funktionsbereiche verantwortlich sind.
Eine N-Tier-Anwendung kann eine Closed-Layer-Architektur oder eine Open-Layer-Architektur aufweisen.
- In einer geschlossenen Architektur kann eine beliebige Schicht nur auf die nächste untere Schicht zugreifen.
- In einer offenen Architektur kann sich eine beliebige Schicht auf beliebige untere Schichten beziehen.
Die Architektur mit geschlossenen Schichten begrenzt die Abhängigkeiten zwischen Schichten. Die Verwendung kann jedoch den Netzwerkverkehr übermäßig erhöhen, wenn eine bestimmte Schicht Anforderungen einfach an die nächste Schicht weiterleitet.
Architekturanwendungen
Die N-Tier-Architektur wird normalerweise in IaaS-Anwendungen verwendet, in denen jede Schicht auf einem separaten Satz virtueller Maschinen ausgeführt wird. Eine N-Tier-Anwendung muss jedoch keine reine IaaS-Anwendung sein. Es ist häufig praktisch, verwaltete Dienste für einige Komponenten einer Lösung zu verwenden, insbesondere für Caching, Messaging und Datenspeicherung.
In den folgenden Fällen wird eine N-Tier-Architektur empfohlen:
- einfache Webanwendungen;
- Portieren einer lokalen Anwendung nach Azure mit minimalem Refactoring
- Konsistente Bereitstellung von lokalen und Cloud-Anwendungen.
Die N-Tier-Architektur ist bei normalen lokalen Anwendungen üblich und eignet sich daher gut zum Portieren vorhandener Anwendungen nach Azure.
Die Vorteile
- Die Möglichkeit, Anwendungen zwischen der lokalen Bereitstellung und der Cloud sowie zwischen Cloud-Plattformen zu übertragen.
- Weniger Training für die meisten Entwickler.
- Eine natürliche Erweiterung des traditionellen Anwendungsmodells.
- Unterstützung für heterogene Umgebungen (Windows / Linux).
Nachteile
- Es ist einfach, eine Anwendung zu erhalten, in der die mittlere Schicht nur CRUD-Operationen in der Datenbank ausführt, wodurch die Verarbeitungszeit der Anforderungen verlängert wird und kein Nutzen entsteht.
- Die monolithische Architektur ermöglicht nicht die Entwicklung einzelner Komponenten durch unabhängige Entwicklungsteams.
- Das Verwalten einer IaaS-Anwendung ist zeitaufwändiger als das Verwalten einer Nur-Dienst-Anwendung.
- In großen Systemen kann es schwierig sein, die Netzwerksicherheit zu verwalten.
Empfehlungen
- Verwenden Sie die automatische Skalierung bei variabler Last. Siehe Best Practices für die automatische Skalierung.
- Verwenden Sie asynchrones Messaging, um Ebenen voneinander zu trennen.
- Semistatische Daten zwischenspeichern. Siehe Überlegungen zum Zwischenspeichern.
- Stellen Sie mit einer Lösung wie Always On Availability Groups in SQL Server eine hohe Verfügbarkeit auf Datenbankebene sicher.
- Installieren Sie eine Webanwendungs-Firewall (WAF) zwischen der Schnittstelle und dem Internet.
- Platzieren Sie jede Ebene in Ihrem eigenen Subnetz. Verwenden Sie Subnetze als Sicherheitsgrenzen.
- Beschränken Sie den Zugriff auf die Datenebene, indem Sie nur Abfragen von Zwischenebenen zulassen.
N-Tier-Architektur für virtuelle Maschinen
Dieser Abschnitt enthält Richtlinien zum Erstellen einer N-Tier-Architektur mit virtuellen Maschinen.

Dieser Abschnitt enthält Richtlinien zum Erstellen einer N-Tier-Architektur mit virtuellen Maschinen. Jede Schicht besteht aus zwei oder mehr virtuellen Maschinen, die in einem Verfügbarkeitssatz oder in einem skalierbaren Satz virtueller Maschinen gehostet werden. Die Verwendung mehrerer virtueller Maschinen bietet Fehlertoleranz bei Ausfall einer dieser Maschinen. Um Anforderungen zwischen virtuellen Maschinen derselben Ebene zu verteilen, werden Lastausgleichssubsysteme verwendet. Die Ebene kann horizontal skaliert werden, wodurch dem Pool neue virtuelle Maschinen hinzugefügt werden.
Jede Ebene befindet sich auch in einem eigenen Subnetz. Dies bedeutet, dass ihre internen IP-Adressen im gleichen Bereich liegen. Dies erleichtert das Anwenden von NSG-Regeln (Network Security Group) und Routing-Tabellen auf einzelne Ebenen.
Der Status der Webschicht und der Geschäftsschicht wird nicht überwacht. Jede virtuelle Maschine kann alle Anforderungen für diese Ebenen verarbeiten. Die Datenschicht muss aus einer replizierten Datenbank bestehen. Für Windows empfehlen wir die Verwendung von SQL Server mit Always On Availability Groups für eine hohe Verfügbarkeit. Für Linux sollten Sie eine Datenbank auswählen, die die Replikation unterstützt, z. B. Apache Cassandra.
Der Zugriff auf jede Ebene wird durch Netzwerksicherheitsgruppen (NSGs) eingeschränkt. Beispielsweise ist der Zugriff auf die Datenbankebene nur für die Geschäftsebene zulässig
Zusätzliche Funktionen
- Die N-Tier-Architektur muss nicht aus drei Ebenen bestehen. Komplexere Anwendungen verwenden tendenziell mehr Ebenen. Verwenden Sie in diesem Fall das Routing durch Schicht 7, um Anforderungen auf eine bestimmte Ebene umzuleiten.
- Ebenen begrenzen die Entscheidung hinsichtlich Skalierbarkeit, Zuverlässigkeit und Sicherheit. Es wird empfohlen, für Dienste mit unterschiedlichen Anforderungen für diese Merkmale unterschiedliche Ebenen zu verwenden.
- Verwenden Sie die automatische Skalierung mit skalierbaren Gruppen virtueller Maschinen.
- Suchen Sie nach Elementen in Ihrer Architektur, die Sie mit verwalteten Diensten ohne größere Umgestaltung implementieren können. Achten Sie insbesondere auf Caching, Messaging, Speicher und Datenbanken.
- Platzieren Sie die Anwendung zur Erhöhung der Sicherheit hinter dem Umkreisnetzwerk. Das Umkreisnetzwerk umfasst virtuelle Netzwerkkomponenten, die Sicherheit bieten, z. B. Firewalls und Paketinspektoren. Weitere Informationen finden Sie unter Perimeter Reference Network Architecture.
- Platzieren Sie für eine hohe Verfügbarkeit zwei oder mehr virtuelle Netzwerkkomponenten im Verfügbarkeitssatz und fügen Sie einen Load Balancer hinzu, um Internetanforderungen zwischen ihnen zu verteilen. Weitere Informationen finden Sie unter Bereitstellen virtueller Netzwerkkomponenten für Hochverfügbarkeit.
- Erlauben Sie keinen direkten Zugriff auf virtuelle Maschinen, auf denen Anwendungscode über die RDP- und SSH-Protokolle ausgeführt wird. Stattdessen sollten Bediener den Bastionsknoten betreten. Dies ist eine im Netzwerk befindliche virtuelle Maschine, die von Administratoren verwendet wird, um eine Verbindung zu anderen virtuellen Maschinen herzustellen. Auf dem Bastion-Host sind NSG-Regeln so konfiguriert, dass der Zugriff über RDP und SSH nur von genehmigten öffentlichen IP-Adressen möglich ist.
- Sie können das virtuelle Azure-Netzwerk mithilfe eines VPN-Typs (Network-to-Network) oder Azure ExpressRoute vom Typ Virtual Network (VPN) zu einem lokalen Netzwerk erweitern. Weitere Informationen finden Sie unter Referenzarchitektur für hybride Netzwerke.
- Wenn Ihre Organisation Active Directory für die Identitätsverwaltung verwendet, können Sie Ihre Active Directory-Umgebung auf das virtuelle Azure-Netzwerk erweitern. Weitere Informationen finden Sie unter Identity Management-Referenzarchitektur.
- Wenn eine höhere Verfügbarkeit erforderlich ist als in der Service Level Vereinbarung für Azure Virtual Machine vorgeschrieben, replizieren Sie die Anwendung zwischen den beiden Regionen und konfigurieren Sie Azure Traffic Manager für das Failover. Weitere Informationen finden Sie unter Starten von virtuellen Windows-Maschinen in mehreren Regionen und Starten von virtuellen Linux-Maschinen in mehreren Regionen.
Sie können die Vollversion des Buches kostenlos herunterladen und unter dem folgenden Link lesen.
→
Herunterladen