Die Zeit läuft davon und bald wird fast nichts mehr von dieser Entwicklung übrig sein, aber ich hatte immer noch keine Zeit, sie zu beschreiben.
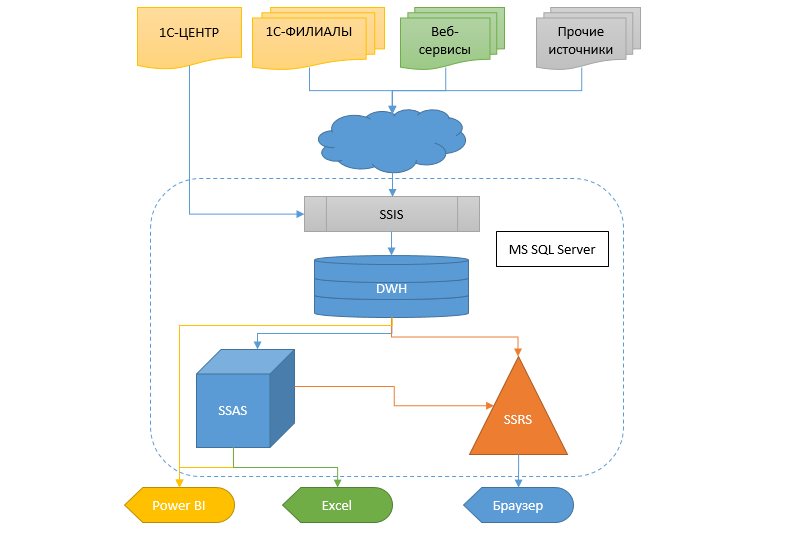
Es geht um ein Unternehmen auf Bundesebene mit einer Vielzahl von Niederlassungen und Unterzweigen. Aber wie immer hat alles vor langer Zeit mit einem kleinen Laden angefangen. Im Laufe der Jahre fand eine ziemlich schnelle und spontane Entwicklung statt, Zweigstellen, Abteilungen und andere Büros erschienen, und die IT-Infrastruktur wurde in jenen Tagen nicht angemessen berücksichtigt, und dies ist auch ein häufiges Ereignis. Natürlich wurde 1C77 überall verwendet, ohne dass eine Replikation und Skalierung erforderlich war. Daher kamen wir am Ende zu dem Schluss, dass ein Sprut-Frankenstein mit Tentakeln erzeugt wurde, die mit Klebeband gebunden waren - in jedem Zweig gab es eine autonome Mutante, die mit der zentralen Basis ausgetauscht wurde im "kniehohen" Modus nur wenige Nachschlagewerke, ohne die es überhaupt nicht möglich war, und der Rest ist autonom. Für einige Zeit begnügten sie sich mit Kopien (Dutzende von ihnen!) Von Zweigstellen in der Zentrale, aber die Daten in ihnen blieben mehrere Tage zurück.
Für die Realität ist es jedoch erforderlich, Informationen schneller und flexibler zu erhalten, und damit muss noch etwas anderes getan werden. Der Übergang von einem Buchhaltungssystem zu einem anderen in einer solchen Größenordnung ist immer noch ein Sumpf. Daher wurde beschlossen, ein Data Warehouse (DX) zu erstellen, in dem Informationen aus verschiedenen Datenbanken fließen, damit später andere Dienste und das Analysesystem in Form von Cubes, SSRS-Berichten und Leckagen Daten von dieser CD erhalten können.
Mit Blick auf die Zukunft werde ich sagen, dass der Übergang zu einem neuen Buchhaltungssystem fast abgeschlossen ist und der größte Teil des hier beschriebenen Projekts in naher Zukunft als unnötig gekürzt wird. Entschuldigung, aber nichts kann getan werden.
Das Folgende ist ein langer Artikel, aber bevor Sie mit dem Lesen beginnen, möchte ich darauf hinweisen, dass ich diese Entscheidung in keinem Fall als Standard übergebe, aber vielleicht findet jemand etwas Nützliches darin.
Ich beginne mit einer allgemeinen Herangehensweise an das Projekt, für das SSDT als Entwicklungsumgebung ausgewählt wurde, mit der anschließenden Veröffentlichung des Projekts in Git. Ich denke, dass es heute genug verschiedene Artikel und Tutorials gibt, die die Stärken dieses Tools beschreiben. Es gibt jedoch einige Punkte, deren Problem außerhalb dieser Umgebung liegt.
Speicherung von Aufzählungen und Datenbankversionen
In Bezug auf Versionen und Aufzählungen bedeuteten die Anforderungen für das Projekt:
- Bequemes Bearbeiten und Verfolgen von Änderungen in der Datenbankversion innerhalb des Projekts
- Bequemes Anzeigen der Datenbankversion über SSMS für Administratoren
- Speichern des Verlaufs von Versionsänderungen in der Datenbank selbst (wer und wann hat die Bereitstellung durchgeführt)
- Aufzählungen in einem Projekt speichern
- Einfache Bearbeitung und Verfolgung von Änderungen bei Übertragungen
- Datenbankbereitstellungssperre über einer vorhandenen, wenn keine inkrementelle Version vorhanden war
- Die Installation einer neuen Version, die Aufzeichnung des Verlaufs, der Übertragungen und die Umstrukturierung sollten in einer Transaktion durchgeführt und im Falle eines Ausfalls zu jedem Zeitpunkt vollständig zurückgesetzt werden
Weil Übertragungen enthalten häufig Logik und sind Grundwerte, ohne die das Hinzufügen von Datensätzen zu anderen Tabellen (aufgrund von FK-Fremdschlüsseln) unmöglich wird. Im Wesentlichen sind sie zusammen mit Metadaten Teil der Datenbankstruktur. Daher führt eine Änderung eines Aufzählungselements zu einer Erhöhung der Datenbankversion. Zusammen mit dieser Version muss garantiert werden, dass die Datensätze während der Bereitstellung aktualisiert werden.
Ich denke, alle Vorteile des Blockierens der Bereitstellung ohne Inkrementieren der Version liegen auf der Hand. Eine davon ist die Unfähigkeit, das Veröffentlichungsskript erneut auszuführen, wenn es bereits früher erfolgreich ausgeführt wurde.
Obwohl dem Datenbanknetzwerk häufig vorgeschlagen wird, nur die Hauptversion (ohne Brüche) zu verwenden, haben wir uns für Versionen im XY-Format entschieden, wobei Y der Patch ist, als ein Tippfehler in der Beschreibung der Tabelle, Spalte, des Namens des Auflistungselements oder etwas anderem Kleinen korrigiert wurde. B. Hinzufügen eines Kommentars zu einer gespeicherten Prozedur usw. In allen anderen Fällen wird die Hauptversion erstellt.
Vielleicht gibt es für jemanden nichts
dergleichen und alles ist offensichtlich. Aber ich habe zu gegebener Zeit ziemlich viel Nerven und Energie in interne Streitigkeiten über das Speichern von Übertragungen im Datenbankprojekt gesteckt, so dass es Feng Shui war (
gemäß meiner Vorstellung davon ) und es bequem war, mit ihnen zu arbeiten. bei gleichzeitiger Minimierung der Fehlerwahrscheinlichkeit.
Bei Übertragungen ist im Allgemeinen alles einfach: Wir erstellen eine PostDeploy-Datei im Projekt und schreiben Code darin, um die Tabellen zu füllen. Mit Merges oder Trankates - so gefällt es Ihnen. Wir haben es vorgezogen zu blinken und vorab zu prüfen, ob die Anzahl der Datensätze in der Zieltabelle die Anzahl der Datensätze in der Quelle (im Projekt) überschreitet. Wenn es überschreitet, wird eine Ausnahme ausgelöst, um die Aufmerksamkeit darauf zu lenken, weil es seltsam ist. Warum enthält die Quelle weniger Datensätze? Weil man überflüssig ist? Warum plötzlich? Und wenn die Datenbank bereits Links dazu hat? Obwohl wir Fremdschlüssel (FK) verwenden, mit denen Sie den Datensatz nicht löschen können, lassen wir diese Option lieber, wenn Links dazu vorhanden sind. Infolgedessen wurde PostDeploy zu einem unlesbaren Blatt, da für jede zu füllende Tabelle zusätzlich zu den Werten selbst auch ein Bestätigungscode, eine Zusammenführung usw. vorhanden ist.
Wenn Sie jedoch PostDeploy im SQLCMD-Modus verwenden, können Codeblöcke in separate Dateien extrahiert werden. Daher bleibt nur eine strukturierte Liste von Dateinamen übrig, um die Aufzählungen in PostDeploy auszufüllen.
Es gibt einige Nuancen bei Datenbankversionen. Das Internet hat lange darüber diskutiert, wo die Datenbankversion gespeichert werden soll, wie sie aussehen soll und ob sie im Allgemeinen irgendwo gespeichert werden muss. Angenommen, wir entscheiden, dass wir es brauchen, an welchem Ort des Projekts, um es zu speichern? Irgendwo in der Wildnis eines PostDeploy-Skripts oder in einer Variablen, die in der ersten Zeile des Skripts deklariert ist?
Meiner Meinung nach weder der eine noch der andere. Es ist bequemer, wenn es in einer separaten Datei gespeichert ist und dort nichts mehr vorhanden ist.
Jemand wird sagen - in den Projekteigenschaften befindet sich Dacpac, und Sie können die Version darin festlegen. Natürlich können Sie diese Version auch in Ihr Skript ziehen, wie
hier beschrieben, aber dies ist unpraktisch - um die Datenbankversion zu ändern, müssen Sie irgendwo weit gehen und auf eine Reihe von Schaltflächen klicken. Ich verstehe die Logik von Microsoft nicht - sie haben sie in einer entfernten Ecke versteckt, zusammen mit Datenbankparametern wie Sortierung, Kompatibilitätsstufe usw., weil sich die Datenbankversion so "oft" ändert wie die Sortierparameter, oder? Bei ständiger Entwicklung wird die Version mit jeder neuen Bereitstellung aufgebaut. Die Bequemlichkeit der Nachverfolgung von Änderungen spielt ebenfalls eine wichtige Rolle. Wenn eine geänderte Datei mit einem Anzeigenamen leuchtet, ist dies eine Sache, und wenn die .sqlproj-Projektdatei leuchtet, in der viele Zeilen im XML-Format vorhanden sind und unter ihnen irgendwo in der Mitte der Zeile wird eine geänderte Ziffer hervorgehoben, irgendwie nicht sehr.
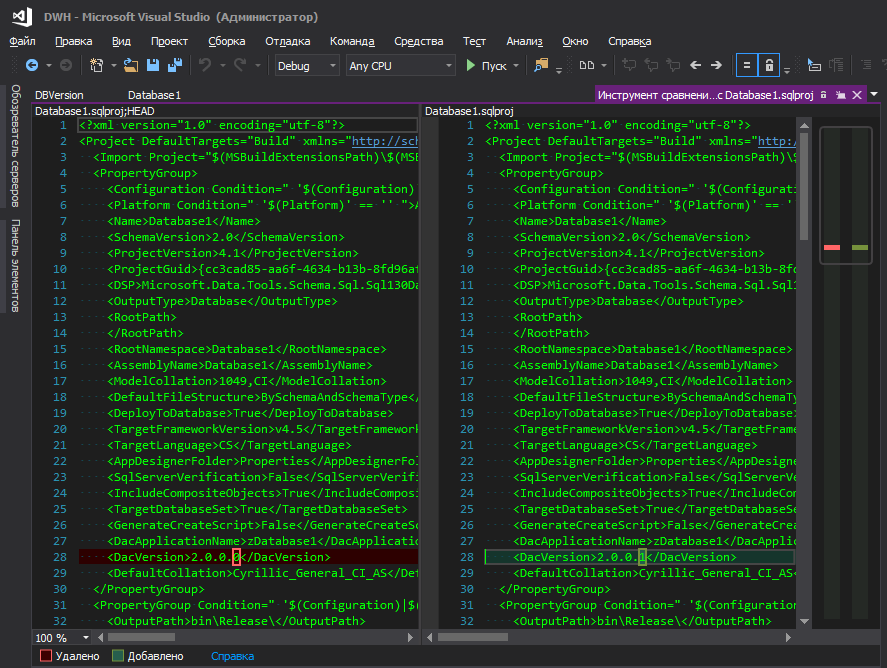
So ist es besser
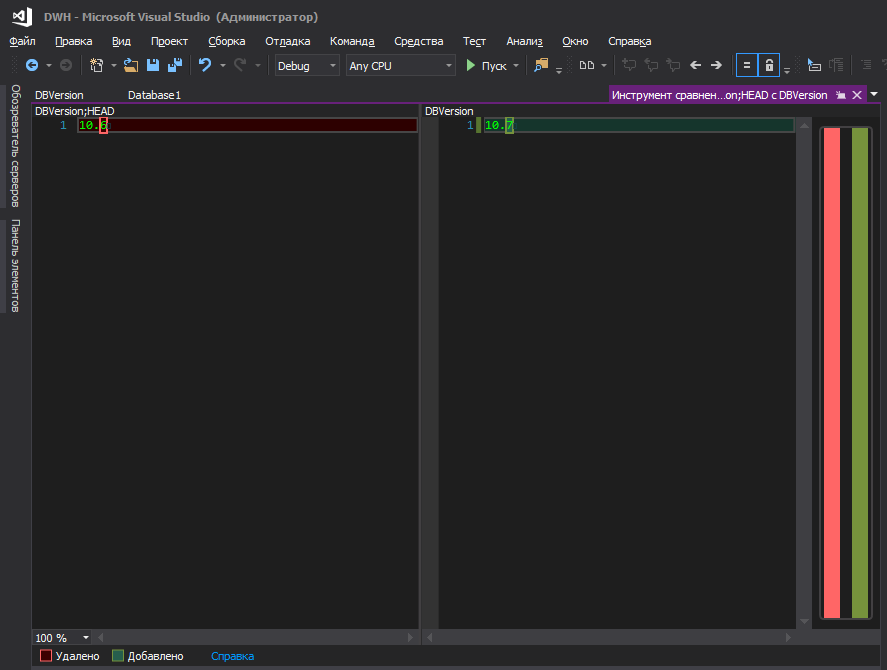
Vielleicht sind dies jedoch nur meine Kakerlaken, und Sie sollten nicht auf sie achten.
Die Frage ist nun: Wo soll diese Version bereits in der bereitgestellten Datenbank gespeichert werden? Wieder scheint es, dass dacpac es wunderbar macht - es schreibt alles auf die Systemplatten, aber um die Version zu sehen, müssen Sie die Anforderung ausführen (oder kann es anders sein, aber ich weiß nur nicht, wie man sie kocht? Es scheint, dass es in älteren Versionen von SSMS eine Schnittstelle dafür gab, und jetzt Nein)
select * from msdb.dbo.sysdac_instances_internal
Für den Administrator (und nicht nur) ist es nicht sehr praktisch. Es ist viel logischer, dass die Version direkt in den Eigenschaften der Datenbank selbst angezeigt wird.

Oder nicht?
Dazu müssen Sie dem im Build enthaltenen Projekt eine Datei hinzufügen, in der die erweiterten Eigenschaften beschrieben werden
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = '';
Ja, sie sind leer und in einem Veröffentlichungsskript sieht es hässlich aus, aber Sie können nicht ohne sie auskommen. Wenn sie nicht im Projekt beschrieben sind und sich in der Datenbank befinden, versucht das Studio, sie bei jeder Bereitstellung zu löschen. (Es gab viele Versuche, dies kurz und bündig und ohne unnötige Bereitstellungsoptionen zu umgehen, aber ohne Erfolg)
Wir werden die Werte für sie im PostDeploy-Skript festlegen.
declare @username varchar(256) = suser_sname() ,@curdatetime varchar(20) = format(getdate(),'dd.MM.yyyy HH:mm:ss') EXECUTE sp_updateextendedproperty @name = N'DeployerName', @value = @username; EXECUTE sp_updateextendedproperty @name = N'DBVersion', @value = [$(DBVersion)]; EXECUTE sp_updateextendedproperty @name = N'DeploymentDate', @value = @curdatetime;
sp_updateextendedproperty ohne Überprüfung aus, da zum Zeitpunkt des Starts des Blocks von PostDeploy aus alle Eigenschaften bereits erstellt wurden, wenn sie nicht vorhanden waren.
Nun, es wäre schön, den Verlauf darüber zu führen, wer und wann die Datenbank bereitgestellt hat.
Die Bereitstellung von Metadatenänderungen kann in der Transaktion mithilfe von Standardtools durchgeführt werden, indem das Kontrollkästchen
Transaktionsskripts aktivieren im Fenster
Erweiterte Veröffentlichungsoptionen aktiviert wird. Dieses Flag wirkt sich jedoch nicht auf die Bereitstellung der Skripte (Pre / Post) aus und sie werden weiterhin ohne Transaktion ausgeführt. Natürlich hindert nichts die Transaktion daran, am Anfang des PostDeploy-Skripts zu beginnen, aber es handelt sich um eine Transaktion, die von den Metadaten getrennt ist, und wir haben die Aufgabe, die Metadatenänderungen zurückzusetzen, wenn in PostDeploy eine Ausnahme aufgetreten ist.
Die Lösung ist einfach: Starten Sie die Transaktion in PreDeploy und schreiben Sie sie in PostDeploy fest. Verwenden Sie für diese Zwecke keine Häkchen in den Veröffentlichungseinstellungen.
Um die Datenbankversion bequem im Projekt zu speichern und während der Bereitstellung an den gewünschten Stellen zu registrieren, können Sie auf die SQLCMD-Variablen zurückgreifen. Ich möchte die Version jedoch nicht irgendwo in der Wildnis des Codes speichern, sondern an der Oberfläche.
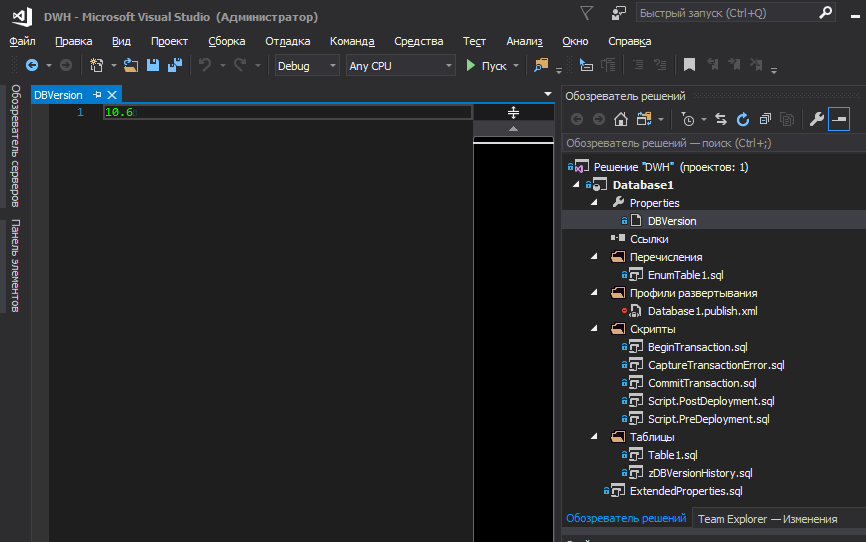
Um die Datenbankversion in einer separaten Datei abzulegen und die Version von dort auf Projektebene zu verwalten, fügen wir .sqlproj den folgenden Block hinzu:
<Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\Properties\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)" Overwrite="true" /> </Target> </Target>
Dies ist eine Anweisung für MSBuild, vor dem Erstellen eine Zeile aus einer Datei zu lesen und eine temporäre Datei basierend auf den gelesenen Daten zu erstellen. MSBuild erstellt eine temporäre Datei
SetPreDepVarsTmp.sql , die
:setvar DBVersion $(ExtDBVersion) Zeile
:setvar DBVersion $(ExtDBVersion) , wobei
$(ExtDBVersion) der aus unserer Datei gelesene Wert ist, in dem die Version der Datenbank gespeichert ist.
Nach solchen Manipulationen können Sie im PreDeploy-Skript auf diese temporäre Datei verweisen und die darin enthaltene globale Transaktion starten:
:r .\SetPreDepVarsTmp.sql go :r ".\BeginTransaction.sql"
ZwischenversionAnfänglich wurden der Datei ExtendedProperties.sql keine leeren Werte zugewiesen, sondern Werte aus Variablen
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = [$(DeployerName)]; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = [$(DeploymentDate)]; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = [$(DBVersion)];
Variablen wiederum wurden von MSBuild automatisch wie folgt automatisch in der Datei SetPreDepVarsTmp.sql registriert:
<PropertyGroup> <CurrentDateTime>$([System.DateTime]::Now.ToString(dd.MM.yyyy HH:mm:ss))</CurrentDateTime> </PropertyGroup> <PropertyGroup> <NewLine> -- </NewLine> </PropertyGroup> <Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)$(NewLine):setvar DeploymentDate "$(CurrentDateTime)"$(NewLine):setvar DeploymentUser $(UserDomain)\$(UserName)" Overwrite="true" /> </Target>
Bei diesem Ansatz müssen Sie diese Eigenschaften nicht in PostDeploy neu installieren. Das Problem besteht jedoch darin, dass SetPreDepVarsTmp.sql statische Werte enthielt und das Veröffentlichungsskript jetzt generiert, aber in einer Stunde oder, noch schlimmer, am nächsten Tag bereitgestellt wurde (der Entwickler hat es lange Zeit überprüft) Zum Beispiel visuell) unterscheidet sich das in den Eigenschaften angegebene Veröffentlichungsdatum vom tatsächlichen Veröffentlichungsdatum und stimmt nicht mit dem Datum in der Historie überein.
Inhalt der BeginTransaction.sql-DateiIm Wesentlichen handelt es sich hierbei nur um das Kopieren und Einfügen aus dem Standard-Transaktionsstartblock, den das Studio generiert, wenn das Kontrollkästchen
Transaktionsskripte aktivieren aktiviert ist. Wir verwenden es jedoch auf unsere eigene Weise. Im Skript wurde nur der Name der temporären Tabelle von
#tmpErrors in
#tmpErrorsManual geändert, sodass kein Namenskonflikt besteht, wenn jemand das Kontrollkästchen
#tmpErrorsManual .
IF (SELECT OBJECT_ID('tempdb..#tmpErrors')) IS NOT NULL DROP TABLE
PostDeploy-Skript declare @TableName VarChar(255) = null
Mit der Variablen SkipEnumDeploy können Sie, wie bereits klar geworden ist, die Phase der Aktualisierung von Listen überspringen. Dies kann bei geringfügigen kosmetischen Änderungen hilfreich sein. Obwohl dies aus religiöser Sicht möglicherweise nicht zutrifft, ist es in der Entwicklungsphase definitiv nützlich.
Die Dateien
CaptureTransactionError.sql und
CommitTransaction.sql CaptureTransactionError.sql ebenfalls (mit geringfügigen Änderungen) aus dem Standardtransaktionsalgorithmus
CaptureTransactionError.sql und
CommitTransaction.sql , den das Studio generiert, wenn das obige Flag gesetzt ist und den wir jetzt selbst spielen.
Inhalt CaptureTransactionError.sql IF @@ERROR <> 0 AND @@TRANCOUNT > 0 BEGIN ROLLBACK; END IF @@TRANCOUNT = 0 BEGIN INSERT INTO
CommitTransaction.sql-Inhalt Inhalt EnumTable1.sql set @TableName = N'Table1' PRINT N' '+@TableName+'...' begin try set nocount on drop table if exists
Bei der Bereitstellung von
Publish Skript die folgende Struktur
Idealerweise möchte ich natürlich, dass die Version zum Zeitpunkt der Veröffentlichung angezeigt wird

Sie können den Wert jedoch nicht aus der Datei in dieses Fenster ziehen, obwohl MSBuild ihn liest und mithilfe zusätzlicher Anweisungen in der .sqlproj-Datei in die ExtDBVersion-Eigenschaft einfügt, wie im obigen Beispiel, sondern in der Konstruktion
<SqlCmdVariable Include="DBVersion"> <DefaultValue> </DefaultValue> <Value>$(ExtDBVersion)</Value> </SqlCmdVariable>
rollt nicht.
Die Nachfolger der Entwickler in ihrem
Web-Tagebuch schreiben, wie das gemacht wird. Entsprechend ihrer Version liegt die Magie in der Anweisung
SqlCommandVariableOverride , die einfach ist - fügen Sie der .sqlproj-Projektdatei ein paar Zeilen hinzu
<ItemGroup> <SqlCommandVariableOverride Include="DBVersion=$(ExtDBVersion)" /> </ItemGroup>
und fertig. Netter Versuch, aber nein. Vielleicht hat bei der Veröffentlichung dieses Blogposts alles funktioniert, aber seitdem haben Sie in Amerika drei Präsidentschaftswahlen abgehalten, und niemand weiß, welche Anweisungen morgen möglicherweise nicht mehr funktionieren.

Und
hier versuchte ein Kamerad alle Optionen, aber keiner von ihnen startete.
Nehmen Sie daher entweder die Version von dacpac oder speichern Sie sie in PostDeploy oder in einer separaten Datei oder _________ (geben Sie Ihre Version ein).
Integration mit 1C
Das erste Problem war, dass 1C77 keinen Anwendungsserver oder anderen Dämon hat, mit dem es interagieren kann, ohne die Plattform zu starten. Diejenigen, die mit 1C77 gearbeitet haben, wissen, dass sie keinen vollständigen Konsolenmodus hat. Sie können die Plattform mit Parametern ausführen und sogar etwas basierend darauf tun, aber es gibt nur sehr wenige Konsolenparameter und ihr Zweck war unterschiedlich. Aber auch mit ihrer Hilfe können Sie einen ganzen Mähdrescher nakolkhozit. Es kann jedoch unvorhersehbar herausfliegen, ein modales Fenster öffnen und darauf warten, dass jemand auf OK und andere Reize klickt. Und vielleicht das größte Problem - die Geschwindigkeit der Plattform lässt zu wünschen übrig ... Daher gibt es nur eine Lösung - direkte Abfragen an die 1C-Datenbank. Angesichts der Struktur können Sie diese Abfragen nicht einfach annehmen und schreiben, aber der Vorteil ist, dass es eine ganze Community gibt, die einmal ein wunderbares Tool entwickelt hat - 1C ++ (1cpp.dll), was für sie unglaublich ist. DANKE! In der Bibliothek können Sie Abfragen in Form von 1C schreiben, die dann in echte Namen von Tabellen und Feldern umgewandelt werden. Wenn jemand es nicht weiß, kann die Anfrage unter Verwendung eines Pseudonamens geschrieben werden und es wird so aussehen
select from $.
Eine solche Anfrage ist für Menschen verständlich, aber es gibt keine solche Tabelle und kein solches Feld auf dem Server, es gibt andere Namen, also wird 1C ++ daraus
select SP5278 from SC2235
und eine solche Anfrage wird vom Server bereits verstanden. Jeder ist glücklich, niemand schwört - weder eine Person noch ein Server. Hier scheint das Problem behoben zu sein.
Das zweite Problem lag in der Konfigurationsebene: Eine Konfiguration wurde in den Filialen verwendet, eine andere in der Zentrale und die dritte in den Filialen! Klasse? !! 1 Ich denke auch. Darüber hinaus sind sie kein typisches und nicht einmal typisches Erbe, sondern wurden während der Wikinger von Grund auf neu geschrieben, und leider haben nicht die besten Architekten den Grundstein für diese ... Die Implementierung von Dokumenten hat beispielsweise in jeder Konfiguration unterschiedliche Details. Aber nicht nur die Namen einiger Felder unterscheiden sich, was viel mehr Spaß macht, wenn die Namen der Details gleich sind, sondern die Bedeutung der darin gespeicherten Daten ist UNTERSCHIEDLICH.

In den Konfigurationen werden fast keine Register verwendet, alles baut auf den Feinheiten von Dokumenten auf. Daher musste ich manchmal ein ganzes Blatt für eine saubere Transaktion mit einer Reihe von Fällen und Verknüpfungen schreiben, um die Logik einer Prozedur aus der Konfiguration zu wiederholen, die einige Informationen im Textfeld des Formulars anzeigt.
Wir müssen dem Entwicklungsteam Tribut zollen, das all die Jahre das unterstützt hat, was es von den "Implementierern" geerbt hat. Es ist eine große Aufgabe - dies zu unterstützen und sogar etwas zu optimieren. Bis Sie sehen - Sie verstehen nicht, ich selbst habe zunächst nicht geglaubt, dass alles so kompliziert sein könnte. Fragen Sie - warum nicht von Grund auf neu schreiben? Banaler Mangel an Ressourcen. Das Unternehmen entwickelte sich so schnell, dass sie trotz eines großen Teams von Programmierern einfach nicht mit den Anforderungen des Unternehmens Schritt halten konnten, ganz zu schweigen von der Neufassung des gesamten Konzepts.
Wir setzen die Geschichte der Anfragen fort. Offensichtlich wurden alle Blöcke für die Datenextraktion zu Speichern, damit sie später auf der Serverseite unter Umgehung der 1C-Plattform gestartet werden konnten. Die Regel lautete: Ein Speicher ist für das Abrufen einer Entität verantwortlich. Weil Die Wunschliste in der Startphase hat sich bereits sehr angesammelt, da sie im Laufe der Jahre schmerzhaft geworden ist. Dann haben sich Dutzende von Speicherdateien herausgestellt.
Das dritte Problem ist, wie man die Geschwindigkeit und Qualität der Entwicklung erhöht und wie man dann all dieses Monster unterstützt. Schreiben Sie eine Anfrage für 1C ++ und kopieren Sie das Ergebnis der Konvertierung in einen Speicher? Es ist sehr unpraktisch und langwierig, außerdem besteht eine hohe Fehlerwahrscheinlichkeit - kopieren Sie die falsche oder die falsche oder wählen Sie nicht die letzte Zeile der Abfrage aus und kopieren Sie ohne diese. Dies gilt insbesondere für direkte 1C-Abfragen, da es keinen Pseudonamen wie
Directory gibt. Nomenklatur. Artikel, nur echte Namen
SC2235.SP5278 und daher das Kopieren einer Anfrage aus dem Warenverzeichnis in ein Geschäft, das Kunden abruft, ist sehr einfach. Natürlich wird die Anforderung höchstwahrscheinlich aufgrund der Nichtübereinstimmung von Typen und Anzahl der Felder in der Zieltabelle fallen, aber es gibt identische Kennzeichen, z. B. Aufzählungen, bei denen nur zwei Spalten ID und Name sind. Im Allgemeinen bleibt nur eine Art von Automatisierung anzuwenden. Nun, genug Texte, lasst uns zur Sache kommen!
Ich wollte, dass der Speicherentwicklungsprozess wie folgt abläuft:
- Wir korrigieren die SQL-Abfrage mit Pseudonamen und speichern sie
- Wir drücken einen magischen Knopf und am Ausgang erhalten wir die korrigierte gespeicherte Prozedur auf dem konvertierten SQL, die für den Server freigegeben ist
Einige Details
Um das dritte Problem zu lösen, wurde eine externe Verarbeitung (.ert) geschrieben. Es gibt eine Reihe von Prozeduren in der Verarbeitung, von denen jede den Abfragetext zum Extrahieren einer Entität unter Verwendung eines Pseudonamens enthält, wie z
select * from $.
Auf dem Verarbeitungsformular gibt es ein Feld zum Anzeigen des Ergebnisses einer bestimmten Prozedur, d.h. Anfrage in ein für den Server verständliches Formular konvertiert, damit Sie es schnell ausprobieren können. Außerdem wird dieser Anforderung immer ein
Debug-Block hinzugefügt, der die Deklaration von Variablen, die Namen von Testdatenbanken, Servern und mehr enthält. Es bleibt nur das Kopieren und Einfügen in SSMS und das Drücken von F5. Sie können diese Anforderung natürlich über die Verarbeitung selbst ausführen, aber den Anforderungsplan und all das, na ja, Sie verstehen ... Im Allgemeinen erfolgt das Debuggen auf diese Weise. Weil Es gibt verschiedene Konfigurationen. Bei der Verarbeitung ist es möglich, dieselben Abfragetexte mit Pseudonamen von Objekten in endgültige Abfragen für verschiedene Konfigurationen zu konvertieren. In der Tat ist in einer Konferenz die Nomenklatur SC123 und in einer anderen - SC321. Mit 1C ++ können Sie jedoch zur Laufzeit verschiedene Konfigurationen laden und für jede eine entsprechende Ausgabe gemäß dem Wörterbuch generieren.
Als nächstes wurde der Verarbeitung ein Stapellaufmodus hinzugefügt, in dem jede der Prozeduren für jede Konfiguration automatisch gestartet wird und die Ausgabe jeder dieser Prozeduren in SQL-Dateien (im Folgenden die Basisdateien) geschrieben wird. Auf diese Weise erhalten wir eine Reihe von Kombinationen von Basisdateien, die anschließend mithilfe von VS automatisch in gespeicherte Prozeduren umgewandelt werden sollen. Es ist erwähnenswert, dass die Basisdateien
einen Debug-Block enthalten .
Es scheint, warum nicht sofort eine Schlussfolgerung zu den endgültigen Dateien der gespeicherten Prozeduren ziehen und alles in dieser Verarbeitung behalten? Tatsache ist, dass für einige Tests Debug-Versionen von Abfragen in Stapeln ausgeführt werden müssen, in denen alle Variablen deklariert sind. Außerdem wollte ich, dass die Namen der gespeicherten Prozeduren von VS aus unter Umgehung von 1C verwaltet werden, da dies logisch ist, nicht wahr?
Übrigens werden die Basisdateien auch im Projekt gespeichert, natürlich auch die Dateien der vorgefertigten gespeicherten Prozeduren. Ohne 1C zu starten, können Sie die Basisdatei jederzeit in SSMS öffnen und ausführen, ohne sich um Variablendeklarationen zu kümmern.
Bei der Verarbeitung sind alle Prozeduren mit Anforderungen auch Vorlagen mit demselben Parametersatz, aber in dieser oder jener Prozedur werden nur die erforderlichen Parameter verwendet. In einigen Fällen ist alles involviert, und in einigen Fällen reichen zwei aus. Wenn Sie also eine neue Prozedur hinzufügen, müssen Sie die Vorlage kopieren und die Parameter mit den Abfragen selbst ausfüllen.
Der Code einer der Verarbeitungsprozeduren, die sich danach in eine gespeicherte Prozedur verwandeln
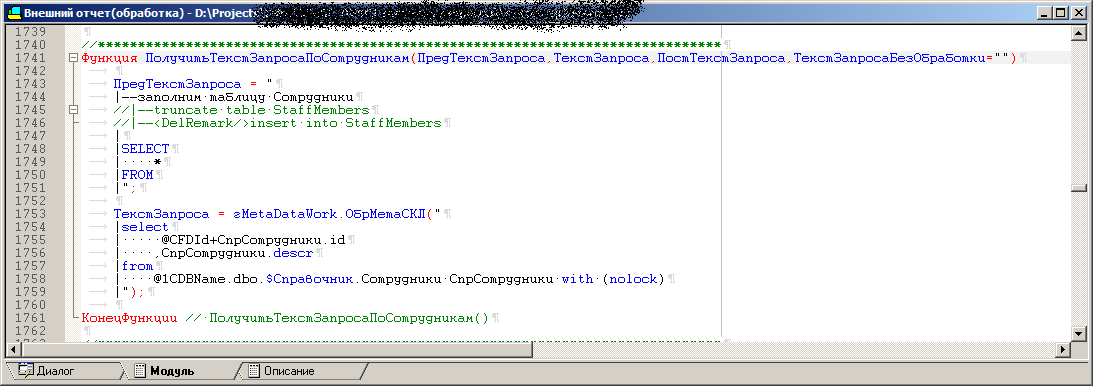
Die letzte Abfrage sieht ungefähr so aus:
++"("+OPENQUERY()+")"+
Aussehen der Verarbeitung

Beim Wechseln der Konfiguration ändert sich die Liste der verfügbaren (erforderlichen) Elemente zum Entladen von Elementen in der Datenliste. Wenn möglich, wurde der Prozedurcode in 1C so weit wie möglich vereinheitlicht. Wenn Gegenparteien extrahiert werden und diese Verzeichnisse in unterschiedlichen Konfigurationen inkonsistent sind, gibt es innerhalb der Generierungsprozedur verschiedene Fälle, z. B.: Dieser Block ist für alle festgelegt, dieser wird nur für eine solche Konfiguration zur endgültigen Anforderung hinzugefügt, und es gibt einen für die andere. Es stellt sich heraus, dass sich gespeicherte Prozeduren für eine Entität, aber unterschiedliche Konfigurationen nicht nur durch Tabellennamen unterscheiden können, sondern auch durch ganze Verknüpfungsblöcke, die in einer vorhanden sind und in einer anderen fehlen. Die Menge der Ausgabefelder ist natürlich dieselbe und entspricht der Empfängertabelle oder dem Container des SSIS-Pakets. Einige Felder sind mit Stubs für Konfigurationen verstopft, bei denen diese Details im Prinzip nicht vorliegen.
Magischer KnopfVisual Studio verfügt über Tools wie MSbuild und die fantastischen T4-Vorlagen. Daher wurde als magischer Knopf ein Skript in C # für T4 geschrieben, das:
- Registriert eine leere Konfiguration in der Registrierung (andernfalls zeigt 1C ein modales Fenster mit einem Vorschlag zum Registrieren einer Conf an und wartet auf Benutzeraktionen).
- Erstellt eine leere Datenbank für diese Konf auf dem SQL Server, da 1C ohne diese Datei einen Fehler ausgibt
- Startet 1C und weist OLE an, die Verarbeitung auszuführen (dieselbe .ert) und eine eindeutige GUID an 1C zu übertragen
- Die Ausgabe besteht aus einer Reihe von Dateien mit vorgefertigten (konvertierten) Anforderungen und einer Markierungsdatei, in die die beim Start empfangene GUID geschrieben wird
- Die Registrierung der conf wird aus der Registrierung gelöscht und eine temporäre leere Datenbank wird vom Server gelöscht
- Überprüft den Inhalt der Token-Datei. Wenn die Markierungsdatei die GUID enthält, die wir beim Start an 1C übergeben haben, bedeutet dies, dass sie bis zum Ende funktioniert hat, nicht abgestürzt ist usw., dann fahren Sie mit dem nächsten Schritt fort, oder es wird ein Fehler angezeigt
- Wir schaffen Lager.
- Wir dekompilieren die .ert-Datei mit gcomp, um die Modultexte und Verarbeitungsformulare zu erhalten. Nun, wir konvertieren in Unicode, um sie anschließend an Git zu senden und dort korrekt anzuzeigen. Für diejenigen, die nicht mit 1C gearbeitet haben: Die .ert-Datei ist eine Binärdatei, und das Studio bläst zusammen mit dem Git, dass die .ert-Datei geändert wurde, aber es ist nicht klar, was genau sich darin geändert hat. Vielleicht hat nur jemand die Schaltfläche einen Pixel nach links verschoben (welche ohne Begründung inakzeptabel)
T4 , ( , ) . , . , , , , - — 1.
, , , , , . — 1, 1, - .
: ?
- / ;
- VS , ;
- 4;
. Fertig.
?Weil , , .sqlproj,
<ItemGroup> <None Include=" \1.sql"> <None Include=" \2.sql"> <None Include=" \3.sql"> </ItemGroup>
Ein
<ItemGroup> <Content Include=" \*.sql" /> </ItemGroup>
« ». , , , :)
, , (, ) . ( ), , - - - , .
, . . , , , , , ( ), . , ( , ) , , , . , . , , , , , ( , 1, , MD ).
,
OPENQUERY , 1 , , , ,
EXEC .
OPENQUERY , , , .
177 ( ) SQL2000, varchar(max) , varchar(8000), 9, … , EXEC(@SQL1+@SQL2). , SQL2016, SQL2000. , , .
select ... from ( select ... from @1CDBName.dbo.$. join @1CDBName.dbo.$. join ... where xxx = 'hello!' ^
CREATE PROCEDURE [dbo].[SP1] @LinkedServerName varchar(24) ,@1CDBName varchar(24) AS BEGIN Declare @TSQL0 varchar(8000), @TSQL1 varchar(8000), @TSQL2 varchar(8000) set @TSQL0=' select ... from OPENQUERY('+@LinkedName+','' select ... from '+@1CDBName+'.dbo.DH123. join '+@1CDBName+'.SC123. ... where '; set @TSQL1=' xxx = ''''hello!'''' join ... join ... )'' join ... '''; set @TSQL2=' ... EXEC(@TSQL0+@TSQL1+@TSQL2) END
ETL
, ( ). (Stage). , ETL SSIS , , , , . . ( ), .
, ( ) , , (.. ), , .
, , . , . zabbix.
.
Weil 1 , , . , ,
truncate .
, ( ) -, « 1-» .
SSIS
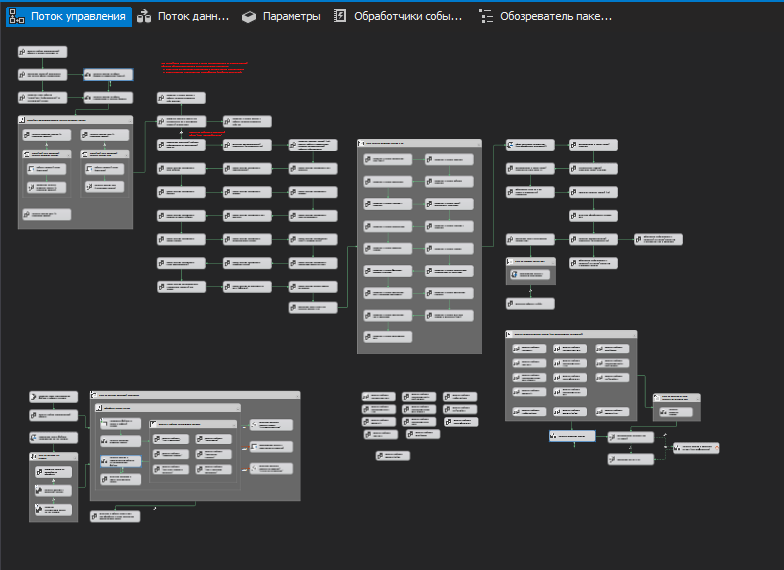
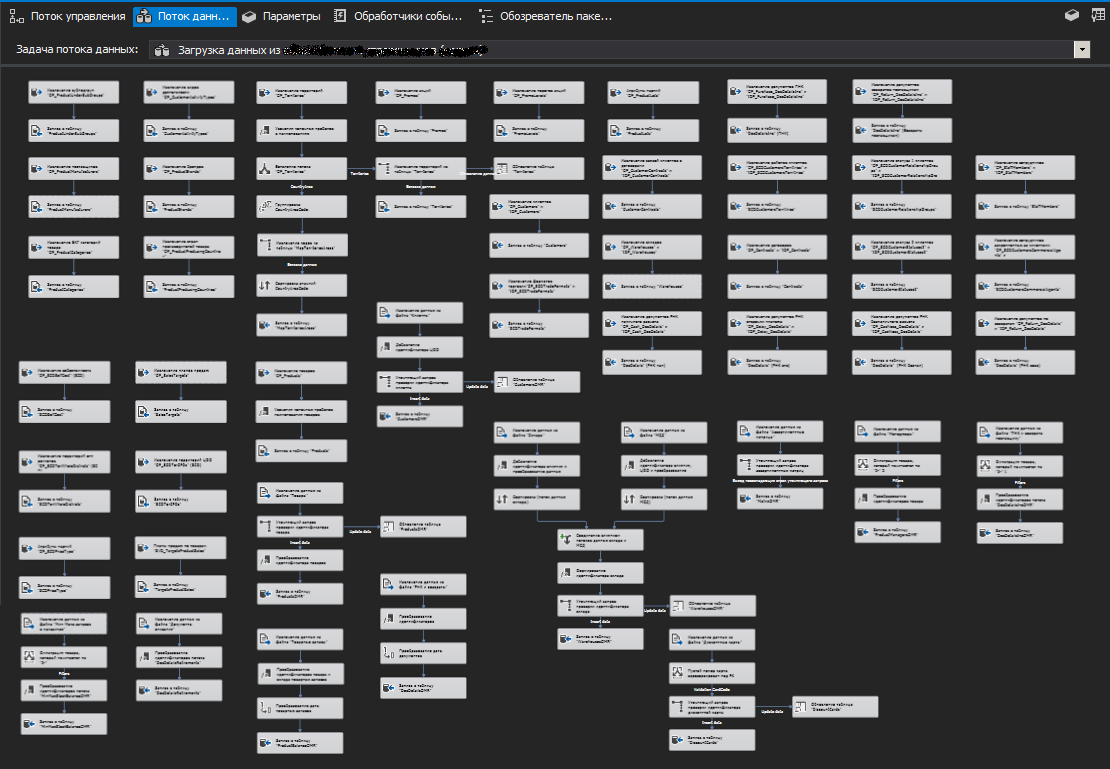
,
SSIS
SQL Server (SQL Server Destination), ,
OLE DB (OLE DB Destination).
, , , . , , . (, )
. , , , (/ ).
.
, ( ). Das heißt, , . , , . - — . .
, (.. ) .
, , .
PS
, , , , . — , . - , , .