Dieser Hinweis ist eine schriftliche Version meines Berichts „So ruinieren Sie die Leistung mit ineffizientem Code“ von der JPoint 2018-Konferenz. Sie können Videos und Folien auf der Konferenzseite ansehen. Im Zeitplan ist der Bericht mit einem anstößigen Glas Smoothie gekennzeichnet, so dass es nichts Super-Kompliziertes gibt, dies ist eher für Anfänger.
Gegenstand des Berichts:
- wie man den Code betrachtet, um Engpässe darin zu finden
- gemeinsame Antimuster
- nicht offensichtlicher Rechen
- Rechen Bypass
Am Rande wiesen sie auf einige Ungenauigkeiten / Auslassungen im Bericht hin, die hier vermerkt sind. Kommentare sind ebenfalls willkommen.
Auswirkungen der Leistung auf die Leistung
Es gibt eine Benutzerklasse:
class User { String name; int age; }
Wir müssen die Objekte miteinander vergleichen, also deklarieren wir die Methoden equals und hashCode :
import lombok.EqualsAndHashCode; @EqualsAndHashCode class User { String name; int age; }
Der Code ist funktionsfähig, die Frage ist anders: Wird die Leistung dieses Codes die beste sein? Um dies zu beantworten, erinnern wir uns an die Funktionen der Object::equals Methode: Sie gibt nur dann ein positives Ergebnis zurück, wenn alle verglichenen Felder gleich sind, andernfalls ist das Ergebnis negativ. Mit anderen Worten, ein Unterschied reicht bereits für ein negatives Ergebnis.
Nachdem wir uns den für @EqualsAndHashCode generierten Code @EqualsAndHashCode wir @EqualsAndHashCode :
public boolean equals(Object that) {
Die Reihenfolge der Überprüfung der Felder entspricht der Reihenfolge ihrer Deklaration, was in unserem Fall nicht die beste Lösung ist, da der Vergleich von Objekten mit equals „schwieriger“ ist als der Vergleich einfacher Typen.
Ok, versuchen wir, mit der Idee equals/hashCode Methoden zu erstellen:
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(name, that.name); }
Eine Idee erstellt intelligenteren Code, der die Komplexität des Vergleichs verschiedener Datentypen kennt. Nun, wir werden @EqualsAndHashCode und explizit equals/hashCode @EqualsAndHashCode schreiben. Nun wollen wir sehen, was passiert, wenn die Klasse erweitert wird:
class User { List<T> props; String name; int age; }
Neuerstellung equals/hashCode :
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(props, that.props)
Listen werden verglichen, bevor Zeichenfolgen verglichen werden. Dies ist nicht sinnvoll, wenn Zeichenfolgen unterschiedlich sind. Auf den ersten Blick gibt es keinen großen Unterschied, da Zeichenfolgen gleicher Länge durch Vorzeichen verglichen werden (d. H. Die Vergleichszeit wächst mit der Länge der Zeichenfolge):
Es gab eine UngenauigkeitDie Methode java.lang.String::equals ist aufdringlich , sodass bei der Ausführung kein Anmeldevergleich stattfindet.
Vergleichen Sie nun zwei ArrayList (als am häufigsten verwendete Listenimplementierung). ArrayList wir ArrayList , stellen wir überrascht fest, dass es keine eigene Implementierung von equals , sondern eine geerbte Implementierung verwendet:
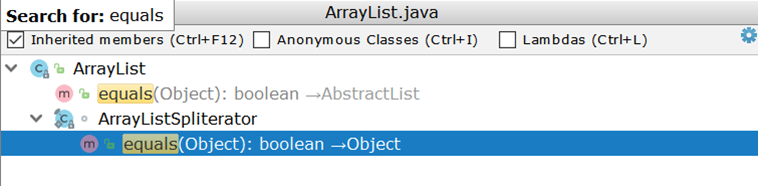
Wichtig ist hier die Erstellung von zwei Iteratoren und deren paarweiser Durchgang. Angenommen, es gibt zwei ArrayList :
- in einer Zahl von 1 bis 99
- in der zweiten Zahl von 1 bis 100
Im Idealfall würde es ausreichen, die Größen der beiden Listen zu vergleichen und, wenn sie nicht übereinstimmen, sofort ein negatives Ergebnis zurückzugeben (wie dies bei AbstractSet Fall ist). In der Realität werden 99 Vergleiche durchgeführt, und erst am hundertsten wird klar, dass die Listen unterschiedlich sind.
Was gibt es mit den Kotliniten?
data class User(val name: String, val age: Int);
Hier ist alles wie bei einem Lombok - die Vergleichsreihenfolge entspricht der Reihenfolge der Ankündigung:
public boolean equals(Object o) { if (this == o) { return true; } if (o instanceof User) { User u = (User) o; if (Intrinsics.areEqual(name, u.name) && age == u.age) {
Um dieses Problem zu umgehen, können Sie Felddeklarationen manuell organisieren.
Lassen Sie uns die Aufgabe komplizieren
void check(Dto dto) { SomeEntity entity = jpaRepository.findOne(dto.getId()); boolean valid = dto.isValid(); if (valid && entity.hasGoodRating()) {
Der Code beinhaltet den Zugriff auf die Datenbank, auch wenn das Ergebnis der Überprüfung der durch den Pfeil angegebenen Bedingungen im Voraus vorhersehbar ist. Wenn der Wert der valid Variablen false ist, wird der Code im if Block niemals ausgeführt. Dies bedeutet, dass Sie auf eine Anforderung verzichten können:
void check(Dto dto) { boolean valid = dto.isValid(); if (valid && hasGoodRating(dto)) {
Hinweis von der SeitenlinieDas Sinken kann unbedeutend sein, wenn sich die von JpaRepository::findOne Entität bereits im Cache der ersten Ebene befindet - dann erfolgt keine Anforderung.
Ein ähnliches Beispiel ohne explizite Verzweigung:
boolean checkChild(Dto dto) { Long id = dto.getId(); Entity entity = jpaRepository.findOne(id); return dto.isValid() && entity.hasChild(); }
Durch eine schnelle Rücksendung können Sie die Anfrage verzögern:
boolean checkChild(Dto dto) { if (!dto.isValid()) { return false; } return jpaRepository.findOne(dto.getId()).hasChild(); }
Eine ziemlich offensichtliche Ergänzung, die nicht im Bericht enthalten warStellen Sie sich vor, dass eine bestimmte Prüfung eine ähnliche Entität verwendet:
@Entity class ParentEntity { @ManyToOne(fetch = LAZY) @JoinColumn(name = "CHILD_ID") private ChildEntity child; @Enumerated(EnumType.String) private SomeType type;
Wenn die Prüfung dieselbe Entität verwendet, sollten Sie sicherstellen, dass der Aufruf der "faulen" untergeordneten Entitäten / Sammlungen nach dem Aufruf der bereits geladenen Felder ausgeführt wird. Auf den ersten Blick hat eine zusätzliche Anforderung keinen wesentlichen Einfluss auf das Gesamtbild, aber alles kann sich ändern, wenn eine Aktion in einer Schleife ausgeführt wird.
Schlussfolgerung: Die Aktions- / Überprüfungsketten sollten in der Reihenfolge der zunehmenden Komplexität der einzelnen Vorgänge angeordnet werden. Möglicherweise müssen einige davon nicht durchgeführt werden.
Zyklen und Massenverarbeitung
Das folgende Beispiel benötigt keine besonderen Erklärungen:
@Transactional void enrollStudents(Set<Long> ids) { for (Long id : ids) { Student student = jpaRepository.findOne(id);
Aufgrund mehrerer Datenbankabfragen ist der Code langsam.
BemerkungDie Leistung kann noch weiter sinken, wenn die Methode enrollStudents außerhalb einer Transaktion ausgeführt wird: Jeder Aufruf von osdjrJpaRepository::findOne wird in einer neuen Transaktion ausgeführt (siehe SimpleJpaRepository ). Dies bedeutet, dass eine Verbindung zur Datenbank empfangen und zurückgegeben sowie der Cache der ersten Ebene erstellt und osdjrJpaRepository::findOne wird.
Fix:
@Transactional void enrollStudents(Set<Long> ids) { if (ids.isEmpty()) { return; } for (Student student : jpaRepository.findAll(ids)) { enroll(student); } }
Messen wir die Laufzeit (in Mikrosekunden) für eine Sammlung von Schlüsseln (10 und 100 Stück). Benchmark
BemerkungWenn Sie Oracle verwenden und mehr als 1000 Schlüssel an findAll , wird die Ausnahme ORA-01795: maximum number of expressions in a list is 1000 .
Außerdem kann das Ausführen einer schweren (mit vielen Schlüsseln) Abfrage schlechter sein als n Abfragen. Es hängt alles von der spezifischen Anwendung ab, sodass der mechanische Austausch des Zyklus zur Massenverarbeitung die Leistung beeinträchtigen kann.
Ein komplexeres Beispiel zum gleichen Thema
for (Long id : ids) { Region region = jpaRepository.findOne(id); if (region == null) {
In diesem Fall können wir die Schleife nicht durch JpaRepository::findAll , JpaRepository::findAll dies die Logik JpaRepository::findAll von JpaRepository::findAll erhaltenen Werte sind nicht null und der if Block funktioniert nicht.
Die Tatsache, dass wir für jeden Datenbankschlüssel diese Schwierigkeit beheben können
Gibt entweder den tatsächlichen Wert oder dessen Abwesenheit zurück. Das heißt, in gewissem Sinne ist eine Datenbank ein Wörterbuch. Java aus der Box gibt uns eine vorgefertigte Implementierung des Wörterbuchs - HashMap - auf der wir die Logik zum Ersetzen der Datenbank aufbauen werden:
Map<Long, Region> regionMap = jpaRepository.findAll(ids) .stream() .collect(Collectors.toMap(Region::getId, Function.identity())); for (Long id : ids) { Region region = map.get(id); if (region == null) { region = new Region(); region.setId(id); } use(region); }
Beispiel umkehren
Dieser Code erstellt immer eine neue Transaktion, um eine Liste von Entitäten zu speichern. Das Absacken beginnt mit mehreren Aufrufen einer Methode, die eine neue Transaktion öffnet:
Lösung: Wenden Sie die Saver::save Methode sofort auf den gesamten Datensatz an:
@Transactional public void audit(List<AuditDto> inserts) { List<AuditEntity> bulk = inserts .map(this::toEntities) .flatMap(List::stream)
Viele Transaktionen verschmelzen zu einer, was zu einer spürbaren Zunahme führt (Zeit in Mikrosekunden): Benchmark
Ein Beispiel mit mehreren Transaktionen ist schwer zu formalisieren, was nicht über den Aufruf von JpaRepository::findOne in einer Schleife gesagt werden kann.
Der Ansatz ist nicht nur auf die Datenbank anwendbar, daher ging Tagir lany Valeev noch weiter. Und wenn wir früher so geschrieben haben:
List<Long> list = new ArrayList<>(); for (Long id : items) { list.add(id); }
und alles war in Ordnung, jetzt schlägt die "Idee" vor, sich selbst zu korrigieren:
List<Long> list = new ArrayList<>(); list.addAll(items);
Aber selbst diese Option erfüllt sie nicht immer, da Sie sie noch kürzer und schneller machen können:
List<Long> list = new ArrayList<>(items);
Vergleichen (Zeit in ns)Für ArrayList bedeutet diese Verbesserung eine spürbare Steigerung:
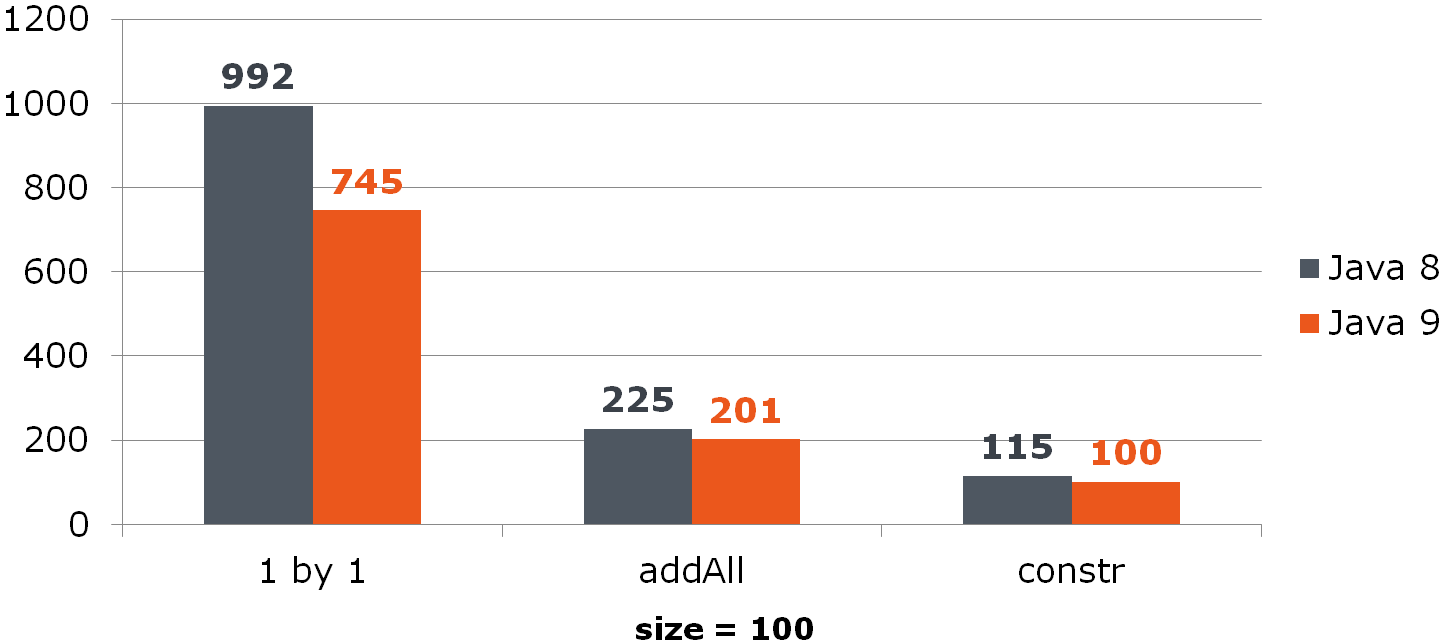
Für HashSet ist es nicht so rosig:

Benchmark
Entfernen aus der ArrayList
for (int i = from; i < to; i++) { list.remove(from); }
Das Problem liegt in der Implementierung der List::remove Methode:
public E remove(int index) { Objects.checkIndex(index, size); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) { System.arraycopy(array, index + 1, array, index, numMoved);
Lösung:
list.subList(from, to).clear();
Was aber, wenn der Remote-Wert im Quellcode verwendet wird?
for (int i = from; i < to; i++) { E removed = list.remove(from); use(removed); }
Jetzt müssen Sie zuerst die bereinigte Liste durchgehen:
List<String> removed = list.subList(from, to); removed.forEach(this::use); removed.clear();
Wenn Sie wirklich im Zyklus löschen möchten, hilft eine Änderung der Durchgangsrichtung durch die Liste, die Schmerzen zu lindern. Seine Bedeutung ist es, eine kleinere Anzahl von Elementen nach dem Reinigen der Zelle zu verschieben:
Vergleichen Sie alle drei Methoden (unter den Spalten sind% entfernte Elemente aus einer Liste der Größe 100):
Hat übrigens jemand die Anomalie bemerkt?
Zu sehen
Wenn wir die Hälfte aller Daten löschen, die vom Ende verschoben werden, wird immer das letzte Element gelöscht und es gibt keine Verschiebung:
Benchmark
Schlussfolgerung: Massenoperationen sind oft schneller als Einzeloperationen.
Umfang und Leistung
Dieser Code benötigt keine besonderen Erklärungen:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); List<Student> underAchieving = repository.findUnderAchieving();
Wir schränken den Bereich ein, der minus 1 Abfrage ergibt:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); if (Settings.leaveBothCategories()) { List<Student> underAchieving = repository.findUnderAchieving();
Und hier sollte der aufmerksame Leser fragen: Was ist mit statischer Analyse? Warum hat uns Idea nichts über die Verbesserung an der Oberfläche erzählt?
Tatsache ist, dass die Möglichkeiten der statischen Analyse begrenzt sind: Wenn die Methode komplex ist (insbesondere mit der Datenbank interagiert) und den allgemeinen Status beeinflusst, kann die Übertragung ihrer Ausführung die Anwendung beschädigen. Der statische Analysator kann sehr einfache Ausführungen melden, deren Übertragung beispielsweise innerhalb des Blocks nichts unterbricht.
Sie können die variable Hervorhebung als Ersatz verwenden, aber verwenden Sie sie auch hier vorsichtig, da Nebenwirkungen immer möglich sind. Sie können die Annotation @org.jetbrains.annotations.Contract(pure = true) , die in der Jetbrains-Annotations- Bibliothek verfügbar ist, um zustandslose Methoden anzugeben :
Fazit: Überschüssige Arbeit verschlechtert häufig nur die Leistung.
Das ungewöhnlichste Beispiel
@Service public class RemoteService { private ContractCounter contractCounter; @Transactional(readOnly = true)
Diese Implementierung öffnet eine Transaktion, auch wenn keine Transaktion erforderlich ist (schnelle Rückgabe -1 von der Methode).
Alles, was Sie tun müssen, ist, die Transaktionalität innerhalb der ContractCounter::countContracts entfernen, wo sie benötigt wird, und sie aus der "externen" Methode zu entfernen.
Vergleichen Sie die Ausführungszeit für den Fall, dass -1 (ns) zurückgegeben wird: Vergleichen Sie den Speicherverbrauch (Bytes): Benchmark
Schlussfolgerung: Controller und "nach außen gerichtete" Dienste müssen von der Transaktionsfähigkeit befreit werden (dies liegt nicht in ihrer Verantwortung), und die gesamte Logik der Überprüfung von Eingabedaten, die keinen Zugriff auf die Datenbank und die Transaktionskomponenten erfordert, sollte dort herausgenommen werden.
Konvertieren Sie Datum / Uhrzeit in Zeichenfolge
Eine der ewigen Aufgaben besteht darin, Datum und Uhrzeit in eine Zeichenfolge umzuwandeln. Vor dem G8 haben wir Folgendes gemacht:
SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.yyyy"); String dateAsStr = formatter.format(date);
Mit der Veröffentlichung von JDK 8 haben wir LocalDate/LocalDateTime und dementsprechend DateTimeFormatter
DateTimeFormatter formatter = ofPattern("dd.MM.yyyy"); String dateAsStr = formatter.format(localDate);
Lassen Sie uns seine Leistung messen:
Date date = new Date(); LocalDate localDate = LocalDate.now(); SimpleDateFormat sdf = new SimpleDateFormat("dd.MM.yyyy"); DateTimeFormatter dtf = DateTimeFormatter.ofPattern("dd.MM.yyyy"); @Benchmark public String simpleDateFormat() { return sdf.format(date); } @Benchmark public String dateTimeFormatter() { return dtf.format(localDate); }
Frage: Nehmen wir an, unser Service empfängt Daten von außerhalb und wir können java.util.Date nicht ablehnen. Wäre es für uns von Vorteil, Date in LocalDate zu konvertieren, wenn letzteres schneller in einen String konvertiert wird? Berechnen Sie:
@Benchmark public String measureDateConverted(Data data) { LocalDate localDate = toLocalDate(data.date); return data.dateTimeFormatter.format(localDate); } private LocalDate toLocalDate(Date date) { return date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate(); }
Daher ist das Konvertierungsdatum -> LocalDate bei Verwendung der "Neun" von Vorteil. Bei G8 verschlingen die Konvertierungskosten alle Vorteile von DateTimeFormatter -a.
Benchmark
Fazit: Nutzen Sie neue Lösungen.
Eine weitere "Acht"
In diesem Code sehen wir offensichtliche Redundanz:
Iterator<Long> iterator = items
Wir entfernen es:
Iterator<Long> iterator = items
Mal sehen, wie viel Leistung sich verbessert hat: Erstaunlich, oder? Ich habe oben argumentiert, dass übermäßige Arbeit die Leistung beeinträchtigt. Aber hier entfernen wir den Überschuss - und (plötzlich) wird es schlimmer. Um zu verstehen, was passiert, nehmen Sie zwei Iteratoren und betrachten Sie sie unter einer Lupe:
Offenlegen Iterator iterator1 = items.stream().collect(toList()).iterator(); Iterator iterator2 = items.stream().iterator();

Der erste Iterator ist die reguläre ArrayList$Itr .
Der Durchgang ist einfach: public boolean hasNext() { return cursor != size; } public E next() { checkForComodification(); int i = cursor; if (i >= size) { throw new NoSuchElementException(); } Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } cursor = i + 1; return (E) elementData[lastRet = i]; }
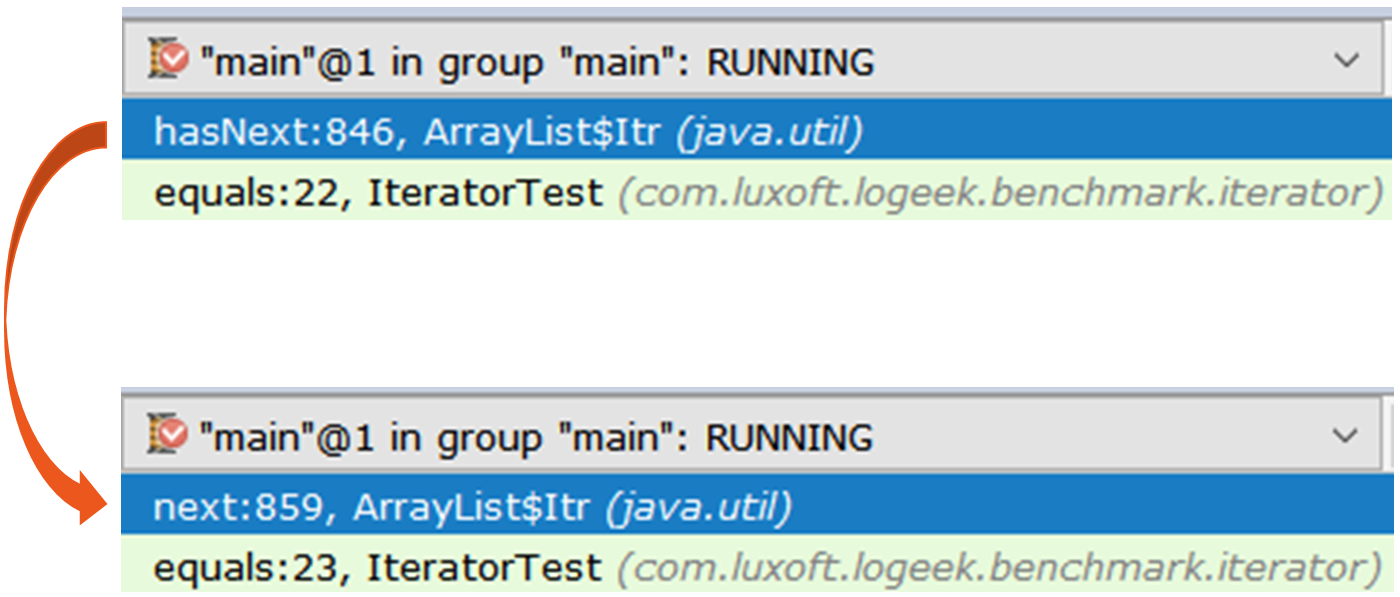
Der zweite ist interessanter, es ist Spliterators$Adapter , der auf ArrayList$ArrayListSpliterator basiert.
Es ist schwieriger, durchzukommen Schauen wir uns die Iterator-Iteration durch den Async-Profiler an :
15.64% juArrayList$ArrayListSpliterator.tryAdvance 10.67% jusSpinedBuffer.clear 9.86% juSpliterators$1Adapter.hasNext 8.81% jusStreamSpliterators$AbstractWrappingSpliterator.fillBuffer 6.01% oojiBlackhole.consume 5.71% jusReferencePipeline$3$1.accept 5.57% jusSpinedBuffer.accept 5.06% cllbir.IteratorFromStreamBenchmark.iteratorFromStream 4.80% jlLong.valueOf 4.53% cllbiIteratorFromStreamBenchmark$$Lambda$8.885721577.apply
Es ist ersichtlich, dass die meiste Zeit damit verbracht wird, den Iterator zu durchlaufen, obwohl wir ihn im Großen und Ganzen nicht benötigen, da die Suche folgendermaßen durchgeführt werden kann:
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Vergleichen Sie mit dem Rest: Stream::forEach eindeutig ein Gewinner, aber das ist seltsam: Es basiert immer noch auf ArrayListSpliterator , aber seine Verwendung hat sich erheblich verbessert.
Sehen wir uns das Profil an: 29.04% oojiBlackhole.consume 22.92% juArrayList$ArrayListSpliterator.forEachRemaining 14.47% jusReferencePipeline$3$1.accept 8.79% jlLong.valueOf 5.37% cllbiIteratorFromStreamBenchmark$$Lambda$9.617691115.accept 4.84% cllbiIteratorFromStreamBenchmark$$Lambda$8.1964917002.apply 4.43% jusForEachOps$ForEachOp$OfRef.accept 4.17% jusSink$ChainedReference.end 1.27% jlInteger.longValue 0.53% jusReferencePipeline.map
In diesem Profil wird die meiste Zeit damit verbracht, die Werte im Blackhole „schlucken“. Im Vergleich zu einem Iterator wird ein wesentlich größerer Teil der Zeit direkt für die Ausführung des Java-Codes aufgewendet. Es kann angenommen werden, dass der Grund das geringere spezifische Gewicht der Speicherbereinigung im Vergleich zur Iterator-Brute-Force ist. Überprüfen Sie:
forEach:·gc.alloc.rate.norm 100 avgt 30 216,001 ± 0,002 B/op iteratorFromStream:·gc.alloc.rate.norm 100 avgt 30 416,004 ± 0,006 B/op
In der Tat liefert Stream::forEach die Hälfte des Speicherverbrauchs.
Warum ist es schneller?Die Anrufkette vom Anfang bis zum Schwarzen Loch sieht folgendermaßen aus:
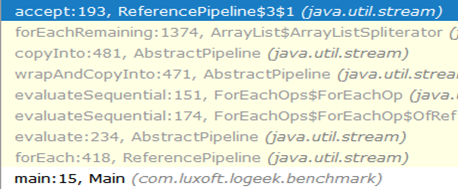
Wie Sie sehen können, ist der Aufruf von ArrayListSpliterator::tryAdvance aus der Kette verschwunden, und ArrayListSpliterator::forEachRemaining :
Highspeed ArrayListSpliterator::forEachRemaining erreicht, indem in einem Methodenaufruf das gesamte Array ArrayListSpliterator::forEachRemaining . Bei Verwendung eines Iterators ist die Passage auf ein Element beschränkt, sodass wir uns immer gegen ArrayListSpliterator::tryAdvance .
ArrayListSpliterator::forEachRemaining hat Zugriff auf das gesamte Array und ArrayListSpliterator::forEachRemaining mit einem ArrayListSpliterator::forEachRemaining ohne zusätzliche Aufrufe darüber.
Wichtiger HinweisBitte beachten Sie den mechanischen Austausch
Iterator<Long> iterator = items .stream() .map(Long::valueOf) .collect(toList()) .iterator(); while (iterator.hasNext()) { bh.consume(iterator.next()); }
auf
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Dies ist nicht immer gleichwertig, da wir im ersten Fall eine Kopie der Daten für die Passage verwenden, ohne den Stream selbst zu beeinflussen, und im zweiten Fall werden die Daten direkt aus dem Stream entnommen.
Benchmark
Fazit: Seien Sie beim Umgang mit komplexen Darstellungen von Daten darauf vorbereitet, dass selbst die "eisernen" Regeln (zusätzliche Arbeitsschäden) nicht mehr funktionieren. Das obige Beispiel zeigt, dass die scheinbar überflüssige Zwischenliste den Vorteil einer schnelleren Implementierung der Aufzählung bietet.
Zwei Tricks
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays .asList(trace) .subList(0, depth) .toArray(new StackTraceElement[newDepth]);
Das erste, was Collection::toArray , ist eine faule "Verbesserung", nämlich das Übergeben eines Arrays mit einer Länge ungleich Null an die Collection::toArray Methode. Es wird ausführlich erklärt, warum dies schädlich ist.
Das zweite Problem ist nicht so offensichtlich, und für sein Verständnis können wir eine Parallele zwischen der Arbeit des Rezensenten und des Historikers ziehen.
Dies ist, was Robin Collingwood darüber schreibt: . :
1)
2)
3)
, :
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays.copyOf(trace, depth);
List<T> list = getList(); Set<T> set = getSet(); return list.stream().allMatch(set::contains);
, , :
List<T> list = getList(); Set<T> set = getSet(); return set.containsAll(list);
:
interface FileNameLoader { String[] loadFileNames(); }
:
private FileNameLoader loader; void load() { for (String str : asList(loader.loadFileNames())) {
, forEach , :
private FileNameLoader loader; void load() { for (String str : loader.loadFileNames()) {
: :
, , , . , : "" ( ), "" ( ), .
→
→