Wie oft hören Sie die Aussage, dass die vom
SIEM- Hersteller bereitgestellten Korrelationsregeln nicht funktionieren und sofort nach der Installation des Produkts gelöscht oder deaktiviert werden? Bei Veranstaltungen zur Informationssicherheit wird dieses Problem in jedem Abschnitt, der SIEM gewidmet ist, auf die eine oder andere Weise behandelt.
Lassen Sie uns ein Risiko eingehen und versuchen, eine Lösung für das Problem zu finden.
Am häufigsten wird das Hauptproblem als die Tatsache bezeichnet, dass die Korrelationsregeln des SIEM-Herstellers zunächst nicht an die jeweilige Infrastruktur eines bestimmten Kunden angepasst sind.
Wenn man die an verschiedenen Standorten geäußerten Probleme analysiert, hat man das Gefühl, dass das Problem keine Lösung hat. Die Implementierung von SIEM muss entweder noch sehr verfeinert werden, was der Hersteller liefert, oder alle Regeln verwerfen und Ihre eigenen von Grund auf neu schreiben, während dieses Problem allen Lösungen aus jedem Teil des Gartner-Quadranten inhärent ist.
Unwillkürlich fragen Sie sich, ob wirklich alles so schlecht ist und dieser gordische Knoten nicht geschnitten werden kann? Ist der Ausdruck „Korrelationsregeln, die sofort funktionieren“ nur ein Marketing-Slogan, der nichts kostet?
Ein Artikel könnte Sie interessieren, wenn:
- Sie arbeiten bereits mit einer SIEM-Lösung.
- Ich plane nur, es umzusetzen.
- Wir haben uns entschlossen, unser SIEM mit Blackjack und Korrelationen basierend auf dem ELK-Stack oder etwas anderem aufzubauen.
Worum geht es in den Artikeln?
Im Rahmen dieser Artikelserie listen wir die Hauptprobleme auf, die die Umsetzung des Konzepts der „sofort einsatzbereiten Korrelationsregeln“ behindern, und versuchen, einen systematischen Lösungsansatz zu beschreiben.
Ich muss sofort sagen, dass es dieser Artikel ist, der von technischen Experten als "Wasser", "über nichts" charakterisiert werden kann. Alles ist so, aber nicht ganz. Bevor ich mich mit einer schwierigen Aufgabe befasse, möchte ich zunächst herausfinden, warum sie entstanden ist und welche Lösung sie uns bietet.
Zum besseren Verständnis der gesamten Bandbreite der vorgestellten Themen werde ich die allgemeine Struktur der gesamten Artikelserie angeben:
- Artikel 1: Dieser Artikel. Lassen Sie uns über die Erklärung des Problems sprechen und versuchen zu verstehen, warum wir im Allgemeinen die Regeln "Korrelationsregeln, die sofort funktionieren" benötigen. Der Artikel wird ideologischer Natur sein und wenn es völlig langweilig wird, können Sie ihn überspringen. Aber ich rate nicht dazu, weil In zukünftigen Artikeln werde ich oft darauf verweisen. Hier werden wir die Hauptprobleme diskutieren, die uns im Weg stehen, und Methoden zu ihrer Lösung.
- Artikel 2: Hurra! Hier kommen wir zu den ersten Details des vorgeschlagenen Ansatzes zur Lösung des Problems. Beschreiben wir, wie unser sicheres SIEM-Informationssystem „sehen“ soll. Lassen Sie uns darüber sprechen, welche Felder zur Normalisierung von Ereignissen erforderlich sind.
- Artikel 3: Wir beschreiben die Rolle der Kategorisierung von Ereignissen und wie die Methodik zur Normalisierung von Ereignissen auf ihrer Grundlage aufgebaut ist. Wir zeigen, wie sich IT-Ereignisse von IS-Ereignissen unterscheiden und warum sie unterschiedliche Kategorisierungsprinzipien haben sollten. Wir geben Live-Beispiele für die Arbeit dieser Methodik.
- Artikel 4: Sehen Sie sich die Assets unseres automatisierten Systems genau an und sehen Sie, wie sie sich auf die Leistung der Regeln auswirken. Wir werden sicherstellen, dass es auch bei ihnen nicht so einfach ist: Sie müssen identifiziert und ständig auf dem neuesten Stand gehalten werden.
- Artikel 5: Das, wofür alles begonnen wurde. Wir beschreiben den Ansatz zum Schreiben der Korrelationsregeln, basierend auf allem, was in früheren Artikeln angegeben wurde.
Problemstellung und warum es wichtig ist
Lassen Sie uns in einfachen Worten versuchen, unsere Aufgabe zu skizzieren: „Ich als Kunde, der eine SIEM-Lösung gekauft hat, abonniere, um die Regelbasis zu aktualisieren, und bezahle den Hersteller (und manchmal den Integrator) für die Unterstützung. Ich möchte umgehend mit den festgelegten Korrelationsregeln versorgt werden wäre in meinem SIEM nützlich. “ Was mich betrifft, so ein guter Wunsch, der nicht mit architektonischen oder strukturellen technischen Einschränkungen belastet ist.
Und jetzt, Aufmerksamkeit, nehmen wir an, dass wir bereits alle Probleme gelöst haben und unsere Aufgabe bereits abgeschlossen ist. Was gibt uns das?
- Erstens sparen wir die Arbeitskosten unserer Spezialisten. Jetzt müssen sie keine Zeit mehr damit verbringen, die Logik jeder neuen Regel zu studieren und sie an die Realität eines bestimmten automatisierten Systems anzupassen.
- Zweitens sparen wir seitdem das Budget Wir bitten den Integrator oder eine andere Person nicht, die Regeln für uns gegen eine Gebühr zu schreiben oder anzupassen.
- Drittens verfügen alle bedeutenden SIEM-Marktteilnehmer über Forschungseinheiten und -abteilungen, die sich auf die Analyse von Bedrohungen der Informationssicherheit konzentrieren. Es ist wichtig, ihre Erfahrung zu nutzen, insbesondere wenn wir dafür bezahlen.
- Viertens verkürzen wir unsere Reaktion auf neue Bedrohungen. Ich werde nicht über die Ewigkeit schreiben, die zwischen dem Auftreten einer Bedrohung, der Entwicklung von Korrelationsregeln für deren Erkennung und Implementierung in einem bestimmten Produkt für einen bestimmten Kunden vergeht. Viele Artikel wurden bereits zu diesem Thema verfasst.
- Fünftens bringt uns dies alle der Möglichkeit näher, einheitliche Regeln untereinander zu teilen, die für jeden Kunden funktionieren, natürlich im Rahmen einer bestimmten SIEM-Lösung.
Viele technische Experten, die eine Lösung für das Problem gefunden und bis zu diesem Punkt gelesen haben, werden sofort Einwände erheben: "Ja, natürlich gibt es Pluspunkte, aber dies ist technisch nicht machbar." Persönlich glaube ich, dass die Aufgabe ziemlich „hebt“ und jetzt gibt es sowohl auf dem westlichen als auch auf dem russischen Markt SIEMs, die alle Elemente enthalten, die zur Lösung erforderlich sind. Ich möchte Ihre Aufmerksamkeit darauf richten - die Produkte ermöglichen es Ihnen nicht, das Problem zu lösen, sondern enthalten nur alle erforderlichen Blöcke, aus denen Sie wie vom Designer die gesuchte Lösung zusammenstellen können.
Ich denke das ist sehr wichtig, weil Alles, was später beschrieben wird, kann in fast jedem vorhandenen und ausgereiften SIEM implementiert werden.
Genug der Texte, dann werden wir detaillierter über die Probleme sprechen, die bei der Lösung unseres Problems auftreten.
Die Herausforderungen, vor denen wir stehen
Lassen Sie uns auf der Suche nach einer Lösung für das oben genannte Problem sehen, mit welchen Problemen wir konfrontiert sind. Das Hervorheben der Hauptprobleme ermöglicht ein besseres Verständnis der Probleme sowie die Entwicklung eines systematischen Lösungsansatzes.
Die Probleme, mit denen wir konfrontiert sind, sind ein Schneeball, der die Situation dramatisch verschärft. Viele dieser Probleme führen dazu, dass die Erstellung von „Korrelationsregeln, die sofort funktionieren“ äußerst schwierig ist.
Im Allgemeinen sind die Probleme in die folgenden vier großen Blöcke unterteilt:
- Datenverlust während der Normalisierung im Zusammenhang mit der Transformation von Modellen der "Welt".
- Fehlen klarer und allgemein anerkannter Regeln zur Normalisierung von Ereignissen.
- Die ständige "Mutation" des Schutzobjekts - unser automatisiertes System.
- Fehlende Regeln zum Schreiben von Korrelationsregeln.
Lassen Sie uns diese Fragen nun genauer untersuchen.
Weltmodelltransformation
Dieses Problem lässt sich am einfachsten anhand der folgenden Analogie beschreiben.
Die Welt um uns herum ist vielfältig und vielfältig, aber unser Hören und Sehen fixiert nur ein begrenztes Strahlungsspektrum. Nachdem wir ein Phänomen gesehen oder gehört haben, bauen wir das Bild dieses Ereignisses in unseren Köpfen auf, wobei wir bereits sein abgeschnittenes Modell verwenden. Zum Beispiel sieht unser Auge nicht im Infrarotspektrum und das Ohr nimmt keine Vibrationen unter 16 Hz auf. Dies ist die erste Transformation des ursprünglichen Phänomens. In diesem Modell bringt unsere Vorstellungskraft etwas mit, das nicht im ursprünglichen Phänomen enthalten war. Wir können den Gesprächspartner über dieses Phänomen anhand der mündlichen Rede mit all ihren Einschränkungen und Merkmalen informieren. Dies ist die zweite Transformation des Modells. Schließlich beschließt der Gesprächspartner in unseren Worten, seinem Kollegen im Boten über dieses Phänomen zu schreiben. Dies ist die dritte und wahrscheinlich dramatischste Transformation des Modells in Bezug auf Informationsverlust.
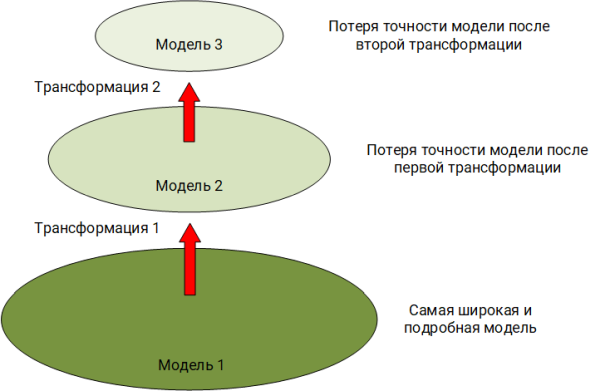
In dem oben beschriebenen Beispiel beobachten wir ein klassisches Problem, bei dem das ursprüngliche „konzeptionelle Modell“ (
Sovetov B. Ya., Yakovlev S. A., Systemmodellierung ) durch Vereinfachung in ein anderes Modell umgewandelt wird, während es im Detail verliert.
Genau das Gleiche passiert in der Welt der Ereignisse, die durch Software oder Hardware erzeugt werden.
Eine Erklärung, die hier dienen kann, ist ein derart vereinfachtes Bild bereits aus unserem Themenbereich:
- Die erste Transformation des Modells. Eine ausführbare Datei wurde in den RAM geladen, das Betriebssystem begann mit der Ausführung der darin beschriebenen Anweisungen. Das Betriebssystem übergibt einige Informationen zu diesem Vorgang an den Dämon- / Protokollierungsdienst (auditd, eventlog usw.). Wenn Sie keine erweiterte Prüfung von Aktionen aktivieren, fallen einige Informationen nicht in diesen Dämon. Aber auch bei einem erweiterten Audit werden einige Informationen immer noch verworfen, weil OS-Entwickler entschieden, dass ein solches Informationsvolumen ausreicht, um zu verstehen, was passiert.
- Die zweite Transformation des Modells. Und jetzt erstellt der Dämon / Dienst ein Ereignis, schreibt Informationen auf die Festplatte, und hier verstehen wir, dass die Länge der Ereigniszeile durch eine bestimmte Anzahl von Bytes begrenzt werden kann. Wenn der Dämon / Dienst ein strukturiertes Protokoll verwaltet, enthält er ein Schema des Ereignisses mit bestimmten Feldern. Was tun, wenn so viele Informationen vorhanden sind, dass sie nicht in ein „verkabeltes“ Schema passen? Richtig, höchstwahrscheinlich werden diese Informationen einfach verworfen.
Nun, wie es als Teil unserer Aufgabe aussieht.
Wir haben bereits ein vereinfachtes Modell (das bereits viele Details verloren hat) eines Phänomens, das durch einen Datensatz in einer Protokolldatei dargestellt wird - ein Ereignis. SIEM liest dieses Ereignis und normalisiert es, indem es Daten auf die Felder seines Schemas verteilt. Die Anzahl der Felder im Schema a priori kann sie nicht so weit enthalten, wie es erforderlich ist, um alle mögliche Semantik aller Ereignisse aus allen Quellen abzudecken, dh in diesem Schritt wird das Modell transformiert und die Daten gehen verloren.

Es ist wichtig zu verstehen, dass der Experte aufgrund dieses Problems, der die Protokolle in SIEM analysiert oder die Korrelationsregel beschreibt, nicht das ursprüngliche Ereignis selbst sieht, sondern sein mindestens zweimal verzerrtes Modell, das viele Informationen verloren hat. Und wenn die verlorenen Informationen für die Untersuchung des Vorfalls äußerst wichtig sind und als Folge des Schreibens der Regel von irgendwoher extrahiert werden müssen. Es ist für einen Experten möglich, die fehlenden Informationen entweder anhand der Originalquelle (Rohereignis, Speicherauszug usw.) zu finden oder indem er die fehlenden Daten in seinem Kopf auf der Grundlage seiner eigenen Erfahrung modelliert, was aus den Korrelationsregeln praktisch nicht direkt möglich ist.
Ein guter Indikator für dieses Problem sind Felder wie die Gerätezeichenfolge des Kunden, das Datenfeld oder etwas anderes. Diese Felder stellen eine Art "Speicherauszug" dar, in dem Daten abgelegt werden, von denen sie nicht wissen, wo sie abgelegt werden sollen, oder wenn alle anderen geeigneten Felder einfach überflutet werden.
Die Menge der Taxonomiefelder spiegelt in der Regel das Modell der "Welt" wider, wie der SIEM-Entwickler den Themenbereich sieht. Wenn das Modell sehr "schmal" ist, enthält es eine kleine Anzahl von Feldern, und bei Normalisierung einiger Ereignisse werden sie einfach übersehen. SIEM mit einem anfänglich festen und dynamisch nicht erweiterbaren Satz von Feldern hat häufig dieses Problem.
Wenn andererseits zu viele Felder vorhanden sind, treten Probleme auf, weil nicht verstanden wird, in welches Feld Sie bestimmte Daten des ursprünglichen Ereignisses einfügen müssen. Diese Situation beinhaltet die Möglichkeit des Auftretens einer semantischen Duplizierung, wenn semantisch dieselben Daten des Anfangsereignisses sofort in mehrere Felder passen. Dies wird häufig bei Lösungen beobachtet, bei denen der Satz von Schemafeldern von jedem Normalisierungsmodul mit Unterstützung einer neuen Quelle dynamisch erweitert werden kann.
Wenn Sie ein "Kampf" SIEM zur Hand haben, schauen Sie sich Ihre Ereignisse an. Wie oft verwenden Sie während der Normalisierung reservierte zusätzliche Felder (benutzerdefinierte Gerätezeichenfolge, Datenfeld usw.)? Viele Arten von Ereignissen mit zusätzlichen Feldern weisen darauf hin, dass Sie das erste Problem beobachten. Denken Sie jetzt daran oder fragen Sie Ihre Kollegen, wie oft sie mit Unterstützung einer neuen Quelle ein neues Feld hinzufügen mussten, da nicht genügend reservierte vorhanden waren. Die Antwort auf diese Frage ist ein Indikator für das zweite Problem.
Ereignisnormalisierungsmethode
Es ist wichtig, sich daran zu erinnern, wer und wie Ereignisse normalisiert, weil es spielt eine wichtige Rolle. Ein Teil der Quellen wird direkt vom Entwickler von SIEM-Lösungen unterstützt, ein Teil ist der Integrator, der SIEM für Sie implementiert hat, und ein Teil gehört Ihnen. Hier erwartet uns das nächste Problem: Jeder der Teilnehmer interpretiert die Bedeutung der Felder des Ereignisschemas auf seine Weise und führt daher die Normalisierung auf unterschiedliche Weise durch. Somit können verschiedene Teilnehmer semantisch identische Daten in verschiedene Felder zerlegen. Natürlich gibt es eine Reihe von Feldern, deren Name keine doppelte Interpretation zulässt. Angenommen, src_ip oder dst_ip, aber selbst bei ihnen gibt es Schwierigkeiten. Ist es beispielsweise bei Netzwerkereignissen erforderlich, src_ip in dst_ip zu ändern, wenn eingehende und ausgehende Verbindungen innerhalb derselben Sitzung normalisiert werden?
Auf der Grundlage des oben Gesagten muss eine klare Methodik zur Unterstützung von Quellen erstellt werden, in deren Rahmen klar angegeben wird:
- Was sind die Felder der Schaltung für das, was benötigt wird.
- Welche Datentypen entsprechen welchen Feldern?
- Welche Informationen sind uns im Rahmen jeder Art von Veranstaltung wichtig?
- Was sind die Regeln für das Ausfüllen der Felder.
Das Modell des Schutzobjekts und seiner Mutation
Schutzobjekt ist im Rahmen der Aufgabenlösung unser automatisiertes System (AS). Ja, es ist die AU in der Definition von
GOST 34.003-90 mit all ihren Prozessen, Personen und Technologien. Dies ist ein wichtiger Punkt, auf den wir später in den folgenden Artikeln zurückkommen werden.
Das Wort "Mutation" wird hier nicht zufällig gewählt. Erinnern wir uns, dass unter Mutation in der Biologie anhaltende Veränderungen im Genom verstanden werden. Was ist das AC-Genom? Im Rahmen dieser Artikelserie werde ich unter dem AS-Genom seine Architektur und Struktur verstehen. Und „dauerhafte Veränderungen“ sind nichts anderes als das Ergebnis der täglichen Arbeit von Systemadministratoren, Netzwerkingenieuren und Informationssicherheitsingenieuren. Unter dem Einfluss dieser Änderungen wechselt der Wechselstrom jede Minute von einem Zustand in einen anderen. Einige Staaten zeichnen sich durch ein hohes Maß an Sicherheit aus, andere weniger. Aber jetzt spielt es für uns keine Rolle.
Es ist wichtig zu verstehen, dass das AC-Modell nicht statisch ist, dessen Parameter alle in der technischen und funktionalen Dokumentation beschrieben sind, sondern ein lebendes, ständig mutierendes Objekt. SIEM, das das Modell des Schutzobjekts in sich selbst erstellt, muss dies berücksichtigen und in der Lage sein, es zeitnah und effizient zu aktualisieren und mit der Mutationsrate Schritt zu halten. Und wenn wir die Korrelationsregeln „out of the box“ machen wollen, müssen sie diese Mutationen berücksichtigen und immer mit dem relevantesten Bild der „Welt“ arbeiten.
Methodik zur Entwicklung von Korrelationsregeln
Aus der oben dargestellten
„Pyramide“ geht hervor, dass wir bei der Entwicklung von Korrelationsregeln gezwungen sind, uns um alle Probleme zu kämpfen, die auf niedrigeren Ebenen liegen. Um diese Probleme zu lösen, sind die Regeln mit zusätzlicher Logik ausgestattet: zusätzliche Filterung von Ereignissen, Überprüfung auf leere Werte, Umwandlung von Datentypen und Transformation dieser Daten (z. B. Extrahieren eines Domänennamens aus dem vollständig qualifizierten Domänenbenutzernamen), Isolieren von Informationen darüber, wer mit wem und mit wem interagiert Veranstaltungsrahmen.
Nach all dem sind die Regeln von einer solchen Anzahl von Fangausdrücken umgeben, dass nach Teilzeichenfolgen und regulären Ausdrücken gesucht wird, dass die Logik ihrer Arbeit nur ihren Autoren und bis zu ihrem nächsten Urlaub klar wird. Darüber hinaus erfordern die ständigen Änderungen im automatisierten System - Mutationen eine regelmäßige Aktualisierung der Regeln gegen Betrug. Ein bekanntes Bild?
Zusammenfassend
Im Rahmen dieser Artikelserie werden wir versuchen zu verstehen, wie die Korrelationsregeln sofort funktionieren.
Um das Problem zu lösen, müssen wir uns den folgenden Problemen stellen:
- Datenverlust während der Transformation des "Welt" -Modells in der Normalisierungsphase.
- Das Fehlen einer klaren Definition einer Normalisierungsmethode.
- Permanente Mutation des Schutzobjekts unter dem Einfluss von Menschen und Prozessen.
- Fehlende Methodik zum Schreiben von Korrelationsregeln.
Viele dieser Probleme liegen in der Ebene der Konstruktion des richtigen Ereignisschemas - einer Reihe von Feldern und des Prozesses der Normalisierung von Ereignissen - der Grundlage von Korrelationsregeln. Ein weiterer Teil der Probleme wird durch organisatorische und methodische Methoden gelöst. Wenn es uns gelingt, eine Lösung für diese Probleme zu finden, wird sich das Konzept der Ausarbeitung der Regeln positiv auswirken und das von den SIEM-Herstellern festgelegte Fachwissen auf ein neues Niveau heben.
Was weiter? «» , – .
:SIEM: « ». 1: ? (
)
SIEM: « ». 2. «»SIEM: « ». 3.1.SIEM: « ». 3.2.SIEM: « ». 4.SIEM: « ». 5.