 Wir haben kürzlich darüber gesprochen, warum wir einen eigenen RFM-Segmentierer entwickelt haben, mit dem RFM-Analysen in 20 Sekunden durchgeführt werden können , und gezeigt, wie die Ergebnisse im Marketing verwendet werden können.
Wir haben kürzlich darüber gesprochen, warum wir einen eigenen RFM-Segmentierer entwickelt haben, mit dem RFM-Analysen in 20 Sekunden durchgeführt werden können , und gezeigt, wie die Ergebnisse im Marketing verwendet werden können.
Jetzt erzählen wir, wie es angeordnet ist.
Aufgabe: Schreiben Sie einen neuen RFM-Analysealgorithmus
Wir waren mit den verfügbaren Ansätzen zur RFM-Analyse nicht zufrieden. Aus diesem Grund haben wir uns entschlossen, einen eigenen Segmentierer zu entwickeln, der:
- Es funktioniert vollautomatisch.
- Baut aus 3 bis 15 Segmenten.
- Passt sich jedem Tätigkeitsbereich des Kunden an (egal was es ist: ein Blumen- oder Elektrowerkzeugladen).
- Es bestimmt die Anzahl und Position von Segmenten basierend auf verfügbaren Daten und nicht vordefinierten Parametern, die nicht universell sein können.
- Es wählt Segmente so aus, dass sie immer Verbraucher haben (im Gegensatz zu einigen Ansätzen, wenn einige Segmente leer sind).
So lösen Sie das Problem
Als wir die Aufgabe erkannten, erkannten wir, dass sie außerhalb der Macht des Menschen lag, und baten die künstliche Intelligenz um Hilfe. Um dem Auto beizubringen, Verbraucher in Segmente zu unterteilen, haben wir uns für Clustering- Methoden entschieden.
Clustering-Methoden werden verwendet, um nach einer Struktur in den Daten zu suchen und Gruppen ähnlicher Objekte darin auszuwählen - genau das, was Sie für die RFM-Analyse benötigen.
Clustering bezieht sich auf maschinelle Lernmethoden der Klasse " Lernen ohne Lehrer ". Eine Klasse wird so genannt, weil es Daten gibt, aber niemand weiß, was damit zu tun ist, deshalb kann sie keine Maschine unterrichten.
Wir konnten keine Unternehmen mit diesem Ansatz auf dem Markt finden. Obwohl sie einen Artikel gefunden haben, in dem der Autor wissenschaftliche Forschung zu diesem Thema betreibt. Aber wie wir aus eigener Erfahrung verstanden haben, ist der Übergang von der Wissenschaft zur Wirtschaft keineswegs ein Schritt.
Stufe 1. Datenverarbeitung
Daten müssen für das Clustering vorbereitet werden.
Zuerst überprüfen wir sie auf falsche Werte: negative Werte usw.
Dann entfernen wir Emissionen - Verbraucher mit ungewöhnlichen Eigenschaften. Es gibt nur wenige von ihnen, aber sie können das Ergebnis stark beeinflussen und nicht zum Besseren. Um sie zu trennen, verwenden wir eine spezielle Methode des maschinellen Lernens - den lokalen Ausreißerfaktor .

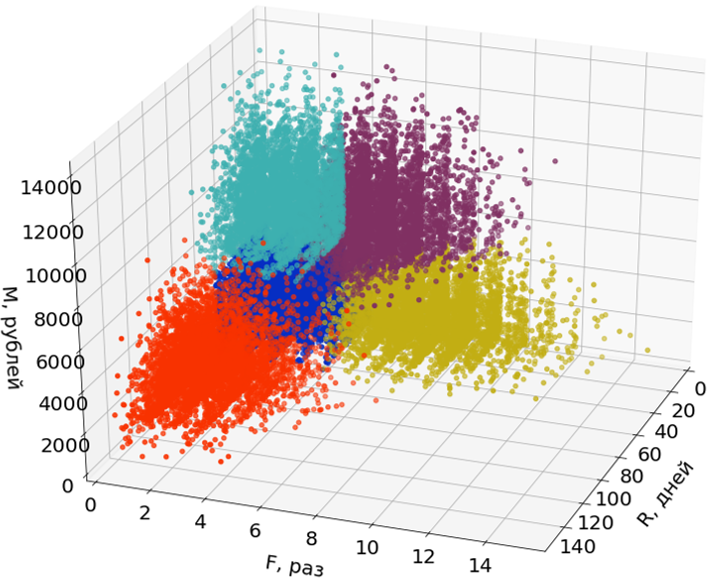
Hier auf den Bildern verwende ich nur zwei der drei Dimensionen (R und M) von drei, um die Wahrnehmung zu erleichtern.
Emissionen sind nicht am Aufbau von Segmenten beteiligt, sondern werden ihnen nach Bildung der Segmente zugewiesen.
Stufe 2. Consumer Clustering
Ich werde die Terminologie klarstellen: Mit Clustern meine ich Gruppen von Objekten, die durch die Verwendung von Clustering-Algorithmen erhalten werden, und Segmente als Endergebnis, dh das Ergebnis der RFM-Analyse.
Es gibt mehrere Dutzend Clustering-Algorithmen. Beispiele für einige davon finden Sie in der Dokumentation zum scikit-learn-Paket .
Wir haben acht Algorithmen mit verschiedenen Modifikationen ausprobiert. Die meisten hatten nicht genug Speicher. Oder die Zeit ihrer Arbeit war unendlich. Fast alle Algorithmen, die es technisch geschafft haben, die Aufgabe zu bewältigen, lieferten schreckliche Ergebnisse: Beispielsweise betrachtete der beliebte DBSCAN 55% der Objekte als Rauschen und teilte den Rest in 4302 Cluster auf.
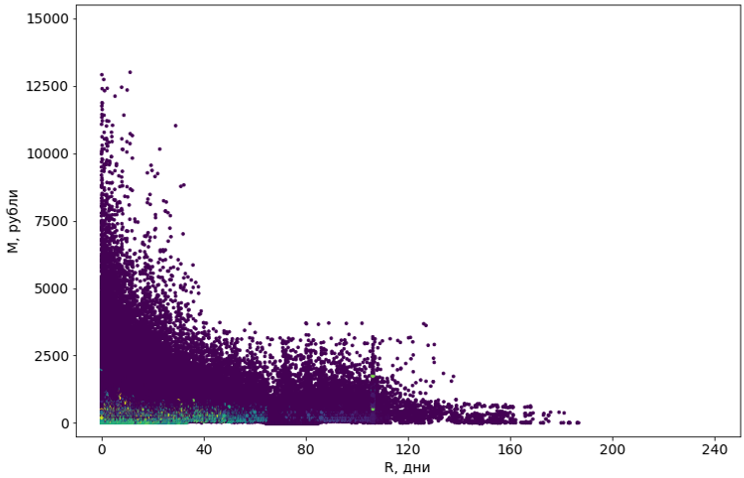
Violette Objekte werden als "Rauschen" definiert.
Aus diesem Grund haben wir den K-Means -Algorithmus (K-Means) gewählt, da er nicht nach Punktclustern sucht, sondern einfach die Punkte um die Zentren gruppiert. Wie sich herausstellte, war dies die richtige Entscheidung.
Aber zuerst haben wir ein paar Probleme gelöst:
Instabilität. Dies ist ein bekanntes Problem bei den meisten Clustering-Algorithmen, einschließlich K-Means. Die Instabilität liegt in der Tatsache, dass bei wiederholten Starts die Ergebnisse unterschiedlich sein können, da ein Element der Zufälligkeit verwendet wird.
Daher gruppieren wir viele Male und dann wieder, aber bereits die Zentren der Cluster. Als endgültige Zentren der Cluster nehmen wir die Zentren der resultierenden Cluster (dh Cluster, die durch die Zentren der ersten Cluster gebildet werden).
Die Anzahl der Cluster. Die Daten können unterschiedlich sein, und die Anzahl der Cluster muss ebenfalls unterschiedlich sein.
Um die optimale Anzahl von Clustern für jeden Kundenstamm zu finden, führen wir Clustering mit einer anderen Anzahl von Clustern durch und wählen dann das beste Ergebnis aus .
Geschwindigkeit. Der K-Means-Algorithmus ist nicht sehr schnell, aber akzeptabel (einige Minuten für eine durchschnittliche Basis von mehreren hunderttausend Verbrauchern). Wir führen es jedoch viele Male aus: Erstens, um die Stabilität zu erhöhen, und zweitens, um die Anzahl der Cluster auszuwählen. Und die Betriebszeit nimmt sehr zu.
Zur Beschleunigung verwenden wir eine Modifikation der Mini Batch K-Means . Die Cluster-Zentren werden bei jeder Iteration nicht für alle Objekte neu berechnet, sondern nur für eine kleine Teilstichprobe. Die Qualität sinkt erheblich, aber die Zeit wird erheblich verkürzt.
Sobald wir diese Probleme behoben hatten, begann das Clustering erfolgreich.
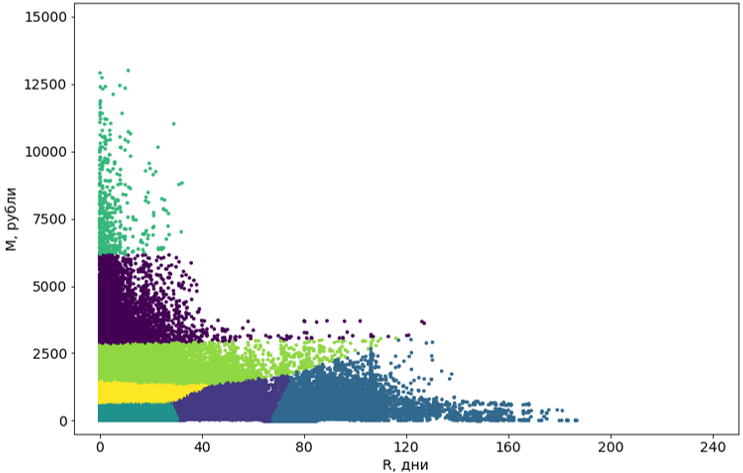
Stufe 3. Nachbearbeitung von Clustern
Die mit dem Algorithmus erhaltenen Cluster müssen in eine Form gebracht werden, die für die Wahrnehmung geeignet ist.
Zuerst verwandeln wir diese Cluster von Kurven in rechteckige. Eigentlich macht dies sie zu Segmenten. Die Rechteckigkeit der Segmente ist eine Anforderung an unser System und trägt zusätzlich zur Verständlichkeit der Segmente selbst bei. Zum Konvertieren verwenden wir einen anderen Algorithmus für maschinelles Lernen - den Entscheidungsbaum .
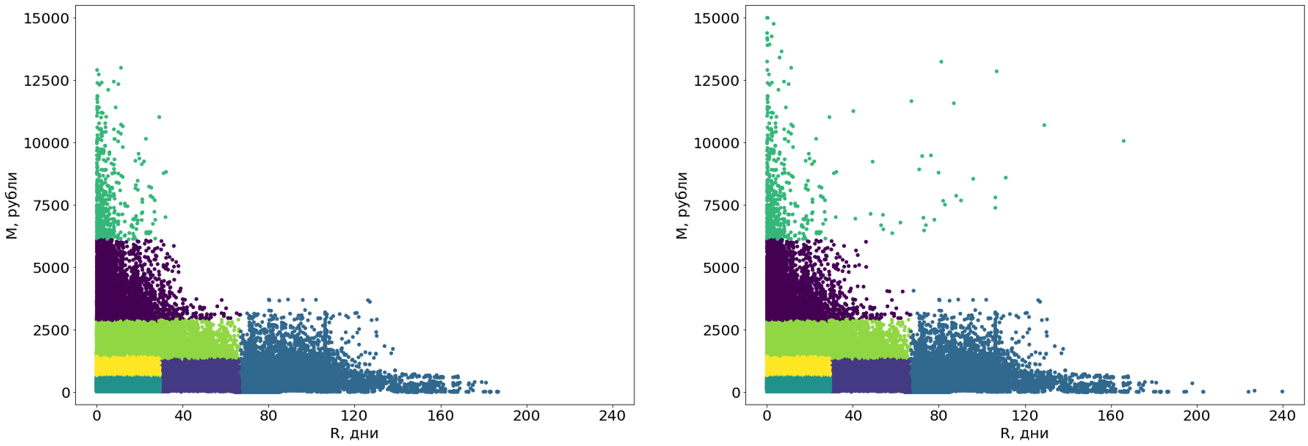
Der Entscheidungsbaum basiert auf ausreißerfreien Daten, und die Ausreißer werden dann den fertigen Segmenten zugeordnet
Zweitens haben wir eine andere coole Sache gemacht - die Beschreibung der Segmente. Ein spezieller Algorithmus, der ein Wörterbuch verwendet, beschreibt jedes Segment in Live-Russisch, damit die Menschen beim Betrachten seelenloser Zahlen keine Sehnsucht verspüren.

Testergebnisse
Das Produkt ist fertig. Aber bevor Sie anfangen zu verkaufen, muss es getestet werden. Überprüfen Sie also, ob die RFM-Analyse wie beabsichtigt durchgeführt wird.
Wir wissen, dass der beste Weg, um zu verstehen, ob wir etwas Wertvolles getan haben, darin besteht, herauszufinden, wie nützlich die Analyse für unsere Kunden ist. Und wir werden es tun. Aber das ist eine lange Zeit, und die Ergebnisse werden später vorliegen, und wir möchten wissen, wie erfolgreich wir die Aufgabe jetzt bewältigt haben.
Daher haben wir als einfachere und schnellere Metrik die Methode der „historischen Kontrollgruppe“ verwendet.
Zu diesem Zweck haben wir mehrere Datenbanken mithilfe von RFM-Analysen an verschiedenen Stellen in der Vergangenheit segmentiert: eine Datenbank für den Status vor sechs Monaten, die andere vor einem Jahr usw.
Basierend auf jeder Segmentierung für jede Basis haben wir unsere Prognose der Kundenaktionen vom ausgewählten Zeitpunkt bis zur Gegenwart erstellt. Dann verglichen sie diese Prognosen mit dem tatsächlichen Verhalten der Kunden.

Testbeispiel an einer historischen Kontrollgruppe mit einer Kontrolldauer von sechs Monaten
Im Bild:
- Die Spalten R, F und M geben üblicherweise die Grenzen der Segmente entlang jeder Achse an. Dies ist das Ergebnis der Basissegmentierung in der Form, wie sie vor einem halben Jahr war.
- Die Spalte "Größe" zeigt die Größe des Segments vor sechs Monaten im Verhältnis zur Gesamtgröße der Datenbank.
- Die Spalten „Kaufwahrscheinlichkeit“ und „Betrag“ sind Daten zum tatsächlichen Verbraucherverhalten in den nächsten sechs Monaten.
- Die Kaufwahrscheinlichkeit ist definiert als das Verhältnis der Anzahl der Verbraucher aus dem Segment, die einen Kauf getätigt haben, zur Gesamtzahl der Verbraucher im Segment.
- Betrag - Der Gesamtbetrag, den Verbraucher aus dem Segment ausgeben, bezogen auf den Betrag, den Verbraucher aus allen Segmenten ausgeben.
Die Ergebnisse sind konsistent. Beispielsweise haben Kunden aus Segmenten, für die wir eine hohe Häufigkeit von Einkäufen prognostiziert haben, tatsächlich häufiger gekauft.
Obwohl wir den korrekten Betrieb des Algorithmus aufgrund solcher Tests nicht zu 100 Prozent garantieren können, haben wir entschieden, dass er erfolgreich war.
Was verstehen wir?
Maschinelles Lernen kann einem Unternehmen wirklich helfen, unlösbare oder sehr schlecht gelöste Probleme zu lösen.
Die eigentliche Herausforderung ist jedoch nicht der Kaggle-Wettbewerb. Hier müssen Sie nicht nur eine bessere Qualität in einer bestimmten Metrik erzielen, sondern auch darüber nachdenken, wie gut der Algorithmus funktioniert, ob er für Menschen geeignet ist und ob das Problem im Allgemeinen mit ML gelöst werden muss oder ob Sie sich einen einfacheren Weg vorstellen können.
Und schließlich erschwert das Fehlen einer formalen Qualitätsmetrik die Aufgabe mehrmals, da es schwierig ist, das Ergebnis richtig zu bewerten.