In der Welt des maschinellen Lernens ist einer der beliebtesten Modelltypen der entscheidende Baum und die darauf basierenden Ensembles. Die Vorteile von Bäumen sind: einfache Interpretation, es gibt keine Einschränkungen hinsichtlich der Art der anfänglichen Abhängigkeit, weiche Anforderungen an die Größe der Stichprobe. Bäume haben auch einen großen Fehler - die Tendenz zur Umschulung. Daher werden Bäume fast immer zu Ensembles zusammengefasst: zufälliger Wald, Gradientenverstärkung usw. Komplexe theoretische und praktische Aufgaben bestehen darin, Bäume zusammenzusetzen und zu Ensembles zu kombinieren.
Im selben Artikel werden wir das Verfahren zum Generieren von Vorhersagen aus einem bereits trainierten
XGBoost Modell sowie Implementierungsfunktionen in den beliebten Gradienten-Boosting-
XGBoost und
LightGBM . Außerdem wird der Leser mit der
leaves Bibliothek für Go vertraut gemacht, mit der Sie Vorhersagen für Baumensembles treffen können, ohne die C-API der Originalbibliotheken zu verwenden.
Woher wachsen die Bäume?
Betrachten Sie zunächst die allgemeinen Bestimmungen. Sie arbeiten normalerweise mit Bäumen, wo:
- Die Partition in einem Knoten erfolgt gemäß einer Funktion
- Binärbaum - Jeder Knoten hat einen linken und einen rechten Nachkommen
- Bei einem wesentlichen Attribut besteht die Entscheidungsregel darin, den Wert des Attributs mit einem Schwellenwert zu vergleichen
Ich habe diese Abbildung aus der
XGBoost-Dokumentation entnommen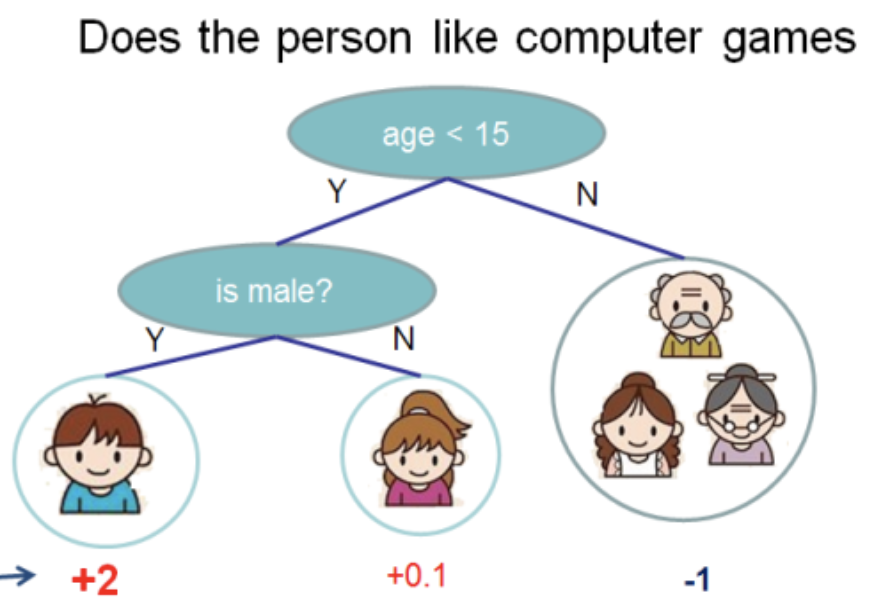
In diesem Baum haben wir 2 Knoten, 2 Entscheidungsregeln und 3 Blätter. Unter den Kreisen werden die Werte angezeigt - das Ergebnis der Anwendung des Baums auf ein Objekt. Normalerweise wird eine Transformationsfunktion auf das Ergebnis der Berechnung eines Baums oder Baumensembles angewendet. Zum Beispiel ein
Sigmoid für ein binäres Klassifizierungsproblem.
Um Vorhersagen aus dem Ensemble von Bäumen zu erhalten, die durch Gradientenverstärkung erhalten wurden, müssen Sie die Ergebnisse der Vorhersagen aller Bäume hinzufügen:
double pred = 0.0; for (auto& tree: trees) pred += tree->Predict(feature_values);
Im Folgenden wird es
C++ , as In dieser Sprache sind
XGBoost und
LightGBM geschrieben. Ich werde irrelevante Details weglassen und versuchen, den prägnantesten Code zu geben.
Betrachten Sie als Nächstes, was in
Predict verborgen ist und wie die Datenstruktur des Baums strukturiert ist.
XGBoost-Bäume
XGBoost hat mehrere Klassen (im Sinne von OOP) von Bäumen. Wir werden über
RegTree sprechen (siehe
include/xgboost/tree_model.h ), das laut Dokumentation das wichtigste ist. Wenn Sie nur die für Vorhersagen wichtigen Details belassen, sehen die Mitglieder der Klasse so einfach wie möglich aus:
class RegTree {
Die
GetNext ist in der
GetNext Funktion implementiert. Der Code wird geringfügig geändert, ohne das Ergebnis der Berechnungen zu beeinflussen:
Zwei Dinge folgen von hier:
RegTree funktioniert nur mit realen Attributen (Typ float )- Übersprungene Kennwerte werden unterstützt
Das Herzstück ist die
Node Klasse. Es enthält die lokale Struktur des Baums, die Entscheidungsregel und den Wert des Blattes:
class Node { public:
Folgende Merkmale können unterschieden werden:
- Blätter werden als Knoten dargestellt, für die
cleft_ = -1 - das
info_ Feld info_ als union , d.h. Je nach Knotentyp teilen sich zwei Datentypen (in diesem Fall derselbe) einen Speicher - Das höchstwertige Bit in
sindex_ ist dafür verantwortlich, wo das Objekt, dessen Attributwert übersprungen wird
Um den Pfad vom Aufrufen der
RegTree::Predict Methode bis zum Empfang der Antwort verfolgen zu können, werde ich die beiden fehlenden Funktionen
RegTree::Predict :
float RegTree::Predict(const RegTree::FVec& feat, unsigned root_id) const { int pid = this->GetLeafIndex(feat, root_id); return nodes_[pid].leaf_value; } int RegTree::GetLeafIndex(const RegTree::FVec& feat, unsigned root_id) const { auto pid = static_cast<int>(root_id); while (!nodes_[pid].IsLeaf()) { unsigned split_index = nodes_[pid].SplitIndex(); pid = this->GetNext(pid, feat.Fvalue(split_index), feat.IsMissing(split_index)); } return pid; }
In der
GetLeafIndex Funktion
GetLeafIndex wir die
GetLeafIndex in einer Schleife
GetLeafIndex bis wir das Blatt treffen.
LightGBM-Bäume
LightGBM hat keine Datenstruktur für den Knoten. Stattdessen enthält die Datenstruktur des
include/LightGBM/tree.h Datei
include/LightGBM/tree.h ) Arrays von Werten, wobei die Knotennummer als Index verwendet wird. Werte in Blättern werden auch in separaten Arrays gespeichert.
class Tree {
LightGBM unterstützt kategoriale Funktionen. Die Unterstützung erfolgt über ein Bitfeld, das für alle Knoten in
cat_threshold_ gespeichert ist. In
cat_boundaries_ welchem Knoten welcher Teil des
cat_boundaries_ entspricht. Das
threshold_ für den kategorialen Fall wird in
int konvertiert und entspricht dem Index in
cat_boundaries_ , um nach dem Anfang des
cat_boundaries_ zu suchen.
Betrachten Sie die entscheidende Regel für ein kategoriales Attribut:
int CategoricalDecision(double fval, int node) const { uint8_t missing_type = GetMissingType(decision_type_[node]); int int_fval = static_cast<int>(fval); if (int_fval < 0) { return right_child_[node];; } else if (std::isnan(fval)) {
Es ist ersichtlich, dass
missing_type Wert
NaN abhängig vom
missing_type die Lösung automatisch entlang des rechten Zweigs des Baums senkt. Andernfalls wird
NaN durch 0 ersetzt. Die Suche nach einem Wert in einem Bitfeld ist ganz einfach:
bool FindInBitset(const uint32_t* bits, int n, int pos) { int i1 = pos / 32; if (i1 >= n) { return false; } int i2 = pos % 32; return (bits[i1] >> i2) & 1; }
zum Beispiel wird für das kategoriale Attribut
int_fval=42 geprüft, ob das 41. Bit (Nummerierung von 0) in dem Array gesetzt ist.
Dieser Ansatz hat einen wesentlichen Nachteil: Wenn ein kategoriales Attribut große Werte annehmen kann, z. B. 100500, wird für jede Entscheidungsregel für dieses Attribut ein Bitfeld mit einer Größe von bis zu 12564 Byte erstellt!
Daher ist es wünschenswert, die Werte von kategorialen Attributen so neu zu nummerieren, dass sie kontinuierlich von 0 auf den Maximalwert gehen .
Ich für meinen Teil habe erklärende Änderungen an
LightGBM und diese
akzeptiert .
Der Umgang mit physischen Attributen unterscheidet sich nicht wesentlich von
XGBoost , und ich werde dies der Kürze
XGBoost überspringen.
Blätter - Bibliothek für Vorhersagen in Go
XGBoost und
LightGBM sehr leistungsfähige Bibliotheken zum
LightGBM Gradienten-
LightGBM Modellen auf Entscheidungsbäumen. Um sie in einem Backend-Dienst zu verwenden, in dem Algorithmen für maschinelles Lernen benötigt werden, müssen die folgenden Aufgaben gelöst werden:
- Regelmäßiges Training von Modellen offline
- Lieferung von Modellen im Backend-Service
- Modelle online abfragen
Zum Schreiben eines geladenen Backend-Dienstes ist
Go eine beliebte Sprache.
XGBoost oder
LightGBM durch die C-API und cgo ist nicht die einfachste Lösung. Die Erstellung des Programms ist kompliziert. Aufgrund der unachtsamen Behandlung können Sie
SIGTERM Probleme mit der Anzahl der Systemthreads erkennen (OpenMP in Bibliotheken vs. Go-Laufzeit-Threads).
Deshalb habe ich beschlossen, eine Bibliothek auf pure
Go für Vorhersagen mit in
XGBoost oder
LightGBM Modellen zu schreiben. Es heißt
leaves .

Hauptmerkmale der Bibliothek:
- Für
LightGBM Modelle
- Lesen von Modellen aus einem Standardformat (Text)
- Unterstützung für physische und kategoriale Attribute
- Unterstützung für fehlende Werte
- Optimierung der Arbeit mit kategorialen Variablen
- Vorhersageoptimierung mit Nur-Vorhersage-Datenstrukturen
- Für
XGBoost Modelle
- Lesen von Modellen aus einem Standardformat (binär)
- Unterstützung für fehlende Werte
- Vorhersageoptimierung
Hier ist ein minimales
Go Programm, das ein Modell von der Festplatte lädt und eine Vorhersage anzeigt:
package main import ( "bufio" "fmt" "os" "github.com/dmitryikh/leaves" ) func main() {
Die Bibliotheks-API ist minimal. Um das
XGBoost Modell zu verwenden
XGBoost rufen
leaves.XGEnsembleFromReader einfach die
leaves.XGEnsembleFromReader Methode anstelle der obigen auf. Vorhersagen können in
PredictDense durch Aufrufen der
PredictDense oder
model.PredictCSR . Weitere Verwendungsszenarien finden Sie in
Blatttests .
Trotz der Tatsache, dass
Go langsamer als
C++ läuft (hauptsächlich aufgrund intensiverer Laufzeit- und Laufzeitprüfungen), konnte dank einer Reihe von Optimierungen eine Vorhersagerate erzielt werden, die mit dem Aufruf der C-API der ursprünglichen Bibliotheken vergleichbar ist.
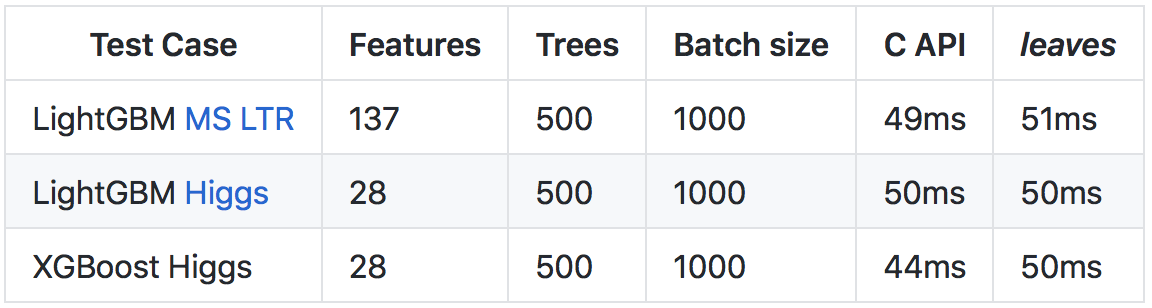
Weitere Details zu den Ergebnissen und Vergleichsmethoden finden Sie im
Repository auf github .
Siehe die Wurzel
Ich hoffe, dieser Artikel öffnet die Tür zur Implementierung von Bäumen in den
XGBoost und
LightGBM . Wie Sie sehen können, sind die grundlegenden Konstruktionen recht einfach, und ich ermutige die Leser, Open Source zu nutzen, um den Code zu studieren, wenn Fragen zur Funktionsweise auftreten.
Für diejenigen, die sich für das Thema der Verwendung von Gradientenverstärkungsmodellen in ihren Diensten in der Sprache Go interessieren, empfehle ich, dass Sie sich mit der
Blattbibliothek vertraut machen. Mithilfe von
leaves Sie ganz einfach führende Lösungen für maschinelles Lernen in Ihrer Produktionsumgebung verwenden, ohne dabei im Vergleich zu den ursprünglichen C ++ - Implementierungen an Geschwindigkeit zu verlieren.
Viel Glück!