 Artikelübersetzung: Experimentatoren Faustregeln
Artikelübersetzung: Experimentatoren FaustregelnBesitzer von Webportalen, von den kleinsten bis zu den größten, wie Amazon, Facebook, Google, LinkedIn, Microsoft und Yahoo, versuchen, ihre Websites durch Optimierung verschiedener Metriken zu verbessern, von der Anzahl der Wiederverwendungszeiten bis zu ihrer Zeit und ihrem Umsatz. Wir haben uns für Tausende von Experimenten auf Amazon, Booking.com, LinkedIn und Microsoft interessiert und möchten die sieben Faustregeln teilen, die wir aus diesen Experimenten und ihren Ergebnissen abgeleitet haben. Wir glauben, dass diese Regeln sowohl bei der Optimierung des Webs als auch bei der Analyse außerhalb von Kontrollexperimenten weit verbreitet sind. Obwohl es Ausnahmen gibt.
Um diese Regeln bedeutender zu machen, werden wir echte Beispiele aus unserer Arbeit geben, von denen die meisten zum ersten Mal veröffentlicht werden. Einige Regeln wurden bereits früher ausgesprochen (z. B. „Geschwindigkeit ist wichtig“), aber wir haben sie durch Annahmen ergänzt, die beim Entwerfen von Experimenten verwendet werden können, und zusätzliche Beispiele, die unser Verständnis dafür verbessern, wo Geschwindigkeit besonders wichtig ist und in welchen Bereichen des Webs Seiten ist es nicht kritisch.
Dieser Artikel hat zwei Zwecke.
Erstens : Bringen Sie den Experimentatoren die Regeln des guten Geschmacks bei, um die Websites zu optimieren.
Zweitens : Bereitstellung neuer Themen für die KDD-Community, um die Anwendbarkeit dieser Regeln, ihre Verbesserung und das Vorhandensein von Ausnahmen zu untersuchen.
Einführung
Besitzer von Webportalen vom kleinsten bis zum größten Giganten versuchen, ihre Websites zu verbessern. Führende Unternehmen verwenden Benchmarking-Tests (z. B. A / B-Tests), um Änderungen zu bewerten. Dies geschieht durch Amazon [1], Ebay, Etsy [2], Facebook [3], Google [4], Groupon, Intuit [5], LinkedIn [6], Microsoft [7], Netflix [8], ShopDirect [9]. , Yahoo und Zynga [10].
Wir haben Erfahrung in der Website-Optimierung gesammelt und mit vielen Unternehmen zusammengearbeitet, darunter Amazon, Booking.com, LinkedIn und Microsoft. Zum Beispiel führen Bing und LinkedIn zu jedem Zeitpunkt Hunderte von parallelen Experimenten durch [6; 11]. Aufgrund der Vielfalt und Vielfalt der Experimente, an denen wir teilgenommen haben, haben sich Faustregeln entwickelt, die wir hier diskutieren werden. Sie werden durch echte Projekte bestätigt, aber es gibt Ausnahmen von jeder Regel (wir werden auch darüber sprechen). Zum Beispiel ist die 72-Regel ein gutes Beispiel für eine nützliche Faustregel im Finanzbereich. Es wird behauptet, dass Sie den jährlichen Wachstumsprozentsatz mit 72 multiplizieren müssen, um ungefähr zu bestimmen, wie viele Jahre Sie Ihre Investition verdoppeln werden. In normalen Situationen ist die Regel sehr nützlich (wenn der Zinssatz zwischen 4 und 12% schwankt), in anderen Bereichen funktioniert sie jedoch nicht.
Da diese Regeln gemäß den Ergebnissen von Kontrollexperimenten formuliert wurden, eignen sie sich gut für die Standortoptimierung und einfache Analyse, auch wenn Kontrollexperimente nicht an Standorten durchgeführt werden (obwohl es in diesem Fall nicht möglich ist, die Auswirkung der vorgenommenen Änderungen genau zu bewerten).
Was Sie in diesem Artikel finden:
- Nützliche Regeln zum Experimentieren mit Websites. Sie befinden sich noch in der Entwicklung, und wir müssen zusätzlich die Breite ihrer Anwendung bewerten und herausfinden, ob es neue Ausnahmen von diesen Regeln gibt. Die Bedeutung der Verwendung von Kontrollexperimenten wurde im Artikel „Online-kontrollierte Experimente im großen Maßstab“ [11] diskutiert.
- Verbesserung früherer Regeln. Beobachtungen wie „Geschwindigkeitsfragen“ wurden bereits von anderen Autoren [12; 13] und uns [14] geäußert. Bei der Gestaltung des Experiments haben wir jedoch einige Annahmen getroffen, und wir werden über Studien sprechen, die zeigen, dass in einigen Bereichen der Seite die Geschwindigkeit besonders kritisch ist und in anderen nicht. Wir haben auch die alte Regel „Tausende von Benutzern“ verbessert, die die Frage beantwortet, wie viele Personen für die Durchführung eines Kontrollexperiments benötigt werden.
- Zum ersten Mal werden reale Beispiele für Kontrollexperimente veröffentlicht. Bei Amazon, Bing und LinkedIn werden Kontrollexperimente als Teil des Entwicklungsprozesses verwendet [7; 11]. Viele Unternehmen, die noch keine Kontrollexperimente verwenden, können von zusätzlichen Beispielen für die Arbeit mit Änderungen mit der Einführung neuer Entwicklungsparadigmen stark profitieren [7, 15]. Unternehmen, die bereits Kontrollexperimente durchführen, werden von den beschriebenen Erkenntnissen profitieren.
Kontrollexperimente, Daten und der Prozess des Extrahierens von Wissen aus Daten
Wir werden hier Kontroll-Online-Experimente diskutieren, bei denen Benutzer zufällig in Gruppen eingeteilt werden (um beispielsweise verschiedene Site-Optionen anzuzeigen). Darüber hinaus wird die Aufteilung fortlaufend durchgeführt, dh jeder Benutzer hat während des gesamten Experiments die gleiche Erfahrung (ihm wird immer die gleiche Version der Site angezeigt). Die Interaktion des Benutzers mit der Website (Klicks, Seitenaufrufe usw.) wird aufgezeichnet, und die wichtigsten Messdaten (Klickrate, Anzahl der Sitzungen pro Benutzer, Einnahmen des Benutzers) werden auf ihrer Grundlage berechnet. Statistische Tests werden durchgeführt, um die berechneten Metriken zu analysieren. Und wenn der Unterschied zwischen den Metriken der Kontrollgruppe (die die alte Version der Site gesehen hat) und der experimentellen (die die neue Version gesehen hat) der Gruppe statistisch signifikant ist, können wir auch mit hoher Wahrscheinlichkeit sagen, dass die vorgenommenen Änderungen die im Experiment beobachteten Metriken beeinflussen. Details sind in „Kontrollierte Experimente im Internet: Umfrage und praktischer Leitfaden“ [16] beschrieben.
Wir haben an vielen Experimenten teilgenommen, deren Ergebnisse falsch waren, und viel Zeit und Mühe aufgewendet, um die Gründe zu verstehen und Wege zu finden, dies zu beheben. Viele Fallstricke sind in den Artikeln [17] und [18] beschrieben. Wir möchten einige Fragen zu den Daten hervorheben, die bei der Durchführung von Online-Kontrollexperimenten verwendet wurden, und zum Prozess des Erlangens von Wissen aus diesen Daten:
- Die Datenquelle sind die realen Websites, über die wir oben gesprochen haben. Es werden keine künstlich erzeugten Informationen angezeigt. Alle Beispiele basieren auf einer realen Benutzerinteraktion, und Metriken werden nach dem Entfernen von Bots berechnet [16].
- Die Benutzergruppen in den Beispielen werden zufällig aus der gleichmäßigen Verteilung der Zielgruppe entnommen (dh Benutzer, die beispielsweise auf den Link klicken müssen, um die untersuchten Änderungen anzuzeigen) [16]. Die Methode zur Benutzeridentifizierung hängt von der Website ab: Wenn der Benutzer nicht angemeldet ist, werden Cookies verwendet, und wenn er angemeldet ist, wird sein Login verwendet.
- Die Größe der Benutzergruppen nach dem Löschen von Bots reicht von Hunderttausenden bis Millionen (genaue Werte sind in den Beispielen angegeben). In den meisten Experimenten ist dies erforderlich, damit geringfügige Unterschiede in den Metriken eine hohe statistische Signifikanz haben.
- Die angegebenen Ergebnisse waren bei einem p-Wert <0,05 statistisch signifikant und gewöhnlich sogar noch geringer. Die erstaunlichen Ergebnisse (in Regel 1) wurden mindestens noch einmal reproduziert, so dass der kumulative p-Wert, der auf dem kumulativen Fisher-Wahrscheinlichkeitstest basiert, einen viel geringeren Wert als erforderlich hatte.
- Jedes Experiment ist unsere persönliche Erfahrung, die von mindestens einem der Autoren auf das Vorhandensein von Standard-Fallstricken überprüft wurde. Jedes Experiment wurde mindestens eine Woche lang durchgeführt. Die Anteile des Publikums, die Standortoptionen demonstrierten, waren während des gesamten Versuchszeitraums stabil (um die Auswirkungen des Simpson-Paradoxons zu vermeiden), und die Verhältnisse zwischen dem Publikum, die wir während des Experiments beobachteten, stimmten mit den Verhältnissen überein, die wir zu Beginn des Experiments festgelegt hatten [17].
Faustregeln für Experimente
Die ersten drei Regeln beziehen sich auf die Auswirkungen von Änderungen auf wichtige Metriken:
- kleine Änderungen können große Auswirkungen haben;
- Veränderung hat selten einen großen positiven Effekt;
- Ihre Versuche, die von anderen angekündigten herausragenden Erfolge zu wiederholen, sind eher weniger erfolgreich.
Die folgenden 4 Regeln sind unabhängig voneinander, aber jede von ihnen ist sehr nützlich.
Regel Nr. 1: Kleine Änderungen können GROSSE Auswirkungen auf wichtige Metriken haben
Jeder, der auf das Leben von Websites gestoßen ist, weiß, dass jede kleine Änderung große negative Auswirkungen auf wichtige Kennzahlen haben kann. Ein kleiner JavaScript-Fehler kann die Zahlung unmöglich machen, und kleine Fehler, die den Stapel zerstören, können zum Absturz des Servers führen. Wir werden uns jedoch auf positive Änderungen der wichtigsten Kennzahlen konzentrieren. Die gute Nachricht ist, dass es viele Beispiele gibt, bei denen eine kleine Änderung zu einer Verbesserung der wichtigsten Kennzahlen geführt hat. Bryan Eisenberg schrieb, dass das Entfernen des Coupon-Eingabefelds auf dem Kaufformular die Conversion auf der Website von Doctor Footcare um 1000% erhöhte [20]. Jared Spool schrieb, dass die Aufhebung der Registrierungspflicht zum Zeitpunkt des Kaufs einem großen Einzelhändler 300 Millionen US-Dollar pro Jahr einbrachte [21].
Trotzdem konnten wir im Prozess der persönlich durchgeführten Experimente keine so signifikanten Veränderungen feststellen. Wir haben jedoch signifikante Verbesserungen durch kleine Änderungen mit einer überraschend hohen Kapitalrendite (hohes Verhältnis von Gewinn zu Kosten des investierten Aufwands) festgestellt.
Wir möchten auch darauf hinweisen, dass es sich um einen stabilisierten Effekt handelt, nicht um einen „Blitz auf der Sonne“ oder eine Funktion mit einem speziellen Nachrichten- / Vireneffekt. Ein Beispiel für etwas, nach dem wir nicht suchen, wurde im Buch Ja! Beschrieben: 50 Wissenschaftlich erprobte Wege, um zu überzeugen [22]. Collen Szot, der Autor einer Fernsehsendung, die einen 20-jährigen Verkaufsrekord im Couch Store-Fernsehsender brach, ersetzte drei Wörter in der Standard-Informationsticker-Leiste, was zu einem enormen Anstieg der Anzahl der Käufe führte. Anstelle des Satzes "Operatoren warten, bitte rufen Sie jetzt an" folgerte Collen: "Wenn die Operatoren beschäftigt sind, rufen Sie bitte erneut zurück." Die Autoren erklären dies mit den folgenden soziologischen Beweisen: Die Zuschauer denken, dass wenn die Leitung besetzt ist, Leute wie sie, die den Nachrichtensender sehen, auch anrufen.
Wenn Tricks wie der oben erwähnte regelmäßig angewendet werden, wird ihr Effekt ausgeglichen, da sich Benutzer daran gewöhnen. In Kontrollversuchen verschwindet der Effekt in solchen Fällen schnell. Wir empfehlen daher, mindestens zwei Wochen lang ein Experiment durchzuführen und die Dynamik zu überwachen. Obwohl in der Praxis solche Dinge selten sind [11; 18]. Situationen, in denen wir einen positiven Effekt der Auswirkungen solcher Änderungen beobachteten, wurden mit Empfehlungssystemen in Verbindung gebracht, wenn die Änderung an sich einen kurzfristigen Effekt hat oder wenn die endgültigen Ressourcen für die Verarbeitung verwendet werden.
Wenn LinkedIn beispielsweise den Funktionsalgorithmus "Personen, die Sie vielleicht kennen" geändert hat, hat dies nur zu einem einmaligen Anstieg der Klickmetriken geführt. Selbst wenn der Algorithmus viel besser funktioniert, kennt jeder Benutzer eine begrenzte Anzahl von Personen, und nachdem er seine Hauptbekannten kontaktiert hat, wird die Wirkung eines neuen Algorithmus nachlassen.
Beispiel: Öffnen von Links in einer neuen Registerkarte. Eine Reihe von drei Experimenten
Im August 2008 führte MSN UK ein Experiment für mehr als 900.000 Benutzer durch, bei dem der Link zu HotMail in einem neuen Tab (oder einem neuen Fenster in älteren Browsern) geöffnet wurde. Wir haben zuvor berichtet [7], dass diese minimale Änderung (eine Codezeile) zu einer Zunahme der Beteiligung von MSN-Benutzern führte. Das Engagement, gemessen an der Anzahl der Klicks pro Benutzer auf der Startseite, stieg bei den Benutzern, die auf HotMail geklickt haben, um 8,9%.
Im Juni 2010 haben wir das Experiment vor einem Publikum von 2,7 Millionen MSN-Benutzern in den USA reproduziert. Die Ergebnisse waren ähnlich. Tatsächlich ist dies auch ein Beispiel für ein Merkmal mit dem Effekt der Neuheit. Am ersten Tag der Einführung für alle Benutzer waren 20% der Bewertungen negativ. In der zweiten Woche sank der Anteil der Unzufriedenen auf 4% und in der dritten und vierten Woche auf 2%. Die Verbesserung der Schlüsselkennzahlen war während dieser Zeit stabil.
Im April 2011 führte MSN in den USA ein sehr umfangreiches Experiment mit mehr als 12 Millionen Benutzern durch, denen eine Seite mit Suchergebnissen in einem neuen Tab geöffnet wurde. Das Engagement, gemessen in Klicks auf den Benutzer, stieg um satte 5%. Dies war eine der besten Funktionen im Zusammenhang mit der Benutzerinteraktion, die MSN jemals implementiert hat, und es war eine triviale Änderung des Codes.
Alle großen Suchmaschinen experimentieren mit dem Öffnen von Links in neuen Registerkarten / Fenstern, aber die Ergebnisse für die "Suchergebnisseite" sind nicht so beeindruckend.
Beispiel: Schriftfarbe
Im Jahr 2013 führte Bing eine Reihe von Experimenten mit Schriftfarben durch. Die Gewinnoption ist in Abbildung 1 rechts dargestellt. So wurden die drei Farben geändert:
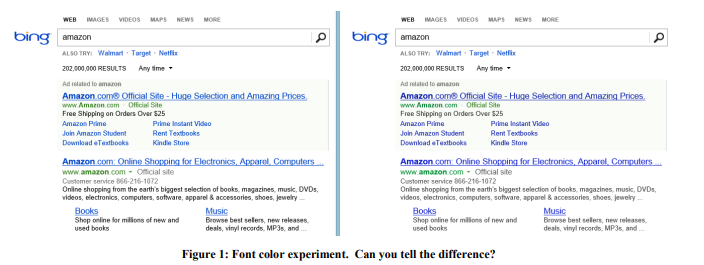
Die Kosten einer solchen Änderung? Günstig: Ersetzen Sie einfach mehrere Farben in der CSS-Datei. Das Ergebnis des Experiments zeigte, dass Benutzer ihre Ziele schneller erreichen (eine strenge Definition des Erfolgs ist ein Geschäftsgeheimnis), und die Monetarisierung aus dieser Überarbeitung stieg um mehr als 10 Millionen US-Dollar pro Jahr. Wir waren skeptisch gegenüber solch erstaunlichen Ergebnissen, also haben wir dieses Experiment an einer viel größeren Stichprobe von 32 Millionen Benutzern reproduziert und die Ergebnisse wurden bestätigt.

Beispiel: Das richtige Angebot zur richtigen Zeit
Bereits im Jahr 2004 enthielt die Amazon-Startseite zwei Slots, deren Inhalt automatisch getestet wurde, sodass Inhalte, die die Zielmetrik besser verbessern, häufiger angezeigt werden. Das Angebot, eine Amazon-Kreditkarte zu erhalten, erreichte den ersten Platz, was seitdem überraschend war Dieses Angebot hatte nur sehr wenige Klicks pro Impression. Tatsache ist jedoch, dass diese Anwendung sehr profitabel war, weshalb der erwartete Wert trotz der geringen Klickrate sehr hoch war. Aber nur, ob der Ort für eine solche Ankündigung erfolgreich ausgewählt wurde? Nein! Infolgedessen wurde der Vorschlag zusammen mit einem einfachen Beispiel für den Vorteil in den Warenkorb verschoben, den der Benutzer nach dem Hinzufügen des Produkts sieht. Daher wurde der Vorteil dieses Vorschlags am Beispiel jedes Produkts hervorgehoben. Wenn der Benutzer Waren in den Warenkorb gelegt hat, ist dies eine klare Absicht, einen Kauf zu tätigen, und es ist Zeit für ein solches Angebot.

Ein Kontrollexperiment zeigte, dass eine so einfache Änderung jährlich mehrere zehn Millionen Dollar einbrachte.
Beispiel: Antivirus
Werbung ist ein profitables Geschäft, und die von Benutzern installierte "kostenlose" Software enthält häufig einen böswilligen Teil, der Seiten mit Anzeigen verstopft. Abbildung 2 zeigt beispielsweise, wie die Bing-Ergebnisseite für einen Benutzer mit einem Schadprogramm aussieht, das der Seite viele Anzeigen hinzugefügt hat (rot hervorgehoben).
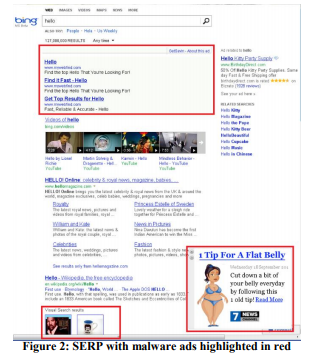
Benutzer bemerken normalerweise nicht einmal, dass so viel Werbung nicht von der Website angezeigt wird, die sie besuchen, sondern von bösartigem Code, den sie versehentlich installiert haben. Das Experiment war schwierig zu implementieren, aber ideologisch relativ einfach: Ändern der grundlegenden Verfahren zum Ändern des DOM und Einschränken der Anwendungen, die die Seite ändern können. Das Experiment wurde über 3,8 Millionen Benutzer durchgeführt, deren Computer Code von Drittanbietern hatten, der das DOM bearbeitete. In der Testgruppe wurden diese Änderungen blockiert. Die Ergebnisse zeigten eine Verbesserung aller Schlüsselmetriken, einschließlich einer Leitmetrik wie der Anzahl der Sitzungen pro Benutzer, d. H. Leute kamen öfter auf die Seite. Darüber hinaus erledigten Benutzer ihre Aufgaben erfolgreicher und schneller, und der Jahresumsatz stieg um mehrere Millionen Dollar. Die Seitenladegeschwindigkeit, die wir in Regel Nr. 4 diskutieren werden, hat sich für die vom Experiment betroffenen Seiten um Hunderte von Millisekunden verringert.
Die Entwicklung von zwei weiteren kleinen Änderungen an Bing, die streng vertraulich sind, dauerte Tage und führte jeweils zu einer Steigerung der Werbeeinnahmen um fast 100 Millionen US-Dollar pro Jahr. In einem vierteljährlichen Bericht von Microsoft im Oktober 2013 heißt es: "Die Werbeeinnahmen aus der Suche sind um 47% gestiegen, da die Gewinne aus jeder Suche und jeder Seite gestiegen sind." Diese beiden Änderungen haben maßgeblich zum genannten Gewinnwachstum beigetragen.
Nach diesen Beispielen könnten Sie denken, dass sich Unternehmen auf viele kleine Änderungen konzentrieren sollten. Aber unten sehen Sie, dass dies überhaupt nicht der Fall ist. Ja, Ausbrüche treten aufgrund kleiner Änderungen auf, sind jedoch sehr selten und unerwartet: In Bing erzielt wahrscheinlich eines von 500 Experimenten einen so hohen ROI und ein reproduzierbares positives Ergebnis. Wir behaupten nicht, dass diese Ergebnisse auf anderen Gebieten reproduzierbar sind, wir wollen nur die Idee vermitteln: Die Durchführung einfacher Experimente ist die Mühe wert und kann letztendlich zu einem Durchbruch führen.
Die Gefahr, die sich aus der Konzentration auf kleine Änderungen ergibt, ist Inkrementalismus: Eine Organisation mit Selbstachtung sollte eine Reihe von Änderungen mit einem potenziell hohen ROI aufweisen, gleichzeitig sollten jedoch mehrere wichtige Änderungen vorgenommen werden, um den großen Jackpot zu knacken [23].
Regel Nummer 2: Änderungen wirken sich selten positiv auf wichtige Kennzahlen aus
Wie Al Pacino im Film Jeden Sonntag sagte, wird der Sieg Zentimeter für Zentimeter gegeben. Jährlich werden Hunderte und Tausende von Experimenten an Standorten wie Bing durchgeführt. Die meisten schlagen fehl, und diejenigen, die erfolgreich sind, wirken sich um 0,1% bis 1,0% auf die Schlüsselmetrik aus, was die Gesamtwirkung verringert. Die in der vorherigen Regel beschriebenen kleinen Änderungen mit großer Wirkung treten auf, sind jedoch selten.
Es ist wichtig, zwei Dinge zu beachten:
- Wichtige Metriken beziehen sich nicht auf eine einzelne Funktion, die leicht verbessert werden kann, sondern auf eine Metrik, die für das gesamte Unternehmen von Bedeutung ist: beispielsweise die Anzahl der Sitzungen pro Benutzer [18] oder die Zeit bis zum Erreichen des Benutzerziels [24].
Bei der Entwicklung eines Features ist es sehr einfach, die Anzahl der Klicks auf dieses Feature (oder eine andere Feature-Metrik) erheblich zu verbessern, indem Sie es einfach hervorheben oder vergrößern. Aber um die Klickrate der gesamten Seite oder der gesamten Benutzererfahrung zu erhöhen, liegt hier die Herausforderung. Die meisten Funktionen führen nur zu Klicks auf der Seite und verteilen sie auf verschiedene Bereiche. - Metriken sollten in kleine Segmente unterteilt werden, damit sie viel einfacher zu optimieren sind. Kann ein Team beispielsweise die Messdaten für Wetterabfragen bei Bing problemlos verbessern oder TV-Programme bei Amazon kaufen? Hinzufügen eines guten Vergleichstools. Eine Verbesserung der Schlüsselkennzahlen um 10 Prozent löst sich jedoch aufgrund der Segmentgröße in den Kennzahlen des gesamten Produkts auf. Eine 10-prozentige Verbesserung in einem 1-prozentigen Segment wirkt sich beispielsweise um etwa 0,1% auf das gesamte Projekt aus (ungefähr, denn wenn sich die Segmentmetriken vom Durchschnitt unterscheiden, kann der Effekt auch unterschiedlich sein).
Die Bedeutung dieser Regel ist groß, da während der Experimente falsch positive Fehler auftreten. Sie haben zwei Arten von Gründen:
- Die ersten werden durch Statistiken verursacht. Wenn wir tausend Experimente pro Jahr durchführen, führt die Wahrscheinlichkeit eines falsch positiven Fehlers von 0,05 dazu, dass wir für eine feste Metrik hunderte Male ein falsch positives Ergebnis erhalten. Und wenn wir mehrere Metriken verwenden, die nicht miteinander korreliert sind, verstärkt sich dieses Ergebnis nur. Selbst große Websites wie Bing verfügen nicht über genügend Datenverkehr, um die Empfindlichkeit zu erhöhen und Schlussfolgerungen mit einem niedrigeren p-Wert für Metriken wie die Anzahl der Sitzungen pro Benutzer zu ziehen.
- , , .
[11]. [25;26]. , , p-value 0,05 - .
:
Wenn wir eine vorläufige Erfolgswahrscheinlichkeit von ⅓ haben (wie in [7] gesagt, ist dies der Durchschnittswert unter den Experimenten bei Microsoft), beträgt die hintere Wahrscheinlichkeit eines wirklich positiven statistisch signifikanten Experiments 89%. Und wenn das Experiment eines der Experimente ist, über die wir in der ersten Regel gesprochen haben, wenn nur 1 von 500 eine Durchbruchlösung enthält, sinkt die Wahrscheinlichkeit auf 3,1%.
Eine lustige Konsequenz dieser Regel ist die Tatsache, dass es viel einfacher ist, sich an jemandem festzuhalten, als sich allein zu entwickeln. Entscheidungen in einem Unternehmen, das sich auf statistische Signifikanz konzentriert, wirken sich eher positiv aus. Wenn wir beispielsweise eine Erfolgsrate von Experimenten von 10 bis 20% haben und die Tests der Funktionen durchführen, die erfolgreich waren und in anderen Suchmaschinen eingesetzt wurden, ist unser Erfolgsniveau höher. Das Gegenteil ist auch der Fall: Andere Suchmaschinen müssen ebenfalls die von Bing implementierten Dinge testen und in die Tat umsetzen.
Mit der Erfahrung haben wir gelernt, Ergebnissen nicht zu vertrauen, die zu gut aussehen, um wahr zu sein. Menschen reagieren unterschiedlich auf unterschiedliche Situationen. Sie vermuten, dass etwas nicht stimmt, studieren die negativen Ergebnisse von Experimenten mit ihren großartigen neuen Funktionen, stellen Fragen und tauchen tiefer in die Suche nach den Gründen für dieses Ergebnis ein. Aber wenn das Ergebnis einfach positiv ist, lässt der Verdacht nach und die Menschen beginnen zu feiern und studieren nicht tiefer und suchen nicht nach Anomalien.
Wenn die Ergebnisse außergewöhnlich gut sind, sind wir es gewohnt, das Twymansche Gesetz zu befolgen [27]: Alles, was interessant oder anders aussieht, ist normalerweise falsch.
Twymans Gesetz kann mit Bayes'scher Folgerung erklärt werden. Nach unserer Erfahrung wussten wir, dass ein Durchbruch selten vorkommt. Zum Beispiel haben mehrere Experimente unsere Leitmetrik, die Anzahl der Sitzungen pro Benutzer, erheblich verbessert. Stellen Sie sich vor, dass die Verteilung, auf die wir in den Experimenten stoßen, normal ist, zentriert auf Punkt 0 und mit einer Standardabweichung von 0,25%. Wenn das Experiment + 2% zum Wert der Schlüsselmetrik ergab, nennen wir das Twymansche Gesetz und sagen, dass dies ein sehr interessantes Ergebnis ist, das in einem Abstand von 8 Standardabweichungen vom Durchschnitt liegt und eine Wahrscheinlichkeit von
10-15 hat , ohne andere Faktoren. Selbst mit statistischer Signifikanz ist die vorläufige Erwartung so stark, dass wir die Feier des Erfolgs verschieben und tiefer in die Suche nach der Ursache des falsch positiven Fehlers des zweiten Typs einsteigen werden. Das Twymansche Gesetz wird oft angewendet, um zu beweisen, dass
=NP . Heute wird sich kein Site-Editor freuen, wenn er solche Beweise erhält. Höchstwahrscheinlich wird er sofort mit einer Vorlagenantwort antworten: "In Ihrem Beweis, dass P = NP ist, wurde auf Seite X ein Fehler gemacht."
Beispiel: Ersatz-Office-Online-Metrik
Cook und sein Team [17] sprachen über ein interessantes Experiment, das sie mit Microsoft Office Online durchgeführt hatten. Das Team testete ein neues Seitendesign, bei dem ein Knopf stark hervorstach und zur Bezahlung des Produkts aufrief. Die Schlüsselmetrik, die das Team messen wollte: die Anzahl der Einkäufe pro Benutzer. Die Verfolgung realer Einkäufe erforderte jedoch eine Änderung des Abrechnungssystems, und zu diesem Zeitpunkt war dies schwierig. Dann entschied sich das Team, die Metrik „Klicks, die zu einem Kauf führen“ zu verwenden und die Formel
( ) * = anzuwenden.
( ) * = , bei denen die Conversion von Klicks zu Kauf erfolgt.
Zu ihrer Überraschung verringerte sich die Anzahl der Klicks im Experiment um 64%. Solche schockierenden Ergebnisse erzwangen eine eingehendere Analyse der Daten, und es stellte sich heraus, dass die Annahme einer stabilen Konvertierung vom Klick zum Kauf falsch ist. Die experimentelle Seite, auf der die Kosten des Produkts angegeben waren, zog weniger Klicks an, aber die Benutzer, die darauf klickten, waren besser qualifiziert und hatten eine viel größere Conversion von Klick zu Kauf.
Beispiel: Mehr Klicks von einer langsamen Seite
Der Bing-Suchergebnisseite wurde JavaScript hinzugefügt. Dieses Skript verlangsamte normalerweise die Seite, sodass jeder einen leichten negativen Einfluss auf die wichtigsten Messgrößen für das Engagement erwarten konnte, z. B. die Anzahl der Klicks auf einen Benutzer. Aber die Ergebnisse zeigten das Gegenteil, es gab mehr Klicks! [18] Trotz der positiven Dynamik folgten wir Twymans Gesetz und lösten das Rätsel. Click-Tracker basieren auf Web Beacons, und einige Browser haben keinen Anruf getätigt, wenn der Benutzer die Seite verlassen hat. [28] Somit beeinflusste JavaScript die Genauigkeit der Klickzahlen.
Beispiel: Bing Edge
Für mehrere Monate im Jahr 2013 hat Bing sein Content Delivery Network von Akamai auf sein eigenes Bing Edge umgestellt. Das Umschalten des Datenverkehrs auf Bing Edge wurde mit vielen anderen Verbesserungen kombiniert. Mehrere Teams berichteten, dass sie wichtige Kennzahlen verbessert haben: Die Klickrate der Bing-Homepage stieg, Funktionen wurden häufiger verwendet und der Abfluss begann zu sinken. Und so stellte sich heraus, dass all diese Verbesserungen mit sauberen Klickzahlen zusammenhängen: Bing Edge verbesserte nicht nur die Seitengeschwindigkeit, sondern auch die Zustellbarkeit von Klicks. Um den Effekt zu bewerten, haben wir ein Experiment gestartet, bei dem der Leuchtturm-Ansatz zum Verfolgen von Klicks durch einen Ansatz mit einem erneuten Laden der Seite ersetzt wurde. Diese Technik wird in der Werbung verwendet und führt zu einem leichten Klickverlust, wodurch der Effekt jedes Klicks verlangsamt wird. Die Ergebnisse zeigten, dass der Prozentsatz der verlorenen Klicks um mehr als 60% gesunken ist! Die meisten der in diesem Zeitraum angekündigten Erfolge waren das Ergebnis einer verbesserten Klickbereitstellung.
Beispiel: MSN Bing Search
Die automatische Vervollständigung ist eine Dropdown-Liste, die Optionen zum Vervollständigen einer Anforderung bietet, während eine Person sie eingibt. MSN plante, diese Funktion mit einem neuen und verbesserten Algorithmus zu verbessern (Entwicklungsteams für Funktionen sind immer bereit zu erklären, warum ihr neuer Algorithmus a priori besser ist als der alte, aber sie sind oft frustriert, wenn sie die Ergebnisse von Experimenten sehen). Das Experiment war ein großer Erfolg: Die Anzahl der Suchanfragen, die mit MSN bei Bing eingingen, nahm erheblich zu. Nach unseren Regeln begannen wir zu verstehen und stellten fest, dass der neue Code beim Klicken auf die Eingabeaufforderung zwei Suchanfragen stellte (von denen eine vom Browser sofort geschlossen wurde, sobald die Suchergebnisse angezeigt wurden).
Die Erklärung für viele positive Ergebnisse ist daher möglicherweise nicht so aufregend. Unsere Aufgabe ist es, einen echten Einfluss auf den Benutzer zu finden. Die Twyman-Regel hat dabei wirklich geholfen und viele der experimentellen Ergebnisse verstanden.
Regel Nummer 3. Ihr Nutzen wird variieren.
Es gibt viele dokumentierte Beispiele für erfolgreiche Kontrollexperimente. Beispiel: „
Welcher Test hat gewonnen? “ Enthält Hunderte von Beispielen für A / B-Tests, und die Liste wird jede Woche aktualisiert.
Obwohl dies ein großartiger Ideengeber ist, haben diese Beispiele mehrere Probleme:
- Qualität variiert. In diesen Studien spricht jemand aus einem Unternehmen über das Ergebnis eines A / B-Tests. Gab es eine Expertenbewertung? Wurde es richtig durchgeführt? Gab es Emissionen? War der p-Wert klein genug (wir haben veröffentlichte A / B-Tests mit einem p-Wert von mehr als 0,05 gesehen, was normalerweise als statistisch nicht signifikant angesehen wird)? Gab es Fallstricke, über die wir zuvor gesprochen haben und die die Testautoren nicht richtig überprüft haben?
- Was in einer Domäne funktioniert, funktioniert möglicherweise nicht in einer anderen. Zum Beispiel empfiehlt Neil Patel [29], das Wort „kostenlos“ in Anzeigen zu verwenden, die eine 30-Tage-Testversion anstelle einer „30-Tage-Geld-zurück-Garantie“ anbieten. Dies funktioniert möglicherweise mit einem Produkt und einer Zielgruppe, aber wir vermuten, dass das Ergebnis stark vom Produkt und der Zielgruppe abhängt. Joshua Porter [30] gibt an, dass "Rot besser als Grün" für Schaltflächen ist, die "Get Started Now" aufrufen. Da wir jedoch nicht viele Websites mit einer roten Handlungsaufforderungstaste gesehen haben, ist dieses Ergebnis anscheinend nicht so gut reproduziert.
- Die Wirkung von Neuheit und erstem Mal. Wir erreichen Stabilität in unseren Experimenten, und viele Experimente in vielen Beispielen wurden nicht lange genug durchgeführt, um solche Effekte zu überprüfen.
- Falsche Interpretation der Ergebnisse. Ein versteckter Grund oder ein bestimmter Faktor wird möglicherweise nicht erkannt oder missverstanden. Wir geben zwei Beispiele. Eines davon ist das erste dokumentierte Kontrollexperiment.
Beispiel 1 Skorbut ist eine Krankheit, die durch einen Mangel an Vitamin C verursacht wird. In den 16 bis 18 Jahrhunderten starben mehr als 100.000 Menschen, die meisten von ihnen waren Seeleute, die lange Reisen unternahmen und länger im Meer blieben, als Obst und Gemüse überleben konnten. Im Jahr 1747 stellte Dr. James Lind fest, dass Skorbut auf Schiffen im Mittelmeer weniger betroffen ist. Er fing an, einigen Seeleuten Zitronen und Orangen zu geben, während andere die übliche Diät überließen. Das Experiment war sehr erfolgreich, aber der Arzt verstand den Grund nicht. Im Royal Maritime Hospital in Großbritannien behandelte er Skorbutpatienten mit konzentriertem Zitronensaft, den er Rob nannte. Der Arzt konzentrierte es durch Erhitzen, wodurch Vitamin C zerstört wurde. Lind verlor das Vertrauen und griff häufig auf Blutvergießen zurück. 1793 wurden echte Tests durchgeführt. und Zitronensaft ist Teil der täglichen Ernährung der Seeleute geworden. Skorbut verschwand schnell und britische Seeleute werden immer noch Zitronengras genannt.
Beispiel 2 Marissa Mayer sprach über ein Experiment, bei dem Google die Anzahl der Ergebnisse auf einer Suchseite von 10 auf 30 erhöhte. Der Traffic und der Gewinn von Nutzern, die bei Google suchten, gingen um 20% zurück. Und wie hat sie das erklärt? Die Seite benötigte eine halbe Sekunde länger, um generiert zu werden. Natürlich ist die Produktivität ein wichtiger Faktor, aber wir vermuten, dass dies nur einen kleinen Teil der Verluste betraf. Hier ist unsere Vision der Ursachen:
- Bing führte isolierte Verlangsamungsexperimente durch [11], bei denen sich nur die Leistung änderte. Eine Verzögerung der Serverantwort von 250 Millisekunden beeinträchtigte den Umsatz um ca. 1,5% und die Klickrate um 0,25%. Dies ist ein großer Einfluss, und es kann davon ausgegangen werden, dass 500 Millisekunden den Umsatz und die Klickrate um 3% bzw. 0,5%, jedoch nicht um 20% beeinflussen (vorausgesetzt, hier gilt eine lineare Annäherung). Alte Tests in Bing [32] zeigten einen ähnlichen Effekt auf Klicks und weniger Auswirkungen auf den Umsatz mit einer Verzögerung von 2 Sekunden.
- Jake Brutlag von Google schrieb in einem Blogbeitrag über ein Experiment [12], dass die Verlangsamung der Suchergebnisse von 100 Millisekunden auf 400 einen signifikanten Einfluss auf die spezifische Anzahl der Suchvorgänge hat und zwischen 0,2% und 0,6% liegt, was sehr gut funktioniert mit unseren Experimenten, aber sehr weit von den Ergebnissen von Marissa Mayer.
- BIng führte ein Experiment durch, bei dem 20 statt 10 Suchergebnisse angezeigt wurden. Durch den Gewinnverlust wurde die Hinzufügung zusätzlicher Werbung vollständig eliminiert (wodurch die Seite noch etwas langsamer wurde). Wir glauben, dass das Verhältnis von Werbung zu Suchalgorithmen viel wichtiger ist als die Leistung.
Wir sind skeptisch gegenüber den vielen bemerkenswerten Ergebnissen von A / B-Tests, die in verschiedenen Quellen veröffentlicht wurden. Fragen Sie sich bei der Überprüfung der Versuchsergebnisse, wie viel Vertrauen Sie in sie haben. Und denken Sie daran, auch wenn die Idee auf einer Site funktioniert hat, ist es nicht erforderlich, dass sie auf einer anderen Site funktioniert. Das Beste, was wir tun können, ist über die Reproduktion von Experimenten und deren Erfolg oder Misserfolg zu sprechen. Es wird für die Wissenschaft am vorteilhaftesten sein.
Regel Nummer 4: Geschwindigkeit bedeutet viel
Webentwickler, die ihre Funktionen mithilfe von Kontrollexperimenten testen, stellten schnell fest, dass die Leistung oder Geschwindigkeit der Website kritische Parameter sind [13; 14; 33]. Selbst eine geringfügige Verzögerung des Betriebs der Site kann wichtige Kennzahlen der Testgruppe beeinflussen.
Der beste Weg, um die Auswirkungen der Leistung zu bewerten, besteht darin, ein isoliertes Verlangsamungsexperiment durchzuführen, d.h. nur mit Verzögerung hinzufügen. Abbildung 3 zeigt ein Standarddiagramm der Beziehung zwischen Leistung und der zu testenden Metrik (CTR, Erfolgsquote der Einheiten und Umsatz). Normalerweise ist die Site umso besser, je schneller sie ist (höher in dieser Grafik). Wenn Sie die Arbeit der Testgruppe in Bezug auf die Kontrollgruppe verlangsamen, können Sie den Einfluss der Leistung auf die Metrik messen, an der Sie interessiert sind. Es ist wichtig zu beachten:
- Die Auswirkung der Verlangsamung auf die Testgruppe wird hier und jetzt gemessen (gestrichelte Linie in der Grafik) und hängt von der Site und der Zielgruppe ab. Wenn sich die Site oder Zielgruppe ändert, kann sich eine Leistungsverschlechterung unterschiedlich auf die wichtigsten Metriken auswirken.
- Das Experiment zeigt die Auswirkung der Verzögerung auf wichtige Metriken. Dies kann sehr nützlich sein, wenn Sie versuchen, die Wirkung einer neuen Funktion zu messen, deren erste Implementierung nicht effektiv ist. Angenommen, es verbessert die Metrik von M um X% und verlangsamt gleichzeitig die Site um T%. Mit dem Experiment mit der Verzögerung können wir den Effekt der Verzögerung auf die Metrik M bewerten, den Effekt des Merkmals korrigieren und den vorhergesagten Effekt X '% erhalten (es ist logisch anzunehmen, dass diese Effekte die Eigenschaft der Additivität haben). Und so können wir die Frage beantworten: "Wie wird sich dies auf die Schlüsselmetrik auswirken, wenn sie effektiv implementiert wird?".
- Wir können davon ausgehen, dass sich die Tatsache, dass die Site schneller arbeitet und zur Berechnung des ROI der Optimierungsbemühungen beiträgt, auf die Schlüsselmetrik auswirkt. Mit einer linearen Näherung (dem ersten Term der Taylor-Reihe) können wir annehmen, dass der Effekt auf die Metrik in beiden Richtungen gleich ist. Wir nehmen an, dass das vertikale Delta in beiden Richtungen gleich und nur im Vorzeichen unterschiedlich ist. Wenn wir also mit der Verzögerung verschiedener Werte experimentieren, können wir uns grob vorstellen, wie sich die Beschleunigung auf dieselben Werte auswirkt. Wir haben solche Tests bei Bing durchgeführt und unsere Theorie wurde vollständig bestätigt.
Wie wichtig ist Leistung? Kritisch wichtig. Bei Amazon führt eine Verlangsamung um 100 Millisekunden zu einem Umsatzrückgang von 1%, wie Greg Linded sagte [34, S. 10]. Die Redner von Bing und Google [32] zeigen einen signifikanten Einfluss der Leistung auf die wichtigsten Messdaten.
Beispiel: Server-Verlangsamungsexperiment
Wir haben in Bing ein zweiwöchiges Experiment durchgeführt, um den Service für 10% der Benutzer um 100 Millisekunden und für andere 10% der Benutzer um 250 Millisekunden zu verlangsamen. Es stellte sich heraus, dass alle 100 Millisekunden Servicebeschleunigung den Umsatz um 0,6% erhöhte. Von hier aus erschien sogar ein Satz, der die Essenz unserer Organisation gut widerspiegelt:
Ein Ingenieur, der die Serverleistung um 10 Millisekunden (1/30 der Geschwindigkeit, mit der wir blinzeln) verbessert, wird seinem Unternehmen mehr als ein Jahr Gewinn einbringen. Jede Millisekunde zählt.
In dem beschriebenen Experiment haben wir die Antwortzeit des Servers und dann die Betriebszeit aller Elemente auf der Seite verlangsamt. Die Seite enthält jedoch wichtigere Teile und weniger wichtige Teile. Beispielsweise wissen Benutzer möglicherweise nicht, dass Elemente außerhalb des Bildschirmbereichs noch nicht geladen wurden. Aber gibt es sofort angezeigte Elemente, die verlangsamt werden können, ohne den Benutzer zu verletzen? Wie Sie unten sehen werden, gibt es solche Elemente.
Beispiel: Die Leistung des rechten Panels ist nicht so kritisch
In Bing befinden sich einige als Snapshots bezeichnete Elemente im rechten Bereich und werden spät geladen (nach dem Ereignis window.onload). Wir haben kürzlich ein Experiment durchgeführt: Elemente des rechten Panels wurden um 250 Millisekunden verlangsamt. Wenn dies wichtige Kennzahlen beeinflusst, ist es so unbedeutend, dass wir nichts bemerkt haben. An dem Experiment waren fast 20 Millionen Benutzer beteiligt.
Die Seitenladezeit (PLT) wird häufig mithilfe des Ereignisses window.onload berechnet, um den Abschluss nützlicher Browseraktivitäten anzuzeigen. Heute weist diese Metrik jedoch einen schwerwiegenden Fehler bei der Arbeit mit modernen Browsern auf. Wie Steve Souders [32] gezeigt hat, wird der obere Rand der Amazon-Seite in 2 Sekunden gerendert, während windows.onload in 5,2 Sekunden ausgelöst wird. Schurman [32] gab an, dass sie die Seite dynamisch rendern konnten, daher war es wichtig, dass sie den Header sehr schnell zeigten. Das Gegenteil ist auch der Fall: In Google Mail wird windows.onload nach 3,3 Sekunden ausgelöst, während in diesem Moment nur die Download-Leiste auf dem Bildschirm angezeigt wird und der gesamte Inhalt in 4,8 Sekunden angezeigt wird.
Es gibt Metriken, die sich auf die Zeit beziehen, zum Beispiel: Zeit bis zum ersten Ergebnis (z. B. Zeit bis zum ersten Tweet auf Twitter, erstes Suchergebnis auf der Ergebnisseite). Der Begriff „Wahrgenommene Leistung“ wird jedoch immer verwendet, um eine solche Geschwindigkeit der Seite zu beschreiben, sodass der Benutzer sie als ausreichend voll wahrnimmt. Das Konzept der „wahrgenommenen Leistung“ ist intuitiver zu beschreiben als streng formuliert. Daher hat keiner der Browser Pläne, das Ereignis
perception.ready() zu implementieren. Um dieses Problem zu lösen, werden viele Annahmen und Annahmen verwendet, zum Beispiel:
- Top of Page (AFT) -Zeit [37]. Gemessen als der Moment, in dem alle oberen Pixel der Seite angezeigt werden. Die Implementierung basiert auf Heuristiken, die besonders komplex sind, wenn es um Videos, Gifs, Bildlaufgalerien und andere dynamische Inhalte geht, die den oberen Rand der Seite verändern. Die Schwellenwerte können auf "Prozentsatz der gezeichneten Pixel" eingestellt werden, um den Einfluss kleiner und unbedeutender Elemente zu vermeiden, die die gemessene Metrik erhöhen können.
- Der Geschwindigkeitsindex [38] ist eine Verallgemeinerung der AFT, die den Durchschnitt der Zeit bildet, in der sichtbare Seitenelemente auf dem Bildschirm angezeigt werden. Die Geschwindigkeit leidet nicht unter kleinen Elementen, die zu spät erscheinen, wird jedoch durch dynamischen Inhalt beeinflusst, der den oberen Rand der Seite verändert.
- Seitenphasenzeit und Benutzerverfügbarkeitszeit [39]. Seitenphasenzeit - Die Zeit, die für jede einzelne Seitenwiedergabephase benötigt wird. , . — , .
W3C- , HTML, , , . , , , .
Bing , « » (TTS) [24] . — . , 30 . — «Perceived performance». , ; , , . , , , . , . , , , , — .
№5: — , —
, Bing — , , . , — , , . , , . , , .
:
Bing . , «data mining», Bing «Examples of data mining», «Advantages of Data Mining», «definition of data mining», «Data mining companies»,«data mining software» .. . 10 . , (p-value 0,64).
:
Bing , , , , . . 17 %, (p-value 0,71).
:
Bing , 10 . , :
- , , «ebay», CTR 75 %. 10 . : 8 , , 4 . (p-value 0,92), production.
- , «» , Bing (14 ). , 3 «» , : 1,8 % , 30 , 18 % ( ), (p-value 0,93). .
:
. 10 , 12 % ( $150 , ). , (p-value 0,83)
, , . , , .
, ( Microsoft, Amazon .), CTR. , , . , . , . «» . : — , — .
№6: ,
. .. [40]: « , , . , — ». , online-, , [17;41], , , . , . LinkedIn.
: LinkedIn
LinkedIn . 2013 , , , , — LinkedIn, . , : , . , , , . . : . , , , . , , - , , - . .
: LinkedIn
LinkedIn . , . , . , . , , . , . , , , . , , , . , , . , . , .
offline- , , online, , , [4;11]. (Mullty-Variable) , MV-. ( /B/C/D) .
— Agile, MVP [15]: MVT, , . , . , , .. MV- - .
: 1 % , . Agile- Knight Capital, 2012 440 Knights 75 %.
№7:
. , , . , , . , . , [42] , , n > 30, . , . — , Neil Patel , .
, ( ) [16], , . , , .
,
355 * s^2 , , .
s — , :
$$s = \frac{E (XE (X))^3}{\Var (X)^{3/2}}$$, 1. , , Bing:
|
|
|
|
Revenue/User
| 17,9
| 114 .
| 4,4 %
|
Revenue/User (capped)
| 5,2
| 9,7 .
| 10,5 %
|
Sessions/User
| 3,6
| 4,7 .
| 5,4 %
|
Time To Success
| 2,1
| 1,55 .
| 12,3 %
|
, « » 10, « » — 30. 95 % , , 0,025, 0,3 0,2. Boos Hughes-Oliver [43]. , . , 18,2, 114 . . 4 , 100 1000 , QQ. 95- , , 5 %. 100 000 , -2 2.

, - , . , « » , , 18 5, . , 30 % , .
, , . , , , , 0. , 1.
, [16]. bootstrap [44].
Fazit
7 , , . , , , , . , Twyman' , , . , , , , . — — . , , , , — . , , (, ). , , . — , , , . , : , . , , . , . Agile. — , . , , . , — . , , , .
, , . Mujtaba Khambatti, John Psaroudakis, Sreenivas Addagatke, . Juan Lavista Ferres, Urszula Chajewska, Greben Langendijk, Lukas Vermeer, Jonas Alves. Eytan Bakshy, Brooks Bell Colin McFarland.
- Kohavi, Ron and Round, Matt. Front Line Internet Analytics at Amazon.com. [ed.] Jim Sterne. Santa Barbara, CA: sn, 2004. ai.stanford.edu/~ronnyk/emetricsAmazon.pdf .
- McKinley, Dan. Design for Continuous Experimentation: Talk and Slides. [Online] Dec 22, 2012. mcfunley.com/designfor-continuous-experimentation .
- Bakshy, Eytan and Eckles, Dean. Uncertainty in Online Experiments with Dependent Data: An Evaluation of Bootstrap Methods. KDD 2013: Proceedings of the 19th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2013.
- Tang, Diane, et al. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. Proceedings 16th Conference on Knowledge Discovery and Data Mining. 2010.
- Moran, Mike. Multivariate Testing in Action: Quicken Loan's Regis Hadiaris on multivariate testing. Biznology Blog by Mike Moran. [Online] December 2008. www.biznology.com/2008/12/multivariate_testing_in_action .
- Posse, Christian. Key Lessons Learned Building LinkedIn Online Experimentation Platform. Slideshare. [Online] March 20, 2013. www.slideshare.net/HiveData/googlecontrolledexperimentationpanelthe-hive .
- Kohavi, Ron, Crook, Thomas and Longbotham, Roger. Online Experimentation at Microsoft. Third Workshop on Data Mining Case Studies and Practice Prize. 2009. http://expplatform.com/expMicrosoft.aspx .
- Amatriain, Xavier and Basilico, Justin. Netflix Recommendations: Beyond the 5 stars. [Online] April 2012. techblog.netflix.com/2012/04/netflix-recommendationsbeyond-5-stars.html .
- McFarland, Colin. Experiment!: Website conversion rate optimization with A/B and multivariate testing. sl: New Riders, 2012. 978-0321834607.
- Smietana, Brandon. Zynga: What is Zynga's core competency? Quora. [Online] Sept 2010. www.quora.com/Zynga/What-is-Zyngas-corecompetency/answer/Brandon-Smietana .
- Kohavi, Ron, et al. Online Controlled Experiments at Large Scale. KDD 2013: Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 2013. bit.ly/ExPScale .
- Brutlag, Jake. Speed Matters. Google Research blog. [Online] June 23, 2009. googleresearch.blogspot.com/2009/06/speed-matters.html .
- Sullivan, Nicole. Design Fast Websites. Slideshare. [Online] Oct 14, 2008. www.slideshare.net/stubbornella/designingfast-websites-presentation .
- Kohavi, Ron, Henne, Randal M and Sommerfield, Dan. Practical Guide to Controlled Experiments on the Web: Listen to Your Customers not to the HiPPO. The Thirteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2007). August 2007, pp. 959-967. www.expplatform.com/Documents/GuideControlledExperiments.pdf .
- Ries, Eric. The Lean Startup: How Today's Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses. sl: Crown Business, 2011. 978-0307887894.
- Kohavi, Ron, et al. Controlled experiments on the web: survey and practical guide. Data Mining and Knowledge Discovery. February 2009, Vol. 18, 1, pp. 140-181. www.exp-platform.com/Pages/hippo_long.aspx .
- Crook, Thomas, et al. Seven Pitfalls to Avoid when Running Controlled Experiments on the Web. [ed.] Peter Flach and Mohammed Zaki. KDD '09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 2009, pp. 1105-1114. www.expplatform.com/Pages/ExPpitfalls.aspx .
- Kohavi, Ron, et al. Trustworthy online controlled experiments: Five puzzling outcomes explained. Proceedings of the 18th Conference on Knowledge Discovery and Data Mining. 2012, www.expplatform.com/Pages/PuzzingOutcomesExplained.aspx .
- Wikipedia contributors. Fisher's method. Wikipedia. [Online] Jan 2014. http://en.wikipedia.org/wiki/Fisher %27s_method .
- Eisenberg, Bryan. How to Increase Conversion Rate 1,000 Percent. ClickZ. [Online] Feb 28, 2003. www.clickz.com/showPage.html?page=1756031 .
- Spool, Jared. The $300 Million Button. USer Interface Engineering. [Online] 2009. www.uie.com/articles/three_hund_million_button .
- Goldstein, Noah J, Martin, Steve J and Cialdini, Robert B. Yes!: 50 Scientifically Proven Ways to Be Persuasive. sl: Free Press, 2008. 1416570969.
- Collins, Jim and Porras, Jerry I. Built to Last: Successful Habits of Visionary Companies. sl: HarperBusiness, 2004. 978- 0060566104.
- Badam, Kiran. Looking Beyond Page Load Times – How a relentless focus on Task Completion Times can benefit your users. Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/32 820.
- Why Most Published Research Findings Are False. Ioannidis, John P. 8, 2005, PLoS Medicine, Vol. 2, p. e124. www.plosmedicine.org/article/info :doi/10.1371/journal.pme d.0020124.
- Wacholder, Sholom, et al. Assessing the Probability That a Positive Report is False: An Approach for Molecular Epidemiology Studies. Journal of the National Cancer Institute. 2004, Vol. 96, 6. jnci.oxfordjournals.org/content/96/6/434.long .
- Ehrenberg, ASC The Teaching of Statistics: Corrections and Comments. Journal of the Royal Statistical Society. Series A, 1974, Vol. 138, 4.
- Ron Kohavi, David Messner,Seth Eliot, Juan Lavista Ferres, Randy Henne, Vignesh Kannappan,Justin Wang. Tracking Users' Clicks and Submits: Tradeoffs between User Experience and Data Loss. Redmond: sn, 2010.
- Patel, Neil. 11 Obvious A/B Tests You Should Try. QuickSprout. [Online] Jan 14, 2013. http://www.quicksprout.com/2013/01/14/11-obvious-ab-tests-youshould-try/ .
- Porter, Joshua. The Button Color A/B Test: Red Beats Green. Hutspot. [Online] Aug 2, 2011. blog.hubspot.com/blog/tabid/6307/bid/20566/The-ButtonColor-AB-Test-Red-Beats-Green.aspx .
- Linden, Greg. Marissa Mayer at Web 2.0. Geeking with Greg. [Online] Nov 9, 2006. glinden.blogspot.com/2006/11/marissa-mayer-at-web20.html .
- Performance Related Changes and their User Impact. Schurman, Eric and Brutlag, Jake. sl: Velocity 09: Velocity Web Performance and Operations Conference, 2009.
- Souders, Steve. High Performance Web Sites: Essential Knowledge for Front-End Engineers. sl: O'Reilly Media, 2007. 978-0596529307.
- Linden, Greg. Make Data Useful. [Online] Dec 2006. sites.google.com/site/glinden/Home/StanfordDataMining.20 06-11-28.ppt.
- Wikipedia contributors. Above the fold. Wikipedia, The Free Encyclopedia. [Online] Jan 2014. en.wikipedia.org/wiki/Above_the_fold .
- Souders, Steve. Moving beyond window.onload (). High Performance Web Sites Blog. [Online] May 13, 2013. www.stevesouders.com/blog/2013/05/13/moving-beyondwindow-onload .
- Brutlag, Jake, Abrams, Zoe and Meenan, Pat. Above the Fold Time: Measuring Web Page Performance Visually. Velocity: Web Performance and Operations Conference. 2011. en.oreilly.com/velocitymar2011/public/schedule/detail/18692 .
- Meenan, Patrick. Speed Index. WebPagetest. [Online] April 2012. sites.google.com/a/webpagetest.org/docs/usingwebpagetest/metrics/speed-index .
- Meenan, Patrick, Feng, Chao (Ray) and Petrovich, Mike. Going Beyond onload — How Fast Does It Feel? Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/31 344.
- Fisher, Ronald A. Presidential Address. Sankhyā: The Indian Journal of Statistics. 1938, Vol. 4, 1. www.jstor.org/stable/40383882 .
- Kohavi, Ron and Longbotham, Roger. Unexpected Results in Online Controlled Experiments. SIGKDD Explorations. 2010, Vol. 12, 2. www.exp-platform.com/Documents/2010- 12 %20ExPUnexpectedSIGKDD.pdf.
- Montgomery, Douglas C. Applied Statistics and Probability for Engineers. 5th. sl: John Wiley & Sons, Inc, 2010. 978- 0470053041.
- Boos, Dennis D and Hughes-Oliver, Jacqueline M. How Large Does n Have to be for Z and t Intervals? The American Statistician. 2000, Vol. 54, 2, pp. 121-128.
- Efron, Bradley and Robert J. Tibshirani. An Introduction to the Bootstrap. New York: Chapman & Hall, 1993. 0-412-04231- 2.