Hallo Habr! Ich präsentiere Ihnen die Übersetzung des Artikels „
Lernen eines 3D-Gesichts-Morphable-Modells aus 2D-Bildern “.

Das dreidimensionale morphbare Modell des Gesichts (3D Morphable Model, im Folgenden 3DMM) ist ein statistisches Modell der Struktur und Textur des Gesichts, das von Computer Vision, Computergrafik, bei der Analyse des menschlichen Verhaltens und in der plastischen Chirurgie verwendet wird.
Die Einzigartigkeit jedes Gesichtsmerkmals macht das Modellieren eines menschlichen Gesichts zu einer
nicht trivialen Aufgabe . 3DMM wird erstellt, um ein Gesichtsmodell in einem Raum expliziter Entsprechungen zu erhalten. Dies bedeutet eine punktweise Entsprechung zwischen dem resultierenden Modell und anderen Modellen, die Morphing ermöglichen. Darüber hinaus sollten Transformationen auf niedriger Ebene, wie z. B. Unterschiede zwischen einem männlichen Gesicht und einem weiblichen, neutralen Gesichtsausdruck eines Lächelns, in 3DMM widergespiegelt werden.

Forscher der University of Michigan bieten die neueste 3DMM-Methode für tiefes Lernen an. Mit der hohen Effizienz tiefer neuronaler Netze zur Implementierung nichtlinearer Abbildungen können mit ihrer Methode 3DMM basierend auf einem in einer beliebigen Umgebung aufgenommenen 2D-Bild erhalten werden.
Frühere Ansätze
Typischerweise werden 3DMMs unter Verwendung eines Satzes von 3D-Gesichts-Scans und eines Satzes von 2D-Bildern derselben Gesichter erhalten. Der allgemein akzeptierte Ansatz besteht darin, im Unterricht mit einem Lehrer eine Dimensionsreduktion zu verwenden, die mithilfe der Hauptkomponentenanalyse (PCA) an einem Trainingsdatensatz durchgeführt wird, der aus 3D-Scans von Gesichtern und entsprechenden 2D-Bildern besteht. Bei Verwendung linearer Modelle wie PCA können nichtlineare Transformationen und Gesichtsvariationen in 3DMM nicht berücksichtigt werden. Darüber hinaus wird zur Modellierung genauer 3D-Texturen von Gesichtern eine große Menge an „3D-Informationen“ benötigt. Somit ist die Verwendung dieses Ansatzes unwirksam.
Vorgeschlagene Methode
Die Idee des
vorgeschlagenen Verfahrens besteht darin, tiefe neuronale Netze oder insbesondere
Faltungs-neuronale Netze (die für das betrachtete Problem besser geeignet und hinsichtlich der Rechenzeit kostengünstiger sind als mehrschichtige Perzeptrone) zu verwenden, um 3DMM zu erhalten. Ein codierendes neuronales Netzwerk (Codierer) nimmt ein Gesichtsbild als Eingabe und generiert Gesichtstextur- und Albedoparameter, mit denen zwei decodierende neuronale Netzwerke (Decodierer) Textur und Albedo bewerten.
Wie bereits erwähnt, weist lineares 3DMM eine Reihe von Problemen auf, wie beispielsweise die Notwendigkeit von 3D-Gesichtsabtastungen, die Unfähigkeit, aus einem beliebigen Winkel aufgenommene Bilder zu verwenden, und die begrenzte Genauigkeit der Darstellung aufgrund der Verwendung von linearem PCA. Das vorgeschlagene Verfahren ermöglicht es wiederum, ein nichtlineares 3DMM-Modell zu erhalten, das auf 2D-Bildern von hochauflösenden Gesichtern basiert,
die aus einem beliebigen Winkel aufgenommen wurden .
Planare Ansicht
Bei ihrem Ansatz verwenden die Forscher eine detaillierte 2D-Gesichtskarte, um ihre Textur und Albedo darzustellen. Sie argumentieren, dass die Berücksichtigung räumlicher Informationen eine wichtige Rolle spielt, da sie Faltungs-Neuronale Netze verwenden und Frontalbilder des Gesichts nur wenige Informationen über die Seiten enthalten. Deshalb fiel ihre Wahl auf die planare Darstellung.
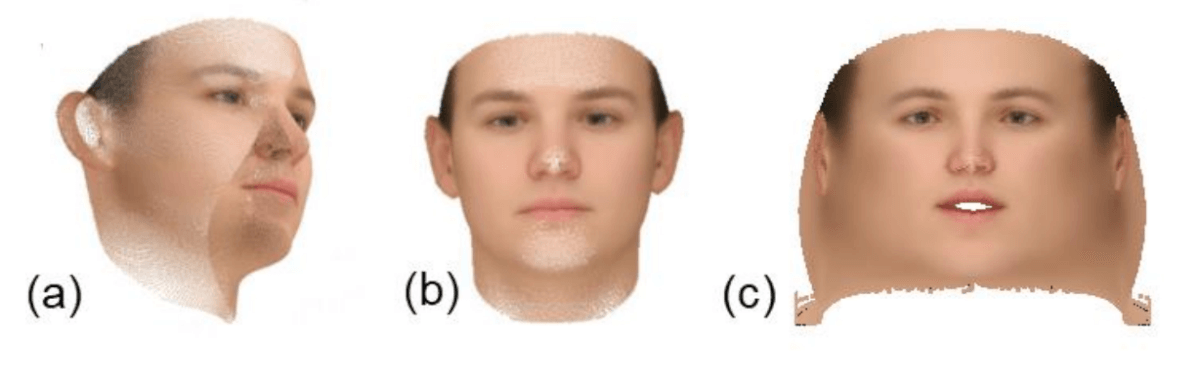
Drei verschiedene Ansichten der Albedo. (a) - 3D-Darstellung, (c) - Albedo als 2D-Frontalbild eines Gesichts, (c) - planare Darstellung.
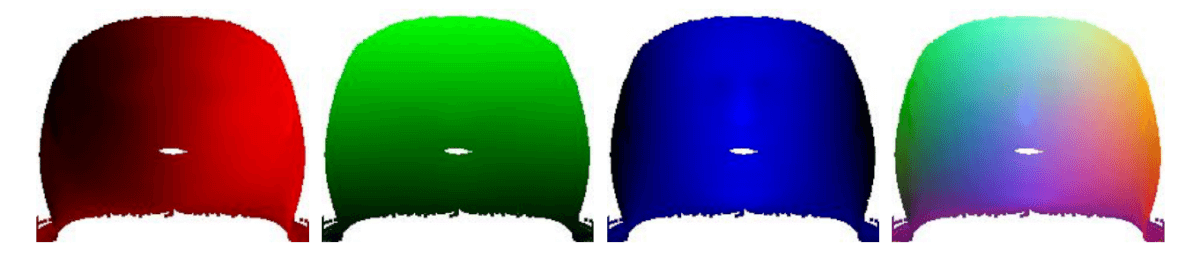
Planare Ansicht. x, y, z und zusammenfassende Darstellung der Textur.
Neuronale Netzwerkarchitektur
Die Forscher entwarfen ein neuronales Netzwerk, das ein Bild als Eingabe in einen Vektor aus Textur, Albedo und Beleuchtung codiert. Codierte versteckte Vektoren für Albedo und Textur werden unter Verwendung von zwei Decodern decodiert, die als Faltungs-Neuronale Netze verwendet werden. Am Ausgang geben die Decoder die Blendung des Gesichts, seine Albedo und 3D-Gesichtsstruktur ab. Unter Verwendung dieser Parameter generiert eine differenzierbare Rendering-Ebene ein Gesichtsmodell, indem die vom Encoder erhaltenen Parameter für 3D-Textur, Albedo, Beleuchtung und Kamerastandort kombiniert werden. Die Architektur ist in der folgenden Abbildung dargestellt.
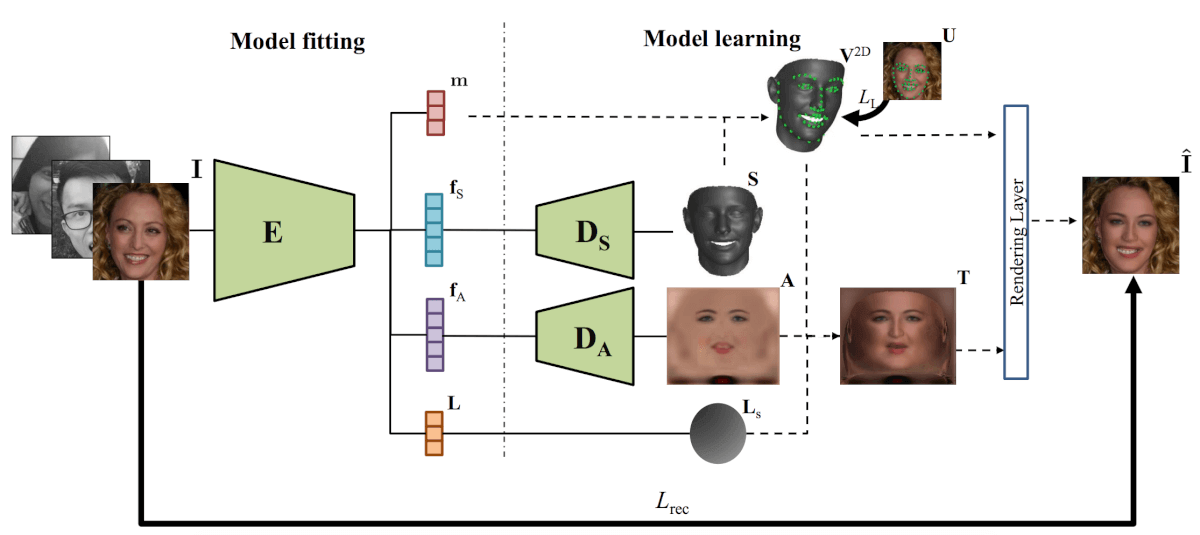
Die Architektur des vorgeschlagenen Verfahrens zum Erhalten von nichtlinearem 3DMM
Das resultierende stabile nichtlineare 3DMM kann zur Überlappung von 2D-Gesichtern und zur Lösung des Problems der dreidimensionalen Gesichtsrekonstruktion verwendet werden.
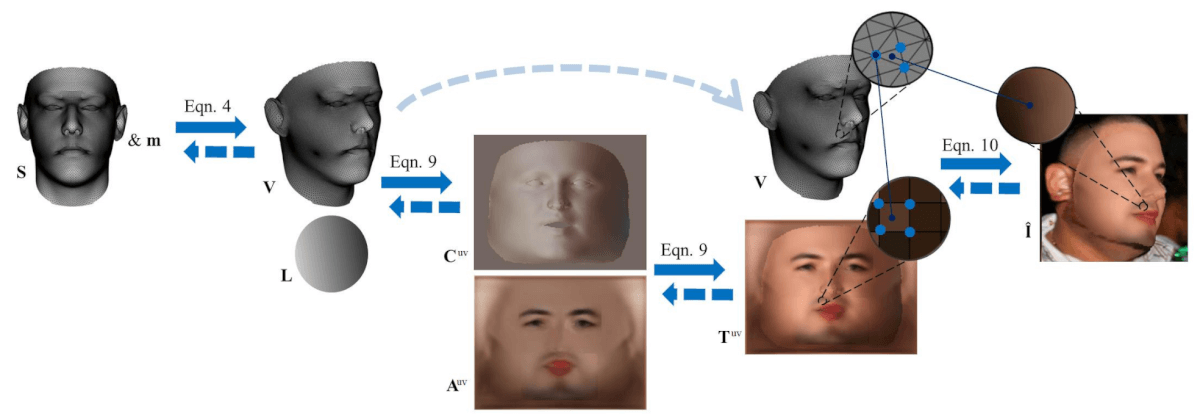
Layer-Layout rendern
Vergleich mit anderen Methoden
Die betrachtete Methode wurde anhand der folgenden Aufgaben als Beispiel mit anderen Methoden verglichen:
2D-Overlay, 3D-Gesichtsrekonstruktion und -bearbeitung . Das vorgeschlagene Verfahren ist anderen modernen Ansätzen zur Lösung dieser Probleme überlegen. Die Vergleichsergebnisse sind unten dargestellt.
2D-Gesichtsüberlagerung
Eine der Anwendungen der Methode ist die Gesichtsüberlagerung, die die Analyse von Gesichtern bei einer Reihe von Aufgaben (z. B. Gesichtserkennung) erheblich verbessern sollte. Das Auferlegen von Gesichtern ist keine leichte Aufgabe, aber die betrachtete Methode zeigt bei der Lösung hohe Ergebnisse.

2D-Overlay-Ergebnisse. Unsichtbare Markierungen sind rot markiert. Die betrachtete Methode spiegelt ungewöhnliche Körperhaltungen, Beleuchtung und Gesichtsausdrücke wider.
3D-Gesichtsrekonstruktion
Die betrachtete Methode wurde auch mit 3D-Gesichtsrekonstruktion verglichen und zeigte im Vergleich zu anderen Methoden hervorragende Ergebnisse.

Quantitativer Vergleich der 3D-Rekonstruktionsergebnisse

Die Ergebnisse der 3D-Rekonstruktion im Vergleich zur Methode von Sela et al. Die vorgeschlagene Methode spart Gesichtshaare und andere Gesichtsmerkmale viel besser als diese Methode.

Die Ergebnisse der 3D-Rekonstruktion im Vergleich zu VRN von Jackson und anderen am Beispiel des berühmten CelebA-Datensatzes.

Die Ergebnisse der 3D-Rekonstruktion im Vergleich zur Methode von Tewari und anderen. Wie Sie sehen können, löst die vorgeschlagene Methode das Problem der Komprimierung des Gesichts bei Vorhandensein verschiedener Texturen (z. B. Gesichtsbehaarung).
Gesichtsbearbeitung
Die beschriebene Methode unterteilt das Bild des Gesichts in separate Elemente und ermöglicht es Ihnen, das Gesicht durch Bearbeiten zu ändern. Die Ergebnisse dieser Methode beim Bearbeiten von Gesichtern wurden am Beispiel von Aufgaben wie dem Ändern der Beleuchtung und dem Hinzufügen zusätzlicher Gesichtselemente bewertet.

Die Ergebnisse des Hinzufügens eines Bartes. Die erste Spalte enthält das Originalbild, die nächste - verschiedene Grad der Veränderung des Bartes.

Vergleich mit der Methode von Shu et al. (Zweite Zeile). Wie Sie sehen können, liefert die vorgeschlagene Methode realistischere Bilder, und außerdem bleibt die Identität des Gesichts besser erhalten.
Fazit
Die vorgeschlagene Methode wird vermutlich weit verbreitet sein, da Sie damit genaue und stabile 3DMM erhalten. Obwohl 3DMM von Anfang an weit verbreitet war, gab es bis zum Aufkommen der fraglichen Methode keine effektive Möglichkeit, dieses Modell unter Verwendung von 2D-Bildern aus einem beliebigen Winkel zu erhalten.
Das vorgeschlagene Verfahren verwendet tiefe neuronale Netze als Approximator für die nachhaltige Modellierung menschlicher Gesichter mit all ihren Merkmalen. Eine solch ungewöhnliche Art, 3DMM zu erhalten, ermöglicht es Ihnen, das Bild zu manipulieren und kann für viele Aufgaben verwendet werden, von denen einige dem Artikel vorgestellt wurden.
Übersetzung - Boris Rumyantsev.