
Die Skalierung eines DBMS ist eine sich ständig weiterentwickelnde Zukunft. DBMS verbessern und skalieren besser auf Hardwareplattformen, während die Hardwareplattformen selbst die Produktivität, die Anzahl der Kerne und den Speicher erhöhen - Achilles holt die Schildkröte ein, hat es aber immer noch nicht. Das Problem der Skalierung von DBMS ist in vollem Gange.
Postgres Professional hatte nicht nur theoretisch, sondern auch praktisch ein Problem mit der Skalierung: bei seinen Kunden. Und mehr als einmal. Einer dieser Fälle wird in diesem Artikel behandelt.
PostgreSQL lässt sich auf NUMA-Systemen gut skalieren, wenn es sich um ein einzelnes Motherboard mit mehreren Prozessoren und mehreren Datenbussen handelt. Einige Optimierungen können
hier und
hier gelesen
werden . Es gibt jedoch eine andere Klasse von Systemen, sie haben mehrere Motherboards, deren Datenaustausch über Interconnect erfolgt, während eine Instanz des Betriebssystems daran arbeitet, und für den Benutzer sieht dieses Design wie eine einzelne Maschine aus. Und obwohl solche Systeme formal auch NUMA zugeordnet werden können, sind sie im Wesentlichen näher an Supercomputern als Der Zugriff auf den lokalen Speicher des Knotens und der Zugriff auf den Speicher des benachbarten Knotens unterscheiden sich radikal. Die PostgreSQL-Community ist der Ansicht, dass die einzige Postgres-Instanz, die auf solchen Architekturen ausgeführt wird, eine Problemquelle darstellt, und es gibt noch keinen systematischen Lösungsansatz.
Dies liegt daran, dass die Softwarearchitektur, die Shared Memory verwendet, grundsätzlich darauf ausgelegt ist, dass die Zugriffszeit verschiedener Prozesse auf ihren eigenen und Remote-Speicher mehr oder weniger vergleichbar ist. Wenn wir mit vielen Knoten arbeiten, rechtfertigt sich die Wette auf gemeinsam genutzten Speicher als schnellen Kommunikationskanal nicht mehr, da es aufgrund der Latenz viel „billiger“ ist, eine Anforderung zum Ausführen einer bestimmten Aktion an den Knoten (Knoten) zu senden, an dem interessante Daten als diese Daten auf dem Bus senden. Daher sind für Supercomputer und im Allgemeinen Systeme mit vielen Knoten Clusterlösungen relevant.
Dies bedeutet nicht, dass die Kombination von Mehrknotensystemen und einer typischen Postgres-Shared-Memory-Architektur beendet werden muss. Wenn Postgres-Prozesse den größten Teil ihrer Zeit mit komplexen Berechnungen vor Ort verbringen, ist diese Architektur sogar sehr effizient. In unserer Situation hatte der Client bereits einen leistungsstarken Multi-Node-Server gekauft, und wir mussten die Probleme von PostgreSQL darauf lösen.
Die Probleme waren jedoch schwerwiegend: Die einfachsten Schreibanforderungen (Ändern mehrerer Feldwerte in einem Datensatz) wurden in einem Zeitraum von mehreren Minuten bis zu einer Stunde ausgeführt. Wie später bestätigt wurde, zeigten sich diese Probleme gerade aufgrund der großen Anzahl von Kernen und dementsprechend der radikalen Parallelität bei der Ausführung von Anforderungen mit einem relativ langsamen Austausch zwischen Knoten in ihrer ganzen Pracht.
Daher wird sich der Artikel sozusagen für zwei Zwecke herausstellen:
- Erfahrungsaustausch: Was tun, wenn in einem System mit mehreren Knoten die Datenbank ernsthaft verlangsamt wird? Wo soll ich anfangen, wie kann ich diagnostizieren, wohin ich mich bewegen soll?
- Beschreiben Sie, wie die Probleme des PostgreSQL-DBMS selbst mit einem hohen Grad an Parallelität gelöst werden können. Einschließlich der Auswirkungen der Änderung des Algorithmus zum Aufheben von Sperren auf die Leistung von PostgreSQL.
Server und DB
Das System bestand aus 8 Klingen mit jeweils 2 Sockeln. Insgesamt mehr als 300 Kerne (ohne Hypertreading). Ein schneller Reifen (proprietäre Herstellertechnologie) verbindet die Klingen. Nicht, dass es sich um einen Supercomputer handelt, aber für eine Instanz des DBMS ist die Konfiguration beeindruckend.
Die Last ist auch ziemlich groß. Mehr als 1 Terabyte Daten. Über 3000 Transaktionen pro Sekunde. Über 1000 Verbindungen zu Postgres.
Nachdem wir begonnen hatten, uns mit den stündlichen Aufnahmeerwartungen zu befassen, war das erste, was wir taten, als Ursache für Verzögerungen auf die CD zu schreiben. Sobald unverständliche Verzögerungen einsetzten, wurden Tests ausschließlich mit
tmpfs . Das Bild hat sich nicht verändert. Die Festplatte hat nichts damit zu tun.
Erste Schritte mit Diagnosen: Ansichten
Da die Probleme höchstwahrscheinlich auf die starke Konkurrenz von Prozessen zurückzuführen sind, die auf dieselben Objekte „klopfen“, müssen zunächst die Sperren überprüft werden. In PostgreSQL gibt es für eine solche Prüfung die Ansichten
pg.catalog.pg_locks und
pg_stat_activity . Die zweite, bereits in Version 9.6, fügte Informationen darüber hinzu, worauf der Prozess wartet (
Amit Kapila, Ildus Kurbangaliev ) -
wait_event_type . Mögliche Werte für dieses Feld werden
hier beschrieben.
Aber zuerst zählen:
postgres=
Das sind reelle Zahlen. Erreichte bis zu 200.000 Sperren.
Gleichzeitig hingen solche Schlösser an der unglücklichen Bitte:
SELECT COUNT(mode), mode FROM pg_locks WHERE pid =580707 GROUP BY mode; count | mode —
Beim Lesen des Puffers verwendet das DBMS beim Schreiben die
share -
exclusive . Das heißt, Schreibsperren machten weniger als 1% aller Anforderungen aus.
In der Ansicht
pg_locks sehen
pg_locks nicht immer so aus, wie
in der Benutzerdokumentation beschrieben.
Hier ist die Streichholzplatte:
AccessShareLock = LockTupleKeyShare RowShareLock = LockTupleShare ExclusiveLock = LockTupleNoKeyExclusive AccessExclusiveLock = LockTupleExclusive
Die Abfrage SELECT mode FROM pg_locks zeigte, dass CREATE INDEX (ohne CONCURRENTLY) auf 234 INSERTs und 390 INSERTs auf die
buffer content lock Pufferinhalts warten würde. Eine mögliche Lösung besteht darin, INSERTs aus verschiedenen Sitzungen so zu „lehren“, dass sie sich in Puffern weniger überschneiden.
Es ist Zeit, perf zu verwenden
Das Dienstprogramm
perf sammelt viele Diagnoseinformationen. Im
record ... werden Statistiken von Systemereignissen in Dateien geschrieben (standardmäßig befinden sie sich in
./perf_data ), und im
report werden die gesammelten Daten analysiert. Sie können beispielsweise Ereignisse filtern, die nur
postgres oder eine bestimmte
postgres betreffen:
$ perf record -u postgres $ perf record -p 76876 , $ perf report > ./my_results
Als Ergebnis werden wir so etwas sehen
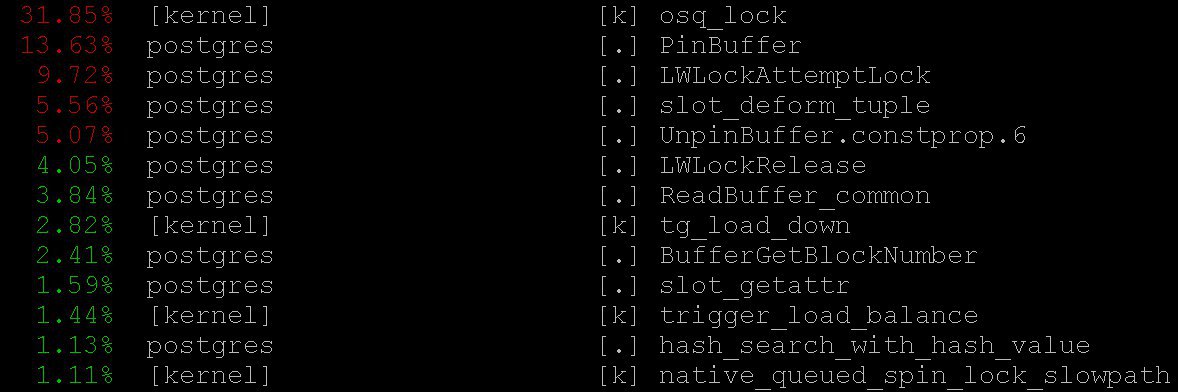
Die Verwendung von
perf zur Diagnose von PostgreSQL wird beispielsweise
hier sowie im
pg-Wiki beschrieben .
In unserem Fall gab selbst der einfachste Modus
perf top wichtige Informationen -
perf top , was natürlich im Geiste des
top Betriebssystems funktioniert. Bei
perf top wir
perf top dass der Prozessor die meiste Zeit in den
PinBuffer() sowie in den Funktionen
PinBuffer() und
LWLockAttemptLock(). .
PinBuffer() ist eine Funktion, die den Zähler für Verweise auf den Puffer erhöht (Zuordnung einer Datenseite zum RAM), dank derer Postgres-Prozesse wissen, welche Puffer herausgedrückt werden können und welche nicht.
LWLockAttemptLock() - Die
LWLock .
LWLock ist eine Art Sperre mit zwei Ebenen von
shared und
exclusive , ohne
deadlock zu definieren. Sperren werden dem
shared memory vorab zugewiesen, wartende Prozesse warten in einer Warteschlange.
Diese Funktionen wurden bereits in PostgreSQL 9.5 und 9.6 ernsthaft optimiert. Die darin enthaltenen Spinlocks wurden durch den direkten Einsatz atomarer Operationen ersetzt.
Flammengraphen
Ohne sie ist es unmöglich: Selbst wenn sie nutzlos wären, wäre es immer noch wert, über sie zu erzählen - sie sind ungewöhnlich schön. Aber sie sind nützlich. Hier ist eine Illustration von
github , nicht von unserem Fall (weder wir noch der Kunde sind noch bereit, Details
github ).

Diese schönen Bilder zeigen sehr deutlich, was die Prozessorzyklen dauern.
perf kann Daten erfassen, aber das
flame graph visualisiert die Daten auf intelligente Weise und erstellt Bäume basierend auf den gesammelten Anrufstapeln. Sie können hier beispielsweise mehr über die Profilerstellung mit Flammengraphen lesen und
hier alles herunterladen, was Sie benötigen.
In unserem Fall war auf den Flammengraphen eine große Menge
nestloop sichtbar. Anscheinend verursachten die JOINs einer großen Anzahl von Tabellen in zahlreichen gleichzeitigen Leseanforderungen eine große Anzahl von
access share .
Die von
perf gesammelten Statistiken zeigen, wohin die Prozessorzyklen gehen. Und obwohl wir gesehen haben, dass die meiste Prozessorzeit für Sperren vergeht, haben wir nicht gesehen, was genau zu so langen Erwartungen an Sperren führt, da wir nicht genau sehen, wo Sperrenerwartungen auftreten, weil CPU-Zeit wird nicht mit Warten verschwendet.
Um die Erwartungen selbst zu sehen, können Sie eine Anforderung an die Systemansicht
pg_stat_activity .
SELECT wait_event_type, wait_event, COUNT(*) FROM pg_stat_activity GROUP BY wait_event_type, wait_event;
enthüllte, dass:
LWLockTranche | buffer_content | UPDATE ************* LWLockTranche | buffer_content | INSERT INTO ******** LWLockTranche | buffer_content | \r | | insert into B4_MUTEX | | values (nextval('hib | | returning ID Lock | relation | INSERT INTO B4_***** LWLockTranche | buffer_content | UPDATE ************* Lock | relation | INSERT INTO ******** LWLockTranche | buffer_mapping | INSERT INTO ******** LWLockTranche | buffer_content | \r
(Die Sternchen hier ersetzen einfach Anforderungsdetails, die wir nicht offenlegen.)
Sie können die Werte
buffer_content (Blockieren des Inhalts von Puffern) und
buffer_mapping (Blockieren der Komponenten der Hash-Platte
shared_buffers )
shared_buffers .
Für Hilfe zu gdb
Aber warum gibt es so viele Erwartungen an diese Art von Schlössern? Für detailliertere Informationen zu den Erwartungen musste ich den
GDB Debugger verwenden. Mit
GDB wir einen Aufrufstapel spezifischer Prozesse erhalten. Durch Anwenden von Abtastung, d.h. Nachdem Sie eine bestimmte Anzahl von zufälligen Anrufstapeln gesammelt haben, können Sie sich ein Bild davon machen, welche Stapel die längsten Erwartungen haben.
Betrachten Sie den Prozess der Erstellung von Statistiken. Wir werden die "manuelle" Sammlung von Statistiken betrachten, obwohl im wirklichen Leben spezielle Skripte verwendet werden, die dies automatisch tun.
Zunächst muss
gdb an den PostgreSQL-Prozess angehängt werden. Suchen Sie dazu die
pid Serverprozesses, z. B. von
$ ps aux | grep postgres
Nehmen wir an, wir haben gefunden:
postgres 2025 0.0 0.1 172428 1240 pts/17 S 23 0:00 /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/data
und fügen Sie nun die
pid in den Debugger ein:
igor_le:~$gdb -p 2025
Sobald wir uns im Debugger befinden, schreiben wir
bt [
bt backtrace ] oder
where . Und wir bekommen viele Informationen über diesen Typ:
(gdb) bt #0 0x00007fbb65d01cd0 in __write_nocancel () from /lib64/libc.so.6 #1 0x00000000007c92f4 in write_pipe_chunks ( data=0x110e6e8 "2018‐06‐01 15:35:38 MSK [524647]: [392‐1] db=bp,user=bp,app=[unknown],client=192.168.70.163 (http://192.168.70.163) LOG: relation 23554 new block 493: 248.389503\n2018‐06‐01 15:35:38 MSK [524647]: [393‐1] db=bp,user=bp,app=["..., len=409, dest=dest@entry=1) at elog.c:3123 #2 0x00000000007cc07b in send_message_to_server_log (edata=0xc6ee60 <errordata>) at elog.c:3024 #3 EmitErrorReport () at elog.c:1479
Nachdem wir Statistiken gesammelt hatten, einschließlich Aufrufstapel aus allen Postgres-Prozessen, die wiederholt zu verschiedenen Zeitpunkten gesammelt wurden, stellten wir fest, dass die
buffer partition lock der
buffer partition lock innerhalb der
buffer partition lock der
relation extension lock 3706 Sekunden (ungefähr eine Stunde) dauerte, dh ein Teil der Hash-Tabelle des Puffers
relation extension lock Manager, der erforderlich war, um den alten Puffer zu ersetzen, um ihn anschließend durch einen neuen zu ersetzen, der dem erweiterten Teil der Tabelle entspricht. Es war auch eine bestimmte Anzahl von Sperren für Pufferinhalte erkennbar, die der Erwartung entsprachen, die Seiten des
B-tree Index zum Einfügen zu sperren.

Zunächst kamen zwei Erklärungen für eine solch ungeheure Wartezeit:
- Jemand anderes nahm dieses
LWLock und steckte fest. Dies ist jedoch unwahrscheinlich. Weil innerhalb der Pufferpartitionssperre nichts Kompliziertes passiert. - Wir haben ein pathologisches Verhalten von
LWLock . Das heißt, trotz der Tatsache, dass niemand das Schloss zu lange nahm, hielt seine Erwartung unangemessen lange an.
Diagnosepflaster und Baumbehandlung
Durch die Reduzierung der Anzahl gleichzeitiger Verbindungen würden wir wahrscheinlich den Strom von Anforderungen an Sperren entladen. Aber das wäre wie Kapitulation. Stattdessen schlug
Alexander Korotkov , der Chefarchitekt von Postgres Professional (natürlich half er bei der Vorbereitung dieses Artikels), eine Reihe von Patches vor.
Zunächst war es notwendig, sich ein detaillierteres Bild von der Katastrophe zu machen. Unabhängig davon, wie gut die fertigen Werkzeuge sind, sind auch Diagnose-Patches aus eigener Herstellung hilfreich.
Es wurde ein Patch geschrieben, der eine detaillierte Protokollierung der in der
RelationAddExtraBlocks() -Funktion verbrachten Zeit in
RelationAddExtraBlocks(). hinzufügt. Wir finden also heraus, wie viel Zeit in
RelationAddExtraBlocks().Und zur Unterstützung von ihm wurde in
pg_stat_activity weiterer Patch geschrieben, der darüber berichtet, was wir jetzt in
relation extension auf die
relation extension tun. Dies wurde folgendermaßen durchgeführt: Wenn die
relation erweitert wird, wird
application_name zu
RelationAddExtraBlocks . Dieser Prozess wird jetzt bequem mit maximalen Details unter Verwendung von
gdb bt und
perf analysiert.
Tatsächlich wurden zwei medizinische (und nicht diagnostische) Patches geschrieben. Der erste Patch hat das Verhalten von
B‐tree Blattsperren geändert: Früher wurde das Blatt bei der Aufforderung zum Einfügen als
share blockiert und danach
exclusive . Jetzt wird er sofort
exclusive . Jetzt wurde dieser Patch
bereits für
PostgreSQL 12 festgeschrieben . Glücklicherweise erhielt
Alexander Korotkov in diesem Jahr den
Status eines Committers - des zweiten PostgreSQL-Committers in Russland und des zweiten im Unternehmen.
Der Wert für
NUM_BUFFER_PARTITIONS wurde ebenfalls von 128 auf 512 erhöht, um die Belastung der Zuordnungssperren zu verringern: Die Puffermanager-Hash-Tabelle wurde in kleinere Teile unterteilt, in der Hoffnung, dass die Belastung für jedes bestimmte Teil verringert wird.
Nach dem Anwenden dieses Patches waren die Sperren für den Inhalt der Puffer weg, aber trotz der Zunahme von
buffer_mapping blieb
NUM_BUFFER_PARTITIONS ,
buffer_mapping wir erinnern Sie daran, Teile der Puffermanager-Hash-Tabelle zu blockieren:
locks_count | active_session | buffer_content | buffer_mapping ----‐‐‐--‐‐‐+‐------‐‐‐‐‐‐‐‐‐+‐‐‐------‐‐‐‐‐‐‐+‐‐------‐‐‐ 12549 | 1218 | 0 | 15
Und selbst das ist nicht viel. B - Baum ist kein Engpass mehr. Die
heap- Erweiterung trat in den Vordergrund.
Behandlung des Gewissens
Als nächstes stellte Alexander die folgende Hypothese und Lösung vor:
Wir warten viel Zeit auf die
buffer parittion lock wenn wir den
buffer parittion lock . Vielleicht gibt es auf derselben
buffer parittion lock eine sehr gefragte Seite, zum Beispiel die Wurzel eines
B‐tree . Zu diesem Zeitpunkt gibt es einen kontinuierlichen Fluss von Anforderungen für die
shared lock von Leseanforderungen.
Die Warteschlange bei
LWLock "nicht fair". Da
shared lock so viele wie nötig gleichzeitig verwendet werden können, werden nachfolgende
shared lock ohne Warteschlange übergeben, wenn die
shared lock bereits aktiviert ist. Wenn der Strom gemeinsam genutzter Sperren so intensiv ist, dass sich keine „Fenster“ zwischen ihnen befinden, ist das Warten auf eine
exclusive lock fast unendlich.
Um dies zu beheben, können Sie versuchen, einen Patch für "Gentleman" -Verhalten von Schlössern anzubieten. Es weckt das Gewissen
shared locker und sie stehen ehrlich in der Warteschlange, wenn es bereits ein
exclusive lock (interessanterweise haben schwere Schlösser -
hwlock - keine Probleme mit dem Gewissen: Sie stehen immer ehrlich in der Warteschlange)
locks_count | active_session | buffer_content | buffer_mapping | reladdextra | inserts>30sec ‐‐‐‐‐‐-‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐--‐-‐+‐‐‐‐‐‐-‐‐‐‐‐‐+‐‐‐‐------ 173985 | 1802 | 0 | 569 | 0 | 0
Alles ist gut! Es gibt keine langen
insert . Obwohl die Schlösser an den Stücken der Hash-Platten erhalten blieben. Aber was zu tun ist, das sind die Eigenschaften der Reifen unseres kleinen Supercomputers.
Dieser Patch wurde auch
der Community angeboten . Unabhängig davon, wie sich das Schicksal dieser Patches in der Community entwickelt, hindert nichts sie daran, in die nächsten Versionen von
Postgres Pro Enterprise zu gelangen , die speziell für Kunden mit stark ausgelasteten Systemen entwickelt wurden.
Moral
share leichte
share Locks -
exclusive Blöcke, die die Warteschlange überspringen - haben das Problem der stündlichen Verzögerungen in einem System mit mehreren Knoten gelöst. Das Hash-Tag des
buffer manager funktionierte nicht, da zu viel Fluss von
share lock die Sperren keine Chance hatten, alte Puffer zu ersetzen und neue zu laden. Probleme mit der Erweiterung des Puffers für die Datenbanktabellen waren nur eine Folge davon. Zuvor war es möglich, den Engpass mit Zugriff auf die
B-tree Wurzel zu erweitern.
PostgreSQL wurde nicht für NUMA-Architekturen und Supercomputer entwickelt. Die Anpassung an solche Postgres-Architekturen ist eine große Aufgabe, die die koordinierten Anstrengungen vieler Menschen und sogar Unternehmen erfordern würde (und möglicherweise erfordern würde). Die unangenehmen Folgen dieser architektonischen Probleme können jedoch gemildert werden. Und wir müssen: Die Lasttypen, die zu ähnlichen Verzögerungen wie den beschriebenen führten, sind recht typisch, ähnliche Notsignale von anderen Orten kommen weiterhin zu uns. Ähnliche Probleme traten früher auf - bei Systemen mit weniger Kernen waren nur die Folgen nicht so ungeheuerlich, und die Symptome wurden mit anderen Methoden und anderen Patches behandelt. Jetzt ist eine andere Medizin erschienen - nicht universell, aber eindeutig nützlich.
Wenn PostgreSQL also mit dem Speicher des gesamten Systems als lokal arbeitet, kann kein Hochgeschwindigkeitsbus zwischen Knoten mit der Zugriffszeit auf den lokalen Speicher verglichen werden. Aufgaben entstehen aufgrund dieser schwierigen, oft dringenden, aber interessanten. Und die Erfahrung, sie zu lösen, ist nicht nur für die Entscheidenden, sondern auch für die gesamte Gemeinschaft nützlich.
