
Jede der Technologien, die von dem Moment an entwickelt wurden, in dem eine Person einen Stein aufgehoben hat, muss das Leben einer Person verbessern und ihre Hauptfunktionen erfüllen. Jede Technologie kann jedoch „Nebenwirkungen“ haben, dh einen Menschen und die Welt um ihn herum auf eine Weise beeinflussen, an die zum Zeitpunkt der Erstellung dieser Technologie niemand gedacht hat oder denken wollte. Ein anschauliches Beispiel: Es wurden Maschinen geschaffen, und eine Person konnte lange Strecken schneller als zuvor zurücklegen. Gleichzeitig begann die Verschmutzung.
Heute werden wir über die "Nebenwirkung" des Internets sprechen, die nicht die Erdatmosphäre betrifft, sondern den Geist und die Seele der Menschen selbst. Tatsache ist, dass das World Wide Web ein hervorragendes Instrument für die Verbreitung und den Austausch von Informationen, für die Kommunikation zwischen physisch voneinander entfernten Menschen und für vieles mehr geworden ist. Das Internet hilft in verschiedenen Bereichen der Gesellschaft, von der Medizin bis zur banalen Vorbereitung auf den Test der Geschichte. Der Ort, an dem sich leider sehr viele, manchmal namenlose Stimmen und Meinungen versammeln, ist leider mit dem gefüllt, was dem Menschenhass so innewohnt.
In der heutigen Studie zerlegen Wissenschaftler mehrere Algorithmen, deren Hauptaufgabe darin besteht, beleidigende, unhöfliche und feindliche Botschaften zu identifizieren. Es gelang ihnen, alle diese Algorithmen zu brechen, wodurch ihre geringe Effizienz demonstriert und auf die Fehler hingewiesen wurde, die behoben werden sollten. Wie Wissenschaftler gebrochen haben, was angeblich funktioniert hat, warum sie es getan haben und welche Schlussfolgerungen wir alle ziehen müssen - wir werden im Bericht der Forscher nach Antworten auf diese und andere Fragen suchen. Lass uns gehen.
Hintergrund der StudieSoziale Netzwerke und andere Formen der Internetinteraktion zwischen Menschen sind zu einem integralen Bestandteil unseres Lebens geworden. Leider verstehen viele Benutzer solcher Dienste zu wörtlich so etwas wie „Meinungs-, Gedanken- und Meinungsfreiheit“ und decken dies mit ihrem Recht auf unanständiges, vertrautes und unhöfliches Verhalten im Netzwerk ab. Jeder von uns war auf die eine oder andere Weise mit der „Aktivität“ solcher Individuen konfrontiert. Viele wurden sogar Gegenstand solcher Reden. Natürlich kann nicht geleugnet werden, dass eine Person das Recht hat, zu sagen, was sie denkt. Ihre Gedanken auszudrücken ist jedoch eine Sache, und jemanden zu beleidigen ist eine andere. Neben der Redefreiheit wird auch die Anonymität ausgenutzt, da Sie jedem etwas sagen können, während Sie inkognito bleiben. Infolgedessen werden Sie nicht für Ihr unangemessenes Verhalten bestraft.
Es ist nicht wert zu erklären, dass die Sätze "Ich mochte es nicht" und "Dies ist ein kompletter Fick **, Autor tötet gegen die Wand" (dies ist eine noch mehr oder weniger anständige Option) völlig unterschiedliche emotionale Farben haben, obwohl sie eine gemeinsame Essenz haben - für den Kommentator Mir gefällt nicht, was er gesehen / gelesen / gehört hat usw. Aber wenn Sie einer Person verbieten, ihre Unzufriedenheit auf diese Weise auszudrücken, wird dies als Verletzung ihrer Rechte angesehen? Viele werden ja sagen. Auf der anderen Seite lohnt es sich, den wachsenden exponentiellen Hass im Internet, der in den meisten Fällen nicht gerechtfertigt ist, weiterhin zu ignorieren. Hass als solcher hat einen Platz zu sein. Dies ist natürlich eine sehr starke und unglaublich negative Emotion. Wenn eine Person jedoch denjenigen hasst, der etwas Schreckliches getan hat (Mord, Vergewaltigung und andere unmenschliche Handlungen), kann dies immer noch irgendwie gerechtfertigt sein. Aber wenn sich Hass in der Ansprache einer völlig fremden Person manifestiert, die nichts Unmoralisches oder Unmenschliches begangen hat, ist dies eine ganz andere Geschichte.
Jetzt haben viele Unternehmen und Forschungsgruppen beschlossen, eigene Algorithmen zu erstellen, mit denen jeder Text analysiert und festgestellt werden kann, wo
die Feindseligkeitssprache * vorhanden ist und in welchem Umfang sie ausgedrückt wird. Unsere heutigen Helden haben beschlossen, diese Algorithmen zu testen, insbesondere die sehr beworbene Google Perspective API, die den „Säuregehalt“ der Phrase bestimmt, d. H. Wie sehr kann dieser Satz als Beleidigung angesehen werden.
Hassrede * - wie aus dem Namen dieses Begriffs hervorgeht, handelt es sich um eine Kombination von Sprachmitteln, die darauf abzielen, eine lebhafte Feindseligkeit zwischen den Gesprächspartnern auszudrücken. Die häufigsten Formen der Hassrede sind: Rassismus, Sexismus, Fremdenfeindlichkeit, Homophobie und andere Formen der Feindseligkeit gegenüber etwas anderem.
Die Hauptaufgaben, die sich die Forscher selbst gestellt haben, sind die Untersuchung der beliebtesten Algorithmen zur Identifizierung von Hassreden, das Verständnis ihrer Arbeitsmethoden und der Versuch, sie zu umgehen.
ForschungsalgorithmenWissenschaftler haben mehrere Algorithmen ausgewählt, deren Datenbanken sich voneinander unterscheiden, wodurch wir auch die beste Datenbank ermitteln können. Einige Algorithmen beruhen eher auf der Identifizierung sexueller
Konnotationen * , andere auf religiösen. Allen Algorithmen gemeinsam ist die Quelle ihres Wissens - Twitter. Laut den Forschern ist dies alles andere als perfekt, da dieser Dienst bestimmte Einschränkungen aufweist (z. B. die Anzahl der Zeichen in einer Nachricht). Daher sollte die Basis eines effektiven Algorithmus aus verschiedenen sozialen Netzwerken und Diensten gefüllt werden.
Konnotation * - eine Methode zum Färben eines Wortes oder einer Phrase mit zusätzlichen semantischen oder emotionalen Schattierungen. Kann je nach sprachlicher, kultureller oder anderer Form der sozialen Trennung variieren. Beispiel: windig - „der Tag war windig“ (die direkte Bedeutung des Wortes), „er war immer ein windiger Mensch“ (in diesem Fall bedeutet dies Unbeständigkeit und Frivolität).
Liste der Algorithmen und ihrer Funktionalität:
Detox : Wikipedia-Projekt zur Identifizierung unangemessener Sprache in redaktionellen Kommentaren. Es basiert auf der
logistischen Regression * und einem
mehrschichtigen Perzeptron * unter Verwendung von
N-Gramm * -Modellen auf der Ebene von Buchstaben und Wörtern. Die Größe der N-Gramm eines Wortes variiert zwischen 1 und 3 und die Buchstaben zwischen 1 und 5.
Die logistische Regression * ist ein Modell zur Vorhersage der Wahrscheinlichkeit eines Ereignisses durch Anpassen von Daten an eine logistische Kurve.
Ein mehrschichtiges Perzeptron * ist ein Modell der Informationswahrnehmung, das aus drei Hauptschichten besteht: S - Sensoren (Empfang eines Signals), A - assoziative Elemente (Verarbeitung) und R-reagierende Elemente (Reaktion auf ein Signal) sowie eine zusätzliche Schicht A.
N-Gramm * ist eine Folge von n Elementen.
Daten für die Algorithmusbasis wurden von Dritten gesammelt, und jeder der Kommentare wurde von zehn Bewertern bewertet.
T1 : Ein Algorithmus mit einer Basis, die in drei Arten von Kommentaren von Twitter unterteilt ist (Hassrede, Beleidigungen ohne Hassrede und neutral). Forscher sagen, dass dies die einzige Basis mit einer ähnlichen Kategorisierung ist. Hassreden wurden entdeckt, indem auf Twitter nach bestimmten Mustern gesucht wurde. Darüber hinaus wurden die gefundenen Ergebnisse von drei CrowdFlower-Mitarbeitern ausgewertet (jetzt Figure Eight Inc., eine Studie über maschinelles Lernen und künstliche Intelligenz). Der größte Teil der Basis (76%) besteht aus beleidigenden Phrasen, während die feindliche Sprache nur 5% ausmacht.
T2 : Ein Algorithmus, der tiefe neuronale Netze verwendet. Der Schwerpunkt lag auf dem Langzeit-Kurzzeitgedächtnis (LSTM). Die Basis dieses Algorithmus ist in drei Kategorien unterteilt: Rassismus, Sexismus und nichts. Die Forscher kombinierten die ersten beiden Kategorien zu einer und bildeten eine integrale Kategorie feindlicher Sprache. Die Basis der Basis waren 16.000 Tweets.
T1 * ,
T3 : Ein Algorithmus, der auf dem Faltungsnetzwerk (CNN) und kontrollierten Wiederholungseinheiten (GRU) basiert und die T1-Wissensbasis verwendet und diese durch separate Kategorien für Flüchtlinge und Muslime (T3) ergänzt.
AlgorithmusleistungDie Leistung der Algorithmen wurde mit zwei Methoden getestet. Im ersten Fall arbeiteten sie wie ursprünglich beabsichtigt. Und im zweiten Fall wurden die Algorithmen durch die Datenbanken jedes einzelnen von ihnen trainiert, eine Art Erfahrungsaustausch.
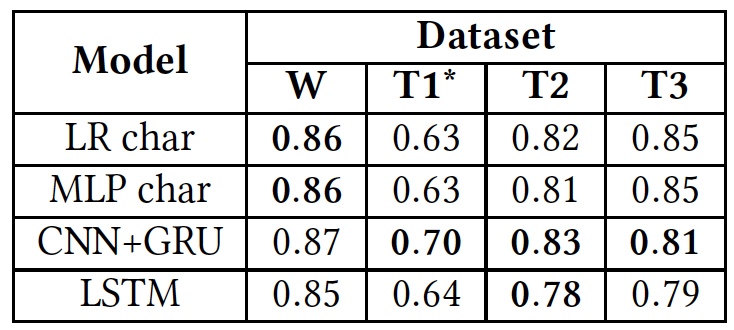 Testergebnisse (Ergebnisse der Verwendung von Originaldatenbanken sind fett gedruckt).
Testergebnisse (Ergebnisse der Verwendung von Originaldatenbanken sind fett gedruckt).Wie aus der obigen Tabelle ersichtlich ist, zeigten alle Algorithmen ungefähr die gleichen Ergebnisse, wenn sie auf verschiedene Texte (Datenbanken) angewendet wurden. Dies deutet darauf hin, dass alle mit demselben Texttyp studiert haben.
Die einzige signifikante Abweichung ist in T1 * zu sehen. Dies liegt an der Tatsache, dass die Datenbank dieses Algorithmus laut Wissenschaftlern extrem unausgeglichen ist. Hassreden nehmen, wie wir bereits wissen, nur 5% ein. Die anfängliche Unterteilung in drei Kategorien von Texten wurde in eine Unterteilung in zwei umgewandelt, als „Beleidigungen, aber ohne feindliche Sprache“ und „neutrale“ Texte zu einer Gruppe zusammengefasst wurden, die etwa 80% der gesamten Basis einnahm.
Darüber hinaus haben die Forscher die Algorithmen umgeschult. Zunächst wurden die ursprünglichen Basen verwendet. Danach musste jeder der Algorithmen mit der Basis eines anderen Algorithmus arbeiten, anstatt mit seinem eigenen.
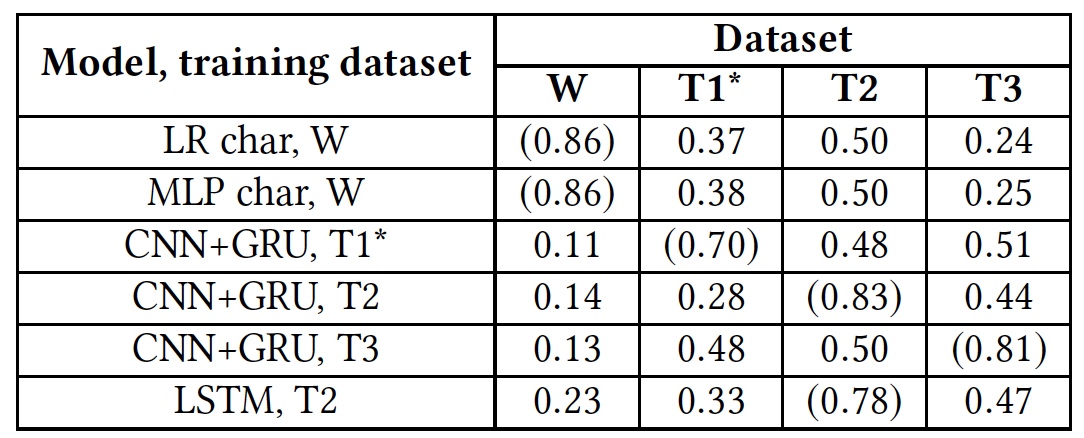 Umschulung der Testergebnisse (Ergebnisse unter Verwendung nativer Datenbanken sind in Klammern angegeben).
Umschulung der Testergebnisse (Ergebnisse unter Verwendung nativer Datenbanken sind in Klammern angegeben).Dieser Test zeigte, dass alle Algorithmen für die Arbeit mit fremden Datenbanken völlig unvorbereitet waren. Dies deutet darauf hin, dass sich sprachliche Indikatoren für Hassreden in verschiedenen Datenbanken nicht überschneiden. Dies kann daran liegen, dass in verschiedenen Datenbanken nur sehr wenige übereinstimmende Wörter vorhanden sind, oder an Ungenauigkeiten bei der Interpretation bestimmter Phrasen.
Beleidigungen und HassredenDie Forscher beschlossen, zwei Kategorien von Texten besondere Aufmerksamkeit zu widmen: beleidigend und feindselig. Unter dem Strich kombinieren einige Algorithmen sie zu einem Heap, während andere versuchen, sie als unabhängige Gruppen zu trennen. Beleidigungen sind natürlich eindeutig ein negatives Phänomen, und es kann sicher einer Kategorie mit Feindseligkeit zugeordnet werden. Das Definieren von Beleidigungen ist jedoch ein viel komplizierterer Prozess als das Erkennen von offensichtlichem Hass im Text.
Um die Algorithmen auf die Fähigkeit zu testen, Beleidigungen zu erkennen, wurde die T1-Basis verwendet. Der T1 * -Algorithmus nahm jedoch nicht an diesem Test teil, da er bereits auf solche Arbeiten vorbereitet ist, wodurch die Ergebnisse seiner Überprüfung verzerrt werden.
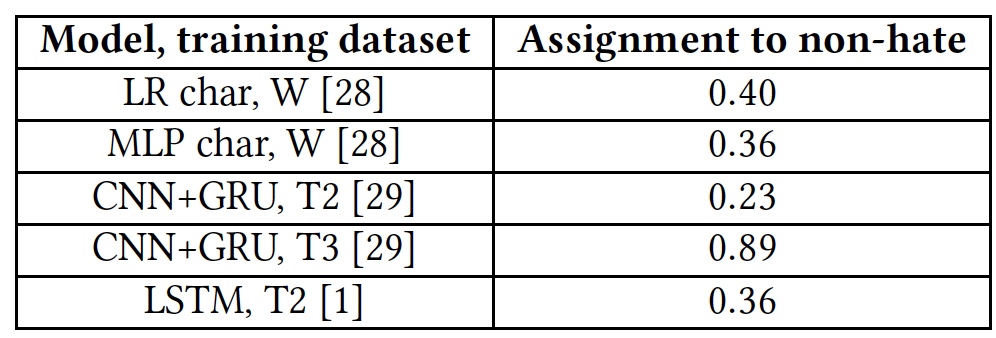 Testergebnisse für die Fähigkeit, anstößige Texte zu erkennen.
Testergebnisse für die Fähigkeit, anstößige Texte zu erkennen.Alle Algorithmen zeigten eher mittelmäßige Ergebnisse. Die Ausnahme war T3, aber nicht auf Kosten ihrer Talente. Tatsache ist, dass Wörter, die dem Algorithmus nicht vertraut sind, mit dem Tag
unk gekennzeichnet sind. Fast 40% der Wörter in jedem Satz wurden mit diesem Tag markiert, und der Algorithmus zählte sie automatisch als Beleidigungen. Und das war natürlich alles andere als immer richtig. Mit anderen Worten, der T3-Algorithmus hat die Aufgabe aufgrund seines kurzen Wortschatzes auch nicht bewältigt.
Als eines der Hauptprobleme von Algorithmen betrachten Wissenschaftler den menschlichen Faktor. Die meisten Datenbanken der einzelnen Algorithmen werden von Personen gesammelt, analysiert und ausgewertet. Und hier sind starke Ergebnisunterschiede möglich. Der gleiche Satz mag für manche Menschen beleidigend oder für andere neutral erscheinen.
Auch das Fehlen von Algorithmen zum Verstehen von nicht standardmäßigen Phrasen, die ruhig Schimpfwörter enthalten können, jedoch ohne Beleidigungen oder Feindseligkeitssprache, wirkt sich ebenfalls negativ aus.
Um dies zu demonstrieren, wurde ein Test mit mehreren Phrasen durchgeführt. Dann wurde der Test wiederholt, aber in jeder der Phrasen wurde das sehr obszöne Wort "
f * ck " hinzugefügt (markiert mit dem Buchstaben
F in der Tabelle).
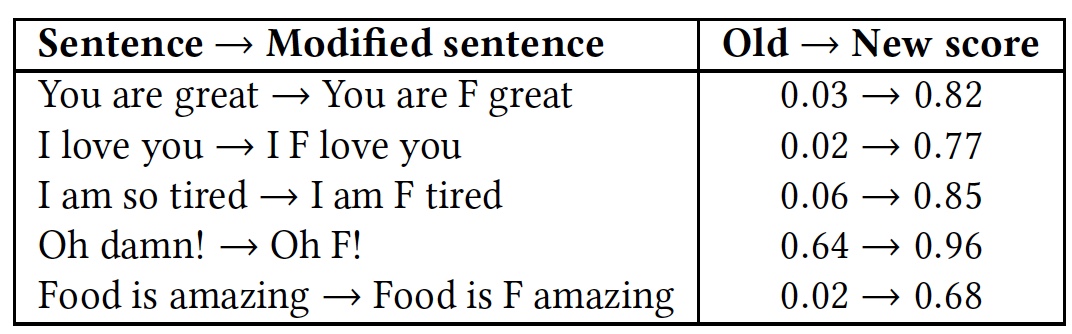 Vergleichende Erkennungsergebnisse von Phrasen mit und ohne das Wort „f * ck“.
Vergleichende Erkennungsergebnisse von Phrasen mit und ohne das Wort „f * ck“.Wie aus der Tabelle hervorgeht, hat es sich gelohnt, ein Wort mit dem Buchstaben F hinzuzufügen, da alle Algorithmen die Phrase sofort als Sprache der Feindseligkeit verstanden haben. Das Wesen der Phrasen blieb zwar gleich, freundlich, aber die emotionale Farbe änderte sich zu einer ausgeprägteren.
Die oben beschriebenen Google Perspective API-Tests zeigen ähnliche Ergebnisse. Dieser Algorithmus ist auch nicht in der Lage, feindliche Sprache von Beleidigungen und Beleidigungen von einem einfachen Beinamen zu unterscheiden, mit dem eine Phrase emotional verschönert wird.
Wie betrüge ich den Algorithmus?Wie so oft ist es nicht immer schlecht, wenn jemand etwas kaputt macht. Und das alles, denn wenn wir brechen, zeigen wir das Fehlen eines Systems, dessen Schwachstelle, das verbessert werden sollte, indem eine Wiederholung des Zusammenbruchs verhindert wird. Die oben genannten Modelle waren keine Ausnahme, und die Forscher beschlossen, zu prüfen, wie ihre Arbeit gestört werden könnte. Wie sich herausstellte, war es nicht so schwierig, wie die Entwickler dieser Algorithmen dachten.
Das Algorithmus-Bypass-Modell ist einfach: Der Cracker weiß, dass seine Texte überprüft werden, er kann die Eingabedaten (Text) so ändern, dass eine Erkennung vermieden wird. Der Cracker hat keinen Zugriff auf den Algorithmus selbst und seine Struktur. Einfach ausgedrückt, der Angreifer bricht den Algorithmus ausschließlich auf Benutzerebene.
Der Algorithmus-Bypass (nennen wir es das gute alte Wort "Hacking") ist in drei Typen unterteilt:
- Ändern des Wortes: absichtliche Tippfehler und Leet, dh Ersetzen einiger Buchstaben durch Zahlen (zum Beispiel: Sie sehen heute großartig aus! - Y0U 100K 6r347 70D4Y!);
- Ändern Sie den Abstand zwischen Wörtern: Fügen Sie Leerzeichen hinzu und entfernen Sie sie.
- Fügen Sie Wörter am Ende einer Phrase hinzu.
Das erste Hacking-Programm - das Ändern von Wörtern - sollte drei Aufgaben erfolgreich ausführen: Reduzieren Sie den Erkennungsgrad eines Wortes durch einen Algorithmus, vermeiden Sie Rechtschreibkorrekturen und behalten Sie die Lesbarkeit von Wörtern für eine Person bei.
Das Programm tauscht die beiden Buchstaben des Wortes aus. Bevorzugt werden Buchstaben, die näher an der Wortmitte und aneinander liegen. Nur der erste und der letzte Buchstabe des Wortes sind ausgeschlossen. Ferner werden die Wörter mit Blick auf Leet modifiziert, wobei einige Buchstaben durch Zahlen ersetzt werden: a - 4, e - 3, l - 1, o - 0, s - 5.
Um mit solchen Tricks fertig zu werden, wurden die Algorithmen durch die Einführung der Rechtschreibprüfung und der stochastischen Transformation der Trainingswissensbasis leicht verbessert. Das heißt, nicht nur die Hauptwörter waren in der Datenbank vorhanden, sondern sie wurden auch durch Neuanordnen der Buchstaben des Formulars geändert.
Je länger das Wort ist, desto mehr Optionen zum Neuanordnen von Buchstaben stehen zur Verfügung, wodurch die Funktionen des Cracker-Programms erweitert werden.
Die Methode zum Entfernen oder Hinzufügen von Leerzeichen hat auch ihre eigenen Eigenschaften. Das Entfernen von Leerzeichen eignet sich besser für entgegengesetzte Algorithmen, die ganze Wörter analysieren. Algorithmen, die jeden Buchstaben analysieren, können jedoch problemlos mit dem Fehlen von Leerzeichen umgehen.
Das Hinzufügen von Leerzeichen scheint eine sehr ineffiziente Methode zu sein, kann jedoch einige Algorithmen austricksen. Modelle, die die Wörter als Ganzes betrachten, führen eine lexikalische Analyse der Phrase durch und teilen sie in Komponenten (Token) auf. In diesem Fall dient der Raum als Worttrennzeichen, dh als wichtiges Element der Phrasenanalyse. Wenn mehr Lücken als nötig vorhanden sind, werden die Wörter zwischen ihnen für den Algorithmus nicht mehr erkennbar. Gleichzeitig behält diese Bypass-Methode ein hohes Maß an Lesbarkeit von Phrasen für eine Person bei. Die Methode funktioniert einfach: Ein zufälliger Buchstabe im Wort wird ausgewählt, nachdem ein Leerzeichen eingefügt wurde. Infolgedessen hört ein Wort, das dem Algorithmus zuvor bekannt war, auf, ein solches zu sein. Beispiel: "Hass" - "Hass". Wenn Sie alle Lücken im Text entfernen, wird die gesamte Phrase für den Algorithmus zu einem unverständlichen Wort für ihn. Wie in der Geschichte, in der die Tochter ihrer Mutter ein neues Telefon gab und sie ihr eine SMS mit dem Text schrieb: "Lieber, auf diesem Telefon ein Leerzeichen zu lassen." Wir können diesen Satz lesen, aber der Algorithmus wird ihn als ein Wort wahrnehmen, das er natürlich nicht kennt.
Wenn der Algorithmus die Buchstaben jedoch separat analysiert, kann er die Phrase erkennen, weshalb diese Hacking-Methode in solchen Fällen nicht geeignet ist.
Um solchen Angriffen entgegenzuwirken, wurden auch die Algorithmen umgeschult. Um das Hinzufügen von Leerzeichen zu bekämpfen, durchlief die Algorithmusbasis ein Programm zur zufälligen Einführung von Leerzeichen: Ein Wort aus n Buchstaben kann auf n-1 Arten durch ein Leerzeichen getrennt werden. Dies führte jedoch zu einer kombinatorischen Explosion, wenn die Komplexität des Algorithmus aufgrund der Zunahme der Größe der Eingabedaten stark zunimmt. Daher ist das Erlernen des Algorithmus basierend auf der bekannten Methode zum Hinzufügen von Leerzeichen eine äußerst schwierige und ineffiziente Übung.
Das Löschen von Leerzeichen ist ebenfalls schwierig. Wenn die Algorithmusbasis mit Phrasen aufgefüllt wird, die er kennt, jedoch ohne Leerzeichen, funktioniert dies nur dann effektiv, wenn eine solche Phrase angewendet wird. Es lohnt sich, ein paar Buchstaben oder ein Wort zu ersetzen, und der Algorithmus erkennt nichts.
Bei der Hacking-Methode durch Hinzufügen von Wörtern ist die Funktionsweise des Erkennungsalgorithmus das Wesentliche. Er unterteilt die Wörter in Kategorien, sagt "gut" und "schlecht". Wenn die Phrase mehr "gute" hat, bestimmt der Algorithmus höchstwahrscheinlich die gesamte Phrase als "gut". Umgekehrt. Wenn Sie der Phrase "schlecht" ein zufälliges "gutes" Wort hinzufügen, können Sie den Algorithmus täuschen, und die Bedeutung der Phrase für die Person, die sie liest, bleibt gleich. Das Hack-Programm generiert Zufallszahlen (von 10 bis 50) oder Wörter am Ende jeder Phrase. Als Quelle für zufällige Wörter wurde eine Liste der häufigsten von Google bereitgestellten englischen Wörter ausgewählt.
 Eine Tabelle mit den Ergebnissen der Anwendung der oben genannten Methoden zum Hacken und Reagieren von Algorithmen (A-Angriff, AT-Training nach dem Prinzip eines Angriffsprogramms, SC-Rechtschreibprüfung, RW-Entfernen von Leerzeichen).
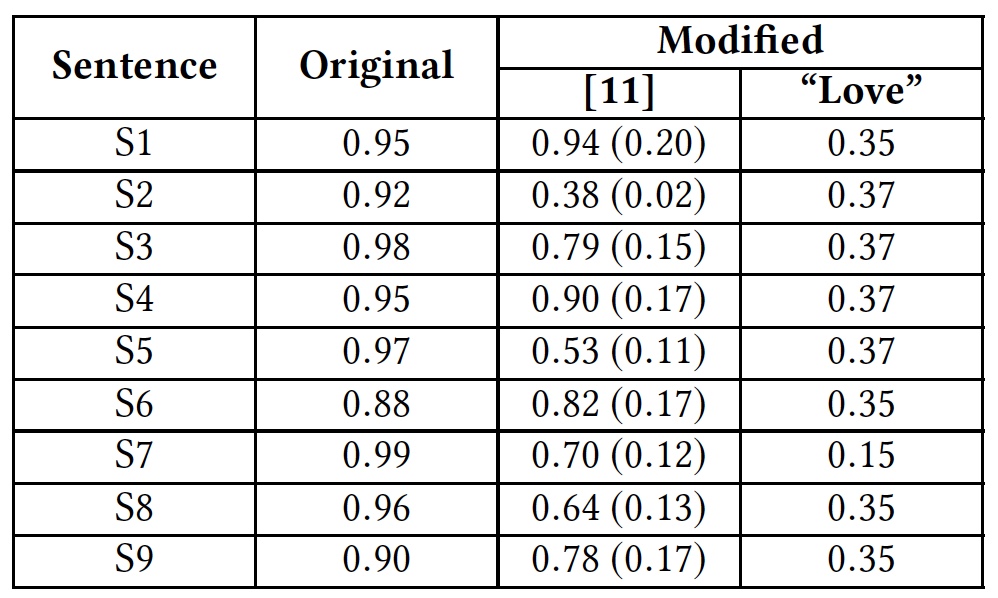
Eine Tabelle mit den Ergebnissen der Anwendung der oben genannten Methoden zum Hacken und Reagieren von Algorithmen (A-Angriff, AT-Training nach dem Prinzip eines Angriffsprogramms, SC-Rechtschreibprüfung, RW-Entfernen von Leerzeichen).Um die Problemumgehung durch die Einführung zusätzlicher Wörter zu veranschaulichen, führten die Forscher einen Test mit dem Wort „Liebe“ durch. Dieses Wort wurde am Ende anstößiger Sätze hinzugefügt.
 Testergebnisse mit dem Wort "Liebe".
Testergebnisse mit dem Wort "Liebe".Die Tabelle zeigt, dass diese Methode alle Algorithmen täuschen konnte, die das gesamte Wort analysieren. Algorithmen, die Buchstaben getrennt analysieren, litten ebenfalls, aber nicht so sehr.
Zuvor wurde die Google Perspective-API bereits getestet, was ihre unwirksame Fähigkeit zeigte, neutrale und anstößige Texte zu erkennen.Dann haben wir Testphrasen verwendet (ich werde aus offensichtlichen Gründen nicht übersetzen):S1: Climate change is happening and it's not changing in our favor. If you think differently you're an idiot.
S2: They're stupid, it's getting warmer, we should enjoy it while it lasts
S3: They are liberal idiots who are uneducated
S4: idiots. backward thinking people. nationalists. not accepting facts. susceptible to lies.
S5: They are stupid and ignorant with no class
S6: It's stupid and wrong
S7: If they voted for Hilary they are idiots
S8: Anyone who voted for Trump is a moron
S9: Screw you trump supporters
. , , Google Perspective API . «love» .
 Google Perspective API: «» () .
Google Perspective API: «» () ., Google Perspective API.
,
.
, , , .
, , . ? ? , ? : , , , . , , ? . , , . , — ?
, . ? ? ,
30% entry-level , : VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps $20 ? ( RAID1 RAID10, 24 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps ,
.
Dell R730xd 2 ? 2 Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 $249 ! . c Dell R730xd 5-2650 v4 9000 ?