
Dies ist der letzte Artikel in einer Reihe von Schulungsartikeln für Entwickler auf dem Gebiet der künstlichen Intelligenz. Es werden die Schritte zum Erstellen eines Deep-Learning-Modells für die Musikgenerierung, zur Auswahl des richtigen Modells und zur Datenvorverarbeitung sowie die Verfahren zum Einstellen, Trainieren, Testen und Ändern von BachBot erläutert.
Musikgenerierung - Über eine Aufgabe nachdenken
Der erste Schritt bei der Lösung vieler Probleme mithilfe künstlicher Intelligenz (KI) besteht darin, das Problem auf ein Grundproblem zu reduzieren, das mithilfe von KI gelöst wird. Ein solches Problem ist die Sequenzvorhersage, die in Übersetzungs- und Verarbeitungsanwendungen in natürlicher Sprache verwendet wird. Unsere Aufgabe, Musik zu erzeugen, kann auf das Problem der Vorhersage einer Sequenz reduziert werden, und die Vorhersage wird für eine Sequenz von Noten durchgeführt.
Modellauswahl
Es gibt verschiedene Arten von neuronalen Netzen, die als Modelle betrachtet werden können: direkt verteilte neuronale Netze, wiederkehrende neuronale Netze und neuronale Netze mit Langzeitgedächtnis.
Neuronen sind die grundlegenden abstrakten Elemente, die sich zu neuronalen Netzen verbinden. Im Wesentlichen ist ein Neuron eine Funktion, die Daten am Eingang empfängt und das Ergebnis ausgibt.
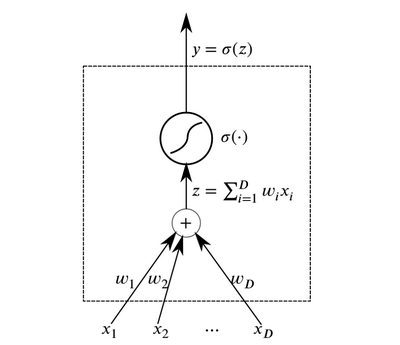 Neuron
NeuronSchichten von Neuronen, die am Eingang dieselben Daten empfangen und verbundene Ausgänge haben, können kombiniert werden, um ein
neuronales Netzwerk mit direkter Ausbreitung aufzubauen. Solche neuronalen Netze zeigen hohe Ergebnisse aufgrund der Zusammensetzung nichtlinearer Aktivierungsfunktionen, wenn Daten durch mehrere Schichten geleitet werden (das sogenannte Deep Learning).
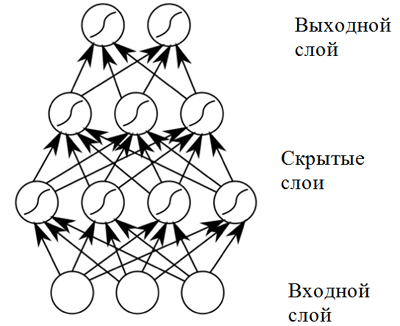 Neuronales Netzwerk mit direkter Verteilung
Neuronales Netzwerk mit direkter VerteilungEin direkt verteiltes neuronales Netzwerk zeigt gute Ergebnisse in einer Vielzahl von Anwendungen. Ein solches neuronales Netzwerk hat jedoch einen Nachteil, der seine Verwendung in einer Aufgabe im Zusammenhang mit der Musikkomposition (Sequenzvorhersage) nicht zulässt: Es hat eine feste Dimension von Eingabedaten, und Musikkompositionen können unterschiedliche Längen haben. Darüber hinaus
berücksichtigen neuronale Netze mit direkter Verteilung keine Eingaben aus früheren Zeitschritten, was sie für die Lösung des Sequenzvorhersageproblems nicht sehr nützlich macht! Ein Modell, das als
wiederkehrendes neuronales Netzwerk bezeichnet wird, ist für diese Aufgabe besser geeignet.
Rekursive neuronale Netze lösen diese beiden Probleme, indem sie Verbindungen zwischen versteckten Knoten einführen: In diesem Fall können Knoten im nächsten Zeitschritt Informationen über die Daten im vorherigen Zeitschritt empfangen.
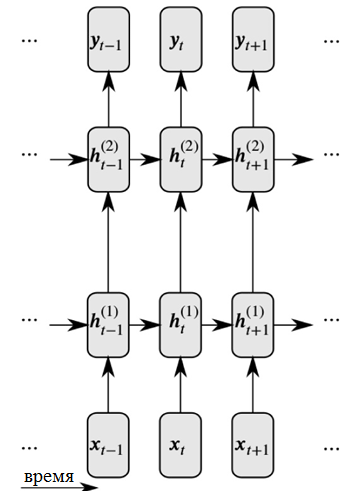 Detaillierte Darstellung eines wiederkehrenden neuronalen Netzwerks
Detaillierte Darstellung eines wiederkehrenden neuronalen NetzwerksWie Sie in der Abbildung sehen können, erhält jedes Neuron jetzt Eingaben sowohl von der vorherigen neuronalen Schicht als auch von der vorherigen Zeit.
Rekursive neuronale Netze, die sich mit großen Eingabesequenzen befassen, stoßen auf das sogenannte
Problem des verschwindenden Gradienten : Dies bedeutet, dass der Einfluss früherer Zeitschritte schnell verschwindet. Dieses Problem ist charakteristisch für die Aufgabe der Musikkomposition, da es wichtige langfristige Abhängigkeiten in Musikwerken gibt, die berücksichtigt werden müssen.
Um das Problem eines verschwindenden Gradienten zu lösen, kann eine Modifikation des wiederkehrenden Netzwerks verwendet werden, das als
neuronales Netzwerk mit langem Kurzzeitgedächtnis (oder LSTM-neuronales Netzwerk) bezeichnet wird . Dieses Problem wird durch die Einführung von Speicherzellen gelöst, die von drei Arten von "Gates" sorgfältig überwacht werden. Klicken Sie auf den folgenden Link, um weitere Informationen zu erhalten:
Allgemeine Informationen zu neuronalen LSTM-Netzen .
Daher verwendet BachBot ein Modell, das auf dem neuronalen LSTM-Netzwerk basiert.
Vorbehandlung
Musik ist eine sehr komplexe Kunstform und umfasst verschiedene Dimensionen: Tonhöhe, Rhythmus, Tempo, dynamische Farbtöne, Artikulation und mehr. Um die Musik für die Zwecke dieses Projekts zu vereinfachen
, werden nur die Tonhöhe und die Dauer der Klänge berücksichtigt . Darüber hinaus wurden alle Chöre in C-Dur oder A-Moll
transponiert , und die Notenzeiten wurden
zeitlich (gerundet) auf das nächste Vielfache der Sechzehntelnote
quantisiert . Diese Maßnahmen wurden ergriffen, um die Komplexität der Kompositionen zu verringern und die Netzwerkleistung zu erhöhen, während der grundlegende Inhalt der Musik unverändert blieb. Operationen zur Normalisierung der Tonalitäten und Dauer von Noten wurden unter Verwendung der music21-Bibliothek durchgeführt.
def standardize_key(score): """Converts into the key of C major or A minor. Adapted from https://gist.github.com/aldous-rey/68c6c43450517aa47474 """
Der Code zur Standardisierung der Schlüsselzeichen in den gesammelten Werken, die Tasten in C-Dur oder A-Moll werden in der Ausgabe verwendetDie Zeitquantisierung auf das nächste Vielfache der Sechzehntelnote wurde unter Verwendung der
Stream.quantize () -Funktion der
music21- Bibliothek durchgeführt. Das Folgende ist ein Vergleich von Statistiken, die einem Datensatz vor und nach seiner vorläufigen Verarbeitung zugeordnet sind:
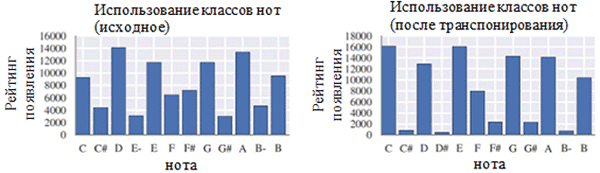 Verwendung jeder Notenklasse vor (links) und nach der Vorverarbeitung (rechts). Eine Notenklasse ist eine Note unabhängig von ihrer Oktave.
Verwendung jeder Notenklasse vor (links) und nach der Vorverarbeitung (rechts). Eine Notenklasse ist eine Note unabhängig von ihrer Oktave.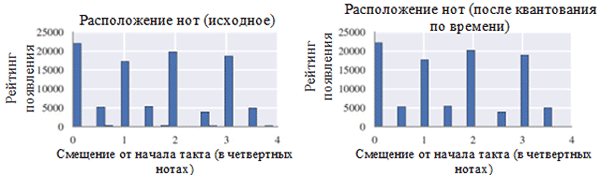 Position der Notizen vor (links) und nach der Vorverarbeitung (rechts)
Position der Notizen vor (links) und nach der Vorverarbeitung (rechts)Wie Sie in der obigen Abbildung sehen können, hat die Transposition der ursprünglichen Tonart der Chöre in die Tonart C-Dur oder c-Moll (a-Moll) die in den gesammelten Werken verwendete Notenklasse erheblich beeinflusst. Insbesondere die Anzahl der Vorkommen für Noten in Tonarten in Dur-Tonarten (C-Dur) und a-Moll (a-Moll) (C, D, E, F, G, A, B) nahm zu. Sie können auch kleine Peaks für die Noten F # und G # beobachten, da sie in der aufsteigenden Folge von melodischem a-Moll (A, B, C, D, E, F # und G #) vorhanden sind.
Andererseits hatte die Zeitquantisierung einen viel geringeren Effekt. Dies kann durch die hohe Auflösung der Quantisierung erklärt werden (ähnlich wie beim Runden auf viele signifikante Stellen).
Codierung
Nachdem die Daten vorverarbeitet wurden, müssen die Chöre in ein Format codiert werden, das mithilfe eines wiederkehrenden neuronalen Netzwerks leicht verarbeitet werden kann. Das erforderliche Format ist eine
Folge von Token . Für das BachBot-Projekt wurde die Codierung auf der Ebene der Noten (jedes Token repräsentiert eine Note) anstelle der Ebene der Akkorde (jedes Token repräsentiert einen Akkord) ausgewählt. Diese Lösung reduzierte die Größe des Wörterbuchs von 128
4 möglichen Akkorden auf 128 mögliche Noten, wodurch die Arbeitseffizienz gesteigert werden konnte.
Für das BachBot-Projekt wurde ein ursprüngliches Kodierungsschema für Musikkompositionen erstellt. Der Choral ist in Zeitschritte unterteilt, die Sechzehntelnoten entsprechen. Diese Schritte werden als Frames bezeichnet. Jeder Frame enthält eine Folge von Tupeln, die den Wert der Tonhöhe einer Note im Format einer digitalen Musikinstrument-Schnittstelle (MIDI) und ein Zeichen für die Bindung dieser Note an eine vorherige Note derselben Höhe (Note, Zeichen für Bindung) darstellen. Die Noten innerhalb des Rahmens sind in absteigender Reihenfolge der Höhe nummeriert (Sopran → Alt → Tenor → Bass). Jeder Rahmen kann auch einen Rahmen haben, der das Ende einer Phrase markiert; Fermaten werden durch ein Punktsymbol (.) Über der Note dargestellt. Die Symbole
START und
END werden am Anfang und am Ende jedes Chors hinzugefügt. Diese Symbole bewirken eine Initialisierung des Modells und ermöglichen es dem Benutzer, zu bestimmen, wann die Komposition endet.
START
(59, True)
(56, True)
(52, True)
(47, True)
|||
(59, True)
(56, True)
(52, True)
(47, True)
|||
(.)
(57, False)
(52, False)
(48, False)
(45, False)
|||
(.)
(57, True)
(52, True)
(48, True)
(45, True)
|||
ENDEin Beispiel für die Codierung von zwei Akkorden. Jeder Akkord dauert einen achten Taktschlag, der zweite Akkord wird von einer Farm begleitet. Die Sequenz "|||" markiert das Ende des Rahmens def encode_score(score, keep_fermatas=True, parts_to_mask=[]): """ Encodes a music21 score into a List of chords, where each chord is represented with a (Fermata :: Bool, List[(Note :: Integer, Tie :: Bool)]). If `keep_fermatas` is True, all `has_fermata`s will be False. All tokens from parts in `parts_to_mask` will have output tokens `BLANK_MASK_TXT`. Time is discretized such that each crotchet occupies `FRAMES_PER_CROTCHET` frames. """ encoded_score = [] for chord in (score .quantize((FRAMES_PER_CROTCHET,)) .chordify(addPartIdAsGroup=bool(parts_to_mask)) .flat .notesAndRests):
Code, der zum Codieren der music21-Tonalität mithilfe eines speziellen Codierungsschemas verwendet wirdModellaufgabe
Im vorherigen Teil wurde eine Erklärung gegeben, die zeigt, dass die Aufgabe der automatischen Komposition auf die Aufgabe der Vorhersage einer Sequenz reduziert werden kann. Insbesondere kann ein Modell die wahrscheinlichste nächste Note basierend auf vorherigen Noten vorhersagen. Um diese Art von Problem zu lösen, ist ein neuronales Netzwerk mit langem Kurzzeitgedächtnis (LSTM) am besten geeignet. Formal sollte das Modell P (x
t + 1 | x
t , h
t-1 ), die Wahrscheinlichkeitsverteilung für die nächstmöglichen Noten (x
t + 1 ) basierend auf dem aktuellen Token (x
t ) und dem vorherigen verborgenen Zustand (h
t-1 ) vorhersagen. . Interessanterweise wird dieselbe Operation von Sprachmodellen ausgeführt, die auf wiederkehrenden neuronalen Netzen basieren.
Im Kompositionsmodus wird das Modell mit dem
START- Token initialisiert. Anschließend wird das
nächstwahrscheinlichste Token ausgewählt, dem Sie folgen möchten. Danach wählt das Modell weiterhin das nächstwahrscheinlichste Token unter Verwendung der vorherigen Notiz und des vorherigen ausgeblendeten Status aus, bis ein END-Token generiert wird. Das System enthält Temperaturelemente, die ein gewisses Maß an Zufälligkeit hinzufügen, um zu verhindern, dass BachBot immer wieder dasselbe Stück komponiert.
Verlustfunktion
Beim Training eines Vorhersagemodells muss normalerweise eine Funktion minimiert werden (sogenannte Verlustfunktion). Diese Funktion beschreibt den Unterschied zwischen der Modellvorhersage und der Grundwahrheitseigenschaft. BachBot minimiert den Verlust der Kreuzentropie zwischen der vorhergesagten Verteilung (x
t + 1 ) und der tatsächlichen Verteilung der Zielfunktion. Die Verwendung der Kreuzentropie als Verlustfunktion ist ein guter Ausgangspunkt für eine Vielzahl von Aufgaben. In einigen Fällen können Sie jedoch auch Ihre eigene Verlustfunktion verwenden. Ein weiterer akzeptabler Ansatz besteht darin, verschiedene Verlustfunktionen zu verwenden und ein Modell anzuwenden, das den tatsächlichen Verlust während der Überprüfung minimiert.
Schulung / Prüfung
Beim Training eines rekursiven neuronalen Netzwerks verwendete BachBot eine Token-Korrektur mit dem Wert x
t + 1, anstatt eine Modellvorhersage anzuwenden. Dieser als obligatorisches Lernen bezeichnete Prozess wird verwendet, um die Konvergenz sicherzustellen, da Modellvorhersagen zu Beginn des Trainings natürlich zu schlechten Ergebnissen führen. Im Gegensatz dazu sollte während der Validierung und Zusammensetzung die Vorhersage des Modells x
t + 1 als Eingabe für die nächste Vorhersage wiederverwendet werden.
Andere Überlegungen
Um die Effizienz in diesem Modell zu erhöhen, wurden die folgenden praktischen Methoden verwendet, die für neuronale LSTM-Netze üblich sind: normalisierte Gradientenabschneidung, Eliminierungsmethode, Paketnormalisierung und BPTT-Methode (Truncated Time Error Back Propagation).
Das normalisierte Gradientenkürzungsverfahren beseitigt das Problem des unkontrollierten Wachstums des Gradientenwerts (die Umkehrung des Problems des verschwindenden Gradienten, das unter Verwendung der Architektur von LSTM-Speicherzellen gelöst wurde). Mit dieser Technik werden Gradientenwerte, die einen bestimmten Schwellenwert überschreiten, abgeschnitten oder skaliert.
Die Ausschlussmethode ist eine Technik, bei der einige
zufällig ausgewählte Neuronen während des Netzwerktrainings getrennt (ausgeschlossen) werden. Dies vermeidet eine Überanpassung und verbessert die Qualität der Generalisierung. Das Problem der Überanpassung tritt auf, wenn das Modell für den Trainingsdatensatz optimiert wird und in geringerem Maße für Proben außerhalb dieses Satzes anwendbar ist. Die Ausschlussmethode verschlechtert häufig den Verlust während des Trainings, verbessert ihn jedoch in der Überprüfungsphase (mehr dazu weiter unten).
Die Berechnung des Gradienten in einem wiederkehrenden neuronalen Netzwerk für eine Folge von 1000 Elementen entspricht in ihren Kosten den Vorwärts- und Rückwärtspassagen im neuronalen Netzwerk mit direkter Verteilung von 1000 Schichten.
Die BPTT-Methode (
Truncated Error Back Propagation ) über die Zeit wird verwendet, um die Kosten für die Aktualisierung von Parametern während des Trainings zu senken. Dies bedeutet, dass Fehler nur während einer festen Anzahl von Zeitschritten weitergegeben werden, die vom aktuellen Moment zurückgezählt werden. Bitte beachten Sie, dass mit der BPTT-Methode weiterhin langfristige Lernabhängigkeiten möglich sind, da latente Zustände bereits in vielen früheren Zeitschritten aufgedeckt wurden.
Parameter
Das Folgende ist eine Liste relevanter Parameter für Modelle wiederkehrender neuronaler Netze / neuronaler Netze mit langem Kurzzeitgedächtnis:
- Die Anzahl der Schichten . Das Erhöhen dieses Parameters kann die Effizienz des Modells erhöhen, das Trainieren dauert jedoch länger. Außerdem können zu viele Schichten zu einer Überanpassung führen.
- Die Dimension des latenten Zustands . Das Erhöhen dieses Parameters kann die Komplexität des Modells erhöhen, dies kann jedoch zu einer Überanpassung führen.
- Dimension von Vektorvergleichen
- Die Sequenzlänge / Anzahl der Frames vor dem Abschneiden der Rückausbreitung des Fehlers über die Zeit.
- Wahrscheinlichkeit des Ausschlusses von Neuronen . Die Wahrscheinlichkeit, mit der ein Neuron während jedes Aktualisierungszyklus aus dem Netzwerk ausgeschlossen wird.
Die Methode zur Auswahl des optimalen Parametersatzes wird später in diesem Artikel erläutert.
Implementierung, Schulung und Test
Plattformauswahl
Derzeit gibt es viele Plattformen, auf denen Sie Modelle für maschinelles Lernen in verschiedenen Programmiersprachen (einschließlich JavaScript!) Implementieren können. Beliebte Plattformen sind
Scikit-Learn ,
TensorFlow und
Torch .
Die Torch-Bibliothek wurde als Plattform für das BachBot-Projekt ausgewählt. Zunächst wurde die TensorFlow-Bibliothek ausprobiert, zu diesem Zeitpunkt wurden jedoch umfangreiche wiederkehrende neuronale Netze verwendet, was zu einem Überlauf des Arbeitsspeichers der GPU führte. Torch ist eine wissenschaftliche Computerplattform, die auf der schnellen Programmiersprache LuaJIT * basiert. Die Torch-Plattform enthält hervorragende Bibliotheken für die Arbeit mit neuronalen Netzen und die Optimierung.
Modellimplementierung und Schulung
Die Implementierung hängt natürlich von der Sprache und Plattform ab, für die Sie sich entscheiden. Um zu erfahren, wie BachBot mithilfe von Torch neuronale Netze mit langem Kurzzeitgedächtnis implementiert, lesen Sie die Skripte, mit denen BachBot-Parameter trainiert und eingestellt werden. Diese Skripte sind auf der
Feynman Lyang GitHub- Website verfügbar
.Ein guter Ausgangspunkt für die Navigation im Repository ist das
Skript 1-train.zsh . Damit finden Sie den Pfad zur Datei
bachbot.py .
Genauer gesagt ist das Hauptskript zum Festlegen von Modellparametern die Datei
LSTM.lua . Das Skript zum Trainieren des Modells ist die Datei
train.lua .
Hyperparameter-Optimierung
Um nach den optimalen Werten der Hyperparameter zu suchen, wurde die Rastersuchmethode unter Verwendung des folgenden Parameterrasters verwendet.
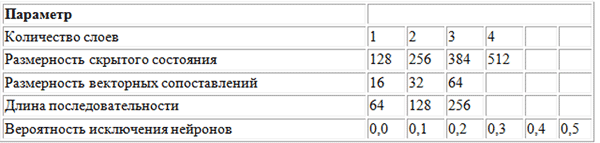 Raster der von BachBot bei der Rastersuche verwendeten Parameter
Raster der von BachBot bei der Rastersuche verwendeten ParameterEine Rastersuche ist eine vollständige Suche aller möglichen Kombinationen von Parametern. Andere vorgeschlagene Methoden zur Optimierung von Hyperparametern sind die Zufallssuche und die Bayes'sche Optimierung.
Der optimale Satz von Hyperparametern, der als Ergebnis einer Rastersuche erkannt wird, ist wie folgt: Anzahl der Schichten = 3, Dimension des verborgenen Zustands = 256, Dimension der Vektorvergleiche = 32, Sequenzlänge = 128, Wahrscheinlichkeit der Eliminierung von Neuronen = 0,3.
Dieses Modell erreichte während des Trainings einen Kreuzentropieverlust von 0,324 und in der Verifizierungsphase von 0,477. Das Diagramm der Lernkurve zeigt, dass der Lernprozess nach 30 Iterationen konvergiert (~ 28,5 Minuten bei Verwendung einer einzelnen GPU).
Verlustdiagramme während des Trainings und während der Verifizierungsphase können auch die Wirkung jedes Hyperparameters veranschaulichen. Von besonderem Interesse für uns ist die Wahrscheinlichkeit, Neuronen zu eliminieren:
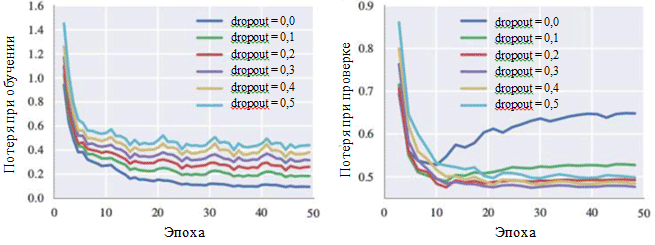 Lernkurven für verschiedene Einstellungen der Ausschlussmethode
Lernkurven für verschiedene Einstellungen der AusschlussmethodeIn der Figur ist zu sehen, dass das Eliminierungsverfahren das Auftreten einer Überanpassung wirklich vermeidet. Obwohl mit einer Ausschlusswahrscheinlichkeit von 0,0 der Verlust während des Trainings minimal ist, ist der Verlust in der Überprüfungsphase maximal. Große Wahrscheinlichkeitswerte führen zu einer Zunahme der Verluste während des Trainings und zu einer Abnahme der Verluste in der Verifizierungsphase. Der Mindestwert des Verlusts während der Verifizierungsphase bei der Arbeit mit BachBot wurde mit einer Ausnahmewahrscheinlichkeit von 0,3 festgelegt.
Alternative Bewertungsmethoden (optional)
Bei einigen Modellen - insbesondere bei kreativen Anwendungen wie dem Komponieren von Musik - ist der Verlust möglicherweise kein geeignetes Maß für den Erfolg des Systems. Stattdessen kann die subjektive menschliche Wahrnehmung das beste Kriterium sein.
Ziel des BachBot-Projekts ist es, automatisch Musik zu komponieren, die nicht von Bachs eigenen Kompositionen zu unterscheiden ist. Um den Erfolg der Ergebnisse zu bewerten, wurde eine Umfrage unter Benutzern im Internet durchgeführt. Die Umfrage erhielt die Form eines Wettbewerbs, bei dem die Benutzer gefragt wurden, welche Werke zum BachBot-Projekt und welche zu Bach gehören.
Die Umfrageergebnisse zeigten, dass die Umfrageteilnehmer (759 Personen mit unterschiedlichem Ausbildungsniveau) in nur 59 Prozent der Fälle zwischen zwei Stichproben genau unterscheiden konnten. Dies ist nur 9 Prozent höher als das Ergebnis zufälliger Vermutungen! Probieren Sie die
BachBot-Umfrage selbst aus!
Anpassung des Modells an die Harmonisierung
Jetzt kann BachBot P (x
t + 1 | x
t , h
t-1 ) berechnen, die Wahrscheinlichkeitsverteilung für die nächstmöglichen Noten basierend auf der aktuellen Note und dem vorherigen versteckten Zustand. Dieses sequentielle Vorhersagemodell kann anschließend angepasst werden, um die Melodie zu harmonisieren. Ein solches angepasstes Modell ist erforderlich, um die mit Hilfe von Emotionen modulierte Melodie im Rahmen eines Musikprojekts mit einer Diashow zu harmonisieren.
Wenn Sie mit der Modellharmonisierung arbeiten, wird eine vorgegebene Melodie bereitgestellt (normalerweise ist dies ein Sopranpart), und danach sollte das Modell Musik für die verbleibenden Teile komponieren. Um diese Aufgabe zu erfüllen, wird eine gierige "Best-First" -Suche mit der Einschränkung verwendet, dass die Melodienoten festgelegt sind. Gierige Algorithmen beinhalten Entscheidungen, die aus lokaler Sicht optimal sind. Im Folgenden finden Sie eine einfache Strategie zur Harmonisierung:
Angenommen, x t sind Token in der vorgeschlagenen Harmonisierung. Wenn zum Zeitpunkt t die Note der Melodie entspricht, ist x t gleich der gegebenen Note. Andernfalls ist x t gemäß den Vorhersagen des Modells gleich der wahrscheinlichsten nächsten Note. Den Code für diese Modellanpassung finden Sie auf der Feynman Lyang GitHub-Website: HarmModel.lua , harmonize.lua .
Das Folgende ist ein Beispiel für die Harmonisierung des Schlaflieds Twinkle, Twinkle, Little Star mit BachBot unter Verwendung der obigen Strategie.
 Harmonisierung des Schlaflieds von Twinkle, Twinkle, Little Star mit BachBot (im Sopranpart). Teile von Bratsche, Tenor und Bass wurden ebenfalls mit BachBot gefüllt
Harmonisierung des Schlaflieds von Twinkle, Twinkle, Little Star mit BachBot (im Sopranpart). Teile von Bratsche, Tenor und Bass wurden ebenfalls mit BachBot gefülltIn diesem Beispiel wird die Melodie des Wiegenlieds Twinkle, Twinkle, Little Star im Sopranpart gegeben. Danach wurden die Teile Viola, Tenor und Bass mit BachBot nach einer Harmonisierungsstrategie gefüllt. Und
so klingt es .
Trotz der Tatsache, dass BachBot bei der Ausführung dieser Aufgabe gute Leistungen erbracht hat, sind mit diesem Modell bestimmte Einschränkungen verbunden. Genauer gesagt, der Algorithmus
blickt nicht in die Melodie hinein und verwendet nur die aktuelle Note der Melodie und den vergangenen Kontext, um nachfolgende Noten zu erzeugen. Wenn Menschen eine Melodie harmonisieren, können sie die gesamte Melodie abdecken, was die Ableitung geeigneter Harmonisierungen vereinfacht. Die Tatsache, dass dieses Modell dazu nicht in der Lage ist, kann zu
Überraschungen führen, da die Verwendung nachfolgender Informationen, die Fehler verursachen, eingeschränkt ist. Um dieses Problem zu lösen, kann die sogenannte
Strahlensuche verwendet werden.
Bei Verwendung der Strahlensuche werden verschiedene Bewegungslinien überprüft. Anstatt nur eine, die wahrscheinlichste Note, die derzeit ausgeführt wird, zu verwenden, können beispielsweise vier oder fünf wahrscheinlichste Noten berücksichtigt werden, wonach der Algorithmus seine Arbeit mit jeder dieser Noten fortsetzt. Durch Untersuchen der verschiedenen Optionen kann das Modell
Fehler beheben . Die Strahlensuche wird häufig in Anwendungen zur Verarbeitung natürlicher Sprache verwendet, um Sätze zu erstellen.
Mit Hilfe von Emotionen modulierte Melodien können nun durch ein solches Harmonisierungsmodell geleitet werden, um sie zu vervollständigen.