
Vor etwas mehr als einem Jahr haben wir die
Splunk Machine Learning Toolkit- Anwendung
überprüft , mit der Sie Maschinendaten auf der Splunk-Plattform mithilfe verschiedener Algorithmen für maschinelles Lernen analysieren können.
Heute möchten wir über die Updates sprechen, die im letzten Jahr erschienen sind. Viele neue Versionen wurden veröffentlicht, verschiedene Algorithmen und Visualisierungen wurden hinzugefügt, um die Datenanalyse in Splunk auf ein neues Niveau zu heben.
Neue Algorithmen
Bevor Sie über Algorithmen sprechen, sollten Sie beachten, dass es eine
ML-SPL-API gibt, mit der Sie jeden Open-Source-Algorithmus mit mehr als 300 Python-Algorithmen laden können. Dazu müssen Sie jedoch in der Lage sein, bis zu einem gewissen Grad in Python zu programmieren.
Daher werden wir uns mit den Algorithmen befassen, die zuvor nur nach der Manipulation von Python verfügbar waren, jetzt aber in die Anwendung eingebettet sind und von jedem problemlos verwendet werden können.
 ACF (Autokorrelationsfunktion)
ACF (Autokorrelationsfunktion)Eine Autokorrelationsfunktion zeigt die Beziehung zwischen einer Funktion und ihrer verschobenen Kopie um den Betrag der Zeitverschiebung. Mit ACF können Sie doppelte Abschnitte finden oder die Frequenz des Signals bestimmen, die aufgrund überlappender Geräusche und Vibrationen bei anderen Frequenzen verborgen sind.
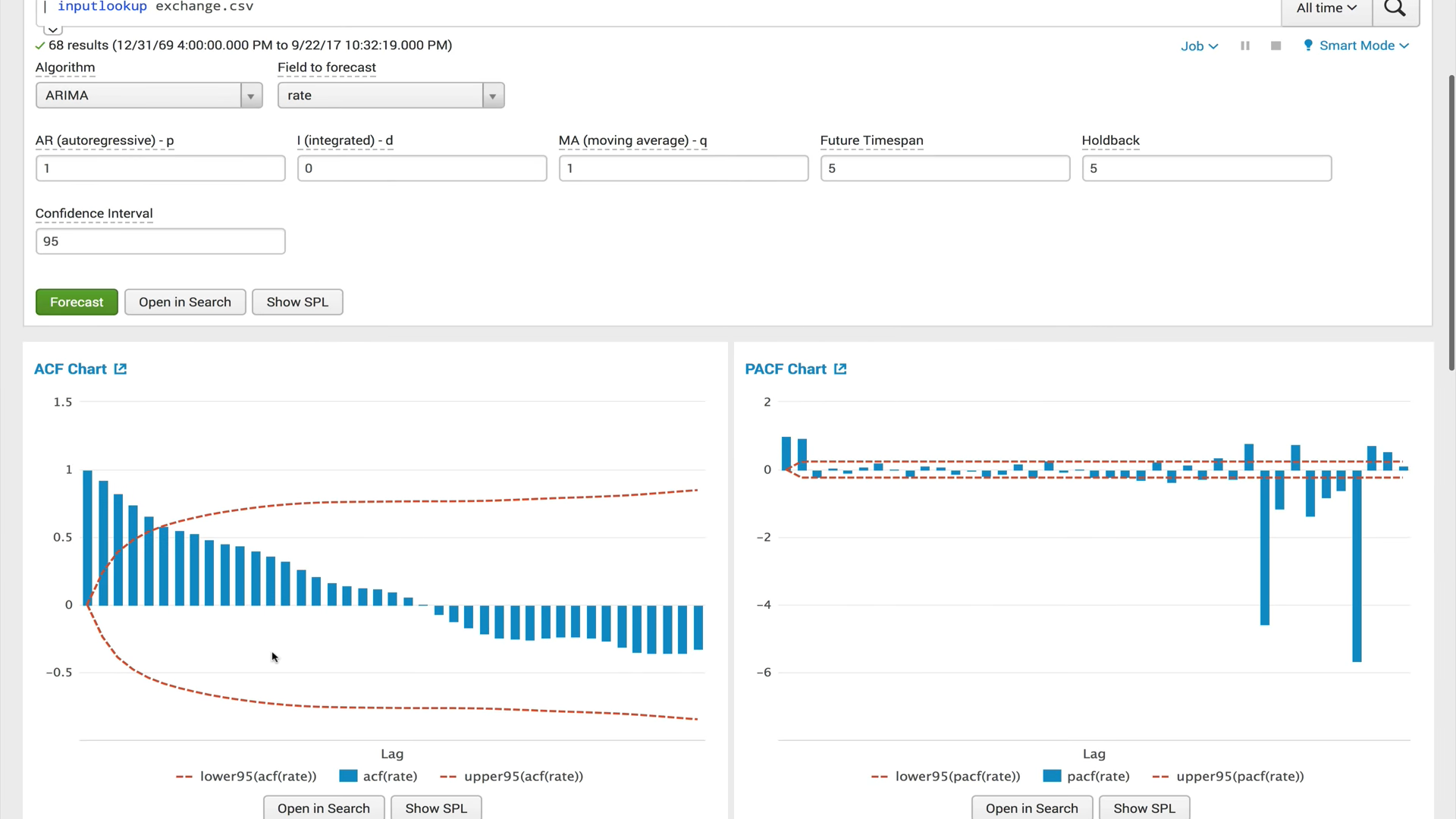
PACF (partielle Autokorrelationsfunktion)Die private Autokorrelationsfunktion zeigt die Korrelation zwischen den beiden Variablen abzüglich des Effekts aller internen Autokorrelationswerte. Die private Autokorrelation mit einer bestimmten Verzögerung ähnelt der normalen Autokorrelation, ihre Berechnung schließt jedoch den Einfluss der Autokorrelation mit kleineren Verzögerungen aus. In der Praxis liefert die private Autokorrelation ein „saubereres“ Bild der periodischen Abhängigkeiten.
ARIMA (integrierter Prozess der Autoregression und des gleitenden Durchschnitts)Das ARIMA-Modell ist eines der beliebtesten Modelle für die Erstellung von Kurzzeitprognosen. Autoregressive Werte drücken die Abhängigkeit des aktuellen Werts von Zeitreihen von vorherigen aus, und der gleitende Durchschnitt des Modells bestimmt die Auswirkung früherer Prognosefehler (auch als weißes Rauschen bezeichnet) auf den aktuellen Wert.
 Gradient Boosting Classifier und Gradient Boosting Regressor
Gradient Boosting Classifier und Gradient Boosting RegressorGradient Boosting ist eine maschinelle Lernmethode, die für Regressions- und Klassifizierungsprobleme verwendet wird und ein Vorhersagemodell in Form eines Ensembles schwacher Modelle, normalerweise Entscheidungsbäume, erstellt. Er baut das Modell schrittweise auf, wenn jeder nachfolgende Algorithmus versucht, die Mängel der Zusammensetzung aller vorherigen Algorithmen auszugleichen. Anfänglich entstand in den Arbeiten das Konzept des Boostings im Zusammenhang mit der Frage, ob es möglich ist, mit vielen schlechten (etwas von der zufälligen Definition abweichenden) Lernalgorithmen einen guten zu erhalten. In den letzten 10 Jahren war das Boosten neben neuronalen Netzen eine der beliebtesten Methoden des maschinellen Lernens. Die Hauptgründe sind Einfachheit, Vielseitigkeit, Flexibilität (die Fähigkeit, verschiedene Modifikationen zu erstellen) und vor allem eine hohe Generalisierungsfähigkeit.
X bedeutetDer X-Mittel-Clustering-Algorithmus ist ein fortschrittlicher K-Mittel-Algorithmus, der automatisch die Anzahl der Cluster basierend auf dem Bayes'schen Informationskriterium (BIC) bestimmt. Dieser Algorithmus ist praktisch, wenn keine vorläufigen Informationen über die Anzahl der Cluster vorliegen, in die diese Daten unterteilt werden können.
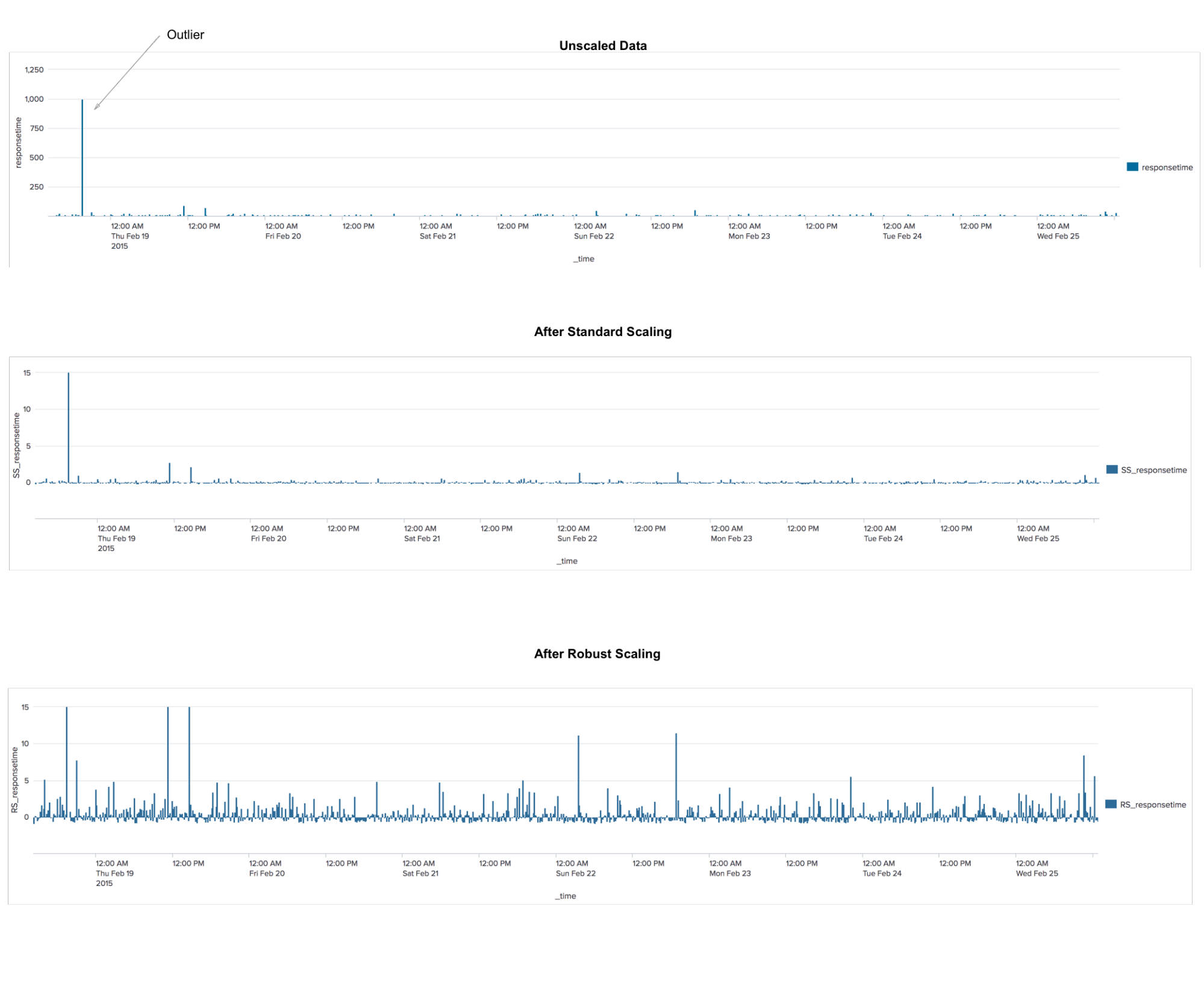
RobustscalerDies ist ein Datenvorverarbeitungsalgorithmus. Die Anwendung ähnelt dem StandardScaler-Algorithmus, der die Daten so transformiert, dass für jedes Merkmal der Durchschnitt 0 und die Varianz 1 beträgt, was dazu führt, dass alle Merkmale den gleichen Maßstab haben. Diese Skalierung garantiert jedoch nicht den Empfang bestimmter Minimal- und Maximalwerte der Attribute. RobustScaler ähnelt StandardScaler darin, dass die Funktionen aufgrund ihrer Anwendung dieselbe Skalierung haben. RobustScaler verwendet jedoch den Median und die Quartile anstelle des Mittelwerts und der Varianz. Dadurch kann RobustScaler Ausreißer oder Messfehler ignorieren, was für andere Skalierungsmethoden ein Problem sein kann.
 TFIDF
TFIDFEine statistische Kennzahl zur Bewertung der Bedeutung eines Wortes im Kontext eines Dokuments, das Teil einer Dokumentensammlung ist. Das Prinzip lautet: Wenn ein Wort häufig in einem Dokument gefunden wird, während es in allen anderen Dokumenten selten vorkommt, ist dieses Wort für das Dokument selbst von großer Bedeutung.
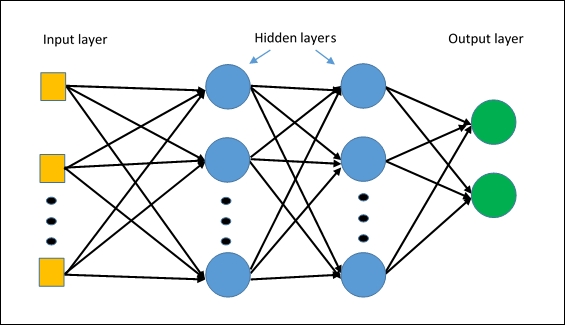
MLPClassifierDer erste neuronale Netzwerkalgorithmus in Splunk. Der Algorithmus basiert auf einem
mehrschichtigen Perzeptron , das nichtlineare Beziehungen in den Daten erfasst.
Verwaltung
In neuen Versionen hat sich die Verwaltung der Anwendung erheblich geändert.
Zunächst wurde ein
Vorbild für den Zugang zu verschiedenen Modellen und Experimenten hinzugefügt.
Zweitens wurde eine neue Schnittstelle zur
Verwaltung von Modellen eingeführt. Jetzt können Sie leicht sehen, welche Modelltypen Sie haben, die Einstellungen jedes Modells überprüfen (z. B. welche Variablen zum Trainieren verwendet wurden) und die Freigabeeinstellungen für jedes Modell anzeigen oder aktualisieren.
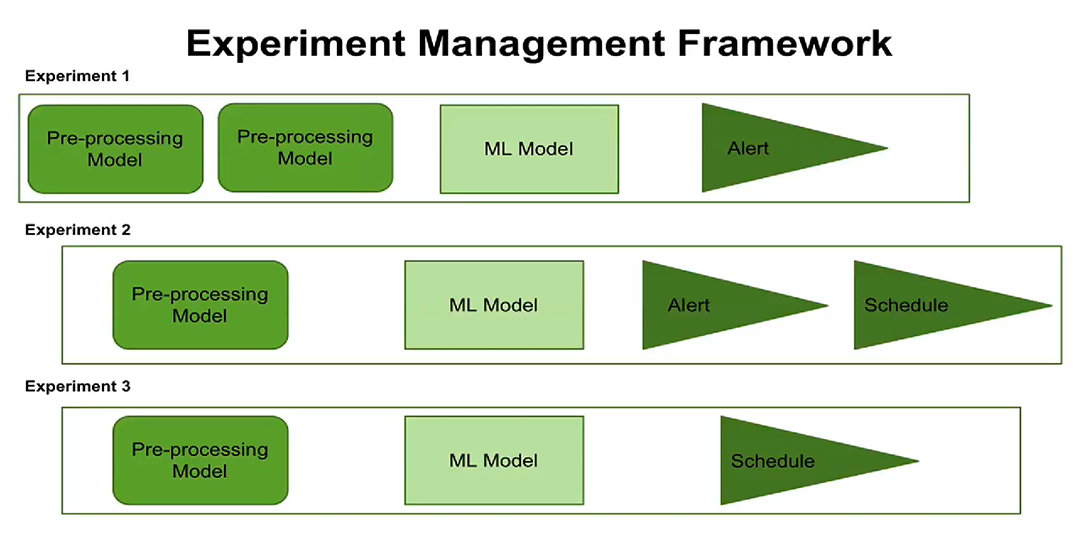
Drittens die Entstehung des Konzepts des Experimentmanagements. Jetzt können Sie
die Ausführung von Experimenten nach einem Zeitplan konfigurieren und Warnungen konfigurieren. Benutzer können sehen, wann jedes Experiment ausgeführt werden soll, welche Verarbeitungsschritte und Parameter für jedes Experiment konfiguriert sind.
Das neue Konzept des Experimentmanagements bietet Ihnen jetzt die Möglichkeit, mehrere Experimente gleichzeitig zu erstellen und zu verwalten, um aufzuzeichnen, wann diese Experimente durchgeführt wurden und welche Ergebnisse erzielt wurden.
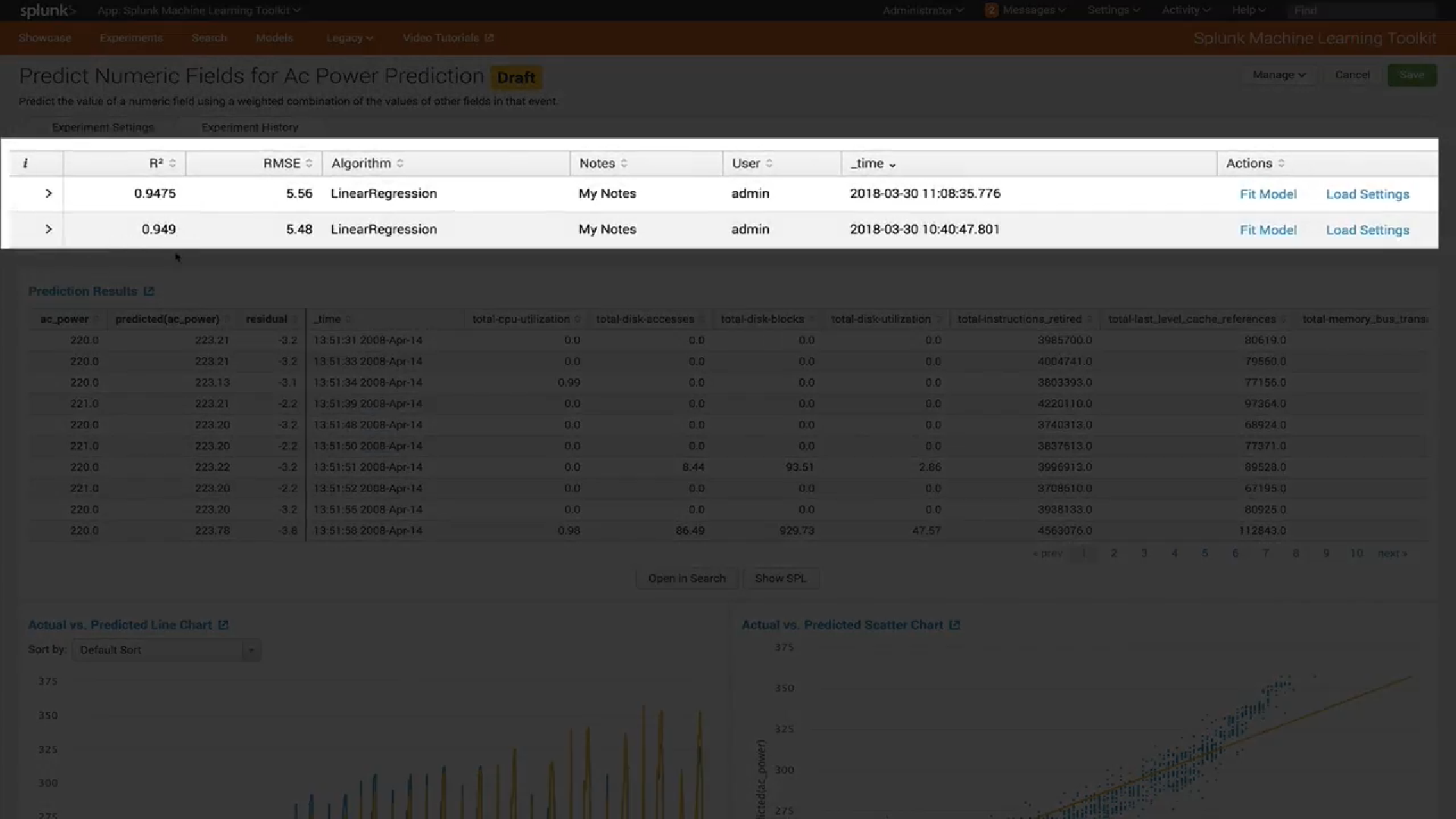
Visualisierung
In der neuesten Version von MLTK 3.4 wurde eine neue Art der Visualisierung hinzugefügt. Das berühmte
Box Plot oder, wie wir es auch nennen, "Boxen mit Schnurrbart".
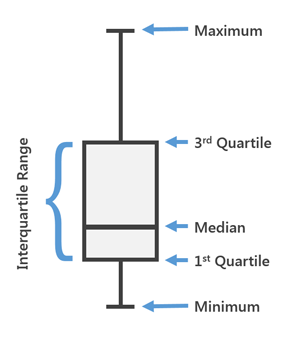
Box Plot wird in beschreibenden Statistiken verwendet. Mit ihm können Sie bequem den Median (oder, falls erforderlich, den Durchschnitt), das untere und obere Quartil, die minimalen und maximalen Werte der Stichprobe und der Ausreißer anzeigen. Mehrere dieser Kästchen können nebeneinander gezeichnet werden, um eine Verteilung visuell mit einer anderen zu vergleichen. Mit Abständen zwischen verschiedenen Teilen der Box können Sie den Grad der Streuung (Dispersion) und Asymmetrie der Daten bestimmen und Ausreißer identifizieren.
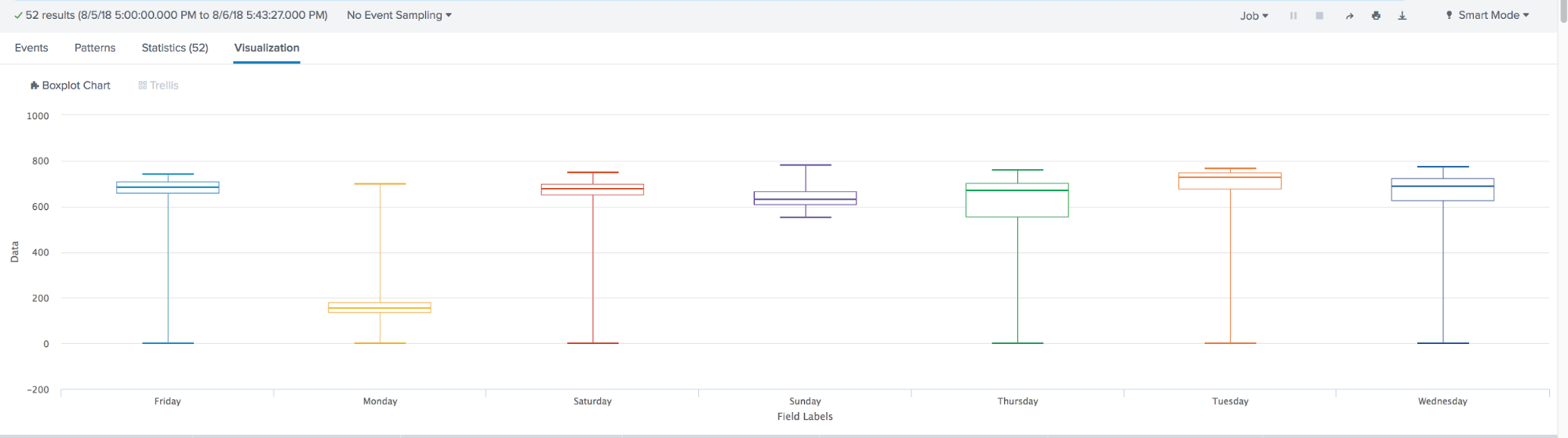
Zusammenfassend hat das maschinelle Lernen bei Splunk im Laufe des Jahres einen großen Schritt nach vorne gemacht. Erschienen:
- Viele neue integrierte Algorithmen wie: ACF, PACF, ARIMA, Gradient BoostingClassifier, Gradient Boosting Regressor, X-Mittel, RobustScaler, TFIDF, MLPClassifier;
- Rollenbasiertes Zugriffsmodell und die Fähigkeit, Modelle und Experimente zu verwalten;
- Visualisierungsbox-Plot
