Dieser Bericht von Alexey Milovidov, Leiter des ClickHouse-Entwicklungsteams, gibt einen Überblick über die wenigen bekannten DBMS. Einige von ihnen sind veraltet, andere haben ihre Entwicklung gestoppt und werden aufgegeben. Alexey macht in den aufgeführten Beispielen auf interessante architektonische Lösungen aufmerksam, versteht deren Schicksal und erklärt, welche Anforderungen Ihr Open-Source-Projekt erfüllen sollte.
- In meinem Bericht geht es um Datenbanken. Lassen Sie mich gleich fragen, welche U-Bahn-Karte auf dieser Folie angezeigt wird. Alle Linien gehen in eine Richtung.
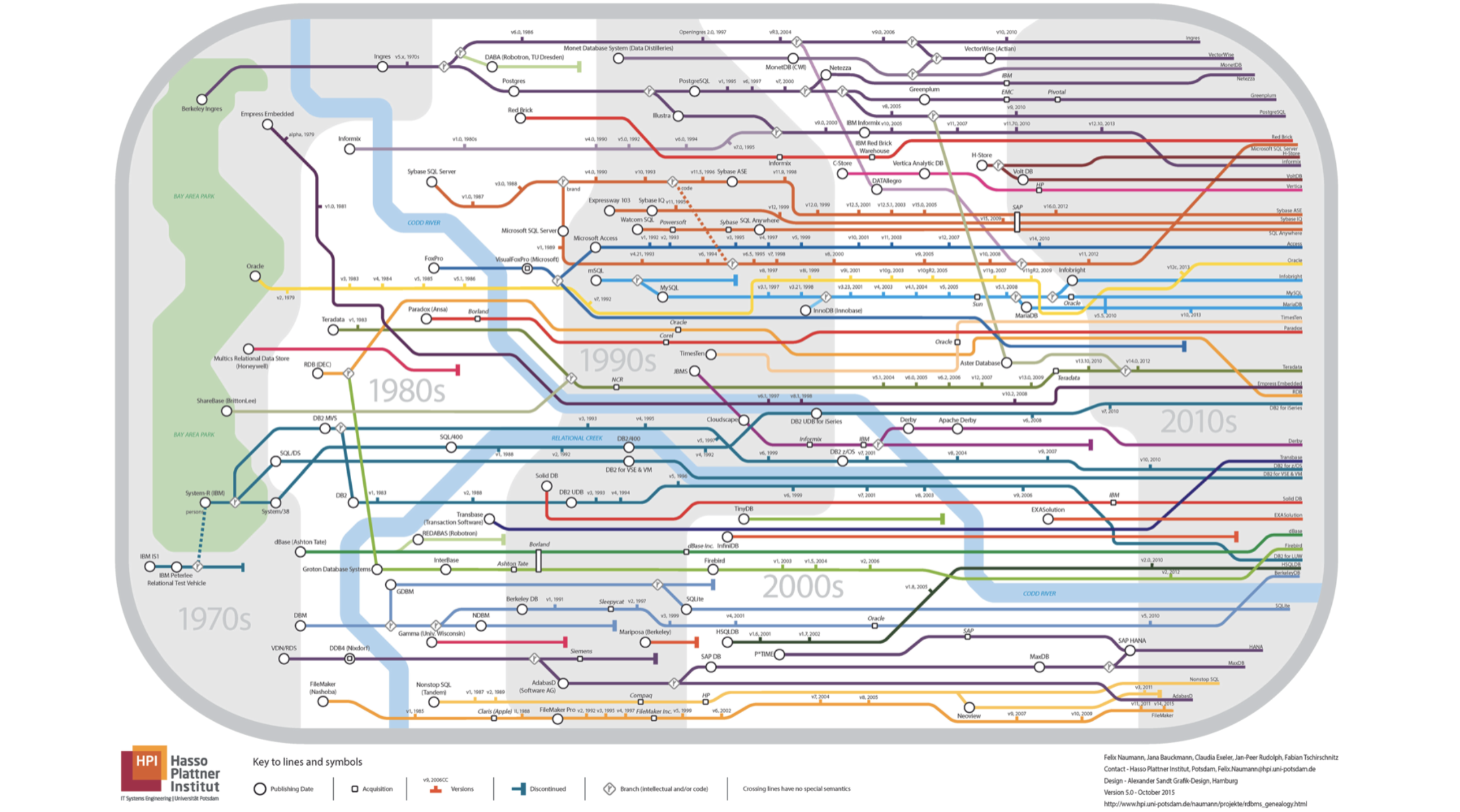
Alles ist falsch, es ist überhaupt nicht unterirdisch, es ist der Stammbaum relationaler Datenbanken. Wenn Sie genau hinschauen, werden Sie sehen, dass der Fluss der
Kodda River ist.
Ich werde nicht über sie sprechen. Was könnte langweiliger sein, als über MySQL, PostgreSQL oder ähnliches zu sprechen? Stattdessen werde ich über das Erstellen von Datenbanken sprechen.

Manuelle Montage. Systeme, die niemandem bekannt sind. Sie werden entweder von einer Person entworfen oder lange aufgegeben.

Das erste Beispiel ist EventQL. Bitte heben Sie Ihre Hand, wenn Sie jemals von diesem System gehört haben. Keine einzige Person, außer denen, die in Yandex arbeiten und meinen Bericht bereits angehört haben. Es war also nicht umsonst, dass ich dieses System in meine Bewertung aufgenommen habe.

Dies ist eine verteilte Spaltendatenbank-Engine, die für die Ereignisverarbeitung und -analyse entwickelt wurde. Es führt sehr schnelle SQL-Abfragen durch, Open Source seit dem 26. Juli 2016, geschrieben in C ++, ZooKeeper wird für die Koordination verwendet, es gibt keine Abhängigkeiten daneben. Es erinnert mich an etwas. Unser wunderbares System, jeder kennt den Namen schon. EventQL ist so etwas wie ClickHouse, aber besser. Verteilt, massiv parallel, spaltenorientiert, skalierbar auf Petabyte, schnelle Reichweite - alles ist klar, wir haben alles. Fast vollständige Unterstützung für SQL 2009, Echtzeit-Einfügungen und -Updates, automatische Verteilung von Daten über den Cluster und sogar die ChartSQL-Sprache zur Beschreibung von Diagrammen. Wie großartig! Dies versprechen wir allen und was wir nicht haben.
Trotzdem gibt es beim letzten Commit vor fast einem Jahr eine Seite, die nicht geladen wird, man muss sie über web.archive.org ansehen.
Fragen Sie auf GitHub - was sind Ihre Entwicklungspläne, was wird als nächstes passieren? Niemand antwortete.
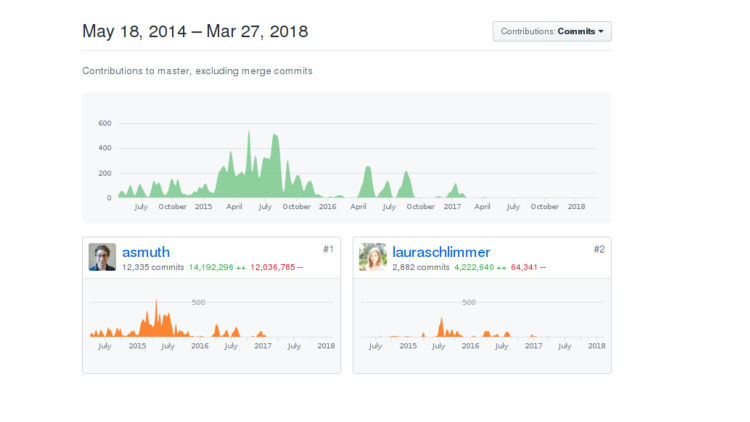
Das System hat zwei Entwickler. Einer ist ein Backend-Entwickler, der zweite ist ein Frontend. Ich werde nicht zeigen, wer von ihnen vielleicht selbst raten wird. Hergestellt von DeepCortex. Der Name kommt mir bekannt vor, aber es gibt viele Unternehmen, die das Wort Deep und das Wort Cortex verwenden. DeepCortex ist eine unbekannte Firma aus Berlin. Das System wurde seit 2014 entwickelt, es wurde lange Zeit intern entwickelt, dann wurde es in Open Source veröffentlicht und ein Jahr später aufgegeben.

Es sieht ungefähr so aus: Sie warfen sie in die Luft und dachten, plötzlich würde jemand sie bemerken oder sie würde irgendwo wegfliegen. Leider gibt es keine.
Ein weiterer Nachteil ist die relativ unpraktische AGPL-Lizenz. Auch wenn die Verwendung für Ihr Unternehmen keine ernsthaften Einschränkungen darstellt, wird häufig befürchtet, dass die Rechtsabteilung einige Punkte dagegen hat.
Ich begann zu suchen, was passiert ist, warum es nicht entwickelt wird. Ich habe mir das Konto des Entwicklers angesehen, im Prinzip ist alles in Ordnung, die Person lebt, schreibt weiterhin alle Commits in das private Repository. Es ist nicht klar, was passiert ist.

Entweder zog die Person in ein anderes Unternehmen und verlor das Interesse an Unterstützung, oder die Prioritäten des Unternehmens änderten sich oder einige Lebensumstände. Vielleicht fühlte sich das Unternehmen selbst nicht sehr schlecht, und Open Source wurde für alle Fälle erstellt. Oder einfach nur müde. Ich weiß die genaue Antwort nicht. Wenn jemand weiß, bitte sag es mir.

Aber das alles wurde nicht umsonst getan. Zunächst ChartSQL zur deklarativen Beschreibung von Diagrammen. Ähnliches wird jetzt im Tabix-Datenvisualisierungssystem für ClickHouse verwendet. EventQL hat ein Blog, das jedoch derzeit nicht verfügbar ist. Sie müssen sich in web.archive.org umsehen. Es gibt TXT-Dateien. Das System ist sehr kompetent implementiert, und wenn Sie interessiert sind, können Sie den Code lesen und interessante Architekturlösungen sehen.
Das ist alles über sie für jetzt. Und das nächste System gewinnt alle, was ich in Betracht ziehen werde, weil es den besten und köstlichsten Namen hat. Alenka-System.
Ich wollte ein Foto der Schokoladenverpackung hinzufügen, befürchte jedoch, dass es Urheberrechtsprobleme geben wird. Was ist Alenka?

Dies ist ein analytisches DBMS, das Abfragen auf Grafikbeschleunigern ausführt. Openors, Apache 2-Lizenz, 1103 Sterne, geschrieben in CUDA, ein wenig C ++, ein Entwickler aus Minsk. Es gibt sogar einen JDBC-Treiber. Öffner seit 2012. Seit 2016 entwickelt sich das System jedoch aus irgendeinem Grund nicht mehr weiter.

Dies ist ein persönliches Projekt, nicht Eigentum des Unternehmens, sondern ein Projekt einer Person. Dies ist ein solcher Forschungsprototyp, um die Möglichkeiten zu untersuchen, wie Daten auf der GPU schnell verarbeitet werden können. Es gibt interessante Tests von Mark Litvinchik, bei Interesse können Sie sich den Blog ansehen. Wahrscheinlich haben viele bereits seine Tests dort gesehen, dass ClickHouse das schnellste ist.

Ich habe keine Antwort, warum das System aufgegeben wird, nur Vermutungen. Jetzt arbeitet eine Person für nVidia, wahrscheinlich ist dies nur ein Zufall.

Dies ist ein großartiges Beispiel, da es das Interesse und den Horizont erhöht. Sie können sehen und verstehen, wie Sie dies tun können und wie das System auf der GPU arbeiten kann.
Wenn Sie sich jedoch für dieses Thema interessieren, gibt es eine Reihe weiterer Optionen. Zum Beispiel das MapD-System.
Wer hat von MapD gehört? Beleidigen. Dies ist ein gewagter Start, der auch eine GPU-Datenbank entwickelt. Kürzlich in Open Source unter der Apache 2-Lizenz veröffentlicht. Ich weiß nicht, wofür es ist, gut oder umgekehrt. Dieses Startup ist so erfolgreich, dass es in Open Source angelegt ist oder umgekehrt und bald geschlossen wird.
Es gibt einen PGStorm. Wenn Sie sich mit PostgreSQL auskennen, sollten Sie etwas über PGStorm erfahren. Auch Open Source, entwickelt von einer Person. Von den geschlossenen Systemen gibt es BrytlytDB, Kinetica und das russische Unternehmen Polymatic, das das Business Intelligence-System herstellt. Analytik, Visualisierung und so weiter. Und für die Datenverarbeitung können auch Grafikbeschleuniger verwendet werden, was möglicherweise interessant ist.

Ist es möglich, etwas cooleres als eine GPU zu machen? Zum Beispiel gab es ein System, das Daten auf einem FPGA verarbeitete. Das ist Kickfire. Sie lieferte ihre Lösung in Form von Eisen sofort mit der Software. Das Unternehmen wurde zwar vor langer Zeit geschlossen, diese Lösung war ziemlich teuer und konnte nicht mit anderen solchen Schränken mithalten, wenn ein Anbieter Ihnen diesen Schrank bringt, und alles funktioniert auf magische Weise.
Darüber hinaus gibt es Prozessoren, die Anweisungen zum Beschleunigen von SQL - SQL in Silicon in den neuen SPARC - Prozessormodellen enthalten. Sie müssen jedoch nicht glauben, dass Sie Join in Assembler schreiben, es ist nicht vorhanden. Es gibt einfache Anweisungen, die entweder die Dekomprimierung mit einfachen Algorithmen und ein wenig Filterung durchführen. Im Prinzip kann es nicht nur SQL beschleunigen. Beispielsweise verfügen Intel-Prozessoren über eine Reihe von SSE 4.2-Anweisungen zum Verarbeiten von Zeichenfolgen. Als es irgendwann im Jahr 2008 erschien, hatte die Intel-Website einen Artikel mit dem Titel „Verwenden neuer Intel-Prozessoranweisungen zur Beschleunigung der XML-Verarbeitung“. Hier ist es ungefähr gleich. Anweisungen, die zur Beschleunigung einer Datenbank nützlich sind, können ebenfalls verwendet werden.
Eine weitere sehr interessante Option ist die Übertragung der Aufgabe, Daten teilweise auf SSD zu filtern. Jetzt sind SSDs ziemlich leistungsfähig geworden. Dies ist ein kleiner Computer mit einem Controller, und Sie können Ihren Code grundsätzlich hochladen, wenn Sie es wirklich versuchen. Ihre Daten werden von der SSD gelesen, aber sofort gefiltert und nur die erforderlichen Daten an Ihr Programm übertragen. Sehr cool, aber das alles befindet sich noch in der Forschungsphase. Hier ist ein Artikel über VLDB, lesen Sie.
Weiterhin eine bestimmte ViyaDB.

Es wurde erst vor einem Monat eröffnet. "Analytische Datenbank für unsortierte Daten." Warum "unsortiert" in den Namen aufgenommen wird, ist unklar, warum eine solche Betonung vorgenommen werden sollte. Was können Sie in anderen Datenbanken nur mit sortierten arbeiten?
Alles ist in Ordnung, der Quellcode auf GitHub, Apache 2.0-Lizenz, geschrieben in modernstem C ++, alles ist in Ordnung. Ein Entwickler, aber nichts.

Was mir am besten gefallen hat, wo Sie ein Beispiel nehmen können, ist die hervorragende Startvorbereitung. Daher bin ich überrascht, dass niemand gehört hat. Es gibt eine wundervolle Seite, es gibt Dokumentation, es gibt einen Artikel über Habré, es gibt einen Artikel über Medium, LinkedIn, Hacker News. Na und? Ist das alles umsonst? Sie haben sich nichts davon angesehen. Hier sagen sie, Habr ist kein Kuchen. Na ja, vielleicht, aber eine tolle Sache.
Wie ist dieses System?

Daten im RAM arbeitet das System mit aggregierten Daten. Die Voraggregation ist noch nicht abgeschlossen. System für analytische Abfragen. Es gibt eine anfängliche SQL-Unterstützung, die jedoch gerade erst entwickelt wird. Zunächst mussten die Abfragen in einer Art JSON geschrieben werden. Von den interessanten Funktionen geben Sie ihm eine Anfrage und er schreibt Code für C ++ in Ihre Anfrage selbst. Dieser Code wird generiert, kompiliert, dynamisch geladen und verarbeitet Ihre Daten. Wie würde Ihre Anfrage so optimal wie möglich bearbeitet? Idealerweise spezialisierter C ++ - Code, der für Ihre Anfrage geschrieben wurde. Es gibt Skalierung und Consul wird für die Koordination verwendet. Dies ist auch ein Plus, wie Sie wissen, es ist cooler als ZooKeeper. Oder nicht. Ich bin mir nicht sicher, aber es scheint ja.
Einige der Prämissen, von denen dieses System ausgeht, sind etwas widersprüchlich. Ich bin ein großer Enthusiast verschiedener Technologien und möchte niemanden schelten. Dies ist nur meine Meinung, vielleicht irre ich mich.
Die Voraussetzung ist, dass ständig neue Daten im System aufgezeichnet werden, einschließlich rückwirkend vor einer Stunde, vor einem Tag, vor einer Woche. Führen Sie gleichzeitig sofort analytische Abfragen zu diesen Daten durch.

Der Autor behauptet, dass das System dafür notwendigerweise im Speicher sein muss. Es ist nicht so. Wenn Sie sich für das Warum interessieren, können Sie den Artikel „Entwicklung von Datenstrukturen in Yandex.Metrica“ lesen. Eine Person im Raum las.
Es ist nicht erforderlich, Daten im RAM zu speichern. Ich werde nicht sagen, was zu tun ist und welches System installiert werden muss, wenn Sie an der Lösung dieses Problems interessiert sind.

Was kannst du lernen? Eine interessante Architekturlösung ist die Codegenerierung in C ++. Wenn Sie sich für dieses Thema interessieren, können Sie einem solchen Forschungsprojekt DBToaster Aufmerksamkeit schenken. EPFL Institute Research, verfügbar auf GitHub, Apache 2.0. Scala-Code, Sie geben dort eine SQL-Abfrage, dieser Code generiert C ++ - Quellen für Sie, die Daten von irgendwoher optimal lesen und verarbeiten. Wahrscheinlich, aber nicht sicher.

Dies ist nur ein Ansatz zur Codegenerierung für die Abfrageverarbeitung. Es gibt einen noch populäreren Ansatz - die LLVM-Codegenerierung. Das Fazit ist, dass Ihr Programm sozusagen dynamisch Code in Assembler schreibt. Nun, nicht wirklich, auf LLVM. Es gibt MemSQL als Beispiel. Dies ist ursprünglich eine OLTP-Datenbank, eignet sich aber auch gut für Analysen. Geschlossenes, proprietäres C ++ wurde dort ursprünglich zur Codegenerierung verwendet. Dann wechselten sie zu LLVM. Warum? Sie haben C ++ - Code geschrieben, müssen ihn kompilieren und es dauert wertvolle fünf Sekunden, um dies zu tun. Und wenn Ihre Anforderungen mehr oder weniger gleich sind, können Sie den Code einmal generieren. Aber wenn es um Analysen geht, haben Sie dort Ad-hoc-Anfragen, und es ist durchaus möglich, dass sie jedes Mal nicht nur unterschiedlich sind, sondern sogar eine andere Struktur haben. Wenn die Codegenerierung auf LLVM erfolgt, dauert es Millisekunden oder zehn Millisekunden auf unterschiedliche Weise, manchmal auch länger.
Ein anderes Beispiel ist Impala. Verwendet auch LLVM. Wenn wir jedoch über ClickHouse sprechen, gibt es dort auch Codegenerierung, aber hauptsächlich stützt sich ClickHouse auf die Verarbeitung vektorieller Anforderungen. Ein Interpreter, der aber auf Arrays funktioniert, also sehr schnell funktioniert, wie Systeme wie kdb +.
Ein weiteres interessantes Beispiel. Das beste Logo in meiner Bewertung.

Das erste und einzige relationale Open-Source-Datenbankverwaltungssystem, das speziell für Data Warehousing und Business Intelligence entwickelt wurde. Verfügbar auf GitHub, der Apache 2-Lizenz. Früher gab es eine GPL, die jedoch geändert und korrekt ausgeführt wurde. Es ist in Java geschrieben. Letzte Verpflichtung vor sechs Jahren. Ursprünglich wurde das System von der gemeinnützigen Organisation Eigenbase entwickelt. Ziel der Organisation war es, ein Framework zu entwickeln, eine maximal erweiterbare Codebasis für Datenbanken, die nicht nur OLTP sind, sondern beispielsweise eine für Analytics, LucidDB selbst und die andere StreamBase für die Verarbeitung von Streaming-Daten.

Was ist vor sechs Jahren passiert? Gute Architektur, gut erweiterbare Codebasis, mehr als ein Entwickler. Tolle Dokumentation. Es wird jetzt nichts geladen, aber Sie können es über WebArchive sehen. Großartige SQL-Unterstützung.

Aber etwas stimmt nicht. Die Idee ist gut, aber dies wurde von einer gemeinnützigen Organisation für einige Spenden gemacht, und ein paar Startups waren in der Nähe. Aus irgendeinem Grund war alles verbogen. Sie konnten keine Finanzierung finden, es gab keine Enthusiasten und all diese Startups wurden vor langer Zeit geschlossen.
Aber nicht so einfach. Das alles war nicht umsonst.

Es gibt einen solchen Rahmen - Apache Calcite. Es ist eine Art Frontend für SQL-Datenbanken. Es kann Abfragen analysieren, analysieren, alle Arten von Optimierungstransformationen durchführen, einen Plan für die Ausführung von Abfragen erstellen und einen vorgefertigten JDBC-Treiber bereitstellen.
Stellen Sie sich vor, Sie sind plötzlich aufgewacht, hatten gute Laune und haben beschlossen, Ihr relationales DBMS zu entwickeln. Man weiß nie, es passiert. Jetzt können Sie Apache Calcite verwenden. Sie müssen nur noch Datenspeicherung hinzufügen, Daten lesen, Abfrageverarbeitung, Replikation, Fehlertoleranz, Sharding, alles ist einfach. Apache Calcite basiert auf der LucidDB-Codebasis, die ein so fortschrittliches System war, dass sie das gesamte Frontend von dort übernahm, das nun in einer angepassten Form in fast allen Apache-, Hive-, Drill-, Samza-, Storm-Produkten und sogar MapD verwendet wird es ist in C ++ geschrieben, irgendwie hat dieser Code in Java verbunden.

Alle diese interessanten Systeme verwenden Apache Calcite.
Das nächste System ist InfiniDB. Von diesen Namen schwindlig.

Es gab Calpont, ursprünglich InfiniDB, ein proprietäres System, und es war so, dass Vertriebsleiter unser Unternehmen kontaktierten und uns dieses System verkauften. Es war interessant, daran teilzunehmen. Sie sagen, dass ein analytisches DBMS, wunderbar, schneller als Hadoop, spaltenorientiert, natürlich alle Abfragen schnell funktionieren werden. Aber dann hatten sie keinen Cluster, das System skalierte nicht. Ich sage, dass es keinen Cluster gibt - wir können nicht kaufen. Ich sehe, nach einem halben Jahr, als die Version von InfiniDB 4.0 veröffentlicht wurde, haben wir die Integration mit Hadoop hinzugefügt, Skalierung, alles ist in Ordnung.
Sechs Monate sind vergangen und der Quellcode ist in Open Source verfügbar. Ich dachte dann, worauf ich saß und etwas entwickelte, wir müssen es nehmen, da ist etwas fertig.
Sie begannen zu überlegen, wie man sich anpasst, benutzt. Ein Jahr später ging das Unternehmen bankrott. Der Quellcode ist jedoch verfügbar.
Dies wird als Post-Mortem-Open-Source bezeichnet. Und das ist gut. Wenn sich ein Unternehmen nicht sehr wohl fühlt, muss zumindest ein Teil des Erbes erhalten bleiben, damit andere es nutzen können.

Es war alles umsonst. Basierend auf der InfiniDB-Quelle verfügt MariaDB jetzt über eine Tabellen-Engine namens ColumnStore. In der Tat ist dies InfiniDB. Das Unternehmen ist nicht mehr da, die Leute arbeiten jetzt an anderen Orten, aber das Erbe bleibt, und das ist wunderbar. Jeder kennt MariaDB. Wenn Sie es verwenden und die spaltenorientierte Analyse-Engine schnell befestigen müssen, können Sie ColumnStore verwenden. Im Geheimen werde ich sagen, dass dies nicht die beste Lösung ist. Wenn Sie die beste Lösung benötigen, wissen Sie, an wen Sie sich wenden und was Sie verwenden müssen.
Ein anderes System mit dem Wort Infini im Namen. Sie haben ein seltsames Logo, diese Linie scheint nach unten gebogen zu sein. Und noch eine unverständliche Schrift, aus irgendeinem Grund gibt es kein Antialiasing, als wäre es in Paint gemalt. Und alle Buchstaben sind groß, wahrscheinlich um Konkurrenten einzuschüchtern.

Ich bin ein Enthusiast aller Arten von Technologien, sehr respektvoll gegenüber allen Arten von interessanten Lösungen. Ich mache keine Witze, ich muss nicht nachdenken.
Wie war dieses System? Dies ist kein analytisches System mehr, sondern OLTP. Ein System zur Verarbeitung von Transaktionen in extremen Maßstäben. Es gibt eine Site. Der Vorteil dieses Systems besteht darin, dass die Site geladen wird. Denn wenn ich mir alle anderen ansehe, bin ich daran gewöhnt, dass es Domain-Parkplätze oder etwas anderes geben wird. Quellen sind verfügbar. Nun die GPL. Früher war es AGPL, aber zum Glück hat der Autor es schnell geändert. In C ++ geschrieben, mehr als ein Entwickler, im November 2013 auf Open Source veröffentlicht und bereits im Januar 2014 aufgegeben. Eineinhalb Monate. Warum? Welcher Sinn? Warum das?

OLTP-Datenbank mit anfänglicher SQL-Unterstützung, ein persönliches Projekt, kein Unternehmen steht dahinter. Der Autor selbst bei Hackers News sagt, dass er in Open Source gepostet hat, in der Hoffnung, Enthusiasten anzulocken, die an diesem Produkt arbeiten werden.

Diese Hoffnung ist immer zum Scheitern verurteilt. Sie haben eine Idee, Sie sind großartig, Sie sind ein Enthusiast. Also musst du diese Idee machen. Es ist unwahrscheinlich, dass sich jemand davon inspirieren lässt. Oder Sie müssen hart arbeiten, um jemanden zu inspirieren. Es ist also schwer zu hoffen, dass aus dem Nichts auf der anderen Seite der Welt eine Person auftaucht, die anfängt, den Code einer anderen Person auf GitHub hinzuzufügen.
Zweitens vielleicht nur die Komplexität unterschätzen. Die DBMS-Entwicklung ist 20 Minuten lang kein Abenteuer. Es ist schwierig, lang und teuer.
Dies ist ein sehr interessanter Fall, viele haben RethinkDB gehört. Dieses Beispiel ist keine analytische Basis, kein OLTP, sondern eine dokumentenorientierte.

Dieses System hat sein Konzept viele Male geändert. Überdenken. Angenommen, im Jahr 2011 wurde geschrieben, dass dies eine Engine für MySQL ist, die auf SSD hundertmal schneller ist, als sie auf der offiziellen Website geschrieben wurde. Dann wurde gesagt, dass dies ein System mit Memcached-Protokoll ist, das ebenfalls für SSD optimiert ist. Und nach einer Weile ist es eine Datenbank für Echtzeitanwendungen. Das heißt, um Daten zu abonnieren und Updates direkt in Echtzeit zu erhalten. Nehmen wir an, alle Arten von interaktiven Chats, Online-Spielen. Ein Versuch, eine Nische zu finden. Dokumentorientiertes System, JSON-Datenmodell. MongoDB. . MongoDB , ? MongoDB . , , «PostgreSQL ».
? — . . , .
RethinkDB? , RAFT. , , , . JSON, - LINQ . ReQL, ++, , ++.

. . , , , , . , , . 20938 GitHub. - .

, , , , , . Warum? Was ist los?

, 2009 , , , . , , 2016 . , , , . , , RethinkDB, , , The Linux Foundation. AGPL Apache 2, . , — .

, , , , , , . , .
, , . , - , , , , .
. , , . , XML 15 .
- , 2000-, . , XML . - - , . , .

, Sedna. XML , . , . , . , Sedna, , , , . , .
2013, , . XML , , .
— .
— , , . garret.ru, , . , . , , , . .

. 2014 — IMCS, PostgreSQL, . PostgreSQL, SQL, , . select, . -, . , , , . , . , , , - . , .
, - ? .

, , ? , — . : , - , . , . .
— . , , . , , .
— . , -. - , — , , , -.
, , , .
— , ? , - .
, , . . , , , .
— - - . -, KPHP.
— . , , , .

, , : , , , ? — . , . , . ? : , .
. , , . , .
. , - , , multimodel DB, , , OLTP, , , , . , ? , , - . - -, , , , . , .
Zuverlässige Unterstützung der Muttergesellschaft. Es gibt keine Kommentare. Keine restriktive Lizenz, damit andere Unternehmen die Rechtsabteilung nicht erschrecken, haben diese Leute Angst vor allem. Die Vorteile Ihres Systems sollten grundlegende Gründe haben. Wenn Sie eine Datenbank für die XML-Verarbeitung haben, ist dies irgendwie nicht sehr gut. Möglicherweise muss niemand anderes Daten in XML speichern. Und wenn Sie eine dokumentenorientierte Datenbank haben, ist das eine andere. Jeder muss Dokumente aufbewahren, und egal was genau. Darüber hinaus ist die Unterstützung der Community-Entwicklung für eine gute Open Source sehr wichtig. Dies bedeutet nicht nur, dass Sie Pull-Anforderungen halten müssen. Das bedeutet - Sie brauchen Menschen, die sich fühlen, Sie existieren, Fragen beantworten, das Produkt entwickelt sich. Dies ist es, was eine gute und lebendige Open Source ausmacht. Das ist alles, danke.