Vor einigen Monaten haben wir uns in einer der Retrospektiven entschlossen, gemeinsam zu lesen.
Unser Format:
- Wähle ein Buch.
- Wir bestimmen den Teil, der in einer Woche gelesen werden muss. Wählen Sie ein kleines Volumen.
- Am Freitag diskutieren wir, was wir lesen.
- Wir lesen außerhalb der Arbeitszeit, diskutieren während der Arbeitszeit.
- Nach Abschluss des Buches wählen wir gemeinsam Folgendes aus.
Was gibt:
- Motivation zum Lesen und Lesen.
- Entwicklung von Fähigkeiten (auch für die Zukunft).
- Ausrichtung von Denkweise und Terminologie in einem Team.
- Das Wachstum des Vertrauens.
- Ein weiterer Grund zum Reden.
Eines der jüngsten Bücher, die wir lesen, ist das
Entwerfen datenintensiver Anwendungen . Ja, das gleiche Buch mit einem Schwein. Und alle mochten dieses Buch so sehr, dass ich mich entschied, es hier zu rezensieren, damit mehr Leute es lesen.
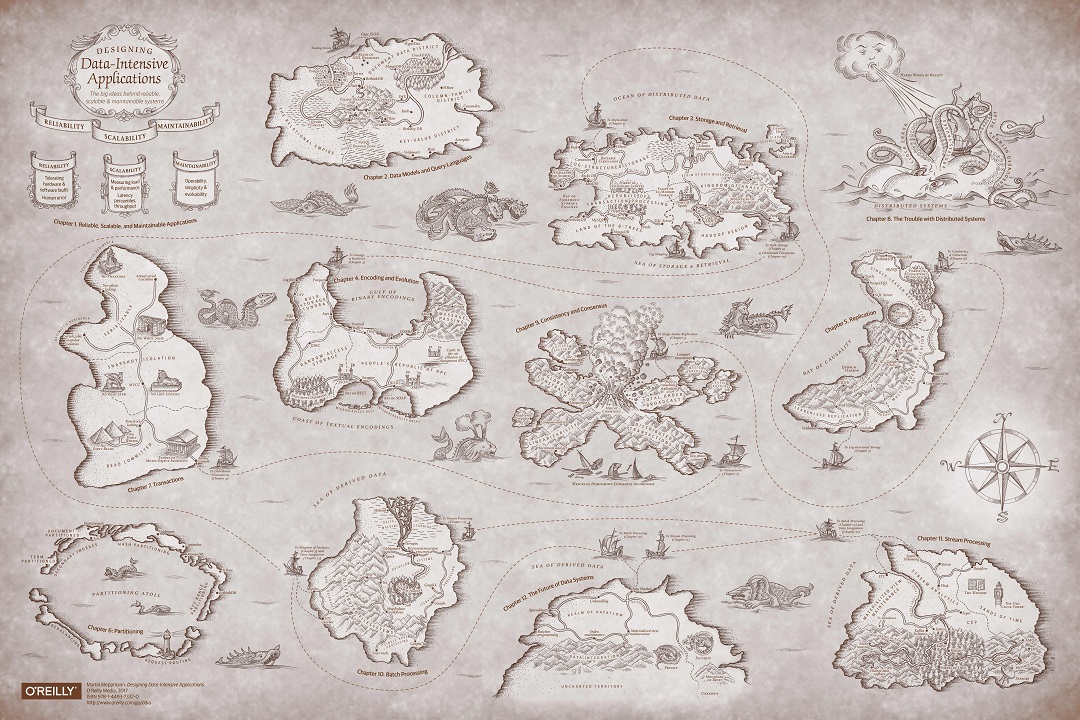 Karte in Originalqualität
Karte in OriginalqualitätEs gibt eine Übersetzung dieses Buches ins Russische vom Verlag Peter. Aber wir lesen im Original, deshalb verspreche ich nicht, dass die Übersetzungen der Begriffe übereinstimmen. Darüber hinaus haben wir einen Teil der Begriffe bewusst nicht übersetzt.
Der erste Teil des Buches ist den Grundlagen von Datenverarbeitungssystemen gewidmet.
Das erste Kapitel zeigt, dass wichtige Eigenschaften solcher Systeme Zuverlässigkeit, Skalierbarkeit und Wartungsfreundlichkeit sind.
Das zweite Kapitel beschreibt verschiedene Datenmodelle. Die üblichen relationalen und dokumentenorientierten DBMS sowie weniger bekannte Diagramm- und Spaltendatenbanken werden beschrieben.
Die ersten Kapitel sind aktuell, legen den Umfang des Buches fest. An vielen Stellen unten verweist der Autor auf die ersten Kapitel. Fairerweise können wir sagen, dass das Buch voller Querverweise ist.
Was von den ersten Kapiteln an überraschend ist, ist die Anzahl der Quellen (nach jedem Kapitel gibt es eine Bibliographie). Links zu Dutzenden von Artikeln (sowohl Blogs als auch wissenschaftlichen) und Büchern sind in allen Kapiteln sorgfältig angeordnet. Die Anzahl der Quellen für einige Kapitel übersteigt hundert.
Das dritte Kapitel beginnt mit dem Quellcode des einfachsten Schlüsselwertspeichers:
Es wird sogar funktionieren, sehr gut schreiben, aber natürlich nicht ohne Leseprobleme.
Und sofort werden Optionen zur Leistungsverbesserung angeboten. Beschreibt die Hash-Indizes SSTable, B-Tree und LSM-Tree. All dies wird an den Fingern erklärt, aber es wird gezeigt, wie diese oder jene Struktur in den bekannten Datenbanken verwendet wird.
Der Fokus auf die Praxis ist ein weiteres Kennzeichen des Buches. Die meisten Beispiele und Rezepte sind so praktisch, dass ich auf fast alles Relevante gestoßen bin.
Das
vierte Kapitel beschreibt die Codierung: von regulärem JSON und XML bis zu Protobuf und AVRO. Wir wählen das Format nicht immer bewusst aus, es wird normalerweise von der einen oder anderen Technologie als Ganzes auferlegt. Aber es ist cool zu verstehen, wie es im Inneren funktioniert, was die Stärken und Schwächen des Formats sind.
Der Autor hat den Begriff Serialisierung nicht speziell verwendet, da dieser Begriff in Datenbanken eine weitere Bedeutung hat.
Der Inhalt der Kapitel ist viel umfangreicher als meine kurze Präsentation. Der erste Teil beschreibt auch die Unterschiede zwischen OLTP und OLAP, wie die Volltextsuche und -suche in Spaltendatenbanken, REST und Nachrichtenbrokern angeordnet sind.
Der zweite Teil des Buches befasst sich mit verteilten Datenverarbeitungssystemen. Fast alle modernen Systeme, die mehr oder weniger ausgelastet sind, verfügen über mehrere Replikate oder Subsysteme (Microservices).
Als wir anfingen, gemeinsam zu lesen, diskutierten wir einfach unsere Notizen, interessanten Orte und Gedanken. Irgendwann stellten wir fest, dass wir einfach nicht genug Gespräche hatten, nach der Diskussion ist alles schnell vergessen. Dann beschlossen wir, unsere Praxis zu stärken und fügten eine Mind-Map-Füllung hinzu. Innovation hatte genau dieses Buch. Ab dem zweiten Teil haben wir begonnen, für jedes Kapitel eine Mind Map zu erstellen. Daher wird jedes Kapitel mit unserer Mind Map weitergeführt. Wir haben coggle.it verwendet
Das fünfte Kapitel beschreibt die Replikation.
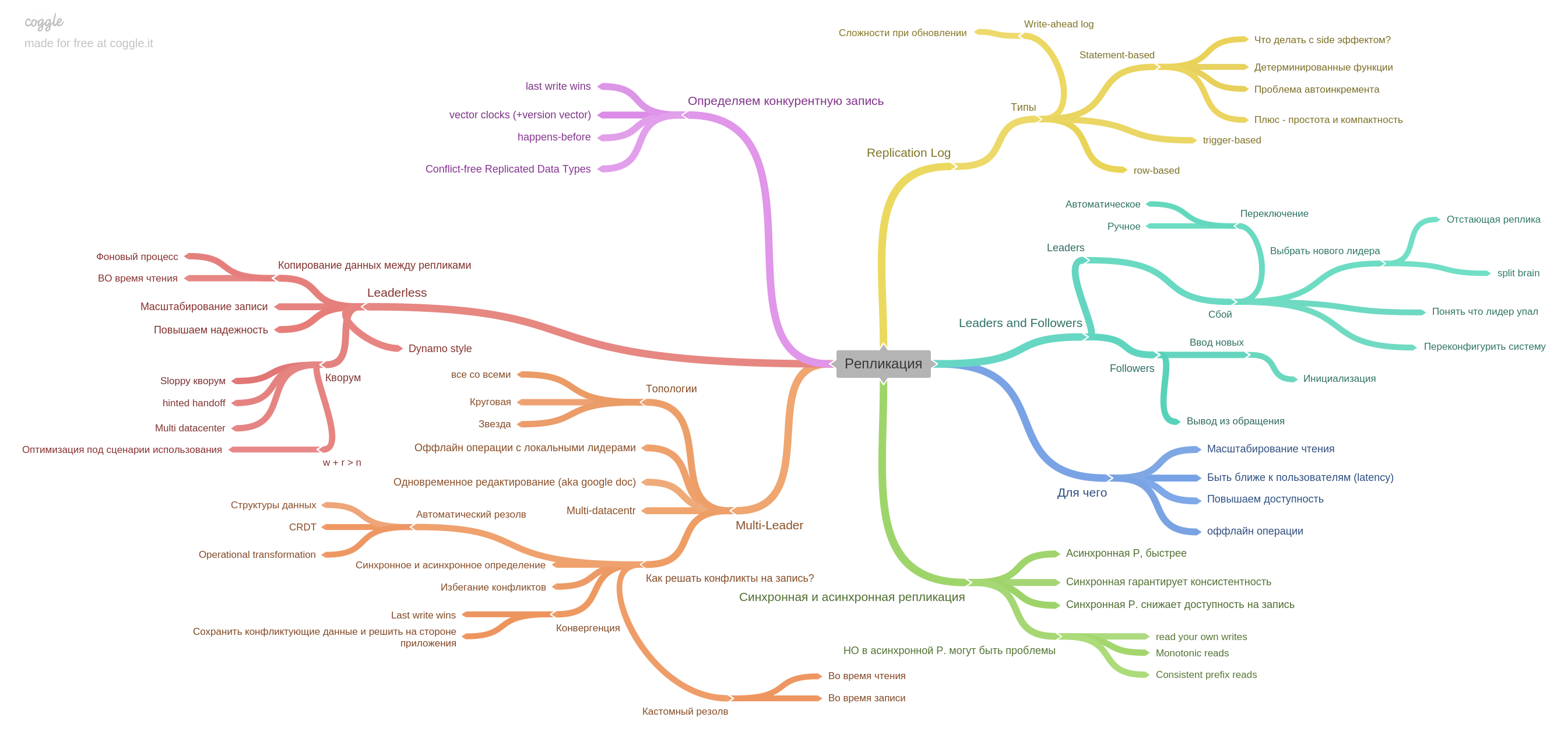
Hier werden alle grundlegenden Informationen zu Replikaten gesammelt: Single-Master, Multimaster, Replikationsprotokoll und wie man mit einem Wettbewerbsrekord in führerlosen Systemen lebt.
Das sechste Kapitel beschreibt die Partitionierung (auch bekannt als Sharding und eine Reihe anderer Begriffe).
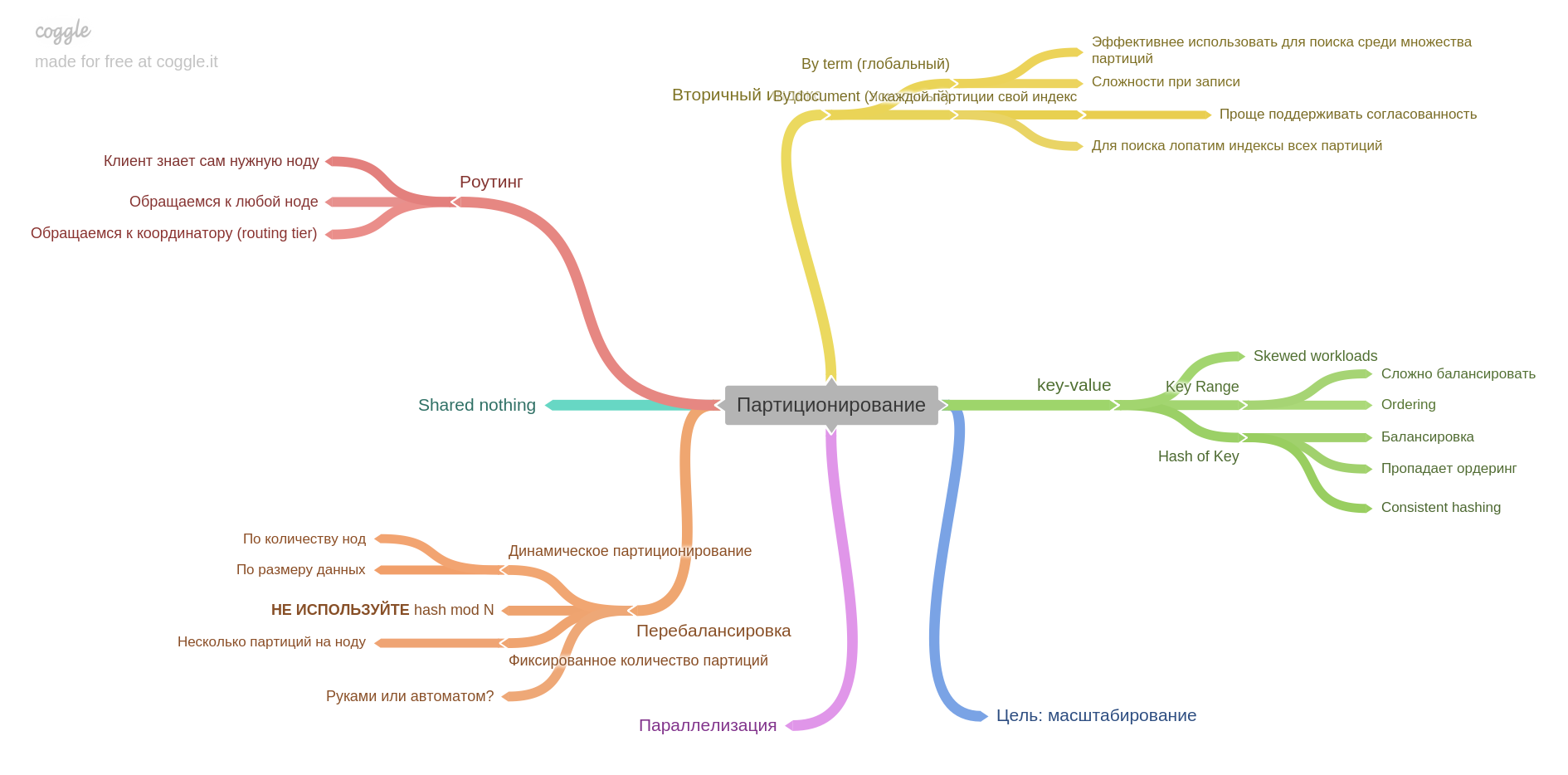
Sie lernen, wie Sie Daten in Shards aufteilen, welche Probleme gelöst werden können und welche zu erhalten sind, wie Sie Indizes erstellen und Daten ausgleichen.
Siebtes Kapitel : Transaktionen.
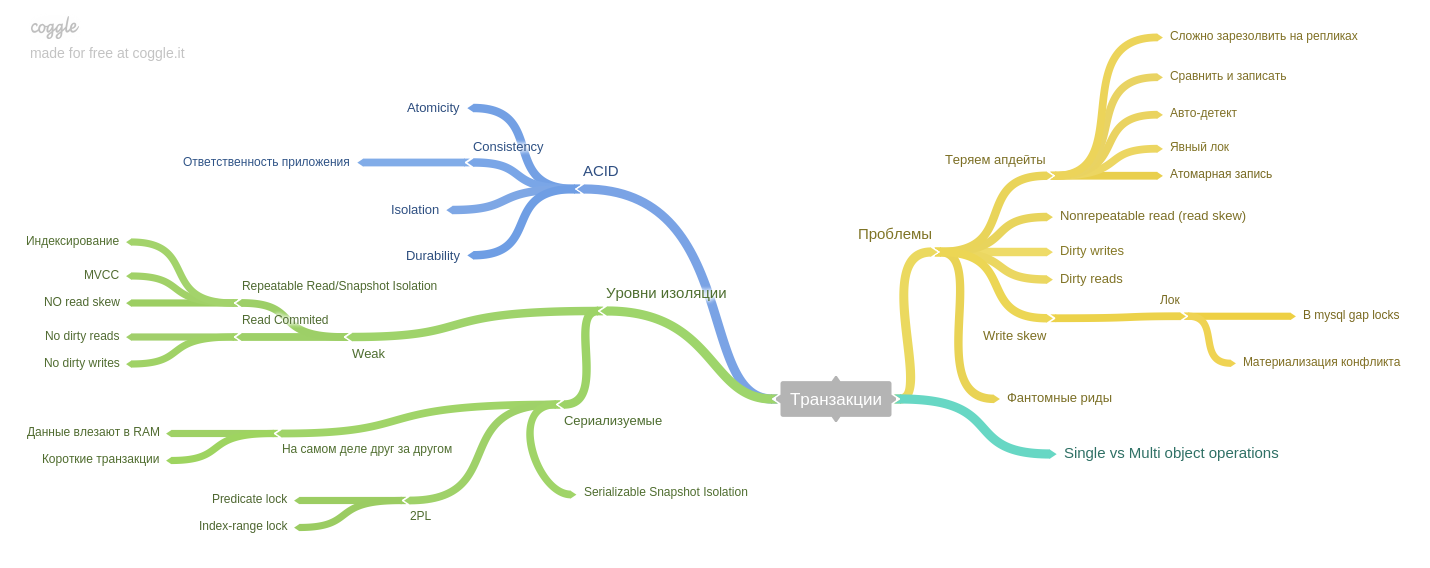
Die Phänomene (Leseversatz, Schreibversatz, Phantomlesevorgänge usw.) werden beschrieben und wie die Isolationsstufen von Datenbanken im ACID-Stil dazu beitragen, Probleme zu vermeiden.
Das achte Kapitel: Über Probleme, die für verteilte Systeme spezifisch sind.
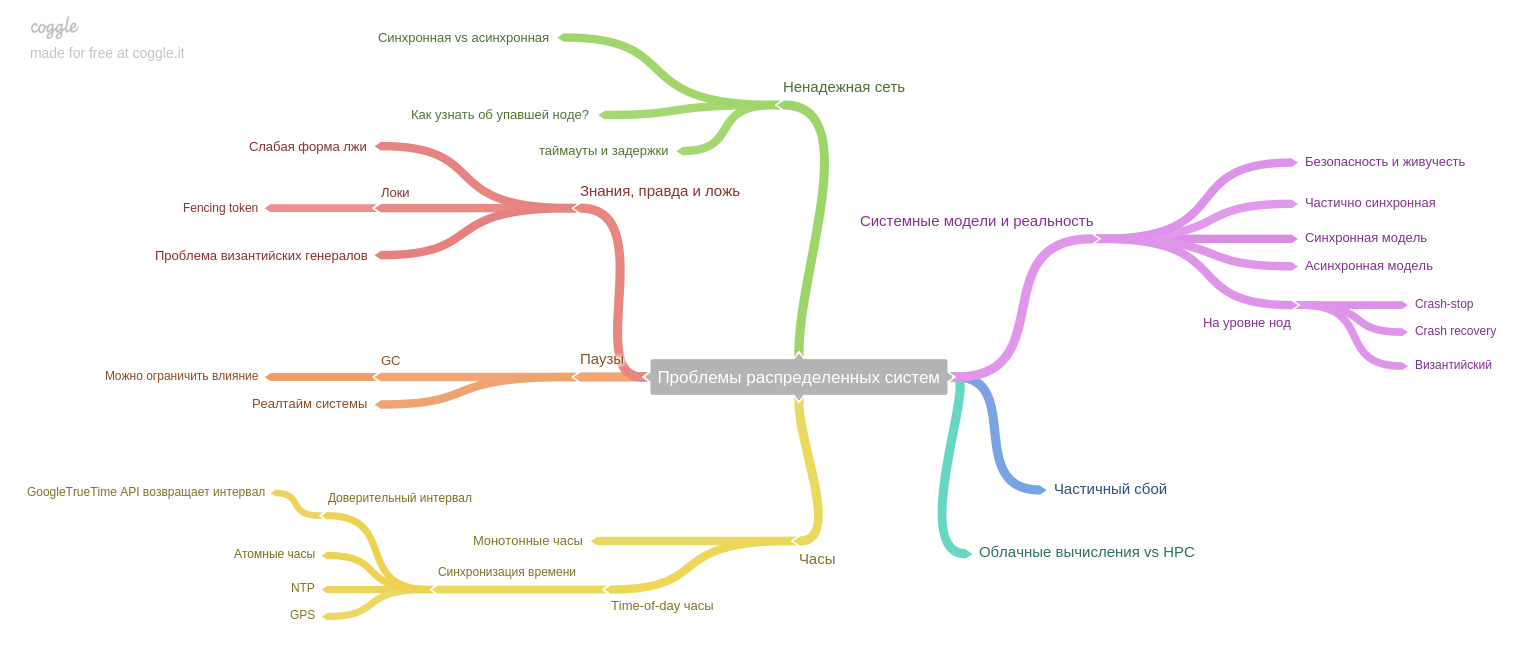
Der Autor betont eine wichtige Idee: Wenn das System früher auf einem Computer arbeitete und im Fehlerfall das gesamte System nicht mehr funktionierte (und neue Daten akzeptierte). Somit blieben die Daten nach Ausfällen in einem konsistenten Zustand, aber heute, im Zeitalter von Replikaten und Mikrodiensten, wird nur ein Teil des Systems heruntergefahren. Daher stehen wir vor einem neuen Problem: Sicherstellung der Datenkonsistenz unter den Bedingungen eines teilweisen Ausfalls, anhaltender Probleme mit einem unzuverlässigen Netzwerk usw.
Das neunte Kapitel beschreibt Kohärenz und Konsens und führt ein wichtiges Konzept ein: Linearisierbarkeit. Ich erinnere mich, dass der Kopf hart hereinkam und in meinen Kopf passte.
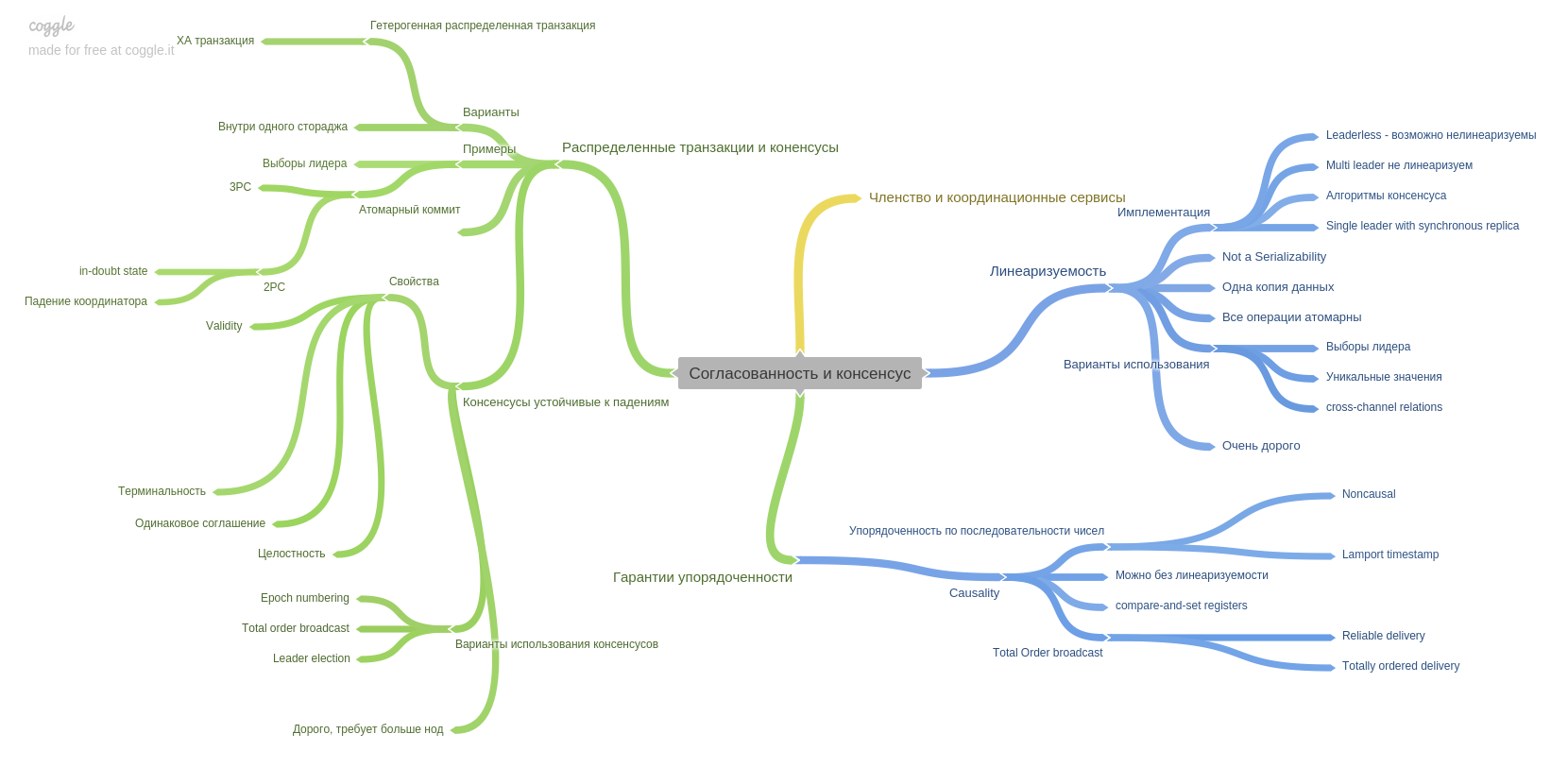
In diesem Kapitel werden auch die Zwei-Phasen-Festschreibungstechnik und ihre Schwachstellen beschrieben. Auch in diesem Kapitel erfahren Sie mehr über Ordnungsgarantien. Wie und was moderne Systeme Ihnen bieten können.
Der dritte Teil des Buches ist abgeleiteten Daten gewidmet (es gibt keine etablierte Übersetzung). Infolgedessen äußert der Autor die Idee, dass alle Indizes, Tabellen und materialisierten Ansichten nur ein Cache über dem Protokoll sind. Nur das Protokoll enthält die relevantesten Daten, alles andere ist zu spät und wird der Einfachheit halber verwendet.
Das zehnte Kapitel.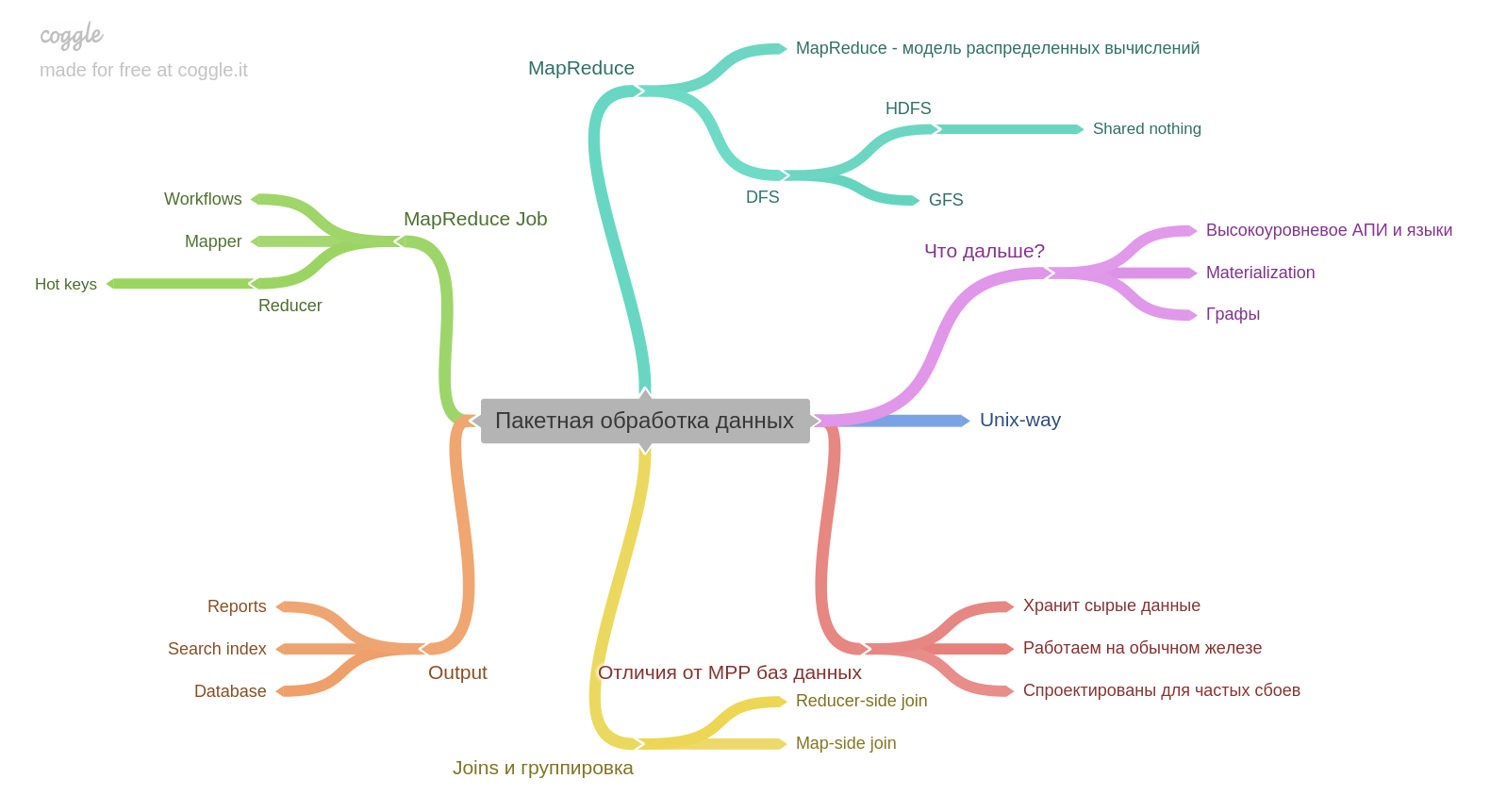
Wenn Sie Erfahrung mit Hadoop oder MapReduce haben, werden Sie vielleicht wenig Neues lernen. Aber ich habe nicht gearbeitet und es war sehr interessant. Ein wichtiger Punkt für mich - das Ergebnis der Stapelverarbeitung an sich kann die Basis für eine andere Datenbank werden.
Kapitel 11. Streaming-Datenverarbeitung.
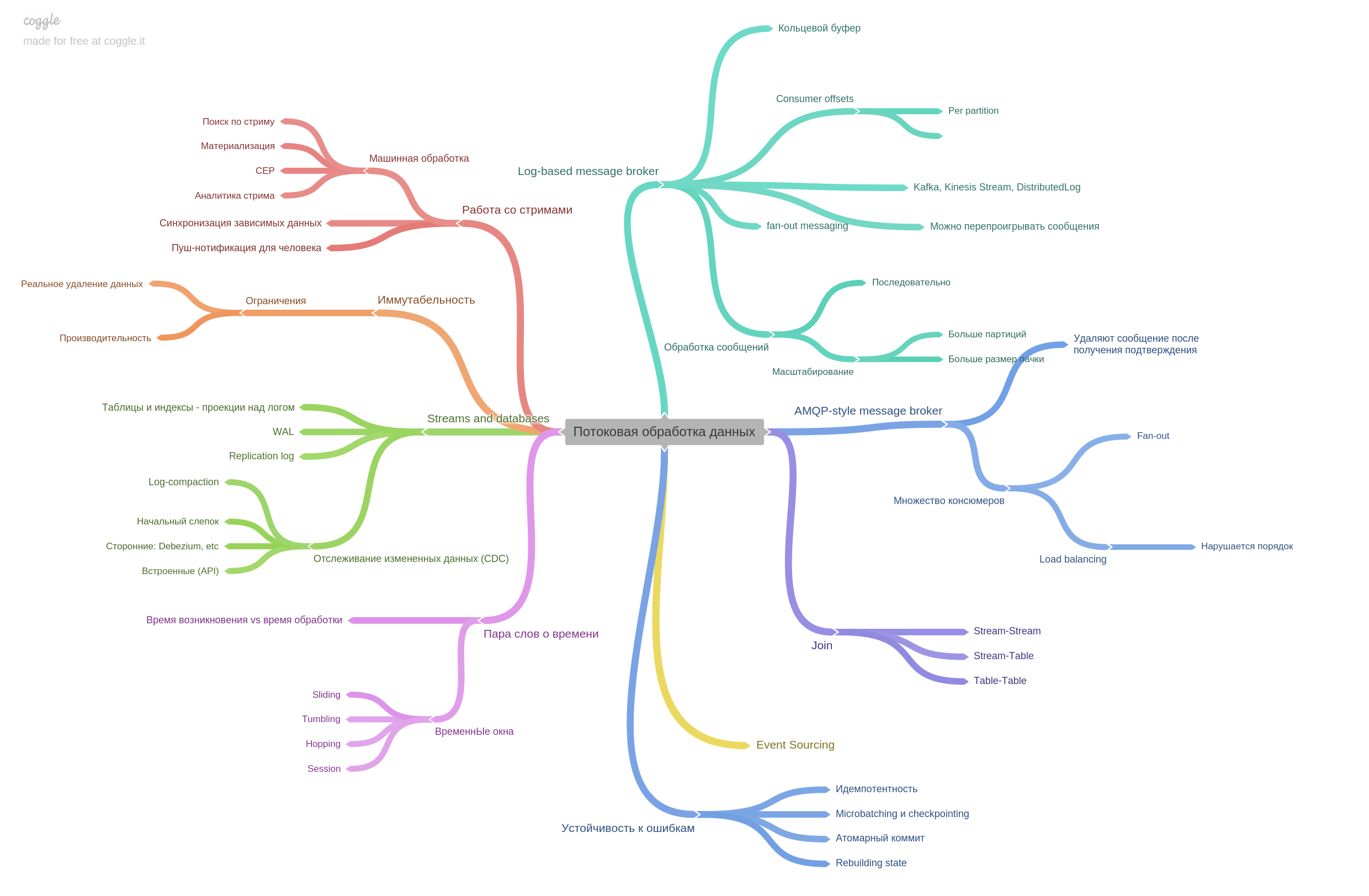
Nachrichtenbroker werden beschrieben und wie sich der AMPQ-Stil vom protokollbasierten unterscheidet. Tatsächlich enthält das Kapitel viele andere Informationen. Es war sehr interessant zu lesen.
Das letzte Kapitel handelt von der Zukunft. Was zu erwarten ist, womit sich die Gedanken von Forschern und Ingenieuren bereits beschäftigen.
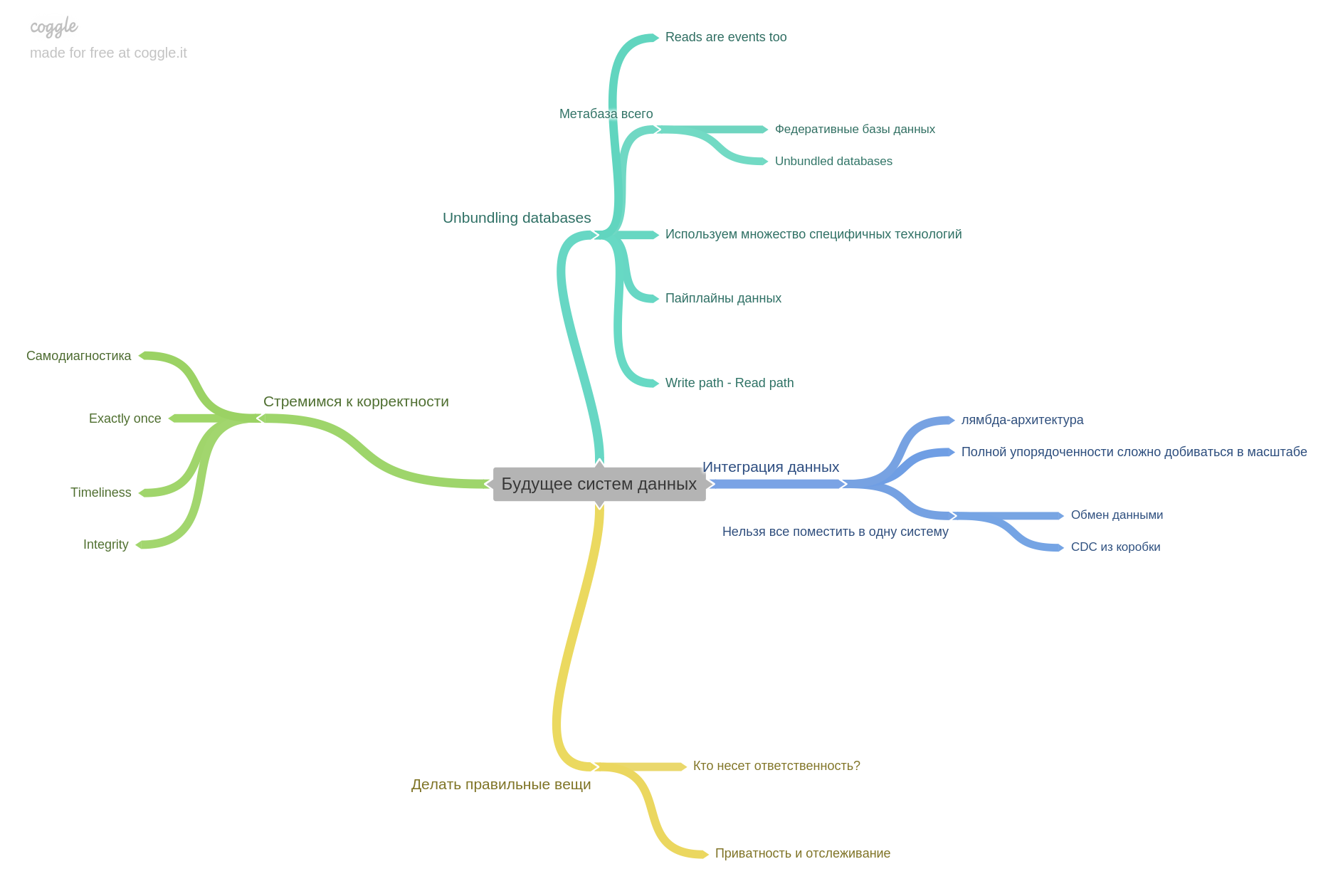
Damit ist meine Überprüfung abgeschlossen. Es ist wichtig zu verstehen, dass ich für jedes Kapitel nur einen Teil der Thesen gemacht habe. Das Buch hat einen so dichten Inhalt, dass es nicht möglich ist, es kurz, sondern vollständig nachzuerzählen.
Persönlich denke ich, dass dieses Buch das beste technische in den letzten Jahren ist. Ich kann es nur empfehlen. Und nicht nur lesen, sondern hart arbeiten. Folgen Sie den Links aus der Bibliographie und spielen Sie mit echten DBMS.
Nachdem Sie dieses Buch gelesen haben, können Sie viele Fragen in einem Interview mit einer technischen Datenbank leicht beantworten. Aber das ist nicht der Punkt. Als Entwickler werden Sie cooler, kennen die interne Struktur, die Stärken und Schwächen verschiedener Datenbanken und denken über die Probleme verteilter Systeme nach.
Ich bin bereit, in den Kommentaren sowohl das Buch selbst als auch unsere Praxis des gemeinsamen Lesens zu diskutieren.
Bücher lesen!