Ja, ich bin auch ein Idiot. Aber das habe ich nicht von mir erwartet. Es scheint "nicht das erste Jahr verheiratet zu sein". Es scheint eine Reihe von intelligenten Artikeln über Fehlertoleranz, Redundanz usw. zu lesen, etwas Vernünftiges, das einmal selbst hier geschrieben wurde. Seit über 10 Jahren bin ich CEO eines Hosting-Anbieters, der unter der Marke
ua-hosting.company tätig ist und Hosting- und Serververmietungsdienste in den Niederlanden, den USA und vor einer Woche in Großbritannien anbietet (fragen Sie nicht, warum der Name ua, die Antwort
in unserem autobiografischen Artikel zu finden ist ) bieten wir unseren Kunden Lösungen mit unterschiedlichem Komplexitätsgrad, manchmal so, dass selbst wir selbst schwer zu verstehen sind, was wir getan haben.
Aber verdammt ... Heute habe ich mich selbst übertroffen. Wir selbst haben die Website und die Abrechnung mit allen Transaktionen, Kundendaten über Dienstleistungen und anderen Dingen vollständig abgerissen, und es war meine Schuld, dass ich selbst "Löschen" sagte. Einige von Ihnen haben dies bereits bemerkt. Es geschah heute, Freitag um 11:20 Uhr Eastern Standard Time (EST). Darüber hinaus wurden unsere Website und die Abrechnung nicht auf demselben Server gehostet, und auch nicht in der Cloud haben wir die Cloud des Rechenzentrums vor zwei Monaten zugunsten unserer eigenen Lösung verlassen. All dies befand sich auf einem fehlertoleranten Geo-Cluster aus zwei virtuellen Servern - unserem neuen Produkt
VPS (KVM) mit dedizierten Laufwerken ,
INDEPENDENT VPS, das sich auf zwei Kontinenten befand - in Europa und den USA. Einer in Amsterdam und der andere in Manassas in der Nähe von Washington, weil DC in zwei zuverlässigen Rechenzentren. Inhalte, auf denen ständig und in Echtzeit dupliziert wurde und deren Fehlertoleranz auf dem üblichen DNS-Cluster basiert, konnten Anfragen an jeden der Server senden, von denen jeder als MASTER diente, und im Falle einer Unzugänglichkeit übernahmen sie die Aufgaben des zweiten.
Ich dachte, dass dies nur einen Meteoriten töten kann, oder etwas anderes, das dem globalen ähnlich ist und zwei Rechenzentren gleichzeitig deaktivieren kann. Aber alles stellte sich als einfacher heraus.
Wir können es sein, wir, wenn wir Idioten sind. In der Welt gibt es nur zwei unbegrenzte Dinge - das Universum und die menschliche Dummheit, und wenn das erste umstritten ist, ist das zweite offensichtlich geworden.
Ich habe mich immer an das Prinzip der Soundredundanz gehalten. Ich gehöre nicht zu den Leuten, die rufen: "Ich verliere 1000 Dollar für eine Stunde Inaktivität", aber gleichzeitig zahle ich 15 Dollar für meine gesamte Infrastruktur. Nein, ich verliere bestimmt nicht so viel. Obwohl ich vielleicht manchmal verliere. Die meisten Idioten, die darüber schreien, glauben nicht einmal, dass Ausfallzeiten pro Sekunde auf lange Sicht manchmal 1.000, 10.000 oder sogar eine Million Dollar Gewinn kosten können. Auf welche Weise? Es ist sehr einfach, in diesem Moment kann ein Kunde hereinkommen, der seine erste Bestellung aufgibt und Ihnen in Zukunft diese Millionen von Dollar bringt, weil Sie immer die Möglichkeit haben, ihm Ihre Einzigartigkeit zu beweisen und seine Empfehlung zu verdienen. Und wenn er den Fehler 504 oder "Es tut mir leid, aber der Server ist derzeit nicht verfügbar" sieht, findet die Transaktion möglicherweise nicht statt. Dies ist uns passiert, nein, kein 504-Fehler beim Anruf eines wichtigen Besuchers, sondern der erste. Rein zufällig befand ich mich zur richtigen Zeit am richtigen Ort, als große Kunden wie Dmitry Sukhanov, der Erfinder von Kinopoisk, unsere Website besuchten, obwohl dies kein sehr gutes Beispiel ist, da er nur 2 Jahre mit uns zusammengearbeitet hat Yandex kaufte es nicht für 60 Millionen Dollar oder wie viel dort. Es war also eher Dmitry als wir, der die Millionen hierher brachte, aber wir waren froh, mit einem so interessanten und nützlichen Projekt zusammenzuarbeiten, und dies machte uns wiederum zu einer Werbung und bot viele neue und zufriedene Kunden.
Im Allgemeinen, warum bin ich das alles. Verluste und die notwendige Redundanz sollten sinnvoll bewertet werden. Obwohl das Risiko besteht, eine Million Dollar zu verlieren, müssen Sie die Wahrscheinlichkeit eines solchen Ereignisses prüfen. Wenn Dmitry einen Zeitfehler 504 gesehen hätte, wäre höchstwahrscheinlich nichts Kritisches passiert, und er wäre wieder zu uns zurückgekehrt. Warum? Zu dieser Zeit waren wir wahrscheinlich einer der wenigen, die in der Ukraine eine Konnektivität von mehr als 1 Gbit / s mit hoher Qualität und minimaler Latenz zu günstigen Preisen anbieten konnten, was für ihre damalige Ressource äußerst wichtig war, um dem ukrainischen Publikum einen qualitativ hochwertigen Zugang zu gewährleisten Portal, da der Auslandsverkehr von schlechter Qualität und immer noch teuer war. Daher ist es wichtig, die Einzigartigkeit der Lösung sicherzustellen, da die Verfügbarkeit für Sie nicht sehr kritisch ist. Und da wir einzigartig sind, können wir uns (auch jetzt noch) mit Tausenden von Server-Clients erlauben, mehrere Stunden oder sogar länger im Leerlauf zu sein. Wir brauchen keine mega-fehlertoleranten Wolken, die eine Betriebszeit von 99,9999% für viel Geld bieten, denn selbst wenn sie fallen, und wenn sie fallen, hat die Praxis sie sehr lange gezeigt, da das Problem, das die Unzugänglichkeit verursacht hat, wahrscheinlich nicht gewöhnlich ist. Und sie werden im Falle einer Verwundbarkeit nicht helfen. Sie werden nicht helfen.
Deshalb haben wir unsere Entscheidung für uns selbst sehr einfach getroffen. Wir haben zwei VPS (KVM) auf den Dell R730xd-Knoten verwendet, denselben VPS (KVM), den wir unseren Kunden anbieten, da dies unser ursprüngliches Prinzip ist - Menschen das zu geben, was wir selbst verwenden:
VPS (KVM) - 2 x Intel Dodeca-Core Xeon E5-2650 v4 (24 Kerne) / 40 GB / 4 x 240 GB SSD RAID10 / Datatraffic - 40 TB - ab 99 USD / Monat. Wenn Sie eine Promo finden, erhalten Sie
30% Rabatt auf die erste Zahlung Code in unserem
Werbeartikel .
Eine in den Niederlanden und eine in den USA. Ja, auf diesen Knoten gibt es neben unserer Site und der Abrechnung zwei weitere echte Kunden, von denen jeder den Betrieb unserer Site theoretisch beeinflussen kann und dies in der Praxis nicht kann. Warum - es steht in einem Werbeartikel, ich werde hier kein zweites Mal auf Details eingehen. Hier geht es nicht darum. Im Allgemeinen ist die Lösung nicht schlechter als dedizierte Einstiegsserver und kann eine sehr große Last bewältigen.
Es ist unter anderem fehlertolerant, Daten werden ständig in Echtzeit repliziert. Und wenn ein Server nicht verfügbar ist, übernimmt der zweite die MASTER-Rolle. Im Idealfall können Sie dafür sorgen, dass der Datenverkehr vom amerikanischen Kontinent vom amerikanischen Server und von Europa, Russland und Asien - dem Server in den Niederlanden - verarbeitet wird.
Wir haben die Server in unserem Rechnungs-WHMCS, einem öffentlich lizenzierten Produkt, das für uns angepasst wurde und von vielen Hosting-Anbietern auf der ganzen Welt, einschließlich uns, verwendet wird, in unser Konto eingebunden, da das Schreiben unseres eigenen Buchhaltungssystems (in unserem Fall) eine offene Schwäche darstellt. . Insbesondere in Fällen, in denen die gewünschte Funktion implementiert wird, indem Sie Ihr eigenes Modul in die vorhandene Abrechnung schreiben, was Ihre Fehlertoleranz erhöht, da das Risiko kritischer Schwachstellen verringert wird. Schließlich können Sie allein oder sogar mit einem kleinen Team kein zuverlässigeres System schreiben als das bestehende, das im Laufe der Jahre von einer Gruppe von Entwicklern geschrieben wurde, bei denen bereits Tausende von Fehlern behoben wurden und für die Entwickler jetzt nur 30 US-Dollar pro Monat für eine Lizenz verlangen und Millionen von Dollar pro Jahr erhalten das kann auch für weitere Verbesserungen ausgegeben werden.
In Bezug auf kritische Sicherheitslücken hat unser Programmierer kürzlich einen Fehler beim Schreiben eines der Servicemodule gemacht, das Zugriff auf eine schreibgeschützte Abrechnungsdatenbank hatte, die von einem unabhängigen Pentester entdeckt wurde und uns aufforderte, 550 US-Dollar für einen gefundenen Fehler zu zahlen, da es sich um eine SQL-Sicherheitslücke handelte -Injektion:
SQL-Injection gehört zu den Top 10 OWASP. Ich habe Ihnen über den Betrag von 550 US-Dollar geschrieben. Dies ist der Mindestbetrag, da die Datenbank darunter leidet und dadurch die Benutzerdaten gefährdet.
Einige Beträge belaufen sich jedoch auf bis zu 10.000 US-Dollar als Belohnung, wie dies bei vk.com der Fall ist.
Natürlich haben wir diesen Anfang unterstützt und ohne Frage eine Entschädigung gezahlt. Da unser Programmierer die zur Verfügung gestellten Daten prüfte und das Vorliegen eines Problems bestätigte, Begründung des Pentesters. Schließlich unterhalten wir noch keinen eigenen Pentester im Staat, und diese Arbeit erfordert beträchtliches Wissen und Zeit, da sie eine Reihe von Studien umfasst:
Sicherheitsüberprüfung der gesamten Ressource, und dies ist eine Überprüfung gemäß den folgenden Parametern, und unser Bericht am Ende der Prüfung enthält:
• A1-Code-Injektion
• A2 Falsche Authentifizierung und Sitzungsverwaltung
• A3 Crossite-Skripte
• A4-Zugriffsverletzung
• A5 Unsichere Konfiguration
• A6 empfindliches Datenleck
• A7 Unzureichender Angriffsschutz
• A8 Fälschung von standortübergreifenden Anfragen
• A9 Verwenden von Komponenten mit bekannten Schwachstellen
• A10 Unzureichende Protokollierung und Überwachung
Denn ja, die Entscheidung wurde eindeutig und schnell getroffen. Darüber hinaus erhöhen solche Studien, wie Pentester feststellte, die Sicherheit des gesamten Web:
Dies ist mein Hobby. Wenn jeder Entwickler wie Sie einen Dialog mit Bug-Jägern führen würde, wäre das Internet zu 80% sicher.
Daher haben wir im Großen und Ganzen einiges bezahlt, insbesondere wenn wir den Betrag durch die Anzahl der Monate dividieren, in denen der für Penetrationstests verantwortliche Mitarbeiter nicht im Personal beschäftigt war. Vielen Dank an den Pentester für den gefundenen Fehler und die Tatsache, dass er sich die Zeit für uns genommen hat. Wir sind ihm wirklich sehr dankbar. Wenn jemand seine Dienste benötigt, wenden Sie sich bitte an, wir werden Kontakte mit seiner Erlaubnis zur Verfügung stellen.
Aber diesmal war es nicht die Verwundbarkeit, die uns getötet hat. Es waren wir und das Merkmal des WHMCS-Produkts. In jedem Fall haben wir ein praktisches Produkt zur Verwaltung virtueller Container installiert - VM Manager, auf das WHMCS zugreifen kann, um den erstellten virtuellen Container zu erstellen, anzuhalten und zu löschen sowie Clients.
Jeden Tag erhalten wir bei WHMCS Dutzende oder sogar Hunderte von Bestellungen, die angenommen (angenommen), gelöscht oder als Betrug gekennzeichnet werden müssen, wenn der Kunde versucht, eine Bestellung mit einer gestohlenen Kreditkarte zu bezahlen. Manchmal gibt es einen Boom solcher Bestellungen und wir können nicht sofort bestimmen, welchen Status wir ihm zuweisen sollen, da wir unsere interne Überprüfung durchführen oder den Benutzer auffordern, sich ordnungsgemäß zu identifizieren, wenn wir seine Bestellung als verdächtig empfinden, und diese Benutzer natürlich nicht immer antworten oder bestehen Identifizierung erfolgreich. Daher sammeln sich von Zeit zu Zeit tausend oder zwei nicht aktivierte Bestellungen oder Bestellungen mit unbekanntem Status an, die leichter zu löschen als zu verarbeiten sind. Wer muss wirklich - nachbestellen.
Vor zwei Monaten haben wir uns entschlossen, das Cloud-basierte Rechenzentrumsprodukt vollständig aufzugeben, als wir begannen, unsere eigene Lösung mit VM Manager bereitzustellen, mit der Sie das System mit einem Klick oder sogar von Ihrem Image aus erstellen können:

Und sie haben es sogar auf NVMe PCIe-SSDs angeboten, die eine Größenordnung schneller sind als normale SSDs zum Lesen und bis zu dreimal zum Schreiben. Die Lösung muss wie die Cloud-Version aktualisiert werden, die Server kosten ab 15 US-Dollar und enthalten ein praktisches VM Manager- und ISP Manager-Control Panel 5 auf Anfrage kostenlos, Support-Upgrade mit einem Mindestschritt von 5 GB DDR4-RAM, 60 GB NVMe PCIe SSD und 3 Core E5-2650 v4
auf einen höheren Tarif in Amsterdam, Manassas und London:
VPS (KVM) - E5-2650 v4 (3 Kerne) / 5 GB DDR4 / 60 GB NVMe SSD / 1 Gbit / s 5 TB - 15 USD / Monat
VPS (KVM) - E5-2650 v4 (6 Kerne) / 10 GB DDR4 / 120 GB NVMe SSD / 1 Gbit / s 10 TB - 30 USD / Monat
VPS (KVM) - E5-2650 v4 (9 Kerne) / 15 GB DDR4 / 180 GB NVMe SSD / 1 Gbit / s 15 TB - 45 USD / Monat
...
VPS (KVM) - E5-2650 v4 (24 Kerne) / 40 GB DDR4 / 480 GB NVMe SSD / 1 Gbit / s 40 TB - 120 USD / Monat
...
VPS (KVM) - E5-2650 v4 (24 Kerne) / 65 GB DDR4 / 780 GB NVMe SSD / 1 Gbit / s 65 TB - 195 USD / Monat
VPS (KVM) - E5-2650 v4 (24 Kerne) / 70 GB DDR4 / 840 GB NVMe SSD / 1 Gbit / s 70 TB - 210 USD / Monat
VPS (KVM) - E5-2650 v4 (24 Kerne) / 75 GB DDR4 / 900 GB NVMe SSD / 1 Gbit / s 75 TB - 225 USD / Monat
Daher ist es nicht sinnvoll, einen großen Teil der Rechenzentrums-Cloud zu mieten und den Kunden die alten E3-1230-Prozessoren anzubieten, obwohl sie für uns ab 3,99 USD pro Monat aufgebraucht sind. Wir glauben, dass Kunden die höchste Qualität und maximale Leistung zum niedrigsten Preis erhalten sollten. Ja, wir können das Produkt nicht für 3,99 US-Dollar anbieten und decken möglicherweise nicht die Anforderungen einiger Entwickler ab, die nur minimale Ressourcen und Leistung benötigen, aber die Knotenkosten sind höher 7.000 Euro und wir können es uns zumindest vorerst nicht leisten, mehr als 15 Kunden darauf zu setzen, da wir bereit sind, Qualität zu garantieren. Und Qualität bedeutet nicht nur Stabilität, sondern auch das maximale Leistungs- / Preisverhältnis und dann die Kosteneffizienz.
Um dies zu feiern, haben wir die gesamte Cloud-Infrastruktur (die aus Tausenden von VPS besteht) storniert, zwei unabhängige virtuelle Server für uns bestellt (ja, wir bezahlen uns selbst für unsere Server), eine Site bereitgestellt und vor zwei Monaten eine neue Lösung in Rechnung gestellt, wie wir alles beschrieben haben oben in die Schutzgruppe gebracht, damit sich das System nicht selbst stoppt, wenn Sie plötzlich vergessen haben, pünktlich zu zahlen ... Es scheint alles getan zu haben.
Und heute, nach 2 Monaten, haben wir beschlossen, abzubrechen (nicht löschen, eine solche Schaltfläche ist auch vorhanden, aber wir versuchen, nie etwas zu löschen, damit immer ein Verlauf vorhanden ist). Über 1000 ausstehende Bestellungen, denen in der WHMCS-Abrechnung noch kein Status zugewiesen wurde . Vermutlich? Ja, das ist es. Sie fragten mich - kann ich stornieren? Ich habe "Löschen" bestätigt.
Manchmal, trotz der großen Menge an Ressourcen, gibt WHMCS einen 504-Fehler aus, da die Datenerfassung groß ist und einige Prozesse nicht in das zugewiesene Zeitlimit passen, alles erledigt ist und die Abrechnung weiterhin funktioniert, aber hier haben wir keine Verfügbarkeit. Die Abrechnung und die Website sind nicht mehr verfügbar. Wir haben den Grund nicht sofort verstanden. Aber dann wurde ihnen klar. Die Bestellung für unsere 2 VPS wurde nicht angenommen (ja, wir haben unsere Bestellung nicht angenommen!) Und wurde daher vom System "storniert", was zum Start des Moduls und zum gleichzeitigen Entfernen von zwei Containern führte, die angeblich nicht erstellt, sondern von den Virtuals erstellt wurden unser geliebter VM Manager. Nachdem unsere Administratoren wie erwartet einen der Knoten betreten hatten, sahen sie das Bild „Lebewohl“:
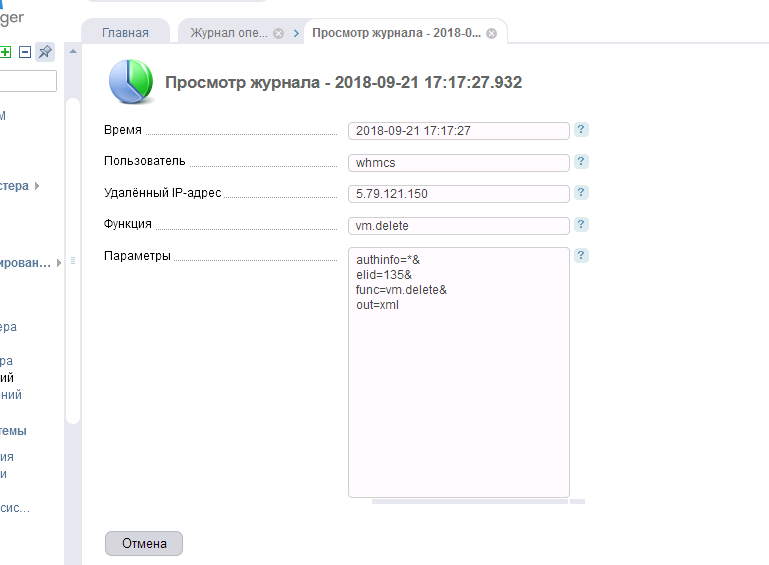
Was ist das? Ein Fehler in den WHMCS-Entwicklern, der dazu führt, dass nicht akzeptierte Bestellungen entfernt und tatsächlich mit ihrer VPS-ID erstellt werden, wenn sie storniert werden, oder unsere Dummheit (der Verkaufsabteilung) ist nicht mehr wichtig. Das Ergebnis war eins - "Abschied von der Website mit Abrechnung." Das Panel hat sie nur abgewischt. Und die Administratoren hatten nur eine Frage an uns (Vertrieb):
Naher erstellt einen Service mit Hauptstandort und Abrechnung.
Und dann töte sie auch zur Hölle.
Und obwohl wir Backups hatten, auch in zwei geografisch verteilten Regionen, fühlte ich mich unwohl. Da ich mir über die Aktualität der Backups nicht sicher war, war ich mir nicht sicher, ob unsere Administratoren alles richtig gemacht haben, wie es ursprünglich in diesen vorgeschrieben war. die Aufgabe, dass die Datenbank tatsächlich jede Stunde oder öfter gesichert wurde und die Daten aktualisiert und mehrere frühere Versionen von Dateien gespeichert wurden. Diese Sicherungen für einige Softwarefehler wurden überhaupt nicht beendet (schließlich habe ich sie persönlich nicht kontrolliert. Warum sollte ich sicher sein, dass unsere Administratoren sich Sorgen um unsere Daten machen, wenn ich diese Kontrolle erreiche?). Ein paar negative Gedanken ... Lass das Universum das nicht überleben!
Ich hatte bereits den Gedanken, dass es mindestens 1 Stunde oder noch schlimmer keine Transaktionen geben würde, und ich müsste Kundenzahlungen manuell wiederherstellen, Daten zu früheren Transaktionen vergleichen und den Kontoinhabern schreiben, dass wir das Konto neu erstellt und dafür bezahlt haben , um uns von der falschen Seite zu zeigen, um eine Benachrichtigung zu senden, dass wir Dummköpfe sind und eine solche Software-Fehlfunktion gemacht haben ... Und wenn es kein neues Backup gibt - dies ist im Allgemeinen eine Pipe, müsste es sehr lang und trostlos sein, um alles wiederherzustellen ...
In diesem Fall haben wir eine interne Tabelle, in der viele Hauptdaten manuell dupliziert werden und die von uns aktualisiert wird, wodurch ein Softwarefehler und das Umschreiben falscher Daten vermieden werden. Trotz der Verfügbarkeit von Backups verwenden wir diese Methode weiterhin. Schließlich hebt niemand die Möglichkeit eines globalen Zvezdets auf.
Zum Glück stellte sich heraus, dass alles nicht so schlimm war, und sogar diese. ein Spezialist, der ein Problem lösen musste und der zu Beginn ankündigte:
Der Abend war ein Erfolg, ich danke Ihnen allen.
Ich holte es ab.
Trotzdem war der Abend ein Erfolg. Da ursprünglich die Lösung für die Verwendung von lvm und eines neuen virtuellen Containers noch nicht erstellt worden war, war es möglich, die tatsächlichen Daten wiederherzustellen, obwohl mit einem Tanz mit einem Tamburin:
Alles über das Dienstprogramm lvm stellte mit seinen Befehlen die virtuelle Volume-Gruppe und dann die virtuelle wieder her, aktivierte dann die Partition, stellte sie in den linken Ordner, erstellte den Server und legte die Daten dort ab. Es war auf andere Weise möglich, aber diese Option war in unserem Fall die schnellste + Besonderheit der Einstellungen des virtuellen Servers, für die jeder seinen eigenen RAID hat.
Welche Schlussfolgerungen werden gezogen? Redundanz und Redundanz sollten die Schwachstellenabrechnung und das dümmste Entwicklungsszenario umfassen, in dem alles, auch Backups, zerstört werden können. Wir haben nicht gelitten und keine großen Verluste erlitten, nur weil die Daten nicht vollständig gelöscht wurden. Wenn eine Wiederherstellung aus Sicherungen erforderlich ist, gehen Transaktionen pro Stunde und Arbeitszeit erheblich verloren. Es schien uns, dass die Wahrscheinlichkeit, dass Backups bei der Verwendung eines Geoclusters nützlich sein könnten, minimal ist - wir haben uns geirrt. Wir haben nicht berücksichtigt, dass es möglich ist, beide Server gleichzeitig zu löschen und dass wir die Server nicht löschen werden, aber wir.
Es ist immer ein von Ihrem System unabhängiger externer Speicher mit Zugriff erforderlich, vorzugsweise nur über einen Code, der ebenfalls reserviert ist, um sicherzustellen, dass die Daten nicht verloren gehen. Im Moment denke ich trotz des Vorhandenseins von Backups in unserer Infrastruktur in zwei Regionen ernsthaft über die Möglichkeit nach, etwas wie Amazon Glacier zu verwenden, obwohl letzteres sehr teuer ist. Laut den Administratoren ist dort alles nur in Bezug auf Marketing in Ordnung, aber wenn Sie anfangen, es zu verwenden, werden Sie mit der Tatsache konfrontiert, dass die Lösung ziemlich teuer ist, weil Sie für jede Anfrage und jede Datei bezahlen müssen, die sehr interessant als ihre aws-cli-Anwendung angesehen wird, insbesondere wenn Daten müssen wiederhergestellt werden. Kürzlich hat ein Kunde aus Großbritannien darum gebeten, dort eine Reservierung einzurichten. Nach einigen Monaten der Nutzung lehnte er dies ab - es stellte sich als sehr teuer heraus. Trotzdem müssen wir herausfinden, was teurer ist. — . — , , . , .
, — , , , . , , , , , .
PS , ( , EST ). , , . , - . , , . , — , . . !
.
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps ,
, 30% VPS , ,
.
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel Dodeca-Core Xeon E5-2650v4 128 GB DDR4 6 x 480 GB SSD 1 Gbit / s 100 TV von 249 US-Dollar in den Niederlanden und den USA! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?