Vor ein paar Jahren habe ich ein Migrationsprojekt im Netzwerk eines unserer Kunden abgeschlossen. Die Aufgabe bestand darin, die Plattform zu ändern, die die Last auf die Server verteilt. Das Service-Provisioning-Schema dieses Clients hat sich in fast 10 Jahren zusammen mit neuen Entwicklungen in der Rechenzentrumsbranche weiterentwickelt. Daher erwartete der „wählerische“ Kunde im besten Sinne eine Lösung, die nicht nur die Fehlertoleranzanforderungen von Netzwerkgeräten, Load Balancern und Servern erfüllt , würde aber auch Eigenschaften wie Skalierbarkeit, Flexibilität, Mobilität und Einfachheit besitzen. In diesem Artikel werde ich versuchen, die Hauptbeispiele für die Verwendung von Load Balancern ohne Bezugnahme auf den Hersteller, ihre Funktionen und Methoden zur Kopplung mit dem Datenlieferungsnetzwerk konsequent von einfach bis komplex darzulegen.
Load Balancer werden zunehmend als Application Delivery Controller (ADCs) bezeichnet. Aber wenn die Anwendungen auf dem Server ausgeführt werden, warum sollten sie irgendwo bereitgestellt werden? Aus Gründen der Fehlertoleranz oder Skalierung kann die Anwendung auf mehr als einem Server ausgeführt werden. In diesem Fall benötigen Sie eine Art Reverse-Proxy-Server, der die interne Komplexität vor den Verbrauchern verbirgt, den gewünschten Server auswählt, eine Anforderung an ihn sendet und sicherstellt, dass der Server den richtigen zurückgibt Aus Sicht des Protokolls wird das Ergebnis andernfalls ein anderer Server ausgewählt und dort eine Anfrage gesendet. Um diese Funktionen zu implementieren, muss der ADC die Semantik des Anwendungsschichtprotokolls verstehen, mit dem er arbeitet. Auf diese Weise können Sie anwendungsspezifische Regeln für die Verkehrsübermittlung, die Analyse des Ergebnisses und die Überprüfung des Serverstatus konfigurieren. Ein Verständnis der Semantik von HTTP ermöglicht beispielsweise die Konfiguration bei HTTP-Anforderungen
GET /docs/index.html HTTP/1.1 Host: www.company.com Accept-Language: en-us Accept-Encoding: gzip, deflate
werden an eine Gruppe von Servern gesendet, mit anschließender Komprimierung der Ergebnisse und Zwischenspeicherung sowie Anforderungen
POST /api/object-put HTTP/1.1 HOST: b2b.company.com X-Auth: 76GDjgtgdfsugs893Hhdjfpsj Content-Type: application/json
nach völlig anderen Regeln verarbeitet.
Wenn Sie die Semantik des Protokolls kennen, können Sie Sitzungen auf der Ebene der Objekte des Anwendungsprotokolls organisieren, z. B. mithilfe von HTTP-Headern, RDP-Cookies oder Multiplex-Anforderungen, um eine Transportsitzung mit vielen Benutzeranforderungen zu füllen, sofern die Anwendungsebene des Protokolls dies zulässt.
Der Anwendungsbereich von ADC wird manchmal nur durch die Bereitstellung von HTTP-Verkehr unangemessen vorgestellt. Tatsächlich ist die Liste der unterstützten Protokolle für die meisten Hersteller viel umfangreicher. Selbst wenn ADC nicht die Semantik des Anwendungsschichtprotokolls versteht, kann es nützlich sein, um verschiedene Aufgaben zu lösen. Ich habe beispielsweise am Aufbau einer autarken virtuellen Farm von SMTP-Servern teilgenommen. Während der Spam-Angriffe nimmt die Anzahl der Instanzen mithilfe der Feedback-Steuerung über die Länge der Nachrichtenwarteschlange zu eine zufriedenstellende Zeit für das Überprüfen von Nachrichten mit ressourcenintensiven Algorithmen bereitzustellen. Während der Aktivierung hat sich der Server bei ADC registriert und seinen Teil der neuen TCP-Sitzungen erhalten. Im Fall von SMTP war ein solches Betriebsschema aufgrund der hohen Entropie der Verbindungen auf Netzwerk- und Transportebene gerechtfertigt. Für eine gleichmäßige Lastverteilung bei ADC-Spam-Angriffen ist nur TCP-Unterstützung erforderlich. Ein ähnliches Schema kann verwendet werden, um eine Farm aus Datenbankservern, hoch geladenen DNS-, DHCP-, AAA- oder RAS-Serverclustern zu erstellen, wenn die Server in der Domäne als gleichwertig angesehen werden können und wenn sich ihre Leistungsmerkmale nicht zu stark voneinander unterscheiden. Ich werde nicht weiter auf das Thema Protokollfunktionen eingehen. Dieser Aspekt ist zu umfangreich, um in der Einleitung dargelegt zu werden. Wenn etwas interessant erscheint - schreiben Sie, vielleicht ist dies eine Gelegenheit für einen Artikel mit einer tieferen Darstellung einer Anwendung, und jetzt kommen wir zum Punkt.
In den meisten Fällen schließt ADC die Transportschicht, sodass die End-to-End-TCP-Sitzung zwischen dem Verbraucher und dem Server zusammengesetzt wird. Der Verbraucher richtet eine Sitzung mit ADC und ADC mit einem der Server ein.
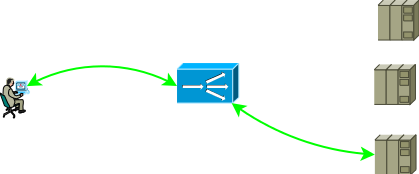 Abb. 1
Abb. 1Die Netzwerkkonfigurations- und Adressierungseinstellungen sollten einen solchen Verkehrsfortschritt ermöglichen, damit zwei Teile der TCP-Sitzung den ADC durchlaufen. Die einfachste Möglichkeit, den Datenverkehr des ersten Teils zum ADC zu bringen, besteht darin, einer der ADC-Schnittstellenadressen eine Dienstadresse zuzuweisen. Im zweiten Teil sind die folgenden Optionen möglich:
- ADC als Standard-Gateway für das Servernetzwerk;
- Broadcast an ADC-Verbraucheradressen in einer seiner Schnittstellenadressen.
Tatsächlich sieht eine etwas realistischere Ansicht des ersten Anwendungsschemas so aus. Dies ist die Grundlage, von der aus wir ausgehen werden:
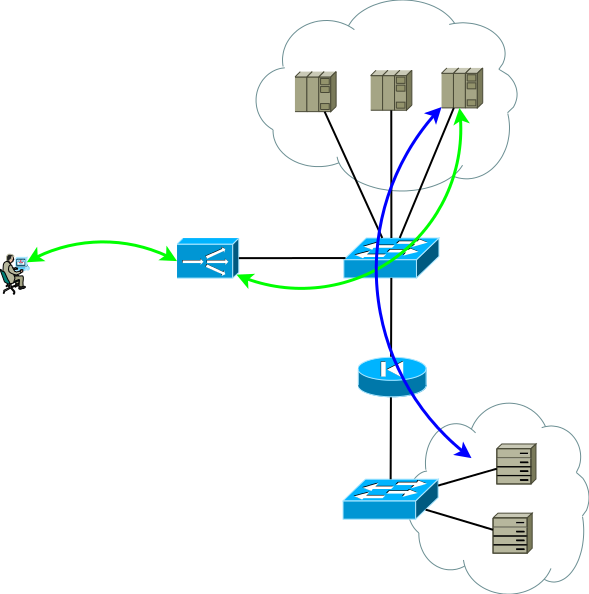 Abb.2
Abb.2Die zweite Gruppe von Servern kann Datenbanken, Anwendungs-Back-End, Netzwerkspeicher oder Front-End für einen anderen Satz von Diensten sein, wenn eine klassische Anwendung in Mikrodienste zerlegt wird. Diese Gruppe von Servern kann eine separate Routingdomäne mit eigenen Richtlinien sein, die sich in einem anderen Rechenzentrum befindet, oder aus Sicherheitsgründen vollständig isoliert sein. Server befinden sich selten im selben Segment, häufiger werden sie für den beabsichtigten Zweck mit klar geregelten Zugriffsrichtlinien in Segmenten platziert. Die Abbildung zeigt dies als Firewall.
Studien zeigen, dass moderne mehrschichtige Anwendungen mehr West-Ost-Verkehr erzeugen und es unwahrscheinlich ist, dass der gesamte Intra-Code- / Inter-Segment-Verkehr durch den ADC geleitet wird. Die Switches in Abbildung 2 sind nicht unbedingt physisch. Routing-Domänen können mithilfe virtueller Entitäten implementiert werden, die als Virtual-Router, VRF, VR, VPN-Instanz oder virtuelle Routing-Tabelle für verschiedene Hersteller bezeichnet werden.
Übrigens gibt es eine Variante der Kopplung mit dem Netzwerk, ohne dass eine Symmetrie der Verkehrsströme vom Verbraucher zum ADC und vom ADC zu den Servern erforderlich ist. Sie ist bei langlebigen Sitzungen gefragt, bei denen eine sehr große Menge an Verkehr in eine Richtung übertragen wird, z. B. Streaming oder Videoinhalte senden. In diesem Fall sieht der ADC nur den Stream vom Client zu den Servern. Dieser Stream wird an die ADC-Schnittstellenadresse gesendet. Nach einer einfachen Verarbeitung, die darin besteht, die MAC-Adresse durch die Schnittstellen-MAC eines der Server zu ersetzen, wird die Anforderung an den Server gesendet, auf dem die Dienstadresse einer der logischen Schnittstellen zugewiesen ist. Der umgekehrte Verkehr vom Server zum Verbraucher umgeht den ADC gemäß der Server-Routing-Tabelle. Die Unterstützung einer einzelnen Broadcast-Domäne für das gesamte Front-End kann sehr schwierig sein. Darüber hinaus ist die Fähigkeit von ADC, Antworten zu analysieren und die Sitzungsfähigkeit zu unterstützen, in diesem Fall sehr eingeschränkt. Tatsächlich handelt es sich nur um einen Wechsel. Daher wird diese Option nicht weiter betrachtet, obwohl einige eng sind Aufgaben können verwendet werden.
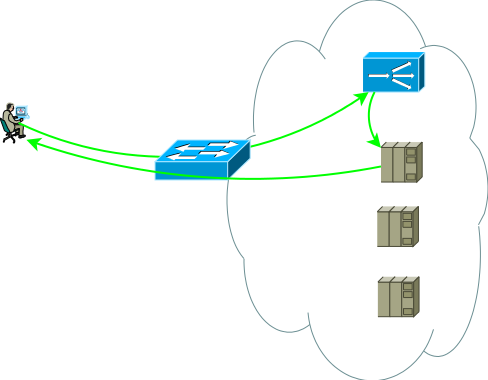 Abb.3
Abb.3Wir haben also ein Basisdatenzentrum (siehe Abbildung 2). Lassen Sie uns überlegen, welche Probleme das Basisdatenzentrum zur Evolution führen können. Ich sehe zwei Themen für die Analyse:
- Angenommen, das Switching-Subsystem ist vollständig reserviert. Denken wir nicht darüber nach, wie oder warum das Thema zu umfangreich ist. Anwendungen werden auf mehreren Servern ausgeführt und mit ADC gesichert. Wie reserviere ich den ADC selbst?
- Wenn die Analyse zeigt, dass die nächste saisonale Spitzenlast die Fähigkeiten von ADC überschreiten kann, denken Sie natürlich an die Skalierbarkeit.
Diese Aufgaben sind insofern ähnlich, als die Anzahl der ADC-Instanzen beim Lösen sicherlich zunimmt. Gleichzeitig kann die Fehlertoleranz nach dem Schema Aktiv / Sicherung und Aktiv / Aktiv organisiert werden, und die Skalierung kann nur nach dem Schema Aktiv / Aktiv durchgeführt werden. Versuchen wir, sie einzeln zu lösen und herauszufinden, welche Eigenschaften verschiedene Lösungen haben.
Die ADCs vieler Hersteller können als Elemente einer Netzwerkinfrastruktur, RIP, OSPF, BGP betrachtet werden - all dies ist vorhanden, was bedeutet, dass Sie ein triviales Aktiv / Backup-Sicherungsschema erstellen können. Der aktive ADC übergibt die Dienstpräfixe an den Upstream-Router und empfängt von ihm die Standardroute, um seine Tabelle auszufüllen und zum Rechenzentrum an die entsprechende virtuelle Routing-Tabelle zu übertragen. Der Backup-ADC macht dasselbe, generiert jedoch unter Verwendung der Semantik des ausgewählten Routing-Protokolls weniger attraktive Ansagen. Bei diesem Ansatz können Server die tatsächliche IP-Adresse des Verbrauchers anzeigen, da kein Grund für die Adressübersetzung besteht. Dieses Schema funktioniert auch ordnungsgemäß, wenn mehr als ein Upstream-Router vorhanden ist. Um jedoch eine Situation zu vermeiden, in der der aktive ADC die Standardeinstellung und die Konnektivität mit dem Router verliert, während er weiterhin die Standardeinstellung vom Sicherungs-ADC erhält und diese weiterhin gegenüber dem Rechenzentrum ankündigt, versuchen Sie, die Nähe zwischen diesen zu vermeiden ADC und die Verwendung statischer Routen.
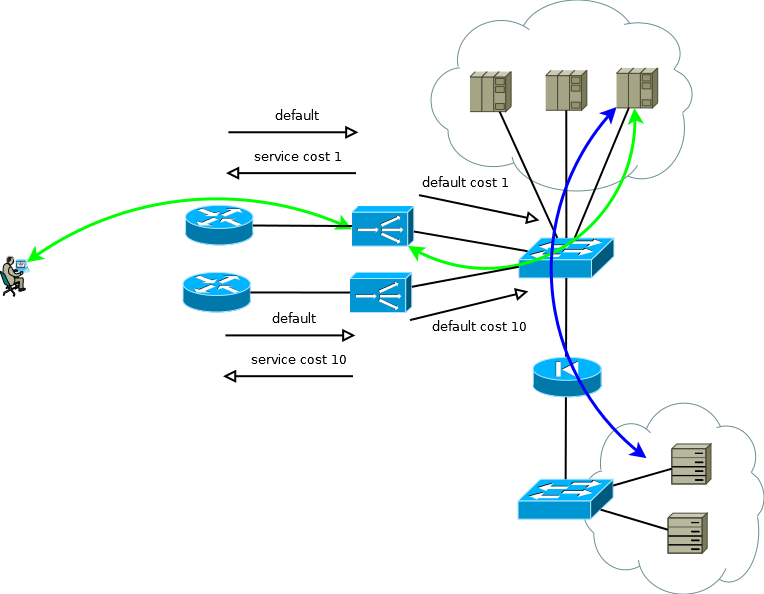 Abb. 4
Abb. 4Wenn die Server nicht mit echten Consumer-IP-Adressen arbeiten müssen oder das Anwendungsschichtprotokoll das Einbetten in Header wie HTTP ermöglicht, wird das Schema in Active / Active umgewandelt, wobei die Leistung nahezu linear von der Anzahl der ADCs abhängt. Bei mehr als einem Upstream-Router muss darauf geachtet werden, dass der eingehende Datenverkehr in mehr oder weniger einheitlichen Abschnitten eintrifft. Diese Aufgabe kann leicht gelöst werden, wenn in der ECMP-Routingdomäne die Übertragung zu diesen Routern beginnt, wenn dies schwierig ist oder wenn die Routingdomäne nicht von Ihnen bedient wird. Sie können Vollnetzverbindungen zwischen ADX und den Routern verwenden, sodass die ECMP-Übertragung direkt zu diesen Routern beginnt.
 Abb.5
Abb.5Zu Beginn dieses Teils habe ich geschrieben, dass Fehlertoleranz und Skalierung zwei große Unterschiede sind. Lösungen für diese Probleme haben eine andere Ressourcennutzung. Wenn Sie ein Aktiv / Standby-Schema entwerfen, müssen Sie sich damit abfinden, dass die Hälfte der Ressourcen inaktiv ist. Und wenn es so kommt, dass Sie den nächsten quantitativen Schritt unternehmen müssen, sollten Sie darauf vorbereitet sein, die erforderlichen Ressourcen in Zukunft mit zwei weiteren zu multiplizieren.
Die Vorteile von Aktiv / Aktiv zeigen sich, wenn Sie mit mehr als zwei Geräten arbeiten. Angenommen, Sie müssen die Leistung von 8 beliebigen Einheiten (8.000 Verbindungen pro Sekunde oder 8 Millionen gleichzeitige Sitzungen) sicherstellen und ein Szenario mit einem einzelnen Gerätefehler bereitstellen. In der Active / Active-Version benötigen Sie im Fall von Active / Standby nur drei ADC-Instanzen mit einer Kapazität von 4 -. zwei mal 8. Wenn Sie diese Zahlen in Ressourcen übersetzen, die nicht genutzt werden, erhalten Sie ein Drittel bis eine Hälfte. Das gleiche Berechnungsprinzip kann verwendet werden, um den Anteil unterbrochener Verbindungen während einer Teilausfallperiode abzuschätzen. Mit zunehmender Anzahl von Aktiv / Aktiv-Instanzen wird die Mathematik noch angenehmer, und das System erhält die Möglichkeit, die Produktivität schrittweise zu steigern, anstatt schrittweise Aktiv / Standby.
Es ist richtig, eine andere Art von Aktiv / Aktiv- oder Aktiv / Standby-Arbeitsschemata zu erwähnen - Clustering. Aber es wird nicht sehr richtig sein, viel Zeit darauf zu verwenden, da ich versucht habe, über Ansätze und nicht über die Merkmale von Herstellern zu schreiben. Bei der Auswahl dieser Lösung müssen Sie die folgenden Dinge klar verstehen:
- Die Cluster-Architektur schränkt diese oder jene Funktionalität manchmal ein. In einigen Projekten ist dies von grundlegender Bedeutung. In einigen Projekten kann dies in Zukunft wichtig werden. Alles hängt vom Hersteller ab und jede Lösung muss einzeln ausgearbeitet werden.
- Der Cluster ist häufig eine Fehlerdomäne, und es treten Fehler in der Software auf.
- Der Cluster ist leicht zu montieren, aber sehr schwer zu zerlegen. Technologie ist weniger mobil - Sie können keine Teile des Systems steuern.
- Sie fallen in die zähe Umarmung Ihres Herstellers.
Trotzdem gibt es positive Dinge:
- Der Cluster ist einfach zu installieren und zu bedienen.
- Manchmal können Sie eine nahezu optimale Ressourcennutzung erwarten.
Unser Rechenzentrum aus Abbildung 5 wächst also weiter. Die Aufgabe, die Sie möglicherweise lösen müssen, besteht darin, die Anzahl der Server zu erhöhen. Dies ist in einem vorhandenen Rechenzentrum nicht immer möglich. Nehmen wir also an, dass ein neuer geräumiger Standort mit zusätzlichen Servern angezeigt wurde.
 Abb.6
Abb.6Eine neue Site ist möglicherweise nicht sehr weit entfernt. Dann können Sie das Problem erfolgreich lösen, indem Sie die Routing-Domänen erneuern. Ein allgemeinerer Fall, der das Erscheinungsbild der Site in einer anderen Stadt oder in einem anderen Land nicht ausschließt, stellt das Rechenzentrum vor neue Herausforderungen:
- Nutzung von Kanälen zwischen Standorten;
- Der Unterschied in der Verarbeitungszeit für Anforderungen, die ADC zur Verarbeitung an nahe und entfernte Server gesendet hat.
Die Aufrechterhaltung eines breiten Kanals zwischen Standorten kann ein sehr kostspieliges Unterfangen sein, und die Auswahl eines Standorts ist keine triviale Aufgabe mehr - ein überlasteter Standort mit kurzer Reaktionszeit oder kostenlos mit einem großen Standort. Wenn Sie darüber nachdenken, müssen Sie eine geografisch verteilte Rechenzentrumskonfiguration erstellen. Diese Konfiguration ist einerseits verbraucherfreundlich, da Sie damit Dienste an einem Punkt in Ihrer Nähe empfangen können, andererseits können die Anforderungen an das Kanalband zwischen Standorten erheblich reduziert werden.
Für den Fall, dass echte IP-Adressen für die Server nicht zugänglich sein müssen oder wenn das Anwendungsschichtprotokoll die Übertragung in den Headern ermöglicht, unterscheidet sich das Gerät eines geografisch verteilten Rechenzentrums nicht wesentlich von dem, was ich als Basisdatenzentrum bezeichnet habe. ADC kann an jedem Standort Verarbeitungsanforderungen an lokale Server senden oder diese zur Verarbeitung an einen benachbarten Server senden. Die Übertragung der Verbraucheradresse macht dies möglich. Es sollte ein gewisses Augenmerk auf die Überwachung des eingehenden Verkehrsvolumens gelegt werden, um die ADC-Menge innerhalb des Standorts so zu halten, dass sie dem Anteil des Verkehrs entspricht, den der Standort empfängt. Mit der Übersetzung von Verbraucheradressen können Sie die Anzahl der ADCs erhöhen / verringern oder sogar Instanzen zwischen Standorten entsprechend den Änderungen in der Matrix für eingehenden Datenverkehr oder während der Migration / des Starts verschieben. Trotz seiner Einfachheit ist das Schema sehr flexibel, weist angenehme Betriebseigenschaften auf und lässt sich leicht für mehr als zwei Standorte replizieren.
 Abb. 7
Abb. 7Wenn Sie mit einem Protokoll arbeiten, das Weiterleitungsanforderungen ermöglicht, wie im Fall der HTTP-Umleitung, kann diese Funktion als zusätzlicher Hebel zur Steuerung der Kanallast zwischen Standorten, als Mechanismus für die routinemäßige Wartung auf Servern oder als Methode zum Erstellen von Active / Backup-Serverfarmen auf verschiedenen Servern verwendet werden Websites. Zum erforderlichen Zeitpunkt, automatisch oder nach einigen Auslöseereignissen, kann ADC Datenverkehr von lokalen Servern entfernen und Verbraucher an einen benachbarten Standort verschieben. Es lohnt sich, der Entwicklung dieses Algorithmus besondere Aufmerksamkeit zu widmen, damit die koordinierte Arbeit von ADC die Möglichkeit der gegenseitigen Weiterleitung von Anfragen oder Resonanz ausschließt.
Von besonderem Interesse ist der Fall, wenn die Server echte IP-Adressen von Verbrauchern benötigen und das Protokoll der Anwendungsschicht nicht in der Lage ist, zusätzliche Header zu übertragen, oder wenn ADCs arbeiten, ohne die Semantik des Protokolls der Anwendungsschicht zu verstehen. In diesem Fall ist es nicht möglich, eine konsistente Verbindung zwischen TCP-Sitzungssegmenten herzustellen, indem einfach eine Route im ADC-Standard deklariert wird. Wenn Sie dies tun, verwenden die Server des ersten Standorts den lokalen ADC als Standardgateway für die Sitzungen, die vom zweiten Standort stammen. In diesem Fall wird die TCP-Sitzung nicht eingerichtet, da der ADC des ersten Standorts nur eine Schulter der Sitzung sieht.
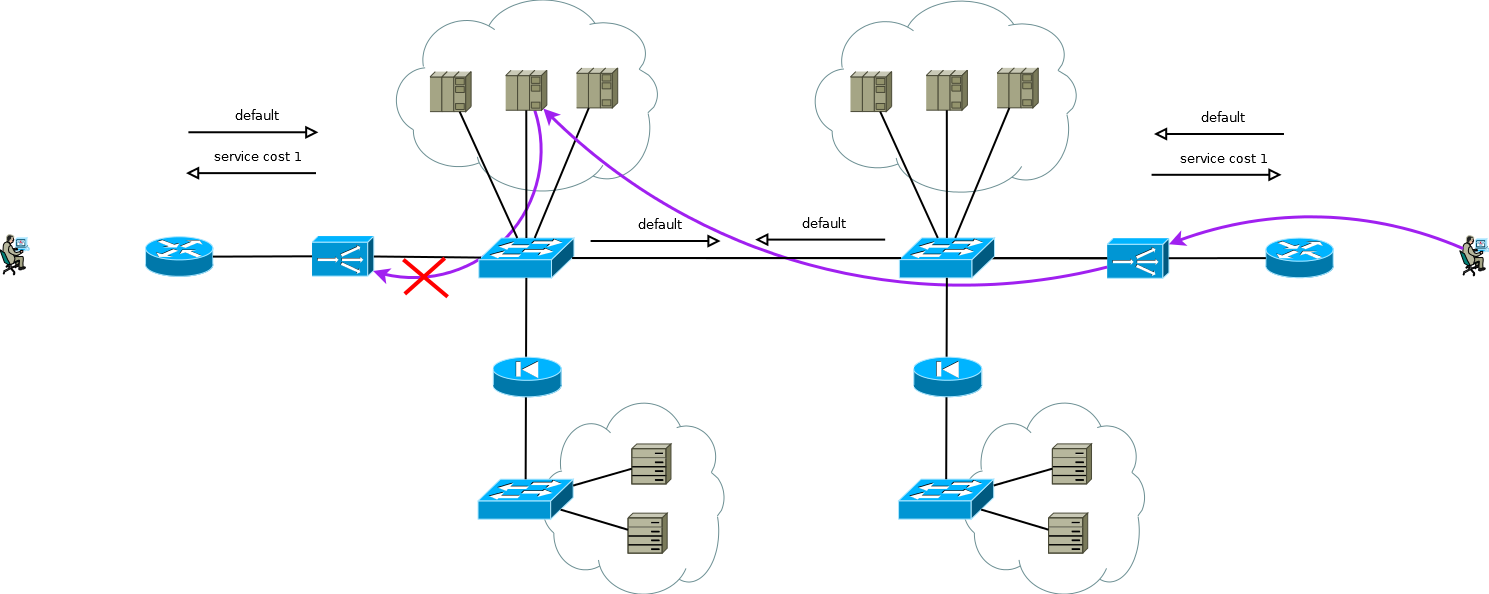 Abb. 8
Abb. 8Es gibt einen kleinen Trick, mit dem Sie Active / Active ADC weiterhin in Kombination mit Active / Active-Serverfarmen an verschiedenen Standorten ausführen können (ich betrachte den Fall von Active / Backup an zwei Standorten nicht, eine sorgfältige Lektüre der obigen Informationen ermöglicht es Ihnen, dieses Problem ohne weitere Diskussion zu lösen). Der Trick besteht darin, auf dem ADC des zweiten Standorts nicht die Serverschnittstellenadressen zu verwenden, sondern die logische ADC-Adresse, die der Serverfarm am ersten Standort entspricht. Gleichzeitig empfangen die Server Datenverkehr wie vom lokalen ADC und verwenden das lokale Standardgateway. Um diesen Betriebsmodus auf dem ADC beizubehalten, müssen Sie die Speicherfunktion der Schnittstelle aktivieren, von der das erste Paket zum Einrichten der TCP-Sitzung stammt. Verschiedene Hersteller nennen diese Funktion unterschiedlich, aber das Wesentliche ist dasselbe - merken Sie sich die Schnittstelle in der Sitzungsstatustabelle und verwenden Sie sie für den Antwortverkehr, ohne auf die Routing-Tabelle zu achten. Das Schema ist voll funktionsfähig und ermöglicht es Ihnen, die Last flexibel auf alle verfügbaren Server zu verteilen, wo immer sie sich befinden. Bei zwei oder mehr Standorten wirkt sich der Ausfall eines ADC nicht auf die Verfügbarkeit des gesamten Dienstes aus, schließt jedoch die Möglichkeit der Verarbeitung von Datenverkehr auf Standortservern mit ausgefallenen ADCs vollständig aus. Dies sollte bei der Vorhersage des Verhaltens und der Auslastung bei Teilausfällen berücksichtigt werden.
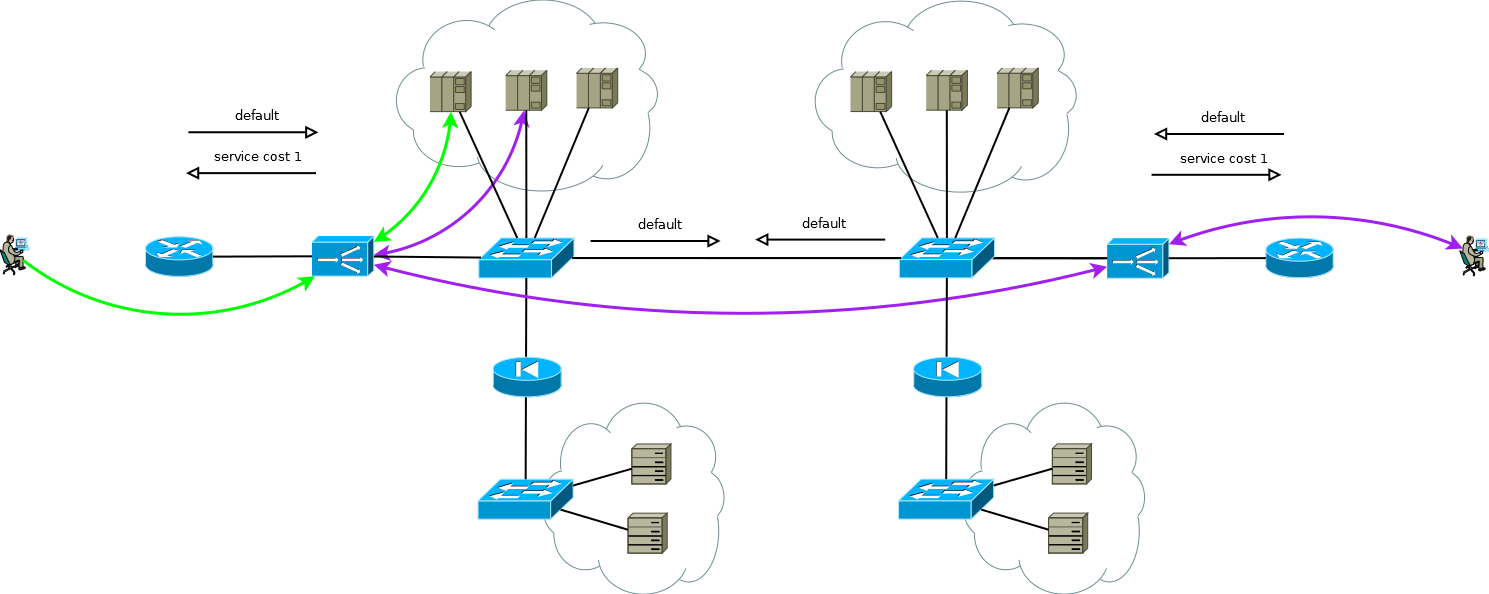 Abb. 9
Abb. 9Die Dienste unseres Kunden funktionierten ungefähr genauso, als ich anfing, an einem Migrationsprojekt zur neuen ADC-Plattform zu arbeiten. Es war nicht schwierig, das Verhalten der Geräte der alten Plattform auf der neuen Plattform im Rahmen eines bewährten und kundenfreundlichen Schemas einfach nachzubilden. Dies haben sie von uns erwartet.
Aber sehen Sie sich noch einmal Abbildung 9 an. Sehen Sie, was dort optimiert werden kann?
Der Hauptnachteil der Arbeit mit der ADC-Kette besteht darin, dass sie die Ressourcen von zwei ADCs verbraucht, um einen Teil der Sitzungen zu verarbeiten. Bei diesem Client war die Auswahl absolut bewusst, da dies auf die Besonderheiten der Anwendungen und die Notwendigkeit zurückzuführen war, die Last sehr schnell (von 20 bis 50 Sekunden) auf Server verschiedener Standorte umverteilen zu können. Zu verschiedenen Zeitpunkten beanspruchte die Doppelverarbeitung durchschnittlich 15 bis 30 Prozent der ADC-Ressourcen, was ausreicht, um über eine Optimierung nachzudenken. Nachdem wir diesen Punkt mit den Ingenieuren des Clients besprochen hatten, schlugen wir vor, die Unterstützung für die ADC-Sitzungstabelle durch Schnittstellenbindung durch Quellrouting auf Servern zu ersetzen, die PBR auf dem Linux-IP-Stack verwenden. Als Schlüssel haben wir folgende Optionen in Betracht gezogen:
- zusätzliche IP-Adresse auf Servern auf einer gemeinsamen Schnittstelle für jeden ADC;
- Schnittstellen-IP-Adresse auf Servern auf einem separaten 802.1q für jeden ADC;
- Separates Overlay-Tunnelnetzwerk auf Servern für jeden ADC.
Die erste und die zweite Option würden sich irgendwie auf das gesamte Netzwerk auswirken. Unter den Nebenwirkungen von Option 1 schien es uns inakzeptabel, dass eine Erhöhung, die ein Vielfaches der Anzahl von ADC-, ARP-Tabellen auf den Switches und der zweiten Option war, eine Erhöhung der Anzahl von End-to-End-Broadcast-Domänen zwischen Standorten oder einzelnen Instanzen von virtuellen Routing-Tabellen erfordern würde. Die lokale Natur der dritten Option schien uns sehr attraktiv zu sein, und wir machten uns an die Arbeit, was zu einem einfachen Controller führte, der die Konfiguration von Tunneln auf Servern und ADC sowie die PBR-Konfiguration auf dem IP-Stack von Linux-Servern automatisiert.
 Abb. 10
Abb. 10Wie ich schrieb, war die Migration abgeschlossen, der Client bekam, was er wollte - eine neue Plattform, Einfachheit, Flexibilität, Skalierbarkeit und als Ergebnis des Wechsels zu einem Overlay die Vereinfachung der Konfiguration von Netzwerkgeräten im Rahmen der Wartung dieser Dienste - anstelle mehrerer Kopien von virtuellen Tabellen und großen Broadcast-Domänen - IP .
Kollegen, die mit ADC-Herstellern zusammenarbeiten, dieser Absatz konzentriert sich mehr auf Sie. Einige Ihrer Produkte sind gut, aber achten Sie auf eine engere Integration mit Anwendungen auf Servern, die Automatisierung ihrer Einstellungen und die Orchestrierung des gesamten Entwicklungs- und Betriebsprozesses. Dies scheint mir in Form einer klassischen Controller-Agent-Interaktion zu sein, bei der Änderungen am ADC vorgenommen werden. Der Benutzer leitet die Berufung des Controllers an registrierte Agenten ein. Dies haben wir mit dem Client getan, aber "out of the box".Darüber hinaus ist es für einige Kunden möglicherweise bequem, von einem PULL-Modell für die Interaktion mit Servern zu einem PUSH-Modell zu wechseln. Die Anwendungsfunktionen auf den Servern sind sehr umfangreich, sodass es manchmal einfacher ist, eine ernsthafte anwendungsspezifische Überprüfung des Dienstes auf dem Agenten selbst zu organisieren. Wenn die Prüfung ein positives Ergebnis liefert, überträgt der Agent Informationen, beispielsweise in einer Form ähnlich der BGP-Kostengemeinschaft, zur Verwendung in gewichteten Berechnungsalgorithmen.Häufig führen verschiedene Abteilungen einer Organisation eine Server- und ADC-Wartung durch. Der Wechsel zu einem PUSH-Interaktionsmodell kann interessant sein, da bei diesem Modell keine Koordination zwischen Abteilungen über eine Mensch-Person-Schnittstelle erforderlich ist. Dienste, an denen der Server teilnimmt, können in Form einer ähnlichen Funktion wie die erweiterte BGP Flow-Spec direkt vom Agenten an den ADC übertragen werden.Es gibt noch viel mehr zu schreiben. Warum bin ich das alles? Da wir die freie Wahl haben, entscheiden wir uns für eine bequemere, geeignetere oder für eine Option, die das Zeitfenster erweitert, um unsere Risiken zu minimieren. Große Akteure in der Internetbranche erfinden etwas völlig Innovatives, um ihre Probleme zu lösen, was morgen vorgeschrieben ist. Kleinere Akteure und Unternehmen mit Erfahrung in der Softwareentwicklung verwenden zunehmend Technologien und Produkte, die eine tiefgreifende Anpassung für sich selbst ermöglichen. Viele Hersteller von Load Balancern stellen einen Rückgang der Nachfrage nach ihren Produkten fest. Mit anderen Worten, die Server und Anwendungen, die vor einiger Zeit auf ihnen, Switches und Routern ausgeführt wurden, haben sich bereits qualitativ verändert und sind in die SDN-Ära eingetreten. Die Balancer sind an der SchwelleFühren Sie diesen Schritt bei geöffneter Tür aus, da Sie sonst den Wettbewerbsvorteil verlieren und an die Peripherie wechseln können.