Ich schlage vor, eine kostenlose Übersetzung eines kurzen Artikels über die praktische Anwendung von GraphQL zu lesen. Das Original ist hier erhältlich (
En ).
Ein paar Worte zu GraphQL
GraphQL ist eine API-Abfragesprache, die einen deklarativen Ansatz zum Abrufen von Daten bietet. Kunden können nur die erforderlichen Daten von einem Webserver anfordern und nicht mehr. GraphQL wurde 2012 von Facebook entwickelt und wird immer noch unterstützt. Es wurde von vielen anderen großen und nicht so großen Unternehmen verwendet. Unter anderem Yelp, Shopify und Github.
Bei Verwendung von REST-APIs werden Anforderungen normalerweise an mehrere Adressen gesendet, um alle erforderlichen Daten in der Anwendung abzurufen. Mit der GraphQL-API können Sie die gesamte Anfrage an die Adresse senden und genau angeben, welche Daten Sie mit dieser Anfrage erhalten möchten. Daher ist GraphQL übrigens großartig, wenn es in einer langsamen mobilen Verbindung verwendet wird.
API-Versionen können für Entwicklungsteams Kopfschmerzen bereiten. Mit GraphQL können Sie sich darüber keine Sorgen machen. Mit GraphQL können Sie neue Felder und Typen (dies wird später erläutert) zu Ihrer GraphQL-API hinzufügen, ohne vorhandene Abfragen zu beeinflussen. Alte und nicht verwendete Felder können vor API-Clients ausgeblendet werden. Mit einer einzigen, sich weiterentwickelnden Version bietet die GraphQL-API Ihrer Anwendung ständigen Zugriff auf neue API-Implementierungen und bietet eine saubere und einfach zu wartende Codebasis.
Voraussetzung
Stellen Sie vor dem Start sicher, dass Node Version 6 und älter installiert ist. Sie können die Version mit dem folgenden Befehl überprüfen:
node -v
Wenn Sie Node nicht installiert haben, rufen Sie die URL
https://nodejs.org/ auf und befolgen Sie die Installationsanweisungen.
Anpassen von GraphQL und Express
Eine einfache Möglichkeit, einen Graph API-Server zu erstellen, ist die Verwendung von Express, einem beliebten Framework für Node.js. Installieren Sie Express mit npm:
npm init npm install express --save
Dann installieren Sie `graphql` und` express-graphql`:
npm install graphql express-graphql --save
Die anfängliche Struktur des Ordners lautet also wie folgt:
|---- node_modules
|---- package.jsonSchnellstart in der GraphQL-API
In diesem kleinen Abschnitt werden wir versuchen, schnell eine einfache GraphQL-API zu erstellen. Dies ist wichtig für die weitere Erzählung, damit Ihnen klar wird, was genau wir tun und wie die mit GraphQL erstellte API aussieht. Wenn einige Punkte schwierig und unverständlich erscheinen, machen Sie sich keine Sorgen, wir werden darauf zurückkommen.
Jetzt verwenden wir das Objekt "buildSchema" aus "graphql", um das Schema ("Schema") zu erstellen. Erstellen Sie eine example.js-Datei in unserem Ordner.
const express = require('express'); const { buildSchema } = require('graphql'); const graphqlHTTP = require('express-graphql'); let port = 3000; let schema = buildSchema(` type Query { postTitle: String, blogTitle: String } `); let root = { postTitle: () => { return 'Build a Simple GraphQL Server With Express and NodeJS'; }, blogTitle: () => { return 'scotch.io'; } }; const app = express(); app.use('/', graphqlHTTP({ schema: schema, rootValue: root, graphiql: true
Jetzt können Sie `example.js` im Terminal ausführen:
node example.js
Jetzt können Sie auf localhost: 3000 GraphiQL entdecken. Damit können Sie Ihre API in einem Browser testen. Es unterstützt die automatische Vervollständigung und trifft Annahmen für Sie basierend auf den in Ihrem Schema verfügbaren Typen und Feldern.

Fordern wir nun unser Schema für "blogTitle" an:

So einfach können Sie die GraphQL-API anfordern.
Einführung
Jetzt verstehen Sie, wie GraphQL funktioniert, und wir können das Thema tiefer beginnen.
Beginnen wir mit der Erstellung eines GraphQL-Servers auf Basis von Express. Erstellen Sie nun in unserem Ordner den Ordner "src" und erstellen und speichern Sie darin die Datei "schema.js". Diese Datei sieht folgendermaßen aus:
Als nächstes erstellen Sie den Ordner "data" im Ordner "src". Wir werden 2 Dateien darin platzieren: 'autoren.js' und 'posts.js'.
Der Inhalt dieser Dateien ist ziemlich groß, sodass Sie sie nicht über einen
Link zu Github oder unter dem Spoiler abrufen können.
Autoren.js const Authors = [ { id: '8dlx7ak38fd39dv79ad', name: 'Orinami Olatunji', twitterHandle: '@orinami_' }, { id: 'jd3kd03d0w9a0l35rh74', name: 'Ojima Udale', twitterHandle: '@uncooloj' }, { id: '0hy894hf0dlkfh9oinv', name: 'Xabi Alonso', twitterHandle: '@alonso' } ]; module.exports = Authors;
posts.js const Posts = [ {'id':'0176413761b289e6d64c2c14a758c1c7','author_id':'0hy894hf0dlkfh9oinv','author':'alonso', 'category':'meteor','body':'Most developers and companies use two different apps for the marketing website and for the app itself. Thus, they can update each of the apps without affecting the other. [Stripe](https://stripe.com/), [Digital Ocean](https://www.digitalocean.com/) and many other companies follow this technique. Most Meteor apps also do the same.\n\nSo, in a scenario like this, sometimes we need to show the login state of the app on the landing page too. For an example, see our Kadira home page (\u003chttps://kadira.io\u003e). If you are logged into the Kadira app (\u003chttps://ui.kadira.io\u003e), we show a button with "Open Kadira UI" on the home page, which replaces the login button.\n\n[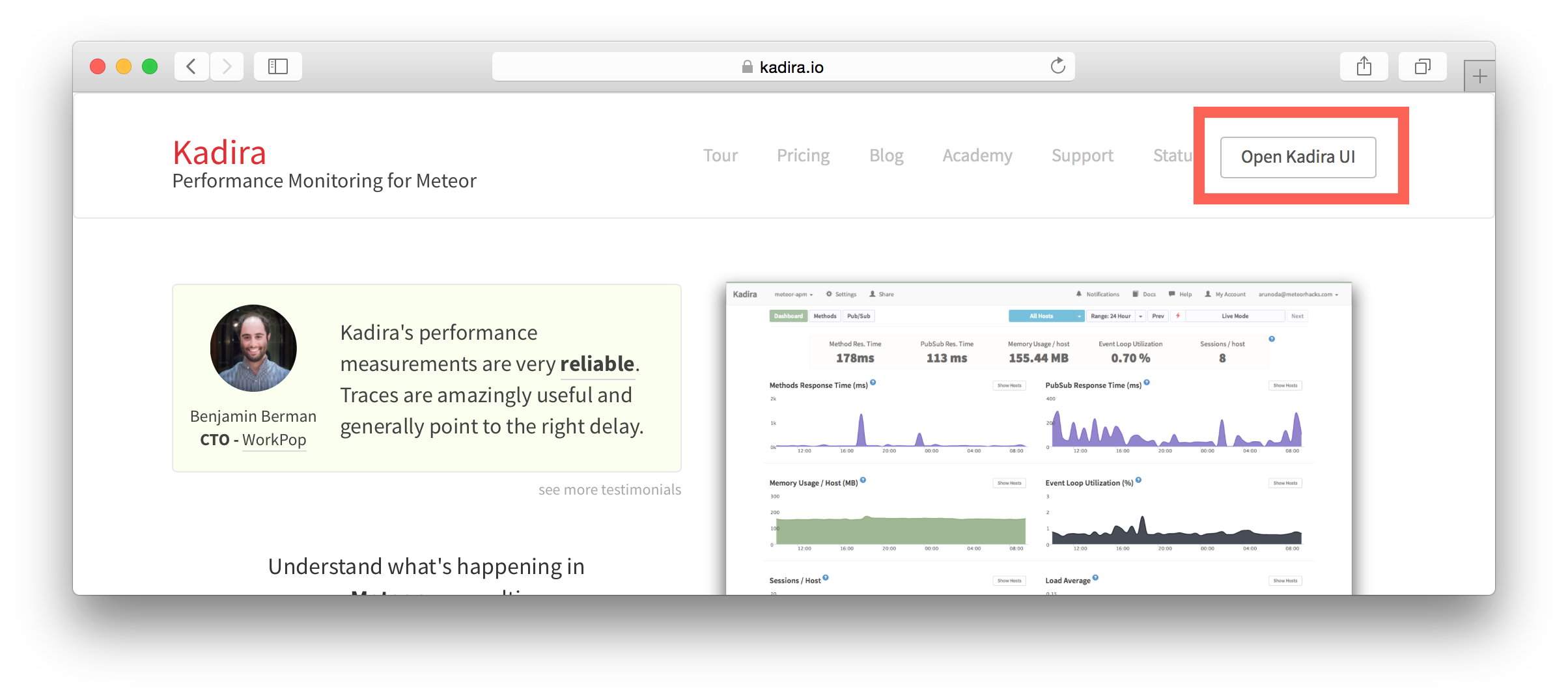](https://kadira.io)\n\n## How Did We Do It?\n\nMeteor does not have a built-in way to share login states across multiple apps or subdomains. So, we have to find an alternative way to do so.\n\nAs a solution, we can use browser cookies to share the login state between multiple domains. That\'s exactly what we did. We wrapped this up into a Meteor package, which now you can also use.\n\nIn this guide, I\'m going to explain how to share the login state between multiple domains using the [`kadira:login-state`](https://github.com/kadirahq/meteor-login-state) package.\n\n### On Meteor App\n\nFirst of all, install the `kadira:login-state` package in your Meteor app:\n\n~~~\nmeteor add kadira:login-state\n~~~\n\nThen, you need to add a new entry in the `public` object as the `loginState` in the `settings.json` file for your app. (If you haven\'t created the settings.json yet, you need to create it first.)\n\n~~~json\n{\n "public": {\n "loginState": {\n "domain": ".your-domain-name.com",\n "cookieName": "app-login-state-cookie-name"\n }\n }\n}\n~~~\n\nThe `domain` field must be your main domain name, starting with a dot. It allows you to share the login state, which can be accessed from any of its subdomains. You can use any appropriate identifier, such as `cookieName`.\n\nNow, everything has been set up on the Meteor app.\n\n### On the Static App (the Landing Page)\n\nNow we have to show the login state of the app on the landing page. For this, we need to add support for the login state for the static app (or landing page).\n\nActually, there are three different ways to do this. Here I will show you how to do so by pasting a few lines of JavaScript code.\n\nYou need to create a JavaScript file in your js folder. I create it as `js/login_state.js`. After that, copy and paste the following code snippet into it:\n\n~~~javascript\nLoginState = {};\n\nLoginState.get = function(cookieName) {\n var loginState = getCookie(cookieName);\n if(loginState) {\n return JSON.parse(decodeURIComponent(loginState));\n } else {\n return false;\n }\n};\n\nfunction getCookie(cname) {\n var name = cname + "=";\n var ca = document.cookie.split(\';\');\n for(var i=0; i \u003c ca.length; i++) {\n var c = ca[i];\n while (c.charAt(0)==\' \') c = c.substring(1);\n if (c.indexOf(name) != -1) return c.substring(name.length,c.length);\n }\n return;\n}\n~~~\n\nInsert that file into the head section of your HTML document: \n\n`\u003cscript src="js/login-state.js"\u003e\u003c/script\u003e`\n\n\u003e If you prefer, you can also use [Browserify](https://github.com/kadirahq/meteor-login-state#installing-via-browserify) or [Bower](https://github.com/kadirahq/meteor-login-state#installing-via-bower) to load the above JS file.\n\u003e The package name for both Browserify and Bower is `meteor-login-state`.\n\nThen, use the following code to get the login state of your app. You need to provide the relevant `cookieName` to do so: \n\n~~~javascript\nvar loginState = LoginState.get("app-login-state-cookie-name");\nif(loginState) {\n // the user has loggedIn to the meteor app\n // see the loginState Object for the addtional data\n // (append your code here!)\n console.log(loginState);\n} else {\n // user has not loggedIn yet.\n // (append your code here!) \n}\n~~~\n\nThe `loginState` object will be something like this:\n\n~~~json\n{\n timestamp: 1435835751489,\n username: "username",\n userId: "meteor-user-id",\n email: "user@email.com"\n url: "https://ui.kadira.io"\n}\n~~~\n\nNow you can do whatever you need to do with the login state.\n\nGive it a try and let me know what you think.','date':{'$date':'2015-07-07T00:00:00.000Z'},'layout':'blog_post','slug':'sharing-meteor-login-state-between-sub-domains','summary':'In this blog we\'ll show you how we shared login state between our static web app and our Meteor app Kadira UI.','title':'Sharing the Meteor Login State Between Subdomains'}, {'id':'03390abb5570ce03ae524397d215713b','author_id':'0hy894hf0dlkfh9oinv','author':'alonso', 'category':'product','body':'Here is a common feedback we received from our users:\n\n\u003e Hi, I have a suggestion. It would be great if I could "dismiss" errors or mark them as resolved on my end. This way, I can keep track of which errors I have resolved.\n\nToday we are happy to announce new Kadira feature which allows you to track **status** to errors. With that, you can mark errors as "Ignored", "Fixing" or "Fixed".\n\nOnce you mark an error as "Ignored", it will be hidden. \n\nBut you can click on "Show Ignored Errors" checkbox or filter by "ignored" status to view them again.\n\n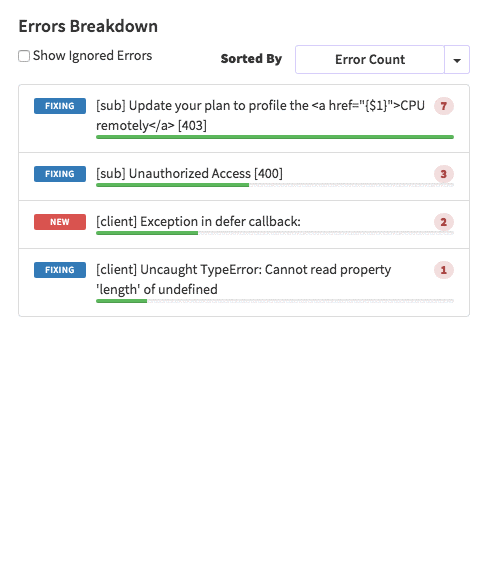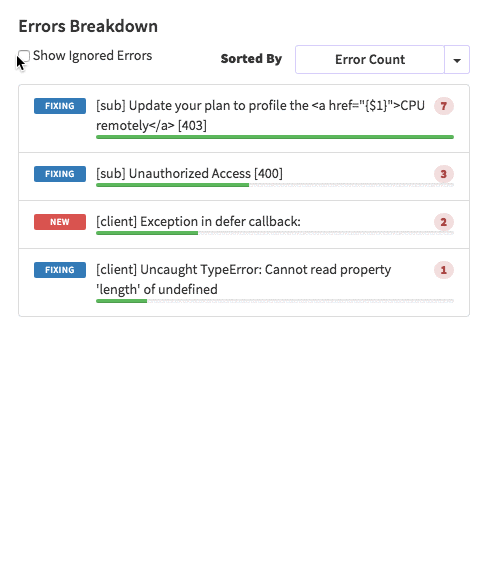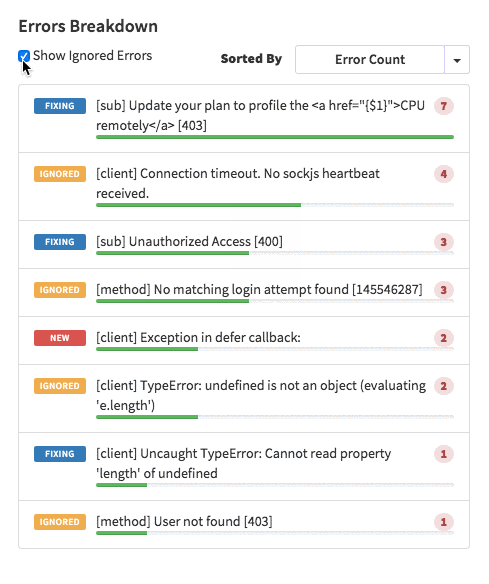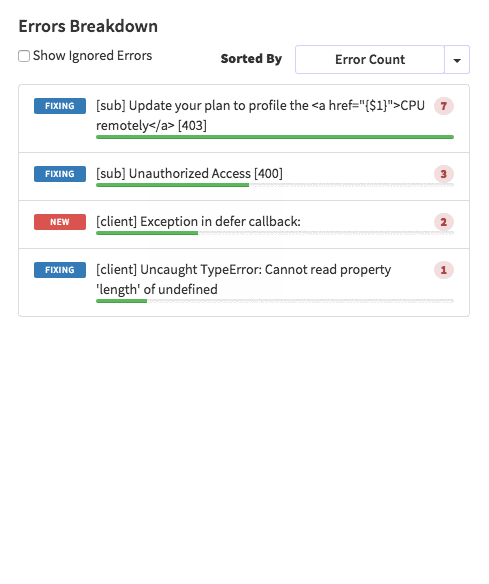\n\nYou can also filter errors by status like this:\n\n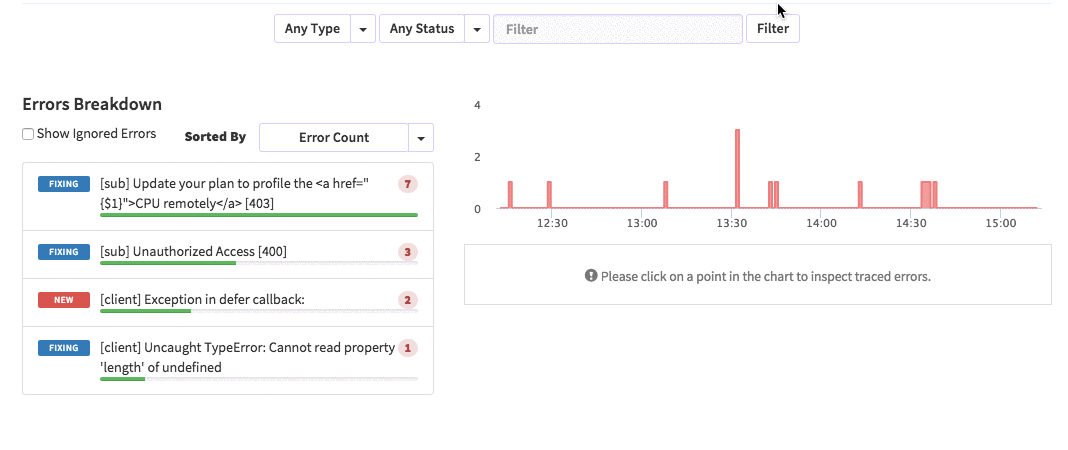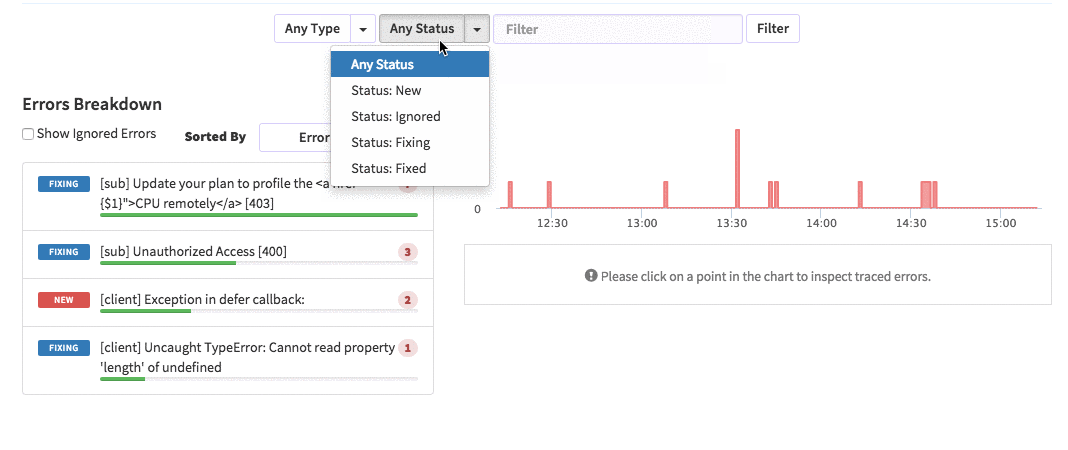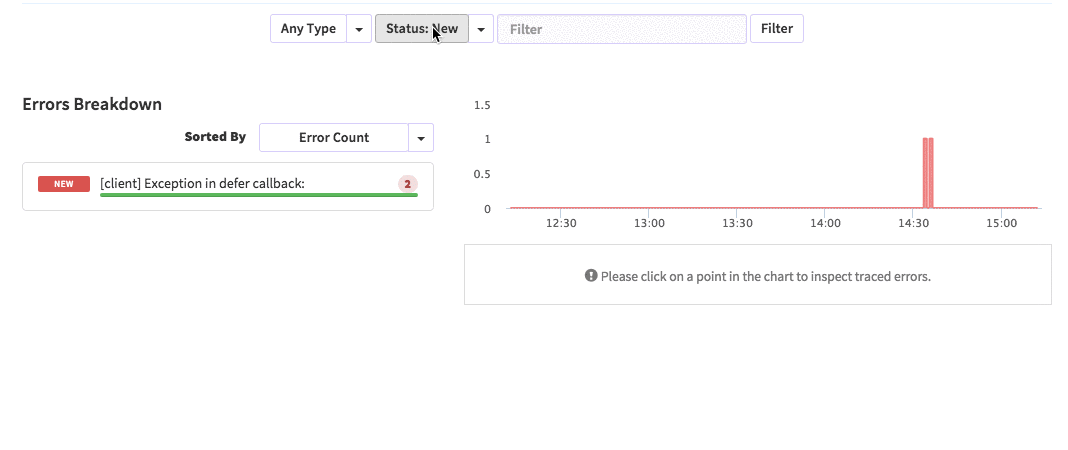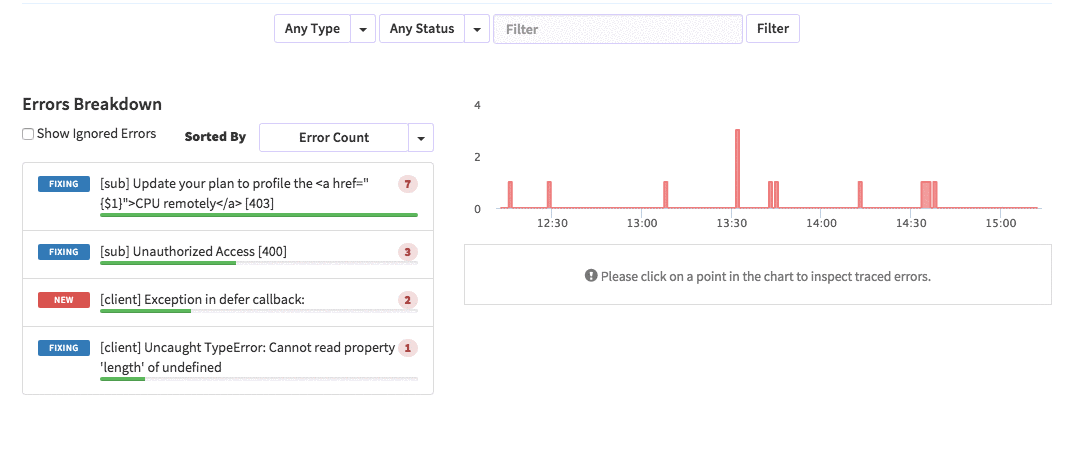\n\nWe are rolling out this feature to all our paid users. [Give it a try](https://ui.kadira.io/apps/AUTO/errors/overview?metric=count).\n\n### What's next?\n\nRight now we are planning to add few more feature related this. Could you help us on [prioritizing](https:
Typen in GraphQL
GraphQL hat das Modul 'grapql / type', mit dem der Typ bestimmt wird. Typen können aus dem Modul 'graphql / type' oder aus dem Stammmodul 'graphql' importiert werden.Grundlegende Typen sind ID , String , Int , Float und Boolean . Wir fügen auch den Autorentyp hinzu. Fügen Sie dazu unserer Datei schema.js Folgendes hinzu: const AuthorType = new GraphQLObjectType({ name: "Author", description: "This represent an author", fields: () => ({ id: {type: new GraphQLNonNull(GraphQLString)}, name: {type: new GraphQLNonNull(GraphQLString)}, twitterHandle: {type: GraphQLString} }) });
Wie Sie sehen können, mussten wir zum Hinzufügen eines neuen Typs ein Objekt der GraphQLObjectType-Klasse erstellen und einige seiner Eigenschaften vorschreiben. Name und Beschreibung - um den Typ zu beschreiben, Felder zum Definieren von Attributen des Typs Autor: ID, Name und TwitterHandler.Weitere Details zu Typen finden Sie unter graphql.org/graphql-js/type/.Jetzt erstellen wir einen Typ für Beiträge: const PostType = new GraphQLObjectType({ name: "Post", description: "This represent a Post", fields: () => ({ id: {type: new GraphQLNonNull(GraphQLString)}, title: {type: new GraphQLNonNull(GraphQLString)}, body: {type: GraphQLString}, author: { type: AuthorType, resolve: function(post) { return _.find(Authors, a => a.id == post.author_id); } } }) });
Fügen Sie dies zu schema.js hinzu. Dadurch wird ein PostType-Objekt erstellt, das in der Stammabfrage verwendet wird (wörtlich die Stammabfrage. Tatsächlich der Einstiegspunkt in unsere GraphQL-API).Wurzel Wurzel
Die Stammabfrage wird verwendet, um die Ressourcen anzuzeigen, die den Clients Ihrer Anwendung zur Verfügung stehen. Wir könnten 2 Ressourcen zur Verfügung stellen: Autoren und Beiträge.Fügen wir unserer Datei "schema.js" Folgendes hinzu: const BlogQueryRootType = new GraphQLObjectType({ name: 'BlogAppSchema', description: "Blog Application Schema Query Root", fields: () => ({ authors: { type: new GraphQLList(AuthorType), description: "List of all Authors", resolve: function() { return Authors } }, posts: { type: new GraphQLList(PostType), description: "List of all Posts", resolve: function() { return Posts } } }) });
Hier ist die Stammabfrage als BlogQueryRootType definiert. Wenn Sie bemerken, wurde hier ein neuer Typ deklariert: new GraphQLList (). Es wird ein Wrapper um andere Typen erstellt, der eine Liste dieser Typen darstellt.Schemadefinition
Das Diagramm definiert, wie die Daten in Ihrer Anwendung generiert werden sollen und wie die Daten miteinander verbunden werden sollen. Die Definition des Schemas wirkt sich darauf aus, wie die Daten in Ihrer Datenbank (oder Ihren Datenbanken) gespeichert werden. In der Schemadefinition bestimmen Sie auch, welche Abfragen, Mutationen und Abonnements für Ihre Datenanzeigeschnittstelle verfügbar sind.Fügen wir unserer Datei ein Schema hinzu: const BlogAppSchema = new GraphQLSchema({ query: BlogQueryRootType });
Hier wird der Abfrage das BlogQueryRootType-Objekt zugewiesen, das als Root-API-Anforderung verwendet wird.Implementierung der GraphQL-API
Wir brauchen das `lodash` Paket. `Lodash` ist ein Javascript-Toolkit, das saubere, leistungsstarke Methoden zum Bearbeiten von Objekten und Sammlungen bietet. Wenn Sie mit der Unterstrichbibliothek vertraut waren, ist dies großartig! Lodash wurde daraus erstellt, indem zusätzliche Funktionen hinzugefügt und einige Probleme mit der Unterstrichleistung gelöst wurden. npm install lodash --save
Mit diesem Befehl wird die lodash-Bibliothek installiert und die entsprechende Abhängigkeit zur Datei package.json hinzugefügt.Fügen Sie den folgenden Code oben in die Datei schema.js ein. const _ = require('lodash');
Schauen wir uns nun die Datei schema.js an. So sollte die Datei am Ende aussehen. const _ = require('lodash');
Wenn Sie in PostType feststellen, haben wir ein zusätzliches Auflösungsattribut. Auflösen ist eine Funktion, mit der Daten bearbeitet, ihre Werte konvertiert usw. werden können. und bringen Sie sie zum Ende der Operation zurück.BlogAppSchema wird mithilfe von module.exports in die Datei server.js exportiert. Erstellen Sienun die Datei server.js im Stammordner und fügen Sie den folgenden Code hinzu: const express = require('express'); const graphqlHTTP = require('express-graphql'); const schema = require('./src/schema.js'); let port = 3000; const app = express(); app.use('/', graphqlHTTP({ schema: schema, graphiql: true })); app.listen(port); console.log('GraphQL API server running at localhost:'+ port);
Überprüfen Sie jetzt unser Ergebnis auf localhost: 3000. Öffnen Sie dazu ein Terminal und führen Sie folgende Schritte aus: node server.js
Ergebnis:
 Dies ist graphiql, es hilft Ihnen, die API im Browser zu testen. Also die folgende Abfrage:
Dies ist graphiql, es hilft Ihnen, die API im Browser zu testen. Also die folgende Abfrage: { posts { id title author { name } } }
Wird ein Ergebnis wie dieses geben: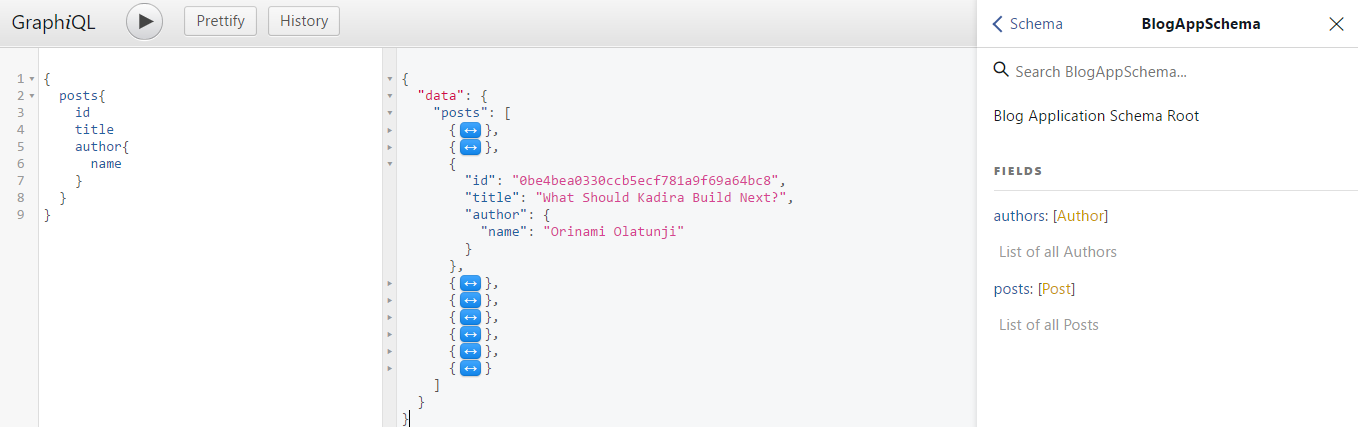
Fazit
Ich bin so froh, dass ich diese Lektion mit dir beendet habe. Jetzt wissen Sie, wie Sie eine GraphQL-API basierend auf Express und NodeJS erstellen. Ich hoffe, die Lektion war interessant und Sie haben viel daraus gelernt.Wenn Sie mehr über GraphQL erfahren möchten, besuchen Sie graphql.org .