 Vor sechs Monaten haben wir die Migration aller unserer zustandslosen Dienste auf Kubernetes abgeschlossen. Auf den ersten Blick ist die Aufgabe recht einfach: Sie müssen einen Cluster bereitstellen, Anwendungsspezifikationen schreiben und loslegen. Aufgrund der Besessenheit, Stabilität in der Arbeit unseres Dienstes zu gewährleisten, musste ich sofort verstehen, wie k8s funktionieren, und verschiedene Fehlerszenarien testen. Die meisten Fragen, die ich zu allem hatte, was mit dem Netzwerk zu tun hatte. Eines dieser schlüpfrigen Probleme ist der Betrieb von Diensten in Kubernetes.
Vor sechs Monaten haben wir die Migration aller unserer zustandslosen Dienste auf Kubernetes abgeschlossen. Auf den ersten Blick ist die Aufgabe recht einfach: Sie müssen einen Cluster bereitstellen, Anwendungsspezifikationen schreiben und loslegen. Aufgrund der Besessenheit, Stabilität in der Arbeit unseres Dienstes zu gewährleisten, musste ich sofort verstehen, wie k8s funktionieren, und verschiedene Fehlerszenarien testen. Die meisten Fragen, die ich zu allem hatte, was mit dem Netzwerk zu tun hatte. Eines dieser schlüpfrigen Probleme ist der Betrieb von Diensten in Kubernetes.
Die Dokumentation sagt uns:
- rollen Sie die Anwendung aus
- Lebendigkeits- / Bereitschaftsproben festlegen
- Erstellen Sie einen Dienst
- dann funktioniert alles: Lastausgleich, Failover usw.
In der Praxis ist jedoch alles etwas komplizierter. Mal sehen, wie es tatsächlich funktioniert.
Ein bisschen Theorie
Außerdem meine ich, dass der Leser bereits mit dem kubernetes-Gerät und seiner Terminologie vertraut ist. Wir erinnern uns nur daran, was ein Dienst ist.
Service ist die Essenz von k8s, die eine Reihe von Herden und Methoden für den Zugriff auf diese beschreibt.
Zum Beispiel haben wir unsere Anwendung gestartet:
apiVersion: apps/v1 kind: Deployment metadata: name: webapp spec: selector: matchLabels: app: webapp replicas: 2 template: metadata: labels: app: webapp spec: containers: - name: webapp image: defaultxz/webapp command: ["/webapp", "0.0.0.0:80"] ports: - containerPort: 80 readinessProbe: httpGet: {path: /, port: 80} initialDelaySeconds: 1 periodSeconds: 1
$ kubectl get pods -l app=webapp NAME READY STATUS RESTARTS AGE webapp-5d5d96f786-b2jxb 1/1 Running 0 3h webapp-5d5d96f786-rt6j7 1/1 Running 0 3h
Um darauf zugreifen zu können, müssen wir einen Dienst erstellen, in dem wir bestimmen, auf welche Kanäle wir zugreifen möchten (Selektor) und auf welchen Ports:
kind: Service apiVersion: v1 metadata: name: webapp spec: selector: app: webapp ports: - protocol: TCP port: 80 targetPort: 80
$ kubectl get svc webapp NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE webapp ClusterIP 10.97.149.77 <none> 80/TCP 1d
Jetzt können wir von jedem Computer im Cluster aus auf unseren Service zugreifen:
curl -i http://10.97.149.77 HTTP/1.1 200 OK Date: Mon, 24 Sep 2018 11:55:14 GMT Content-Length: 2 Content-Type: text/plain; charset=utf-8
Wie funktioniert das alles?
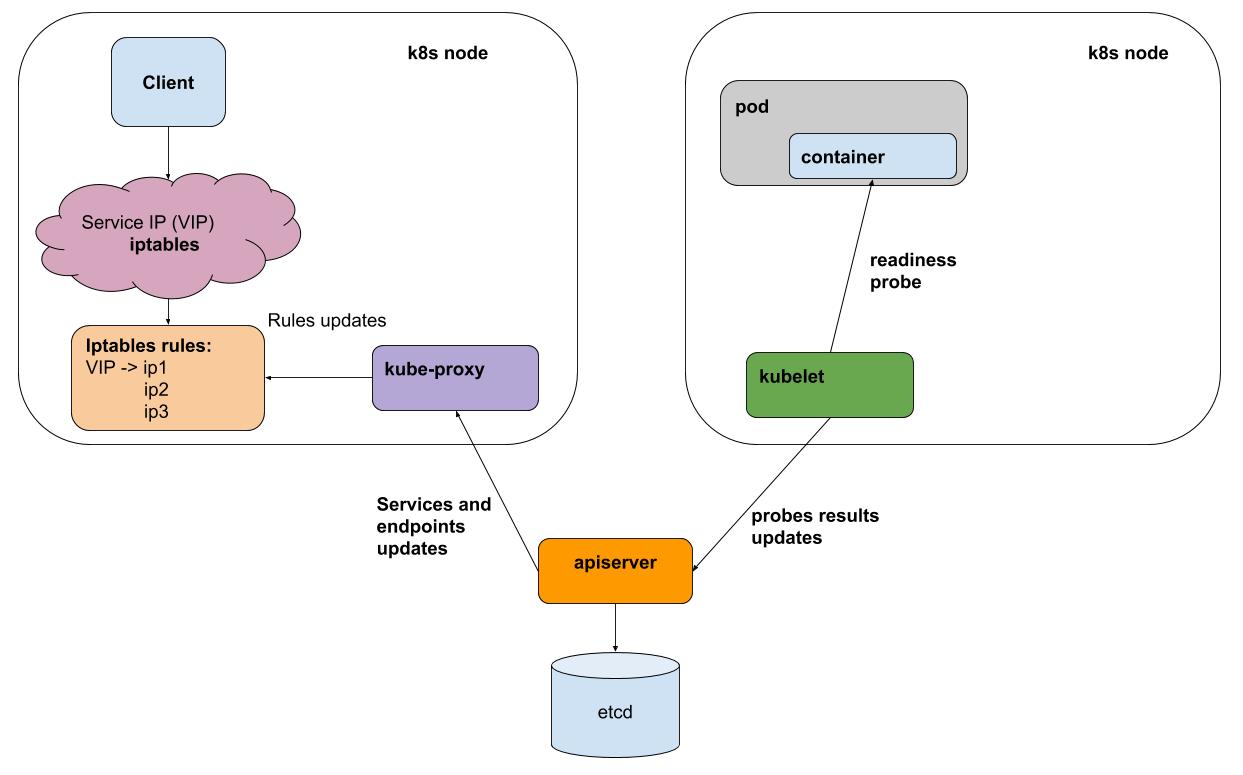
Sehr vereinfacht:
- Sie haben kubectl die Bereitstellungsspezifikationen angewendet
- Magie passiert, deren Details in diesem Zusammenhang nicht wichtig sind
- Infolgedessen stellte sich heraus, dass sich Arbeitsknoten der Anwendung auf einigen Knoten befanden
- Sobald jedes Kubelet-Intervall (k8s-Agent auf jedem Knoten) Liveness / Readiness-Samples aller auf seinem Knoten ausgeführten Pods durchführt, sendet es die Ergebnisse an einen Apiserver (Schnittstelle zu k8s-Gehirnen).
- kube-proxy auf jedem Knoten erhält von apiserver Benachrichtigungen über alle Änderungen an Diensten und Herden, die an Diensten teilnehmen
- kube-proxy spiegelt alle Änderungen in der Konfiguration der zugrunde liegenden Subsysteme (iptables, ipvs) wider.
Betrachten Sie der Einfachheit halber die Standard-Proxy-Methode - iptables. In iptables haben wir für unsere virtuelle IP 10.97.149.77:
-A KUBE-SERVICES -d 10.97.149.77/32 -p tcp -m comment --comment "default/webapp: cluster IP" -m tcp --dport 80 -j KUBE-SVC-BL7FHTIPVYJBLWZN
Der Verkehr geht an die Kette KUBE-SVC-BL7FHTIPVYJBLWZN , in der er auf zwei andere Ketten verteilt ist
-A KUBE-SVC-BL7FHTIPVYJBLWZN -m comment --comment "default/webapp:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-UPKHDYQWGW4MVMBS -A KUBE-SVC-BL7FHTIPVYJBLWZN -m comment --comment "default/webapp:" -j KUBE-SEP-FFCBJRUPEN3YPZQT
Das sind unsere Schoten:
-A KUBE-SEP-UPKHDYQWGW4MVMBS -p tcp -m comment --comment "default/webapp:" -m tcp -j DNAT --to-destination 10.244.0.10:80 -A KUBE-SEP-FFCBJRUPEN3YPZQT -p tcp -m comment --comment "default/webapp:" -m tcp -j DNAT --to-destination 10.244.0.11:80
Testen des Ausfalls eines der Herde
Meine Webapp-Testanwendung kann in den "Fehlerausschlag" -Modus wechseln. Dazu müssen Sie die URL "/ err" abrufen.
Die Ergebnisse von ab -c 50 -n 20.000 in der Mitte des Tests zogen "/ err" an einem der Herde:
Complete requests: 20000 Failed requests: 3719
Der Punkt hier ist nicht die spezifische Anzahl von Fehlern (ihre Anzahl variiert je nach Last), sondern dass sie es sind. Im Allgemeinen haben wir das "schlechte" aus dem Gleichgewicht gebracht, aber zum Zeitpunkt des Wechsels hat der Client des Dienstes Fehler erhalten. Die Ursache der Fehler ist leicht zu erklären: Bereitschaftstests werden einmal pro Sekunde + sogar kurze Zeit für die Verbreitung von Informationen durchgeführt, die nicht auf den Test reagiert haben.
Hilft IPVS-Backend für kube-proxy (experimentell)?
Nicht wirklich! Es löst das Problem der Proxy-Optimierung, bietet einen benutzerdefinierten Ausgleichsalgorithmus, löst jedoch nicht das Problem der Fehlerverarbeitung.
Wie man ist
Dieses Problem kann nur von einem Balancer gelöst werden, der es erneut versuchen kann. Mit anderen Worten, für http benötigen wir einen L7-Balancer. Solche Balancer für Kubernetes werden bereits in vollem Umfang verwendet, entweder in Form von Ingress (es war als Punkt beim Umzug in den Cluster gedacht, aber im Großen und Ganzen macht es genau das, was es benötigt) oder als Implementierung einer separaten Schicht - beispielsweise eines Service- Meshs , istio .
In unserer Produktion haben wir aufgrund der zusätzlichen Komplexität noch nicht begonnen, Ingress- oder Service-Mesh zu verwenden. Solche Abstraktionen helfen meiner Meinung nach in Fällen, in denen Sie häufig eine große Anzahl von Diensten konfigurieren müssen. Gleichzeitig "bezahlen" Sie die Steuerbarkeit und die einfache Infrastruktur. Sie werden zusätzliche Zeit aufwenden, um herauszufinden, wie Sie die Rertai und Zeitüberschreitungen für einen bestimmten Dienst einrichten.
Wie geht es uns?
Wir nutzen kopflose k8s-Dienste. Solche Dienste haben keine virtuelle IP und dementsprechend sind kube-proxy und iptables nicht an ihrer Arbeit beteiligt. Für jeden dieser Dienste können Sie eine Liste der Live-Herde entweder über das DNS oder über die API abrufen.
Für Anwendungen, die mit anderen Diensten interagieren, stellen wir mit Gesandten einen Beiwagencontainer her. Evoy erhält regelmäßig eine aktuelle Liste der Pods für alle erforderlichen Dienste über DNS. Vor allem kann es im Fehlerfall Anfragen für andere Pods wiederholen. Sie können es als DaemonSet auf jedem Knoten ausführen. Wenn diese Instanz jedoch fehlschlägt, funktionieren alle Anwendungen, die sie verwenden, nicht mehr. Da der Ressourcenverbrauch dieses Proxys recht gering ist, haben wir uns für die Sidecar-Container-Variante entschieden.
Dies ist im Wesentlichen genau das, was istio tut, aber in unserem Fall hat sich das Gleichgewicht in Richtung Einfachheit verschoben (keine Notwendigkeit, istio zu lernen, auf seine Fehler zu stoßen). Vielleicht ändert sich dieses Gleichgewicht und wir werden anfangen, so etwas wie istio zu verwenden.
Wir bei okmeter.io kubernetes haben definitiv Wurzeln geschlagen und glauben an die weitere Verbreitung. Unterstützung für die Überwachung von k8s in unserem Service ist unterwegs, bleiben Sie dran!