Hallo allerseits!
Heute werde ich Ihnen sagen, wie wir bei
hh.ru manuelle Statistiken zu Experimenten betrachten. Wir werden sehen, woher die Daten stammen, wie wir sie verarbeiten und auf welche Fallstricke wir stoßen. In diesem Artikel werde ich eine gemeinsame Architektur und einen gemeinsamen Ansatz vorstellen. Es wird ein Minimum an echten Skripten und Code geben. Das Hauptpublikum sind unerfahrene Analysten, die sich für die Struktur der Datenanalyse-Infrastruktur in hh.ru interessieren. Wenn dieses Thema interessant sein wird - schreiben Sie in die Kommentare, wir können uns mit dem Code in den folgenden Artikeln befassen.
In unserem
anderen Artikel erfahren Sie, wie automatische Metriken für A / B-Experimente berücksichtigt werden.

Welche Daten analysieren wir und woher kommen sie?
Wir analysieren Zugriffsprotokolle und alle benutzerdefinierten Protokolle, die wir selbst schreiben.
95.108.213.12 - - [13 / Aug / 2018: 04: 00: 02 +0300] 200 "GET / Arbeitgeber / 2574971 HTTP / 1.1" 12012 "-" Mozilla / 5.0 (kompatibel; YandexBot / 3.0; + http: / /yandex.com/bots) "-" gardabani.headhunter.ge "" 0.063 "-" 1534122002.858 "-" 192.168.2.38:1500 "[0.064] {15341220027959c8c01c51a6e01b682f} 200 https 1 -" - "- - [35827] [0,000 0]
178.23.230.16 - - [13 / Aug / 2018: 04: 00: 02 +0300] 200 "GET / vacancy / 24266672 HTTP / 1.1" 24229 " hh.ru/vacancy/24007186?query=bmw " "Mozilla / 5.0 ( Macintosh; Intel Mac OS X 10_10_5) AppleWebKit / 603.3.8 (KHTML, wie Gecko) Version / 10.1.2 Safari / 603.3.8 - hh.ru 0.210 last_visit = 1534111115966 :: 1534121915966; hhrole = anonym; Regionen = 1; tmr_detect = 0% 7C1534121918520; total_searches = 3; unique_banner_user = 1534121429.273825242076558 1534122002.859 - 192.168.2.239:1500 [0.208] {1534122002649b7eef2e901d8c9c0469} 200 https 1 - "-" - [35927] [0.001]
In unserer Architektur schreibt jeder Dienst Protokolle lokal und wird dann über die selbst geschriebenen Client-Server-Protokolle (einschließlich Nginx-Zugriffsprotokollen) in einem zentralen Repository gesammelt (im Folgenden Protokollierung). Entwickler haben Zugriff auf diesen Computer und können die Protokolle bei Bedarf manuell protokollieren. Aber wie können in angemessener Zeit mehrere hundert Gigabyte an Protokollen verschlungen werden? Gießen Sie sie natürlich in Hadoop!
Woher kommen die Daten in Hadoop?
Hadoop speichert nicht nur Serviceprotokolle, sondern lädt auch die Produktdatenbank hoch. Jeden Tag laden wir in hadoop einige der Tabellen hoch, die für die Analyse benötigt werden.
Serviceprotokolle gelangen auf drei Arten in Hadoop.
- Weg zur Stirn - cron wird nachts aus dem Protokollspeicher gestartet, und rsync lädt Rohprotokolle auf hdfs hoch.
- Der Weg ist in Mode - Protokolle von Diensten werden nicht nur in den gemeinsamen Speicher, sondern auch in Kafka gegossen, wo Flume sie liest, vorverarbeitet und in HDFS speichert.
- Der Pfad ist altmodisch - in den Tagen vor kafka haben wir unseren eigenen Service geschrieben, der Rohprotokolle aus dem Speicher liest, aus der Vorverarbeitung herausholt und auf hdfs hochlädt.
Lassen Sie uns jeden Ansatz genauer betrachten.
Stirnpfad
Cron führt ein reguläres Bash-Skript aus.
Wie wir uns erinnern, haben alle Protokolle im Protokollrepository die Form gewöhnlicher Dateien. Die Ordnerstruktur sieht ungefähr so aus: /logging/java/2018/08/10/{service_nameasure/*.log
Hadoop speichert seine Dateien in ungefähr derselben Ordnerstruktur wie hdfs-raw / banner-version / year = 2018 / month = 08 / day = 10
Jahr, Monat, Tag verwenden wir als Partitionen.
Daher müssen wir nur die richtigen Pfade bilden (Zeilen 3-4), dann alle erforderlichen Protokolle auswählen (Zeile 6) und sie mit rsync in hadoop (Zeile 8) füllen.
Die Vorteile dieses Ansatzes:- Schnelle Entwicklung
- Alles ist transparent und klar.
Nachteile:Modischer Weg
Da wir die Protokolle mit einem selbstgeschriebenen Skript in das Repository hochladen, war es logisch, die Möglichkeit zu schrauben, sie nicht nur auf den Server, sondern auch auf kafka hochzuladen.
Vorteile- Online-Protokolle (Protokolle in Hadoop werden angezeigt, wenn Sie Kafka ausfüllen)
- Sie können eine Vorverarbeitung durchführen
- Es hält die Last gut und Sie können große Protokolle hochladen
Nachteile- Schwierigeres Setup
- Ich muss Code schreiben
- Weitere Teile des Gießprozesses
- Kompliziertere Überwachung und Analyse von Vorfällen
Altmodische Art und Weise
Es unterscheidet sich von der Mode nur in Abwesenheit von Kafka. Daher erbt es alle Nachteile und nur einige der Vorteile des vorherigen Ansatzes. Ein separater Dienst (ustats-uploader) in Java liest regelmäßig die erforderlichen Dateien, verarbeitet sie vor und lädt sie auf hadoop hoch.
Vorteile- Sie können eine Vorverarbeitung durchführen
Nachteile- Schwierigeres Setup
- Ich muss Code schreiben
Und so kamen die Daten in Hadoop und bereit für die Analyse. Lassen Sie uns ein wenig innehalten und uns daran erinnern, was Hadoop ist und warum Hunderte von Gigabyte viel schneller als normales Grep darauf verbraucht werden können.
Hadoop
Hadoop ist ein verteiltes Data Warehouse. Die Daten liegen nicht auf einem separaten Server, sondern werden auf mehrere Computer verteilt und auch nicht in einer Instanz, sondern in mehreren gespeichert - dies wurde durchgeführt, um die Zuverlässigkeit sicherzustellen. Die Basis der Datenverarbeitungsgeschwindigkeit liegt in einer Änderung des Ansatzes im Vergleich zu herkömmlichen Datenbanken.
Bei einer regulären Datenbank extrahieren wir Daten daraus und senden sie an den Kunden, der eine Analyse durchführt und das Ergebnis an den Analysten zurückgibt. Um schneller zählen zu können, müssen wir viele Kunden haben und Anforderungen parallelisieren (z. B. um Daten durch Monate zu teilen - und jeder Kunde kann Daten für seinen Monat lesen).
In Hadoop ist das Gegenteil der Fall. Wir senden den Code (genau das, was wir berechnen möchten) an die Daten, und dieser Code wird im Cluster ausgeführt. Wie wir wissen, liegen Daten auf vielen Computern, sodass jeder Computer nur Code für seine Daten ausführt und das Ergebnis an den Client zurückgibt.
Viele haben wahrscheinlich von
Map-Reduce gehört , aber das Schreiben von Code für Analysen ist nicht sehr bequem und schnell, während das Schreiben in SQL viel einfacher ist. Daher gab es Dienste, die SQL für den Benutzer transparent in Kartenreduzierung verwandeln können, und der Analyst ahnt möglicherweise nicht, wie seine Anforderung tatsächlich berücksichtigt wird.
In hh.ru verwenden wir dafür Hive und Presto. Hive war der erste, aber wir bewegen uns allmählich zu Presto, weil es für unsere Anfragen viel schneller ist. Als GUI verwenden wir Farbton und Zeppelin.
Für mich ist es bequemer, Analysen in Python in Jupyter zu betrachten. Dadurch können wir sie mit einem Klick lesen und an der Ausgabe korrekt formatierte Excel-Tabellen erhalten, was viel Zeit spart. Schreiben Sie in die Kommentare, dieses Thema bezieht sich auf einen separaten Artikel.
Kehren wir zur Analyse selbst zurück.
Wie kann man verstehen, was wir berücksichtigen wollen?
Der Produktmanager hatte die Aufgabe, die Ergebnisse des Experiments zu berechnen
Wir versenden einen E-Mail-Newsletter, in dem wir geeignete Stellen für den Bewerber versenden (mag jeder solche Mailings?). Wir haben beschlossen, das Design des Briefes ein wenig zu ändern und wollen verstehen, ob es besser wurde. Dazu werden wir berücksichtigen:
- die Anzahl der Übergänge zu offenen Stellen aus dem Brief;
- Feedback nach dem Übergang
Ich möchte Sie daran erinnern, dass wir nur Zugriffsprotokoll und Datenbank haben. Wir müssen unsere Metriken in Form von Linkklicks formulieren.
Anzahl der Übergänge zu einer offenen Stelle aus einem Brief
Der Übergang ist eine GET-Anforderung an
hh.ru/vacancy/26646861 . Um zu verstehen, woher der Übergang kam, fügen wir utm-Tags des Formulars? Utm_source = email_campaign_123 hinzu. Für GET-Anfragen im Zugriffsprotokoll werden Informationen zu den Parametern angezeigt, und wir können die Übergänge nur aus unserer Mailingliste herausfiltern.
Die Anzahl der Antworten nach dem Übergang
Hier könnten wir einfach die Anzahl der Antworten auf offene Stellen aus dem Newsletter berechnen, aber dann wären die Statistiken falsch, da die Antworten durch etwas anderes beeinflusst werden könnten, außer für unseren Brief, zum Beispiel, dass eine Anzeige in ClickMe für eine freie Stelle gekauft wurde, und daher die Anzahl der Antworten stark gewachsen.
Wir haben zwei Möglichkeiten, um die Anzahl der Antworten zu formulieren:
- Die Antwort ist ein POST auf hh.ru/applicant/vacancy_response/popup?vacancy_id=26646861 , der einen Referer hh.ru/vacancy/26646861?utm_source=email_campaign_123 enthält .
- Die Nuance dieses Ansatzes besteht darin, dass wir den Benutzer nicht zählen, wenn er zu einer freien Stelle gewechselt ist und dann ein wenig auf der Website herumgelaufen ist und dann auf eine freie Stelle geantwortet hat.
- Wir können uns die ID des Benutzers merken , der zu hh.ru/vacancy/26646861 gewechselt ist , und die Anzahl der Bewertungen für die freie Stelle während des Tages basierend auf der Datenbank berechnen.
Die Wahl des Ansatzes wird von den Geschäftsanforderungen bestimmt. Normalerweise reicht die erste Option aus, aber alles hängt davon ab, worauf der Produktmanager wartet.
Fallstricke, die auftreten können
- Nicht alle Daten befinden sich in Hadoop. Sie müssen Daten aus der Produktdatenbank hinzufügen. Zum Beispiel in Protokollen normalerweise nur ID, und wenn Sie einen Namen benötigen, dann ist es in der Datenbank. Manchmal müssen Sie mit resume_id nach einem Benutzer suchen, und dieser wird auch in der Datenbank gespeichert. Dazu entladen wir einen Teil der Datenbank in hadoop, damit der Join einfacher wird.
- Daten können Kurven sein. Dies ist im Allgemeinen eine Katastrophe für Hadoop und die Art und Weise, wie wir Daten in ihn laden. Abhängig von den Daten kann ein leerer Wert null, keine, keine, eine leere Zeichenfolge usw. sein. Sie müssen in jedem Fall vorsichtig sein, da die Daten wirklich unterschiedlich sind, auf unterschiedliche Weise und für unterschiedliche Zwecke geladen werden.
- Lange Zählung für den gesamten Zeitraum. Zum Beispiel müssen wir unsere Übergänge und Antworten für den Monat berechnen. Dies sind ungefähr 3 Terabyte an Protokollen. Sogar Hadoop wird dies für einige Zeit in Anspruch nehmen. Normalerweise ist es ziemlich schwierig, eine 100% ige Arbeitsanfrage beim ersten Mal zu schreiben, daher schreiben wir sie durch Ausprobieren. Jedes Mal 20 Minuten zu warten ist eine sehr lange Zeit. Lösungsmöglichkeiten:
- Debuggen der Anforderung in den Protokollen in 1 Tag. Da wir Daten in hadoop partitioniert hatten, ist es ziemlich schnell, etwas für einen Tag Protokolle zu berechnen.
- Laden Sie die erforderlichen Protokolle in die temporäre Tabelle hoch. In der Regel verstehen wir, an welchen URLs wir interessiert sind, und können aus diesen URLs eine temporäre Tabelle für die Protokolle erstellen.
Persönlich ist die erste Option für mich bequemer, aber manchmal muss ich eine temporäre Tabelle erstellen, dies hängt von der Situation ab. - Verzerrungen in den endgültigen Metriken
- Es ist besser, die Protokolle zu filtern. Sie müssen zum Beispiel auf den Antwortcode, die Umleitung usw. achten. Besser weniger Daten, aber genauer, von denen Sie sicher sind.
- So wenige Zwischenschritte wie möglich in der Metrik. Zum Beispiel ist der Wechsel zu einer freien Stelle ein Schritt (GET-Anforderung für / freie Stelle / 123). Die Antwort ist zwei (Übergang zu Vakanz + POST). Je kürzer die Kette, desto weniger Fehler und genauer die Metrik. Manchmal kommt es vor, dass die Daten zwischen Übergängen verloren gehen und es im Allgemeinen unmöglich ist, etwas zu berechnen. Um dieses Problem zu lösen, müssen wir uns überlegen, was und wie wir berücksichtigen, bevor wir ein Experiment entwickeln. Ihr separates Protokoll der notwendigen Ereignisse hilft sehr. Wir können die notwendigen Ereignisse aufnehmen, und somit wird die Ereigniskette genauer und das Zählen ist einfacher.
- Bots können eine Reihe von Übergängen erzeugen. Sie müssen verstehen, wohin Bots gehen können (z. B. auf Seiten, auf denen eine Autorisierung erforderlich ist, sollte dies nicht der Fall sein), und diese Daten filtern.
- Große Probleme - zum Beispiel kann es in einer der Gruppen einen Bewerber geben, der 50% aller Antworten generiert. Es wird eine Reihe von Statistiken geben, solche Daten müssen auch gefiltert werden.
- Es ist schwierig zu formulieren, was im Hinblick auf das Zugriffsprotokoll zu beachten ist. Dies hilft bei der Kenntnis der Codebasis, der Erfahrung und der Chrome-Entwicklungstools. Wir lesen die Beschreibung der Metrik aus dem Produkt, wiederholen sie mit unseren Händen auf der Website und sehen, welche Übergänge generiert werden.
Lassen Sie uns abschließend darüber sprechen, wie das Ergebnis der Berechnungen aussehen soll.
Berechnungsergebnis
In unserem Beispiel gibt es 2 Gruppen und 2 Metriken, die einen Trichter bilden.
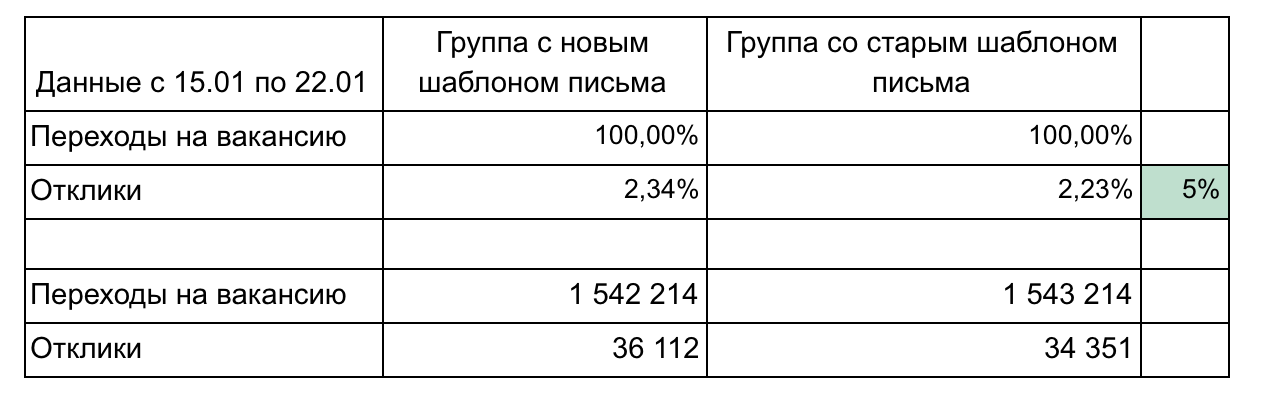
Empfehlungen für die Berichterstattung über die Ergebnisse:
- Teile nicht überladen, bis sie benötigt werden. Einfach und kleiner ist besser (hier könnten wir beispielsweise jede freie Stelle einzeln anzeigen oder nach Tag klicken). Konzentrieren Sie sich auf eine Sache.
- Während der Demo-Ergebnisse werden möglicherweise Details benötigt. Überlegen Sie sich also, welche Fragen Sie möglicherweise stellen, und bereiten Sie die Details vor. (In unserem Beispiel kann die Detaillierung der Übergangsgeschwindigkeit nach dem Senden der E-Mail entsprechen - 1 Tag, 3 Tage, eine Woche, Gruppierung der offenen Stellen nach Berufsfeldern)
- Denken Sie an die statistische Signifikanz. Beispielsweise ist eine Änderung von 1% mit 100 Klicks und 15 Klicks unbedeutend und kann zufällig sein. Verwenden Sie Taschenrechner
- Automatisieren Sie so viel wie möglich, da Sie mehrmals zählen müssen. Normalerweise möchte man schon mitten in einem Experiment verstehen, wie die Dinge laufen. Nach dem Experiment können Fragen auftauchen und Sie müssen etwas klären. Daher ist es notwendig, 3-4 Mal zu zählen, und wenn jede Berechnung eine Folge von 10 Abfragen und anschließendem manuellen Kopieren ist, um zu übertreffen, wird es weh tun und viel Zeit verbringen. Lernen Sie Python, es wird eine Menge Zeit sparen.
- Verwenden Sie eine grafische Darstellung der Ergebnisse, wenn dies gerechtfertigt ist. Mit den integrierten Hive- und Zeppelin-Tools können Sie sofort einfache Diagramme erstellen.
Es ist notwendig, verschiedene Metriken häufig zu berücksichtigen, da wir fast jede Aufgabe im Rahmen eines A / B-Experiments ausgeben. Die Berechnungen sind nicht kompliziert, nach 2-3 Experimenten wird verstanden, wie das geht. Denken Sie daran, dass in Zugriffsprotokollen viele nützliche Informationen gespeichert sind, mit denen Unternehmen Geld sparen, Ihre Idee fördern und nachweisen können, welche der Änderungsoptionen besser ist. Die Hauptsache ist, diese Informationen erhalten zu können.