TL; DR : Der Autor hat einen NetFlow / sFlow-Sammler aus GoFlow , Kafka , ClickHouse , Grafana und einer Krücke auf Go zusammengestellt.
Hallo, ich bin ein Exploiter und liebe es wirklich zu wissen, was in der Infrastruktur passiert. Und ich beschäftige mich auch gerne mit anderen Menschen, und diesmal bin ich in das Netzwerk eingestiegen.
Angenommen, Sie haben Ihre eigene Netzwerkausrüstung und eine Tüte Monolithen, Mikrodienste und Monolithen von Mikrodiensten, die mit ihren Abhängigkeiten in Form von Datenbanken, Caches und FTP-Servern am Internet haften. Und manchmal fangen einige Bewohner dieser Tasche an, in einem Netzwerk ungezogen zu spielen.
Hier nur einige Beispiele für solche Streiche:
- Backup außerhalb des vorgeschriebenen Fensters in 40 Streams;
- Konfigurationsfehler beim Senden einer Anwendung in einem DC an den Cache eines anderen DC;
- Fragen der Anwendung im nächsten Rack an denselben Cache "Geben Sie mir dieses halbe Megabyte-Objekt aus dem Cache" zweihundert Mal pro Sekunde.
SNMP-Zähler von Switch-Ports oder VMs geben nur ein ungefähres Verständnis dessen, was passiert, aber ich möchte Genauigkeit und Geschwindigkeit der Problemanalyse. Die NetFlow / IPFIX- und sFlow- Protokolle helfen dabei, indem sie umfangreiche Verkehrsinformationen direkt von Netzwerkgeräten generieren. Es bleibt, es irgendwo zu platzieren und es irgendwie zu verarbeiten.
Von den verfügbaren NetFlow-Kollektoren wurden folgende berücksichtigt:
- Flow-Tools - Ich mochte die Speicherung in Dateien nicht (es dauerte lange, bis eine Auswahl getroffen wurde, insbesondere betriebsbereite während der Reaktion auf den Vorfall) oder MySQL (eine Tabelle mit Milliarden Zeilen dort zu haben, scheint eine ziemlich düstere Idee zu sein).
- Elasticsearch + Logstash + Kibana ist eine sehr ressourcenintensive Gruppe von bis zu 6 Kernen älterer 2,2-GHz-CPU für den Empfang von 5000 Flows pro Sekunde. Mit Kibana können Sie jedoch alle Arten von Filtern in den Browser einfügen, was sehr hilfreich ist.
- vflow - mochte das Ausgabeformat nicht (JSON, das ohne Änderung nicht zur gleichen Elasticsearch hinzugefügt werden kann);
- Boxed Solutions - mochte weder den hohen Preis noch den kleinen Unterschied zum ausgewählten.
Und es wurde ausgewählt, beschrieben in der Präsentation von Louis Poinsignon auf dem RIPE 75 . Das allgemeine Schema eines einfachen Sammlers lautet wie folgt:
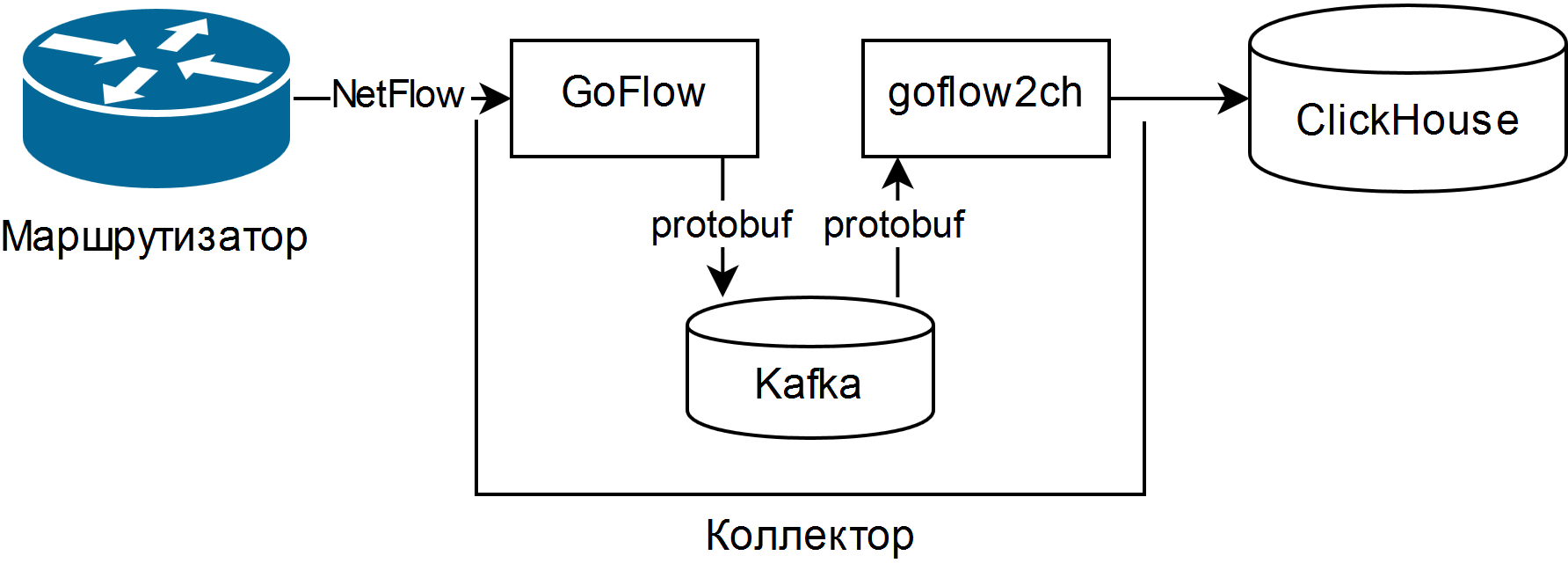
GoFlow analysiert NetFlow / sFlow-Pakete und legt sie in einem lokalen Kafka im Protobuf-Format ab. Die selbstgeschriebene „Schaufel“ goflow2ch nimmt Nachrichten von Kafka entgegen und überträgt sie stapelweise an Clickhouse, um die Produktivität zu steigern. Das Schema befasst sich überhaupt nicht mit dem Problem der Hochverfügbarkeit, aber für jede Komponente gibt es entweder reguläre oder mehr oder weniger einfache externe Möglichkeiten, sie bereitzustellen.
Tests haben gezeigt, dass die CPU-Kosten für das Parsen und Verwalten derselben 5000 Threads pro Sekunde etwa ein Viertel des CPU-Kerns ausmachen und der verwendete Speicherplatz 11 bis 14 Byte pro leicht abgeschnittenem Stream beträgt.
Zum Anzeigen von Informationen wird entweder die Web-Benutzeroberfläche für ClickHouse mit dem Namen Tabix oder das Plugin für Grafana verwendet .
Die Vorteile des Systems:
- die Fähigkeit, mit dem SQL-Dialekt beliebige Fragen zum Status des Netzwerks zu stellen;
- Geringer Ressourcenbedarf und horizontale Skalierbarkeit. Alte / langsame Prozessoren und magnetische Festplatten reichen aus.
- Bei Bedarf wird eine vollwertige Datenpipeline zur Analyse von Netzwerkereignissen gesammelt, auch in Echtzeit mithilfe von Kafka Streams, Flink oder Analoga.
- die Fähigkeit, den Speicher auf ein Minimum zu ändern.
Die Minuspunkte sind auch anständig:
- Um Fragen zu stellen, müssen Sie SQL und seinen ClickHouse-Dialekt gut kennen. Es gibt keine vorgefertigten Berichte und Grafiken.
- viele neue bewegliche Teile in Form von Kafka, Zookeeper und ClickHouse. Die ersten beiden sind in Java, was zu religiöser Ablehnung führen kann. Für mich persönlich war dies kein Problem, da dies alles schon irgendwie in der Organisation verwendet wurde;
- muss Code schreiben. Entweder eine „Schaufel“, die Daten von Kafka an ClickHouse überträgt, oder ein Adapter für die direkte Aufzeichnung von GoFlow.
Erfüllte Funktionen:
- Stellen Sie sicher, dass Sie die Drehung entsprechend der Größe der Daten in Kafka und ClickHouse anpassen, und überprüfen Sie dann, ob sie wirklich funktioniert. In Kafka ist die Größe der Protokollpartition begrenzt, und in ClickHouse - Partitionierung durch einen beliebigen Schlüssel. Eine stündliche neue Partition und das Entfernen unnötiger Partitionen alle 10 Minuten eignen sich gut für die Betriebsüberwachung und werden aus nur wenigen Zeilen zu einem Skript.
- "Schaufel" profitiert von der Verwendung von Verbrauchergruppen , sodass Sie weitere "Schaufeln" für Skalierung und Fehlertoleranz hinzufügen können.
- Mit Kafka können Sie keine Daten verlieren, wenn die "Schaufel" oder ClickHouse abstürzt (z. B. aufgrund einer starken Anforderung und / oder falsch begrenzter Ressourcen). Es ist jedoch besser, die Datenbank sorgfältig zu konfigurieren.
- Wenn Sie sFlow erfassen, denken Sie daran, dass einige Switches standardmäßig die Paketabtastrate unterwegs ändern und sie für jeden Stream angezeigt wird.
Als Ergebnis wurde ein Tool zur Überwachung der Netzwerksituation sowohl im Plus oder Minus der Echtzeit als auch in der historischen Perspektive aus Open-Source-Komponenten und blauem Isolierband erhalten. Trotz seiner Knietiefe hat er bereits dazu beigetragen, die Zeit für die zeitweise Lösung mehrerer Vorfälle zu verkürzen.