Wir haben
begonnen, die Kontrollgruppen (
Control Groups, Cgroups) in Red Hat Enterprise Linux 7 zu untersuchen - einem Mechanismus auf Kernel-Ebene, mit dem Sie die Verwendung von Systemressourcen steuern, die theoretischen Grundlagen kurz untersuchen und nun mit der Verwaltung von CPU-, Speicher- und E / A-Ressourcen fortfahren können.
Bevor Sie jedoch etwas ändern, ist es immer hilfreich herauszufinden, wie alles jetzt angeordnet ist.
Es gibt zwei Tools, mit denen Sie den Status aktiver Gruppen im System anzeigen können. Erstens ist dies systemd-cgls - ein Befehl, der eine baumartige Liste von Gruppen und laufenden Prozessen anzeigt. Ihre Ausgabe sieht ungefähr so aus:
Hier sehen wir die Top-Level-Gruppen: user.slice und system.slice. Wir haben keine virtuellen Maschinen, daher erhalten diese Gruppen der obersten Ebene unter Last 50% der CPU-Ressourcen (da das Maschinen-Slice nicht aktiv ist). In user.slice gibt es zwei untergeordnete Slices: user-1000.slice und user-0.slice. Benutzer-Slices werden durch die Benutzer-ID (UID) identifiziert, sodass die Identifizierung des Eigentümers schwierig sein kann, außer wenn Prozesse ausgeführt werden. In unserem Fall zeigen SSH-Sitzungen, dass Benutzer 1000 mrichter und Benutzer 0 root ist.
Der zweite Befehl, den wir verwenden werden, ist systemd-cgtop. Es zeigt ein Bild der Ressourcennutzung in Echtzeit (die Ausgabe von systemd-cgls wird übrigens auch in Echtzeit aktualisiert). Auf dem Bildschirm sieht es ungefähr so aus:
Bei systemd-cgtop gibt es ein Problem: Es werden nur Statistiken für die Dienste und Slices angezeigt, für die die Ressourcennutzungsabrechnung aktiviert ist. Die Abrechnung wird aktiviert, indem Drop-In-Conf-Dateien in den entsprechenden Unterverzeichnissen in / etc / systemd / system erstellt werden. Das Drop-In im folgenden Screenshot aktiviert beispielsweise die CPU- und Speichernutzung für den sshd-Dienst. Um dies selbst zu tun, erstellen Sie einfach dasselbe Drop-In in einem Texteditor. Darüber hinaus kann die Abrechnung auch mit der systemctl-Set-Eigenschaft sshd.service CPUAccounting = true-Befehl MemoryAccounting = true aktiviert werden.
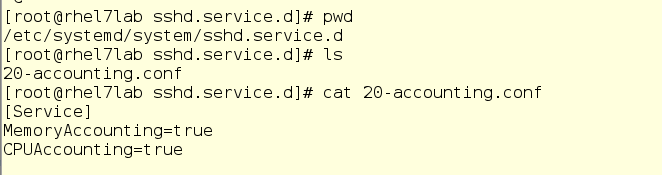
Nach dem Erstellen des Drop-Ins müssen Sie den Befehl systemctl daemon-reload sowie den Befehl systemctl restart <Dienstname> für den entsprechenden Dienst eingeben. Infolgedessen werden Statistiken zur Ressourcennutzung angezeigt. Dies führt jedoch zu einer zusätzlichen Belastung, da die Ressourcen auch für die Buchhaltung aufgewendet werden. Daher sollte die Buchhaltung sorgfältig und nur für diejenigen Dienste und Gruppen aufgenommen werden, die auf diese Weise überwacht werden müssen. Anstelle von systemd-cgtop können Sie jedoch häufig die Befehle top oder iotop verwenden.
Wechseln Sie die CPU-Bälle zum Spaß und sinnvoll
Lassen Sie uns nun sehen, wie sich eine Änderung des Prozessorkugels (CPU-Freigaben) auf die Leistung auswirkt. Zum Beispiel werden wir zwei nicht privilegierte Benutzer und einen Systemdienst haben. Der Benutzer mit dem mrichter-Login hat eine UID von 1000, die mit der Datei / etc / passwd überprüft werden kann.
Dies ist wichtig, da Benutzer-Slices nach UID und nicht nach Kontonamen benannt werden.
Lassen Sie uns nun das Drop-In-Verzeichnis durchgehen und prüfen, ob bereits etwas für das Slice vorhanden ist.
Nein, da ist nichts. Obwohl es noch etwas anderes gibt - werfen Sie einen Blick auf foo.service:
Wenn Sie mit systemd-Einheitendateien vertraut sind, sehen Sie hier eine ganz normale Einheitendatei, die den Befehl / usr / bin / sha1sum / dev / zero als Dienst (mit anderen Worten als Dämon) ausführt. Für uns ist es wichtig, dass foo benötigt wird buchstäblich alle Prozessorressourcen, die das System ihm zur Verfügung stellt. Außerdem haben wir hier eine Drop-In-Einstellung für den foo-Dienst, bei der der Wert der CPU-Bälle gleich 2048 ist. Wie Sie sich erinnern, wird er standardmäßig mit dem Wert 1024 verwendet, sodass foo unter Last einen doppelten Anteil der CPU-Ressourcen innerhalb der system.slice erhält , das übergeordnete Slice der obersten Ebene (da foo ein Dienst ist).
Führen Sie nun foo durch systemctl und sehen Sie, was der oberste Befehl uns zeigt:
Da das System praktisch keine anderen Funktionen enthält, verbraucht der foo-Dienst (pid 2848) fast die gesamte Prozessorzeit einer CPU.
Lassen Sie uns nun mrichter in die Gleichung des Benutzers einführen. Zuerst schneiden wir ihm einen CPU-Ball auf 256, dann meldet er sich an und startet foo.exe, also dasselbe Programm, aber als Benutzerprozess.
Also startete mrichter foo. Und hier ist, was der oberste Befehl jetzt zeigt:
Seltsam, oder? Der Benutzer mrichter scheint ungefähr 10 Prozent der Prozessorzeit zu bekommen, da er = 256 Bälle hat und foo.service bis zu 2048 hat, nicht wahr?
Jetzt führen wir dorf in die Gleichung ein. Dies ist ein weiterer gewöhnlicher Benutzer mit einem Standard-CPU-Ball von 1024. Er wird auch foo ausführen, und wir werden wieder sehen, wie sich die Verteilung der Prozessorzeit ändert.
dorf ist ein Benutzer der alten Schule, er startet nur den Prozess, ohne intelligente Skripte oder irgendetwas anderes. Und wieder schauen wir uns die Ausgabe von top an:
Also ... schauen wir uns den cgroups-Baum an und versuchen herauszufinden, was was ist:
Wenn Sie sich erinnern, gibt es normalerweise in einem System drei Top-Level-Gruppen: System, Benutzer und Maschine. Da es in unserem Beispiel keine virtuellen Maschinen gibt, bleiben nur System- und Benutzer-Slices übrig. Jeder von ihnen hat eine CPU-Kugel von 1024 und erhält daher unter Last die Hälfte der Prozessorzeit. Da foo.service im System lebt und es in diesem Slice keine anderen Kandidaten für die CPU-Zeit gibt, erhält foo.service 50% der CPU-Ressourcen.
Außerdem leben die Benutzer dorf und mrichter im User-Slice. Der erste Ball ist 1024, der zweite - 256. Daher erhält dorf viermal mehr Prozessorzeit als mrichter. Nun wollen wir sehen, was oben zu sehen ist: foo.service - 50%, dorf - 40%, mrichter - 10%.
Wenn wir dies in eine Anwendungsfallsprache übersetzen, können wir sagen, dass dorf eine höhere Priorität hat. Dementsprechend sind cgroups so konfiguriert, dass der Benutzer mrichter Ressourcen für die Zeit abschneidet, die er benötigt. Während mrichter allein im System war, erhielt er 50% der Prozessorzeit, da im User-Slice sonst niemand um CPU-Ressourcen konkurrierte.
In der Tat sind CPU-Bälle eine Möglichkeit, ein bestimmtes „garantiertes Minimum“ an Prozessorzeit bereitzustellen, selbst für Benutzer und Dienste mit einer niedrigeren Priorität.
Darüber hinaus haben wir die Möglichkeit, ein festes Kontingent für CPU-Ressourcen festzulegen, eine bestimmte Grenze in absoluten Zahlen. Wir werden dies für den Benutzer mrichter tun und sehen, wie sich die Verteilung der Ressourcen ändert.
Lassen Sie uns nun die Aufgaben des Benutzers dorf beenden und Folgendes passiert:
Für mrichter beträgt das absolute CPU-Limit 5%, sodass foo.service den Rest der Prozessorzeit erhält.
Setzen Sie Mobbing fort und beenden Sie foo.service:
Was wir hier sehen: mrichter hat 5% der Prozessorzeit und die restlichen 95% des Systems sind inaktiv. Formeller Spott, ja.
Tatsächlich können Sie mit diesem Ansatz Dienste oder Anwendungen effektiv beruhigen, die plötzlich alle Prozessorressourcen zum Nachteil anderer Prozesse schwingen und zu sich ziehen möchten.
Also haben wir gelernt, wie man die aktuelle Situation mit cgroups kontrolliert. Jetzt gehen wir etwas tiefer und sehen, wie cgroup auf der Ebene des virtuellen Dateisystems implementiert wird.
Das Stammverzeichnis für alle laufenden cgroups befindet sich unter / sys / fs / cgroup. Wenn das System gestartet wird, wird es voll, wenn Dienste und andere Aufgaben gestartet werden. Beim Starten und Stoppen von Diensten werden deren Unterverzeichnisse angezeigt und ausgeblendet.
Im folgenden Screenshot haben wir ein Unterverzeichnis für den CPU-Controller aufgerufen, nämlich das System-Slice. Wie Sie sehen, ist das Unterverzeichnis für foo noch nicht hier. Führen Sie foo aus und überprüfen Sie einige Dinge, nämlich die PID und den aktuellen CPU-Ball:
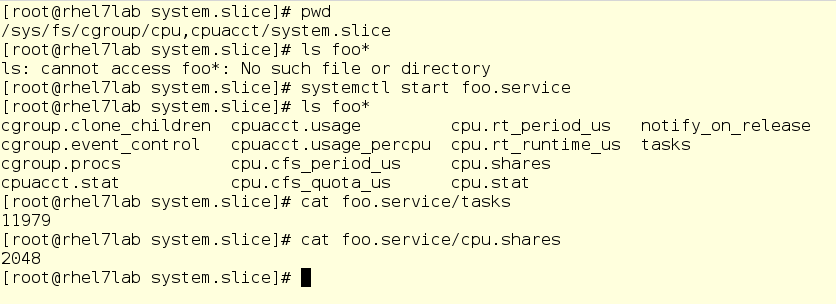
Wichtiger Hinweis: Hier können Sie Werte im laufenden Betrieb ändern. Ja, theoretisch sieht es cool aus (und in Wirklichkeit auch), aber es kann zu einem großen Durcheinander werden. Bevor Sie etwas ändern, wägen Sie daher alles sorgfältig ab und spielen Sie niemals auf Kampfservern. Ein virtuelles Dateisystem ist jedoch etwas, in das Sie sich vertiefen können, wenn Sie lernen, wie cgroups funktionieren.