Die erste Ausgabe der CTP-Version von SQL Server 2019 wurde am 24. September vorgestellt. Ich möchte sagen, dass sie alle möglichen Verbesserungen und neuen Funktionen enthält (von denen viele im Vorschau-Formular in der Azure SQL-Datenbank enthalten sind). Ich hatte die außergewöhnliche Gelegenheit, dies etwas früher kennenzulernen, wodurch ich mein Verständnis der Veränderungen auch oberflächlich erweitern konnte. Sie können auch die
neuesten Veröffentlichungen des SQL Server-Teams und die
aktualisierte Dokumentation lesen.
Ohne auf Details einzugehen, werde ich die folgenden neuen Kernelfunktionen diskutieren: Leistung, Fehlerbehebung, Sicherheit, Verfügbarkeit und Entwicklung. Im Moment habe ich etwas mehr Details als andere, und einige von ihnen sind bereits für die Veröffentlichung vorbereitet. Ich werde auf diesen Abschnitt sowie auf viele andere Artikel und Dokumentationen zurückkommen und sie veröffentlichen. Ich möchte Sie schnell darüber informieren, dass dies keine umfassende Überprüfung ist, sondern nur ein Teil der Funktionalität, die ich bis CTP 2.0 „berühren“ konnte. Es gibt noch viel zu erzählen.
Leistung
Tabellenvariablen: Verzögerte Planerstellung
Die Tabellenvariablen haben vor allem im Bereich der Kostenschätzung einen nicht sehr guten Ruf. Standardmäßig geht SQL Server davon aus, dass eine Tabellenvariable nur eine Zeile enthalten kann, was manchmal zu einer unzureichenden Auswahl des Plans führt, wenn die Variable ein Vielfaches mehr Zeilen enthält. OPTION (RECOMPILE) wird normalerweise als Problemumgehung verwendet. Dies erfordert jedoch Codeänderungen und ist in Bezug auf Ressourcen verschwenderisch, um jedes Mal eine Neuerstellung durchzuführen, während die Anzahl der Zeilen meistens gleich ist. Um die Neuerstellung zu emulieren, wurde
das Ablaufverfolgungsflag 2453 eingeführt, es erfordert jedoch auch einen Start mit dem Flag und funktioniert nur, wenn eine signifikante Änderung in den Zeilen auftritt.
Auf Kompatibilitätsstufe 150 wird eine verzögerte Konstruktion durchgeführt, wenn Tabellenvariablen vorhanden sind und der Abfrageplan erst erstellt wird, wenn die Tabellenvariable einmal ausgefüllt wird. Die Kosten werden basierend auf den Ergebnissen der ersten Verwendung der Tabellenvariablen ohne weitere Neuerstellung geschätzt. Dies ist ein Kompromiss zwischen der ständigen Neuerstellung, um die genauen Kosten zu erhalten, und dem völligen Fehlen einer Neuerstellung mit konstanten Kosten 1. Wenn die Anzahl der Zeilen relativ konstant bleibt, ist dies ein guter Indikator (und noch besser, wenn die Anzahl 1 überschreitet), kann aber weniger rentabel sein, wenn Die Anzahl der Zeilen ist sehr unterschiedlich.
Ich habe eine ausführlichere Analyse in einem kürzlich erschienenen Artikel
Tabellarische Variablen vorgestellt: Verzögerte Erstellung in SQL Server , und Brent Ozar hat darüber auch in dem Artikel
Schnelle tabellarische Variablen (und neue Probleme bei der Parameteranalyse) gesprochen .
Speicherzuweisungs-Feedback im String-Modus
SQL Server 2017 verfügt über ein Feedback zur Stapelspeicherzuweisung, das
hier ausführlich beschrieben wird. Im Wesentlichen wertet SQL Server für jede Speicherzuweisung, die einem Abfrageplan zugeordnet ist, der Stapelmodusanweisungen enthält, den von der Abfrage verwendeten Speicher aus und vergleicht ihn mit dem angeforderten Speicher. Wenn der angeforderte Speicher zu klein oder zu groß ist, was zu einer Überlastung der Tempdb oder einer Verschwendung von Speicher führt, wird beim nächsten Start der zugewiesene Speicher für den entsprechenden Abfrageplan angepasst. Durch dieses Verhalten wird entweder das zugewiesene Volume reduziert und die Parallelität erweitert oder erhöht, um die Leistung zu verbessern.
Jetzt erhalten wir das gleiche Verhalten für Abfragen im Zeichenfolgenmodus unter Kompatibilitätsstufe 150. Wenn die Abfrage gezwungen wurde, Daten auf der Festplatte zusammenzuführen, wird der zugewiesene Speicher für nachfolgende Starts erhöht. Wenn nach Abschluss der Anforderung die Hälfte des Speichers benötigt wurde, als zugewiesen wurde, wird er für nachfolgende Anforderungen nach unten angepasst. Bretn Ozar beschreibt dies ausführlicher in seinem Artikel
Conditional Memory Allocation .
Stapelmodus für die zeilenweise Speicherung
Ab SQL Server 2012 hat das Abfragen von Tabellen mit Spaltenindizes von einer verbesserten Leistung im Stapelmodus profitiert. Leistungsverbesserungen sind auf einen Abfrageprozessor zurückzuführen, der eher eine Stapelverarbeitung als eine zeilenweise Verarbeitung durchführt. Zeilen werden auch vom Speicherkern in Paketen verarbeitet, wodurch Parallelitätsaustauschanweisungen vermieden werden. Paul White (
@SQL_Kiwi ) erinnerte mich daran, dass, wenn Sie eine leere Tabelle mit Spaltenspeicher verwenden, um
Stapelmodusoperationen zu ermöglichen, die verarbeiteten Zeilen durch eine unsichtbare Anweisung in Paketen gesammelt werden. Diese Krücke kann jedoch Verbesserungen aus der Stapelverarbeitung zunichte machen. Einige Informationen hierzu finden Sie in der
Antwort auf Stack Exchange .
Auf Kompatibilitätsstufe 150 wählt SQL Server 2019 in bestimmten Fällen automatisch den Stapelmodus als Mittelweg aus, selbst wenn keine Spaltenindizes vorhanden sind. Sie könnten denken, warum nicht einfach einen Spaltenindex und einen Hut erstellen? Oder weiterhin die oben genannte Krücke benutzen? Dieser Ansatz wurde auf herkömmliche Objekte mit zeilenbasiertem Speicher ausgedehnt, da Spaltenindizes aus mehreren Gründen nicht immer möglich sind, einschließlich Funktionseinschränkungen (z. B. Trigger), Overhead bei hoch geladenen Aktualisierungs- oder Löschvorgängen und mangelnder Unterstützung durch Dritthersteller. Und von dieser Krücke ist nichts Gutes zu erwarten.
Ich habe eine sehr einfache Tabelle mit 10 Millionen Zeilen und einem Clustered-Index für eine Ganzzahlspalte erstellt und diese Abfrage ausgeführt:
SELECT sa5, sa2, SUM(i1), SUM(i2), COUNT(*) FROM dbo.FactTable WHERE i1 > 100000 GROUP BY sa5, sa2 ORDER BY sa5, sa2;
Der Plan zeigt deutlich die Suche nach geclusterten Indizes und die Parallelität, jedoch kein Wort zum Spaltenindex (wie
SentryOne Plan Explorer zeigt):
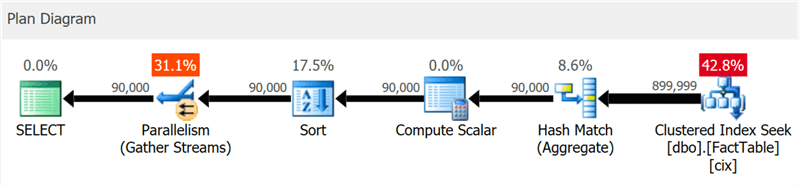
Wenn Sie jedoch etwas tiefer graben, können Sie sehen, dass fast alle Operatoren im Batch-Modus ausgeführt wurden, sogar Sortier- und Skalarberechnungen:

Sie können diese Funktion deaktivieren, indem Sie auf einer niedrigeren Kompatibilitätsstufe bleiben, indem Sie die Datenbankkonfiguration ändern oder die Eingabeaufforderung DISALLOW_BATCH_MODE in der Abfrage verwenden:
SELECT … OPTION (USE HINT ('DISALLOW_BATCH_MODE'));
In diesem Fall wird ein zusätzlicher Austauschoperator angezeigt, alle Operatoren werden zeilenweise ausgeführt und die Ausführungszeit für Abfragen wird fast verdreifacht.

Ab einer bestimmten Ebene können Sie dies im Diagramm sehen, aber im Detailbaum des Plans können Sie auch den Einfluss einer Auswahlbedingung sehen, die Zeilen erst nach dem Sortieren ausschließen kann:

Die Wahl des Batch-Modus ist nicht immer ein guter Schritt - die im Entscheidungsalgorithmus enthaltene Heuristik berücksichtigt die Anzahl der Zeilen, die Arten der vorgeschlagenen Operatoren und die erwarteten Vorteile des Batch-Modus.
APPROX_COUNT_DISTINCT
Diese neue Aggregatfunktion ist für Data Warehousing-Szenarien vorgesehen und entspricht COUNT (DISTINCT ()). Anstatt jedoch kostspielige Sortierungen durchzuführen, um die tatsächliche Menge zu bestimmen, stützt sich die neue Funktion auf Statistiken, um relativ genaue Daten zu erhalten. Sie müssen verstehen, dass der Fehler innerhalb von 2% des genauen Betrags liegt. In 97% der Fälle, die für Analysen auf hoher Ebene üblich sind, werden diese Werte auf Indikatoren angezeigt oder für schnelle Bewertungen verwendet.
Auf meinem System habe ich eine Tabelle mit ganzzahligen Spalten erstellt, die eindeutige Werte im Bereich von 100 bis 1.000.000 und Zeilenspalten mit eindeutigen Werten im Bereich von 100 bis 100.000 enthalten. Sie enthielt keine Indizes außer dem gruppierten Primärschlüssel im ersten Ganzzahlspalte. Hier sind die Ergebnisse der Ausführung von COUNT (DISTINCT ()) und APPROX_COUNT_DISTINCT () für diese Spalten, anhand derer Sie geringfügige Abweichungen feststellen können (jedoch immer innerhalb von 2%):
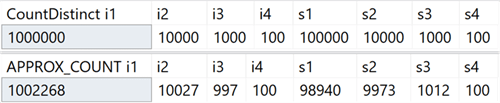
Der Gewinn ist enorm, wenn es Speicherbeschränkungen gibt, die für die meisten von uns gelten. Wenn Sie sich die Abfragepläne ansehen, können Sie in diesem speziellen Fall einen großen Unterschied im Speicherverbrauch des Hash-Match-Operators feststellen:

Beachten Sie, dass Sie in der Regel nur dann signifikante Leistungsverbesserungen feststellen, wenn Sie bereits speichergebunden sind. Auf meinem System dauerte die Ausführung aufgrund der hohen CPU-Auslastung der neuen Funktion etwas länger:

Vielleicht wäre der Unterschied bedeutender, wenn ich größere Tabellen, weniger Speicher für SQL Server, eine höhere Parallelität oder eine Kombination der oben genannten hätte.
Tipps zur Verwendung der Kompatibilitätsstufe innerhalb einer Abfrage
Haben Sie eine spezielle Abfrage, die unter einer bestimmten Kompatibilitätsstufe besser funktioniert als die aktuelle Datenbank? Dies ist jetzt dank neuer Abfragehinweise möglich, die sechs verschiedene Kompatibilitätsstufen und fünf verschiedene Modelle zur Schätzung der Anzahl der Elemente unterstützen. Im Folgenden sind die verfügbaren Kompatibilitätsstufen, eine Beispielsyntax und ein jeweils verwendetes Kompatibilitätsstufenmodell aufgeführt. Sehen Sie, wie sich dies auf Bewertungen auswirkt, auch für Systemansichten:

Kurz gesagt: Sie müssen sich nicht mehr an die Ablaufverfolgungsflags erinnern oder sich fragen, ob Sie sich Gedanken darüber machen müssen, ob der TF 4199-Patch für das Abfrageoptimierungsprogramm verteilt wurde oder von einem anderen Service Pack abgebrochen wurde. Beachten Sie, dass diese zusätzlichen Hinweise kürzlich auch für SQL Server 2017 im kumulativen Update Nr. 10 hinzugefügt wurden (Einzelheiten finden Sie
im Blog von Pedro Lopez ). Sie können alle verfügbaren Hinweise mit dem folgenden Befehl anzeigen:
SELECT name FROM sys.dm_exec_valid_use_hints;
Vergessen Sie jedoch nicht, dass Hinweise eine außergewöhnliche Maßnahme sind. Sie eignen sich häufig, um aus einer schwierigen Situation herauszukommen, sollten jedoch nicht für die langfristige Verwendung geplant werden, da sich ihr Verhalten bei nachfolgenden Aktualisierungen ändern kann.
Fehlerbehebung
Vereinfachte Standardprofilerstellung
Um diese Verbesserung zu verstehen, müssen einige Punkte beachtet werden. In SQL Server 2014 wurde die Ansicht DMV sys.dm_exec_query_profiles eingeführt, mit der der Benutzer, der die Abfrage ausführt, Diagnoseinformationen zu allen Anweisungen in allen Teilen der Abfrage erfassen kann. Die gesammelten Informationen werden nach Abschluss der Abfrage verfügbar und ermöglichen es Ihnen zu bestimmen, welche Bediener die Hauptressourcen tatsächlich ausgegeben haben und warum. Jeder Benutzer, der eine bestimmte Anforderung nicht erfüllt hat, kann diese Daten für jede Sitzung empfangen, in der die Anweisung STATISTICS XML oder STATISTICS PROFILE enthalten war, oder für alle Sitzungen, die das erweiterte Ereignis query_post_execution_showplan verwenden, obwohl dieses Ereignis insbesondere die Gesamtleistung beeinträchtigen kann.
In Management Studio 2016 wurde eine Funktion hinzugefügt, mit der Sie Datenströme, die den Abfrageplan durchlaufen, in Echtzeit basierend auf den von DMV gesammelten Informationen anzeigen können, wodurch die Fehlerbehebung noch leistungsfähiger wird. Der Plan Explorer bietet auch die Möglichkeit, Daten, die die Abfrage durchlaufen, sowohl in Echtzeit als auch im Wiedergabemodus zu visualisieren.
Ab SQL Server 2016 Service Pack 1 (SP1) können Sie auch eine einfache Version der Datenerfassung für alle Sitzungen mithilfe des Ablaufverfolgungsflags 7412 oder der erweiterten Eigenschaft query_thread_profile aktivieren, mit der Sie sofort aktuelle Informationen zu jeder Sitzung abrufen können, ohne dass etwas erforderlich ist Nehmen Sie dies ausdrücklich auf (insbesondere Dinge, die die Leistung beeinträchtigen). Dies wird
im Blog von Pedro Lopez ausführlicher beschrieben.
In SQL Server 2019 ist diese Funktion standardmäßig aktiviert, sodass Sie in keiner Abfrage Sitzungen mit erweiterten Ereignissen ausführen oder Ablaufverfolgungsflags und STATISTICS-Anweisungen verwenden müssen. Schauen Sie sich jederzeit die Daten der DMV für alle gleichzeitigen Sitzungen an. Es ist jedoch möglich, diesen Modus mit LIGHTWEIGHT_QUERY_PROFILING zu deaktivieren. Diese Syntax funktioniert jedoch nicht in CTP 2.0 und wird in zukünftigen Editionen behoben.
Statistiken zu gruppierten Spaltenindizes sind jetzt in geklonten Datenbanken verfügbar
In aktuellen Versionen von SQL Server werden beim Klonen einer Datenbank nur die ursprünglichen Objektstatistiken aus gruppierten Spaltenindizes verwendet, ausgenommen Aktualisierungen, die nach ihrer Erstellung an der Tabelle vorgenommen wurden. Wenn Sie einen Klon verwenden, um Abfragen und andere Leistungstests zu konfigurieren, die auf Nennleistungen basieren, funktionieren diese Beispiele möglicherweise nicht. Parikshit Savyani beschrieb die Einschränkungen
in dieser Veröffentlichung und stellte eine temporäre Lösung bereit. Bevor Sie den Klon erstellen, müssen Sie ein Skript erstellen, das DBCC SHOW_STATISTICS ... WITH STATS_STREAM für jedes Objekt ausführt. Es ist teuer und natürlich leicht zu vergessen.
In SQL Server 2019 sind diese aktualisierten Statistiken automatisch im Klon verfügbar, sodass Sie verschiedene Abfrageszenarien testen und objektive Pläne basierend auf realen Statistiken abrufen können, ohne STATS_STREAM für alle Tabellen manuell ausführen zu müssen.
Komprimierungsprognose für die Spaltenspeicherung
In aktuellen Versionen wird die Prozedur sys.sp_estimate_data_compression_savings wie folgt überprüft:
if (@data_compression not in ('NONE', 'ROW', 'PAGE'))
Dies bedeutet, dass Sie die Komprimierung einer Zeile oder Seite überprüfen können (oder das Ergebnis des Löschens der aktuellen Komprimierung sehen können). In SQL Server 2019 sieht diese Prüfung jetzt folgendermaßen aus:
if (@data_compression not in ('NONE', 'ROW', 'PAGE', 'COLUMNSTORE', 'COLUMNSTORE_ARCHIVE'))
Dies ist eine gute Nachricht, da Sie damit die Auswirkungen des Hinzufügens eines Spaltenindex zu einer Tabelle ohne diese Tabelle grob vorhersagen oder Tabellen oder Partitionen in ein noch komprimierteres Spaltenspeicherformat konvertieren können, ohne die Tabelle auf einem anderen System wiederherstellen zu müssen. Ich hatte eine Tabelle mit 10 Millionen Zeilen, für die ich eine gespeicherte Prozedur mit jedem der fünf Parameter durchgeführt habe:
EXEC sys.sp_estimate_data_compression_savings @schema_name = N'dbo', @object_name = N'FactTable', @index_id = NULL, @partition_number = NULL, @data_compression = N'NONE';
Ergebnisse:

Wie bei anderen Komprimierungsarten hängt die Genauigkeit vollständig von den verfügbaren Zeilen und der Repräsentativität der übrigen Daten ab. Dies ist jedoch eine ziemlich leistungsstarke Methode, um ohne große Schwierigkeiten vorhersehbare Ergebnisse zu erzielen.
Neue Funktion zum Abrufen von Seiteninformationen
DBCC PAGE und DBCC IND wurden lange Zeit verwendet, um Informationen über Seiten zu sammeln, die einen Abschnitt, einen Index oder eine Tabelle enthalten. Sie sind jedoch nicht dokumentiert und werden nicht unterstützt. Es kann mühsam sein, die Lösung von Aufgaben zu automatisieren, die mit mehreren Indizes oder Seiten verbunden sind.
Später wurde eine dynamische Verwaltungsfunktion (DMF) sys.dm_db_database_page_allocations angezeigt, die einen Satz zurückgibt, der alle Seiten im angegebenen Objekt darstellt. Immer noch undokumentiert und mit Fehlern, die bei großen Tabellen zu einem echten Problem werden können: Selbst um Informationen über eine Seite zu erhalten, muss die gesamte Struktur gelesen werden, was sehr teuer sein kann.
In SQL Server 2019 wurde ein weiteres DMF angezeigt - sys.dm_db_page_info. Grundsätzlich werden alle Seiteninformationen ohne den Aufwand der DMF-Verteilung zurückgegeben. Um die Funktion in aktuellen Builds verwenden zu können, müssen Sie die Nummer der gesuchten Seite im Voraus kennen. Vielleicht wurde dieser Schritt absichtlich gemacht, weil Nur so kann die Leistung sichergestellt werden. Wenn Sie also versuchen, alle Seiten in einem Index oder einer Tabelle zu identifizieren, müssen Sie weiterhin die DMF-Verteilung verwenden. Im nächsten Artikel werde ich diese Frage genauer beschreiben.
Sicherheit
Permanente Verschlüsselung in einer sicheren Umgebung (Enklave)
Derzeit schützt die permanente Verschlüsselung vertrauliche Daten während der Übertragung und im Speicher durch Ver- / Entschlüsselung an jedem Ende des Prozesses. Leider führt dies häufig zu schwerwiegenden Einschränkungen bei der Arbeit mit Daten, z. B. der Unfähigkeit, Berechnungen und Filter durchzuführen. Daher müssen Sie den gesamten Datensatz auf die Clientseite übertragen, um beispielsweise eine Bereichssuche durchzuführen.
Eine sichere Umgebung (Enklave) ist ein geschützter Speicherbereich, in dem solche Berechnungen und Filter delegiert werden können (Windows verwendet
virtualisierungsbasierte Sicherheit ). Die Daten bleiben im Kernel verschlüsselt, können jedoch in einer sicheren Umgebung sicher entschlüsselt oder verschlüsselt werden. Sie müssen lediglich den Parameter ENCLAVE_COMPUTATIONS mithilfe von SSMS zum Primärschlüssel hinzufügen, indem Sie beispielsweise das Kontrollkästchen "Berechnungen in einer sicheren Umgebung zulassen" aktivieren:
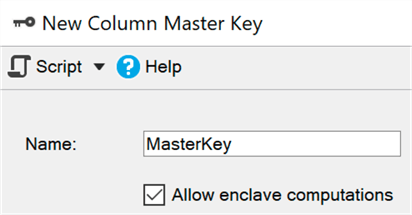
Jetzt können Sie Daten im Vergleich zur alten Methode (bei der der Assistent, das Cmdlet Set-SqlColumnEncyption oder Ihre Anwendung den gesamten Satz vollständig aus der Datenbank abrufen, verschlüsseln und zurücksenden müssten) fast sofort verschlüsseln:
ALTER TABLE dbo.Patients ALTER COLUMN SSN char(9)
Ich denke, dass für viele Unternehmen diese Verbesserung die Hauptnachricht sein wird, aber im aktuellen CTP werden einige dieser Subsysteme noch verbessert, daher sind sie standardmäßig deaktiviert, aber
hier können Sie sehen, wie sie aktiviert werden.
Zertifikatverwaltung in Configuration Manager
Das Verwalten von SSL- und TLS-Zertifikaten war schon immer ein Problem, und viele Menschen waren gezwungen, mühsam eigene Skripts zu erstellen, um ihre Unternehmenszertifikate bereitzustellen und zu verwalten. Mit dem aktualisierten Configuration Manager für SQL Server 2019 können Sie schnell Zertifikate einer Instanz anzeigen und überprüfen, bald ablaufende Zertifikate finden und Zertifikatbereitstellungen für alle Replikationen in der Verfügbarkeitsgruppe oder alle Knoten in der Failoverclusterinstanz synchronisieren.
Ich habe nicht alle diese Vorgänge ausprobiert, aber sie sollten für frühere Versionen von SQL Server funktionieren, wenn die Verwaltung von SQL Server 2019 Configuration Manager stammt.
Integrierte Datenklassifizierung und -prüfung
Das SQL Server-Entwicklungsteam hat die Möglichkeit hinzugefügt, Daten in SSMS 17.5 zu klassifizieren. Auf diese Weise können Sie alle Spalten identifizieren, die vertrauliche Informationen enthalten oder verschiedenen Standards widersprechen (natürlich HIPAA, SOX, PCI und GDPR). Der Assistent verwendet einen Algorithmus, der Spalten anbietet, die Probleme verursachen sollen. Sie können jedoch entweder den Satz anpassen, indem Sie diese Spalten aus der Liste entfernen, oder eigene hinzufügen. Zum Speichern der Klassifizierung werden erweiterte Eigenschaften verwendet. Der integrierte SSMS-Bericht verwendet dieselben Informationen, um seine Daten anzuzeigen. Außerhalb des Berichts sind diese Eigenschaften nicht so offensichtlich.
SQL Server 2019 hat eine neue Anweisung für diese Metadaten eingeführt, die bereits in der Azure SQL-Datenbank verfügbar ist und den Namen ADD SENSITIVITY CLASSIFICATION trägt. Sie können das Gleiche wie der Assistent in SSMS tun, die Informationen werden jedoch nicht mehr in der erweiterten Eigenschaft gespeichert, und der Zugriff auf diese Daten wird im Audit automatisch als neue XML-Spalte data_sensitivity_information angezeigt. Es enthält alle Arten von Informationen, die während des Audits betroffen waren.
Angenommen, ich habe eine Tabelle für externe Auftragnehmer:
CREATE TABLE dbo.Contractors ( FirstName sysname, LastName sysname, SSN char(9), HourlyRate decimal(6,2) );
Bei Betrachtung einer solchen Struktur wird deutlich, dass alle vier Spalten entweder potenziell anfällig für Leckagen sind oder nur einem begrenzten Personenkreis zugänglich sein sollten. Hier können Sie mit Berechtigungen auskommen, aber zumindest müssen Sie sich auf diese konzentrieren. Daher können wir diese Spalten auf verschiedene Arten klassifizieren:
ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.FirstName, dbo.Contractors.LastName WITH (LABEL = 'Confidential – GDPR', INFORMATION_TYPE = 'Personal Info'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.SSN WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'National ID'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.HourlyRate WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'Financial');
Anstatt sich sys.extended_properties anzusehen, können Sie sie jetzt in sys.sensitivity_classifications sehen:

Und wenn wir für diese Tabelle Audit Sampling (oder DML) durchführen, müssen wir nichts speziell ändern. Nach dem Erstellen der Klassifizierung zeichnet
SELECT * im Überwachungsprotokoll einen Datensatz dieser Art von Informationen in einer neuen Spalte data_sensitivity_information auf:
<sensitivity_attributes> <sensitivity_attribute label="Confidential - GDPR" information_type="Personal Info" /> <sensitivity_attribute label="Highly Confidential" information_type="National ID" /> <sensitivity_attribute label="Highly Confidential" information_type="Financial" /> </sensitivity_attributes>
Dies löst natürlich nicht alle Probleme der Einhaltung von Standards, kann aber einen echten Vorteil bringen. Die Verwendung des Assistenten zum automatischen Identifizieren von Spalten und zum Übersetzen von sp_addextendedproperty-Aufrufen in ADD SENSITIVITY CLASSIFICATION-Befehle kann die Einhaltung von Standards erheblich vereinfachen. Später werde ich einen separaten Artikel darüber schreiben.
Sie können auch die Erstellung (oder Aktualisierung) von Berechtigungen basierend auf der Bezeichnung in den Metadaten automatisieren - die Erstellung eines dynamischen SQL-Skripts, das den Zugriff auf alle vertraulichen (GDPR) Spalten verbietet, mit denen Sie Benutzer, Gruppen oder Rollen verwalten können. Ich werde in Zukunft an diesem Thema arbeiten.
Verfügbarkeit
Erstellung eines erneuerbaren Index in Echtzeit
In SQL Server 2017 wurde es möglich, die Neuerstellung des Index in Echtzeit anzuhalten und fortzusetzen. Dies kann sehr nützlich sein, wenn Sie die Anzahl der verwendeten Prozessoren ändern, ab dem Zeitpunkt der Unterbrechung nach einem Fehler fortfahren oder einfach die Lücke zwischen den Servicefenstern schließen müssen. Ich habe in einem
früheren Artikel über diese Funktion gesprochen.
In SQL Server 2019 können Sie dieselbe Syntax verwenden, um Echtzeitindizes zu erstellen, anzuhalten und fortzufahren sowie die Ausführungszeit zu begrenzen (Festlegen der Pausenzeit):
CREATE INDEX foo ON dbo.bar(blat) WITH (ONLINE = ON, RESUMABLE = ON, MAX_DURATION = 10 MINUTES);
Wenn diese Abfrage zu lange funktioniert, können Sie zum Anhalten ALTER INDEX in einer anderen Sitzung ausführen (auch wenn der Index physisch noch nicht vorhanden ist):
ALTER INDEX foo ON dbo.bar PAUSE;
In aktuellen Builds kann der Grad der Parallelität während der Erneuerung nicht verringert werden, wie dies beim Wiederaufbau der Fall ist. Beim Versuch, DOP zu reduzieren:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 2);
Wir bekommen folgendes:
Msg 10666, Level 16, State 1, Line 3 Cannot resume index build as required DOP 4 (DOP operation was started with) is not available. Please ensure sufficient DOP is available or abort existing index operation and try again. The statement has been terminated.
Wenn Sie dies versuchen und dann den Befehl ohne zusätzliche Parameter ausführen, wird derselbe Fehler angezeigt, zumindest bei den aktuellen Builds. Ich denke, dass der Erneuerungsversuch irgendwo aufgezeichnet wurde und das System ihn wieder verwenden wollte. Um fortzufahren, müssen Sie den richtigen (oder höheren) DOP-Wert angeben:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 4);
Um es klar zu machen: Sie können den DOP erhöhen, wenn Sie eine angehaltene Indexerstellung fortsetzen, aber nicht senken.
Ein zusätzlicher Vorteil davon ist, dass Sie die Erstellung und / oder Erneuerung von Indizes in Echtzeit als Standardmodus konfigurieren können, indem Sie die Klauseln ELEVATE_ONLINE und ELEVATE_RESUMABLE für die neue Datenbank verwenden.
Echtzeiterstellung / Neuerstellung von gruppierten Spaltenindizes
Neben der Erstellung erneuerbarer Indizes haben wir auch die Möglichkeit, Clustered-Column-Indizes in Echtzeit zu erstellen oder neu zu erstellen. Dies ist eine wesentliche Änderung, die es Ihnen ermöglicht, die Zeit der Servicefenster nicht mehr für die Pflege solcher Indizes zu verwenden oder (zur größeren Sicherheit) Indizes von zeilenweise in spaltenweise umzuwandeln:
CREATE TABLE dbo.splunge ( id int NOT NULL ); GO CREATE UNIQUE CLUSTERED INDEX PK_Splunge ON dbo.splunge(id); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (DROP_EXISTING = ON, ONLINE = ON);
Eine Warnung: Wenn ein vorhandener traditioneller Clustered-Index in Echtzeit erstellt wurde, ist seine Konvertierung in einen Clustered-Spaltenindex auch nur in diesem Modus möglich. Wenn es Teil des Primärschlüssels ist, eingebaut oder nicht ... CREATE TABLE dbo.splunge ( id int NOT NULL CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED (id) ); GO
Wir erhalten folgenden Fehler: Msg 1907, Level 16 Cannot recreate index 'PK_Splunge'. The new index definition does not match the constraint being enforced by the existing index.
Sie müssen zuerst die Einschränkung entfernen, um sie in einen gruppierten Spaltenindex zu konvertieren. Beide Vorgänge können jedoch in Echtzeit ausgeführt werden: ALTER TABLE dbo.splunge DROP CONSTRAINT PK_Splunge WITH (ONLINE = ON); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (ONLINE = ON);
Dies funktioniert, aber große Tabellen dauern wahrscheinlich länger als wenn der Primärschlüssel als eindeutiger Clustered-Index implementiert würde. Ich kann nicht sicher sagen, ob dies eine absichtliche Einschränkung oder nur eine Einschränkung des aktuellen CTP ist.Umleiten einer Replikationsverbindung von einem sekundären Server zu einem primären
Mit dieser Funktion können Sie die Umleitung konfigurieren, ohne zu lauschen, sodass Sie die Verbindung zum Primärserver wechseln können, auch wenn der Sekundärserver direkt in der Verbindungszeichenfolge angegeben ist. Diese Funktion kann verwendet werden, wenn die Clustering-Technologie das Abhören nicht unterstützt, wenn AGs ohne Cluster verwendet werden oder wenn in einem Szenario mit mehreren Subnetzen ein komplexes Umleitungsschema vorhanden ist. Dadurch wird verhindert, dass die Verbindung beispielsweise Schreibvorgänge für die schreibgeschützte Replikation (bzw. Fehler) versucht.Entwicklung
Zusätzliche Funktionen des Diagramms
Diagrammbeziehungen unterstützen jetzt die MERGE-Anweisung für einen Knoten oder Grenztabellen unter Verwendung von MERGE-Prädikaten. Jetzt kann ein Bediener eine vorhandene Kante aktualisieren oder eine neue einfügen. Mit der neuen Kantenbeschränkung können Sie bestimmen, welche Knoten die Kante verbinden kann.Utf-8
SQL Server 2012 hat die Unterstützung für UTF-16 und zusätzliche Zeichen hinzugefügt, indem die Sortierung durch Angabe eines Namens mit dem Suffix _SC festgelegt wurde, z. B. Latin1_General_100_CI_AI_SC, um Unicode-Spalten (nchar / nvarchar) zu verwenden. In SQL Server 2017 können Sie UTF-8-Daten mit Tools wie BCP und BULK INSERT aus und in diese Spalten importieren und exportieren .In SQL Server 2019 gibt es neue Sortieroptionen, um die erzwungene Aufbewahrung von UTF-8-Daten in ihrer ursprünglichen Form zu unterstützen. Mit der neuen Sortierung mit dem Suffix _SC_UTF8 wie Latin1_General_100_CI_AI_SC_UTF8 können Sie auf einfache Weise Zeichen- oder Varchar-Spalten erstellen und UTF-8-Daten korrekt speichern. Dies kann dazu beitragen, die Kompatibilität mit externen Anwendungen und DBMS zu verbessern, ohne die Kosten für die Verarbeitung und Speicherung von nvarchar zu verursachen.Osterei habe ich gefunden
Soweit ich mich erinnere, beschweren sich SQL Server-Benutzer über diese vage Fehlermeldung: Msg 8152 String or binary data would be truncated.
In den CTP-Builds, mit denen ich experimentiert habe, wurde eine interessante Fehlermeldung festgestellt, die vorher nicht vorhanden war: Msg 2628 String or binary data would be truncated in table '%.*ls', column '%.*ls'. Truncated value: '%.*ls'
Ich denke, hier wird nichts anderes benötigt. Dies ist eine große (wenn auch sehr späte) Verbesserung und verspricht, viele glücklich zu machen. Diese Funktionalität ist in CTP 2.0 jedoch nicht verfügbar. Ich gebe Ihnen nur die Gelegenheit, ein wenig nach vorne zu schauen. Brent Ozar listete alle neuen Nachrichten auf, die er im aktuellen CTP gefunden hatte, und würzte sie mit einigen hilfreichen Kommentaren in seinem Artikel sys.messages: Entdecken zusätzlicher Funktionen .Fazit
SQL Server 2019 bietet gute zusätzliche Funktionen, mit denen Sie die Arbeit mit Ihrer bevorzugten relationalen Datenbankplattform verbessern können, und es gibt eine Reihe von Änderungen, über die ich nicht gesprochen habe. Energieeffizienter Speicher, Clustering für maschinelle Lerndienste, Replikation und verteilte Transaktionen unter Linux, Kubernetes, Konnektoren für Oracle / Teradata / MongoDB, synchrone AG-Replikationen sind gestiegen, um Java (eine Implementierung ähnlich wie Python / R) und ebenso wichtig einen neuen Sprung zu unterstützen. mit dem Titel Big Data Cluster. Um einige dieser Funktionen nutzen zu können, müssen Sie sich mit diesem EAP-Formular registrieren .Bob Wards bevorstehendes Buch Pro SQL Server unter Linux - einschließlich containergestützter Bereitstellung mit Docker und Kuberneteskann einige Hinweise auf eine Reihe anderer Dinge geben, die bald kommen. Und diese Veröffentlichung von Brent Ozar spricht über eine mögliche bevorstehende Korrektur für eine skalare benutzerdefinierte Funktion.Aber selbst in dieser ersten öffentlichen CTP ist für fast jeden etwas Bedeutendes, und ich fordere Sie auf, es selbst zu versuchen!